计算机视觉——day68:YOLO9000: Better, Faster, Stronger(未完结)
YOLO9000是一个通过联合优化检测和分类来检测9000多个对象类别的实时框架。我们使用WordTree联合收割机来自不同来源的数据,并使用联合优化技术在ImageNet和COCO上同时进行训练。YOLO9000是缩小检测和分类之间数据集大小差距的有力一步
YOLO9000: Better, Faster, Stronger
YOLO9000:Better, Faster, Stronger
年后准备试试YOLOv5或者低一些的单阶段目标检测模型,所以时不时看看YOLO的各系列模型,是为了了解这一类模型,也是最终目标做一个各系列的简单对比,fighting!
1. Introduction
YOLO9000可以实时检测各种各样的对象类别,是一种目标检测和分类联合训练的方法。
它是一个可以检测超过9000种不同对象类别的实时对象检测器。首先,我们改进了基础YOLO检测系统,以产生YOLOv2,一种最先进的实时检测器。然后我们使用我们的数据集组合方法和联合训练算法在来自ImageNet的9000多个类和来自COCO的检测数据上训练模型。

- 我们的所有代码和预训练模型都可以在线获得:http://pjreddie.com/yolo9000/
2. Better
Batch Normalization.
批量归一化导致收敛性的显著改善,同时消除了对其他形式正则化的需要[7]。通过在YOLO中的所有卷积层上添加批量归一化,我们在mAP上获得了超过2%的改进。
High Resolution Classifier.
对于YOLOv2,我们首先在ImageNet上以全448×448分辨率微调分类网络10个历元。这为网络提供了时间来调整其滤波器,以便在较高分辨率输入下更好地工作。然后,我们在检测时微调所得到的网络。这种高分辨率分类网络使我们的mAP增加了近4%。
Convolutional With Anchor Boxes.
YOLO直接使用卷积特征提取器顶部的全连接层来预测边界框的坐标。
Faster R-CNN不是直接预测坐标,而是使用手工挑选的先验预测边界框
我们从YOLO中移除完全连接的层,并使用锚框来预测边界框。
Dimension Clusters.
我们在训练集边界框上运行k-均值聚类,以自动找到良好的先验,而不是手动选择先验。
-
对VOC和COCO的框维度进行聚类
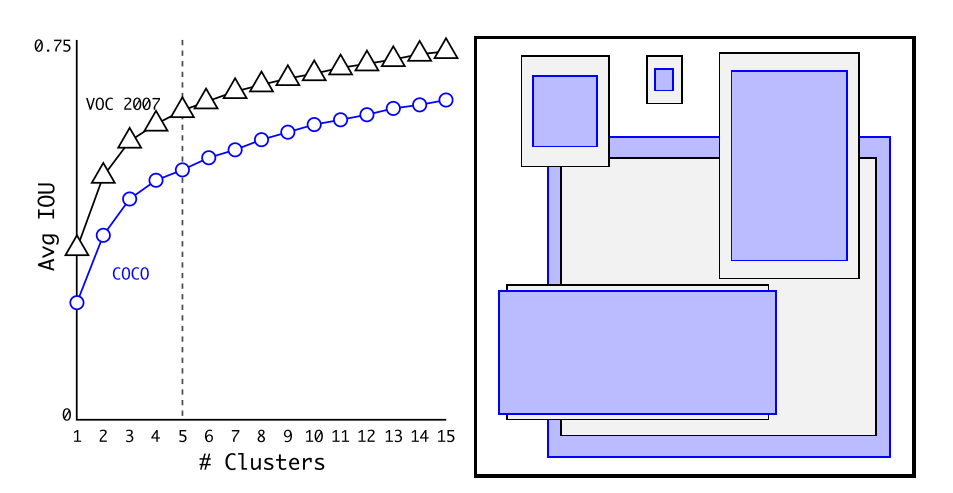
距离度量:d(box, centroid)=1− IOU(box, centroid)
Direct location prediction.
Fine-Grained Features.
这种修改的YOLO预测在13 × 13特征图上的检测。虽然这对于大对象来说已经足够了,但是对于定位较小的对象来说,更细粒度的特征可能会使其受益。更快的R-CNN和SSD都在网络中的各种特征地图上运行他们的提案网络,以获得一系列的分辨率。我们采取了不同的方法,简单地添加一个穿透层,以26 × 26分辨率从早期层中提取特征。
Multi-Scale Training.
原始的YOLO使用448 × 448的输入分辨率。增加锚盒后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池层,因此它可以动态调整大小。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。
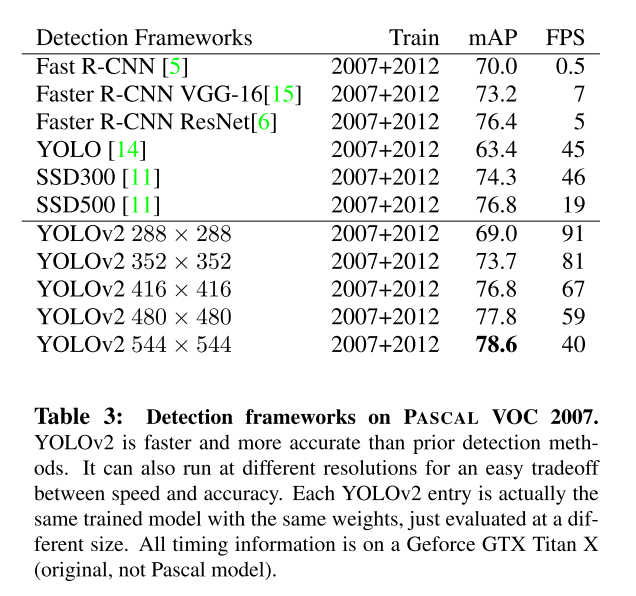
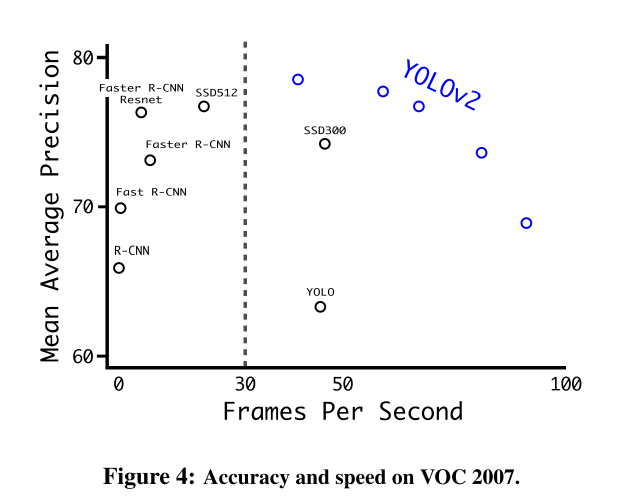
关于YOLOv2与VOC 2007的其他框架的比较,请参见表3。
 图四
图四
5. Conclusion
时间不够,初二要去拜年,中间的一些和其他模型对比的内容我仍在理解和学习,故没有在这给出,之后看明白了就会接着更新这一篇,请谅解。
YOLO9000是一个通过联合优化检测和分类来检测9000多个对象类别的实时框架。我们使用WordTree联合收割机来自不同来源的数据,并使用联合优化技术在ImageNet和COCO上同时进行训练。YOLO9000是缩小检测和分类之间数据集大小差距的有力一步

加入「COC·上海城市开发者社区」,成就更好的自己!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)