kafka的简单介绍以及docker-compose部署单主机Kafka集群
Kafka简单介绍Kafka是由Apache软件基金会开发的一个分布式、分区的、多副本的、多订阅者的开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Ha
Kafka简单介绍
Kafka是由Apache软件基金会开发的一个分布式、分区的、多副本的、多订阅者的开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
主要特性
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量 :即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持Hadoop并行数据加载。
- 发布和订阅消息流(类似于消息队列或者企业级的消息系统)
- 以容错的、持久的方式存储消息流
- 当消息流到来的时候,处理消息
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输
- 同时支持离线数据处理和实时数据处理
应用场景
- 数据推送
- 作为大缓冲区使用
- 日志收集(scribe或者nginx)
- 服务中间件
kafka架构

Broker
代理,用来存储消息,Kafka集群中的每一个服务器都是一个代理(Broker),消费者将从broker拉取订阅的消息
Producer
向Kafa发送消息的进程,生产者会根据topic分布消息。生产者也负责把消息关联到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。算法由开发者定义。
Cousumer
Consermer实例可以是独立的进程,负责订阅和消费消息。消费者用consumerGroup来标识自己。同一个消费组可以并发地消费多个分区的消息,同一个partition也可以由多个consumerGroup并发消费,但是在consumerGroup中一个partition只能由一个consumer消费
CousumerGroup
Consumer Group:同一个Consumer Group中的Consumers,Kafka将相应Topic中的每个消息只发送给其中一个Consumer
主题、分区和副本(Topic,Partition,replication)
对于每个topic,Kafka都用分区的的方法维护(如下图)

Topic
消息的类别。Kafka中可以将Topic从物理上划分成一个或多个分区(Partition),每个分区在物理上对应一个文件夹,以”topicName_partitionIndex”的命名方式命名,该dir包含了这个分区的所有消息(.log)和索引文件(.index),这使得Kafka的吞吐率可以水平扩展。
producer在发布消息的时候,可以为每条消息指定Key,这样消息被发送到broker时,会根据分区算法把消息存储到对应的分区中(一个分区存储多个消息),如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡。
事件被组织并持久地存储在Topic中,Topic类似于文件系统中的文件夹,事件就是该文件夹中的文件。Kafka中的Topic始终是多生产者和多订阅者:一个Topic可以有零个、一个或多个生产者向其写入事件,也可以有零个、一个或多个消费者订阅这些事件。Topic中的事件可以根据需要随时读取,与传统的消息中间件不同,事件在使用后不会被删除,相反,可以通过每个Topic的配置来定义Kafka应该保留事件的时间,之后旧事件将被丢弃。Kafka的性能在数据大小方面实际上是恒定的,因此长时间存储数据是非常好的。
Partition
对Topic中的消息做水平切分,每块称为一个Partition。这意味着一个Topic可以分布在多个Kafka节点上。每个分区都是一个 顺序的、不可变的消息队列, 并且可以持续的添加;分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
数据的这种分布式放置对于可伸缩性非常重要,因为它允许客户端应用程序同时从Kafka节点读取和写入数据。将新事件发布到Topic时,它实际上会appended到Topic的一个Partition中。具有相同事件key的事件将写入同一Partition,Kafka保证给定Topic的Partition的任何使用者都将始终以与写入时完全相同的顺序读取该分区的事件。
Replication
为了使数据具有容错性和高可用性,每个Topic都可以有多个Replication,以便始终有多个Kafka节点具有数据副本,以防出现问题。常见的生产设置是replicationFactor为3,即始终有三份数据副本(包括一份原始数据)。此Replication在Topic的Partition级别执行。
Kafka在指定数量(通过replicationFactor)的服务器上复制每个Topic的Partition,这允许在集群中的某些服务器发生故障时进行自动故障转移,以便在出现故障时服务仍然可用。Replication的单位是Topic的Partition。在非故障条件下,Kafka中的每个Partition都有一个leader和零个或多个follower。replicationFactor是复制副本(包括leader)的总数。所有读和写操作都将转到Partition的leader上。通常,有比Kafka节点多得多的Partition,并且这些Partition的leader在Kafka节点之间均匀分布。follower上的数据需要与leader的数据同步,所有数据都具有相同的偏移量和顺序(当然,在任何给定时间,leader的数据末尾可能有一些尚未复制的数据)。follower会像普通Kafka消费者一样使用来自leader的消息,并将其应用到自己的数据中。如下图所示,三个Kafka节点上有两个Topic(Topic 0和Topic 1),Topic 0有两个Partition并且replicationFactor为3(红色的Partition为leader),Topic 1有三个Partition,replicationFactor也为3(红色的Partition为leader)。

消费序列
无论消息是否被消费了,Kafka集群都会保存所有的消息,直到它们过期 。比如我们配置一个消息的有效期为两天,那么消息发布的两天内,consumer可以消费消息,而超出时间后,消息将被丢弃以释放空间。那么Kafa怎么知道消费到哪儿了呢?每个消费者都维护着一个元数据(偏移量,消费者的消费进度)。这个offset由消费者控制:当consumer消费消息的时候,偏移量也线性地增加。但是偏移量由消费者控制,所以消费者能够把偏移量重置为一个更老的,以便重新读取。此外,由于偏移量由消费者控制offset, 一个消费者的操作不会影响其它消费者对此log的处理。
这些特点使得Kafka消费者的成本很低,他们可以来取自如的消费消息,而且不影响其他消费者,这样,我们可以用tail命令处理任何topic,而不需要改变这些消息。再说说分区。Kafka中采用分区的设计有以下好处。一是可以水平扩展,不受单台服务器的限制;Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元,稍后会谈到这一点。
分布式
log的分区被分散的存储在Kafka集群中,每个服务器只处理分配到它机器上的partitions。此外,partation会根据配置备份到其他server以实现容错性。每个分区,只有一个server可以作为partation Leader,其他的都将作为follower。leader负责处理partation的读写请求,followers被动的同步数据,以便在leader挂掉的时候,升级为leader。需要知道的是,每个server都是一些分区的leader,同事又是其他分区的flowwer,以更好地实现负载均衡,避免热点问题。
异地同步
Kafka MirrorMaker为群集提供geo-replication支持。借助MirrorMaker,消息可以跨多个数据中心或云区域进行复制、同步。 我们可以利用它在active/passive场景中备份和恢复; 或者在active/passive方案中将数据置于更接近用户的位置,或数据本地化。
保证
- 消息将会以被sent的顺序添加到partition Log中
- 消费者将先看到先加入到partition Log中的消息
- 对于一个topic的消息,如果备份数为N,系统最多容许有N-1台失败,而不丢失commit到log的消息
kafka的优点
Kafka作为一个消息系统与传统的企业级消息系统相比,Kafka如何?
传统的消息系统有两种模型:
- 队列模型:一组消费者去消费server上的消息,但是一个消息只能被一个consumer消费
- 发布-订阅模型: 每个消息都会广播到每个消费者,即每个消费者都会消费
队列模型让多个consumer瓜分消息并消费,这样可以很好地水平扩展,提高性能,但和队列模型不同的是,消息一旦被读取就会被干掉,因此有丢数据的风险;发布订阅模型会把每个消息都广播给订阅者,因为不方便做水平扩展。
Kafka同时具备队列模型和发布-订阅模型,你不必纠结于消息系统模型的二选一
Kafka的 consumerGroup结合上这两中模型:队列模型-同一group中,一个messgae只有一个consumer消费,消息多的时候,往group中添加consumer就好,容易扩展;发布订阅模型:同一个消息可以被广播到不同的consumerGroup中。
kafka有更强的顺序保证机制
传统的消息队列按序保存消息,如果有多个消费者从队列消费消息,server将会按照顺序把消息移出队列,不幸的是,即使server顺序移出消息,但是消息到达consumers的过程是异步的,所以他们真正抵达消费者的顺序与stored进队列时不同,消息系统的解决方案是只让一个consumer去消费这个队列,然而这又违背了并发。
这方面,Kafka做的更好,通过分区概念,在一个topic下,Kafka能同时满足
- 顺序保证:同一个partition的消息只能由group中的一个consumer消费
- 负载均衡:由于有多个partition,所以仍然具有并发性
需要注意的是,group中的consumer数不能大于partition,否则会造成空闲
Kafka作为一个存储系统
任何允许把发布消息和消费消息过程解耦的消息队列,本质上都充当了存储系统,不同的是,Kafka是一个高性能的存储系统:
- 写到kafka的数据会被写到硬盘,并且备份,以实现容错。Kafka允许生产者等待消息应答,直到完成备份,保证持久化了。
- Kafka的硬盘结构可以水平扩展,无论你的server是50K还是50T,都可以很好的执行
由于重视存储并且允许client去控制读取位置,你还可以认为kafka是一种具备高性能,低延迟,提交日志存储,复制,和传播特性的分布式文件系统
Kafka流处理
不只是读写和存储数据,Kafka的目标是能够实时流处理。在kafka中,流处理持续获取输入topic的数据,进行处理加工,然后写入输出topic。例如,一个零售APP,接收销售和出货的输入流,统计数量或调整价格后输出。
批处理
把消息、存储、流处理组合在一起似乎并不常见,但对于Kafka来说是非常有必要的,因为它的目标是做一个流平台。
类似于HDFS的分布式文件系统允许存储静态文件来进行批处理。这种系统能够有效地存储和处理历史数据; 传统的消息系统允许你处理订阅topic之后才到达的topic消息。Kafka结合了这两种能力,这种组合对于kafka作为流处理应用的平台和流数据管道的平台是至关重要的。
作为流式应用程序,Kafka通过组合存储和低延迟订阅,可用相同的方式处理过去和未来的数据。 这意味着一个单一的应用程序可以处理历史记录的数据,并且在到达最后一条记录时不用结束,而是等待future data。
作为流数据管道,Kafka能够订阅实时事件,因此Kafka可作为低延迟的管道; 同时Kafka可靠存储数据的特性使得它能够存储一些要求较高的数据(保证安全送达or系统因维护下线一段时间也不会丢数据)。
部署kafka服务
kafka需要依赖zookeeper做配置管理,leader选举和服务发现,所以需要搭建zookeeper服务。
Docker-compose部署单主机zookeeper集群
拉取kafka可用镜像
先搜索有哪些kafka镜像可以用
docker search kafka

我拉取Stars数目最高的镜像
不指定版本号就是拉取最新版本镜像。
docker pull wurstmeister/kafka
拉取一个kafka管理器
docker pull sheepkiller/kafka-manager
运行一个简单的kafka容器
创建zookeeper文件夹
mkdir -p /usr/local/zookeeper/zookeeper-1/data
mkdir -p /usr/local/zookeeper/zookeeper-1/datalog
mkdir -p /usr/local/zookeeper/zookeeper-1/logs
mkdir -p /usr/local/zookeeper/zookeeper-1/conf
创建kafka文件夹
mkdir -p /usr/local/kafka
mkdir -p /usr/local/kafka/kafka-1/logs
mkdir -p /usr/local/kafka/kafka-2/logs
mkdir -p /usr/local/kafka/kafka-3/logs
赋予这个文件夹的读写可执行权限(这个写法比较暴力,实际工作不可取)
文件所有者(Owner)、用户组(Group)、其它用户(Other Users)都赋予了最高权限
chmod -R 777 /usr/local/kafka
chmod -R 777 /usr/local/zookeeper
先运行一个zookeeper
像Docker-compose部署单主机zookeeper集群这篇博客一样,将一些配置文件放到宿主机的如下所示相应文件夹下面(只用放conf下面的哪些配置文件就行了)
docker run -itd --name zookeeper-1 -p 2181:2181 \
-v /usr/local/zookeeper/zookeeper-1/data:/data \
-v /usr/local/zookeeper/zookeeper-1/datalog:/datalog \
-v /usr/local/zookeeper/zookeeper-1/logs:/logs \
-v /usr/local/zookeeper/zookeeper-1/conf:/conf \
zookeeper
再运行一个kafka
docker run -itd --name kafka-1 -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=81.68.82.48:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://81.68.82.48:9092 -e KAFKA_LISTENERS=PLAINTEXT://localhost:9092 -t wurstmeister/kafka
- -e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
- -e KAFKA_ZOOKEEPER_CONNECT 配置zookeeper管理kafka的路径
- -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT 把kafka的地址端口注册给zookeeper
- -e KAFKA_LISTENERS=PLAINTEXT 配置kafka的监听端口
创建成功之后,可以使用docker exec 命令或者docker 可视化界面工具portainer进入容器查看

可以自己进入里面查看文件结构以及文件内容
重要配置文件详解
1.server.properties配置文件
| 属性 | 默认值 | 描述 |
|---|---|---|
| broker.id | 必填参数,broker的唯一标识 | |
| log.dirs | /tmp/kafka-logs | Kafka数据存放的目录。可以指定多个目录,中间用逗号分隔,当新partition被创建的时会被存放到当前存放partition最少的目录。 |
| port | 9092 | BrokerServer 接受客户端连接的端口号 |
| zookeeper.connect | null | Zookeeper的连接串,格式为:hostname1:port1,hostname2:port2,hostname3:port3。可以填一个或多个,为了提高可靠性,建议都填上。注意,此配置允许我们指定一个zookeeper路径来存放此kafka集群的所有数据,为了与其他应用集群区分开,建议在此配置中指定本集群存放目录,格式为:hostname1:port1,hostname2:port2,hostname3:port3/chroot/path 。需要注意的是,消费者的参数要和此参数一致。 |
| message.max.bytes | 1000000 | 服务器可以接收到的最大的消息大小。注意此参数要和consumer的maximum.message.size大小一致,否则会因为生产者生产的消息太大导致消费者无法消费。 |
| num.io.threads | 8 | 服务器用来执行读写请求的IO线程数,此参数的数量至少要等于服务器上磁盘的数量。 |
| queued.max.requests | 500 | I/O线程可以处理请求的队列大小,若实际请求数超过此大小,网络线程将停止接收新的请求。 |
| socket.send.buffer.bytes | 100 * 1024 | The SO_SNDBUFF buffer the server prefers for socket connections. |
| socket.receive.buffer.bytes | 100 * 1024 | The SO_RCVBUFF buffer the server prefers for socket connections. |
| socket.request.max.bytes | 100 * 1024 * 1024 | 服务器允许请求的最大值, 用来防止内存溢出,其值应该小于 Java heap size. |
| num.partitions | 1 | 默认partition数量,如果topic在创建时没有指定partition数量,默认使用此值,建议改为5 |
| log.segment.bytes | 1024 * 1024 * 1024 | Segment文件的大小,超过此值将会自动新建一个segment,此值可以被topic级别的参数覆盖。 |
| log.roll.{ms,hours} | 24 * 7 hours | 新建segment文件的时间,此值可以被topic级别的参数覆盖。 |
| log.retention.{ms,minutes,hours} | 7 days | Kafka segment log的保存周期,保存周期超过此时间日志就会被删除。此参数可以被topic级别参数覆盖。数据量大时,建议减小此值。 |
| log.retention.bytes | -1 | 每个partition的最大容量,若数据量超过此值,partition数据将会被删除。注意这个参数控制的是每个partition而不是topic。此参数可以被log级别参数覆盖。 |
| log.retention.check.interval.ms | 5 minutes | 删除策略的检查周期 |
| auto.create.topics.enable | true | 自动创建topic参数,建议此值设置为false,严格控制topic管理,防止生产者错写topic。 |
| default.replication.factor | 1 | 默认副本数量,建议改为2。 |
| replica.lag.time.max.ms | 10000 | 在此窗口时间内没有收到follower的fetch请求,leader会将其从ISR(in-sync replicas)中移除。 |
| replica.lag.max.messages | 4000 | 如果replica节点落后leader节点此值大小的消息数量,leader节点就会将其从ISR中移除。 |
| replica.socket.timeout.ms | 30 * 1000 | replica向leader发送请求的超时时间。 |
| replica.socket.receive.buffer.bytes | 64 * 1024 | The socket receive buffer for network requests to the leader for replicating data. |
| replica.fetch.max.bytes | 1024 * 1024 | The number of byes of messages to attempt to fetch for each partition in the fetch requests the replicas send to the leader. |
| replica.fetch.wait.max.ms | 500 | The maximum amount of time to wait time for data to arrive on the leader in the fetch requests sent by the replicas to the leader. |
| num.replica.fetchers | 1 | Number of threads used to replicate messages from leaders. Increasing this value can increase the degree of I/O parallelism in the follower broker. |
| fetch.purgatory.purge.interval.requests | 1000 | The purge interval (in number of requests) of the fetch request purgatory. |
| zookeeper.session.timeout.ms | 6000 | ZooKeeper session 超时时间。如果在此时间内server没有向zookeeper发送心跳,zookeeper就会认为此节点已挂掉。 此值太低导致节点容易被标记死亡;若太高,.会导致太迟发现节点死亡。 |
| zookeeper.connection.timeout.ms | 6000 | 客户端连接zookeeper的超时时间。 |
| zookeeper.sync.time.ms | 2000 | H ZK follower落后 ZK leader的时间。 |
| controlled.shutdown.enable | true | 允许broker shutdown。如果启用,broker在关闭自己之前会把它上面的所有leaders转移到其它brokers上,建议启用,增加集群稳定性。 |
| auto.leader.rebalance.enable | true | If this is enabled the controller will automatically try to balance leadership for partitions among the brokers by periodically returning leadership to the “preferred” replica for each partition if it is available. |
| leader.imbalance.per.broker.percentage | 10 | The percentage of leader imbalance allowed per broker. The controller will rebalance leadership if this ratio goes above the configured value per broker. |
| leader.imbalance.check.interval.seconds | 300 | The frequency with which to check for leader imbalance. |
| offset.metadata.max.bytes | 4096 | The maximum amount of metadata to allow clients to save with their offsets. |
| connections.max.idle.ms | 600000 | Idle connections timeout: the server socket processor threads close the connections that idle more than this. |
| num.recovery.threads.per.data.dir | 1 | The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. |
| unclean.leader.election.enable | true | Indicates whether to enable replicas not in the ISR set to be elected as leader as a last resort, even though doing so may result in data loss. |
| delete.topic.enable | false | 启用deletetopic参数,建议设置为true。 |
| offsets.topic.num.partitions | 50 | The number of partitions for the offset commit topic. Since changing this after deployment is currently unsupported, we recommend using a higher setting for production (e.g., 100-200). |
| offsets.topic.retention.minutes | 1440 | Offsets that are older than this age will be marked for deletion. The actual purge will occur when the log cleaner compacts the offsets topic. |
| offsets.retention.check.interval.ms | 600000 | The frequency at which the offset manager checks for stale offsets. |
| offsets.topic.replication.factor | 3 | The replication factor for the offset commit topic. A higher setting (e.g., three or four) is recommended in order to ensure higher availability. If the offsets topic is created when fewer brokers than the replication factor then the offsets topic will be created with fewer replicas. |
| offsets.topic.segment.bytes | 104857600 | Segment size for the offsets topic. Since it uses a compacted topic, this should be kept relatively low in order to facilitate faster log compaction and loads. |
| offsets.load.buffer.size | 5242880 | An offset load occurs when a broker becomes the offset manager for a set of consumer groups (i.e., when it becomes a leader for an offsets topic partition). This setting corresponds to the batch size (in bytes) to use when reading from the offsets segments when loading offsets into the offset manager’s cache. |
| offsets.commit.required.acks | -1 | The number of acknowledgements that are required before the offset commit can be accepted. This is similar to the producer’s acknowledgement setting. In general, the default should not be overridden. |
| offsets.commit.timeout.ms | 5000 | The offset commit will be delayed until this timeout or the required number of replicas have received the offset commit. This is similar to the producer request timeout. |
2.producer.properties配置文件
| 属性 | 默认值 | 描述 |
|---|---|---|
| metadata.broker.list | 启动时producer查询brokers的列表,可以是集群中所有brokers的一个子集。注意,这个参数只是用来获取topic的元信息用,producer会从元信息中挑选合适的broker并与之建立socket连接。格式是:host1:port1,host2:port2。 | |
| request.required.acks | 0 | 参见3.2节介绍 |
| request.timeout.ms | 10000 | Broker等待ack的超时时间,若等待时间超过此值,会返回客户端错误信息。 |
| producer.type | sync | 同步异步模式。async表示异步,sync表示同步。如果设置成异步模式,可以允许生产者以batch的形式push数据,这样会极大的提高broker性能,推荐设置为异步。 |
| serializer.class | kafka.serializer.DefaultEncoder | 序列号类,.默认序列化成 byte[] 。 |
| key.serializer.class | Key的序列化类,默认同上。 | |
| partitioner.class | kafka.producer.DefaultPartitioner | Partition类,默认对key进行hash。 |
| compression.codec none | 指定producer消息的压缩格式,可选参数为: “none”, “gzip” and “snappy”。关于压缩参见4.1节 | |
| compressed.topics | null | 启用压缩的topic名称。若上面参数选择了一个压缩格式,那么压缩仅对本参数指定的topic有效,若本参数为空,则对所有topic有效。 |
| message.send.max.retries | 3 | Producer发送失败时重试次数。若网络出现问题,可能会导致不断重试。 |
| retry.backoff.ms | 100 | Before each retry, the producer refreshes the metadata of relevant topics to see if a new leader has been elected. Since leader election takes a bit of time, this property specifies the amount of time that the producer waits before refreshing the metadata. |
| topic.metadata.refresh.interval.ms | 600 * 1000 | The producer generally refreshes the topic metadata from brokers when there is a failure (partition missing, leader not available…). It will also poll regularly (default: every 10min so 600000ms). If you set this to a negative value, metadata will only get refreshed on failure. If you set this to zero, the metadata will get refreshed after each message sent (not recommended). Important note: the refresh happen only AFTER the message is sent, so if the producer never sends a message the metadata is never refreshed |
| queue.buffering.max.ms | 5000 | 启用异步模式时,producer缓存消息的时间。比如我们设置成1000时,它会缓存1秒的数据再一次发送出去,这样可以极大的增加broker吞吐量,但也会造成时效性的降低。 |
| queue.buffering.max.messages | 10000 | 采用异步模式时producer buffer 队列里最大缓存的消息数量,如果超过这个数值,producer就会阻塞或者丢掉消息。 |
| queue.enqueue.timeout.ms | -1 | 当达到上面参数值时producer阻塞等待的时间。如果值设置为0,buffer队列满时producer不会阻塞,消息直接被丢掉。若值设置为-1,producer会被阻塞,不会丢消息。 |
| batch.num.messages | 200 | 采用异步模式时,一个batch缓存的消息数量。达到这个数量值时producer才会发送消息。 |
| send.buffer.bytes | 100 * 1024 | Socket write buffer size |
| client.id | “” | The client id is a user-specified string sent in each request to help trace calls. It should logically identify the application making the request. |
3.consumer.properties配置文件
| 属性 | 默认值 | 描述 |
|---|---|---|
| group.id | Consumer的组ID,相同goup.id的consumer属于同一个组。 | |
| zookeeper.connect | Consumer的zookeeper连接串,要和broker的配置一致。 | |
| consumer.id | null | 如果不设置会自动生成。 |
| socket.timeout.ms | 30 * 1000 | 网络请求的socket超时时间。实际超时时间由max.fetch.wait + socket.timeout.ms 确定。 |
| vsocket.receive.buffer.bytes | 64 * 1024 | The socket receive buffer for network requests. |
| fetch.message.max.bytes | 1024 * 1024 | 查询topic-partition时允许的最大消息大小。consumer会为每个partition缓存此大小的消息到内存,因此,这个参数可以控制consumer的内存使用量。这个值应该至少比server允许的最大消息大小大,以免producer发送的消息大于consumer允许的消息。 |
| num.consumer.fetchers | 1 | The number fetcher threads used to fetch data. |
| auto.commit.enable | true | 如果此值设置为true,consumer会周期性的把当前消费的offset值保存到zookeeper。当consumer失败重启之后将会使用此值作为新开始消费的值。 |
| auto.commit.interval.ms | 60 * 1000 | Consumer提交offset值到zookeeper的周期。 |
| queued.max.message.chunks | 2 | 用来被consumer消费的message chunks 数量, 每个chunk可以缓存fetch.message.max.bytes大小的数据量。 |
| auto.commit.interval.ms | 60 * 1000 | Consumer提交offset值到zookeeper的周期。 |
| queued.max.message.chunks | 2 | 用来被consumer消费的message chunks 数量, 每个chunk可以缓存fetch.message.max.bytes大小的数据量。 |
| fetch.min.bytes | 1 | The minimum amount of data the server should return for a fetch request. If insufficient data is available the request will wait for that much data to accumulate before answering the request. |
| fetch.wait.max.ms | 100 | The maximum amount of time the server will block before answering the fetch request if there isn’t sufficient data to immediately satisfy fetch.min.bytes. |
| rebalance.backoff.ms | 2000 | Backoff time between retries during rebalance. |
| refresh.leader.backoff.ms | 200 | Backoff time to wait before trying to determine the leader of a partition that has just lost its leader. |
| auto.offset.reset | largest | What to do when there is no initial offset in ZooKeeper or if an offset is out of range ;smallest : automatically reset the offset to the smallest offset; largest : automatically reset the offset to the largest offset;anything else: throw exception to the consumer |
| consumer.timeout.ms | -1 | 若在指定时间内没有消息消费,consumer将会抛出异常。 |
| exclude.internal.topics | true | Whether messages from internal topics (such as offsets) should be exposed to the consumer. |
| zookeeper.session.timeout.ms | 6000 | ZooKeeper session timeout. If the consumer fails to heartbeat to ZooKeeper for this period of time it is considered dead and a rebalance will occur. |
| zookeeper.connection.timeout.ms | 6000 | The max time that the client waits while establishing a connection to zookeeper. |
| zookeeper.sync.time.ms | 2000 | How far a ZK follower can be behind a ZK leader |
还有几篇博客也介绍的很清楚:
Kafka的配置文件详细描述
kafka 配置文件参数详解
Kafka最佳实践配置项
服务端必要参数
- zookeeper.connect:必配参数,建议在kafka集群的每台实例都配置所有的zk节点
- broker.id:必配参数。集群节点的标示符,不得重复,取值范围0~n
- log.dirs:不要使用默认的“/tmp/kafka-logs”,因为/tmp目录的性质没法保证数据的持久性
服务端推荐参数
- advertised.host.name:注册到zk供用户使用的主机名
- advertised.port:注册到zk供用户使用的服务端口
- num.partitions:创建topic时的默认partition数量,默认是1
- default.replication.factor:自动创建topic的默认副本数量,建议至少修改为2
- min.insync.replicasISR:提交生成者请求的最小副本数,建议至少2~3个
- unclean.leader.election.enable:是否允许不具备ISR资格的replicas被选举为leader,建议设置为否,除非能够允许数据的丢失
- controlled.shutdown.enable:在kafka收到stop命令或者异常终止时,允许自动同步数据,建议开启
可动态调整的参数
- unclean.leader.election.enable:不严格的leader选举,有助于集群健壮,但是存在数据丢失风险。
- min.insync.replicas:如果同步状态的副本小于该值,服务器将不再接受request.required.acks为-1或all的写入请求。
- max.message.bytes:单条消息的最大长度。如果修改了该值,那么replica.fetch.max.bytes和消费者的fetch.message.max.bytes也要跟着修改。
- cleanup.policy:生命周期终结数据的处理,默认删除。
- flush.messages:强制刷新写入的最大缓存消息数。
- flush.ms:强制刷新写入的最大等待时长。
客户端配置:
- Producer客户端:ack、压缩、同步生产 vs 异步生产、批处理大小(异步生产)
- Consumer客户端方面主要考虑:partition数量及获取消息的大小
Kafka 集群相关知识
首先,我们需要了解Kafka集群的一些机制:
- Kafka是天然支持集群的,哪怕是一个节点实际上也是集群模式
- Kafka集群依赖于Zookeeper进行协调,并且在早期的Kafka版本中很多数据都是存放在Zookeeper的
- Kafka节点只要注册到同一个Zookeeper上就代表它们是同一个集群的
- Kafka通过brokerId来区分集群中的不同节点
Kafka的集群拓扑图如下:

Kafka集群中的几个角色:
- Broker:一般指Kafka的部署节点
- Leader:用于处理消息的接收和消费等请求,也就是说producer是将消息push到leader,而consumer也是从leader上去poll消息
- Follower:主要用于备份消息数据,一个leader会有多个follower
Kafka副本集
关于Kafka的副本集:
- Kafka副本集是指将日志复制多份,我们知道Kafka的数据是存储在日志文件中的,这就相当于数据的备份、冗余
- Kafka可以通过配置设置默认的副本集数量
- Kafka可以为每个Topic设置副本集,所以副本集是相对于Topic来说的
一个Topic的副本集可以分布在多个Broker中,当一个Broker挂掉了,其他的Broker上还有数据,这就提高了数据的可靠性,这也是副本集的主要作用。
我们都知道在Kafka中的Topic只是个逻辑概念,实际存储数据的是Partition,所以真正被复制的也是Partition。如下图:

关于副本因子:
- 副本因子其实决定了一个Partition的副本数量,例如副本因子为1,则代表将Topic中的所有Partition按照Broker的数量复制一份,并分布到各个Broker上
副本分配算法如下:
- 将所有N Broker和待分配的i个Partition排序
- 将第i个Partition分配到第(i mod n)个Broker上
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上
Kafka节点故障原因及处理方式
Kafka节点(Broker)故障的两种情况:
- Kafka节点与Zookeeper心跳未保持视为节点故障
- 当follower的消息落后于leader太多也会视为节点故障
Kafka对节点故障的处理方式:
- Kafka会对故障节点进行移除,所以基本不会因为节点故障而丢失数据
- Kafka的 语义担保也很大程度上避免了数据丢失
- Kafka会对消息进行集群内平衡,减少消息在某些节点热度过高
Kafka Leader选举机制简介
Kafka集群之Leader选举:
- 如果有接触过其他一些分布式组件就会了解到大部分组件都是通过投票选举来在众多节点中选举出一个leader,但在Kafka中没有采用投票选举来选举leader
- Kafka会动态维护一组Leader数据的副本(ISR)
- Kafka会在ISR中选择一个速度比较快的设为leader
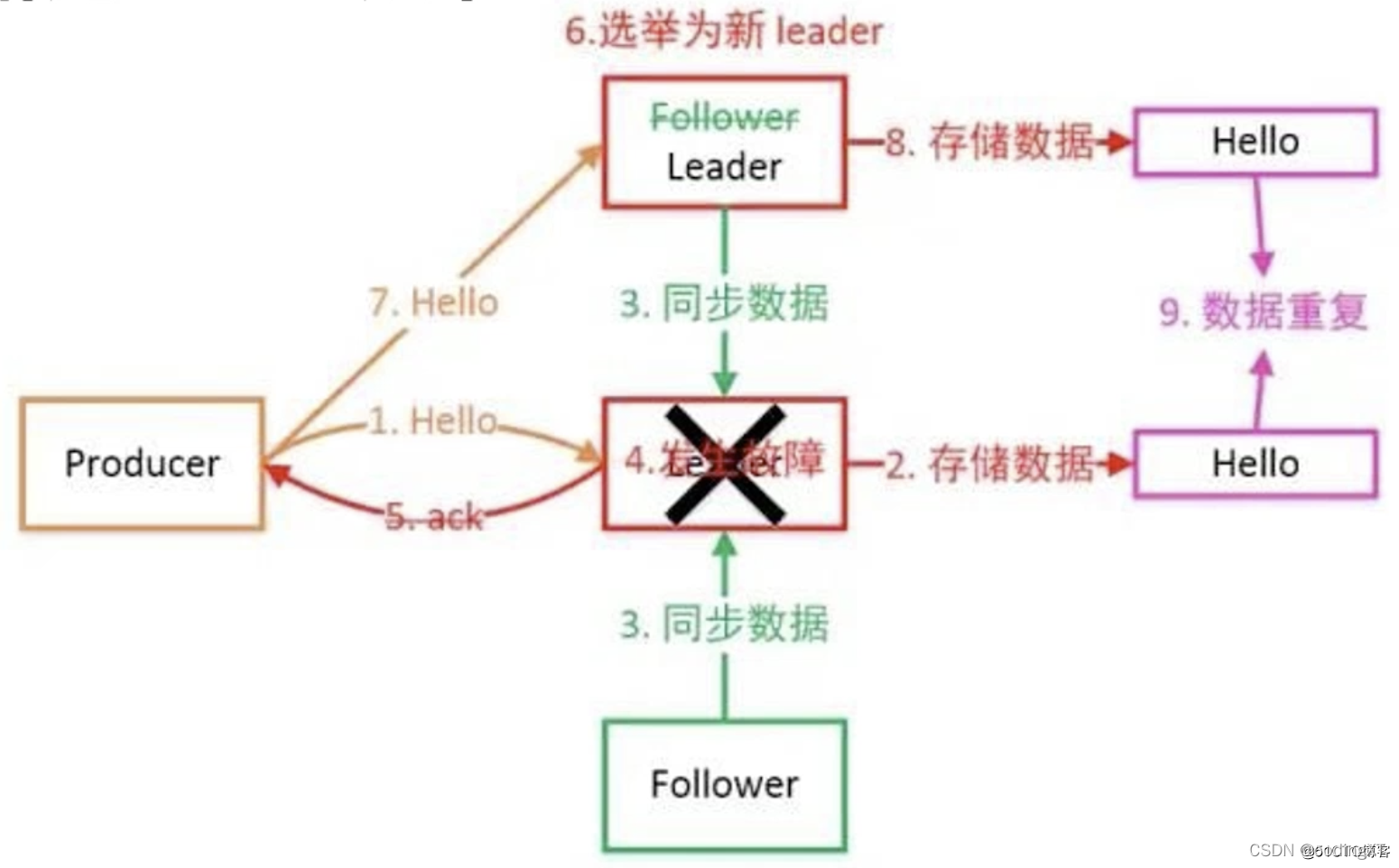
“巧妇难为无米之炊”:Kafka有一种无奈的情况,就是ISR中副本全部宕机。对于这种情况,Kafka默认会进行unclean leader选举。Kafka提供了两种不同的方式进行处理: - 等待ISR中任一Replica恢复,并选它为Leader
等待时间较长,会降低可用性,或ISR中的所有Replica都无法恢复或者数据丢失,则该Partition将永不可用 - 选择第一个恢复的Replica为新的Leader,无论它是否在ISR中
并未包含所有已被之前Leader Commit过的消息,因此会造成数据丢失,但可用性较高
Leader选举配置建议:
- 禁用unclean leader选举
- 手动设置最小ISR
docker-compose搭建kafka
不了解docker-compose的话可以简单看看这篇
Docker-compose 安装与基本使用
我这里就把日志的存储挂载出来
如后续搭建集群运行遇到错误,多半是空格缩进的原因
version: '3.9'
# 配置kafka集群
# container services下的每一个子配置都对应一个节点的docker container
# 给kafka集群配置一个网络,网络名为kafka-net
networks:
kafka-net:
name: kafka-net
driver: bridge
services:
#zookeeper我就配置一个,能运行使用就行,怕服务器资源不太够用
zookeeper-1:
image: zookeeper
container_name: zookeeper
restart: always
# 配置docker container和宿主机的端口映射
ports:
- 2181:2181
- 8081:8080
# 将docker container上的路径挂载到宿主机上 实现宿主机和docker container的数据共享
volumes:
- "/usr/local/zookeeper/zookeeper-1/data:/data"
- "/usr/local/zookeeper/zookeeper-1/datalog:/datalog"
- "/usr/local/zookeeper/zookeeper-1/logs:/logs"
- "/usr/local/zookeeper/zookeeper-1/conf:/conf"
# 配置docker container的环境变量
environment:
# 当前zk实例的id
ZOO_MY_ID: 1
# 整个zk集群的机器、端口列表
ZOO_SERVERS: server.1=zookeeper-1:2888:3888
command: ["zkServer.sh", "start-foreground"]
networks:
- kafka-net
kafka-1:
image: wurstmeister/kafka
container_name: kafka-1
restart: always
# 配置docker container和宿主机的端口映射 8083端口是后期部署kafka connect所需要的端口
ports:
- 9092:9092
- 8084:8083
# plugins 是我方便加入kafka connector 依赖所设文件夹,不使用connect可以不设置
# /opt/kafka/plugins 是配置connector的时候指定的容器内部文件夹路径
volumes:
- "/usr/local/kafka/kafka-1/logs:/kafka"
- "/usr/local/kafka/plugins:/opt/kafka/plugins"
# 配置docker container的环境变量
environment:
KAFKA_ADVERTISED_HOST_NAME: IP ## 修改:宿主机IP
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://IP:9092 ## 修改:宿主机IP
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181"
KAFKA_ADVERTISED_PORT: 9092
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zookeeper-1
networks:
- kafka-net
kafka-2:
image: wurstmeister/kafka
container_name: kafka-2
restart: always
# 配置docker container和宿主机的端口映射
ports:
- 9093:9092
- 8085:8083
volumes:
- "/usr/local/kafka/kafka-2/logs:/kafka"
- "/usr/local/kafka/plugins:/opt/kafka/plugins"
# 配置docker container的环境变量
environment:
KAFKA_ADVERTISED_HOST_NAME: IP ## 修改:宿主机IP
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://IP:9093 ## 修改:宿主机IP
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181"
KAFKA_ADVERTISED_PORT: 9093
KAFKA_BROKER_ID: 2
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zookeeper-1
networks:
- kafka-net
kafka-3:
image: wurstmeister/kafka
container_name: kafka-3
restart: always
# 配置docker container和宿主机的端口映射
ports:
- 9094:9092
- 8086:8083
volumes:
- "/usr/local/kafka/kafka-3/logs:/kafka"
- "/usr/local/kafka/plugins:/opt/kafka/plugins"
# 配置docker container的环境变量
environment:
KAFKA_ADVERTISED_HOST_NAME: IP ## 修改:宿主机IP
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://IP:9094 ## 修改:宿主机IP
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181"
KAFKA_ADVERTISED_PORT: 9094
KAFKA_BROKER_ID: 3
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zookeeper-1
networks:
- kafka-net
kafka-manager:
image: sheepkiller/kafka-manager ## 镜像:开源的web管理kafka集群的界面
container_name: kafka-manager
restart: always
environment:
ZK_HOSTS: IP:2181 ## 修改:宿主机IP
ports:
- "9001:9000" ## 暴露端口
networks:
- kafka-net
将docker-compose.yml文件拷贝到/usr/local/kafka这个文件夹下面。
启动docker-compose的kafka集群
在docker-compose.yml文件所在的地方运行
-d 后台运行
docker-compose up -d
查看运行情况,如果都为UP状态,则为正常运行
docker ps -a

开放端口
我在部署zookeeper的时候是开放了zookeeper哪些服务的端口了的,所以我这里只用开放kafka和kafka-manager的端口
firewall-cmd --permanent --add-port=9092/tcp
firewall-cmd --permanent --add-port=9093/tcp
firewall-cmd --permanent --add-port=9094/tcp
//8084,8085,8086是 kafka connect rest服务的端口号
firewall-cmd --permanent --add-port=8084/tcp
firewall-cmd --permanent --add-port=8085/tcp
firewall-cmd --permanent --add-port=8086/tcp
firewall-cmd --permanent --add-port=9001/tcp
重启防火墙(修改配置后要重启防火墙)
firewall-cmd --reload
服务器控制台的防火墙端口同样也需要开放,便于外界访问服务器,如果服务器部署了安全组,则安全组也要开放这些端口。(据我所知,至少阿里云是设置了安全组的,需要安全组开放这些端口)
登录kafka-manager管理界面
http://服务器IP:9001/
添加集群,因为kafka是使用zookeeper做配置管理的,所以填写zookeeper的地址

可以查看这个集群的信息

测试
创建一个topic
docker exec kafka-1 kafka-topics.sh --create --topic xt --partitions 1 --bootstrap-server localhost:9092 --replication-factor 1

获取topic列表
docker exec kafka-1 kafka-topics.sh --list --bootstrap-server localhost:9092
查看指定topic描述
docker exec kafka-1 kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic xt

References:
- https://www.cnblogs.com/liuxinyustu/articles/14373913.html
- https://zhuanlan.zhihu.com/p/43843796
- https://blog.csdn.net/qq_37960603/article/details/122277935
- https://www.cnblogs.com/jun1019/p/6256371.html
- https://www.cnblogs.com/alan319/p/8651434.html
- https://blog.csdn.net/qq_34319644/article/details/96600138
- https://www.jianshu.com/p/e8c29cba9fae
- https://blog.51cto.com/zero01/2509825
- https://blog.51cto.com/zero01/2501495
(写博客主要是对自己学习的归纳整理,资料大部分来源于书籍、网络资料和自己的实践,整理不易,但是难免有不足之处,如有错误,请大家评论区批评指正。同时感谢广大博主和广大作者辛苦整理出来的资源和分享的知识。)

大数据从业者之家,一起探索大数据的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)