【前沿解读】当AI大模型能像人类一样进行“因果推理”
AI大模型引领技术革命,但因果推理成为关键挑战。文章剖析了人工智能的两大框架:基于关联的模型易受混淆因素干扰,而因果推理框架能更准确揭示变量间真实关系。当前AI发展面临核心矛盾——大数据环境下的不可控数据生成过程与传统因果推理的小数据可控需求。作者提出"识别因果结构-构建因果模型-优化决策机制"的方法体系,并介绍潜在结果框架和功能因果模型等理论工具。随着AI行业人才缺口扩大,掌
AI时代的人工智能已经涉及医疗、金融和司法等各行各业。同时,一个技术的迅速发展也会面临很多挑战。尤其是靠互联网壮大的企业,都开始感到“它懂我吗?”“它真的可以信任吗?”等问题。
在这个信息过载的时代,我们常常会陷入“只知其然,不知其所以然”的境地,只知道这套系统给出的预测有时候会非常靠谱,或者说很好用,但却不知道它背后的底层逻辑是什么。
为了摆脱那些让人晕头转向的关联模型,更好地理解因果推理,就要先弄清楚因果推理的基本理论、方法和现实应用。
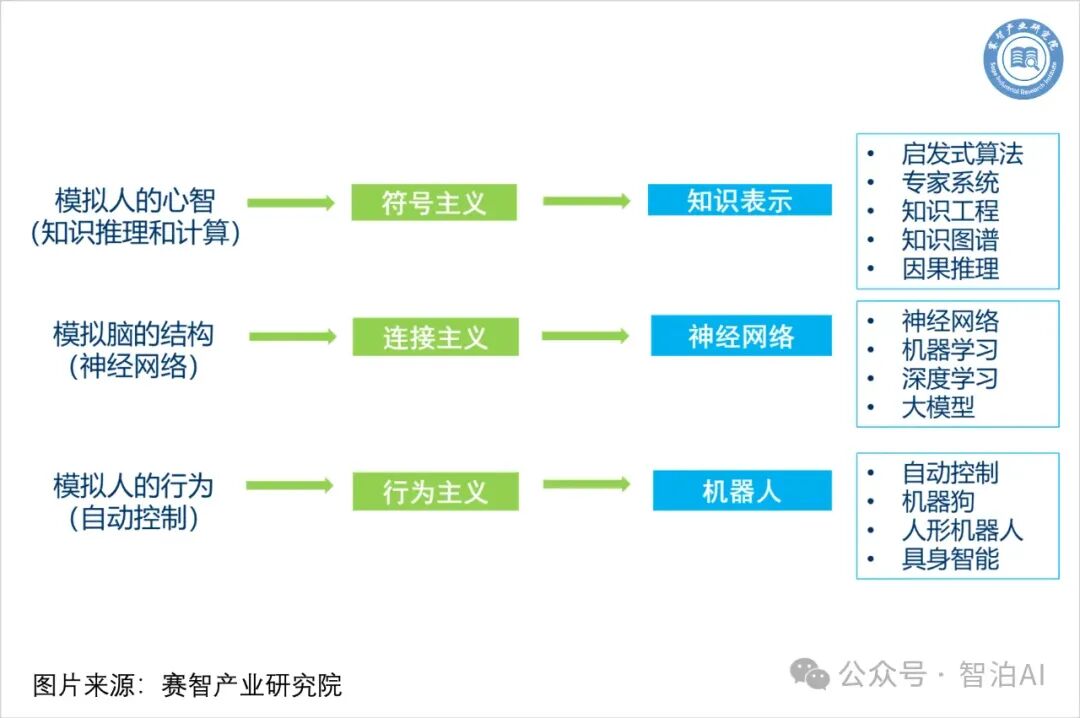
一、基于关联框架的人工智能
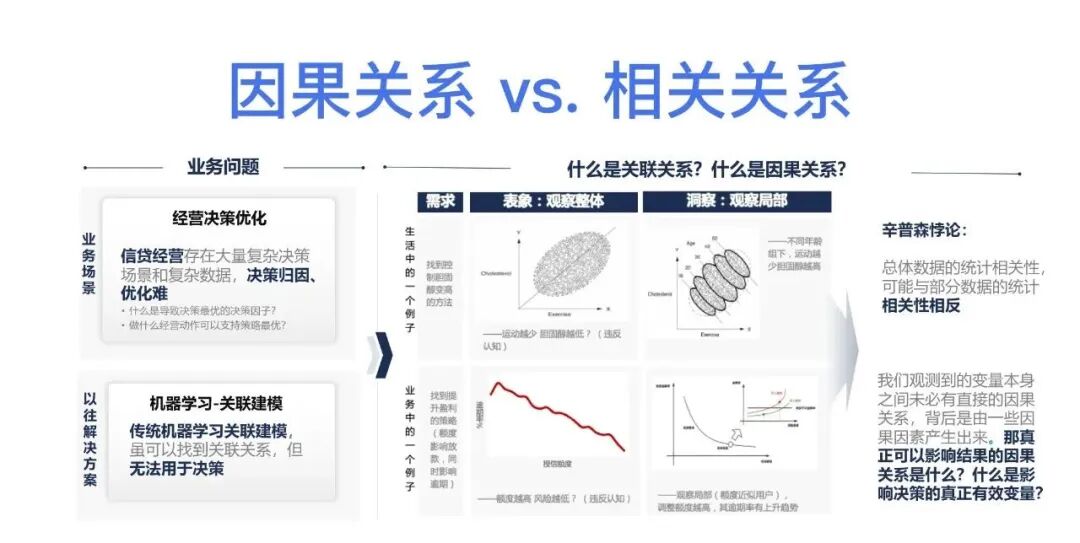
基于关联的框架是指通过观察数据中的相关性来推断变量之间的关系,而基于因果的框架则更注重确定某个变量是否直接导致了结果的变化。
基于关联的框架可能会错误地得出肤色和犯罪率之间存在强关联关系,因为黑人的收入普遍较低,而整体犯罪率也较高。然而,基于因果的框架更加谨慎地考虑了其他可能因素的影响,例如收入水平。通过在两组对照组中控制收入水平的情况下比较黑人和白人的犯罪率,我们可以更准确地判断肤色是否直接导致了犯罪率的差异。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
在基于关联的框架中,由于未能控制其他可能影响结果的因素,因此可能会产生偏差和误导性的结论。
注意:问题并不在于关联模型本身,而在于如何正确地使用机器学习方法。您指出了关联的三种产生方式:因果机制、混淆效应和样本选择偏差,其中只有因果机制产生的关联是稳定、可解释且可回溯的。
在现实世界中,确实存在许多数据相关性,但并不意味着这些关联就是因果关系。混淆效应和样本选择偏差可能会导致虚假关联,从而影响机器学习模型的性能和可靠性。
二、基于因果框架的人工智能
从根本上突破当前机器学习的局限性,可能需要使用更严格的统计逻辑,如因果统计,来替代原来的关联统计。这种方法可能会面临一些挑战,因为因果推理主要应用于小数据控制环境下的统计研究,而机器学习往往涉及到大数据环境,其中数据的产生过程是不可控的。
在传统的因果推理框架中,我们通常能够控制数据的产生过程,从而更好地理解因果关系。例如,在一个行为学实验中,研究人员可以控制谁接受了疫苗,谁没有接受,以便推断疫苗的有效性。然而,在大数据的观测研究中,数据的产生过程是不可知的,这给因果推理带来了挑战。
此外,因果推理和机器学习的目标也存在差异。因果推理更注重理解数据产生的机制,而机器学习主要关注预测未来事件的发生。因此,在将因果推理应用于机器学习时,我们需要考虑如何适应大数据环境的特点,并调整方法以解决因果推理和机器学习之间的目标差异。
以下是一套方法体系,旨在解决这个问题:
识别因果结构:在大规模数据中识别出因果结构是首要任务。这可能涉及到利用因果推断方法来确定变量之间的因果关系,包括因果图、因果图模型等技术。这可以帮助我们理解数据生成的机制,并揭示潜在的因果关系。
因果启发的学习模型:一旦识别出因果结构,就需要将这些信息与机器学习模型进行融合。因果启发的学习模型旨在结合因果推断和机器学习方法,以提高模型的解释性、稳定性和准确性。这可能涉及到开发新的机器学习算法,考虑因果关系的约束和先验知识,以及设计适用于大规模数据的因果推断方法。
设计决策机制:最终目标是利用识别出的因果结构来优化决策过程。这包括反事实推理和决策优化机制,以利用因果关系对决策进行指导和优化。这可能涉及到开发基于因果推断的决策模型,考虑潜在的因果效应并设计相应的决策策略。
通过以上方法体系,可以更好地利用因果推理的思想来指导机器学习模型的发展和应用,从而提高模型的解释性、稳定性和决策效果。这需要跨学科的合作和持续的研究努力,以解决因果推理和机器学习之间的鸿沟,并为实现智能决策系统的发展奠定基础。
三、因果推理的基本理论
(一)因果推理基本范式:因果模型(Structure Causal Model)
核心是在已知的因果图中进行推理,包括识别变量之间的因果关系以及影响程度的估计。目前已有一些成熟的方法和准则,如后门准则、前门准则等,用于处理混淆和进行因果估计。
然而,这种方法面临着一个核心问题,即在观测研究中无法定义完整的因果图。尽管在某些领域(如考古学)中可以通过专家知识来定义因果图,但这种方法可能会重蹈“专家系统”的老路,即过于依赖领域专家的主观判断,可能导致模型的局限性和不确定性。
在因果推理中,核心问题确实是如何有效地发现因果结构。因果结构的发现对于正确理解数据生成的机制、推断因果关系以及做出有效的决策至关重要。发现因果结构的挑战在于,它不仅需要考虑变量之间的关联性,还需要考虑因果关系的方向性和因果链条的复杂性。尤其是在大规模数据和高维度数据的情况下,因果结构的发现变得更加困难。
目前,针对因果结构的发现,有一些方法和技术正在不断发展和完善,包括基于因果图的方法、因果关系的因果发现算法、数据驱动的因果推断方法等。这些方法旨在从数据中推断出变量之间的因果关系,并构建因果图模型,以帮助我们更好地理解数据生成的机制和推断因果关系。
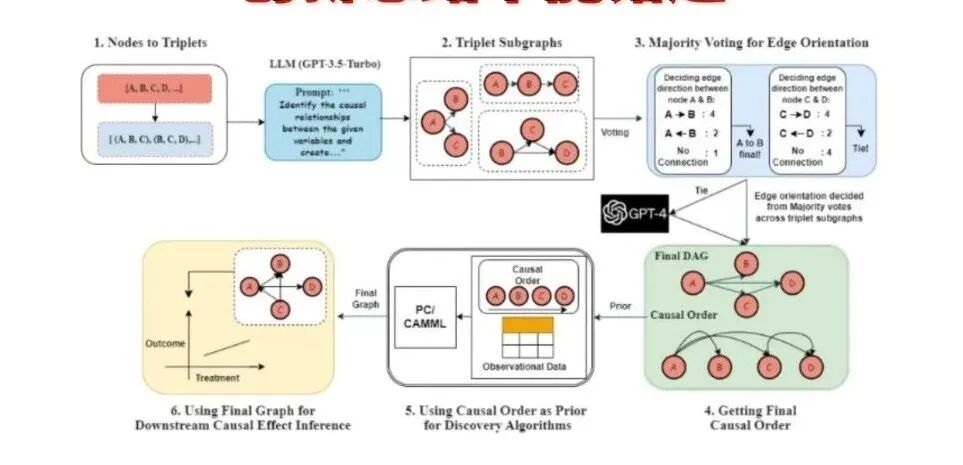
但是,尽管已经取得了一些进展,但在复杂的真实世界数据中,仍然存在许多挑战和困难。因此,继续研究和开发新的方法和技术,以更好地发现因果结构,并将其应用于实际问题中,是当前因果推理领域的重要任务之一。
(二)因果推理基本范式:潜在结果框架(Potential Outcome Framework)
潜在结果框架(Potential Outcome Framework)是因果推理的另一个重要范式,其核心思想是不需要了解所有变量的因果结构,而是关注某个特定变量对输出的因果影响,这个变量通常被称为处理(Treatment)或暴露(Exposure)。
在这个框架下,我们假设了每个个体都有多个潜在结果,其结果取决于是否接受处理。然而,我们只能观测到其中一种结果,这称为个体的观测结果(Observed Outcome)。
在潜在结果框架中,我们需要考虑干扰因素(Confounders),这些因素可能影响处理和结果之间的关系,而且通常是我们无法控制的。为了准确估计处理对结果的因果效应,我们需要假设已经观测到了所有的干扰因素,并且可以通过统计方法进行控制。
总体来说,潜在结果框架提供了一种简化因果推理的方法,特别是在处理因果关系的复杂性和观测限制时。通过关注处理对输出的直接影响,并控制潜在的干扰因素,我们可以更好地理解处理对结果的因果效应。
四、因果发现和问题定义
因果发现的定义是对于给定的一组样本,其中每个样本都由一些变量去表征,我们希望通过一些可观测数据去找到这些变量之间的因果结构。找到的因果图,可以认为是一个图模型,从生成式模型的角度来讲,我们希望找到一个因果图,使得它能够按照其中的因果结构去生成这样的一组样本,而且这组样本的似然性是最高的。
简而言之,因果发现的目标是通过观测数据找出变量之间的因果关系,并用图模型来表示这些关系。这样的因果图能够最好地解释数据的生成过程,即在给定因果结构下生成观测数据的概率最大。因此,因果发现旨在寻找一个最佳的因果图模型,使其能够最好地解释观测数据并揭示变量之间的因果关系。
这里引入因果推理中的一个重要概念Functional Causal Models (FCMs) ,它描述了变量之间的因果关系如何通过函数关系来实现。在一个有向无环图 (DAG) 中,每个变量都有其父节点,其值可以通过父节点和一个函数的作用再加上噪声来生成。
在线性框架下,这个问题可以转化为如何找到一组参数(通常表示为W),使得对于某个特定变量X的重构最为准确。换句话说,我们希望找到一组参数W,通过线性函数关系将X与其父节点之间的关系建模,以最优地重构X的值。
因此,Functional Causal Models 提供了一种将因果关系转化为函数关系的方法,通过寻找合适的函数和参数,可以更好地理解变量之间的因果关系,并进行因果推断和预测。
有向无环图的优化一直是一个开放性问题,2018年的一篇论文[Zheng, Xun, Bryon Aragam,Pradeep K. Ravikumar, and Eric P. Xing. DAGs with NO TEARS: Continuous Optimization for Structure Learning. Advances in Neural Information Processing Systems 31 (2018).]提出来了一个优化方法:可以在全空间的有向无环图内去做梯度优化,通过增加DAG限制和稀疏限制(l1或l2正则),使得最终X的重构误差最小。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)