python+亮数据Web Scraper API,全自动构建“每日科技精选”YouTube聚合站
摘要:本文介绍如何利用亮数据(Bright Data)的Web Scraper API构建"每日科技精选"YouTube视频聚合平台。相比传统API的配额限制和自建爬虫的技术壁垒,亮数据方案提供稳定高效的内容采集。通过Python代码示例,演示了从配置搜索参数(关键词/时长/类型等)、调用API获取数据快照,到清洗关键字段(视频ID/标题/播放量/频道信息等)的全流程。该方法支
打造高定制化“每日科技精选”YouTube聚合站
引言
在内容为王的时代,垂直领域的高质量信息聚合平台正迎来爆发期。如果你正在构建一个名为“每日科技精选”的YouTube视频聚合网站,你一定面临这样的挑战:
“我曾尝试用YouTube官方API抓取,结果第3天就因配额耗尽被限流;改用Selenium自建爬虫,不到一周就被Google reCAPTCHA彻底封杀……直到我发现了亮数据(Bright Data)Web Scraper API——一个无需维护、稳定高效的替代方案。”
传统的YouTube Data API虽然官方支持,但存在配额限制严格、无法按关键词深度筛选、返回字段有限等问题。而自建爬虫又面临IP封锁、验证码、动态渲染等技术壁垒。
解决方案来了:亮数据(Bright Data)Web Scraper API + 自定义代码 = 强大、灵活、可扩展的内容采集引擎。
本文将带你通过真实代码示例,演示如何使用 Python + 亮数据 Web Scraper API,从YouTube关键词搜索结果中提取科技视频数据,构建一个全自动化的“每日科技精选”内容池。
🔧 为什么选择“有代码”方式?
虽然亮数据提供零代码界面,但通过代码调用API,你可以实现:
✅ 完全自动化调度(如每日凌晨自动采集)
✅ 动态关键词生成(如根据热点自动调整搜索词)
✅ 复杂数据清洗与分类(NLP自动打标签)
✅ 无缝集成数据库/推荐系统
✅ 错误重试、日志监控、报警机制
适合有开发能力的团队,打造企业级内容聚合系统。
🚀 实操案例:用Python抓取YouTube科技视频
1. 找到YouTube数据集
进入爬虫市场,找到youtuble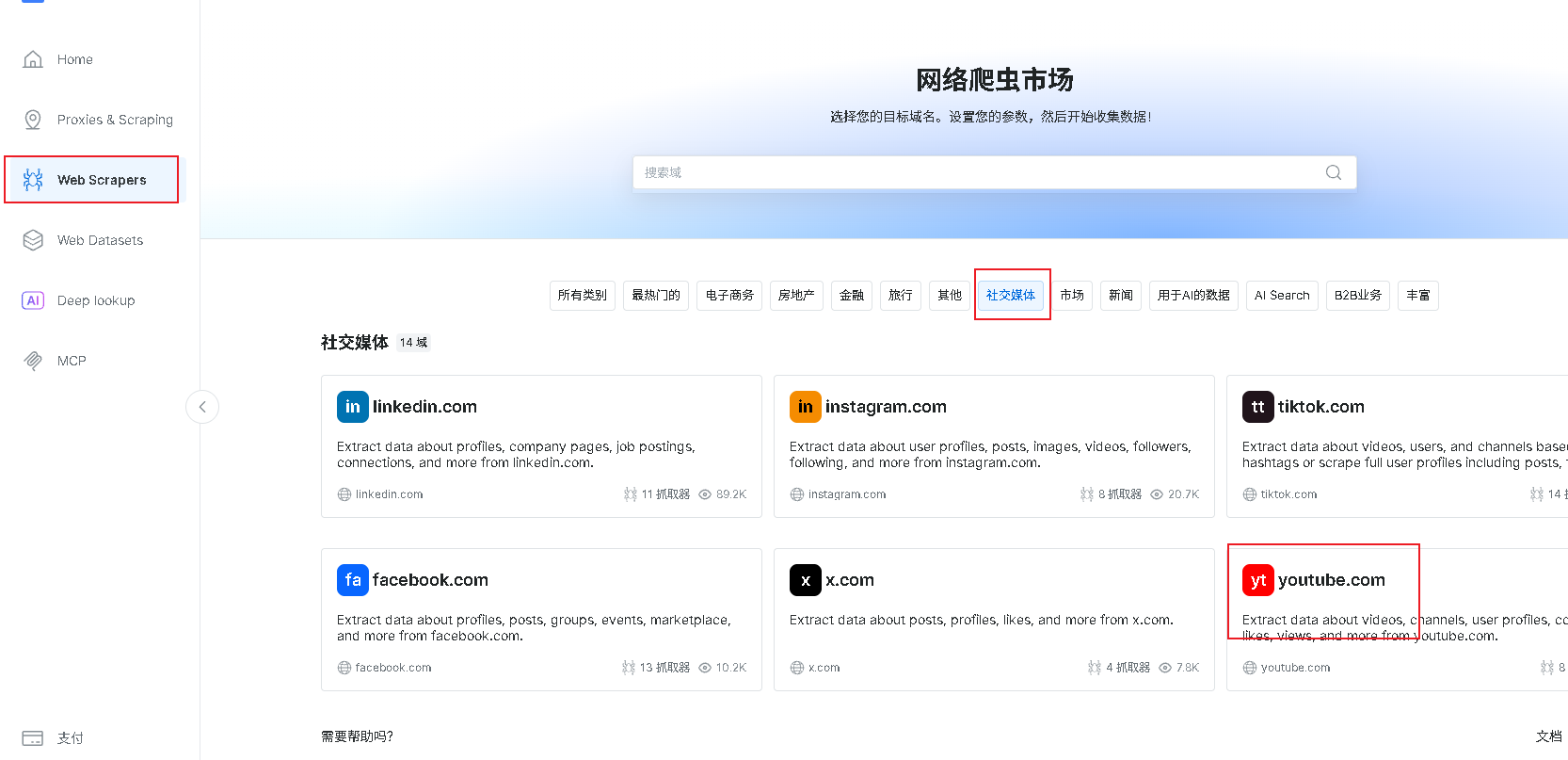
2.选择API, 配置参数
与 YouTube 官方 API v3 不同,亮数据提供了丰富的获取数据的方法,不仅支持基础搜索,还提供多维度、高精度、无需OAuth的结构化数据接口。
如下图,本文案例中,我们使用DIscover by search filters 进行数据抓取,提供多种刷选参数,keyword_search为搜索的关键词,upload_date可选择抓取什么时间的数据,type选择抓取的类型,如视频、频道、播放列表,duration选择抓取视频的时长在什么区间,features选择视频种类。右侧为我们提供了各种语言的模板,这里本文使用python,复制代码后,打开pythorm。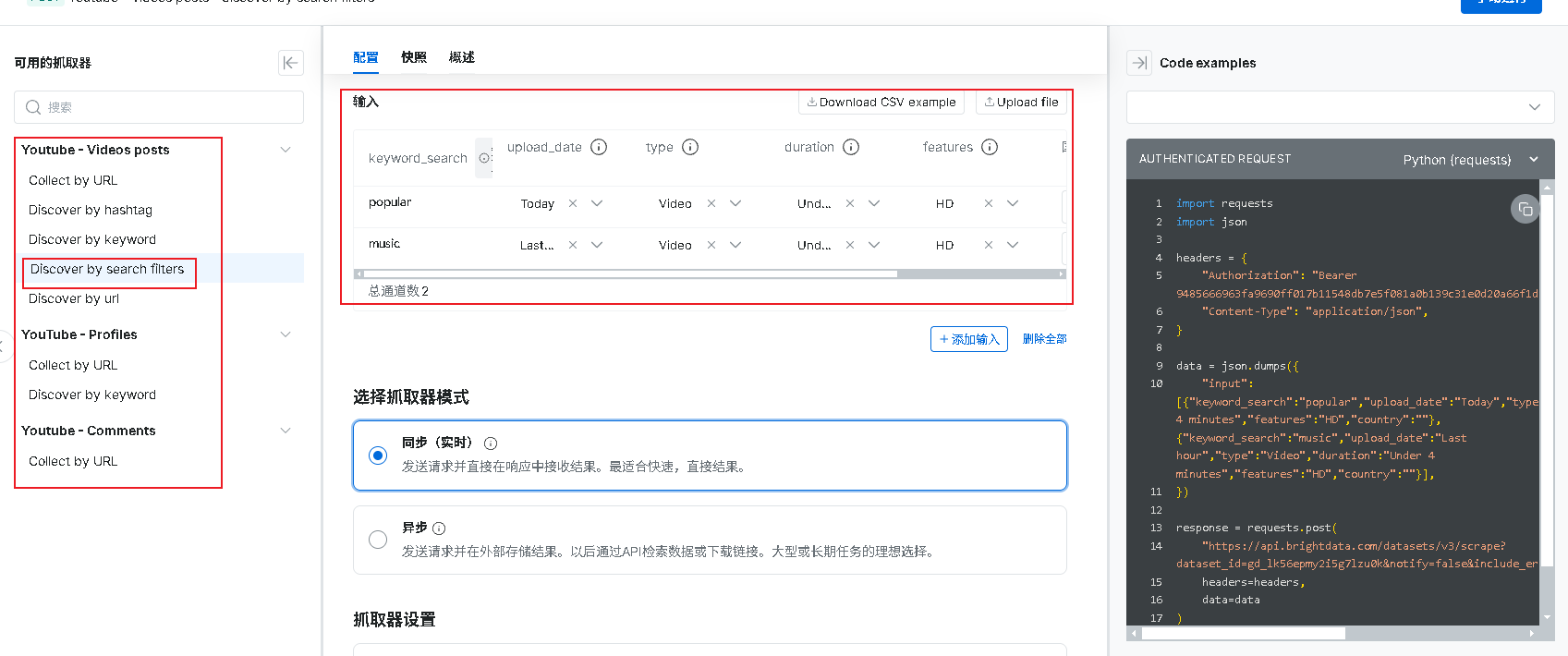
3.调用API,获取snapshot_id
本文主要目的是打造每日科技精选,所以关键词我们给到人工智能和机器学习,这里根据各位的需求来进行抓取,注意Authorization替换成自己账号的密钥,可以在账户设置-》用户管理中查看。
import requests
import json
headers = {
"Authorization": "这里替换成自己的密钥",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"keyword_search":"人工智能新闻","upload_date":"Today","type":"Video","duration":"Under 4 minutes","features":"HD","country":""},
{"keyword_search":"机器学习","upload_date":"Today","type":"Video","duration":"Under 4 minutes","features":"HD","country":""}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_lk56epmy2i5g7lzu0k¬ify=false&include_errors=true&type=discover_new&discover_by=search_filters",
headers=headers,
data=data
)
print(response.json()['snapshot_id'])
4.后台查看状态
代码运行后,我们可以获取到一串snapshot_id,这这条数据的唯一id,由于抓取数据需要时间,这里我们需要等待一下,也可以直接在亮数据后台查看到刚刚代码确实触发了一条指令,状态为Running,当状态为Ready时即可下载。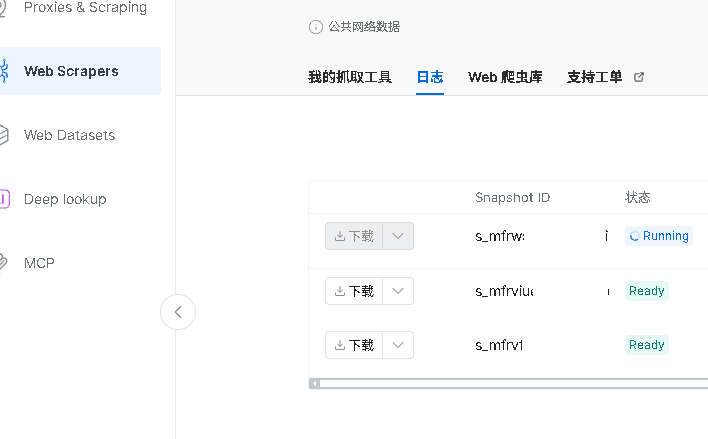
5.获取爬取结果
在数据存储系统中,可以通过 snapshot_id 直接获取对应时间点的数据快照。这个功能在数据备份、恢复和版本控制等场景中非常有用。这里亮数据同样提供api,供我们下载数据。
url = f'https://api.brightdata.com/datasets/v3/snapshot/{response.json()["snapshot_id"]}'
try:
# 定义期望的 Content-Type(支持部分匹配)
expected_content_type = "application/jsonl"
while True:
try:
response = requests.get(url, headers=headers, stream=True)
response.raise_for_status()
content_type = response.headers.get('Content-Type', '').lower()
if expected_content_type in content_type:
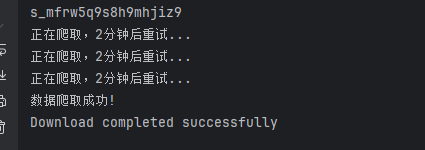
print("数据爬取成功!")
break # 跳出循环
else:
print("正在爬取,2分钟后重试...")
time.sleep(120)
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
with open('json', 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print("Download completed successfully")
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
6.数据清洗,保留需要的字段
在上一步中,我们已经成功获取并保存了数据。接下来可以进行数据清洗工作。由于爬取的数据量较大,我们只需保留所需的字段即可。
for line_num, line in enumerate(response.iter_lines(), 1):
if not line: # 跳过空行
continue
try:
# 解码每一行为 JSON 对象
data = json.loads(line.decode('utf-8'))
# === 数据清洗:提取并重命名重要字段 ===
cleaned = {}
# --- 1. 视频基本信息 ---
# video_id: YouTube 视频唯一标识符(11位字符串)
cleaned['video_id'] = data.get('video_id')
# title: 视频标题
cleaned['title'] = data.get('title')
# url: 视频在 YouTube 的完整链接(通常是 shorts 或 watch 链接)
cleaned['url'] = data.get('url')
# duration_seconds: 视频时长(单位:秒)
cleaned['duration_seconds'] = data.get('video_length')
# date_posted: 视频发布的时间(UTC 时间,ISO 格式)
cleaned['date_posted'] = data.get('date_posted')
# description: 视频描述文字,通常包含简介、标签或外链
cleaned['description'] = data.get('description')
# --- 2. 互动数据 ---
# views: 视频播放量
cleaned['views'] = data.get('views')
# likes: 点赞数量
cleaned['likes'] = data.get('likes')
# comments: 评论数量
cleaned['comments'] = data.get('num_comments')
# subscribers: 该视频所属频道的订阅者数量(估算值)
cleaned['subscribers'] = data.get('subscribers')
# --- 3. 频道信息 ---
# channel.name: 频道的 @用户名(如 @moneycontrol)
# channel.handle: 频道显示名称(如 moneycontrol)
# channel.url: 频道主页链接
# channel.verified: 是否为官方认证频道(蓝色对勾)
# channel.avatar: 频道头像图片 URL
cleaned['channel'] = {
'name': data.get('youtuber'), # @用户名
'handle': data.get('handle_name'), # 昵称
'url': data.get('channel_url'), # 主页链接
'verified': data.get('verified'), # 是否认证
'avatar': data.get('avatar_img_channel') # 头像图片
}
# --- 4. 封面图 ---
# preview_image: 视频缩略图/封面图 URL,可用于展示
cleaned['preview_image'] = data.get('preview_image')
# --- 5. 标签与话题 ---
# hashtags: 视频中使用的 #话题标签 列表(去除 # 符号)
hashtags = data.get('hashtags', [])
cleaned['hashtags'] = [
tag.get('hashtag').lstrip('#') if isinstance(tag, dict) else str(tag).lstrip('#')
for tag in hashtags
if tag and (isinstance(tag, str) or (isinstance(tag, dict) and tag.get('hashtag')))
] if hashtags else []
# --- 6. 字幕内容 ---
# transcript: 视频的自动生成或上传字幕,包含时间戳和文本
# 每条字幕包含:start(开始毫秒)、end(结束毫秒)、text(文字内容)
transcript = data.get('transcript')
if transcript and isinstance(transcript, list):
cleaned['transcript'] = [
{
'start': t.get('start_time'), # 开始时间(毫秒)
'end': t.get('end_time'), # 结束时间(毫秒)
'text': t.get('text') # 字幕文本
}
for t in transcript
if t.get('text') # 只保留有文字的内容
]
else:
cleaned['transcript'] = [] # 若无字幕则为空列表
# --- 7. 推荐视频 ---
# recommended_videos: 播放结束后或侧边栏推荐的相关视频
# 仅保留标题和链接,最多取前 5 个
recommended = data.get('recommended_videos', [])
cleaned['recommended_videos'] = [
{'title': v.get('title'), 'url': v.get('url')}
for v in recommended
if v.get('title') and v.get('url')
][:5]
# --- 8. 搜索发现上下文(用于分析数据来源)---
# discovery: 本次抓取是基于什么搜索条件发现该视频的
discovery = data.get('discovery_input', {})
cleaned['discovery'] = {
# search_keyword: 用户搜索的关键词(如“人工智能新闻”)
'search_keyword': discovery.get('keyword') or discovery.get('keyword_search'),
# upload_date_filter: 指定发布时间范围(如 Today)
'upload_date_filter': discovery.get('start_date'),
# content_type: 内容类型(如 Video)
'content_type': discovery.get('type'),
# duration_limit: 时长限制(如 Under 4 minutes)
'duration_limit': discovery.get('duration'),
# quality_filter: 画质要求(如 HD)
'quality_filter': discovery.get('features'),
# country: 模拟地区(如 US)
'country': discovery.get('country')
}
# --- 9. 抓取时间 ---
# scraped_at: 本条数据被系统抓取的时间(UTC)
cleaned['scraped_at'] = data.get('timestamp')
# --- 10. 警告信息 ---
# warning: 抓取过程中出现的警告(如页面失效、时间不匹配)
cleaned['warning'] = data.get('warning')
# 将清洗后的对象添加到总列表
cleaned_data.append(cleaned)
except json.JSONDecodeError as e:
print(f"第 {line_num} 行 JSON 解析失败: {e}")
except Exception as e:
print(f"处理第 {line_num} 行时发生错误: {e}")
# === 所有数据处理完成后,写入最终的 JSON 文件 ===
with open(output_file, 'w', encoding='utf-8') as f:
# ensure_ascii=False:支持中文不转义
# indent=2:格式化缩进,便于阅读
json.dump(cleaned_data, f, ensure_ascii=False, indent=2)
print(f"清洗完成!共处理 {len(cleaned_data)} 条有效视频数据")
print(f"已保存为结构化 JSON 文件: '{output_file}'")
7.爬取结果
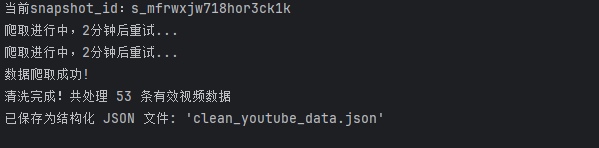
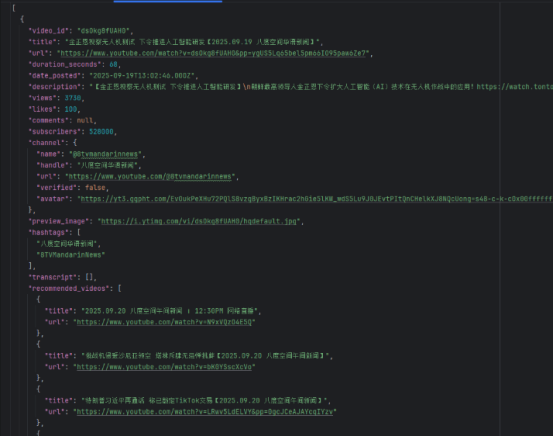
8.完整代码
至此,数据抓取工作现已全部完成,以下是完整代码整合:
import requests
import time
import json
headers = {
"Authorization": "替换为自己的key",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"keyword_search":"人工智能新闻","upload_date":"Today","type":"Video","duration":"Under 4 minutes","features":"HD","country":""},
{"keyword_search":"机器学习","upload_date":"Today","type":"Video","duration":"Under 4 minutes","features":"HD","country":""}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_lk56epmy2i5g7lzu0k¬ify=false&include_errors=true&type=discover_new&discover_by=search_filters",
headers=headers,
data=data
)
print(f"当前snapshot_id:{response.json()['snapshot_id']}")
url = f'https://api.brightdata.com/datasets/v3/snapshot/{response.json()["snapshot_id"]}'
# 输出文件名(保存为标准 JSON 数组)
output_file = 'clean_youtube_data.json'
# 用于存储所有清洗后的数据
cleaned_data = []
try:
# 定义期望的 Content-Type(支持部分匹配)
expected_content_type = "application/jsonl"
while True:
try:
# 发起请求(流式)
response = requests.get(url, headers=headers, stream=True)
response.raise_for_status() # 检查 HTTP 错误(如 404、500)
content_type = response.headers.get('Content-Type', '').lower() # 爬起成功后为: application/jsonl; charset=utf-8
# 判断是否包含 expected_content_type
if expected_content_type in content_type:
print("数据爬取成功!")
break # 跳出循环
else:
print("爬取进行中,2分钟后重试...")
time.sleep(120)
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
for line_num, line in enumerate(response.iter_lines(), 1):
if not line: # 跳过空行
continue
try:
# 解码每一行为 JSON 对象
data = json.loads(line.decode('utf-8'))
# === 数据清洗:提取并重命名重要字段 ===
cleaned = {}
# --- 1. 视频基本信息 ---
# video_id: YouTube 视频唯一标识符(11位字符串)
cleaned['video_id'] = data.get('video_id')
# title: 视频标题
cleaned['title'] = data.get('title')
# url: 视频在 YouTube 的完整链接(通常是 shorts 或 watch 链接)
cleaned['url'] = data.get('url')
# duration_seconds: 视频时长(单位:秒)
cleaned['duration_seconds'] = data.get('video_length')
# date_posted: 视频发布的时间(UTC 时间,ISO 格式)
cleaned['date_posted'] = data.get('date_posted')
# description: 视频描述文字,通常包含简介、标签或外链
cleaned['description'] = data.get('description')
# --- 2. 互动数据 ---
# views: 视频播放量
cleaned['views'] = data.get('views')
# likes: 点赞数量
cleaned['likes'] = data.get('likes')
# comments: 评论数量
cleaned['comments'] = data.get('num_comments')
# subscribers: 该视频所属频道的订阅者数量(估算值)
cleaned['subscribers'] = data.get('subscribers')
# --- 3. 频道信息 ---
# channel.name: 频道的 @用户名(如 @moneycontrol)
# channel.handle: 频道显示名称(如 moneycontrol)
# channel.url: 频道主页链接
# channel.verified: 是否为官方认证频道(蓝色对勾)
# channel.avatar: 频道头像图片 URL
cleaned['channel'] = {
'name': data.get('youtuber'), # @用户名
'handle': data.get('handle_name'), # 昵称
'url': data.get('channel_url'), # 主页链接
'verified': data.get('verified'), # 是否认证
'avatar': data.get('avatar_img_channel') # 头像图片
}
# --- 4. 封面图 ---
# preview_image: 视频缩略图/封面图 URL,可用于展示
cleaned['preview_image'] = data.get('preview_image')
# --- 5. 标签与话题 ---
# hashtags: 视频中使用的 #话题标签 列表(去除 # 符号)
hashtags = data.get('hashtags', [])
cleaned['hashtags'] = [
tag.get('hashtag').lstrip('#') if isinstance(tag, dict) else str(tag).lstrip('#')
for tag in hashtags
if tag and (isinstance(tag, str) or (isinstance(tag, dict) and tag.get('hashtag')))
] if hashtags else []
# --- 6. 字幕内容 ---
# transcript: 视频的自动生成或上传字幕,包含时间戳和文本
# 每条字幕包含:start(开始毫秒)、end(结束毫秒)、text(文字内容)
transcript = data.get('transcript')
if transcript and isinstance(transcript, list):
cleaned['transcript'] = [
{
'start': t.get('start_time'), # 开始时间(毫秒)
'end': t.get('end_time'), # 结束时间(毫秒)
'text': t.get('text') # 字幕文本
}
for t in transcript
if t.get('text') # 只保留有文字的内容
]
else:
cleaned['transcript'] = [] # 若无字幕则为空列表
# --- 7. 推荐视频 ---
# recommended_videos: 播放结束后或侧边栏推荐的相关视频
# 仅保留标题和链接,最多取前 5 个
recommended = data.get('recommended_videos', [])
cleaned['recommended_videos'] = [
{'title': v.get('title'), 'url': v.get('url')}
for v in recommended
if v.get('title') and v.get('url')
][:5]
# --- 8. 搜索发现上下文(用于分析数据来源)---
# discovery: 本次抓取是基于什么搜索条件发现该视频的
discovery = data.get('discovery_input', {})
cleaned['discovery'] = {
# search_keyword: 用户搜索的关键词(如“人工智能新闻”)
'search_keyword': discovery.get('keyword') or discovery.get('keyword_search'),
# upload_date_filter: 指定发布时间范围(如 Today)
'upload_date_filter': discovery.get('start_date'),
# content_type: 内容类型(如 Video)
'content_type': discovery.get('type'),
# duration_limit: 时长限制(如 Under 4 minutes)
'duration_limit': discovery.get('duration'),
# quality_filter: 画质要求(如 HD)
'quality_filter': discovery.get('features'),
# country: 模拟地区(如 US)
'country': discovery.get('country')
}
# --- 9. 抓取时间 ---
# scraped_at: 本条数据被系统抓取的时间(UTC)
cleaned['scraped_at'] = data.get('timestamp')
# --- 10. 警告信息 ---
# warning: 抓取过程中出现的警告(如页面失效、时间不匹配)
cleaned['warning'] = data.get('warning')
# 将清洗后的对象添加到总列表
cleaned_data.append(cleaned)
except json.JSONDecodeError as e:
print(f"第 {line_num} 行 JSON 解析失败: {e}")
except Exception as e:
print(f"处理第 {line_num} 行时发生错误: {e}")
# === 所有数据处理完成后,写入最终的 JSON 文件 ===
with open(output_file, 'w', encoding='utf-8') as f:
# ensure_ascii=False:支持中文不转义
# indent=2:格式化缩进,便于阅读
json.dump(cleaned_data, f, ensure_ascii=False, indent=2)
print(f"清洗完成!共处理 {len(cleaned_data)} 条有效视频数据")
print(f"已保存为结构化 JSON 文件: '{output_file}'")
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
9.数据应用在聚合网站
获得了数据支持后,就可以实现自己的目标了。在本案例中,博主将这些数据用于个人“每日科技精选”YouTube聚合站的建设与维护,如下图所示:
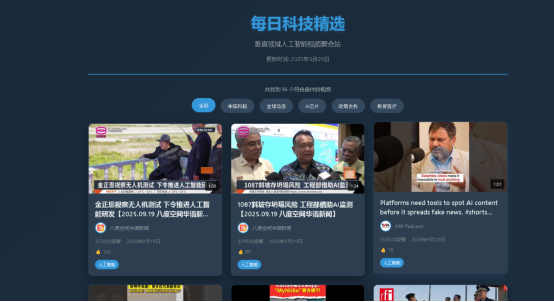
到这里我们的实战就结束了,本文所展示的只是亮数据平台的冰山一角,无论你是创业者、内容运营者,还是技术团队,亮数据 Web Scraper API 都能帮你省下数周开发时间,降低90%维护成本,快速验证商业模式,抢占垂直内容赛道先机。👉 立即免费试用
结语
爬虫不是目的,数据才是资产;自动化不是终点,创造才是意义。希望这篇文章能为你打开一扇门!

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)