【问答对话】kbqa?开放域问答怎么有知识地生成
开放域问答怎么有知识地生成最近流行的大模型,如GPT-3也在开放域问答上有一定的能力,那么如何在大的语言模型基础上融合知识呢,其实主要面临两个问题,1)检索什么知识,怎么检索。2)怎么讲检索知识加入。......
问答是对话的重要任务之一,封闭的垂直领域可以构建问题库,通过检索召回、排序的方式回答,然而到了开放域,怎么既利用外部知识,又能够应对多样的问题,前有kbqa,利用结构化的知识库和语义链接,然而这是最优的么?而最近流行的大模型,如GPT-3也在开放域问答上有一定的能力,那么如何在大的语言模型基础上融合知识呢,其实主要面临两个问题,1)检索什么知识,怎么检索。2)怎么讲检索知识加入。
首先是检索什么知识,怎么检索,传统的倒排,TF-ID,BM25肯定是有效的,最近也有一些文章提出了一些新的思路
DPR
2020 EMNLP, Dense Passage Retrieval for Open-Domain Question Answering
这篇文章是关于怎么检索出知识的,对比的是TF-IDF 和 BM25,文章证明通过少量的query和passage数据就能够训练一个双塔模型,效果上几乎就能取代之前的TF-IDF 和 BM25。top20准确率超过BM25有9%-19%。
双塔模型就众所周知,这里主要说怎么构建正负样本数据,以及损失函数,先说损失函数,主要和正样本相似度要比其他负样本拉开差距:
L ( q ∗ i , p ∗ i + , p ∗ i , 1 − , ⋯ , p ∗ i , n − ) = − log e sim ( q ∗ i , p ∗ i + ) e sim ( q ∗ i , p ∗ i + ) + ∑ ∗ j = 1 n e sim ( q ∗ i , p i , j − ) \begin{array}{c}L\left(q*{i}, p*{i}^{+}, p*{i, 1}^{-}, \cdots, p*{i, n}^{-}\right) =-\log \frac{e^{\operatorname{sim}\left(q*{i}, p*{i}^{+}\right)}}{e^{\operatorname{sim}\left(q*{i}, p*{i}^{+}\right)}+\sum*{j=1}^{n} e^{\operatorname{sim}\left(q*{i}, p_{i, j}^{-}\right)}}\end{array} L(q∗i,p∗i+,p∗i,1−,⋯,p∗i,n−)=−logesim(q∗i,p∗i+)+∑∗j=1nesim(q∗i,pi,j−)esim(q∗i,p∗i+)
构建数据:正样本是固定的(数据集答案、包含答案的段落),负样本选择对于训练至关重要,这里使用了三种方式来构建负样本:
- Random:随机选择一些负样本。
- BM25:BM25召回的但是不包含答案的样本,但是和问题token很match。(这个要慎重,之前facebook向量召回中讲到这种样本甚至会损伤召回,所以后面实验最好的也是加很少这种样本)
- Gold: 训练集中其他样本的positive passage。
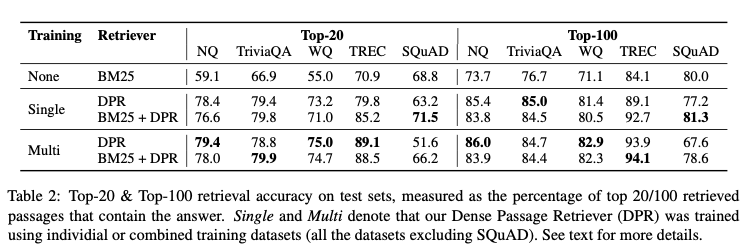 image.png
image.png
如图,实验中表现最好是mini-batch内的gold passage和一条BM25样本。明显优于BM25。
RAG
NeurIPS 2020, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
DPR主要优化检索阶段,那么在生成阶段的优化呢?在DPR基础上, RAG通过利用DPRetriever+BART来做问答,它能够用到预训练的语言模型(BART)和非参数memory(检索知识的dense vector)来生成。检索知识主要是Wiki百科索引。
DPR上面讲过了,那么怎么利用预训练seq2seq语言模型和pre-trained retriever呢,如图:
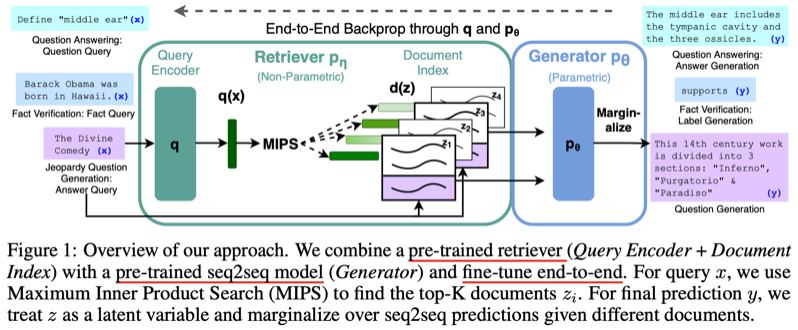 image.png
image.png
预训练的retriever更具query检索最小内积的topk document Zi,最后预测y时候,z作为隐变量输入,但是具体是怎么输入并且复用BART参数的呢?有两种方式:
- RAG-Sequence Model:生成预测每一个token的时候,使用同一个文档,即每篇文档生成一个回答。
p ∗ RAG-Sequence ( y ∣ x ) ≈ ∑ ∗ z ∈ top − k ( p ( ⋅ ∣ x ) ) p ∗ η ( z ∣ x ) p ∗ θ ( y ∣ x , z ) = ∑ ∗ z ∈ top − k ( p ( ⋅ ∣ x ) ) p ∗ η ( z ∣ x ) ∏ ∗ i N p ∗ θ ( y ∗ i ∣ x , z , y ∗ 1 : i − 1 ) p*{\text {RAG-Sequence }}(y \mid x) \approx \sum*{z \in \text { top }-k(p(\cdot \mid x))} p*{\eta}(z \mid x) p*{\theta}(y \mid x, z)=\sum*{z \in \text { top }-k(p(\cdot \mid x))} p*{\eta}(z \mid x) \prod*{i}^{N} p*{\theta}\left(y*{i} \mid x, z, y*{1: i-1}\right) p∗RAG-Sequence (y∣x)≈∑∗z∈ top −k(p(⋅∣x))p∗η(z∣x)p∗θ(y∣x,z)=∑∗z∈ top −k(p(⋅∣x))p∗η(z∣x)∏∗iNp∗θ(y∗i∣x,z,y∗1:i−1)
- RAG-Token Model:生成预测每个token的时候,使用所有文档,所以可以允许生成的时候结合多个文档的答案片段。
p ∗ RAG-Token ( y ∣ x ) ≈ ∏ ∗ i N ∑ ∗ z ∈ top- k ( p ( ⋅ ∣ x ) ) p ∗ η ( z ∣ x ) p ∗ θ ( y ∗ i ∣ x , z ∗ i , y ∗ 1 : i − 1 ) p*{\text {RAG-Token }}(y \mid x) \approx \prod*{i}^{N} \sum*{z \in \text { top- } k(p(\cdot \mid x))} p*{\eta}(z \mid x) p*{\theta}\left(y*{i} \mid x, z*{i}, y*{1: i-1}\right) p∗RAG-Token (y∣x)≈∏∗iN∑∗z∈ top- k(p(⋅∣x))p∗η(z∣x)p∗θ(y∗i∣x,z∗i,y∗1:i−1)
FID
2021 EACL, Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
大模型能够在开发域的知识问答取得不错效果,但是参数量巨大,影响训练和推理,巨大的参数量中,又有哪些是存储着知识呢?本文通过检索方式引入文本知识(可能包含潜在的有用信息),取得了问答的SOTA。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6BivOVWt-1657469246257)(https://ask.qcloudimg.com/developer-images/article/9087485/zvxtbn5f1o.png?imageView2/2/w/1620)]image.png
如上图,某些回答信息可能存在于检索的某个片段之中,所以顺理成章就需要通过query和文本交互提取片段,整体框架包含两部分,检索和生成。
- 检索部分:参考了DPR的向量召回方式,通过faiss召回。
生成部分模型也是简单有效,主要是怎么融合检索的知识:
 image.png
image.png
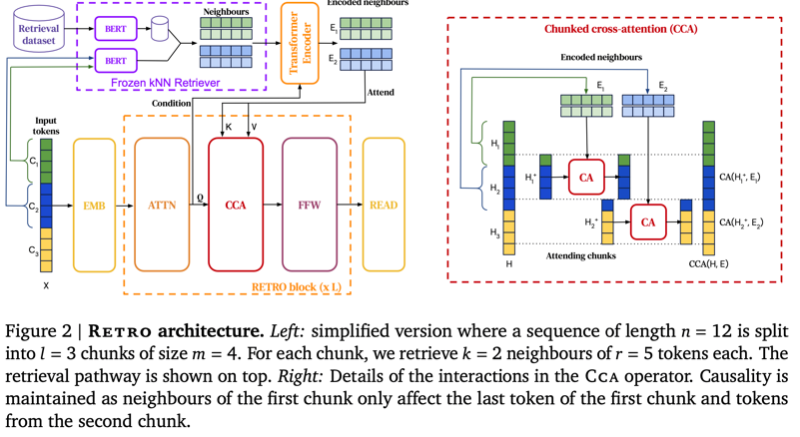
查看其源码,passage包含title和context,即标题和内容,输入时候会加入prompt,即:query:xxx title: xxx context: xxx
Encoder: 这阶段每个q和p交互,有利于提取其中的某些证据的信息。
Decoder: 输入是将每个qp片段的拼接,然后解码时候通过cross attention和这些片段交互,从而在生成阶段选择不同的信息生成不同的答案。
RETRO
如何以GPT-3的4%参数量实现与其相当的效果?RETRO的答案是加入检索知识,剥离模型中用于存储知识的参数。
检索:规模是万亿级别的token,因此并没有建立倒排,而是直接将句子块进行检索。
- 数据库是key-value格式,key是句子向量,而value包含两部分:1)句子chunk,用于计算key向量。2)chunk的后续,
- 使用BERT作为句子编码器,通过对token向量的average pooling获得句子向量。
- 检索是会避免检索出当前句子的下文,避免数据泄露。

模型:采用Transformer Encoder-Decoder,训练任务是自回归语言模型,将原始文本分成n块,生产第i块使用之前的文本以及第i-1块的检索出的k个neighbours作为增强的表达,因此第0块的检索信息是空。
L ( X ∣ θ , D ) ≜ ∑ u = 1 l ∑ i = 1 m ℓ θ ( x ( u − 1 ) m + i ∣ ( x j ) j < ( u − 1 ) m + i , ( RET D ( C u ′ ) ) u ′ < u ) L(X \mid \theta, \mathcal{D}) \triangleq \sum_{u=1}^{l} \sum_{i=1}^{m} \ell_{\theta}\left(x_{(u-1) m+i} \mid\left(x_{j}\right)_{j<(u-1) m+i},\left(\operatorname{RET} \mathcal{D}\left(C_{u^{\prime}}\right)\right)_{u^{\prime}<u}\right) L(X∣θ,D)≜u=1∑li=1∑mℓθ(x(u−1)m+i∣(xj)j<(u−1)m+i,(RETD(Cu′))u′<u)
模型也相对于FID,会较少的重复计算,因为FID中q和p会两两拼接获得解码向量,而Retro是
-
编码阶段:先编码passage然后有一个cross attention计算q和a关联,从而将q的信息融合到 Retrieval Encoder 中。
-
解码阶段:query拼接在解码前作为prompt,在chunked cross attention阶段来学当前生成token和p的关联。q作为prompt个人感觉生成也更加合理。
其实会有一个问题,为什么encoder和decoder中都有cross attention?编码阶段CA可以理解为输入(q)和检索结果的关联,而解码阶段,是去生成每一个字的时候,和检索结果的chunked cross attention,是一个实时生成的CA。

最后可以对比qa表现上的结果,没有战胜FID,作者认为是因为FID使用的T5模型有针对encoder的任务,使得模型encoder更强?而这一点对于qa非常重要😂。
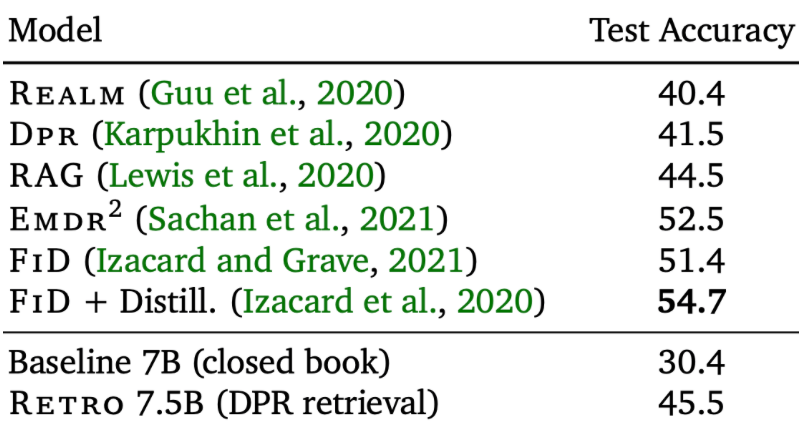
哈哈,最终还是不如FID
内容较多,这一期先到这了,下期继续。

加入「COC·上海城市开发者社区」,成就更好的自己!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)