




- @2401_87638368
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
简单来说,Embedding 就是把人类的文字(词语、句子、甚至图像),翻译成计算机能懂的一长串数字(数组)。这串数字,在数学上就叫作“向量”。我们可以把向量在这个多维空间里想象成一个具体的“坐标”。语义相近的词(比如“高兴”和“开心”),它们在空间中的坐标离得非常近。语义无关的词(比如“高兴”和“水杯”),它们在空间中的坐标离得很远。我们不再匹配字面,而是匹配“意思”。这就是我们在 RAG 架构
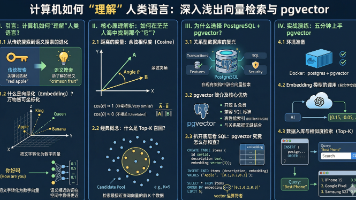
受限于大语言模型(LLM)的上下文窗口限制(Token Limit),以及向量模型在长文本提取核心语义时的局限性,我们需要将长篇大论的长文档“切碎”,变成一段段独立且短小精悍的文本块。这就是文档分块(Chunking)。这就好比在图书馆里找资料,我们找的不是某一本书,而是书中对应具体知识点的那几页。如果说向量检索是“海选”,为了效率通常选出几十个候选者(如 Top 20);那么重排就是“终面”。
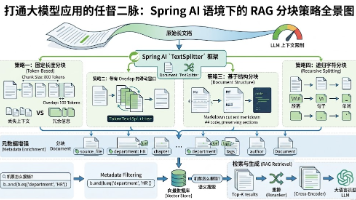
受限于大语言模型(LLM)的上下文窗口限制(Token Limit),以及向量模型在长文本提取核心语义时的局限性,我们需要将长篇大论的长文档“切碎”,变成一段段独立且短小精悍的文本块。这就是文档分块(Chunking)。这就好比在图书馆里找资料,我们找的不是某一本书,而是书中对应具体知识点的那几页。如果说向量检索是“海选”,为了效率通常选出几十个候选者(如 Top 20);那么重排就是“终面”。
RAG 就是给大模型装上了一个随时可以查阅的“外挂大脑”或“参考书”。没有 RAG(闭卷考试):模型只能单纯依靠在预训练阶段死记硬背下来的知识(肚子里的墨水)来硬答。遇到没背过或者忘了的题,就只能瞎蒙。有了 RAG(开卷考试):我们给大模型发了一本“参考书”(你的本地知识库)。当被问到问题时,它不再急着直接作答,而是先去书里查阅相关的资料,然后再结合查到的资料进行作答。这样一来,回答的准确率和时效
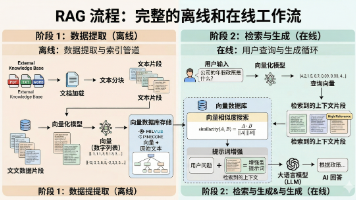
RAG 就是给大模型装上了一个随时可以查阅的“外挂大脑”或“参考书”。没有 RAG(闭卷考试):模型只能单纯依靠在预训练阶段死记硬背下来的知识(肚子里的墨水)来硬答。遇到没背过或者忘了的题,就只能瞎蒙。有了 RAG(开卷考试):我们给大模型发了一本“参考书”(你的本地知识库)。当被问到问题时,它不再急着直接作答,而是先去书里查阅相关的资料,然后再结合查到的资料进行作答。这样一来,回答的准确率和时效
代理模式(Proxy Pattern)是一种结构型设计模式,其核心思想是:为某个对象提供一个代理对象,由代理对象控制对原始对象的访问,从而在不修改原始类的前提下,增强其功能。把代理对象当作经纪人,把原始对象当明星,明星有完成演出的功能,经纪人负责在明星演出的前后做各种增强准备。客户端 ──► 代理对象(Proxy)──► 目标对象(Target)│增强逻辑(前置/后置/异常处理)IoC(Inver

事务(Transaction)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。这些操作要么全部执行成功,要么全部不执行,不存在部分执行的情况。
