在k8s中搭建elasticsearch高可用集群,并对数据进行持久化存储
本文详细阐述了如何在Kubernetes(k8s)环境中搭建一个高可用的Elasticsearch集群,并重点介绍了数据持久化的配置与实现。随着大数据和云计算技术的飞速发展,Elasticsearch作为一款强大的搜索引擎和分析工具,其高可用性和数据持久性成为企业应用的关键需求。首先,文章介绍了Elasticsearch集群的基本概念,包括节点类型、分片、复制因子等核心概念,以及这些概念在实现高可

🐇明明跟你说过:个人主页
🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、Elasticsearch简介
Elasticsearch 是一个开源的分布式搜索和分析引擎,最初由 Elasticsearch N.V. 公司开发,并于 2010 年首次发布。它建立在 Apache Lucene 基础之上,提供了分布式的实时搜索和分析功能,被广泛应用于各种场景,包括日志分析、全文搜索、监控和可视化等。
以下是 Elasticsearch 的一些重要特点和功能:
1. 分布式架构:
- Elasticsearch 是一个分布式系统,数据可以水平扩展到多个节点上存储和处理。
- 数据被分割成多个分片(Shard),每个分片可以被复制到多个副本(Replica),以提高数据的可用性和容错性。
2. 实时搜索:
- Elasticsearch 提供了快速的实时搜索功能,可以在大规模数据集上快速地进行搜索、过滤和排序。
- 支持复杂的搜索查询语法和全文搜索功能,可以满足各种搜索需求。
3. 多种数据类型:
- Elasticsearch 支持多种数据类型的存储和索引,包括文本、数字、日期、地理位置等。
- 支持结构化数据和非结构化数据的索引和查询。
4. 强大的聚合和分析:
- Elasticsearch 提供了丰富的聚合(Aggregation)功能,可以对数据进行统计、分组、计算等操作。
- 支持各种聚合函数和桶(Bucket)操作,可以生成复杂的数据分析报表和可视化。
5. RESTful API:
- Elasticsearch 提供了基于 RESTful API 的接口,支持各种 HTTP 请求和 CRUD 操作。
- 开发者可以使用各种编程语言和工具与 Elasticsearch 进行交互,实现数据的索引、搜索和分析。
6. 可扩展性和灵活性:
- Elasticsearch 提供了丰富的插件和扩展机制,可以根据需求定制和扩展功能。
- 支持与其他开源工具和系统集成,如 Logstash、Kibana、Beats 等,构建完整的日志分析和监控解决方案。

2、k8s简介
Kubernetes单词起源于希腊语, 是“舵手”或者“领航员、飞行员”的意思。
Kubernetes(简称K8s)的前世今生可以追溯到谷歌(Google)内部的一个项目,它起源于2003年,当时谷歌正面临着不断增长的应用程序和服务的管理挑战。这个项目最初被称为"Borg",是一个早期的容器编排系统。Borg 的成功经验成为 Kubernetes 开发的契机。
有关k8s起源的介绍,请参考《初识K8s之前世今生、架构、组件、前景》这篇文章

Kubernetes的优点包括可移植性、可伸缩性和扩展性。它使用轻型的YAML清单文件实现声明性部署方法,对于应用程序更新,无需重新构建基础结构。管理员可以计划和部署容器,根据需要扩展容器并管理其生命周期。借助Kubernetes的开放源代码API,用户可以通过首选编程语言、操作系统、库和消息传递总线来构建应用程序,还可以将现有持续集成和持续交付(CI/CD)工具集成。
二、环境准备
1、k8s集群搭建

如果还未搭建k8s集群,请参考《在Centos中搭建 K8s 1.23 集群超详细讲解》
2、存储准备
在K8s中,创建一个存储类,用于持久化存储es集群的数据,保证node节点重启后数据不会丢失
存储类搭建,请参考《k8s 存储类(StorageClass)创建与动态生成PV解析,(附带镜像)》这篇文章

三、搭建es集群
1、编写YAML文件
apiVersion: v1
kind: Namespace
metadata:
name: es
---
#创建ConfigMap用于挂载配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: sirc-elasticsearch-config
namespace: es
labels:
app: elasticsearch
data: #具体挂载的配置文件
elasticsearch.yml: |+
cluster.name: "es-cluster"
network.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: "*"
bootstrap.system_call_filter: false
xpack.security.enabled: false
index.number_of_shards: 5
index.number_of_replicas: 1
#创建StatefulSet,ES属于数据库类型的应用,此类应用适合StatefulSet类型
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: es
spec:
serviceName: "elasticsearch-cluster" #填写无头服务的名称
replicas: 5
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
initContainers:
- name: fix-permissions
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: es-data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
containers:
- name: elasticsearch
image: elasticsearch:7.17.18
imagePullPolicy: Never
resources:
requests:
memory: "1000Mi"
cpu: "1000m"
limits:
memory: "2000Mi"
cpu: "2000m"
ports:
- containerPort: 9200
name: elasticsearch
env:
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name #metadata.name获取自己pod名称添加到变量MY_POD_NAME,status.hostIP获取自己ip等等可以自己去百度
- name: discovery.type
value: zen
- name: cluster.name
value: elasticsearch
- name: cluster.initial_master_nodes
value: "elasticsearch-0,elasticsearch-1,elasticsearch-2,elasticsearch-3,elasticsearch-4"
- name: discovery.zen.minimum_master_nodes
value: "3"
- name: discovery.seed_hosts
value: "elasticsearch-0.elasticsearch-cluster.es,elasticsearch-1.elasticsearch-cluster.es,elasticsearch-2.elasticsearch-cluster.es,elasticsearch-3.elasticsearch-cluster.es,elasticsearch-4.elasticsearch-cluster.es"
- name: network.host
value: "0.0.0.0"
- name: "http.cors.allow-origin"
value: "*"
- name: "http.cors.enabled"
value: "true"
- name: "number_of_shards"
value: "5"
- name: "number_of_replicas"
value: "1"
- name: path.data
value: /usr/share/elasticsearch/data
volumeMounts:
- name: es-data #挂载数据
mountPath: /usr/share/elasticsearch/data
volumes:
- name: elasticsearch-config
configMap: #configMap挂载
name: sirc-elasticsearch-config
volumeClaimTemplates: #这步自动创建pvc,并挂载动态pv
- metadata:
name: es-data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: nfs
resources:
requests:
storage: 10Gi
#创建Service
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-cluster #无头服务的名称,需要通过这个获取ip,与主机的对应关系
namespace: es
labels:
app: elasticsearch
spec:
ports:
- port: 9200
name: elasticsearch
clusterIP: None
selector:
app: elasticsearch
- Namespace 定义:这个部分定义了一个 Kubernetes Namespace,命名为 es,用于将所有的资源组织在同一个命名空间下。
- ConfigMap 定义:这个部分创建了一个 ConfigMap,其中包含了 Elasticsearch 的配置文件 elasticsearch.yml 的内容。这些配置将被挂载到 Elasticsearch 容器中。
- StatefulSet 定义:这个部分定义了一个 StatefulSet,用于管理 Elasticsearch 的部署。它指定了多个副本数、镜像版本、资源请求、容器端口以及其他的配置。还包括了一些 initContainers,用于初始化容器环境,以及 volumeClaimTemplates,用于动态创建持久化存储。
- Service 定义:这个部分创建了一个 Headless Service,用于为 StatefulSet 中的 Elasticsearch Pods 提供服务发现。它没有 ClusterIP,意味着它不会暴露端口到集群内部,而是用于在集群内部进行通信。
这个 YAML 文件通过使用 Kubernetes 的各种资源对象来定义了一个完整的 Elasticsearch 部署方案

2、创建es集群
[root@master es]# kubectl apply -f es.yaml
查看pod状态

3、创建Service
为es集群创建nodeport类型的service,以便在k8s集群外部访问使用es
编写YAML文件
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-0
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-0
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30000 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-1
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-1
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30001 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-2
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-2
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30002 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-3
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-3
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30003 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-4
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-4
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30004 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整1. Service 元数据:定义了服务的元数据,包括名称和命名空间。这个服务的名称为 my-nodeport-service-0,命名空间为 es。
2. Service 规范:规定了服务的类型、选择器和端口设置。
- type: NodePort:指定了这个服务的类型为 NodePort,这意味着服务将通过每个节点上的指定端口(nodePort)暴露给外部客户端。
- selector:定义了服务所匹配的 Pod 选择器。在这里,它使用了一个特殊的标签 statefulset.kubernetes.io/pod-name,以匹配名为 elasticsearch-0 的 StatefulSet 中的 Pod。
- ports:定义了服务所使用的端口配置。
- protocol: TCP:指定了服务使用的协议为 TCP。
- port: 80:指定了服务暴露的端口号为 80,这是外部客户端可以连接的端口。
- targetPort: 9200:指定了服务转发到 Pod 中容器的端口号为 9200,这是 Elasticsearch Pod 中运行的实际服务的端口。
- nodePort: 30000:指定了 NodePort 类型的端口号为 30000,这个端口将被每个节点使用来暴露服务。
创建svc
[root@master es]# kubectl apply -f service.yaml查看svc

4、访问测试
在浏览器输入node节点IP加30000端口

四、安装elasticsearch-head工具
1、elasticsearch-head介绍
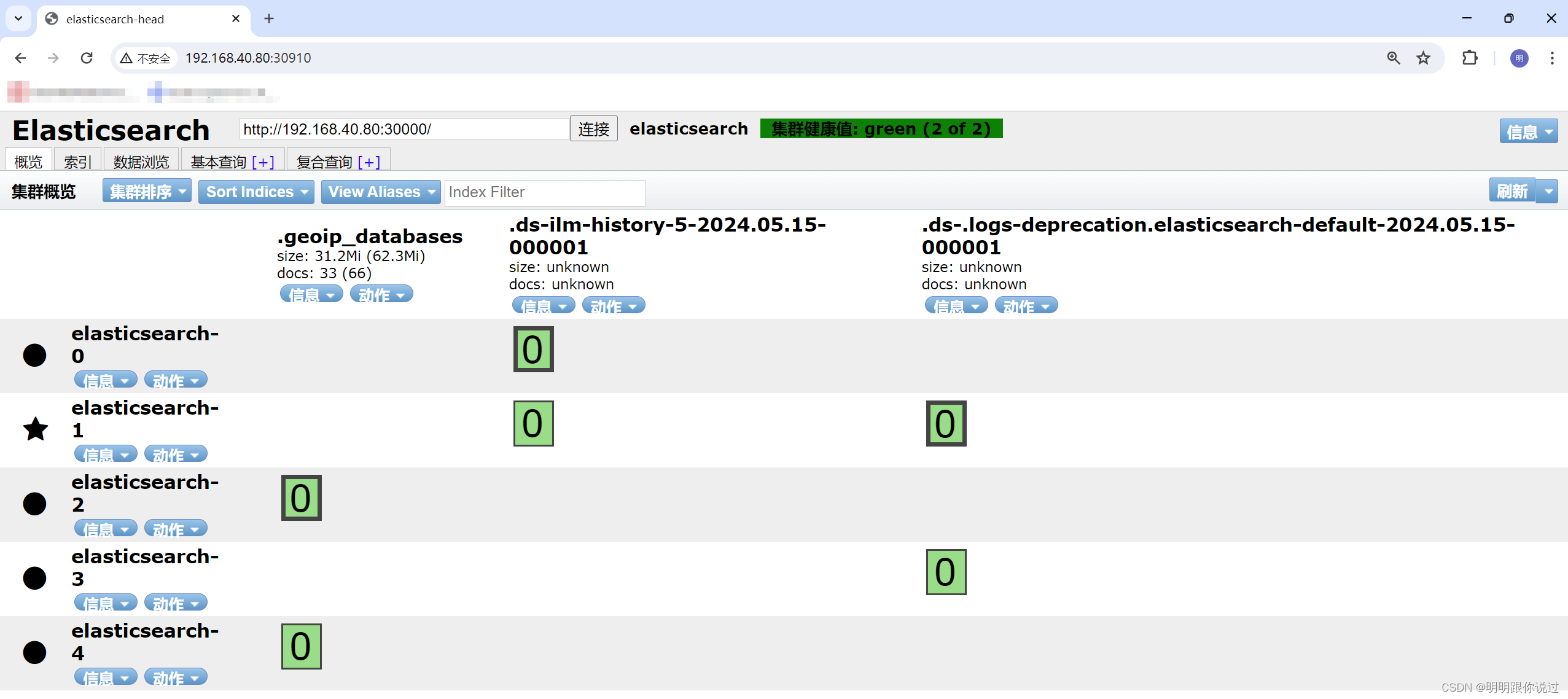
Elasticsearch-Head 是一个基于浏览器的开源工具,用于可视化和管理 Elasticsearch 集群。它提供了一个直观的用户界面,可以帮助用户轻松地监控和管理 Elasticsearch 集群中的索引、节点、分片等。
以下是 Elasticsearch-Head 的一些主要特点和功能:
- 索引管理:Elasticsearch-Head 允许用户查看和管理 Elasticsearch 集群中的索引。它可以显示索引的状态、文档数量、存储大小等信息,并提供索引的创建、删除、优化等操作。
- 节点监控:用户可以通过 Elasticsearch-Head 实时监控集群中的节点状态。它可以显示每个节点的健康状况、负载情况、分片分布等信息,帮助用户识别并解决潜在的问题。
- 分片管理:Elasticsearch-Head 提供了对分片的可视化管理功能。用户可以查看每个索引的分片状态,包括分片的分配情况、复制情况等,还可以手动执行重新分片、分片移动等操作。
- 查询执行:用户可以通过 Elasticsearch-Head 发送和执行查询请求,以检索和分析索引中的数据。它提供了一个简单的查询构建器,可以帮助用户构建和调试 Elasticsearch 查询语句。
- 集群状态:Elasticsearch-Head 显示了整个集群的状态和健康状况。它可以显示集群中的节点数量、主节点数量、分片数量等信息,并提供了实时的集群健康指标。
总的来说,Elasticsearch-Head 是一个非常有用的工具,可以帮助用户更加轻松地管理和监控 Elasticsearch 集群。它的直观界面和丰富功能使得用户可以更加高效地进行索引管理、节点监控、分片管理等操作。
2、安装Elasticsearch-Head
编写YAML文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearchhead
namespace: es
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearchhead
template:
metadata:
labels:
app: elasticsearchhead
spec:
containers:
- name: elasticsearchhead
image: mobz/elasticsearch-head:5
ports:
- containerPort: 9100
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearchhead-service
namespace: es
spec:
type: NodePort
ports:
- port: 9100
targetPort: 9100
nodePort: 30910 # 可根据需要选择合适的端口号
selector:
app: elasticsearchhead部署 elasticsearchhead
[root@master es]# kubectl apply -f elasticsearch-head.yaml3、访问测试
在浏览器输入node节点IP加30910端口

💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于Kubernetes的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 34
34 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)