
Python项目实践:用PySpark分析大数据
Python项目实践:用PySpark分析大数据
大数据,顾名思义,就是大量的数据。一般来说,这些数据都在PB级以上。 PB是数据存储容量的单位,等于2字节的50次方,大约1000TB。这些数据的特点是种类繁多,包括视频、语音、图片、文字等。面对如此多的数据,用常规技术是无法处理的,于是大数据技术应运而生。
1、大数据Hadoop平台介绍
大数据分为很多派别,其中最著名的是Apache Hadoop、Cloudera CDH和Hortonworks。
Hadoop是一个用于大规模数据集分布式存储和处理的开源工具平台。最早是雅虎技术团队根据谷歌公开论文的思路用JAVA开发的,现在属于apache基金会。
Hadoop以分布式文件系统HDFS(Hadoop分布式文件系统)和MapReduce分布式计算框架为核心,为用户提供底层细节透明的分布式基础设施。
HDFS具有高容错性和高扩展性的优点,允许用户在廉价的硬件上部署Hadoop,构建分布式文件存储系统。
MapReduce分布式计算框架允许用户在不了解分布式系统底层细节的情况下开发并行分布式应用,充分利用大规模计算资源,解决传统高性能单机无法解决的大数据处理问题.
Hadoop 已经发展成为一个庞大的系统。只要在与海量数据相关的领域都能看到,以下是Hadoop生态系统中的各种数据工具。
(1)数据采集系统:Nutch
(2)如何存储海量数据,当然是分布式文件系统:HDFS
(3)如何使用数据?分析和处理它
(4)MapReduce 框架允许您编写代码来分析大数据
(5)非结构化数据(日志)采集与处理:fuse/webdav/chukwa/flume/Scribe
(6)将数据导入HDFS中,目前为止RDBSM还可以加入HDFS:Hiho,sqoop
(7)MapReduce 用熟悉的方式操作太麻烦了 Hadoop 数据在:Pig,Hive,Jaql
(8)让你的数据可见:drilldown,Intellicus
(9)用高级语言管理你的任务流:oozie,Cascading
(10)Hadoop当然也有自己的监控管理工具:Hue,karmasphere,eclipse plugin,cacti,ganglia
(11)数据序列化处理与任务调度:Avro,Zookeeper
(12)更多基于Hadoop的上层服务:Mahout,Elastic map Reduce
(13)OLTP在线事务处理系统:Hbase
Apache Hadoop的整体生态图如下。
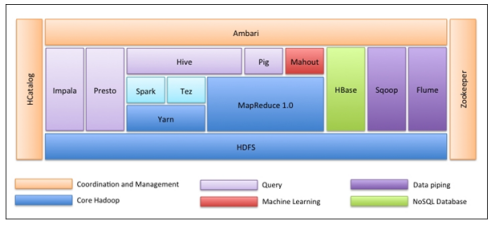
总之,Hadoop是目前分析海量数据的首选工具,已被各行各业广泛应用于以下场景:
(1)大数据存储:分布式存储(各种云盘、百度、360)~还有云平台Hadoop应用)
(2)日志处理:Hadoop 擅长这个
(3)海量计算:并行计算
(4)ETL:数据提取到oracle,mysql,DB2,mongdb和主流数据库
(5)使用HBase做数据分析:处理大量读写操作,具有可扩展性——Facebook基于HBase的实时数据分析系统
(6)机器学习:例如Apache Mahout Project(Apache Mahout介绍(常用领域:协同筛选、聚类和分类)
(7)搜索引擎:Hadoop+lucene实现
(8)数据挖掘:流行的广告推荐
(9)用户行为特征建模
(10)个性化广告推荐
2、大数据在Hadoop中的作用
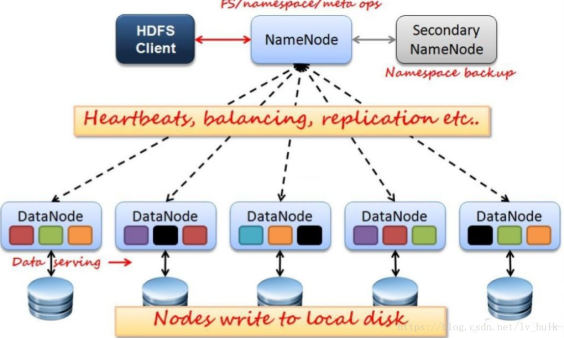
Hadoop是一个开源的分布式存储和计算平台。其中,Hdfs是一个分布式文件存储系统,用于存储文件。存储系统涉及三个角色。
1\。 NameNode:管理元数据信息,给子节点分配任务(FSImage是主节点启动时整个文件系统的快照(元数据镜像文件),Edits是修改记录(操作日志文件))
2\。 DataNode:负责数据存储和实时上报心跳给主节点
3、SecondaryNameNode:
1)首先定期去NameNode获取编辑日志并更新到fsimage。一旦有了新的 fsimage 文件,它就会将其复制回 NameNode。
- 下次重新启动 fsname 时,此文件将花费更少的时间。
这三个角色决定了hadoop分布式文件系统hdfs的运行架构,如下图所示。
yarnYarn,分布式计算的mapreduce框架,是一个资源管理系统,有以下几个角色。
1\。资源管理器监控NodeManager,负责集群的资源调度
2\。 nodemanager 管理节点资源并处理 ResourceManager 命令
3、Hadoop平台环境搭建
Hadoop 在 Linux 上运行。虽然借助工具也可以在 Windows 上运行,但建议在 Linux 系统上运行。这里先介绍Linux环境的安装、配置和Java JDK安装。
1. Linux环境的安装
这里使用Vmware虚拟机安装Linux。首先,需要将 Vmware 虚拟机和主机设置为 NAT 模式配置。 Nat 是网络地址转换。它在主机和虚拟机之间增加了一个地址转换服务,负责外部和虚拟机之间的通信传输和IP转换。
(1) Vmware安装后,默认的NAT设置如下:
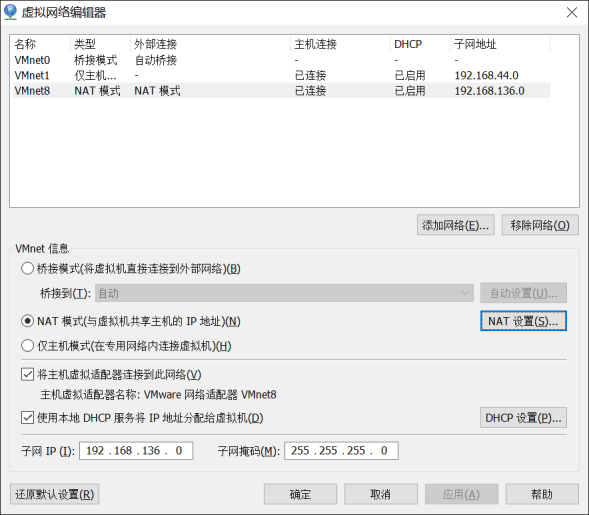
(2) 默认设置为启动DHCP服务。 NAT 会自动为虚拟机分配 IP。需要固定每台机器的IP,所以需要取消这个默认设置。
(3) 为机器设置一个子网段。默认值为 192.168.136。这里设置为100,以后每台虚拟机的Ip都是192.168.100。 *。
(4) 点击NAT设置按钮,打开对话框,可以修改网关地址和DNS地址。在此处指定 NAT 的 DNS 地址。
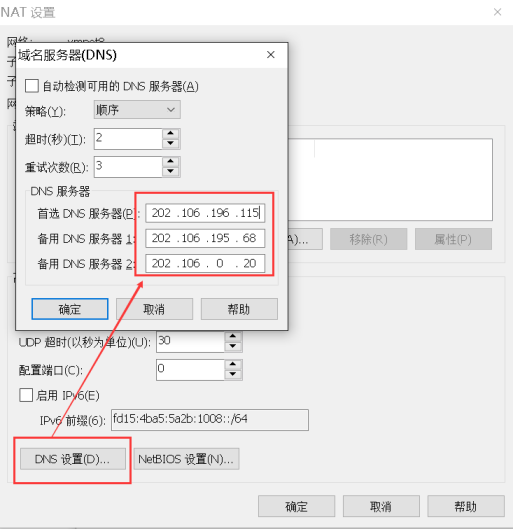
(5)网关地址是。 2 地址在当前网段。这里是固定的,不会被修改。只需要先记住网关地址,后面会用到。
2. Linux环境的安装
(1) 从文件菜单中选择新的虚拟机
(2) 选择经典类型进行安装。下一个。
(3) 选择稍后安装操作系统。下一个。
(4) 选择Linux系统和CentOS 64位版本。
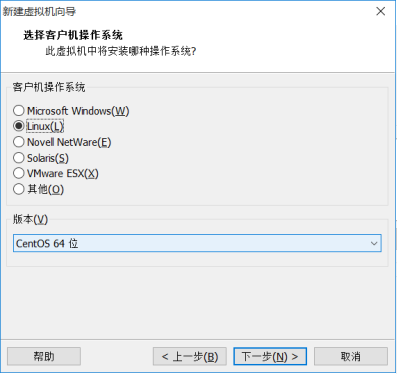
(5)给虚拟机起个名字,给它起个名字,以后会在Vmware左侧显示。并选择主机中Linux系统保存的目录。一台虚拟机应该保存在一个目录下,多个虚拟机不能使用一个目录。
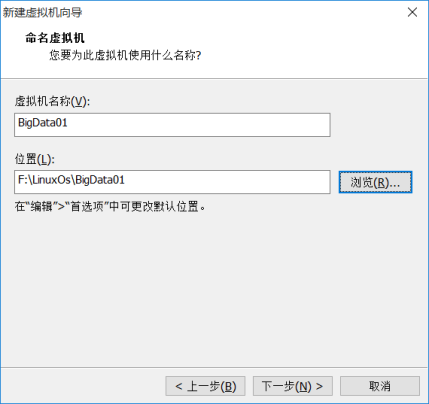
(6) 指定磁盘容量是分配给Linux虚拟机的硬盘大小。默认可以是20G。下一步。
(7) 点击Customize hardware,可以查看和修改虚拟机的硬件配置。我们这里不做修改。
(8)点击Finish创建虚拟机,但是虚拟机还是一个没有操作系统的空壳。接下来,安装操作系统。
(9) 点击Edit virtual machine settings,找到DVD,指定操作系统ISO文件的位置。
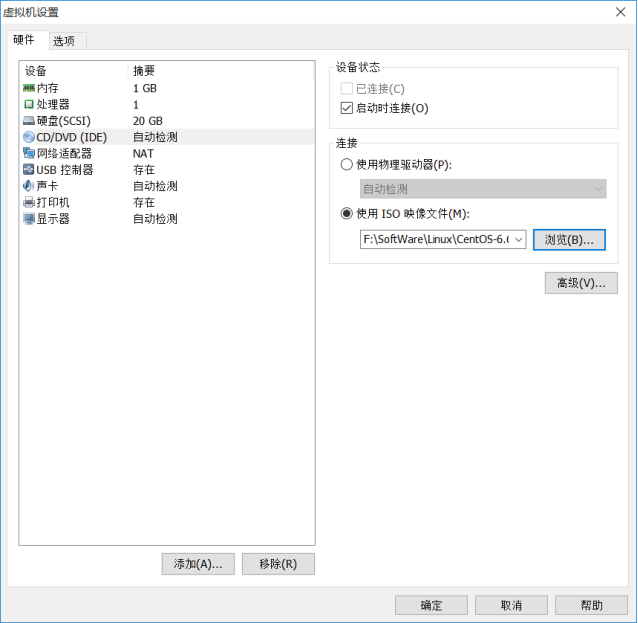
(10)点击启动此虚拟机,选择第一个回车开始安装操作系统。
! zoz100037](https://programming.vip/images/doc/42e24aa756ba06f68ecfd3c0d9cdf314.jpg)
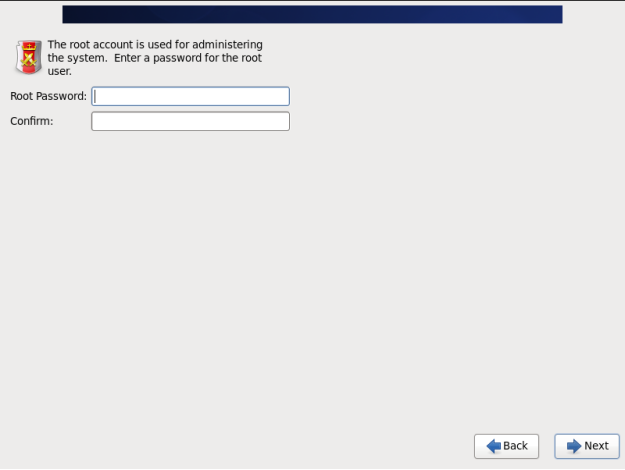
(11) 设置root密码。
(12) 选择桌面,它将安装一个窗口。
(13)首先不要添加普通用户,其他使用默认,然后安装Linux。
3.设置网络
因为在Vmware的NAT设置中关闭了DHCP自动IP分配功能,所以Linux还没有IP。我们需要设置各种网络参数。
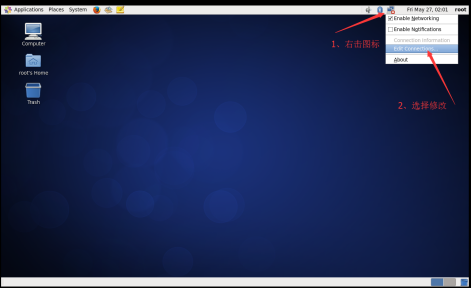
(1)以root进入Xwindow,右击右上角的网络连接图标,选择修改连接。
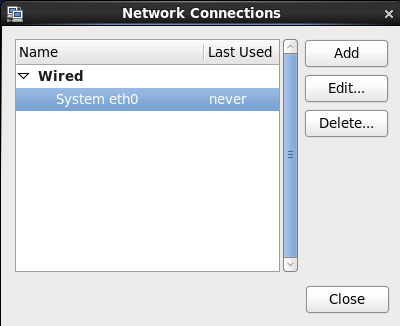
(2)网络连接列出当前Linux中的所有网卡。这里只有一个网卡 System eth0。单击编辑。
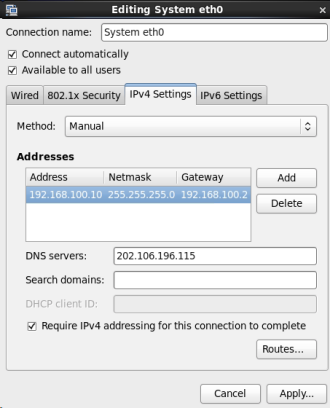
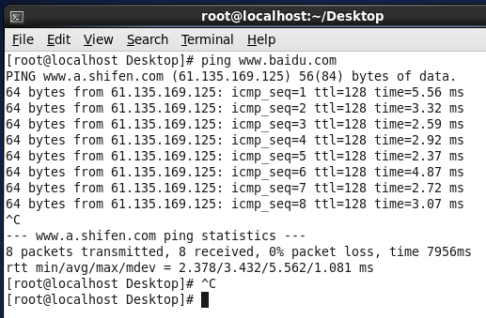
(3)配置IP、子网掩码、网关(与NAT设置相同)、DNS等参数,因为在NAT中网段设置为100.*,所以本机可以设置为192.168.100.10。网关与NAT一致,即192.168.100.2。
(4) 使用ping检查是否可以连接到外网。如下图所示,已经连接成功。
4.修改主机名
临时修改主机名,需要在linux下使用如下指令。
[root@localhost Desktop]# 主机名 mylinux-virtual-machine
要永久修改主机名,需要修改配置文件/etc/sysconfig/network。
[root@mylinux-virtual-machine ~] vi /etc/sysconfig/network
打开文件后,进行以下设置:
NETWORKINGu003dyes #使用网络
HOSTNAMEu003dmylinux-virtual-machine #主机名设置
5.关闭防火墙
学习环境可以直接关闭防火墙。
以root登录后,执行查看防火墙状态。
[root@mylinux-virtual-machine]#service iptables 状态
在某些版本中,默认防火墙是 firewall 或 ufw。
您可以使用临时关闭来关闭防火墙。命令如下。
[root@mylinux-virtual-machine]# service iptables stop
您还可以使用以下命令永久关闭防火墙。
[root@mylinux-virtual-machine]# chkconfig iptables off
关闭防火墙。此设置需要重新启动才能生效。
selinux是Linux的一种子安全机制,可以被学习环境禁用。
禁用 selinux 以编辑 /etc/sysconfig/selinux 文件。打开配置文件/etc/sysconfig/selinu的命令如下。
[hadoop@mylinux-虚拟机]$ vim /etc/sysconfig/selinux
在/etc/sysconfig/selinux文件中设置selinux为disabled,如下。
# 此文件控制系统上 SELinux 的状态。
SELINUXu003d 可以取以下三个值之一:
enforcing - 执行 SELinux 安全策略。
permissive - SELinux 打印警告而不是强制执行。
disabled - 没有加载 SELinux 策略。
SELINUXu003d禁用
SELINUXTYPEu003d 可以采用以下两个值之一:
#targeted - 目标进程受到保护,
mls - 多级安全保护。
SELINUXTYPEu003d目标
6.安装 Java JDK
因为Hadoop底层是用Java实现的,所以需要检查环境中是否安装了Java。
检查是否安装了java JDK。你可以在linux下执行命令。
[root@mylinux-virtual-machine /]# java –version
注意:Hadoop机器上的JDK最好是Oracle的Java JDK,否则会出现一些问题,比如可能没有JPS命令。
如果安装了其他版本的 JDK,请将其卸载。
可以从Oracle官网下载java 8.0以上版本。如下图所示。
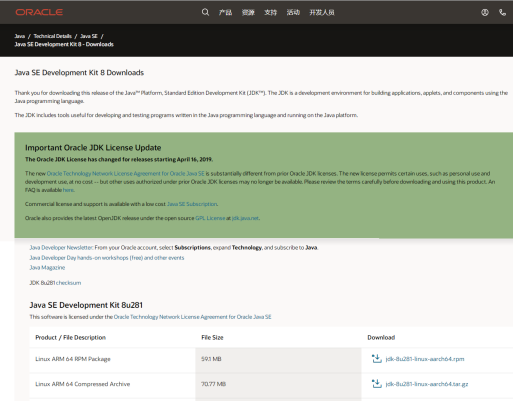
上图中可以下载gz压缩包,在linux下解压。比如解压到/usr/java目录下。 usr 目录存在于 linux 系统本身中。 java目录可以自己创建在usr目录下。 linux下创建usr目录的命令如下。
[root@mylinux-virtual-machine /]# tar -zxvf jdk-8u281-linux-x64.tar.gz -C /usr/java
接下来,添加环境变量。
设置 JDK 环境变量 JAVA_HOME。需要修改配置文件/etc/profile。 linux中的修改命令如下。
[root@mylinux-virtual-machine hadoop]#vi /etc/profile
进入文件后,在文件末尾添加如下内容
导出 JAVA_HOMEu003d"/usr/java/jdk1.8.0_281"
导出 PATHu003d$JAVA_HOME/bin:$PATH
修改后执行source /etc/profile
安装完成后,再次执行java –version,可以看到安装完成了。
[root@mylinux-virtual-machine /]# java -version
java 版本“1.7.0_67”
Java(TM) SE 运行时环境 (build 1.7.0_67-b01)
Java HotSpot(TM) 64 位服务器 VM(构建 24.65-b04,混合模式)
7. Hadoop本地模式安装
Hadoop部署模式包括:本地模式、伪分布式模式、全分布式模式和HA全分布式模式。
区别在于NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程和几台机器上。

本地模式是最简单的模式。所有模块都在 JVM 进程中运行,并使用本地文件系统而不是 HDFS。本地模式主要用于在本地开发过程中运行调试。下载hadoop安装包后,不需要任何设置。默认模式是本地模式。
hadoop安装包可以从官网下载。如下图所示。
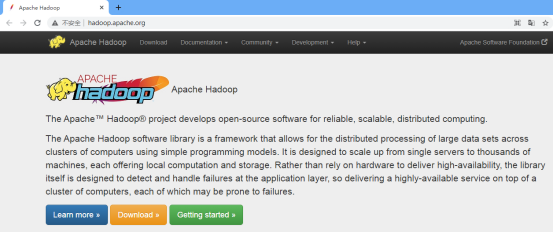
点击官方网站上的“下载”按钮。根据需要选择合适的版本下载,下载后在linux环境下解压压缩包。 linux命令如下。
[hadoop@mylinux-virtual-machine hadoop]# tar -zxvf hadoop-2.7.0.tar.gz -C /usr/hadoop
解压后配置Hadoop环境变量,修改linux下的/etc/profile命令如下。
[hadoop@mylinux-virtual-machine hadoop]# vi /etc/profile
将以下配置信息添加到配置文件中。
导出 HADOOP_HOMEu003d"/opt/modules/hadoop-2.5.0"
导出 PATHu003d$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
执行:source /etc/profile 使配置生效
接下来进入解压目录下的etc/hadoop目录,设置五个文件。
第一步:设置Hadoop env SH文件,修改配置信息中的Java_home参数如下。
导出 JAVA_HOMEu003d"/usr/java/jdk1.8.0_281"
第二步:修改配置核心站点XML文件。修改内容如下。
<配置>
<属性>
<name>fs.defaultFS</name>
<value>hdfs://mylinux-virtual-machine:9000</value>
</属性>
<属性>
<name>hadoop.tmp.dir</name>
<值>/opt/data/tmp</值>
</属性>
</配置>
fs。 defaultfs 参数配置 HDFS 的地址。 hadoop.tmp.dir 配置 Hadoop 临时目录。
第二步:修改HDFS站点XML文件的配置。修改内容如下。
<配置>
<属性>
<name>dfs.replication</name>
<值>1</值>
</属性>
</配置>
dfs.replication 配置 HDFS 存储期间的备份数量。因为这是一个只有一个节点的伪分布式环境,所以设置为1。
Step 4 配置mapred站点xml
默认情况下没有mapred站点的xml文件,但是有一个mapred站点的xml。模板配置模板文件。复制模板以生成 mapred 站点 xml。复制命令如下。
[hadoop@mylinux-virtual-machine hadoop]#cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
在 mapred 站点将以下配置添加到 XML。
<属性>
<name>mapreduce.framework.name</name>
<值>纱线</值>
</属性>
此配置用于指定 mapreduce 在 yarn 框架上运行。
Step 5 配置日元站点xml
在 yarn 站点向 XML 添加配置信息,如下所示。
<配置>
<属性>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</属性>
<属性>
<name>yarn.resourcemanager.hostname</name>
<value>mylinux-虚拟机</value>
</属性>
</配置>
纱。节点管理器。 aux services配置yarn的默认shuffle方式,选择mapreduce的默认shuffle算法。
yarn.resourcemanager.hostname 指定运行资源管理器的节点。
这五步的配置文件信息配置成功后,格式化HDFS。 linux系统中格式化HDFS的说明如下。
hdfs 名称节点-格式
执行该命令后,服务启动时会提示输入三次密码。执行后,让 jps 显示进程信息,如下图所示。
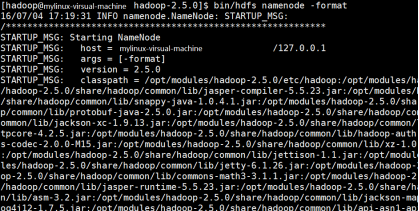
如果您在此消息中找到“has Success”信息,则证明hadoop格式已成功。
格式化就是对分布式文件系统HDFS中的DataNode进行阻塞,统计所有阻塞后的初始元数据,存储在NameNode中。
格式化后,查看核心站点Hadoop.xml tmp。 dir指定的目录下是否有dfs目录(本例为/opt/data目录)。如果是,则说明格式化成功。
启动hadoop平台,可以先启动hdfs。该命令的执行路径在提取的hadoop路径中的/sbin目录下。具体启动方式在linux中执行如下。
[hadoop@mylinux-virtual-machine sbin]#./start-dfs.sh
执行结果如图所示。
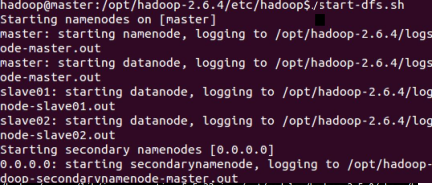
启动hdfs后,可以使用jsp查看进程,如图。
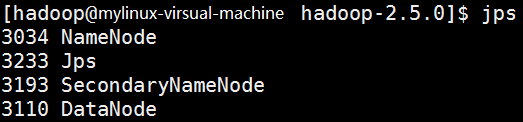
从图中可以看出,NameNode、SecondNameNode和DataNode已经在这个过程中启动了。
接下来继续启动yarn框架。启动目录还是在提取的hadoop路径下的/sbin目录下。具体启动方式在linux中执行如下。
[hadoop@mylinux-virtual-machine sbin]#./start-yarn.sh
执行结果如图所示。
! zoz100076](https://programming.vip/images/doc/32f98a605a1717b13522c6f8a0af6e31.jpg)
启动yarn服务后,继续使用jps查看进程信息,如下图所示。
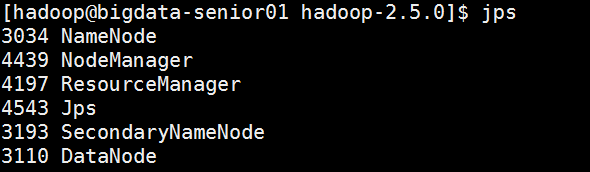
至此,Hadoop环境搭建完成。
3、Spark平台环境搭建
它是当今企业中最有效的数据处理框架。使用 Spark 的成本很高,因为它需要大量内存进行计算,但它仍然是数据科学家和大数据工程师的最爱。
下载spark压缩包需要访问Spark官网。

进入网站后,选择“下载”选项下载指定版本。
下载后在linux平台解压,解压到usr目录下的spark自定义目录下。 linux命令如下。
[hadoop@mylinux-virtual-machine hadoop]# tar -zxvf spark-3.1.1-bin-hadoop2.7.tgz -C /usr/spark
接下来,打开 Spark 配置目录并复制默认的 Spark 环境模板。已经发布为 Spark env 的 sh.template 的形式出现了。使用 cp 命令复制一个副本,并从生成的副本中删除“.template”。 linux命令如下。
[hadoop@mylinux-virtual-machine sbin]#cd /usr/lib/spark/conf/
[hadoop@mylinux-virtual-machine conf]#cp spark-env.sh.template spark-env.sh
[hadoop@mylinux-virtual-machine conf]# vi spark-env.sh
将信息添加到文件
导出 JAVA_HOMEu003d/usr/java/jdk1.8.0_281
导出 HADOOP_HOMEu003d/usr/hadoop/hadoop-2.7.0
导出 PYSPARK_PYTHONu003d/usr/bin/python3
配置信息中,JAVAHOME和hadoop是java和hadoop的路径变量,PYSPARK_PYTHON是Python与pyspark联系的变量信息,/usr/bin/python是linux中python3的路径。你可以通过这样的路径操作来看看是否能找到python3。
5、经典大数据wordCount程序
要了解大数据平台,我们需要对大数据平台进行数据分析。大数据平台的数据分析流程如下图所示。
! zwz 100085 zwz 100086 zwz 100084
图中所示的分析过程中最重要的程序是WordCount程序。 WordCount 程序完全来源于 MapReduce 的分布式计算思想。先解释一下MapReduce的计算思路。
首先看下图。
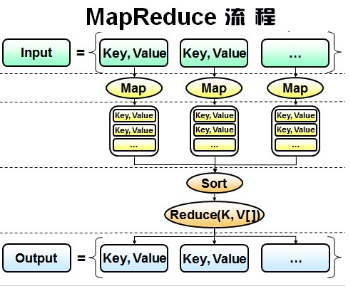
从流程可以看出MapReduce有两个阶段。在Map阶段,首先将输入的大数据文件的切片处理成键值对的形式,然后对每个值对调用Map任务,通过Map任务处理成新的键值对。数据分析的大部分分析思想是分组、排序、汇总和统计。 MapReduce的reduce阶段也是一个分组、排序、汇总和统计阶段。最后,它作为值对的数据集输出。
对于WordCount程序来说,就是统计分布式文件系统中的字数。其输入内容和输出格式如下图所示。
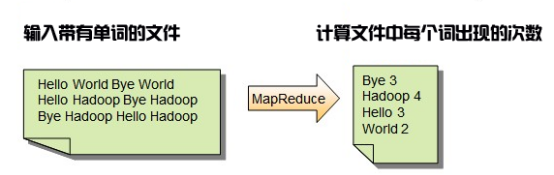
从图中可以看出,输入文件中每个由英文单词组成的句子最终都经过MapReduce过程进行处理,输出文件中每个单词出现的次数。
使用 MapReduce 进程处理此类 wordCount 程序的思路如下图所示。
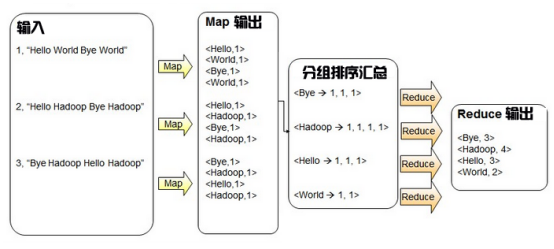
从图中可以看出,输入是每行包含英文单词的句子。经过Map处理后,就变成了英文单词和计数公式的值对。此键值格式仅用于计数。 “<你好,1>”表示有一个“你好”。后面的计数过程中会出现“<Hello, 1>”和一个“hello”,这里只需要按照空格对英文句子进行分词,为每个单词构造(Hello, 1)的格式。 Map处理后的输出结果以key的形式进行分组,即以“hello”为key进行分组,对后续数据进行汇总、统计、求和。最后通过Reduce过程生成汇总统计后的输出结果。
这是代码。
使用 PySpark 时必须实例化 SparkSession 的 Spark 对话。具体实例化格式如下。
SparkSession.builder.master("local").appName("wordCount").getOrCreate()
Builder是指SparkSession是通过静态类builder实例化的。调用builder后,可以调用builder静态类中的很多方法。
master 函数设置 Spark 主 URL 连接。例如“local”设置为在本地运行,“local[4]”在本地运行4核,或者“spark://master:7077”在spark独立集群中运行。
appName(String name) 函数用于设置应用程序名称,该名称将显示在 Spark Web UI 中。
getOrCreate() 获取获取到的SparkSession,如果不存在则根据builder选项新建一个SparkSession。
SparkSession对话框建立后,sparkcontext是第一个用来编写spark程序的类。 SparkContext是Spark Program的主要入口,所以SparkSession建立对话后,获取对话变量sparkcontext program。具体代码如下:
从 pyspark.sql 导入 SparkSession
sparku003dSparkSession.builder.master("local").appName("wordCount").getOrCreate()
scu003dspark.sparkContext
有了Spark程序的入口sparkContext,要完成数据分析的工作,首先要读取要分析的文件,加载一个文件来创建RDD。 RDD 是 Spark 中最基本的数据抽象。 RDD(Resilient Distributed Dataset)被称为弹性分布式数据集,它代表了一个不可变的、可分割的、并行计算的元素集合。 Spark 有一个 collect 方法,可以将 RDD 类型的数据转换成数组进行展示。如果要显示读取的RDD数据,可以使用textFile读取hdfs中的数据,然后通过collect方法显示。 textFile默认从hdfs读取文件,也可以指定sc.textFile("path") 在path前添加hdfs://表示从hdfs文件系统读取数据。具体代码如下。
从 pyspark.sql 导入 SparkSession
sparku003dSparkSession.builder.master("local").appName("wordCount").getOrCreate()
scu003dspark.sparkContext
filesu003dsc.textFile("hdfs://mylinux-virtual-machine:9000/words.txt")
打印(文件。收集())
代码中,通过textFile Txt文件读取hdfs服务器上的话。读取后是RDD类型的数据,通过files的collect()方法转换成数组,通过print方法打印出来。运行结果如下。

从图中的结果可以看出,文件中的数据已经被读出并形成了一个列表。通过遍历读取的RDD,可以对RDD中的每一个数据进行操作。
spark中有两个非常重要的函数:map函数和flatMap函数,这是两个常用的函数。之中
map:对集合中的每个元素进行操作。
flatMap:集合中的每个元素都被操作然后展平。
如果使用collect()方法通过map操作显示之前读取的RDD的具体内容,代码如下。
从 pyspark.sql 导入 SparkSession
sparku003dSparkSession.builder.master("local").appName("wordCount").getOrCreate()
scu003dspark.sparkContext
filesu003dsc.textFile("hdfs://mylinux-virtual-machine:9000/words.txt")
地图_filesu003dfiles.map(lambda x:x.split(" "))
打印(地图_文件)
运行结果如下:

如果之前使用flatMap操作读取RDD,然后使用collect()方法显示具体内容,代码如下。
从 pyspark.sql 导入 SparkSession
sparku003dSparkSession.builder.master("local").appName("wordCount").getOrCreate()
scu003dspark.sparkContext
filesu003dsc.textFile("hdfs://mylinux-virtual-machine:9000/words.txt")
flatmap_filesu003dfiles.flatMap(lambda x:x.split(" "))
打印(平面图_文件)
运行结果如下:
! swz 100103 swz 100104 swz 100102
根据每个元素上两个不同操作的返回结果集:map和flatMap,可以看出flatMap的返回结果更符合wordCount问题的预期。然后将flatMap返回的结果集以计数键值对的形式处理成(hello, 1), (java, 1), (android, 1)等形式。代码如下。
从 pyspark.sql 导入 SparkSession
sparku003dSparkSession.builder.master("local").appName("wordCount").getOrCreate()
scu003dspark.sparkContext
filesu003dsc.textFile("hdfs://mylinux-virtual-machine:9000/words.txt")
flatmap_filesu003dfiles.flatMap(lambda x:x.split(" "))
地图_filesu003d平面图_files.map(lambda x:(x,1))
打印(地图_files.collect())
运行结果如下。
! swz 100106 swz 100107 swz 100105
如上图构造好keyValue数据后,使用spark中的reduceByKey方法。 reduceByKey 是对元素为 KV 对的 RDD 中具有相同 key 的元素的 Value 进行函数 reduce 操作。因此,具有相同 key 的多个元素的 value 被缩减为一个 Value,然后与原始 RDD 中的 key 形成新的 KV 对。这里实现的是同一个key对应的values的求和,可以通过lambda函数来完成。代码如下。
从 pyspark.sql 导入 SparkSession
sparku003dSparkSession.builder.master("local").appName("wordCount").getOrCreate()
scu003dspark.sparkContext
filesu003dsc.textFile("hdfs://mylinux-virtual-machine:9000/words.txt")
flatmap_filesu003dfiles.flatMap(lambda x:x.split(" "))
地图_filesu003d平面图_files.map(lambda x:(x,1))
freduce_mapu003dmap_files.reduceByKey(lambda x,y:x+y)
打印(减少\map.collect())
程序的最终输出如图所示。
! swz 100109 swz 100110 swz 100108
视频讲解地址:
1\。 pyspark分析大数据1-hadoop环境搭建:https://www.bilibili.com/video/BV1Z54y1L7cT/
2\。 pyspark分析大数据2-mapreduce流程:https://www.bilibili.com/video/BV15V411J75a/
3\。 Pyspark分析大数据3-pyspark分析wordcount程序及扩展:https://www.bilibili.com/video/BV1y64y1m7XN/

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20422条内容
已为社区贡献20422条内容

所有评论(0)