
速成--数据分析大盘点(二)
上一篇,我们学习了怎么用nmpy和pandas的一些函数,在接着讲下面的内容之前,希望同学们能够去复习一下,我们温故而知新。好了,话不多说,我们继续。
一.内容补充
在学习pandas库的时候,我们学了两种常见的数据类型,一种是Series,另一种是DataFrame。在DataFrame中,我们提到,它比Series多了一些内容,就是关于轴的概念。我们先一起回忆一下。

它有两个轴,一个是水平轴,axis=1,一个是垂直轴,axis=0。这个很容易记混,我教大家一个小技巧,我们平时说话,喜欢说“10,10”,那么说到轴,最先想起来的就是“x-y”轴,这样对应起来记忆,X轴对应1,Y轴对应0。当然同学们有更好的方法就更好了,总之不要记混。
在python的基础课程中,同学们应该接触过mean()函数和sum()函数,如果没接触过也不要担心,这里我先给大家简单介绍一下,后面会专门出一篇有关python基础的课程。
sum()函数是求和函数,求几个数之间的加和。mean()函数是求平均数的函数。
现在,我们将这两个函数和上面讲到的轴结合一下。就拿上面图中的数字为例,如果想要求名字为df的数据表的每一列的平均值,语句df.mean(axis=0),就能得到结果rank=2.5、GDP=68379.5。是不是很方便,一个简单的语句,就能求出每一列的平均值,这就是统计函数,其实pandas中还有很多统计函数,今天我们学习六种。
二.统计函数
2.1 统计函数使用方法
前面举例子的时候,我们用df.mean(axis=0)求了数据表每一列的平均值,但是,同学们有没有想过,有时我需要多列、不同列求平均值,并不用求每一列的平均值。这就涉及到了单列统计、多列统计。
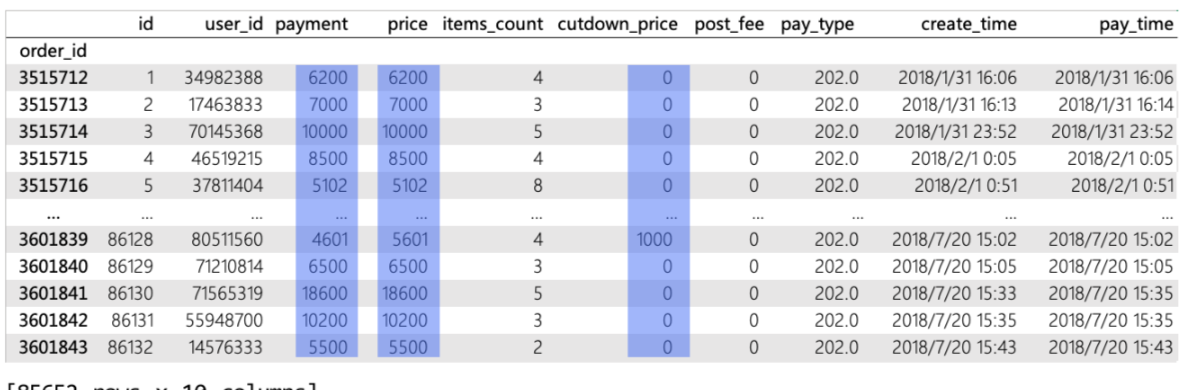
单列统计,现在我们想要知道payment、price、cutdown_price这三列的平均值,就分别写各自语句df["payment"].mean()以此类推。
多列统计也很简单,假如我们要求某100列的平均值,我们总不能一列一条语句写下去,这时就用到我们多列统计,语句df[["columns_1","columns_2",...]]。用上面的例子来具体说,就是现在要求payment、price、cutdown_price这三列的平均值,语句df[["payment","price","cutdown_price"]].mean()。

这里还有一个点需要注意,就是我们通过单列统计返回的是一个值,但是通过多列统计时返回的不是多个值,而是一个Series,如上图。
2.2 mean()函数
前面已经给大家举了不少例子了,相信大家已经知道怎么使用mean()函数了,这里就不再做过多的讲解了。
2.3 round()函数
我们在算出某一列的平均值后,会发现,结果有很长的小数位,这样很不美观,也不利于我们后续的其他处理,因此我们希望能够取整,这时就用到了round()取整函数。
round()函数经常和mean()函数一起出现,它的用法也很灵活,一般来说,是三种情况。

round()的括号里面可以有四种状态。当round()括号里面是正整数时,表示保留到该数的小数点后几位。当round()口号里面是负数时,表示保留到小数点前几位,比如-1就是保留到十位,-2就是保留到百位。当round()括号里是0、或者什么都没有时,表示保留到个位,也就是取整。
它的语句也很简单,我们先用mean()函数求出某一列的平均值,然后将该值赋值给一个变量,接着用round()函数给这个变量做取整操作,语句pay=df["payment"].mean() print(pay.round())。
上面是如果遇到的是单列统计返回一个平均值的情况,那如果是多列统计呢,返回的平均值的Series我们又应该怎么进行round操作呢。
其实很简单,和上面一样,只不过前面的mean函数变了一下,语句pay=df[["payment","price","cutdown_price"]].mean() print(pay.round())。
2.4 max()函数
因为前面我们已经相当于很详细的介绍了两个函数,后面的统计函数的用法和格式都差不多,因此不再详细讲解,只给大家大体说一下,相信同学们会理解应用的很好的。
max()函数是取最大值。现在我们有名为df的数据表,想要求得列名为pay的最大值,语句df["pay"].max()即可。
2.5 min()函数
min()函数是取最小值。同上面的例子,求最小值,语句df["pay"].min()即可。
2.6 sum()函数
sum()函数是求和。也是同样的道理,求这列的和,语句df["pay"].sum()即可。
2.6 count()函数
count()函数求个数。现在我有名为df的数据表,想要求列名为pay的这一列有多少个值,语句df["pay"].count()即可。
2.7 median()函数
median()函数求中位数。同上面,求这列中位数,语句df["pay"].median()即可。
这篇的内容就到这里,我们下篇再见。

展示您要展示的活动信息
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)