
二进制部署 Kubernetes v1.11.0集群
1,官方地址:
从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群
官方也提供了一个互动测试环境供大家测试:https://kubernetes.io/cn/docs/tutorials/kubernetes-basics/cluster-interactive/# k8s包下载地址
https://dl.k8s.io/v版本号/kubernetes-server-linux-amd64.tar.gz
找到需要的版本
https://dl.k8s.io/v1.11.0/kubernetes-server-linux-amd64.tar.gz二进制方式部署k8s集群
目标任务:
1、Kubernetes集群部署架构规划
2、部署Etcd数据库集群
3、在Node节点安装Docker
4、部署Flannel网络插件
5、在Master节点部署组件(api-server,schduler,controller-manager)
6、在Node节点部署组件(kubelet,kube-proxy)
7、查看集群状态
8、运行一个测试示例
9、部署Dashboard(Web UI) 可选Kubernetes集群部署架构规划
操作系统:
CentOS7.4_x64
软件版本:
Docker 19.09.0-ce
Kubernetes 1.13服务器角色、IP、组件:
k8s-master1
192.168.246.162 kube-apiserver,kube-controller-manager,kube-scheduler,etcd
k8s-master2
192.168.246.163 kube-apiserver,kube-controller-manager,kube-scheduler,etcd
k8s-node1
192.168.246.164 kubelet,kube-proxy,docker,flannel,etcd
k8s-node2
192.168.246.165 kubelet,kube-proxy,docker,flannel
Master负载均衡
192.168.246.166 LVS
镜像仓库
10.206.240.188 Harbor
机器配置要求:
3G
主机名称 必须改 必须相互解析
[root@k8s-master1 ~]# vim /etc/hosts
192.168.246.162 k8s-master1
192.168.246.163 k8s-master2
192.168.246.164 k8s-node1
192.168.246.165 k8s-node2
192.168.246.166 lvs-server
关闭防火墙和selinux准备环境
三台机器,所有机器相互做解析 centos7.4
关闭防火墙和selinux
# 设置主机名
# Master节点
hostnamectl set-hostname k8s-master
# node节点
hostnamectl set-hostname k8s-node1
reboot 重新启动服务器,主机名生效
[root@k8s-master ~]# vim /etc/hosts
192.168.96.134 k8s-master
192.168.96.135 k8s-node1
192.168.96.136 k8s-node22,部署Etcd集群
使用cfssl来生成自签证书,任何机器都行(这个证书随便在那台机器生成都可以。哪里用将证书拷贝到哪里就可以了。)
证书三台机器都部署,不然在下面Flannel网络插件还需要在部署证书
证书:
下载cfssl工具:下载的这些是可执行的二进制命令直接用就可以了
[root@k8s-master1 ~]# wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
[root@k8s-master1 ~]# wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
[root@k8s-master1 ~]# wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
[root@k8s-master1 ~]# chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
#移动到 /usr/local/bin 重命名文件
[root@k8s-master1 ~]# mv cfssl_linux-amd64 /usr/local/bin/cfssl
[root@k8s-master1 ~]# mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
[root@k8s-master1 ~]# mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
生成Etcd证书:
创建以下三个文件:
[root@k8s-master1 ~]# mkdir cert
[root@k8s-master1 ~]# cd cert/
[root@k8s-master1 cert]# vim ca-config.json #生成ca中心的
[root@k8s-master1 cert]# cat ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
[root@k8s-master1 cert]# vim ca-csr.json #生成ca中心的证书请求文件
[root@k8s-master1 cert]# cat ca-csr.json
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
[root@k8s-master1 cert]# vim server-csr.json #生成服务器的证书请求文件
[root@k8s-master1 cert]# cat server-csr.json ##真实ip地址 hosts
{
"CN": "etcd",
"hosts": [
"192.168.246.162",
"192.168.246.163",
"192.168.246.164"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
master节点生成证书:
[root@k8s-master1 cert]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
[root@k8s-master1 cert]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
[root@k8s-master1 cert]# ls *pem
ca-key.pem ca.pem server-key.pem server.pem安装Etcd:
二进制包下载地址:
https://github.com/coreos/etcd/releases/tag/v3.2.12
三台机器都操作部署etcd
以下部署步骤在规划的三个etcd节点操作一样,唯一不同的是etcd配置文件中的服务器IP要写当前的:
解压二进制包:
以下步骤三台机器都操作:
# wget https://github.com/etcd-io/etcd/releases/download/v3.2.12/etcd-v3.2.12-linux-amd64.tar.gz
# mkdir /opt/etcd/{bin,cfg,ssl} -p
# tar zxvf etcd-v3.2.12-linux-amd64.tar.gz
# cp etcd-v3.2.12-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
创建etcd配置文件:
# vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd01" #节点名称,各个节点不能相同
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.246.162:2380" #写每个节点的ip
ETCD_LISTEN_CLIENT_URLS="https://192.168.246.162:2379" #写每个节点的ip
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.246.162:2380" #写每个节点的ip
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.246.162:2379" #写每个节点的ip
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.246.162:2380,etcd02=https://192.168.246.164:2380,etcd03=https://192.168.246.165:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
参数解释:
* ETCD_NAME 节点名称,每个节点名称不一样
* ETCD_DATA_DIR 存储数据目录(他是一个数据库,不是存在内存的,存在硬盘中的,所有和k8s有关的信息都会存到etcd里面的)
* ETCD_LISTEN_PEER_URLS 集群通信监听地址
* ETCD_LISTEN_CLIENT_URLS 客户端访问监听地址
* ETCD_INITIAL_ADVERTISE_PEER_URLS 集群通告地址
* ETCD_ADVERTISE_CLIENT_URLS 客户端通告地址
* ETCD_INITIAL_CLUSTER 集群节点地址
* ETCD_INITIAL_CLUSTER_TOKEN 集群Token
* ETCD_INITIAL_CLUSTER_STATE 加入集群的当前状态,new是新集群,existing表示加入已有集群
systemd管理etcd:
# vim /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd
ExecStart=/opt/etcd/bin/etcd \
--name=${ETCD_NAME} \
--data-dir=${ETCD_DATA_DIR} \
--listen-peer-urls=${ETCD_LISTEN_PEER_URLS} \
--listen-client-urls=${ETCD_LISTEN_CLIENT_URLS},http://127.0.0.1:2379 \
--advertise-client-urls=${ETCD_ADVERTISE_CLIENT_URLS} \
--initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS} \
--initial-cluster=${ETCD_INITIAL_CLUSTER} \
--initial-cluster-token=${ETCD_INITIAL_CLUSTER_TOKEN} \
--initial-cluster-state=new \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
把刚才生成的证书拷贝到配置文件中的位置:(将master上面生成的证书scp到剩余两台机器上面)
# cd /root/cert/
# cp ca*pem server*pem /opt/etcd/ssl
直接远程拷贝到剩余两台etcd机器:
[root@k8s-master cert]# scp ca*pem server*pem k8s-node1:/opt/etcd/ssl
[root@k8s-master cert]# scp ca*pem server*pem k8s-node2:/opt/etcd/ssl
全部启动并设置开启启动:
# systemctl daemon-reload
# systemctl start etcd #先启动node节点,再启动master节点, node节点才能加入到master节点
# systemctl enable etcd
# systemctl status etcd #查看etcd服务状态
都部署完成后,三台机器都检查etcd集群状态:
# /opt/etcd/bin/etcdctl --ca-file=/opt/etcd/ssl/ca.pem --cert-file=/opt/etcd/ssl/server.pem --key-file=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.246.162:2379,https://192.168.246.164:2379,https://192.168.246.165:2379" cluster-health
member 18218cfabd4e0dea is healthy: got healthy result from https://10.206.240.111:2379
member 541c1c40994c939b is healthy: got healthy result from https://10.206.240.189:2379
member a342ea2798d20705 is healthy: got healthy result from https://10.206.240.188:2379
cluster is healthy
如果输出上面信息,就说明集群部署成功。
如果有问题第一步先看日志:/var/log/messages 或 journalctl -u etcd
报错:
Jan 15 12:06:55 k8s-master1 etcd: request cluster ID mismatch (got 99f4702593c94f98 want cdf818194e3a8c32)
解决:因为集群搭建过程,单独启动过单一etcd,做为测试验证,集群内第一次启动其他etcd服务时候,是通过发现服务引导的,所以需要删除旧的成员信息,所有节点作以下操作
[root@k8s-master1 default.etcd]# pwd
/var/lib/etcd/default.etcd
[root@k8s-master1 default.etcd]# rm -rf member/
========================================================
如有报错:
# 在每个节点上查看实时日志,确认是否完成选举
journalctl -u etcd -f
# 停止etcd服务
systemctl stop etcd
# 删除数据目录中的成员信息(保留目录结构)
rm -rf /var/lib/etcd/default.etcd/member/在Node节点安装Docker,配置docker镜像加速
master节点负责任务调度的,不负责承载pod。 不会运行docker容器
#docker镜像加速
在Node节点安装Docker
# yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
# yum install -y yum-utils device-mapper-persistent-data lvm2 git
# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# yum install docker-ce -y
启动设置开机自启
# curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://bc437cce.m.daocloud.io #配置加速器部署Flannel网络插件
是解决不同节点上的容器之间的通信的
Flannel要用etcd存储自身一个子网信息,所以要保证能成功连接Etcd,写入预定义子网段:
在node节点部署,如果没有在master部署应用,那就不要在master部署flannel,他是用来给所有的容器用来通信的。
## Flannel 范楼master节点操作:
[root@k8s-master ~]# scp -r cert/ k8s-node1:/root/ #将生成的证书copy到剩下的机器上面
[root@k8s-master ~]# scp -r cert/ k8s-node2:/root/
[root@k8s-master ~]# cd cert/
/opt/etcd/bin/etcdctl \
--ca-file=ca.pem --cert-file=server.pem --key-file=server-key.pem \
--endpoints="https://192.168.246.162:2379,https://192.168.246.164:2379,https://192.168.246.165:2379" \
set /coreos.com/network/config '{ "Network": "172.17.0.0/16", "Backend": {"Type": "vxlan"}}'
## 这条命令是使用 etcdctl 工具,向一个 etcd 集群 设置一个特定的键值对。具体来说,它是为 Flannel 网络插件 设置全局网络配置。
### 这条命令的目的是:在一个安全的(TLS认证)etcd 集群中,为 Flannel CNI 网络插件配置全局参数,指定集群的 Pod 网段为 172.17.0.0/16,并使用 VXLAN 作为网络后端。
## IP地址需要修改,再执行
## etcd地址: 192.168.246.162:2379,https://192.168.246.164:2379,https://192.168.246.165:2379
##### 命令解释
/opt/etcd/bin/etcdctl:etcd 客户端的可执行文件路径。
--ca-file=ca.pem:指定 CA 根证书,用于验证服务端证书。
--cert-file=server.pem:客户端证书,用于向 etcd 服务端证明自己的身份。
--key-file=server-key.pem:客户端私钥,与证书配对使用。
说明:这三者表明 etcd 集群启用了 TLS 双向认证,通信是加密且身份验证的。
#####
--endpoints:指定要连接的 etcd 集群成员地址列表。这里有两个节点:
https://192.168.68.250:2379
https://192.168.68.252:2379
使用 HTTPS 协议,端口为 etcd 默认的客户端通信端口 2379。
###
set:etcdctl 的子命令,用于设置(写入或覆盖)一个键的值。
/coreos.com/network/config:要设置的键(Key)。这是一个约定俗成的路径,Flannel 网络插件会固定读取这个键下的配置数据。
###
"Network": "172.17.0.0/16":
这是 Flannel 将为整个 Kubernetes 集群分配的全局 Pod 网段。
每个 Kubernetes 节点将从该网段中获取一个独立的子网(如 172.17.1.0/24、172.17.2.0/24)。
Flannel 负责确保这些子网间的路由和通信。
"Backend": {"Type": "vxlan"}:
指定 Flannel 使用的后端封装/转发机制为 VXLAN。
VXLAN 是一种隧道协议,它会在物理网络之上创建一个虚拟的 Layer 2 网络,用于封装和传输 Pod 间的跨节点流量。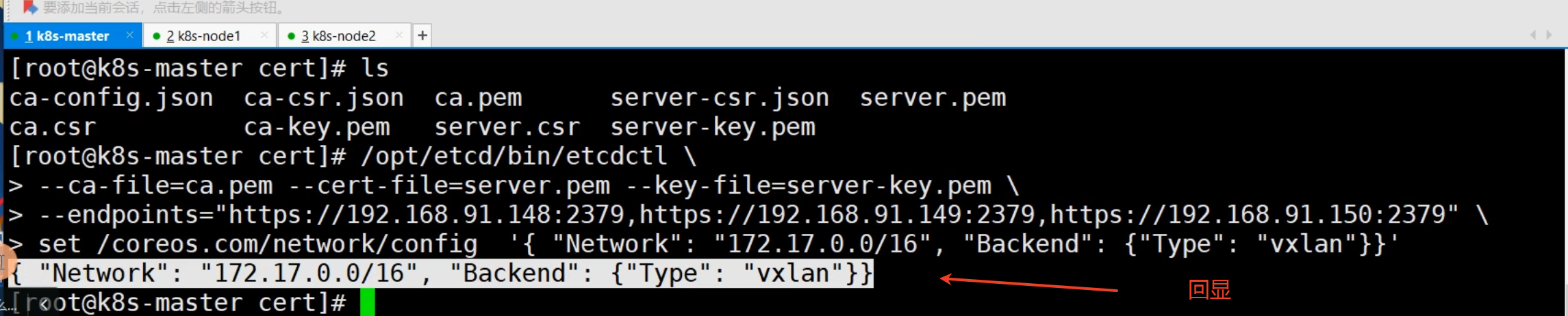
所有node节点部署:
========================================================================================
#注:以下部署步骤在规划的每个node节点都操作。
下载二进制包:
# wget https://github.com/coreos/flannel/releases/download/v0.10.0/flannel-v0.10.0-linux-amd64.tar.gz
# tar zxvf flannel-v0.10.0-linux-amd64.tar.gz
# mkdir -pv /opt/kubernetes/bin
# mv flanneld mk-docker-opts.sh /opt/kubernetes/bin
配置Flannel:
# mkdir -p /opt/kubernetes/cfg/
# vim /opt/kubernetes/cfg/flanneld
# cat /opt/kubernetes/cfg/flanneld
FLANNEL_OPTIONS="--etcd-endpoints=https://192.168.246.162:2379,https://192.168.246.164:2379,https://192.168.246.165:2379 -etcd-cafile=/opt/etcd/ssl/ca.pem -etcd-certfile=/opt/etcd/ssl/server.pem -etcd-keyfile=/opt/etcd/ssl/server-key.pem"
###注意: 修改本机etcd ip
systemd管理Flannel:
# vim /usr/lib/systemd/system/flanneld.service
# cat /usr/lib/systemd/system/flanneld.service
[Unit]
Description=Flanneld overlay address etcd agent
After=network-online.target network.target
Before=docker.service
[Service]
Type=notify
EnvironmentFile=/opt/kubernetes/cfg/flanneld
ExecStart=/opt/kubernetes/bin/flanneld --ip-masq $FLANNEL_OPTIONS
ExecStartPost=/opt/kubernetes/bin/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/subnet.env
Restart=on-failure
[Install]
WantedBy=multi-user.target
配置Docker启动指定子网段:可以将源文件直接覆盖掉
# vim /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/run/flannel/subnet.env
ExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONS
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
##注意:如果第一步没有做,这里需要把证书复制过去。再重启
从master节点拷贝证书文件到node1和node2上:因为node1和2上没有证书,但是flanel需要证书
# mkdir -pv /opt/etcd/ssl/
# scp /opt/etcd/ssl/* k8s-node1:/opt/etcd/ssl/
重启flannel和docker:
# systemctl daemon-reload
# systemctl start flanneld
# systemctl enable flanneld docker
# systemctl restart docker
注意:如果flannel启动不了请检查设置ip网段是否正确
检查是否生效:
[root@k8s-node1 ~]# ps -ef | grep docker
root 3632 1 1 22:19 ? 00:00:00 /usr/bin/dockerd --bip=172.17.77.1/24 --ip-masq=false --mtu=1450
# ip a
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:cd:f6:c9:cc brd ff:ff:ff:ff:ff:ff
inet 172.17.77.1/24 brd 172.17.77.255 scope global docker0
valid_lft forever preferred_lft forever
4: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether ba:96:dc:cc:25:e0 brd ff:ff:ff:ff:ff:ff
inet 172.17.77.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::b896:dcff:fecc:25e0/64 scope link
valid_lft forever preferred_lft forever
注:
1. 确保docker0与flannel.1在同一网段。
2. 测试不同节点互通,在当前节点访问另一个Node节点docker0 IP
案例:node1机器ping node2机器的docker0上面的ip地址
[root@k8s-node1 ~]# ping 172.17.33.1
PING 172.17.33.1 (172.17.33.1) 56(84) bytes of data.
64 bytes from 172.17.33.1: icmp_seq=1 ttl=64 time=0.520 ms
64 bytes from 172.17.33.1: icmp_seq=2 ttl=64 time=0.972 ms
64 bytes from 172.17.33.1: icmp_seq=3 ttl=64 time=0.642 ms
如果能通说明Flannel部署成功。如果不通检查下日志:journalctl -u flannel(快照吧!!!)3,在Master节点部署组件
在部署Kubernetes之前一定要确保etcd、flannel、docker是正常工作的,否则先解决问题再继续。
生成证书
master节点操作--给api-server创建的证书。别的服务访问api-server的时候需要通过证书认证创建CA证书:
[root@k8s-master1 ~]# mkdir -p /opt/crt/
[root@k8s-master1 ~]# cd /opt/crt/
# vim ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
# vim ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "System"
}
]
}
[root@k8s-master1 crt]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
生成apiserver证书:
[root@k8s-master1 crt]# vim server-csr.json
# cat server-csr.json
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1", //这是后面dns要使用的虚拟网络的网关,不用改,就用这个切忌
"127.0.0.1",
"192.168.246.162", // master的IP地址。部署本机集群的地址
"192.168.246.164", // node节点IP
"192.168.246.165",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
[root@k8s-master1 crt]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
生成kube-proxy证书:
[root@k8s-master1 crt]# vim kube-proxy-csr.json
# cat kube-proxy-csr.json
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
[root@k8s-master1 crt]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
最终生成以下证书文件:
[root@k8s-master1 crt]# ls *pem
ca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem server-key.pem server.pem部署apiserver组件
---在master节点进行部署
下载二进制包:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.11.md
下载这个包(kubernetes-server-linux-amd64.tar.gz)就够了,包含了所需的所有组件。
# wget https://dl.k8s.io/v1.11.10/kubernetes-server-linux-amd64.tar.gz
# mkdir /opt/kubernetes/{bin,cfg,ssl} -pv ## 三台机器都需要创建目录
# tar zxvf kubernetes-server-linux-amd64.tar.gz
# cd kubernetes/server/bin
# cp kube-apiserver kube-scheduler kube-controller-manager kubectl /opt/kubernetes/bin
如有master1,master2做在scp这步骤,没有不需要:
从生成证书的机器拷贝证书到master1,master2:----由于证书在master1上面生成的,因此这一步不用scp。
# scp server.pem server-key.pem ca.pem ca-key.pem k8s-master1:/opt/kubernetes/ssl/
# scp server.pem server-key.pem ca.pem ca-key.pem k8s-master2:/opt/kubernetes/ssl/
操作:
[root@k8s-master1 bin]# cd /opt/crt/
# cp server.pem server-key.pem ca.pem ca-key.pem /opt/kubernetes/ssl/
创建token文件:
[root@k8s-master1 crt]# cd /opt/kubernetes/cfg/
# vim token.csv
# cat /opt/kubernetes/cfg/token.csv
674c457d4dcf2eefe4920d7dbb6b0ddc,kubelet-bootstrap,10001,"system:kubelet-bootstrap"
第一列:随机字符串,自己可生成
第二列:k8s集群的用户名
第三列:用户名的UID
第四列:用户组
##不用修改,保存退出
创建apiserver配置文件:
[root@k8s-master1 cfg]# pwd
/opt/kubernetes/cfg
[root@k8s-master1 cfg]# vim kube-apiserver
[root@k8s-master1 cfg]# cat kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=true \
--v=4 \
--etcd-servers=https://192.168.246.162:2379,https://192.168.246.164:2379,https://192.168.246.165:2379 \
--bind-address=192.168.246.162 \ #master的ip地址,就是安装api-server的机器地址
--secure-port=6443 \
--advertise-address=192.168.246.162 \
--allow-privileged=true \
--service-cluster-ip-range=10.0.0.0/24 \ #这里就用这个网段切记不要修改
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \
--authorization-mode=RBAC,Node \
--enable-bootstrap-token-auth \
--token-auth-file=/opt/kubernetes/cfg/token.csv \
--service-node-port-range=30000-50000 \
--tls-cert-file=/opt/kubernetes/ssl/server.pem \
--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \
--client-ca-file=/opt/kubernetes/ssl/ca.pem \
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \
--etcd-cafile=/opt/etcd/ssl/ca.pem \
--etcd-certfile=/opt/etcd/ssl/server.pem \
--etcd-keyfile=/opt/etcd/ssl/server-key.pem"
配置好前面生成的证书,确保能连接etcd。
参数说明:
* --logtostderr 启用日志
* --v 日志等级
* --etcd-servers etcd集群地址
* --bind-address 监听地址
* --secure-port https安全端口
* --advertise-address 集群通告地址
* --allow-privileged 启用授权
* --service-cluster-ip-range Service虚拟IP地址段
* --enable-admission-plugins 准入控制模块
* --authorization-mode 认证授权,启用RBAC授权和节点自管理
* --enable-bootstrap-token-auth 启用TLS bootstrap功能,后面会讲到
* --token-auth-file token文件
* --service-node-port-range Service Node类型默认分配端口范围
systemd管理apiserver:
[root@k8s-master1 cfg]# cd /usr/lib/systemd/system
# vim kube-apiserver.service
# cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-apiserver
ExecStart=/opt/kubernetes/bin/kube-apiserver $KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kube-apiserver
# systemctl start kube-apiserver
# systemctl status kube-apiserver部署schduler组件---master节点部署
创建schduler配置文件:
[root@k8s-master1 cfg]# vim /opt/kubernetes/cfg/kube-scheduler
# cat /opt/kubernetes/cfg/kube-scheduler
KUBE_SCHEDULER_OPTS="--logtostderr=true \
--v=4 \
--master=127.0.0.1:8080 \
--leader-elect"
参数说明:
* --master 连接本地apiserver
* --leader-elect 当该组件启动多个时,自动选举(HA)
systemd管理schduler组件:
[root@k8s-master1 cfg]# cd /usr/lib/systemd/system/
# vim kube-scheduler.service
# cat /usr/lib/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-scheduler
ExecStart=/opt/kubernetes/bin/kube-scheduler $KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kube-scheduler
# systemctl start kube-scheduler
# systemctl status kube-scheduler部署controller-manager组件--控制管理组件---master节点部署
master节点操作:创建controller-manager配置文件:
[root@k8s-master1 ~]# cd /opt/kubernetes/cfg/
[root@k8s-master1 cfg]# vim kube-controller-manager
# cat /opt/kubernetes/cfg/kube-controller-manager
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=true \
--v=4 \
--master=127.0.0.1:8080 \
--leader-elect=true \
--address=127.0.0.1 \
--service-cluster-ip-range=10.0.0.0/24 \ //这是后面dns要使用的虚拟网络,不用改,就用这个 切忌
--cluster-name=kubernetes \
--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \
--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \
--root-ca-file=/opt/kubernetes/ssl/ca.pem \
--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem"
systemd管理controller-manager组件:
[root@k8s-master1 cfg]# cd /usr/lib/systemd/system/
[root@k8s-master1 system]# vim kube-controller-manager.service
# cat /usr/lib/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-controller-manager
ExecStart=/opt/kubernetes/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kube-controller-manager
# systemctl start kube-controller-manager
# systemctl status kube-controller-manager.service
所有组件都已经启动成功,通过kubectl工具查看当前集群组件状态:
[root@k8s-master1 ~]# /opt/kubernetes/bin/kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
如上输出说明组件都正常。
##如没有第2个master节点,下面这步骤不用看了:
配置Master负载均衡
所谓的Master HA,其实就是APIServer的HA,Master的其他组件controller-manager、scheduler都是可以通过etcd做选举(--leader-elect),而APIServer设计的就是可扩展性,所以做到APIServer很容易,只要前面加一个负载均衡轮询转发请求即可。
在私有云平台添加一个内网四层LB,不对外提供服务,只做apiserver负载均衡,配置如下:
其他公有云LB配置大同小异,只要理解了数据流程就好配置了。
在Node节点部署组件
Master apiserver启用TLS认证后,Node节点kubelet组件想要加入集群,必须使用CA签发的有效证书才能与apiserver通信,当Node节点很多时,签署证书是一件很繁琐的事情,因此有了TLS Bootstrapping机制,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。
认证大致工作流程如图所示: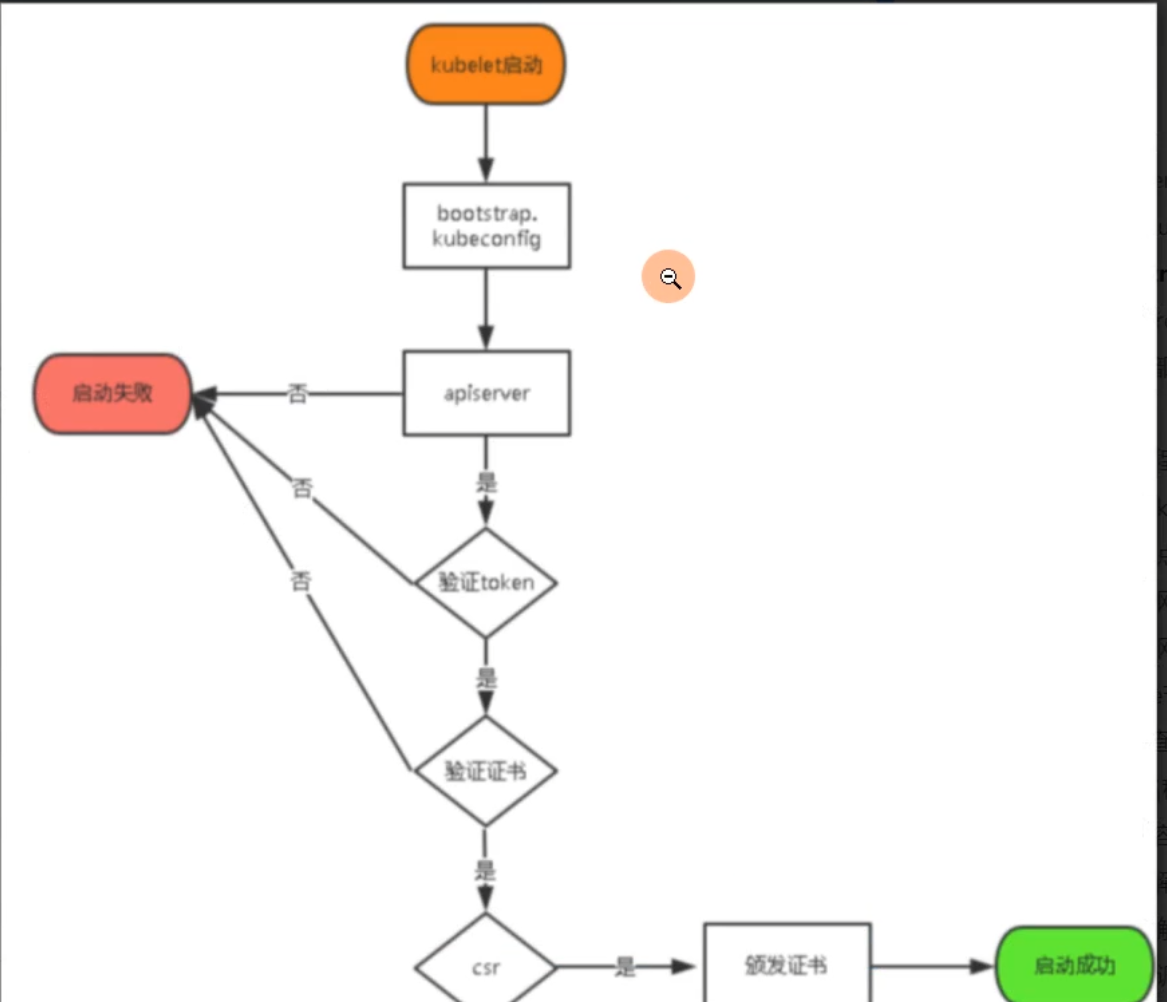
部署bootstrap 组件
----------------------下面这些操作在master节点完成:---------------------------
将kubelet-bootstrap用户绑定到系统集群角色
[root@k8s-master1 ~]# /opt/kubernetes/bin/kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
创建kubeconfig文件:
在生成kubernetes证书的目录下执行以下命令生成kubeconfig文件:
[root@k8s-master1 ~]# cd /opt/crt/
指定apiserver 内网负载均衡地址
[root@k8s-master1 crt]# KUBE_APISERVER="https://192.168.246.162:6443" #写你master的ip地址,集群中就写负载均衡的ip地址
[root@k8s-master1 crt]# BOOTSTRAP_TOKEN=674c457d4dcf2eefe4920d7dbb6b0ddc
# 设置集群参数
[root@k8s-master1 crt]# /opt/kubernetes/bin/kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=bootstrap.kubeconfig
# 设置客户端认证参数
[root@k8s-master crt]# /opt/kubernetes/bin/kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=bootstrap.kubeconfig
# 设置上下文参数
[root@k8s-master crt]# /opt/kubernetes/bin/kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=bootstrap.kubeconfig
# 设置默认上下文
[root@k8s-master crt]# /opt/kubernetes/bin/kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
#====================================================================================
# 创建kube-proxy kubeconfig文件
[root@k8s-master1 crt]# /opt/kubernetes/bin/kubectl config set-cluster kubernetes \
--certificate-authority=ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.kubeconfig
[root@k8s-master1 crt]# /opt/kubernetes/bin/kubectl config set-credentials kube-proxy \
--client-certificate=kube-proxy.pem \
--client-key=kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
[root@k8s-master1 crt]# /opt/kubernetes/bin/kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
[root@k8s-master1 crt]# /opt/kubernetes/bin/kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
[root@k8s-master1 crt]# ls *.kubeconfig
bootstrap.kubeconfig kube-proxy.kubeconfig
#必看:将这两个文件拷贝到Node节点/opt/kubernetes/cfg目录下。
[root@k8s-master1 crt]# scp *.kubeconfig k8s-node1:/opt/kubernetes/cfg/
[root@k8s-master1 crt]# scp *.kubeconfig k8s-node2:/opt/kubernetes/cfg/部署kubelet 组件
----------------------下面这些操作在node节点完成:---------------------------
[root@k8s-master1 ~]# scp kubernetes-server-linux-amd64.tar.gz k8s-node2:/root/
[root@k8s-node1 ~]# tar xzf kubernetes-server-linux-amd64.tar.gz
[root@k8s-node1 ~]# cd kubernetes/server/bin/
[root@k8s-node1 bin]# cp kubelet kube-proxy /opt/kubernetes/bin/
#=====================================================================================
在两个node节点创建kubelet配置文件:
[root@k8s-node1 ~]# vim /opt/kubernetes/cfg/kubelet
KUBELET_OPTS="--logtostderr=true \
--v=4 \
--hostname-override=192.168.246.164 \ #每个节点自己的ip地址
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \
--config=/opt/kubernetes/cfg/kubelet.config \
--cert-dir=/opt/kubernetes/ssl \
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0" #这个镜像需要提前下载
[root@k8s-node1 ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0
[root@k8s-node2 ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0
参数说明:
* --hostname-override 在集群中显示的主机名
* --kubeconfig 指定kubeconfig文件位置,会自动生成
* --bootstrap-kubeconfig 指定刚才生成的bootstrap.kubeconfig文件
* --cert-dir 颁发证书存放位置
* --pod-infra-container-image 管理Pod网络的镜像
其中/opt/kubernetes/cfg/kubelet.config配置文件如下:
[root@k8s-node1 ~]# vim /opt/kubernetes/cfg/kubelet.config
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 192.168.246.164 #写你机器的ip地址
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS: ["10.0.0.2"] #不要改,就是这个ip地址
clusterDomain: cluster.local.
failSwapOn: false
authentication:
anonymous:
enabled: true
webhook:
enabled: false
systemd管理kubelet组件:
# vim /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
After=docker.service
Requires=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet
ExecStart=/opt/kubernetes/bin/kubelet $KUBELET_OPTS
Restart=on-failure
KillMode=process
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kubelet
# systemctl start kubelet
[root@k8s-master ~]# /opt/kubernetes/bin/kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-F5AQ8SeoyloVrjPuzSbzJnFKQaUsier7EGvNFXLKTqM 17s kubelet-bootstrap Pending
node-csr-bjeHSWXOuUDSHganJPL_hDz_8jjYhM2FQyTkbA9pM0Q 18s kubelet-bootstrap Pending
Master审批Node加入集群:
在Master审批Node加入集群:
启动后还没加入到集群中,需要手动允许该节点才可以。在Master节点查看请求签名的Node:
[root@k8s-master1 ~]# /opt/kubernetes/bin/kubectl certificate approve XXXXID
注意:xxxid 指的是上面的NAME这一列
##### 删除特定的 CSR命令:
kubectl delete csr XXXXID
##### 或者删除所有已批准/已颁发的 CSR(谨慎操作)
kubectl delete csr --field-selector status.approved=true
[root@k8s-master1 ~]# /opt/kubernetes/bin/kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr--1TVDzcozo7NoOD3WS2t9xLQqNunsVXj_i2AQ5x1mbs 1m kubelet-bootstrap Approved,Issued
node-csr-L0wqvr69oy8rzXwFm1u1uNx4aEMOOvd_RWPxaAERn_w 27m kubelet-bootstrap Approved,Issued
查看集群节点信息:
[root@k8s-master1 ~]# /opt/kubernetes/bin/kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.246.164 Ready <none> 1m v1.11.10
192.168.246.165 Ready <none> 17s v1.11.10部署kube-proxy组件
创建kube-proxy配置文件:还是在所有node节点
[root@k8s-node1 ~]# vim /opt/kubernetes/cfg/kube-proxy
# cat /opt/kubernetes/cfg/kube-proxy
KUBE_PROXY_OPTS="--logtostderr=true \
--v=4 \
--hostname-override=192.168.246.164 \ #写每个node节点ip
--cluster-cidr=10.0.0.0/24 \ //不要改,就是这个ip
--kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig"
systemd管理kube-proxy组件:
[root@k8s-node1 ~]# cd /usr/lib/systemd/system
# cat /usr/lib/systemd/system/kube-proxy.service
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-proxy
ExecStart=/opt/kubernetes/bin/kube-proxy $KUBE_PROXY_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动:
# systemctl daemon-reload
# systemctl enable kube-proxy
# systemctl start kube-proxy
在master查看集群状态
[root@k8s-master1 ~]# /opt/kubernetes/bin/kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.246.164 Ready <none> 19m v1.11.10
192.168.246.165 Ready <none> 18m v1.11.10
查看集群状态
[root@k8s-master1 ~]# /opt/kubernetes/bin/kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
=====================================================================================
恭喜你,到这里集群部署成功!
============================恭喜你,到这里集群部署成功!
============================
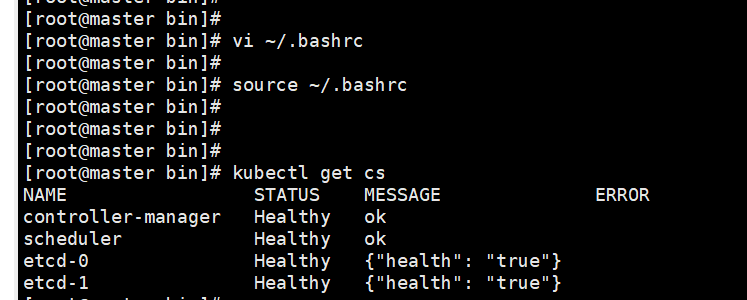
4,设置直接使用kubectl 命令
环境变量:
vi ~/.bashrc
export PATH=$PATH:/opt/kubernetes/bin
source ~/.bashrc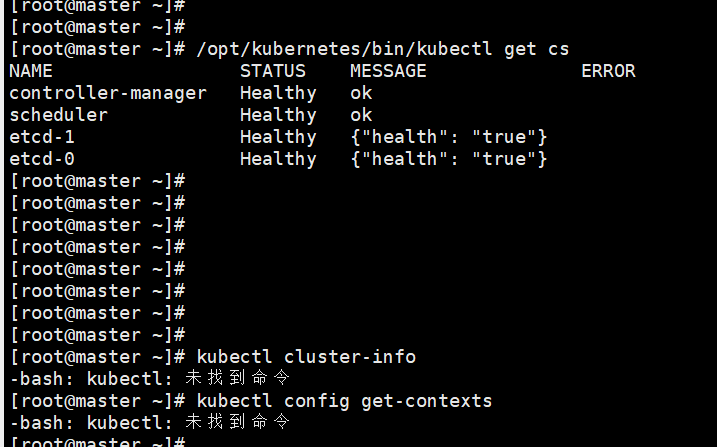
5,下面这些是web端的,如没有web要求。不需要部署
部署Dashboard(Web UI)
* dashboard-deployment.yaml #部署Pod,提供Web服务
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9090
protocol: TCP
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
[root@k8s-master webui]# cat dashboard-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
name: kubernetes-dashboard
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: kubernetes-dashboard-minimal
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
[root@k8s-master webui]# cat dashboard-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort
selector:
k8s-app: kubernetes-dashboard
ports:
- port: 80
targetPort: 9090
[root@k8s-master webui]# /opt/kubernetes/bin/kubectl create -f dashboard-rbac.yaml
[root@k8s-master webui]# /opt/kubernetes/bin/kubectl create -f dashboard-deployment.yaml
[root@k8s-master webui]# /opt/kubernetes/bin/kubectl create -f dashboard-service.yaml
等待数分钟,查看资源状态:
查看名称空间:
[root@k8s-master webui]# /opt/kubernetes/bin/kubectl get all -n kube-system
NAME READY STATUS RESTARTS AGE
pod/kubernetes-dashboard-d9545b947-442ft 1/1 Running 0 21m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes-dashboard NodePort 10.0.0.143 <none> 80:47520/TCP 21m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/kubernetes-dashboard 1 1 1 1 21m
NAME DESIRED CURRENT READY AGE
replicaset.apps/kubernetes-dashboard-d9545b947 1 1 1 21m
查看访问端口:
查看指定命名空间的服务
[root@k8s-master webui]# /opt/kubernetes/bin/kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.0.0.143 <none> 80:47520/TCP 22m测试
1,创建pod
1.1,命令行创建pod
==========================================================
运行一个测试示例--在master节点先安装docker服务
创建一个Nginx Web,判断集群是否正常工
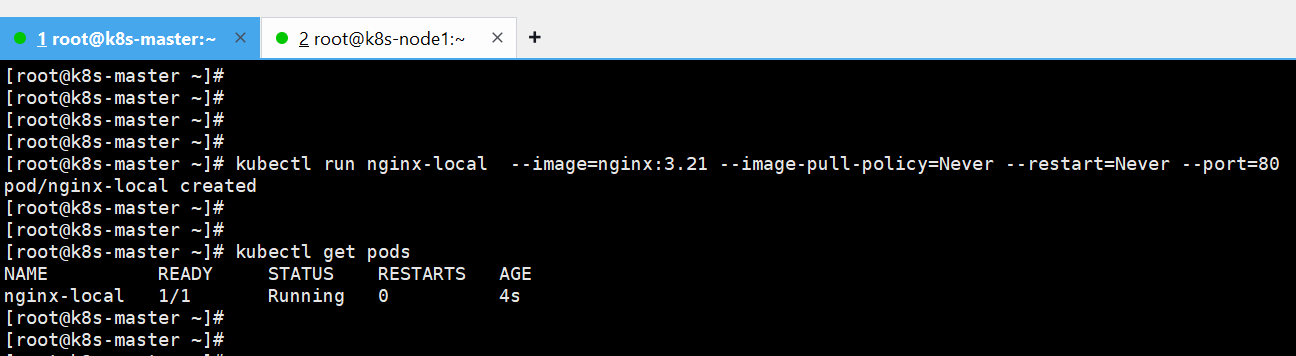
创建pod:
# 使用本地nginx:3.21镜像创建Pod,指定镜像拉取策略为Never
kubectl run nginx-local --image=nginx:3.21 --image-pull-policy=Never --restart=Never --port=80
#######
--image=nginx:3.21 \ # 指定容器镜像
--image-pull-policy=Never \ # 镜像拉取策略,仅使用本地镜像 或者使用 IfNotPresent #本地没有才拉取
--restart=Never \ # Pod 重启策略
--port=80 # 暴露的容器端口1.2,使用 yaml文件创建pod
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
environment: test
spec:
containers:
- name: nginx
image: nginx:3.21
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
protocol: TCP
restartPolicy: Never需要node节点有nginx镜像
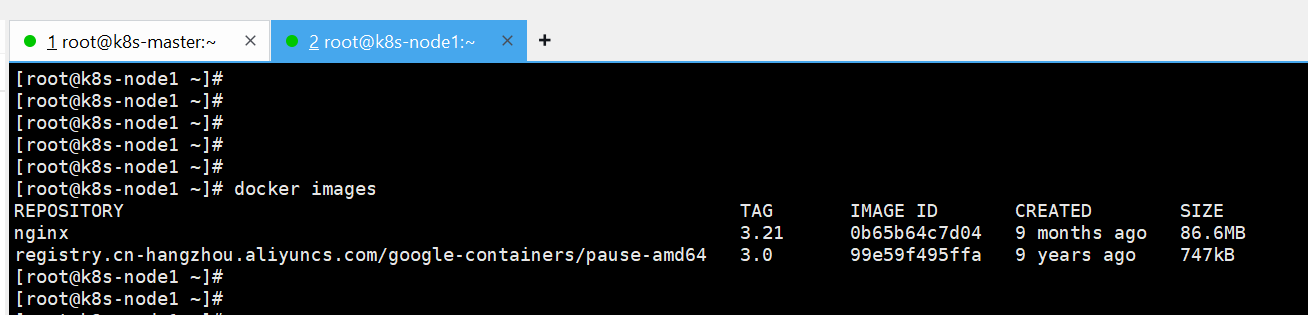
2,创建 Service 来暴露 Pod
在master上面查看:
创建 Service:
# kubectl expose pod nginx-local \
--name=nginx-service \
--type=NodePort \
--port=81 \
--target-port=80
### 命令解释
kubectl expose pod nginx-local \ # pod nginx-local 指定要暴露的 Pod 名称
--name=nginx-service \ # 指定 Service 名称 如果不指定,默认使用 Pod名称nginx-local
--type=NodePort \ # 指定 Service 类型 通过节点 IP 和端口访问
--port=81 \ # Service 对外暴露的端口
--target-port=80 # Pod 容器内部的端口
# expose 参数,暴露,曝光
查看创建的 Service:
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 4h
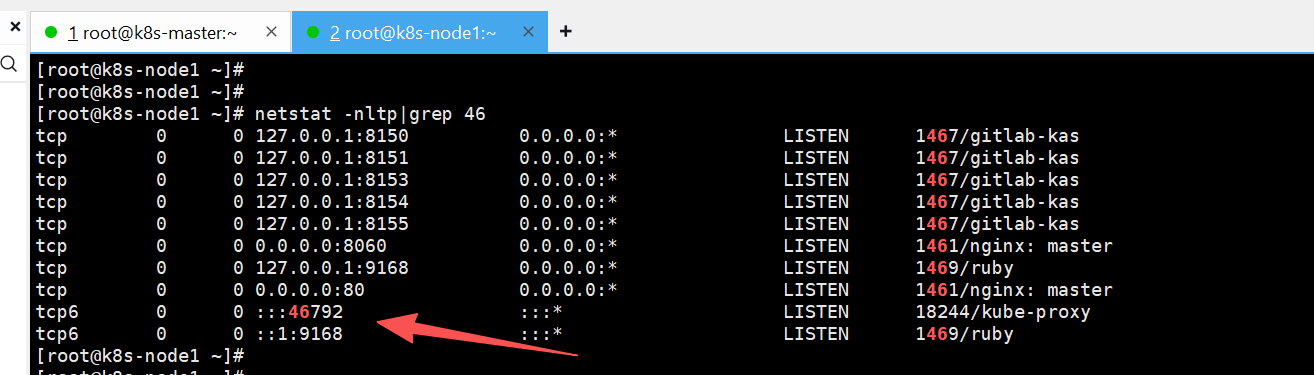
nginx-service NodePort 10.0.0.193 <none> 81:46792/TCP 16s
81:Service 的 ClusterIP 端口(集群内部访问端口)
46792:NodePort 端口 (节点外部访问端口)
# 在集群内部的其他Pod中访问
curl 10.0.0.193:81
# 通过 NodePort 外部访问,浏览器访问
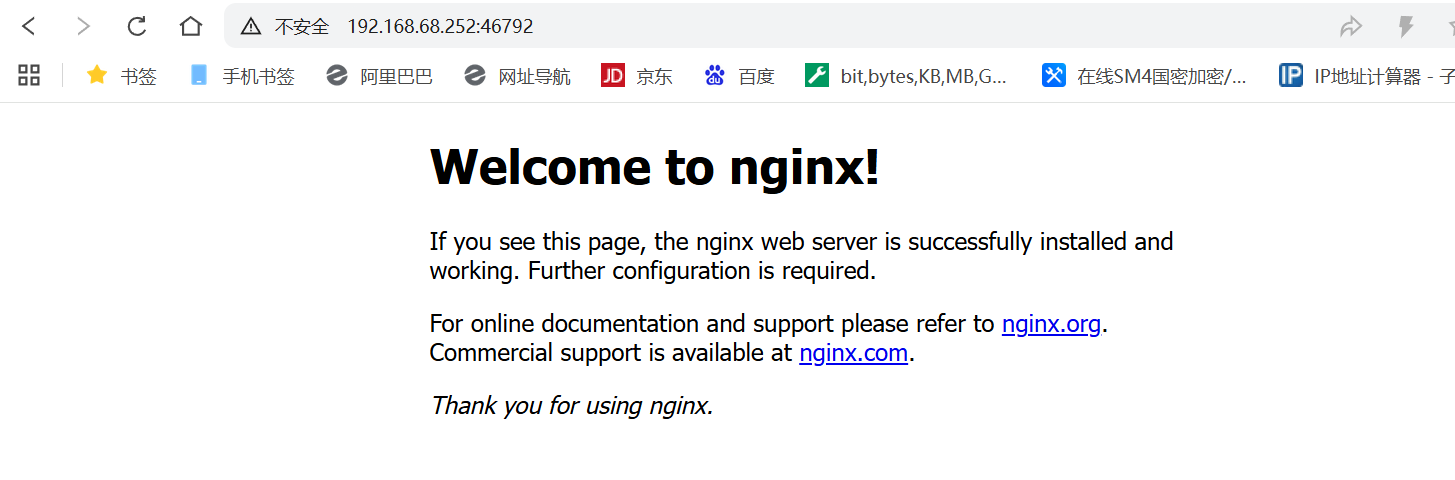
http://192.168.68.252:46792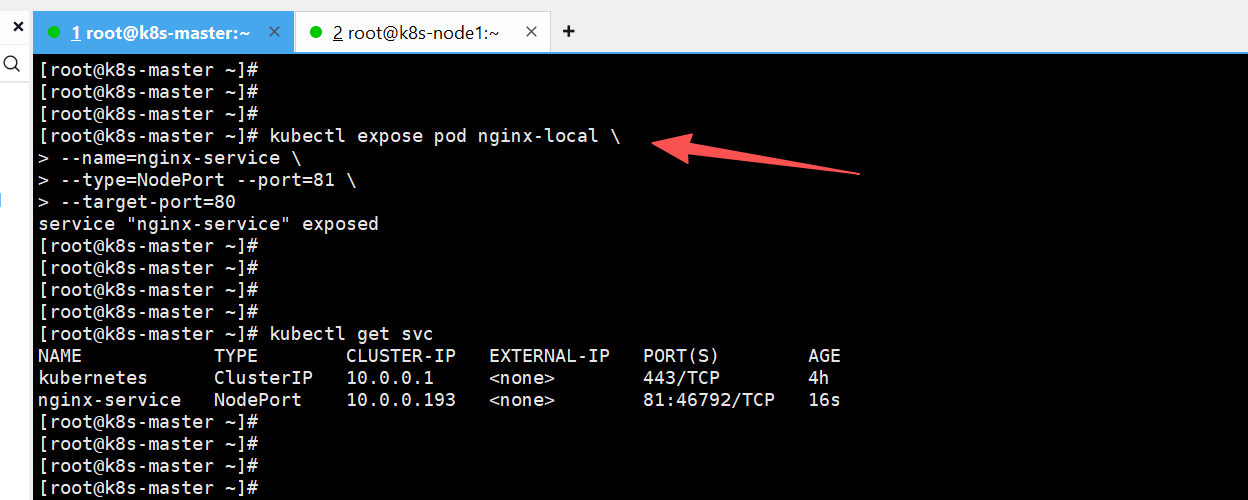
3,浏览器访问
访问nodeip加端口
打开浏览器输入:http://192.168.246.164:46792node节点ip
k8s常用命令
k8s常用命令:
1,查看pod,service,endpoints,secret等等的状态
kubectl get 组件名 # 查看组件状态 (kubectl 扣魄 ctl)
2,创建,变更一个yaml文件内资源,也可以是目录,目录内包含一组yaml文件(实际使用中都是以yaml文件为主,直接使用命令创建pod的很少,推荐多使用yaml文件)
kubectl apply -f xxx.yaml # 创建文件 (apply 额谱来)
3,删除一个yaml文件内资源,也可以是目录,目录内包含一组yaml文件
kubectl delete -f xxx.yaml # 删除文件 (delete 得里特)
4,查看资源状态,比如有一组deployment内的pod没起来,一般用于pod调度过程出现的问题排查
kubectl describe pod pod名 # 查看资源状态 (describe 得思怪博)
5,查看pod日志,用于pod状态未就绪的故障排查
kubectl logs pod名 # 查看日志
6,查看node节点或者是pod资源(cpu,内存资源)使用情况
kubectl top 组件名 #查看CPU资源
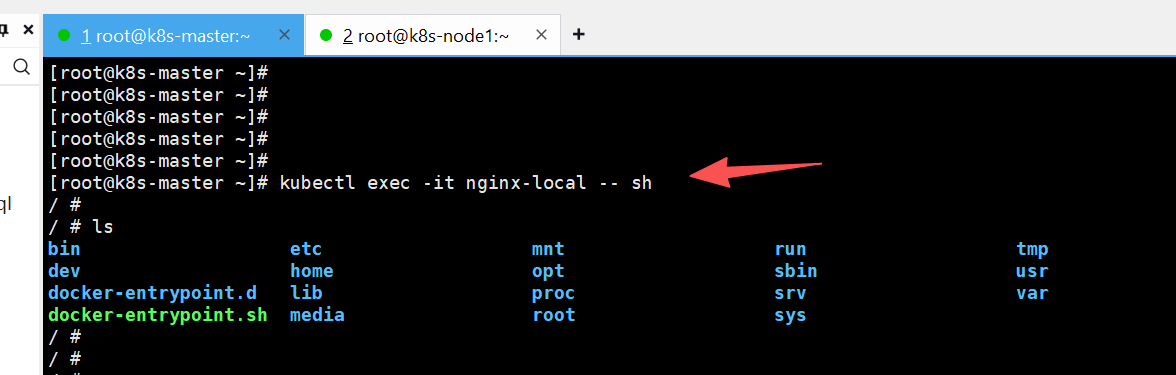
7,进入pod内部
kubectl exec -ti pod名 /bin/bas
8, 查看 kubectl 版本
kubectl version --shorpod yaml文件
---
apiVersion: v1 # api版本号
kind: Pod # 资源类型 (Deployment|StatefulSet|Service)
metadata: # 元数据信息
name: nginx # Pod名称
labels: # 标签
app: nginx # 建议使用有意义的标签
environment: test
spec: # 规格部分 定义Pod声明
containers: # 配置容器位置(Pod管理容器)
- name: nginx # 容器名称
image: nginx:3.21 # 镜像(使用正确版本)
imagePullPolicy: IfNotPresent # 关键:添加这行,优先使用本地镜像或 Never
ports: # 端口声明
- containerPort: 80 # 容器端口声明,唯一性不能重复
protocol: TCP # 协议(可选,默认TCP)
restartPolicy: Never # Pod 重启策略
# 镜像拉取策略
Always 总是拉取最新镜像
IfNotPresent 本地有就不拉取
Never 从不拉取镜像 只使用本地镜像,不尝试拉取
# Pod 重启策略
--restart=Never Pod 退出后永不重启
--restart=Always Pod 退出后总是重启
--restart=OnFailure 仅当失败时重启(非0退出码)
pod命令
# 创建一个名为 nginx-local 的 Pod,使用 nginx:3.21 镜像
kubectl run nginx-local \
--image=nginx:3.21 \
--image-pull-policy=Never \
--restart=Never \
--port=80
# --labels="app=web,env=prod" --env="KEY1=VALUE1"
--image: 指定容器镜像
--labels: 添加标签
--env: 设置环境变量,如 --env="KEY=VALUE"
--restart=Never:退出后永不重启 确保创建的是 Pod 而不是 Deployment Pod
--port: 暴露的端口 这个参数只是容器声明端口,并不会露端口到外部
--rm: 退出后自动删除 Pod(常用于临时调试)
-it: 交互式终端
--labels
标签是键值对,用于:
资源识别和分组:将相关资源分组管理
服务发现:Service 通过标签选择器(selector)找到 Pod
资源筛选:按标签过滤和查找资源
# 按标签筛选
kubectl get pods -l app=web
kubectl get pods -l env=prod
# 创建一个 Pod 并进入交互模式(适合调试)
kubectl run busybox --image=busybox --rm -it --restart=Never -- sh# 查看所有 Pod
kubectl get pods
# 查看指定命名空间的 Pod
kubectl get pods -n <namespace>
# 查看 Pod 详细信息
kubectl describe pod <pod-name>
# 查看 Pod 日志
kubectl logs <pod-name> #-f 是实时日志
# 查看多容器 Pod 中某个容器的日志
kubectl logs <pod-name> -c <container-name>
# 进入 Pod 容器(需要容器有 sh 或 bash)
kubectl exec -it <pod-name> -- sh # 或者/bin/sh /bin/bash
# 删除 Pod
kubectl delete pod <pod-name>
# 强制删除 Pod
kubectl delete pod <pod-name> --force --grace-period=0
# 删除指定的 service
kubectl delete service <pod-name>
# 查看 Pod 的 YAML 定义
kubectl get pod <pod-name> -o yaml
# 查看 Pod 所属的 Deployment
kubectl get pod nginx-68fff76dcb-tmx5g -o yaml | grep -A5 ownerReferences
# 或者直接查看 Deployment
kubectl get deployments
# 删除 Deployment(这会删除对应的 Pods)
kubectl delete deployment nginx
# 更彻底地强制删除(使用 k8s 1.15+)
kubectl delete pod nginx-68fff76dcb-tmx5g --grace-period=0 --force --wait=false
# 重启 Deployment
kubectl rollout restart deployment/<name> 滚动重启
# 重启 StatefulSet
kubectl rollout restart statefulset/<name> 按顺序重启
重启"通常意味着"删除后让控制器重建",而不是传统意义上的重启进程
##
Deployment 是 Kubernetes 中一个核心的工作负载资源对象,用于声明式地管理 Pod 和 ReplicaSet。它提供了一种便捷的方式来部署和更新应用程序其他状态
CrashLoopBackOff: #容器退出,kubelet正在将它重启
InvalidImageName: #无法解析镜像名称
ImageInspectError: #无法校验镜像
ErrImageNeverPull: #策略禁止拉取镜像
ImagePullBackOff: #正在重试拉取
RegistryUnavailable: #连接不到镜像中心
ErrImagePull: #通用的拉取镜像出错
CreateContainerConfigError: #不能创建kubelet使用的容器配置
CreateContainerError: #创建容器失败
m.internalLifecycle.PreStartContainer #执行hook报错
RunContainerError: #启动容器失败
PostStartHookError: #执行hook报错
ContainersNotInitialized: #容器没有初始化完毕
ContainersNotReady: #容器没有准备完毕
ContainerCreating: #容器创建中
PodInitializing:pod #初始化中
DockerDaemonNotReady:docker #还没有完全启动
NetworkPluginNotReady: #网络插件还没有完全启动命名空间
命名空间是 Kubernetes 中的一种虚拟集群机制,用于:
将集群资源逻辑隔离到不同的虚拟集群中
实现多租户环境,不同团队/项目使用不同命名空间
对资源进行分组和权限控制
创建命名空间
# 不同命名空间的资源相互隔离
default 命名空间的 Pod 不能直接访问 kube-system 命名空间的 Pod
比如"测试环境命名空间" 和 "生产环境命名空间"
default 默认命名空间 用户创建的未指定命名空间的资源
# 创建命名空间
kubectl create namespace <namespace-name>
# 查看所有命名空间
kubectl get namespaces
kubectl get ns # 简写
# 查看命名空间中的资源对象
kubectl -n 命名空间 get pods
# 查看带标签的命名空间
kubectl get ns --show-labels
# 查看特定命名空间详情
kubectl describe ns <namespace-name>
# 查看资源在命名空间中的分布
kubectl get all --all-namespaces
# 创建 Pod 时指定 命名空间
kubectl create -f myapp.yaml -n custom-namespace
使用 YAML 配置文件
apiVersion: v1
kind: Namespace
metadata:
name: staging
kubectl apply -f namespace.yaml
删除命名空间
# 删除命名空间(会删除其中所有资源!)
kubectl delete namespace <namespace-name>
# 删除前先查看内容
kubectl get all -n <namespace-name>
# 只删除命名空间但保留资源(需要先移除finalizer)
kubectl get namespace <namespace-name> -o json > ns.json
# 编辑 ns.json,移除 spec.finalizers
curl -k -H "Content-Type: application/json" -X PUT \
--data-binary @ns.json \
http://127.0.0.1:8001/api/v1/namespaces/<namespace-name>/finalize
切换命名空间
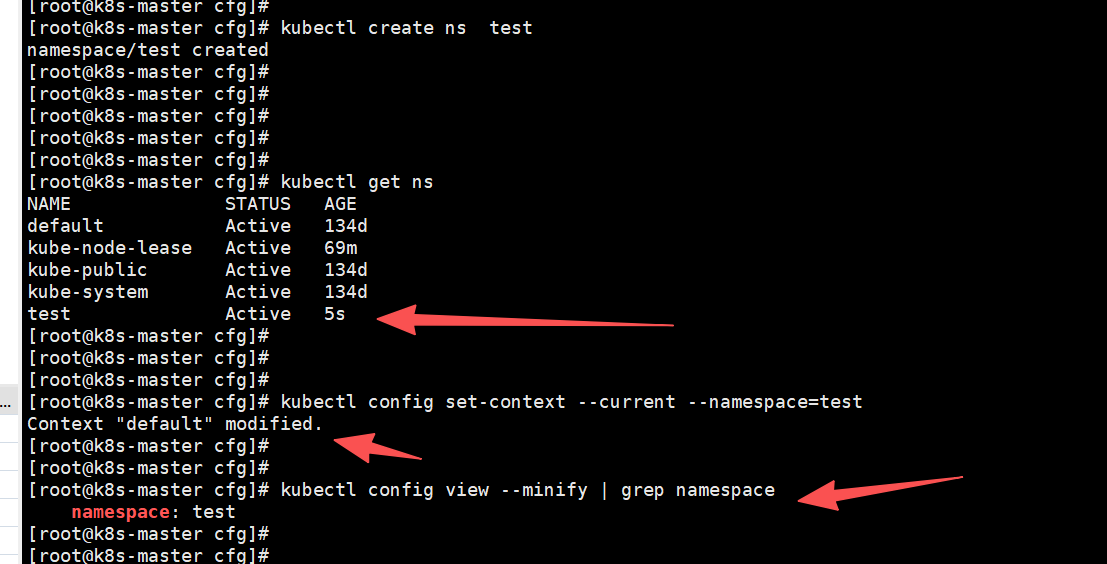
# 切换命名空间
kubectl config set-context --current --namespace=<namespace-name>
# 验证当前命名空间
kubectl config view --minify | grep namespace
# 设置默认命名空间
kubectl config set-context --current --namespace=dev
# 使用 kubens 命令切换
安装 kubens 命令
curl -L https://github.com/ahmetb/kubectx/releases/download/v0.9.1/kubens -o /bin/kubens
chmod +x /bin/kubens
kubens <命名空间名称>
# 列出所有 namespace
[root@k8s-master ~]# kubens
default
kube-system
# 切换
kubens kube-system
# 命令别名
在本机的配置文件中: ~/.ashrc 添加如下别名配置
alias k=kubectl
alias kns=kubens
报错:
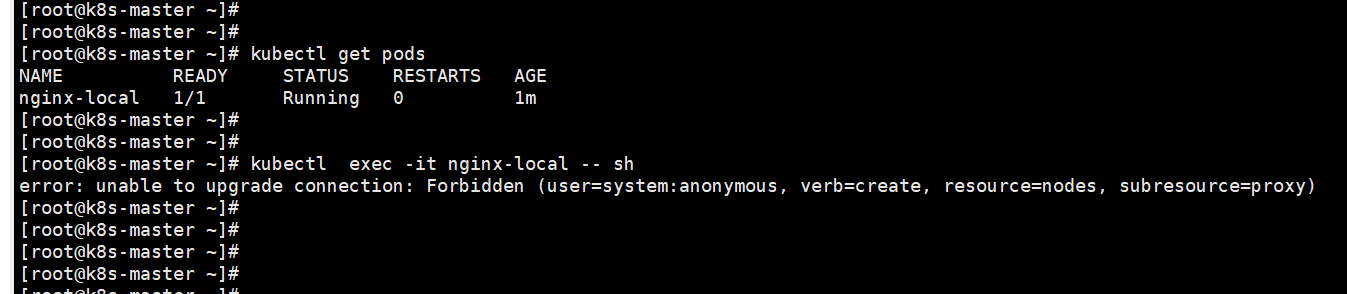
1,kubectl exec 进入报错
错误表明 system:anonymous 用户没有权限通过 kubectl exec 连接到 Pod。这通常是由于 RBAC 权限配置问题引起的
解决方法:
定义 RBAC 规则,修复 RBAC 权限。授权 apiserver 使用的证书(kubernetes.pem)用户名(CN:kuberntes-master)访问 kubelet API 的权限
kubectl create clusterrolebinding kube-apiserver:kubelet-apis --clusterrole=system:kubelet-api-admin --user kubernetes-master

授予 kube-apiserver 访问 kubelet API 的权限
完成后再执行:
kubectl -it exec nginx-local cat /etc/resolv.conf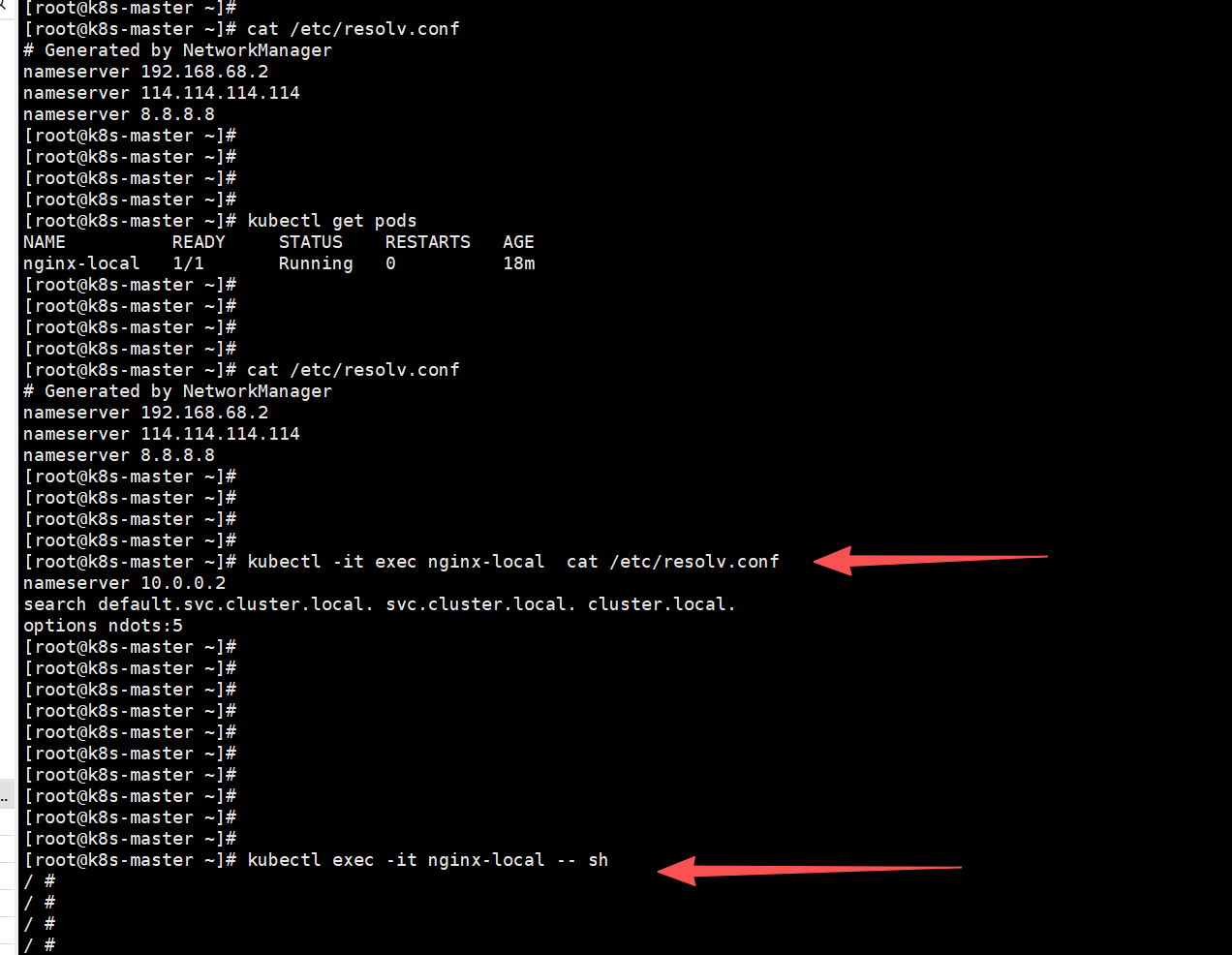
2,如kubectl get nodes 不显示master节点
master节点 部署 kubelet 组件。 再审批master节点加入集群
cd /opt/crt/
cp bootstrap.kubeconfig /opt/kubernetes/cfg
##最小化配置启动 kubelet
vim /etc/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/kubernetes/kubernetes
After=docker.service
Requires=docker.service
[Service]
ExecStart=/opt/kubernetes/bin/kubelet \
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \
--config=/var/lib/kubelet/config.yaml \
--hostname-override=192.168.68.250 \ #master节点ip
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0 \
--allow-privileged=true \
--cluster-dns=10.0.0.2 \
--cluster-domain=cluster.local \
--fail-swap-on=false \
--v=2
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target创建 kubelet 配置文件
1,创建 /var/lib/kubelet 目录
mkdir -p /var/lib/kubelet
2, 创建 kubelet 配置文件
vim /var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS:
- 10.0.0.2
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
enabled: true
x509:
clientCAFile: /opt/kubernetes/ssl/ca.pem
authorization:
mode: Webhook
serializeImagePulls: false
maxPods: 110
podPidsLimit: -1#重新启动 kubelet
sudo systemctl daemon-reload
sudo systemctl start kubelet
sudo systemctl status kubelet
sudo systemctl enable kubelet
报错:检查 kubelet 日志
journalctl -u kubelet -f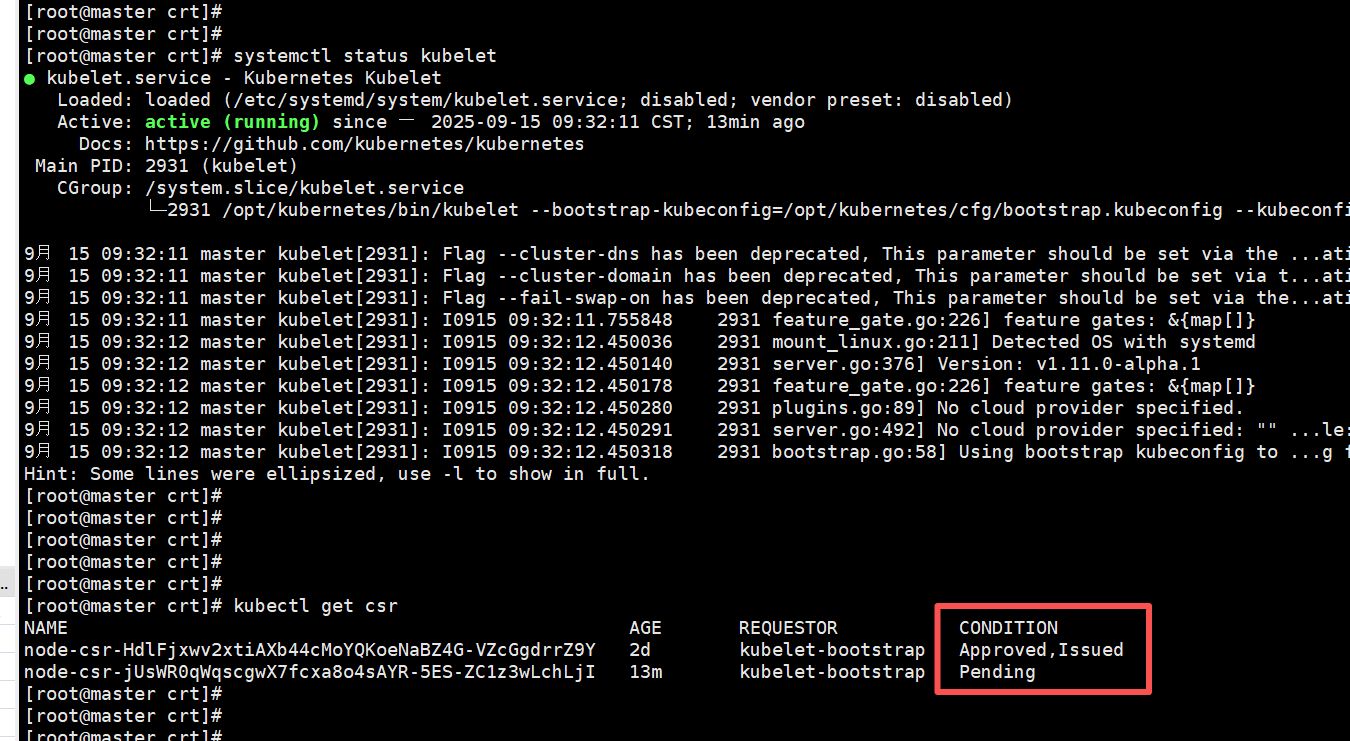
2.2,为 Master 节点添加角色标签
一旦 Master 节点出现在节点列表中,为其添加 master 角色标签:
kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-F5AQ8SeoyloVrjPuzSbzJnFKQaUsier7EGvNFXLKTqM 17s kubelet-bootstrap Pending
node-csr-bjeHSWXOuUDSHganJPL_hDz_8jjYhM2FQyTkbA9pM0Q 18s kubelet-bootstrap Pending
再审批master节点加入集群:
启动后还没加入到集群中,需要手动允许该节点才可以。在Master节点查看请求签名的Node:
[root@k8s-master1 ~]# kubectl certificate approve XXXXID
注意:xxxid 指的是上面的NAME这一列
kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.246.162 Ready <none> 1m v1.11.0-alpha.1
kubectl label node 192.168.246.162 node-role.kubernetes.io/master=
kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.246.162 Ready master 2m v1.11.0-alpha.1
欢迎大家加入成都城市开发者社区,“和我在成都的街头走一走”,让我们一起携手,汇聚IT技术潮流,共建社区文明生态!
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)