- @2403_87387270
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
以影评情感分析为例,为你详细介绍自然语言处理的处理流程。在这个例子中,我们将使用 Python 和一些常用的 NLP 库,如nltk(自然语言工具包)和(机器学习库)。
在深度学习领域,循环神经网络(RNN)及其变体在处理序列数据时展现出了强大的威力。其中,门控循环单元(GRU)作为 RNN 的一种进阶架构,备受关注。今天,咱们就来深入聊聊 GRU 模型,重点探究一下它在训练过程中是否会出现梯度爆炸问题。
TenseFlow 脱胎于对传统深度学习框架局限性的深入思考,旨在构建一个更加灵活、高效且易于使用的开发环境。它汲取了诸多前沿研究成果,融合了多种编程范式的优势,致力于满足从学术研究到工业应用的广泛需求。与一些广为人知的老牌框架相比,TenseFlow 在架构设计上采用了创新性的模块化理念,各个模块既能独立运作以实现特定功能,又能无缝协同,让开发者能够根据项目的独特要求自由组合、定制。
我们使用子模块时,主项目提交的是子模块的引用(commit ID),而不是子模块的代码本身。所以,当你修改了子模块(lightrag)并提交后,需要在主项目中更新子模块的引用到最新的commit ID。然后提交主项目的更改(包括这个更新的引用)并推送到远程仓库。具体步骤如下:在子模块(lightrag)目录中提交更改并推送到其远程仓库。回到主项目,提交子模块的引用(即更新后的commit ID)。
bash# 推送到远程分支# 或者指定上游。
先跑通:两个项目独立运行,排除环境坑;建分支:只在分支开发,不碰原代码;改代码:只改 OCR 函数,在文本提取后加 LightRAG 切分 + 向量化 + 存库逻辑;嵌子模块(可选):需要改 LightRAG 代码时才嵌,否则直接 pip 安装即可;传分支:只传开发分支,原仓库 main 分支不动,子模块需单独传自己的仓库。
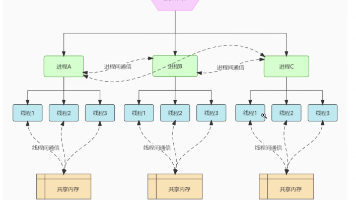
分类算法 分类器

本文介绍了基于BGE模型与Flask框架的智能问答系统开发实践。系统采用BGE-base-zh-v1.5模型进行文本语义编码,结合Faiss实现高效向量检索,并使用Flask搭建Web服务。开发流程包括数据准备、向量编码索引构建、检索逻辑实现(粗排+精排)以及服务封装等关键步骤。该系统可实现中文语义检索功能,适用于企业客服、知识库等场景,未来可通过扩展数据规模、优化模型性能等方式进一步提升效果。
{"instruction": "如何诊断射血分数保留的心力衰竭?", "input": "患者呼吸困难,超声显示LVEF 55%", "output": "HFpEF的诊断需满足三个条件..."},{"query": "HFrEF的诊断标准", "positive": "射血分数降低的心衰表现为LVEF<40%", "negative": "HFpEF的诊断要求LVEF不低于50%"},模型:
LightRAG 的检索机制核心是「模式化 + 可配置」:基础场景用 naive/local,追求速度;通用场景用 hybrid(默认),平衡精度与覆盖;复杂推理用 mix,依赖知识图谱 + 向量融合;纯 LLM 对比用 bypass;所有模式均可通过 top_k/Rerank/令牌数 调优,适配不同数据量和精度需求。GraphRAG:是“社区驱动的图谱检索”,适合大规模知识库的宏观分析,但依赖预