无需微调,仅靠架构:Nexus Architect 的自动化工作流实现推理跃迁
Nexus Architect 不只是一个工具,它代表了一种深刻的范式转变——从追求"更大的模型",转向构建"更智能的系统"。它证明了,真正的推理能力,可以通过结构化协作自动化设计和持续优化来实现,而不仅仅依赖于模型内部的黑盒计算。通过开源其框架PrimisAI/nexus和基准 PrimisAI/arcbench(见文末参考资料),研究团队为整个社区开源了一个强大的平台。这标志着我们正从"模型中
当顶尖AI在"数字表指针"这类常识问题上频频失误,我们是否该反思:真正的推理能力究竟来自更大模型,还是更优架构?Nexus Architect给出了颠覆性答案——通过自动化工作流生成和IPR反馈循环,它将标准LLM转化为超越专用推理模型的"专家团队",性能提升高达66%。本文深入解构这一系统智能新范式。

大家好,我是肆〇柒。今天很高兴和大家分享一项由PrimisAI团队带来的成果——Nexus Architect,这项技术正在重新定义AI推理的边界。作为AI系统架构领域的前沿探索,这项研究由位于加州洛斯加托斯的PrimisAI与犹他大学合作完成,它正尝试解决当前大模型推理能力的深层瓶颈。
一个被忽略的"常识"——数字表没有指针
现在,我们一起设想一个场景:你向当前最先进的AI模型提问:"在数字表上6:10时,分针和时针形成的钝角是多少度?"。一个性能卓越的大型推理模型(LRM)可能会给你一个详尽而精确的回答:"分针在60°,时针在185°,夹角为125°"。这个答案在数学上是完美的,但它忽略了一个最根本的"常识"——数字表根本没有指针。
这个看似简单的例子,深刻地揭示了当前AI推理的一个核心瓶颈:过度依赖模式匹配与记忆化,而非真正的理解与泛化。多项研究证实,当面对新颖、未见过的问题时,即使是顶尖的LRMs也常常表现不佳。它们更像是"记忆大师",而非"推理专家"。当问题稍作变化,或包含需要"跳出框架"思考的"陷阱"时,其性能便可能急剧下降。
这引出了一个根本性问题:我们是否必须通过不断增大模型规模和进行昂贵的专用训练,才能获得真正的推理能力?Nexus Architect 提出了一种颠覆性的答案:真正的智能推理,可能不在于模型内部,而在于系统架构。它通过构建一个由多个专业智能体组成的"专家团队",并辅以自动化的工作流设计和持续的自我优化机制,将一个标准的、现成的LLM,转化为一个在复杂推理任务上超越专用LRMs的超级引擎。
下面,我们一起了解一下Nexus Architect的核心机制。
Nexus:一个为协作而生的轻量级框架
在探讨Nexus Architect的"智能"之前,我们必须理解其坚实的基础——Nexus框架。Nexus并非一个黑盒系统,而是一个设计精良、高度透明的开源框架,这是为了简化复杂多智能体系统的构建与管理。其核心设计理念是**"分而治之"与"低代码"**。
Nexus框架的关键特性构成了其强大能力的基石:
1. 层级化监督架构:系统采用主-从(Main-Assistant)监督模式。一个全局的主监督者(Main Supervisor)负责宏观协调,它可以将复杂任务分解并委派给多个助理监督者(Assistant Supervisor),每个助理监督者再管理一组执行具体任务的工作智能体(Worker Agent)。这种树状结构天然适合处理需要多步骤、多视角分析的复杂任务
2. 声明式YAML配置:这是Nexus最实用的特性之一。开发者无需编写大量胶水代码,即可通过简洁的YAML文件定义整个智能体团队的组织结构、角色分工和交互逻辑。这极大地提升了开发效率和可维护性。
3. Model Context Protocol (MCP):为了解决智能体与外部工具的集成难题,Nexus定义了MCP协议。它允许智能体通过标准化的方式发现和调用外部工具(如计算器、搜索引擎、代码解释器),无论是通过HTTP/SSE还是本地子进程(stdio)。MCP解决了多智能体系统中的"工具碎片化"问题——不同工具往往有各自不兼容的接口标准,导致智能体难以无缝调用。通过统一协议,Nexus使智能体能像调用本地函数一样使用外部工具,大大降低了系统集成的复杂度。
4. 模块化与可追溯性:Nexus内置了结构化的日志系统和持久化的会话历史管理。每个工作流的运行过程、智能体间的通信、工具调用等都被完整记录,确保了系统的可调试性和可重现性。
然而,原始的Nexus框架有一个关键限制:工作流是静态的。开发者需要预先手动设计好所有智能体的角色和交互流程。这就像为每种问题类型都准备了一套固定的"作战方案",缺乏灵活性。当面对一个全新的问题类别时,这套方案可能完全失效。
虽然Nexus框架提供了强大的多智能体协作基础,但其静态工作流的局限性在面对新型问题时暴露无遗。这促使我们思考:能否让系统自动为每类问题设计最优的工作流?这正是Nexus Architect要解决的核心问题。
Nexus Architect:为问题量身定制的"智能架构师"
如果说Nexus框架是搭建智能体团队的"乐高积木",那么Nexus Architect就是那个能够根据任务需求,自动设计出最优"乐高模型"的"智能设计师"。其核心创新在于自动化工作流生成(Automated Workflow Generation)。
一个直观的类比:智能会议策划师
想象你要解决一个复杂的商业决策问题。传统方法是,你(开发者)需要亲自:
1. 规划议程:决定讨论哪些议题。
2. 邀请专家:确定需要财务、市场、技术等哪些领域的专家。
3. 设计流程:规划发言顺序,比如先由市场专家分析需求,再由技术专家评估可行性,最后财务专家核算成本。
4. 准备材料:为每位专家准备相关的背景资料。这个过程耗时耗力,且依赖于你的个人经验。
Nexus Architect则像一个智能会议策划师。你只需提供两样东西:
1. 会议目标(用户提示):例如,"分析我们新产品在东南亚市场的上市策略"。
2. 成功案例(问题-解决方案对):例如,提供3-5个过去成功的市场分析报告作为参考。
然后,这个"智能策划师"会自动完成剩下的所有工作:它会分析目标,理解任务的复杂性,自动生成一份包含所有必要环节的详细会议议程,并为你邀请合适的专家,甚至为他们准备初步的发言提纲。
在技术层面,这个"策划师"本身是一个由GPT-4.1驱动的高级智能体。它通过阅读Nexus框架的合成文档摘要,获得了对整个框架能力的深刻理解。这使得它能精准地判断在何种情况下需要引入计算器工具,何时需要创建一个专门的"验证"智能体,以及如何构建最有效的信息流路径。
自动化工作流生成的五大步骤
Nexus Architect的自动化流程是一个严谨的闭环,具体分为五个阶段。为更清晰地展示这一过程,下表总结了每个步骤的关键要素:
|
步骤 |
输入 |
处理过程 |
输出 |
|
任务分解与规划 |
用户问题描述+示例 |
将高层次目标分解为可执行的子任务 |
任务列表(如"识别问题类型"、"分析潜在陷阱") |
|
推理工作流设计 |
任务列表 |
设计多智能体协作蓝图,确定角色与通信拓扑 |
智能体拓扑结构(如"三角验证"结构) |
|
组件构建与提示工程 |
设计蓝图 |
实例化智能体,生成初始系统提示 |
智能体实例与提示词(如 |
|
工作流验证与测试 |
生成的工作流+示例 |
模拟运行,评估工作流性能 |
通过/失败的测试结果 |
|
迭代提示优化(IPR)反馈循环 |
失败案例 |
分析根本原因,生成结构化反馈 |
优化后的系统提示 |
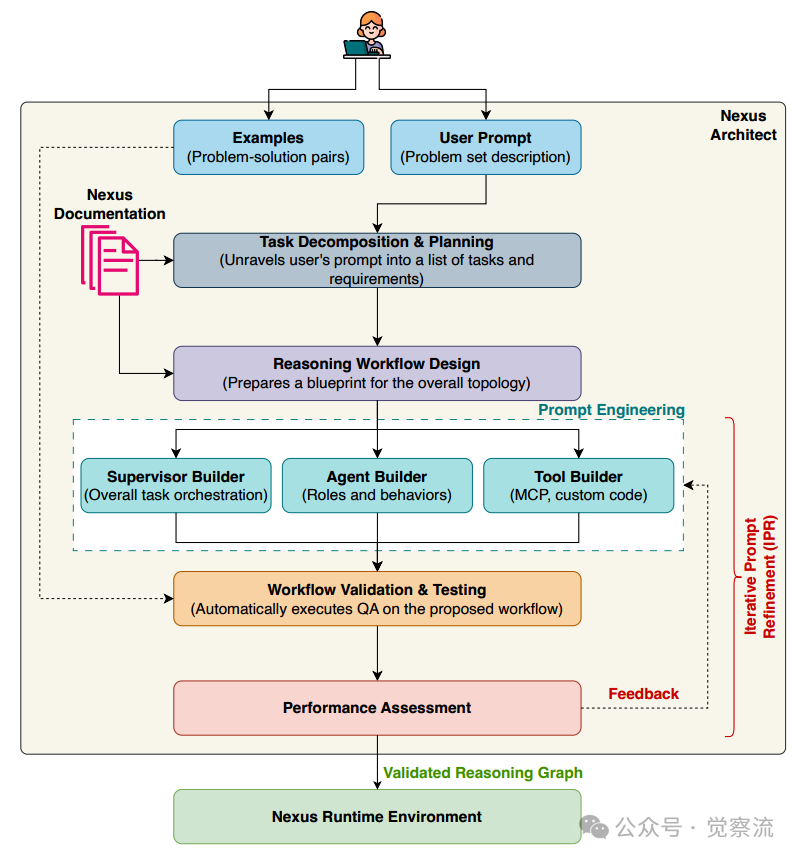
Nexus Architect系统架构图
整个流程如上图所示,从用户提示和问题-解决方案对开始,Nexus Architect会逐步分解任务、设计工作流、构建组件、验证测试,并在必要时通过IPR反馈循环优化系统提示,直到达到预期性能。这一过程完全自动化,开发者只需提供初始输入,系统就能生成一个针对特定问题类别高度优化的多智能体工作流。
1. 任务分解与规划:系统接收用户的问题描述(如"解决一系列逻辑谜题")和少量示例(如3-5个谜题及其正确答案)。它首先将这个高层次目标分解为一系列具体的、可执行的子任务,例如"识别问题类型"、"分析潜在陷阱"、"生成初步假设"、"进行逻辑验证"等。
2. 推理工作流设计:基于分解出的子任务,Architect设计出一个多智能体协作的蓝图。它会决定需要几个智能体,每个智能体的角色(如Analyst、Calculator、Reviewer),以及它们之间的通信拓扑结构。例如,对于一个逻辑谜题,它可能会设计一个"三角验证"结构,其中Analyst负责发现陷阱,Calculator负责计算,Reviewer负责最终把关。
3. 组件构建与提示工程:根据设计蓝图,系统自动实例化各个智能体和工具。每个智能体的初始"系统提示"(System Prompt)由构建器根据其角色生成。例如,Analyst的初始提示可能是:"你是一个逻辑分析师,擅长识别问题中的隐含假设和语言陷阱。"
4. 工作流验证与测试:系统使用提供的示例对刚刚生成的整个工作流进行自动测试。它会模拟运行,检查工作流是否能正确解决问题。
5. 迭代提示优化(IPR)反馈循环:这是整个系统实现"自学习"和"自适应"的核心。如果测试失败,系统不会推倒重来,而是启动IPR循环。它会分析失败案例,生成详细的、结构化的反馈,然后利用这些反馈去优化每个智能体的系统提示。
IPR:智能体团队的"持续进化"引擎
如果说自动化工作流生成是Nexus Architect的"大脑",那么迭代提示优化(IPR)就是它的"脊髓反射"和"学习机制"。IPR使得整个多智能体系统能够从错误中学习,并不断进化。
IPR的工作原理:一个强化学习式的闭环
IPR的流程可以概括为一个简单的循环:
1. 测试:运行工作流,评估性能。
2. 诊断:如果失败,分析根本原因。
3. 优化:根据诊断结果修改智能体的指令。
4. 验证:再次测试,确认改进。为更清晰地理解IPR与传统提示工程的区别,以下表格总结了关键差异:
|
特性 |
传统提示工程 |
IPR |
|
优化范围 |
单个智能体 |
所有智能体(包括监督者和工作智能体) |
|
反馈来源 |
人工经验 |
自动化测试与失败分析 |
|
优化频率 |
一次性 |
迭代式(通常5+轮) |
|
优化依据 |
主观判断 |
结构化诊断反馈 |
|
优化目标 |
单点性能 |
整体系统协同 |
实战案例:教会AI"常识"
让我们回到"数字表"问题,看看IPR是如何工作的。第一轮迭代(失败):
- 输入: "在数字表上6:10时,分针和时针形成的钝角是多少度?"
- 输出: "分针在60°,时针在185°,夹角为125°。" (技术正确,但忽略了前提)
- IPR诊断反馈:
a.问题: Analyst 智能体未能识别问题中的"陷阱"。
b.根本原因: 系统提示没有明确要求优先考虑"元答案"(meta-answer)或"文化常识"。
c.行动指令: 修改 Analyst 的提示,要求其在遇到类似"数字表-指针"这种明显矛盾时,必须将"该物体不具备此功能"作为首要答案。
第二轮迭代(成功):
- 优化后的
Analyst提示: "...当问题的上下文或背景强烈暗示一个陷阱或常识性错误(例如,'数字表—无指针')时,必须明确指出这一点,并将其作为首要结论..." - 输入: (相同问题)
- 输出: "Riddle/Punchline Answer(Primary): Digital watches do not have hands." (正确!)
这个案例揭示了IPR的深层价值:它不仅仅是调优提示词,更是在智能体团队和人类意图之间建立语义对齐。通过几轮迭代,整个团队学会了如何"像人类一样思考",理解了问题背后的文化和语境线索。

IPR迭代过程中的性能提升
如上图所示,IPR机制在迭代过程中持续提升系统性能。图表展示了五次独立实验运行中,IPR迭代对性能的影响。可以看到,随着迭代次数增加(从IPR-iter-1到IPR-iter-5),系统在样本问题上的通过率显著提升,有些运行甚至从60%提升到90%。最终,整个系统在完整数据集上的表现也得到了大幅改善。
关键收获:IPR的优化是全局性的。该过程会迭代优化工作流中所有智能体的系统消息,包括监督者和工作智能体。这确保了整个"专家团队"作为一个整体在协同进化。正如实验数据所示,仅通过5轮IPR迭代,系统在测试集上的表现平均提升了约20个百分点,这解释了为什么一个使用标准LLM(GPT-4.1)的系统能够超越专门训练的LRM——通过多智能体分工避免认知过载,以及IPR机制带来的持续优化能力。
实践指南:三步上手Nexus Architect
理论终将服务于实践。以下是基于开源仓库为大家准备的快速入门指南。
环境准备
复制
# 安装Nexus框架
pip install primisai
# 或从源码安装
git clone git@github.com:PrimisAI/nexus.git
cd nexus
pip install -e .方法一:编程式创建(适合快速原型)
复制
from primisai.nexus.core import Supervisor, Agent
# 配置LLM
llm_config = {
"api_key": "your-openai-api-key",
"model": "gpt-4.1", # Nexus Architect的核心
}
# 创建主监督者
supervisor = Supervisor("LogicSolver", llm_config)
# 创建专业智能体
analyst = Agent("Analyst", llm_config,
system_message="你是一个逻辑分析师,负责识别问题中的陷阱和隐含假设。")
calculator = Agent("Calculator", llm_config,
system_message="你负责精确计算,但必须先确认问题的前提是否成立。")
reviewer = Agent("Reviewer", llm_config,
system_message="你是最终把关者,负责综合所有信息并给出最终答案。")
# 注册智能体,形成团队
supervisor.register_agent(analyst)
supervisor.register_agent(calculator)
supervisor.register_agent(reviewer)
# 提问并获取答案
question = "在数字表上6:10时,分针和时针形成的钝角是多少度?"
response = supervisor.chat(question)
print(response)
# 经过IPR优化后,预期输出: "Riddle/Punchline Answer(Primary): Digital watches do not have hands."方法二:YAML配置(推荐,更灵活)
创建 logic_solver.yaml 文件:
复制
supervisor:
name:LogicSolver
type:supervisor
llm_config:
model:gpt-4.1
api_key:${LLM_API_KEY}# 支持环境变量
system_message:"你负责协调团队解决复杂的逻辑和数学谜题,特别注意引导团队识别问题中的陷阱。"
children:
-name:Analyst
type:agent
system_message:"你是一个逻辑分析师,负责识别问题中的陷阱和隐含假设。"
keep_history:true# 保持历史记录对分析类智能体至关重要,因为它们需要上下文理解问题陷阱
-name:Calculator
type:agent
system_message:"你负责精确计算,但必须先确认问题的前提是否成立。"
keep_history:true
# 可在此处集成MCP工具,如计算器
# tools:
# - name: calculator
# type: function
# python_path: my_tools.calculator.run # 确保工具路径正确,使计算更精确
-name:Reviewer
type:agent
system_message:"你是最终把关者,负责综合所有信息并给出最终答案。"
keep_history: true主程序加载配置:
复制
from primisai.nexus.config import load_yaml_config, AgentFactory
# 加载YAML配置
config = load_yaml_config('logic_solver.yaml')
# 创建智能体团队
logic_solver = AgentFactory().create_from_config(config)
# 开始交互
logic_solver.start_interactive_session()实现IPR:让系统自我进化
IPR是Nexus Architect的核心,虽然其自动化生成机制是内部实现,但其思想可以指导我们的开发实践。在实际应用中,我们可以模拟IPR循环:
1. 运行测试:用一组测试用例(ArcBench风格)评估你的工作流。
2. 收集失败案例:记录所有回答错误或不理想的问题。
3. 分析诊断:人工分析失败原因。是Analyst没发现陷阱?还是Reviewer综合信息有误?
4. 优化提示:根据诊断结果,手动修改相应智能体的系统提示。
5. 重新测试:验证优化效果。
通过反复执行这个循环,你的智能体团队将变得越来越强大。
性能与价值:用标准模型实现超越
Nexus Architect的威力在实验中得到了充分验证。研究团队构建了ArcBench基准,包含158道刻意回避记忆套路的逻辑思考题。
- 实验设置:所有Architect生成的工作流均使用未经过任何微调的GPT-4.1作为底层LLM。
- 对比对象:包括Gemini 2.5 Flash Preview、Claude Sonnet 4、DeepSeek-R1等顶尖LRMs。

Nexus Architect与最先进LLM/LRM的性能对比
结果令人印象深刻:
- Nexus Architect的最佳通过率(Pass Rate)达到了 74.68%。
- 这比表现最好的专用LRM(Gemini 2.5 Flash Preview,44.94%)高出 66%。
- 相比Claude Sonnet 4和DeepSeek-R1,性能接近 2.5倍。
- 相比Llama 4 Scout,性能超过 3倍。
这种性能跃升源于系统设计的两个关键优势:
1. 多智能体分工:将复杂问题分解为更易处理的子任务,避免了单模型的认知过载
2. IPR机制:使系统能从错误中自动学习,而不仅仅是依赖预训练知识这组数据传递了一个明确的信号:通过精妙的系统设计,我们可以将一个"通用型"LLM,转化为在特定领域超越"专家型"LRMs的超级解决方案。对于需要高可靠性的应用场景,这不仅仅是性能的提升,更是成本效益的革命。
适用场景与未来展望
谁应该使用Nexus Architect?
适用场景:
- 复杂决策与分析:需要多角度(技术、商业、风险)分析的任务。
- 反"陷阱"问题:如逻辑谜题、脑筋急转弯、法律条文解读等,其中"理解问题"比"解决问题"更重要。
- 需要高可靠性的系统:如金融风控、医疗辅助诊断(信息整合),要求极低的错误率。
- 模式可学习的任务:存在可被提炼和复用的解决范式。
不适用场景:
- 简单问答:如事实性查询("水的沸点是多少?"),单智能体即可高效解决。
- 超低延迟要求:多智能体间的通信和协调会引入额外延迟。
- 完全开放、无规律的创造性任务:如诗歌创作,协作可能产生冗余而非增益。
未来方向
Nexus Architect的成功预示着AI推理范式的重要转变。未来的研究方向可能包括:
1. 动态工作流重配置:在推理过程中,根据中间结果实时调整团队结构和流程。
2. 多模态扩展:将文本推理能力扩展到图像、音频等多模态领域。
3. 与微调的融合:探索将自动化工作流生成与针对性的模型微调相结合,实现双重增强。
总结:走向"系统智能"的时代
Nexus Architect 不只是一个工具,它代表了一种深刻的范式转变——从追求"更大的模型",转向构建"更智能的系统"。它证明了,真正的推理能力,可以通过结构化协作、自动化设计和持续优化来实现,而不仅仅依赖于模型内部的黑盒计算。通过开源其框架PrimisAI/nexus和基准 PrimisAI/arcbench(见文末参考资料),研究团队为整个社区开源了一个强大的平台。这标志着我们正从"模型中心"的AI时代,迈向一个以系统为中心的新时代。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)