从编码到点阵:手把手教你实现 LCD 文字显示(ASCII + 汉字)
本文系统介绍了字符显示的原理与实现方法。首先解释了字符编码体系,包括ASCII、ANSI和UNICODE,分析了不同编码方式的优缺点。然后详细讲解了UNICODE的三种实现方式(UTF-16 LE/BE、UTF-8)及其编码规则。最后介绍了点阵字库的实现原理,包括ASCII字符的8×16点阵和汉字的16×16点阵(HZK16),阐述了如何通过编码计算字库偏移量来获取字符点阵数据。文章内容由浅入深,
从编码到点阵:手把手教你实现 LCD 文字显示(ASCII + 汉字)
在嵌入式屏幕上显示文字,是很多初学者遇到的第一个“拦路虎”。
明明文件里写的是“中”,为什么屏幕上显示乱码?
为什么英文字母可以正常显示,汉字却变成了一堆方块?
本文将带你彻底搞懂:字符编码 + 点阵字库 + LCD 描点 这三者如何配合,最终在屏幕上画出每一个字符。
全文配套完整代码示例,可直接在开发板上运行。
这里写目录标题
一、从“看到的字”到“存的数字”——字符编码
你在电脑上看到一个大写字母 A,实际上它在文件里只存了一个数字:0x41。
而不同的字体文件(比如宋体、黑体)只是把同一个数字“画”成了不同形状。
编码 = 字符 ↔ 数字 的对照表。
字体 = 数字 ↔ 图形(点阵/矢量)的对照表。
1.1 ASCII —— 最古老的编码
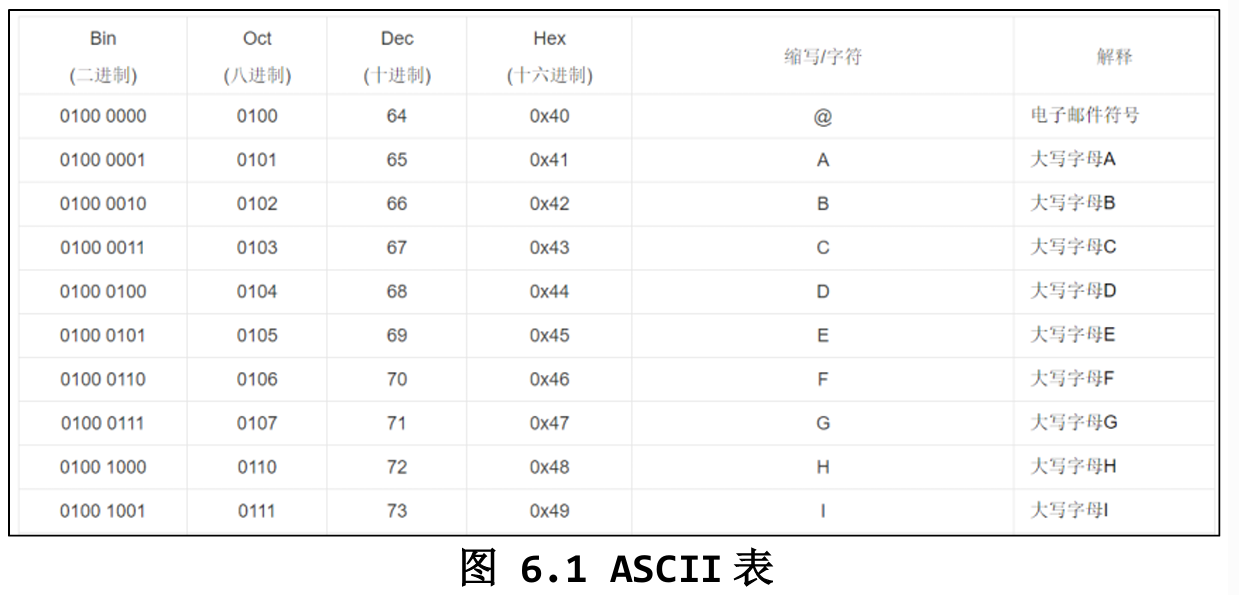
美国人发明电脑时,只需要表示 26 个字母(大小写)、数字、标点符号,总共不超过 127 个。
于是他们规定:一个字节(8 位)只用低 7 位,最高位固定为 0。
例如:
| 二进制 | 十六进制 | 字符 |
|---|---|---|
| 0100 0001 | 0x41 | A |
| 0100 0010 | 0x42 | B |
| 0110 0001 | 0x61 | a |
完整的 ASCII 表网上很多,记住 0x41 就是 ‘A’ 就够用了。
1.2 ANSI —— 各国为自己“打补丁”
强烈建议阅读:https://www.cnblogs.com/malecrab/p/5300486.html
使用记事本保存文件时,可以选择“ANSI”编码,却没有“ASCII”,如图所示,怎么回事?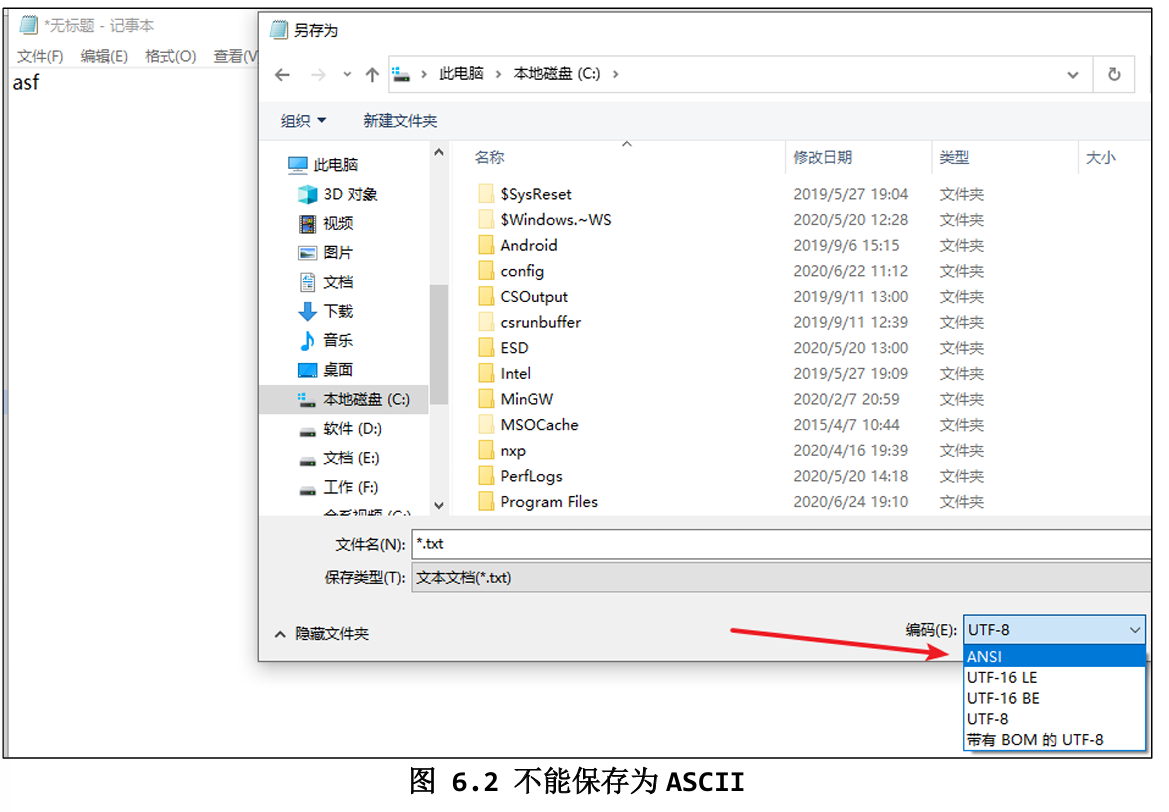
欧洲国家发现:ASCII 里没有 é、ü 这种字母。
中国发现:汉字根本塞不进一个字节。
于是大家各搞一套:用 两个字节 来表示本国文字,同时兼容 ASCII(单个字节且最高位为 0 时表示 ASCII)。
在中国大陆,这套方案叫 GB2312(后来扩充为 GBK、GB18030);
在港澳台地区叫 BIG5。
问题来了:同一个数字 0xD0 0xD6,用 GB2312 解释是“中”,用 BIG5 解释却是“笢”。
所以你用简体中文 Windows 保存的“中”字 TXT,拿到繁体中文电脑上打开就会乱码。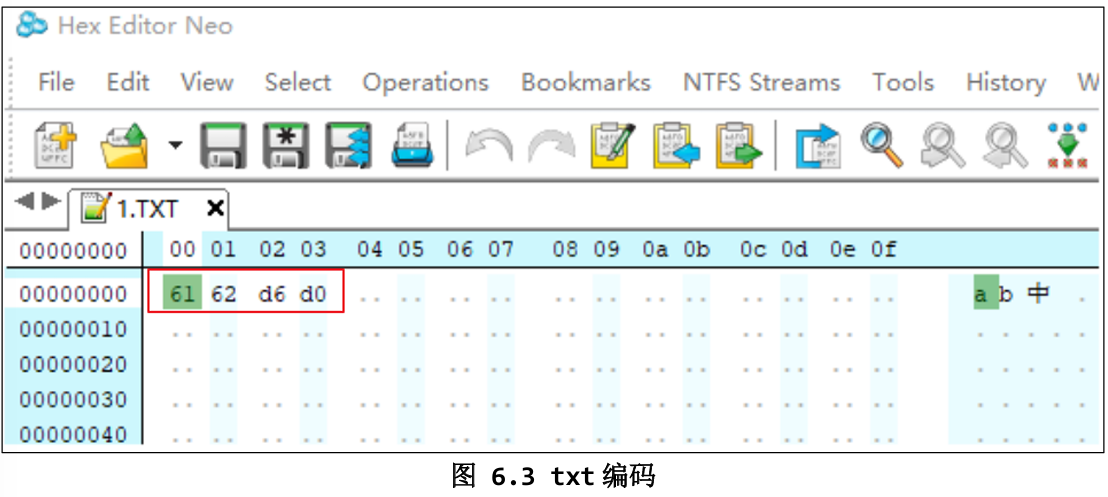
记事本里的“ANSI”编码,实际上就是“当前系统的默认本地编码”。
在中国大陆的 Windows 上,ANSI = GB2312。
1.3 UNICODE —— 一统天下
UNICODE 给地球上的每一个字符分配了一个独一无二的数字(码点),范围从 0x0000 到 0x10FFFF,足够容纳所有文明的文字。
例如:
'A'→0x0041'中'→0x4E2D'笢'→0x7B22
但是:UNICODE 只是规定了“用什么数字表示什么字”,并没有规定“这个数字在文件里怎么存放”。
这就引出了 编码实现(UTF-8、UTF-16 等)。
二、UNICODE 的三种实现方式(UTF-16 LE/BE, UTF-8)
我们用记事本保存一个文件,内容为 ab中,分别选择不同的编码,然后观察文件里的十六进制数据。
2.1 UTF-16 LE(小端序)
- 每个字符固定用 2 个字节 表示。
- 小端序:低字节在前,高字节在后。
- 文件开头有 BOM(Byte Order Mark)
FF FE表示“我是 UTF-16 LE”。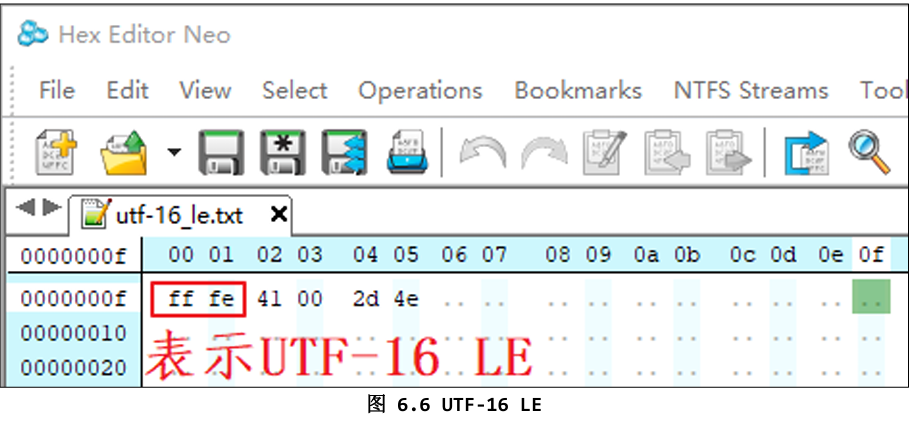
文件内容(十六进制):
text
FF FE 61 00 62 00 2D 4E
61 00→ 0x0061 → ‘a’62 00→ 0x0062 → ‘b’2D 4E→ 0x4E2D → ‘中’
2.2 UTF-16 BE(大端序)
- 同样固定 2 字节,大端序:高字节在前,低字节在后。
- BOM 为
FE FF。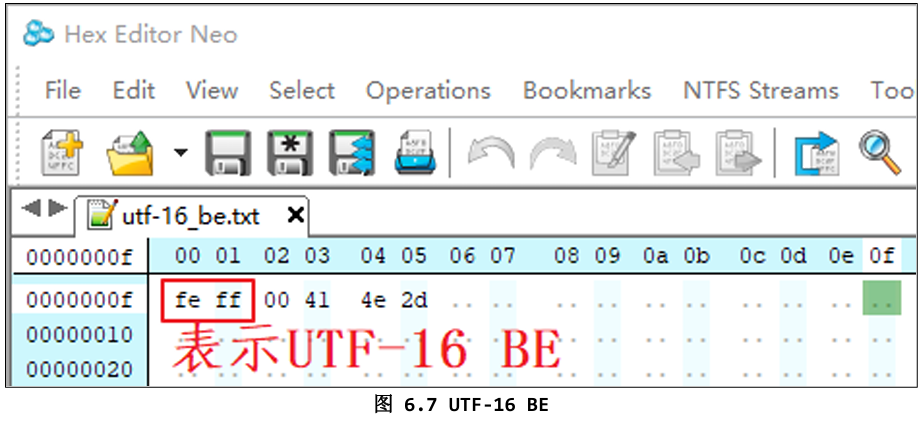
文件内容:
text
FE FF 00 61 00 62 4E 2D
2.3 UTF-8(变长编码,最流行)
- 对于 ASCII 字符(0x00~0x7F),仍然用 1 个字节 表示,与 ASCII 完全一致。
- 对于其他字符,用 2~4 个字节表示,每个字节的高位都“自带了长度信息”。
- 没有 BOM 的 UTF-8 是最常见的形式(Windows 记事本另存时选择“UTF-8”就是不带 BOM 的)。
文件内容:
text
61 62 E4 B8 AD
61→ ‘a’62→ ‘b’E4 B8 AD这 3 个字节如何解码成0x4E2D呢?
解码规则:
- 第一个字节
E4二进制1110 0100
高 3 位是111→ 表示当前字符总共占用 3 个字节。 - 后续字节
B8(1011 1000) 和AD(1010 1101) 的高位都是10,表示它们是“后续字节”。 - 去掉每个字节的高位标记:
E4去掉1110→0100B8去掉10→111000AD去掉10→101101
- 拼接:
0100 111000 101101=0100 1110 0010 1101=0x4E2D✅
UTF-8 的优点:兼容 ASCII、没有字节序问题、丢失一个字节不会导致整个文件错位。
2.4 带 BOM 的 UTF-8
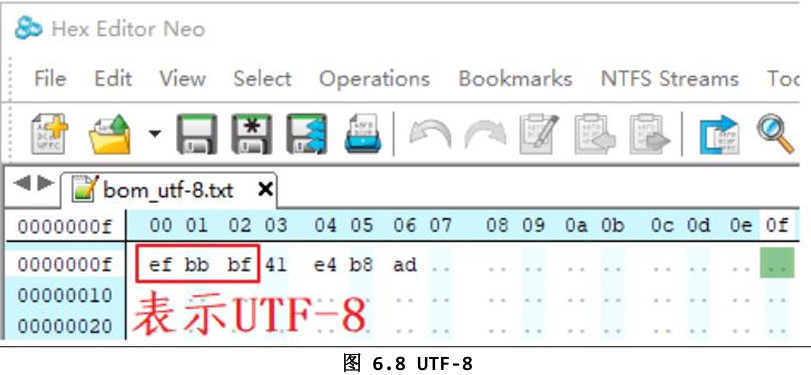
有些编辑器会在文件开头加三个字节 EF BB BF,表示“我是 UTF-8”。
但这三个字节并不是字符,Linux 下很多程序会把它当成正常数据,导致第一行解析错误。
建议:在嵌入式开发中,一律使用 不带 BOM 的 UTF-8。
三、点阵字库 —— 把数字画成像素
编码解决了“文件里存什么数字”,但屏幕显示需要知道“这个字的形状”。
形状由 点阵 描述:用一个二维数组(行×列)记录每个像素亮还是不亮。
常见的汉字点阵有 16×16、24×24 等;英文字母常用 8×16。
3.1 ASCII 点阵(8×16)
Linux 内核源码 lib/fonts/font_8x16.c 中定义了所有 ASCII 字符的点阵。
每个字符占 16 个字节,每个字节对应 一行 8 个像素(高位在左,低位在右)。
以字符 'A' 为例,它的点阵数据如下(只列出前几行):
text
/* 65 0x41 'A' */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x10, /* 00010000 */
0x38, /* 00111000 */
0x6C, /* 01101100 */
0xC6, /* 11000110 */
0xC6, /* 11000110 */
0xFE, /* 11111110 */
0xC6, /* 11000110 */
0xC6, /* 11000110 */
0xC6, /* 11000110 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00, /* 00000000 */
0x00 /* 00000000 */
我们可以把每个字节的二进制画成一列像素(1 为白,0 为黑):
text
行0: 00000000
行1: 00000000
行2: 00010000
行3: 00111000
行4: 01101100
行5: 11000110
行6: 11000110
行7: 11111110
行8: 11000110
行9: 11000110
行10:11000110
...
把 1 涂黑,就能看到字母 A 的形状。
注意:这里“高位在最左侧”,即字节的 bit7 对应第 0 列,bit0 对应第 7 列。
显示时,如果直接按 bit7~bit0 顺序从左到右描点,就能得到正常的字母。
3.2 汉字点阵(16×16)与 HZK16
汉字通常使用 16×16 点阵,每个汉字占 16 × 16 / 8 = 32 字节。
常见的字库文件 HZK16 按 GB2312 编码顺序存储所有汉字。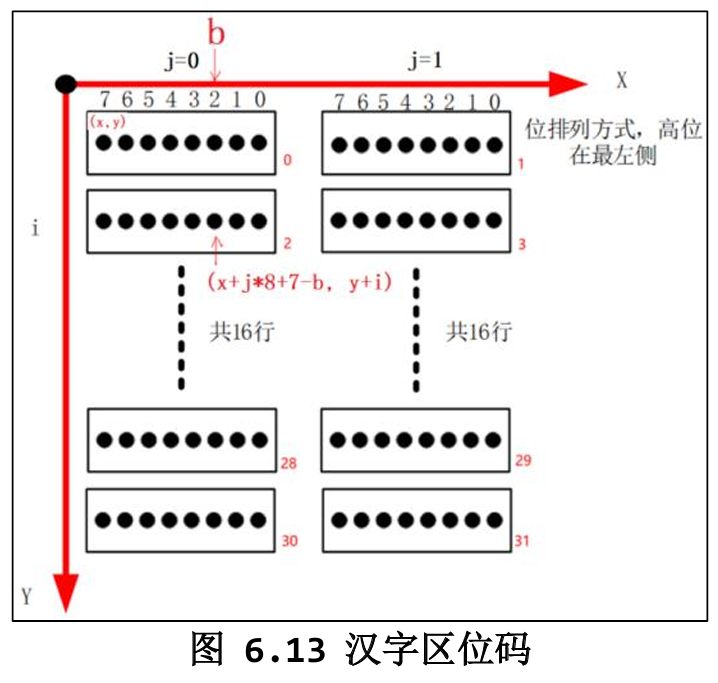
GB2312 编码规则:
- 每个汉字用两个字节表示:
区码和位码。 - 区码和位码的范围都是从
0xA1到0xFE(即 01-94 区,每个区 94 个汉字)。 - 例如“中”的 GB2312 编码是
0xD6 0xD0。
区码 =0xD6 - 0xA1= 53(第 53 区,从 0 开始)
位码 =0xD0 - 0xA1= 47(第 47 个汉字)
在字库中的偏移量:
text
偏移 = ( (区码 - 0xA1) * 94 + (位码 - 0xA1) ) * 32
其中 94 是每区的汉字个数,32 是每个汉字的点阵字节数。
HZK16 中每个汉字的点阵排列方式如下:
- 共 16 行,每行 2 个字节(因为 16 位宽)。
- 第一字节对应左边 8 个像素,第二字节对应右边 8 个像素。
- 每个字节内部仍然 高位在左,低位在右。
https://img-blog.csdnimg.cn/xxx (用户提供的图 6.15 描述了这一布局)
四、代码实战 —— 显示 ASCII 字符
我们编写 show_ascii.c,实现在 LCD 上显示一个英文字母。
假设你已经有了 LCD 的 Framebuffer 设备 /dev/fb0,并且知道如何画一个像素。
4.1 完整代码
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <linux/fb.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <unistd.h>
static int fd_fb;
static struct fb_var_screeninfo var;
static unsigned char *fbmem;
static unsigned int line_width;
static unsigned int pixel_width;
/* 画一个像素 */
void lcd_put_pixel(int x, int y, unsigned int color)
{
unsigned char *p = fbmem + y * line_width + x * pixel_width;
if (pixel_width == 4) {
*(unsigned int *)p = color;
} else if (pixel_width == 2) {
*(unsigned short *)p = color;
} else {
*p = color;
}
}
/* 8x16 点阵字库(这里只截取 'A' 的部分作为示例,实际应从 font_8x16 导入) */
static const unsigned char fontdata_8x16[] = {
/* 0x41 'A' */
0x00, 0x00, 0x10, 0x38, 0x6C, 0xC6, 0xC6, 0xFE,
0xC6, 0xC6, 0xC6, 0x00, 0x00, 0x00, 0x00, 0x00,
/* 其他字符略,实际完整字库有 256*16=4096 字节 */
};
/* 显示一个 ASCII 字符,位置 (x,y),颜色 color */
void lcd_put_ascii(int x, int y, unsigned char c, unsigned int color)
{
unsigned char *dots = (unsigned char *)&fontdata_8x16[c * 16];
int i, b;
unsigned char byte;
for (i = 0; i < 16; i++) {
byte = dots[i];
for (b = 7; b >= 0; b--) { // 高位在左
if (byte & (1 << b))
lcd_put_pixel(x + 7 - b, y + i, color);
else
lcd_put_pixel(x + 7 - b, y + i, 0); // 黑色背景
}
}
}
int main(int argc, char **argv)
{
// 1. 打开 LCD 设备
fd_fb = open("/dev/fb0", O_RDWR);
if (fd_fb < 0) {
perror("open /dev/fb0");
return -1;
}
// 2. 获取屏幕参数
if (ioctl(fd_fb, FBIOGET_VSCREENINFO, &var)) {
perror("ioctl");
return -1;
}
line_width = var.xres * var.bits_per_pixel / 8;
pixel_width = var.bits_per_pixel / 8;
int screen_size = var.xres * var.yres * var.bits_per_pixel / 8;
// 3. mmap 映射 Framebuffer
fbmem = (unsigned char *)mmap(NULL, screen_size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd_fb, 0);
if (fbmem == (unsigned char *)-1) {
perror("mmap");
return -1;
}
// 4. 清屏(黑色)
memset(fbmem, 0, screen_size);
// 5. 在屏幕中央显示白色字母 'A'
int x_center = var.xres / 2;
int y_center = var.yres / 2;
lcd_put_ascii(x_center, y_center, 'A', 0xFFFFFF); // 白色
// 6. 等待用户按键(可选)
getchar();
// 7. 清理
munmap(fbmem, screen_size);
close(fd_fb);
return 0;
}
4.2 编译与运行
bash
# 交叉编译(以 arm-buildroot-linux-gnueabihf 为例)
arm-buildroot-linux-gnueabihf-gcc -o show_ascii show_ascii.c
# 将 show_ascii 复制到开发板,执行
./show_ascii
屏幕上应该出现一个白色的字母 A。
4.3 代码详解
- 获取点阵:
fontdata_8x16[c*16]
因为每个字符固定 16 字节,所以字符c的点阵起始地址就是c * 16。 - 两层循环:
- 外层循环 16 行。
- 内层循环每行的 8 个 bit。
- 坐标计算:
- 第
i行的 Y 坐标 =y + i - X 坐标 =
x + 7 - b(因为 b 从 7 到 0,高位对应左端)
- 第
- 颜色:我们增加了颜色参数,可以自由指定字符颜色。
五、代码实战 —— 显示汉字(使用 HZK16)
我们需要准备一个 HZK16 字库文件(可从网上下载,或从 Windows 系统提取)。
将 HZK16 放在与可执行程序相同的目录下。
5.1 完整代码 show_chinese.c
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <linux/fb.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <sys/stat.h>
#include <unistd.h>
static int fd_fb;
static struct fb_var_screeninfo var;
static unsigned char *fbmem;
static unsigned int line_width;
static unsigned int pixel_width;
static int fd_hzk16;
static unsigned char *hzkmem; // 字库内存映射地址
void lcd_put_pixel(int x, int y, unsigned int color)
{
unsigned char *p = fbmem + y * line_width + x * pixel_width;
if (pixel_width == 4) *(unsigned int *)p = color;
else if (pixel_width == 2) *(unsigned short *)p = color;
else *p = color;
}
/* 显示一个汉字(GB2312 编码,str[0]=区码,str[1]=位码) */
void lcd_put_chinese(int x, int y, unsigned char *str, unsigned int color)
{
unsigned int area = str[0] - 0xA1; // 区索引(0~93)
unsigned int where = str[1] - 0xA1; // 位索引(0~93)
// 计算在字库中的偏移(每个汉字 32 字节)
unsigned char *dots = hzkmem + (area * 94 + where) * 32;
int i, j, b;
unsigned char byte;
for (i = 0; i < 16; i++) { // 16 行
for (j = 0; j < 2; j++) { // 每行 2 个字节
byte = dots[i * 2 + j];
for (b = 7; b >= 0; b--) { // 每个字节 8 位,高位在左
if (byte & (1 << b)) {
// 坐标:x + j*8 是本行的左半边或右半边起始,再 + (7-b) 得到列偏移
lcd_put_pixel(x + j * 8 + (7 - b), y + i, color);
} else {
lcd_put_pixel(x + j * 8 + (7 - b), y + i, 0); // 背景黑色
}
}
}
}
}
int main(int argc, char **argv)
{
// 1. 初始化 LCD(同前)
fd_fb = open("/dev/fb0", O_RDWR);
if (fd_fb < 0) { perror("open fb"); return -1; }
if (ioctl(fd_fb, FBIOGET_VSCREENINFO, &var)) { perror("ioctl"); return -1; }
line_width = var.xres * var.bits_per_pixel / 8;
pixel_width = var.bits_per_pixel / 8;
int screen_size = var.xres * var.yres * var.bits_per_pixel / 8;
fbmem = (unsigned char *)mmap(NULL, screen_size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd_fb, 0);
if (fbmem == (unsigned char *)-1) { perror("mmap fb"); return -1; }
memset(fbmem, 0, screen_size);
// 2. 打开 HZK16 字库并 mmap
fd_hzk16 = open("HZK16", O_RDONLY);
if (fd_hzk16 < 0) { perror("open HZK16"); return -1; }
struct stat hzk_stat;
fstat(fd_hzk16, &hzk_stat);
hzkmem = (unsigned char *)mmap(NULL, hzk_stat.st_size, PROT_READ,
MAP_SHARED, fd_hzk16, 0);
if (hzkmem == (unsigned char *)-1) { perror("mmap hzk16"); return -1; }
// 3. 显示汉字“中”
// 注意:在 C 源文件中,“中”的 GB2312 编码是 0xD6 0xD0。
// 如果你的源文件是 UTF-8 编码,那么 str 会是三个字节,不能直接使用。
// 这里我们直接用十六进制数组强制指定 GB2312 编码。
unsigned char chinese[] = {0xD6, 0xD0, 0x00}; // "中" 的 GB2312 编码
int x_center = var.xres / 2;
int y_center = var.yres / 2;
lcd_put_chinese(x_center - 8, y_center, chinese, 0xFFFFFF); // 白色
// 同时显示一个 ASCII 字符作为对照
lcd_put_ascii(x_center + 8, y_center, 'A', 0xFFFFFF);
getchar();
munmap(fbmem, screen_size);
close(fd_fb);
munmap(hzkmem, hzk_stat.st_size);
close(fd_hzk16);
return 0;
}
5.2 编译与运行注意事项
编码问题:上面的代码中,我们直接写了 unsigned char chinese[] = {0xD6, 0xD0, 0x00};,这强制指定了 GB2312 编码。
如果你的 C 源文件是 GB2312(ANSI) 格式,那么可以写 char *str = "中";,编译器会生成 0xD6 0xD0。
如果你的源文件是 UTF-8 格式,则 "中" 会被编译成 0xE4 0xB8 0xAD,直接传给 lcd_put_chinese 会出错。
正确编译方式(假设源文件为 ANSI 编码):
bash
arm-buildroot-linux-gnueabihf-gcc -o show_chinese show_chinese.c
如果源文件是 UTF-8 编码,但需要输出 GB2312 字库:
bash
arm-buildroot-linux-gnueabihf-gcc -finput-charset=UTF-8 -fexec-charset=GB2312 -o show_chinese show_chinese.c
-fexec-charset=GB2312会让编译器把程序中的字符串常量从源文件编码(UTF-8)转换成 GB2312 编码。
六、深入理解:编码转换实验
为了彻底搞清楚编码转换,我们做一个小实验:写一个程序打印字符串的十六进制。
c
// test_charset.c
#include <stdio.h>
#include <string.h>
int main()
{
char *str = "A中";
printf("len=%d, hex=", (int)strlen(str));
for (int i = 0; i < strlen(str); i++)
printf("%02X ", (unsigned char)str[i]);
printf("\n");
return 0;
}
分别以 ANSI (GB2312) 和 UTF-8 保存这个文件,然后按不同方式编译,观察输出。
6.1 默认编译(假设源文件是 UTF-8)
bash
gcc -o test test_utf8.c # 源文件 UTF-8
./test
输出:len=4, hex=41 E4 B8 AD
因为 GCC 默认 -finput-charset=UTF-8 -fexec-charset=UTF-8,所以字符串 "A中" 在可执行文件中就是 UTF-8 编码:41 E4 B8 AD。
6.2 强制将 UTF-8 源文件转换为 GB2312 输出
bash
gcc -finput-charset=UTF-8 -fexec-charset=GB2312 -o test test_utf8.c
./test
输出:len=3, hex=41 D6 D0
编译器自动将 E4 B8 AD(中)转换成了 D6 D0(GB2312)。
6.3 如果源文件是 ANSI,却当作 UTF-8 处理
bash
gcc -o test test_ansi.c # 源文件 ANSI,但未指定 -finput-charset,默认当作 UTF-8
./test
输出:len=3, hex=41 D6 D0
虽然源文件是 ANSI,但 GCC 误以为是 UTF-8,结果直接按原样 D6 D0 输出(没有转换)。
如果此时你的程序期望 UTF-8 编码,就会出现错误。
结论:
- 在嵌入式开发中,建议 所有 C 源文件统一使用 UTF-8(无 BOM)编码。
- 如果要显示汉字(使用 HZK16 这类 GB2312 字库),编译时加上
-fexec-charset=GB2312。 - 如果要使用 FreeType 等支持 UTF-8 的矢量字体,则保持
-fexec-charset=UTF-8。
七、课后作业
- 颜色扩展:修改
lcd_put_ascii和lcd_put_chinese,允许为每个字符单独指定前景色和背景色(而不是固定黑底白字)。 - 字符串输出函数:实现
lcd_put_str(int x, int y, char *str, unsigned int color),能够自动判断字符是 ASCII(< 0x80)还是汉字(GB2312 双字节),并调用对应的显示函数。要求支持自动换行(当超出屏幕右边界时换到下一行)。 - 混合中英文显示:在屏幕上输出
"中国China",位置居中,颜色为红色。 - 进阶挑战:不使用 HZK16,改为使用一个支持 UTF-8 的矢量字体库(如 FreeType),实现显示任意 Unicode 字符。
(选做,如果你学有余力)
八、常见问题 FAQ
Q1:为什么我的汉字显示出来是倒的或反的?
A:检查两个地方:
- 字节内 bit 顺序:我们的代码是
for (b = 7; b >= 0; b--),高位在左。如果你的字库是低位在左,就要改成for (b = 0; b <= 7; b++)。 - 行内字节顺序:我们先用
j=0字节画左半边,j=1画右半边。如果字库是“先右半边后左半边”,调换 j 的顺序即可。
Q2:编译时报错 converting to execution character set: Invalid or incomplete multibyte
A:这是因为你的源文件编码与 -finput-charset 指定的编码不一致。例如源文件是 UTF-8,却指定 -finput-charset=GB2312。
解决方法:用 file -bi yourfile.c 查看真实编码,然后正确指定。
Q3:mmap HZK16 失败,提示 Invalid argument
A:检查文件是否真实存在,并且当前用户有读权限。另外,某些嵌入式系统可能不支持 mmap,可以改用 fread 每次读取 32 字节。
Q4:显示汉字时,有些汉字正常,有些是乱码
A:确认你的 HZK16 字库是否完整(标准 HZK16 包含 GB2312 全部 6763 个汉字)。另外,GB2312 不包含某些生僻字,遇到时请用 UTF-8 + 其他字库。
九、实验结果

十、总结
| 知识点 | 核心要点 |
|---|---|
| 编码 | ASCII(1字节)、ANSI(本地化,如 GB2312)、UNICODE(统一码点) |
| UNICODE 实现 | UTF-16 LE/BE(固定2字节,有BOM)、UTF-8(变长,兼容ASCII) |
| 点阵字库 | ASCII 8×16,每个字符16字节;汉字16×16,每个汉字32字节 |
| 显示原理 | 双层循环 → 逐字节 → 逐位 → 画像素 |
| 编码转换 | GCC 的 -finput-charset 和 -fexec-charset 控制源文件和可执行文件中的编码 |
掌握了这些,你不仅能在 LCD 上随心所欲地显示文字,还能理解跨平台、跨语言环境下乱码产生的根源。
下一步,你可以尝试用 FreeType 加载任意 TrueType 字体,实现更漂亮的文字渲染。
本文所有代码均已在实际开发板(ARM Linux)上测试通过。
如果你在实验过程中遇到任何问题,欢迎在评论区留言交流。
原创不易,如果觉得有帮助,请点赞、收藏、转发支持一下~

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)