




- @2301_80044974
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大家复现项目时可以把readme 丢给GPT 先了解整体需要做的流程框架,在复现项目之前先仔细阅读readme、分析项目框架,以下是我复现项目的相关流程以及遇到的问题。
每个状态可能做出多个动作,而且每个动作可能到达多个状态,图中的Π称之为策略或决策,P称为状态转移概率,我们将这马尔可夫过程称为。马尔可夫过程由五个基本的元素组成,S表示状态,A表示动作,P表示状态转移概率,γ表示折扣因子,R表示奖励(有时也称回报函数)。简单说:就是智能体在一个状态S下,选择了某个动作A,进入了另外一个状态S’,并获得奖励R的过程。如果(s,a)对应的下个状态s’是唯一的,那么回报
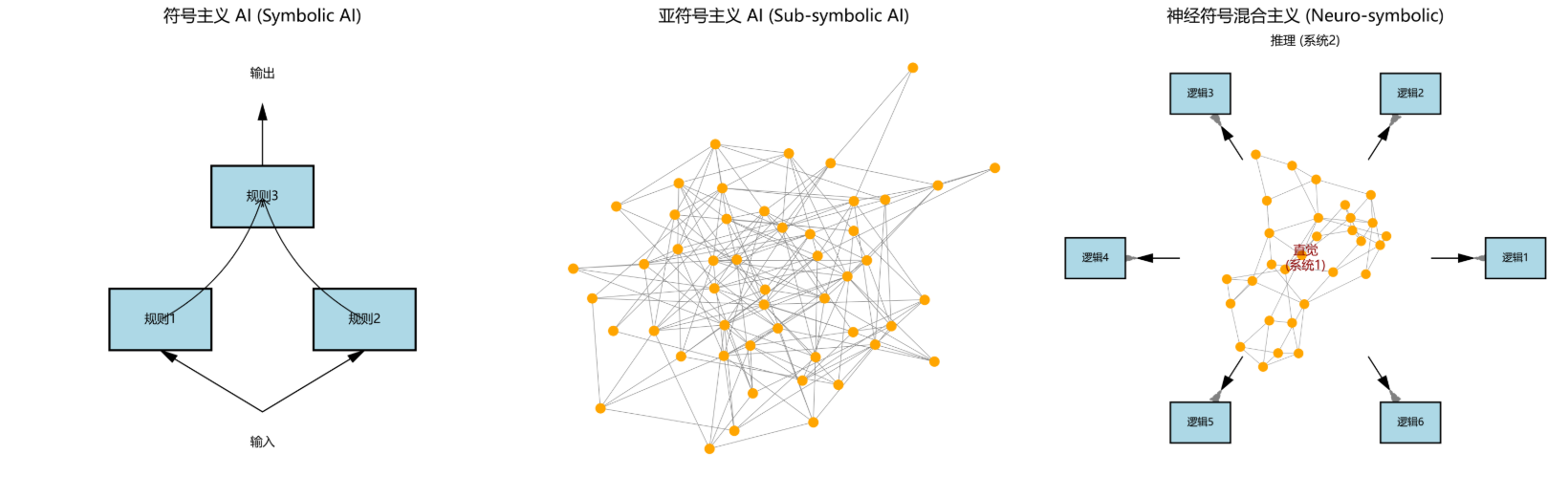
在人工智能领域,智能体被定义为任何能够通过传感器(Sensors)感知其所处环境(Environment),并自主地通过执行器(Actuators)采取行动(Action)以达成特定目标的实体。在人工智能领域,通常使用PEAS 模型来精确描述一个任务环境,即分析其性能度量(Performance)、环境(Environment)、执行器(Actuators)和传感器(Sensors)
传统的机器学习范式,智能体通过与环境交互,根据奖励信号学习最优策略。RL的一个特殊应用,专门用于训练大语言模型,奖励信号来源于人类的偏好反馈。: RLHF = RL + Reward Model(学习人类偏好)另外,传统RL的状态:是具体的环境状态(- Atari游戏: 84x84像素图像- 机器人: 关节角度向量 )动作是明确的控制指令 (-游戏: {上, 下, 左, 右} - 机器人: 每个关
本文摘要介绍了GRPO(Group Relative Policy Optimization)训练中的关键参数配置。主要包括:1)actor_rollout.ref.rollout.n控制每个prompt的采样次数;2)data.train_batch_size设置每次rollout的prompt数量;3)ppo_mini_batch_size决定PPO更新时的小批次大小;4)micro_batc
大家复现项目时可以把readme 丢给GPT 先了解整体需要做的流程框架,在复现项目之前先仔细阅读readme、分析项目框架,以下是我复现项目的相关流程以及遇到的问题。
传统的机器学习范式,智能体通过与环境交互,根据奖励信号学习最优策略。RL的一个特殊应用,专门用于训练大语言模型,奖励信号来源于人类的偏好反馈。: RLHF = RL + Reward Model(学习人类偏好)另外,传统RL的状态:是具体的环境状态(- Atari游戏: 84x84像素图像- 机器人: 关节角度向量 )动作是明确的控制指令 (-游戏: {上, 下, 左, 右} - 机器人: 每个关
传统的机器学习范式,智能体通过与环境交互,根据奖励信号学习最优策略。RL的一个特殊应用,专门用于训练大语言模型,奖励信号来源于人类的偏好反馈。: RLHF = RL + Reward Model(学习人类偏好)另外,传统RL的状态:是具体的环境状态(- Atari游戏: 84x84像素图像- 机器人: 关节角度向量 )动作是明确的控制指令 (-游戏: {上, 下, 左, 右} - 机器人: 每个关
大家复现项目时可以把readme 丢给GPT 先了解整体需要做的流程框架,在复现项目之前先仔细阅读readme、分析项目框架,以下是我复现项目的相关流程以及遇到的问题。