
Asking like Socrates: Socrates helps VLMs understand remote sensing images
本文提出RS-EoT(遥感证据-思维)方法,通过"证据驱动推理"范式解决遥感图像理解中的伪推理问题。该方法采用两阶段训练:先用Socratic Agent合成多轮取证轨迹数据进行SFT冷启动,再通过渐进式强化学习(先定位后问答)提升模型性能。Socratic Agent由文本推理、视觉感知和质量验证三部分组成,生成细粒度证据链。强化学习阶段先训练目标定位能力,再通过重构多选题方
RS-EoT:让大模型在遥感图像中像专家一样逐步验证每个细节
提出了一个面向遥感图像理解的“证据驱动推理”范式 RS-EoT(Evidence-of-Thought),用苏格拉底式自博弈Agent合成数据(SFT 冷启动)+ 两阶段渐进 RL(先定位再问答)
一、问题背景
将多模态Deepseek-R1 风格长链推理(SFT+RL)方法直接搬到遥感 VLM 上,经常出现 pseudo reasoning(伪推理)。
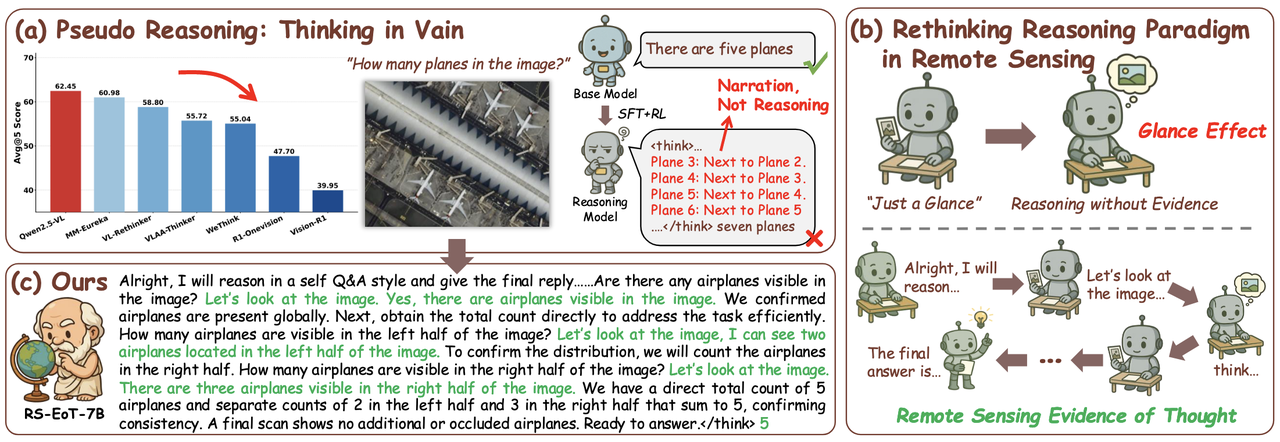
核心问题:
-
遥感图像:范围大、尺度跨度大、目标小而稀疏、背景复杂
-
但很多推理式 VLM:只做一次粗略全局感知,然后语言开始自洽展开 → 容易把“叙述流程”当“推理”
提出方法:
RS-EoT = Remote Sensing Evidence-of-Thought(遥感证据-思维)
-
CoT(Chain-of-Thought) 强调“把推理过程写出来”
-
RS-EoT 强调“推理过程中每一步都要回到图像取证”,即 语言推理 ↔ 视觉核验 的动态循环
二、总体框架
整体方法训练路线分为两段式:
-
SFT 冷启动:用 SocraticAgent 合成 RS-EoT 多轮迭代取证轨迹
-
Progressive RL:
-
Stage 1 RL-Grounding:用 IoU 可验证奖励,先把“找证据/定位”练扎实
-
Stage 2 RL-VQA:再把能力泛化到遥感 VQA,但通过“多选重构 + 对称奖励”避免 reward hacking
SocraticAgent
现成遥感 VQA 数据大多只有“问题-答案”,缺少EoT需要的“中间如何取证”的过程;直接 RL 很容易奖励投机(reward hacking)。因此设计SocraticAgent用于生成EoT训练数据,合成一种“像苏格拉底一样逐步发问”的轨迹,让模型推理变成由粗到细的证据收集过程。 SocraticAgent分为Reasoner、Perceiver、Verifier三个部分。
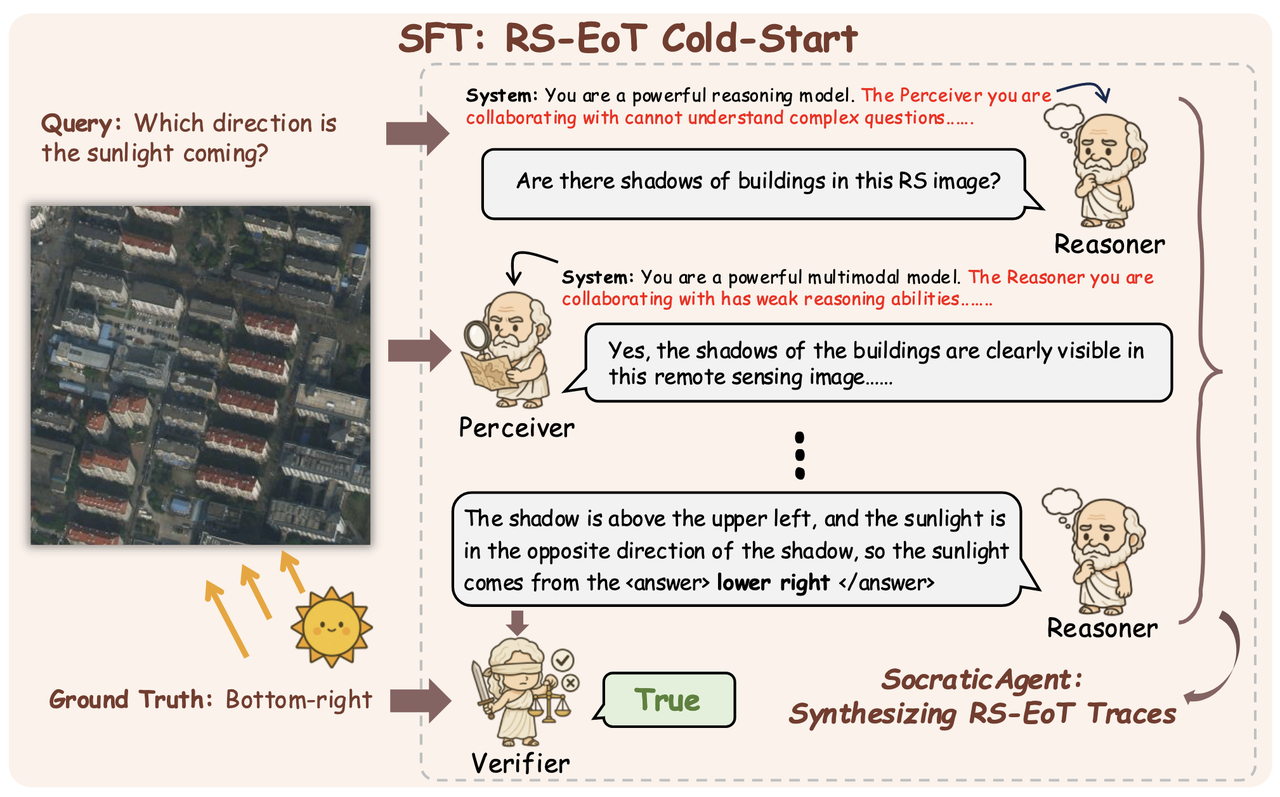
Reasoner(文本推理):只看文本 query 和元信息,不看图;负责拆解问题、提出下一步“可感知的原子问题”。论文使用 GPT-5-mini。
Perceiver(视觉感知):只看图 + Reasoner 的问题,不看原始任务问题;只回答“能从图中直接读出的事实”。论文用 Gemini-2.5-flash。
Verifier(质量门控):检查 Reasoner 最终答案是否和 GT 一致,只保留答对的记录。论文用 doubao-seed-1.6-thinking。
Self-play prompt 约束:
-
告诉 Reasoner:“Perceiver 看不懂复杂问题” → 约束它把问题拆成简单增量问题
-
告诉 Perceiver:“Reasoner 推理很弱” → 约束它回答更短、更直接、不输出高层推理
最终合成一个多模态数据集 RS-EoT-4K(RGB/红外/SAR),并把多轮对话按模板拼接成 self-QA 风格的 <think> ... </think> 轨迹,用来 SFT 训练Qwen2.5-VL-7B。
强化学习
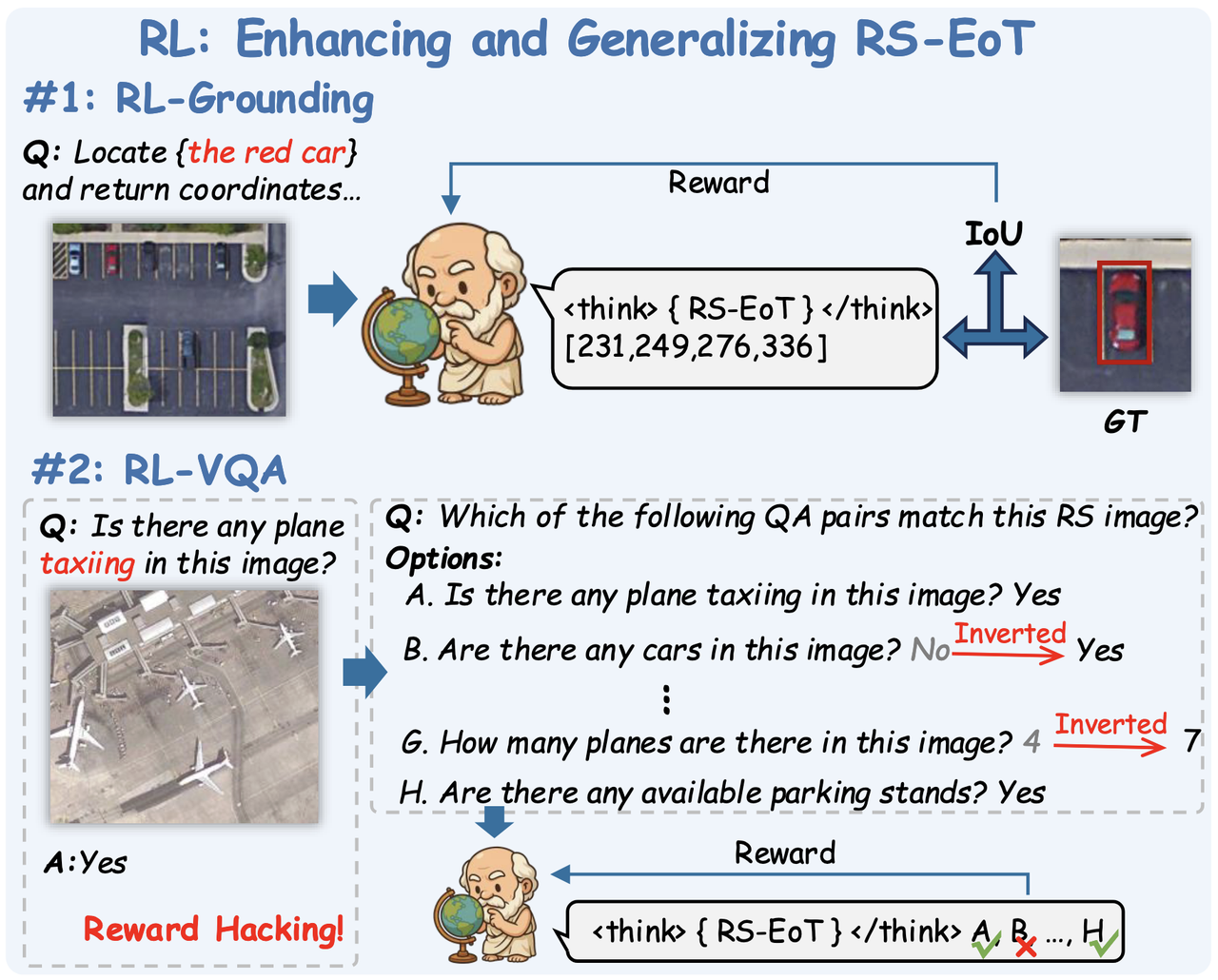
Stage 1:RL-Grounding(IoU 直接做奖励)
强化模型对局部目标与证据的理解与定位能力
Stage 2:把 VQA 重构成 MCQ
把简单 QA 变成必须逐条核验的任务
-
对每张图收集一个 QA 集合 {(Qi, Ai)}m,通常 10 < m < 15
-
随机挑 n 条把答案“翻转/扰动”制造错误选项(Yes↔No 或数值±随机整数)
-
构造多选题:“Which of the following QA pairs match this remote sensing image?”
奖励函数:option-level 对称准确率(symmetric accuracy reward):
-
选对正确选项、正确拒绝错误选项,都给正向信号
-
选错或漏选不给分
-
它提供稳定、细粒度的训练信号,并迫使模型逐项对照图像证据。

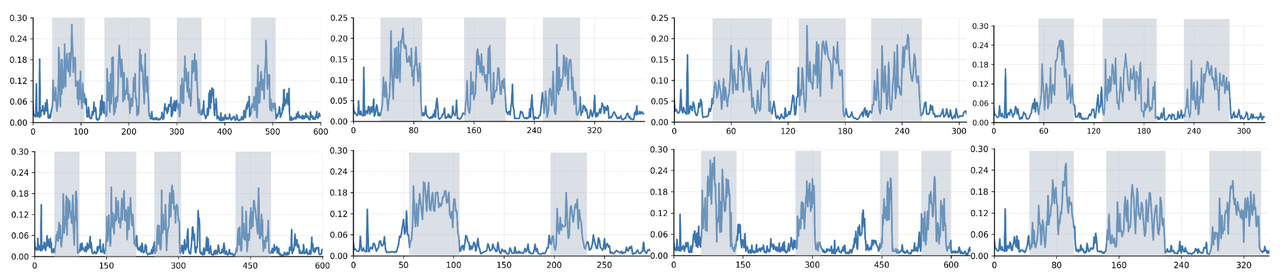
推理时输出的token对于图像内容的注意力分析
Agent生成训练数据时的一些指令细节:




中科创新烁智(CSCITech)
更多推荐
 13
13 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)