
Python数据分析
Python数据分析简介
核心工具库
NumPy(Numerical Python)
Python中专注于快速数组运算的高性能科学计算库。
核心特性:
- 强大的N维数组对象ndarray
- 高效的广播功能
- 支持与C/C++/Fortran代码的无缝集成
- 提供线性代数、傅里叶变换、随机数生成等数学功能
Pandas
基于NumPy构建的结构化数据分析工具。
主要优势:
- 高性能数据处理(依赖NumPy的矩阵运算)
- 完善的数据清洗和分析功能
- 两大核心数据结构:
- Series:一维标签化数组
- DataFrame:二维表格型数据结构
数据可视化工具
Matplotlib
Python生态系统中最常用的开源数据可视化库,支持创建:
- 静态图表
- 动态可视化
- 交互式图形展示
Seaborn
基于Matplotlib构建的数据可视化库,特点:
- 集成pandas数据结构
- 提供更简洁的API
- 绘制信息更丰富、更具吸引力的图像
- 与Pandas配合使用比直接使用Matplotlib更方便
机器学习工具
Scikit-learn
基于Python的机器学习工具:
- 简单高效的数据挖掘和数据分析工具
- 可重复用于各种环境
- 建立在NumPy、SciPy和Matplotlib之上
开发环境
Jupyter Notebook/Lab
数据分析的首选开发环境,可以:
- 创建和共享代码、公式、可视化图表、笔记文档
主要用途
- 数据清理和转换
- 数值模拟
- 统计分析
- 数据可视化
- 机器学习
Python数据分析环境搭建
Anaconda简介
最流行的数据分析平台,特点:
- 附带大量常用数据科学包
- 基于conda(包管理器和环境管理器)
- 提供虚拟环境管理工具
包管理功能
安装包命令:
conda install 包名
pip install 包名
pip install 包名 -i https://mirrors.aliyun.com/pypi/simple/ # 通过阿里云镜像安装
虚拟环境作用
- 解决开源库版本升级导致的API兼容性问题
- 隔离不同Python版本和库版本
- 支持不同版本代码在不同环境中运行
Jupyter Notebook使用指南
启动方式
conda activate 虚拟环境名
jupyter notebook
基本概念
- Cell:代码输入框和输出显示区域
- 命令模式(按ESC进入):
- Y:切换到Code模式
- M:切换到Markdown模式
- A:上方添加cell
- B:下方添加cell
- 双击D:删除当前cell
- Shift+Enter:执行并跳转下一单元
- Ctrl+Enter:执行并停留当前单元
- 标记说明:
- *:表示代码正在运行
Markdown编辑
在命令模式中按M进入Markdown编辑模式,可使用Markdown语法添加格式化的说明文字。
NumPy
NumPy是Python数据分析中不可或缺的核心库
作为Python科学计算的基础包,NumPy有效提升了Python的运算性能,并提供了精确的数据类型系统,使其能够构建复杂的数据结构。该库由C语言开发,被众多科学计算工具作为底层依赖,因此掌握NumPy数据类型对Python数据分析至关重要。
NumPy专注于数值计算,主要提供高效的多维数组(矩阵)处理功能。相比Python原生列表结构,NumPy数组在存储和处理大型矩阵时具有显著性能优势。
核心功能包括:
- 为高性能科学计算和数据分析提供基础支持
- ndarray多维数组支持矢量化运算,兼具高效性和内存优化
- 提供矩阵运算能力,无需循环即可实现类似Matlab的矢量操作
- 包含磁盘数据读写和内存映射文件操作工具
NumPy的核心数据结构是ndarray(通常简称为数组),具有以下关键属性:
- ndarray.ndim:数组维度数
- ndarray.shape:各维度大小的元组(如2×3矩阵的shape为(2,3))
- ndarray.size:数组元素总数
- ndarray.dtype:元素数据类型
- ndarray.itemsize:单个元素占用的字节数
ndarray
NumPy 提供了 ndarray 这一 N 维数组类型,用于存储相同类型的数据集合。相比 Python 的嵌套列表,ndarray 在存储效率和 I/O 性能上具有显著优势,且数据规模越大优势越明显。
ndarray 的主要特点:
- 内置并行计算功能,能自动利用多核处理器
- 底层采用 C 语言实现,不受 Python GIL 限制
- 操作效率远高于纯 Python 代码
ndarray 属性
| 属性名称 | 说明 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维度数 |
| ndarray.size | 数组元素总数 |
| ndarray.itemsize | 单个元素占用的字节数 |
| ndarray.dtype | 数组元素类型 |
数组形状示例
>>> a = np.array([[1,2,3],[4,5,6]]) # 二维数组 (2, 3)
>>> b = np.array([1,2,3,4]) # 一维数组 (4,)
>>> c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]]) # 三维数组 (2, 2, 3)
二维数组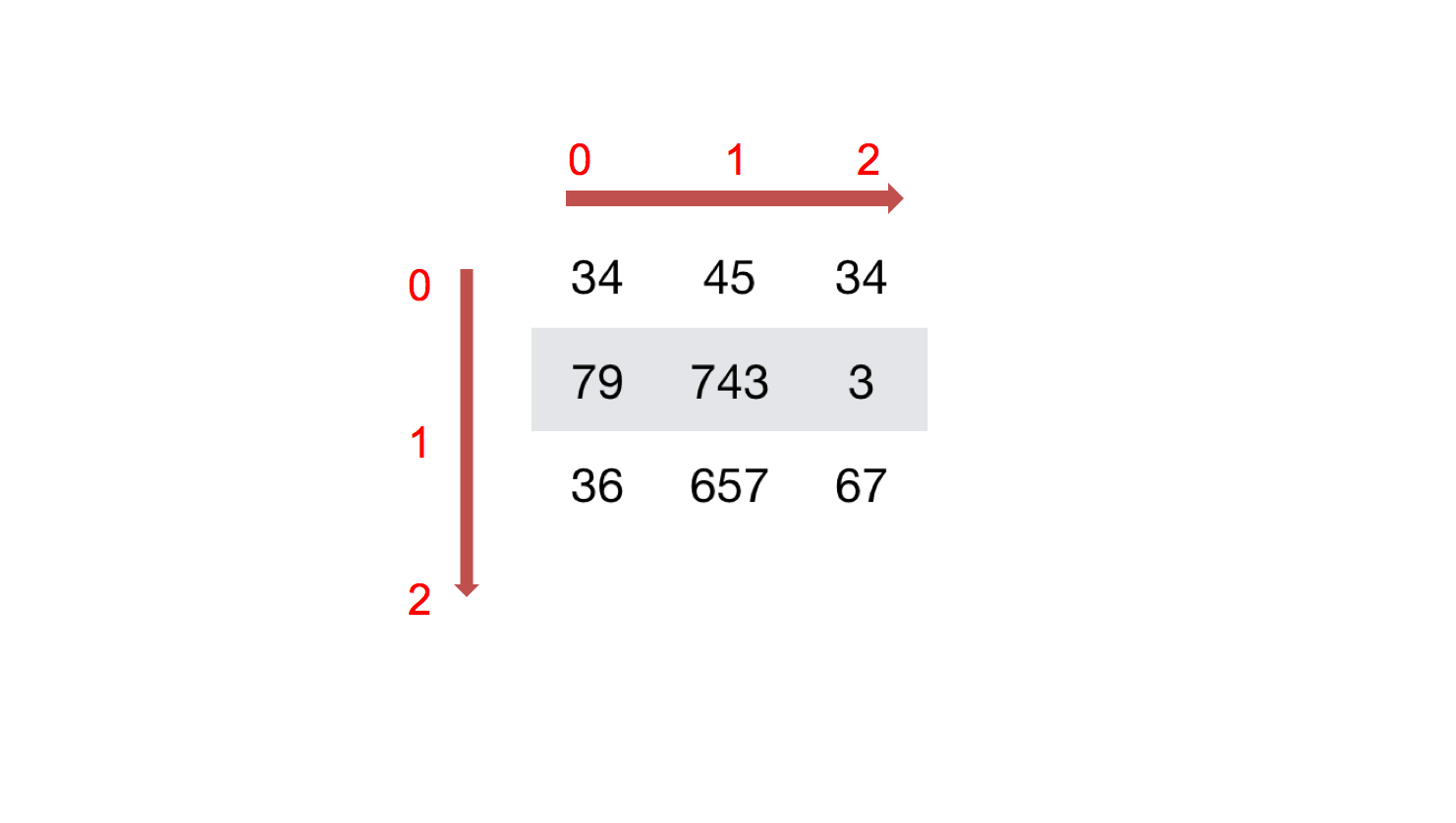
三维数组
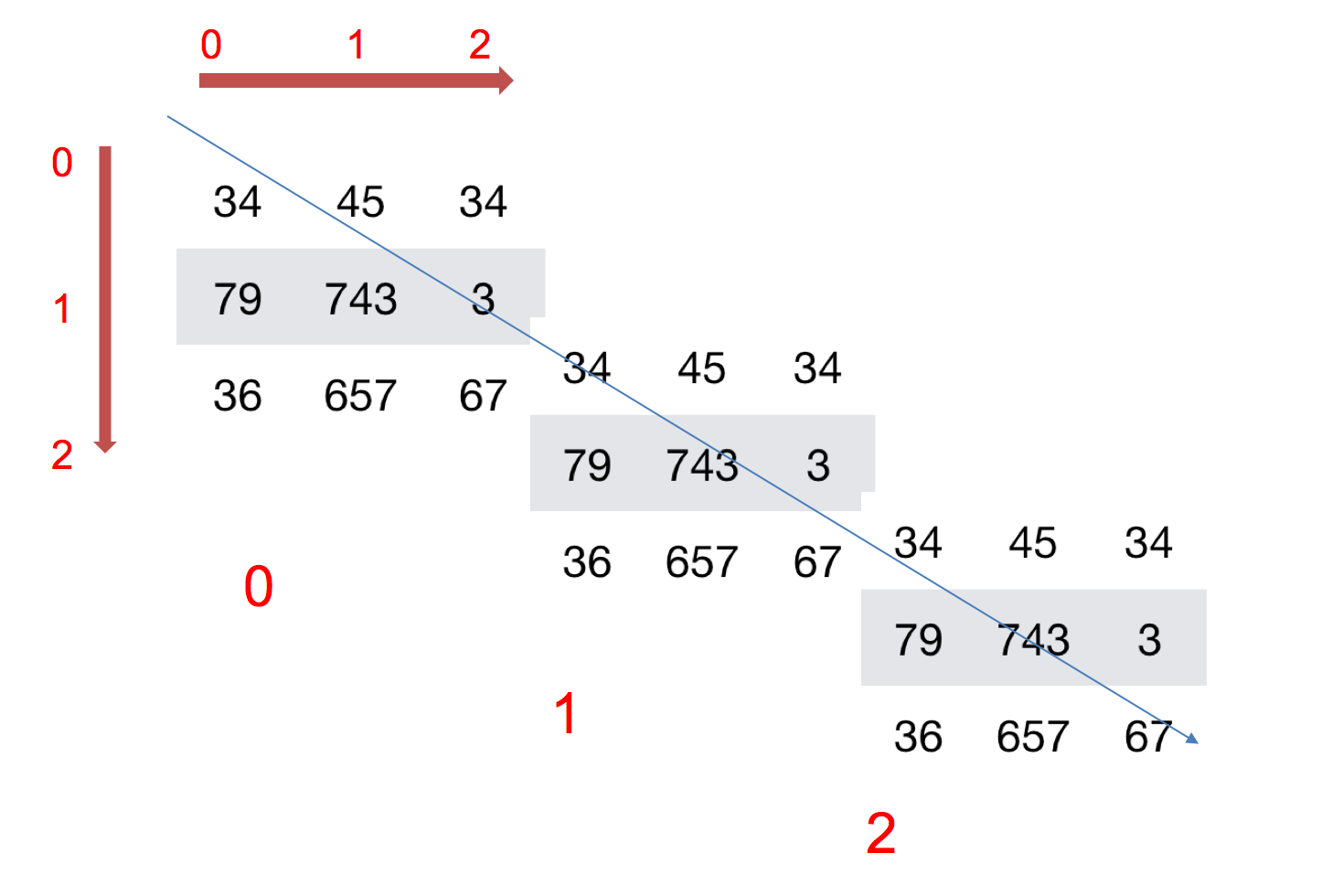
数据类型
ndarray 支持多种数据类型,通过 dtype 指定:
| 类型名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 布尔类型 (True/False) | 'b' |
| np.int8 | 8位整数 (-128~127) | 'i' |
| np.int16 | 16位整数 (-32768~32767) | 'i2' |
| np.int32 | 32位整数 | 'i4' |
| np.int64 | 64位整数 | 'i8' |
| np.uint8 | 无符号8位整数 (0~255) | 'u' |
| np.uint16 | 无符号16位整数 (0~65535) | 'u2' |
| np.uint32 | 无符号32位整数 | 'u4' |
| np.uint64 | 无符号64位整数 | 'u8' |
| np.float16 | 半精度浮点数 (16位) | 'f2' |
| np.float32 | 单精度浮点数 (32位) | 'f4' |
| np.float64 | 双精度浮点数 (64位) | 'f8' |
| np.complex64 | 64位复数 | 'c8' |
| np.complex128 | 128位复数 | 'c16' |
| np.object_ | Python对象 | 'O' |
| np.string_ | 字符串 | 'S' |
| np.unicode_ | Unicode字符串 | 'U' |
np.int32:32位整数,是最常用的整数类型,适用于大多数整数运算。
np.float64:64位浮点数,是默认的浮点数类型,广泛用于科学计算。
np.bool_:布尔类型,用于表示True或False,常用于条件判断和逻辑操作。
np.string_/np.unicode_:定长字符串类型,常用于二进制数据 或 多语言文本数据
np.object_:用于存储任意Python对象,特别是在处理混合类型数据或需要灵活性的时候。
np.string_只支持ASCII编码,不支持Unicode,而np.unicode_支持Unicode字符。
np.string_更适合处理旧有的二进制数据,而np.unicode_更适合处理现代文本数据。
数组的基本属性
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.dtype | 数组元素的类型 |
基本操作
1 生成数组的方法
1.1 生成0和1的数组
np.ones(shape, dtype)np.ones_like(a, dtype):创建与数组a形状相同且元素全为1的数组np.zeros(shape, dtype)np.zeros_like(a, dtype):创建与数组a形状相同且元素全为0的数组
示例:
ones = np.ones([4,8])
print(ones)
# [[1. 1. 1. 1. 1. 1. 1. 1.]
# [1. 1. 1. 1. 1. 1. 1. 1.]
# [1. 1. 1. 1. 1. 1. 1. 1.]
# [1. 1. 1. 1. 1. 1. 1. 1.]]
print(np.zeros_like(ones))
# [[0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0.]]
1.2 从现有数组生成
1.2.1 生成方式
np.array(object, dtype)np.asarray(a, dtype)
示例:
a = np.array([[1,2,3],[4,5,6]])
a1 = np.array(a) # 创建新数组
a2 = np.asarray(a) # 类似索引,不创建新数组
1.3 生成随机数组
使用np.random模块:
# 生成[0.0,1.0)的随机浮点数
rand_num = np.random.rand()
print("随机浮点数:", rand_num)
# 生成3x2的随机数组
rand_array = np.random.rand(3, 2)
print("随机数组:\n", rand_array)
2 数组的索引和切片
索引规则:
- 一维数组:直接索引
- 二维数组:[行,列]
- 三维数组:[深度,行,列]
示例:
# 二维数组示例
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("第1行第2列:", arr[0, 1]) # 2
print("第2行第3列:", arr[1, 2]) # 6
# 切片操作
arr = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
print("第1-2行:\n", arr[0:2, :])
print("第2-3列:\n", arr[:, 1:3])
print("第1行第2-3列:", arr[0, 1:3])
# 三维数组示例
a1 = np.array([[[1,2,3],[4,5,6]], [[12,3,34],[5,6,7]]])
print(a1[0, 0, 1]) # 2
3 形状修改
3.1 ndarray.reshape(shape, order)
返回新形状的视图,不改变行列顺序:
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
reshaped = arr.reshape(3, 3)
print("reshape后:\n", reshaped)
3.2 ndarray.resize(new_shape)
修改数组本身形状(元素数量需相同):
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
resized = np.resize(arr, (2, 5))
print("resize后:\n", resized)
3.3 ndarray.T
数组转置(行列互换):
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("转置后:\n", arr.T)
4 类型修改
4.1 ndarray.astype(type)
返回类型修改后的数组:
arr = np.array([1.1, 2.2, 3.3, 4.4, 5.5])
arr_int = arr.astype(np.int32)
print("转换后:", arr_int)
4.2 ndarray.tobytes([order])
生成包含原始数据字节的Python字节:
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[12, 3, 34], [5, 6, 7]]])
print(arr.tobytes())
5 数组去重
5.1 np.unique()
temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
print(np.unique(temp)) # [1 2 3 4 5 6]
6 ndarray运算
# 生成10名同学5门课成绩
scores = np.random.randint(0, 101, size=(10, 5))
# 取最后4名同学成绩
scores_last4 = scores[-4:, :]
print("最后4名成绩:\n", scores_last4)
# 判断是否大于60
print("是否大于60:\n", scores_last4 > 60)
# 判断前两名是否全及格
print("前两名是否全及格:", np.all(scores[0:2, :] > 60))
# 判断前两名是否有大于90
print("前两名是否有大于90:", np.any(scores[0:2, :] > 80))
# 三元运算
temp = scores[:4, :4]
print("大于60置1否则0:\n", np.where(temp > 60, 1, 0))
7统计运算
- 在数据挖掘和机器学习中,统计指标是数据分析的重要工具。以下是常用的统计运算方法:
- min(a, axis) 计算数组的最小值或沿指定轴的最小值
- max(a, axis) 计算数组的最大值或沿指定轴的最大值
- median(a, axis) 计算沿指定轴的中位数
- mean(a, axis, dtype) 计算沿指定轴的算术平均值
- std(a, axis, dtype) 计算沿指定轴的标准差
- var(a, axis, dtype) 计算沿指定轴的方差
pandas
Pandas框架概述
- Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
- Pandas在数据处理上具有独特的优势:
- 底层是基于Numpy构建的,所以运行速度特别的快
- 有专门的处理缺失数据的API
- 强大而灵活的分组、聚合、转换功能
适用场景:
- 数据量大到Excel严重卡顿,且又都是单机数据的时候,我们使用Pandas
- Pandas用于处理单机数据(小数据集(相对于大数据来说))
- 在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用Pandas
安装Pandas
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pandas

2- 创建python脚本, 导入pandas库
import pandas as pd
3df = pd.read_csv('./1960-2019全球GDP数据.csv', encoding='gbk')
# 设置显示的最大行数和列数为None
pd.set_option('display.max_rows', None) pd.set_option('display.max_columns', None)Python Pandas的作用:(清洗、处理、分析数据)
二、Pandas数据结构与数据类型
- DataFrame
- Series
- 索引列
- 索引名、索引值
- 索引下标、行号
- 数据列
- 列名
- 列值,具体的数据
- 索引列
- Series
其中最核心的就是Pandas中的两个数据结构:DataFrame和Series
Series对象
Series也是Pandas中的最基本的数据结构对象,下文中简称s对象;是DataFrame的列对象,series本身也具有索引。
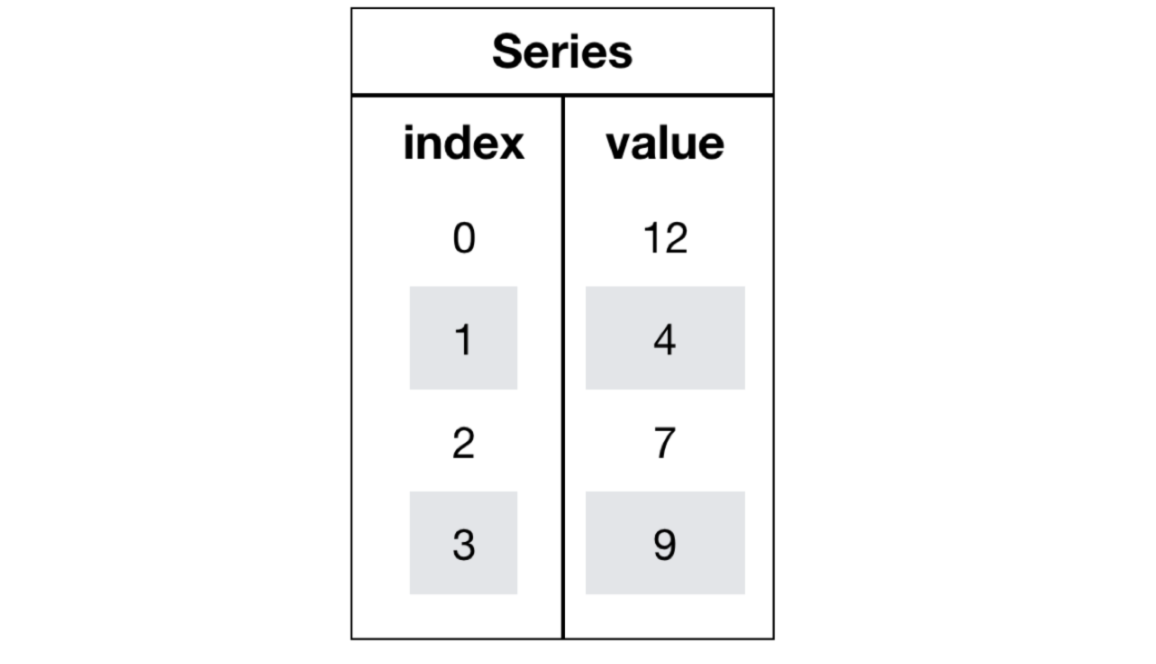
- values:一组数据(numpy.ndarray类型)
- index:相关的数据索引标签;如果没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
创建Series对象
- 1- 导入pandas
- 2- 通过list列表来创建
-
import pandas as pd s2 = pd.Series([1, 2, 3]) print(s2) # 自定义索引 s3 = pd.Series([1, 2, 3], index=['A', 'B', 'C']) print(s3) 0 1 1 2 2 3 dtype: int64 A 1 B 2 C 3 dtype: int64
DataFrame
创建DataFrame对象
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
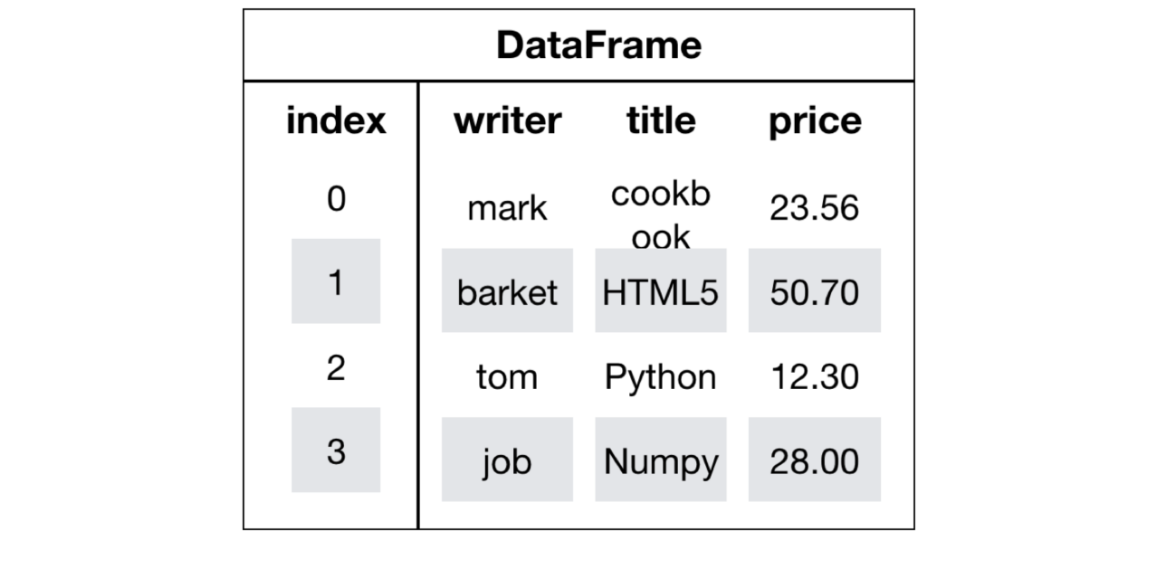
-
df1_data = { '日期': ['2021-08-21', '2021-08-22', '2021-08-23'], '温度': [25, 26, 50], '湿度': [81, 50, 56] } df1 = pd.DataFrame(data=df1_data) df1 # 返回结果如下 日期 温度 湿度 0 2021-08-21 25 81 1 2021-08-22 26 50 2 2021-08-23 50 56
DataFrame对象属性
- 1- shape属性
-
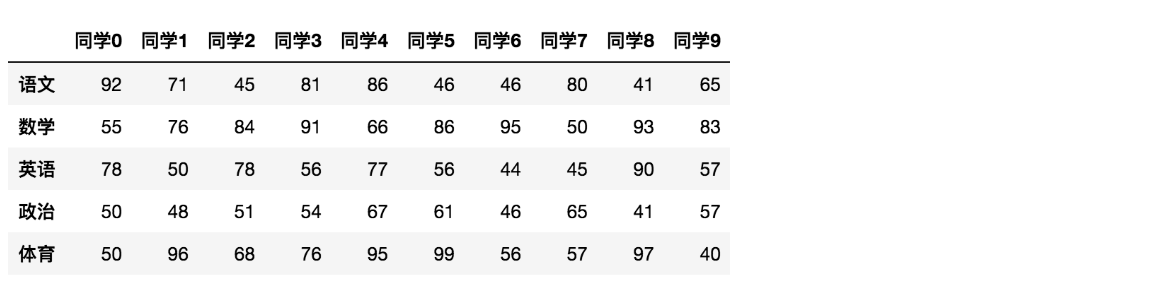
data.shape # 结果 (10, 5) - 2- index属性
-
data.index # 结果 Index(['同学0', '同学1', '同学2', '同学3', '同学4', '同学5', '同学6', '同学7', '同学8', '同学9'], dtype='object')
- 3- columns
-
data.columns # 结果 Index(['语文', '数学', '英语', '政治', '体育'], dtype='object')
- 4- values
-
data.values array([[92, 55, 78, 50, 50], [71, 76, 50, 48, 96], [45, 84, 78, 51, 68], [81, 91, 56, 54, 76], [86, 66, 77, 67, 95], [46, 86, 56, 61, 99], [46, 95, 44, 46, 56], [80, 50, 45, 65, 57], [41, 93, 90, 41, 97], [65, 83, 57, 57, 40]])
- 5- T
DataFrame对象方法
1- head(n)
显示前n行内容
data.head(5)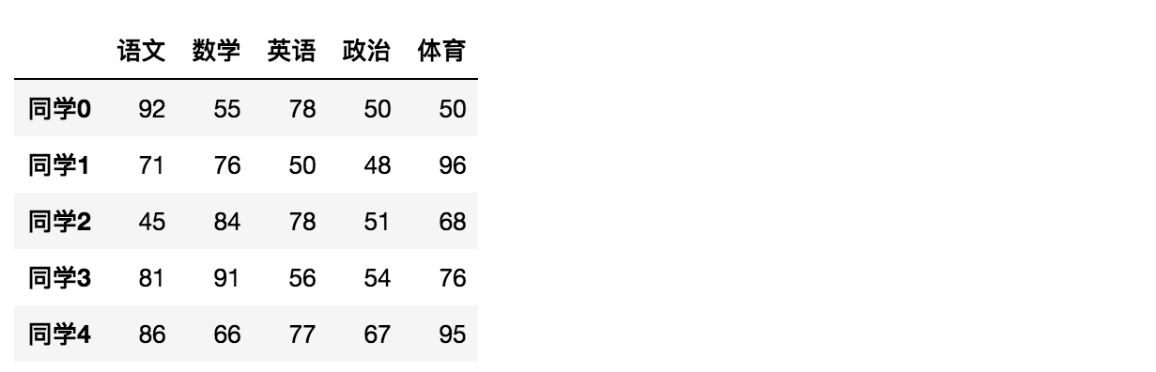
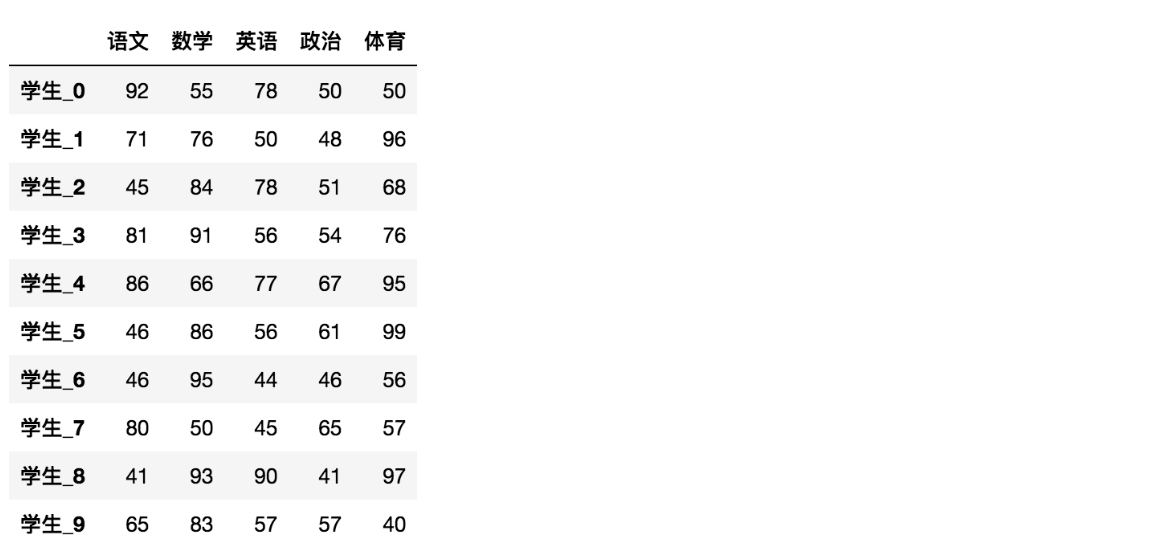
tail(n)如果不补充参数,默认5行。填入参数n则显示后n行
Pandas的数据类型
df或s对象中具体每一个值的数据类型有很多,如下表所示
| Pandas数据类型 | 说明 | 对应的Python类型 |
|---|---|---|
| Object | 字符串类型 | string |
| int | 整数类型 | int |
| float | 浮点数类型 | float |
| datetime | 日期时间类型 | datetime包中的datetime类型 |
| timedelta | 时间差类型 | datetime包中的timedelta类型 |
| category | 分类类型 | 无原生类型,可以自定义 |
| bool | 布尔类型 | bool(True,False) |
| nan | 空值类型 | None |
总结
- series【知道】
- 创建
- pd.Series([], index=[])
- pd.Series({})
- 属性
- 对象.index
- 对象.values
- 创建
- DataFrame【掌握】
- 创建
- pd.DataFrame(data=None, index=None, columns=None)
- 属性
- shape -- 形状
- index -- 行索引
- columns -- 列索引
- values -- 查看值
- T -- 转置
- head() -- 查看头部内容
- tail() -- 查看尾部内容
- DataFrame索引
- 修改的时候,需要进行全局修改
- 对象.reset_index()
- 对象.set_index(keys)
Pandas基本数据操作
数据集
为了更好的理解这些基本操作,我们将读取一个真实的股票数据。关于文件操作,后面在介绍,这里只先用一下API
# 读取文件
data = pd.read_csv("./data/stock_day.csv")
# 删除一些列,让数据更简单些,再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)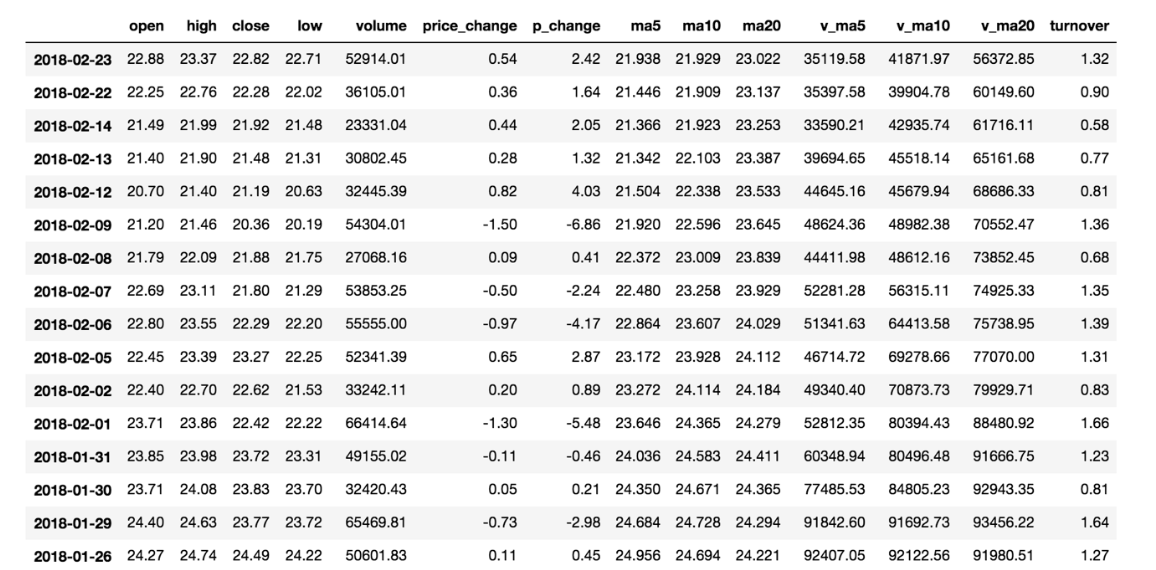
索引操作
# 直接使用行列索引名字的方式(先列后行)
data['open']['2018-02-27']
23.53赋值操作
# 直接修改原来的值
data['close'] = 1
# 或者
data.close = 1排序操作
排序有两种形式,一种对于索引进行排序,一种对于内容进行排序
DataFrame排序
- 使用df.sort_values(by=, ascending=)
- 单个键或者多个键进行排序,
- 参数:
- by:指定排序参考的键
- ascending:默认升序
- ascending=False:降序
- ascending=True:升序
# 按照开盘价大小进行排序 , 使用ascending指定按照大小排序
data.sort_values(by="open", ascending=True).head()
# 按照多个键进行排序
data.sort_values(by=['open', 'high'])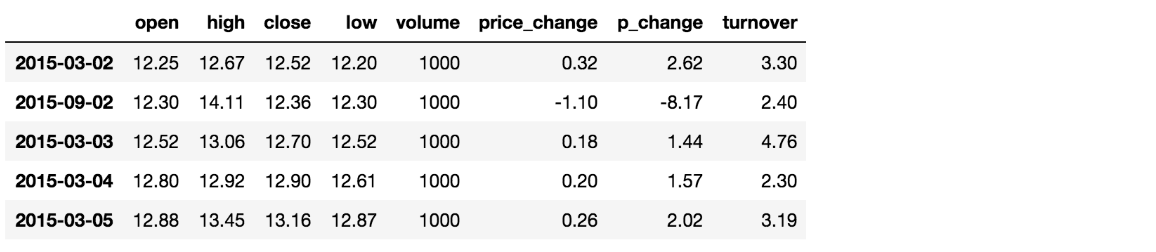
- 使用df.sort_index给索引进行排序
-
# 对索引进行排序 data.sort_index()
Series排序
data['p_change'].sort_values(ascending=True).head()
2015-09-01 -10.03
2015-09-14 -10.02
2016-01-11 -10.02
2015-07-15 -10.02
2015-08-26 -10.01
Name: p_change, dtype: float64- 1.索引【掌握】
- 直接索引 -- 先列后行,是需要通过索引的字符串进行获取
- loc -- 先行后列,是需要通过索引的字符串进行获取
- iloc -- 先行后列,是通过下标进行索引
- 2.赋值【知道】
- data[""] = **
- data. =
- 3.排序【知道】
- dataframe
- 对象.sort_values()
- 对象.sort_index()
- series
- 对象.sort_values()
- 对象.sort_index()
- dataframe
四、DataFrame运算
- 应用add等实现数据间的加、减法运算
- 应用逻辑运算符号实现数据的逻辑筛选
- 应用isin, query实现数据的筛选
- 使用describe完成综合统计
- 使用max, min, mean, std完成统计计算
- 使用idxmin、idxmax完成最大值最小值的索引
- 使用cumsum等实现累计分析
- 应用apply函数实现数据的自定义处理
算法运算
- add(other)
比如进行数学运算加上具体的一个数字
data['open'].add(1)
2018-02-27 24.53
2018-02-26 23.80
2018-02-23 23.88
2018-02-22 23.25
2018-02-14 22.49- sub(other)
比如进行数学运算减去具体的一个数字
data['open'].sub(1)逻辑运算符
逻辑运算符号
- 例如筛选data["open"] > 23的日期数据
- data["open"] > 23返回逻辑结果
-
data["open"] > 23 2018-02-27 True 2018-02-26 False 2018-02-23 False 2018-02-22 False 2018-02-14 False
- 完成多个逻辑判断,
-
data[(data["open"] > 23) & (data["open"] < 24)].head()
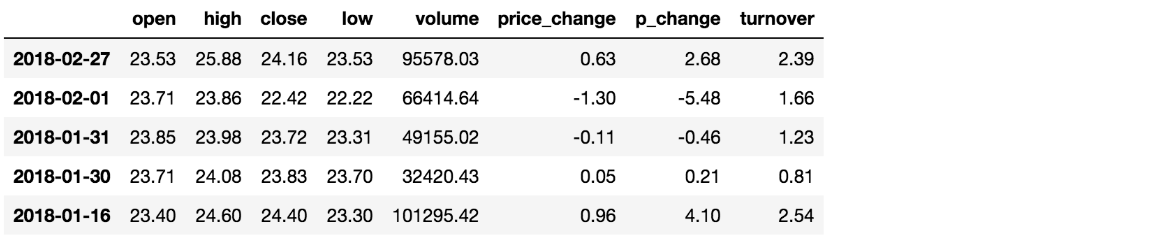
逻辑运算函数
- query(expr)
- expr:查询字符串
通过query使得刚才的过程更加方便简单
data.query("open<24 & open>23").head()
- isin(values)
-
# 可以指定值进行一个判断,从而进行筛选操作 data[data["open"].isin([23.53, 23.85])]
统计运算
describe
综合分析: 能够直接得出很多统计结果,count, mean, std, min, max 等
# 计算平均值、标准差、最大值、最小值
data.describe()Numpy当中已经详细介绍,在这里我们演示min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)结果:
count |
Number of non-NA observations |
|---|---|
sum |
Sum of values |
mean |
Mean of values |
median |
Arithmetic median of values |
min |
Minimum |
max |
Maximum |
mode |
Mode(众数) |
abs |
Absolute Value |
prod |
Product of values(乘积) |
std |
Bessel-corrected sample standard deviation |
var |
Unbiased variance |
idxmax |
compute the index labels with the maximum |
idxmin |
compute the index labels with the minimum |
如果要使用plot函数,需要导入matplotlib.
import matplotlib.pyplot as plt
# plot显示图形
stock_rise.cumsum().plot()
# 需要调用show,才能显示出结果
plt.show()CSV
read_csv
- pandas.read_csv(filepath_or_buffer, sep =',', usecols )
- filepath_or_buffer:文件路径
- sep :分隔符,默认用","隔开
- usecols:指定读取的列名,列表形式
- 举例:读取之前的股票的数据
-
# 读取文件,并且指定只获取'open', 'close'指标 data = pd.read_csv("./data/stock_day.csv", usecols=['open', 'close']) open close 2018-02-27 23.53 24.16 2018-02-26 22.80 23.53 2018-02-23 22.88 22.82 2018-02-22 22.25 22.28 2018-02-14 21.49 21.92
to_csv
- DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode='w', encoding=None)
- path_or_buf :文件路径
- sep :分隔符,默认用","隔开
- columns :选择需要的列索引
- header :boolean or list of string, default True
- index:是否写进行索引,是否写进列索引值
- mode:'w':重写, 'a' 追加
- 举例:保存读取出来的股票数据会生成新的test文件数据
- 保存'open'列的数据,然后读取查看结果
-
# 选取10行数据保存,便于观察数据 data[:10].to_csv("./data/test.csv", columns=['open']) # 读取,查看结果 pd.read_csv("./data/test.csv")
Matplotlib(了解)
-
是专门用于开发2D图表(包括3D图表)
-
以渐进、交互式方式实现数据可视化
- 能将数据进行可视化,更直观的呈现
- 使数据更加客观、更具说服力
matplotlib.pyplot模块
折线图绘制与显示
举例:展现上海一周的天气,比如从星期一到星期日的天气温度如下
import matplotlib.pyplot as plt
# 1.创建画布
plt.figure(figsize=(10, 10), dpi=100)
# 2.绘制折线图
plt.plot([1, 2, 3, 4, 5, 6 ,7], [17,17,18,15,11,11,13])
# 3.显示图像
plt.show()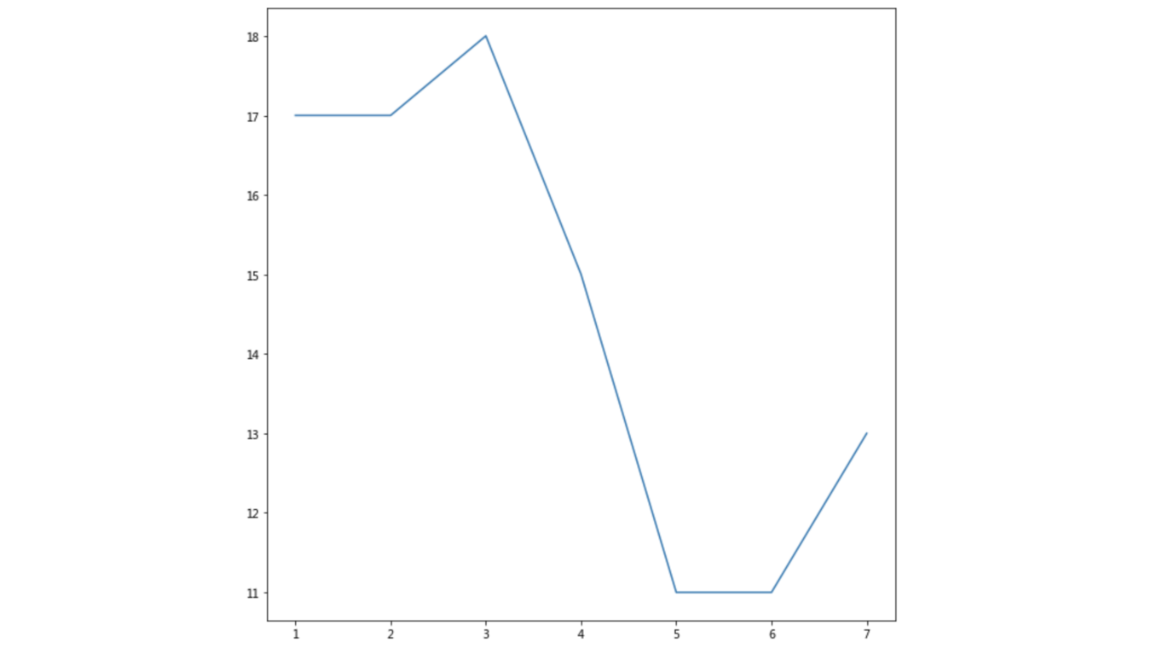
小结
- 什么是matplotlib【了解】
- 是专门用于开发2D(3D)图表的包
- 绘制图像流程【掌握】
- 1.创建画布 -- plt.figure(figsize=(20,8), dpi=100)
- 2.绘制图像 -- plt.plot(x, y)
- 3.显示图像 -- plt.show()
二、Matplotlib基础绘图功能
准备数据并画出初始折线图
import matplotlib.pyplot as plt
import random
# 画出温度变化图
# 0.准备x, y坐标的数据
x = range(60)
y_shanghai = [random.uniform(15, 18) for i in x]
# 1.创建画布 dpi是分辨率 一般80
plt.figure(figsize=(20, 8), dpi=80)
# 2.绘制折线图
plt.plot(x, y_shanghai)
# 3.显示图像
plt.show()添加自定义x,y刻度
-
plt.xticks(x, **kwargs)
x:要显示的刻度值
-
plt.yticks(y, **kwargs)
y:要显示的刻度值
-
# 增加以下两行代码 # 构造x轴刻度标签 x_ticks_label = ["11点{}分".format(i) for i in x] # 构造y轴刻度 y_ticks = range(40) # 修改x,y轴坐标的刻度显示 plt.xticks(x[::5], x_ticks_label[::5]) plt.yticks(y_ticks[::5])
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
plt.grid(True, linestyle='--', alpha=0.5)
plt.xlabel("时间")
plt.ylabel("温度")
plt.title("中午11点0分到12点之间的温度变化图示", fontsize=20)
plt.show()
图片保存
# 保存图片到指定路径
plt.savefig("test.png")- 注意:plt.show()会释放figure资源,如果在显示图像之后保存图片将只能保存空图片。
在一个坐标系中绘制多个图像
需求:再添加一个城市的温度变化
收集到北京当天温度变化情况,温度在1度到3度。怎么去添加另一个在同一坐标系当中的不同图形,其实很简单只需要再次plot即可,但是需要区分线条,如下显示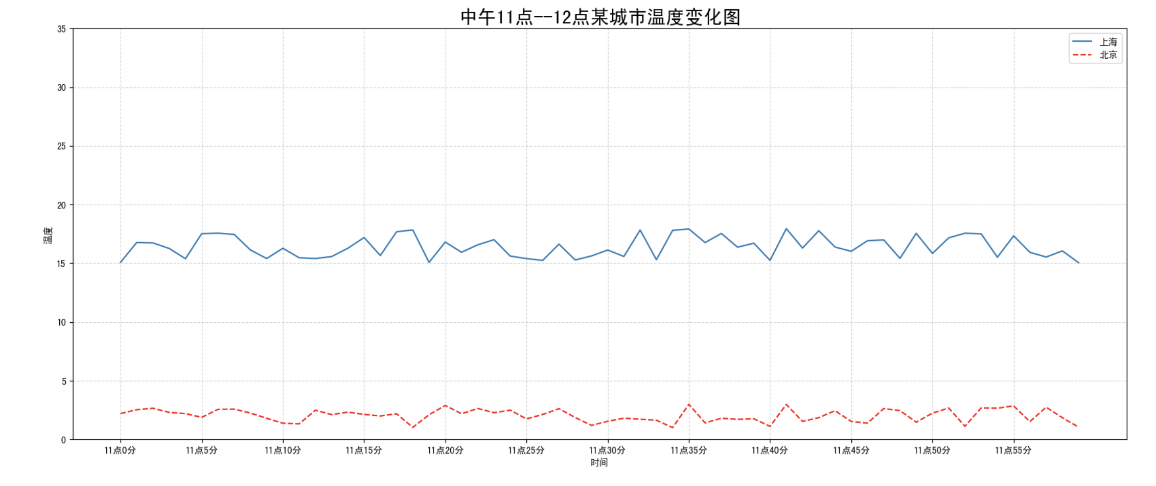
# 增加北京的温度数据
y_beijing = [random.uniform(1, 3) for i in x]
# 绘制折线图
plt.plot(x, y_shanghai)
# 使用多次plot可以画多个折线
plt.plot(x, y_beijing, color='r', linestyle='--')显示图例
- 注意:如果只在plt.plot()中设置label还不能最终显示出图例,还需要通过plt.legend()将图例显示出来。
-
# 绘制折线图 plt.plot(x, y_shanghai, label="上海") # 使用多次plot可以画多个折线 plt.plot(x, y_beijing, color='r', linestyle='--', label="北京") # 显示图例 plt.legend(loc="best")
常见图形种类及意义
柱形图
**柱状图:**排列在工作表的列或行中的数据可以绘制到柱状图中。
特点:绘制连离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计/对比)
api:plt.bar(x, width, align='center', **kwargs)
饼图
-
**饼图:**用于表示不同分类的占比情况,通过弧度大小来对比各种分类。
特点:分类数据的占比情况(占比)
api:plt.pie(x, labels=,autopct=,colors)
散点图
**散点图:**用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
特点:判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
api:plt.scatter(x, y)
柱形图绘制
categories = ['A', 'B', 'C', 'D']
values = [3, 7, 5, 4]
plt.bar(categories, values, color='blue') # 绘制蓝色柱状图
plt.title("Simple Bar Chart") # 设置图表标题
plt.xlabel("Categories") # 设置X轴标签
plt.ylabel("Values") # 设置Y轴标签
plt.show() # 显示图表饼图
sizes = [25, 35, 25, 15]
labels = ['Category A', 'Category B', 'Category C', 'Category D']
plt.pie(sizes, labels=labels, autopct='%1.1f%%') # 绘制饼图,显示百分比
plt.title("Simple Pie Chart") # 设置图表标题
plt.show() # 显示图表散点图绘制
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
plt.scatter(x, y, color='red') # 绘制红色散点图
plt.title("Simple Scatter Plot") # 设置图表标题
plt.xlabel("X-axis") # 设置X轴标签
plt.ylabel("Y-axis") # 设
展示您要展示的活动信息
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)