检测 AMI 以在 CloudWatch 上监控 GPU
如果您之前在 AWS 上使用过预置实例,您就会知道监控的默认指标是有限的。您只能访问 CPU 利用率、网络传输率和磁盘读/写。默认情况下,您没有监控一些基本信息,例如 RAM 和文件系统使用情况(这可能是防止实例因资源不足而发生故障的宝贵信息)。
对于 GPU 加速的应用程序(如机器学习应用程序),这个问题会更进一步,因为您也无法访问 GPU 指标,这对于保证系统的可靠性至关重要(例如,总 GPU 内存消耗会导致在 GPU 上运行的任何应用程序崩溃)。
我创建了一个项目(此处为),展示了我们如何使用 CloudWatch 代理创建一个 AMI,用于 RAM 和文件系统监控,以及一个名为gpumon的自定义服务来收集 GPU 指标并将它们发送到 AWS CloudWatch。
项目结构
在项目中,我们有两个主要目录,如下所示:
.
├── packer ==> AMI creation
└── tf ==> AMI usage example
进入全屏模式 退出全屏模式
第一个包含使用名为packer的工具创建基于 Amazon Linux 2 的 AMI 所需的所有文件。第二个包含terraform中的基础设施即代码,以使用新创建的 AMI 预置实例以进行测试。
AMI 创建
packer是在 AMI 创建步骤中实现基础架构即代码原则的绝佳工具。它能够使用指定的基本 AMI 配置实例,通过 ssh 运行脚本,启动 AMI 创建过程,然后清理所有内容(例如实例、ebs 卷、ssh 密钥对)。
文件packer/gpu.pkr.hcl包含 AMI 的规范。在那里我们可以找到基础 AMI、用于创建 AMI 的实例、存储配置以及用于配置实例的脚本。
1000c我坐
为了让我的生活更轻松一些,我尝试寻找已经安装了 NVIDIA 驱动程序的 AMI,这样我就不必自己安装了。查看有关安装 NVIDIA 驱动程序](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/install-nvidia-driver.html#preinstalled-nvidia-driver)的[AWS 文档,我们可以看到市场上已经有预装 NVIDIA 驱动程序的 AMI 选项。在这些选项中,我们将使用Amazon Linux 2,因为它已经附带了 AWS Systems Manager 代理,我们将在后面使用它。
几点注意事项:
-
您无需订阅市场产品即可访问当前选择的 AMI。但是,您需要订阅才能访问新版本的 AMI ID。
-
您将需要一个基于 GPU 的实例来构建 AMI(根据市场产品规范的要求)。我在一个新的 AWS 账户中测试了这个项目,似乎默认限制不允许配置基于 GPU 的实例(G 系列)。如果您的情况也是如此,
packer也会显示错误。如果是,您可以在此处请求增加限制。
CloudWatch 代理
我们要为基础 AMI 制作的第一个插件是安装和配置 AWS CloudWatch 代理。
AWS 详细记录了代理的安装过程,您可以在此处](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-commandline-fleet.html)中查看其他 Linux 发行版[中的更多详细信息和安装方法。
代理配置由代理读取的.json文件进行,以便了解要监控的指标以及如何在 CloudWatch 上发布它们。您还可以在文档页面上查看有关它的更多信息。
该过程由脚本packer/scripts/install-cloudwatch-agent.sh自动执行。它安装代理并使用文件系统、RAM 和交换使用率等一些相关指标对其进行配置。
请注意,代理配置为以 60 秒的周期发布指标。这可能会产生成本,因为它是经过考虑的详细指标(请转到CloudWatch 定价页面了解更多信息)。
收集 GPU 指标
AWS 已经有文档谈论监控 GPU 使用的方法。关于名为gpumon的工具的简要说明以及关于它的更详细的博客文章。
gpumon是由 AWS 开发的(有点旧的)python 脚本,它利用称为 NVLM(NVIDIA 管理库)的 NVIDIA 库从实例的 GPU 收集指标并将它们发布到 CloudWatch。在这个项目中,脚本变成了systemd单元。脚本本身也进行了修改,以使错误处理更具可读性并正确捕获内存使用情况。
gpumon服务驻留在packer/addons/gpumon中,而install-cloudwatch-gpumon.sh会自动执行安装过程。该服务被配置为在启动时启动 python 脚本并重新启动它由于某种原因停止工作。由于systemd管理该服务,因此可以使用journalctl --unit gpumon看到它的日志。
注意:python 脚本仅在 python2 上测试过,其中已弃用。
pip在您创建 AMI 时在安装过程中发出警告。如果您打算将此脚本用于任何生产工作负载,则应牢记这一点。
关于 GPU 内存使用指标收集
原始脚本从nvmlDeviceGetUtilizationRates()函数中获取 GPU 内存使用情况。我通过一些测试注意到,即使我已将数据加载到 GPU 中,该指标仍为 0。
从NVIDIA 文档这个函数实际上返回正在读/写的内存量,这不是我想要的。为了获得分配的 GPU 内存量,应使用nvmlDeviceGetMemoryInfo()代替。
AMI 使用示例
作为如何使用此 AMI 的示例,还有一个 terraform 项目,其中包含配置实例并使用 CloudWatch 界面对其进行监控所需的资源。
tf/main.tf是包含对模块tf/module/monitored-gpu的引用的根文件,该模块封装了实例和IAM权限等资源。
此示例不需要实例的 SSH 功能。我们将使用 AWS Systems Manager - Session Manager 来访问实例(基础 AMI 已经预装了 SSM 代理)。这种方法更好,因为访问已注册到 AWS,允许对实例访问进行安全审计。此外,任何机器中都没有存储凭据或密钥被泄露。
所需的 AWS 托管权限是:
-
CloudWatchAgentServerPolicy:允许实例发布 CloudWatch 指标; -
AmazonSSMManagedInstanceCore通过会话管理器访问实例。
如何运行
好吧,让我们进入有趣的部分!要玩这个项目,我们首先需要安装一些依赖项(packer和terraform)。
asdf是一个非常方便的工具,可用于安装和管理工具的多个版本。它可以帮助您跟踪使用各种工具的不同版本。有了它,您无需卸载您可能已经拥有的工具版本。通过一些简单的命令,它会安装所需的版本并使其具有上下文感知能力(在进入指定了.tool-versions的目录后,收费版本会自动更改)。
你可以到这个链接来安装asdf。之后你可以简单地运行以下命令来获得packer和terraform的正确版本:
asdf plugin-add terraform https://github.com/asdf-community/asdf-hashicorp.git
asdf plugin-add packer https://github.com/asdf-community/asdf-hashicorp.git
asdf install
进入全屏模式 退出全屏模式
之后,是时候构建 AMI 了:
cd packer
packer init
packer build .
进入全屏模式 退出全屏模式
这将开始在us-east-1区域中构建 AMI 的过程。您可以跟随终端查看正在发生的事情以及脚本的日志。您还可以访问 AWS 控制台查看正在拍摄的快照:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--ZjfsqafD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- (uploads.s3.amazonaws.com/uploads/articles/ubm33n7lcpfyo85zpfi8.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--ZjfsqafD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- (uploads.s3.amazonaws.com/uploads/articles/ubm33n7lcpfyo85zpfi8.png)
并在“快照”页面中获得一个进度条,如下所示:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--T1rcN9O---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/wqemiutrh7qz3qx9qon.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--T1rcN9O---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/wqemiutrh7qz3qx9qon.png)
快照名称标签将在 AMI 创建后出现。
当您在终端上看到类似这样的内容时,将完成 AMI 创建:
...
==> amazon-ebs.gpu: Terminating the source AWS instance...
==> amazon-ebs.gpu: Cleaning up any extra volumes...
==> amazon-ebs.gpu: No volumes to clean up, skipping
==> amazon-ebs.gpu: Deleting temporary security group...
==> amazon-ebs.gpu: Deleting temporary keypair...
Build 'amazon-ebs.gpu' finished after 9 minutes 38 seconds.
==> Wait completed after 9 minutes 38 seconds
==> Builds finished. The artifacts of successful builds are:
--> amazon-ebs.gpu: AMIs were created:
us-east-1: ami-09a9fd45137e9129e
进入全屏模式 退出全屏模式
✅ 此时,您应该已经准备好使用 AMI 了!!
现在是测试它的时候了!获取 AMI id(在本例中为ami-09a9fd45137e9129e)并粘贴它,替换tf/main.tf文件中的文本"<your-ami-id>"。修改后,指定模块的文件部分应如下所示:
module "gpu_vm" {
source = "./modules/monitored-gpu"
ami = "ami-09a9fd45137e9129e"
}
进入全屏模式 退出全屏模式
之后,只需运行:
cd tf
terraform init
terraform apply
进入全屏模式 退出全屏模式
terraform将询问您是否要执行指定的操作。如果在提示之前,它显示它将创建 6 个资源,如下图所示,您可以键入yes开始资源配置。
...
Plan: 6 to add, 0 to change, 0 to destroy.
...
进入全屏模式 退出全屏模式
几分钟(大约 5 分钟)后,转到 CloudWatch 上的_所有指标_页面。您应该已经能够看到两个新的自定义命名空间:CWAgent和GPU。这是新创建的实例在空闲时发布其指标。
[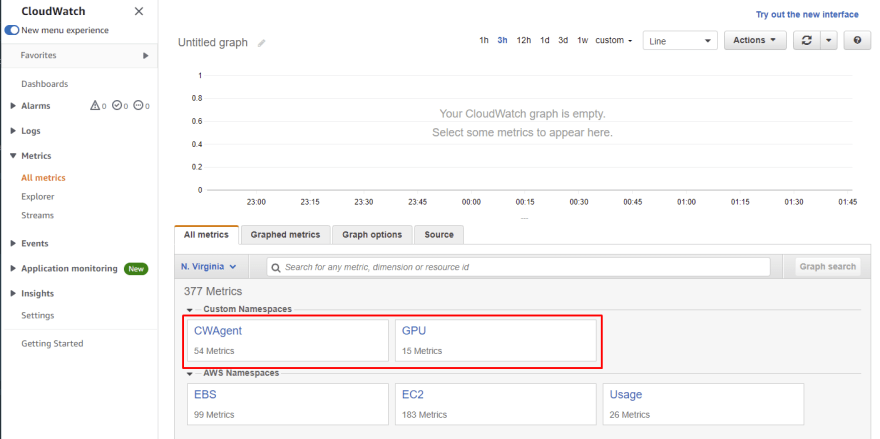 ](https://res.cloudinary.com/practicaldev/image/fetch/s--pl2MGBWF--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/zftyatlcwrfqnj9h6kj5.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--pl2MGBWF--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/zftyatlcwrfqnj9h6kj5.png)
您可以看到有关 RAM 和交换的更多详细信息,例如,使用CWAgent命名空间,如下图所示。有了它,您可以监控 AMI 的启动行为、评估其性能并验证其行为是否符合预期。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--qIY3xpI4--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/5azcrr02cca54px3vuku.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--qIY3xpI4--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/5azcrr02cca54px3vuku.png)
交换使用率为 0,因为此 AMI 中没有配置交换(您可以按照此文档来添加它)。您看到的 RAM 使用高峰是我正在做的一个测试😅。
现在,让我们稍微使用一下这个硬件来看看指标的变化。转到 EC2 页面上的 Instances 选项卡,如下图所示。右键单击正在运行的实例并点击连接。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--bGZ7ZUGK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/vassimnj4wxsmcc472ua.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--bGZ7ZUGK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/vassimnj4wxsmcc472ua.png)
之后,转到会话管理器选项卡并点击_connect。
[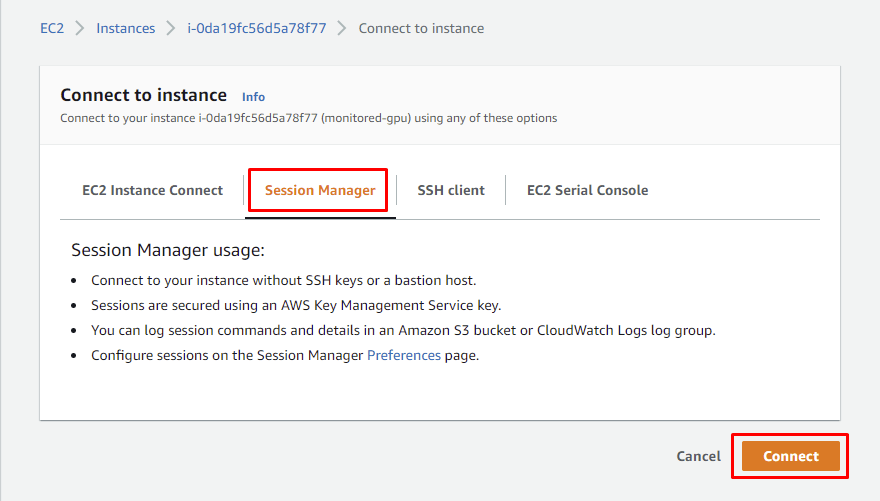 ](https://res.cloudinary.com/practicaldev/image/fetch/s--BX2VELkU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/cjkhgb83dtq0xv0sf775.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--BX2VELkU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/cjkhgb83dtq0xv0sf775.png)
您现在应该可以通过浏览器访问 shell。运行以下命令将克隆并构建一个实用程序来对 GPU 进行 5 分钟的压力测试。
sudo -s
yum install -y git
cd ~
git clone https://github.com/wilicc/gpu-burn.git
make CUDAPATH=/opt/nvidia/cuda
./gpu_burn 600
进入全屏模式 退出全屏模式
您可以查看 CloudWatch 以查看gpu-burn执行其操作时资源使用的影响,如下图所示。
借助这些指标,现在可以轻松创建警报以在检测到资源使用异常时提醒您,或使用自定义指标为集群创建自动扩展功能。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--M46E1bod--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/hkspyq8uaepwzk07q0bo.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--M46E1bod--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to -uploads.s3.amazonaws.com/uploads/articles/hkspyq8uaepwzk07q0bo.png)
清理
要结束派对并关灯,只需:
-
在
tf/目录下运行terraform destroy; -
注销我;
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--zv8IUinn--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- (uploads.s3.amazonaws.com/uploads/articles/q9bghbgaxjwfucv23fm4.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--zv8IUinn--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- (uploads.s3.amazonaws.com/uploads/articles/q9bghbgaxjwfucv23fm4.png)
- 并删除 EBS 快照。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--r2BVfqId--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/gzrd8oudreiofyysl6mp.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--r2BVfqId--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/gzrd8oudreiofyysl6mp.png)
感谢你们!非常感谢评论和反馈。
请随时通过LinkedIn或Github与我联系。

CI/CD社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献22912条内容
已为社区贡献22912条内容

所有评论(0)