
第十七届蓝桥杯pythonB组满分题解
我不多整什么稀奇古怪的东西就按照题目顺序来写。
第十七届蓝桥杯pythonB组满分题解
这里写目录标题
 我不多整什么稀奇古怪的东西就按照题目顺序来写。
我不多整什么稀奇古怪的东西就按照题目顺序来写。
AP16260 [蓝桥杯 2026 省 Python/Java B 组] 和平干饭日
 这道题很简单,枚举每一项即可,难点在于求出当前项的值。
这道题很简单,枚举每一项即可,难点在于求出当前项的值。
但实际上我们并不需要求出这个值,只需要求这个值模 26 的结果即可。
因此我们维护出这个值模 26 的结果,每次往后多拼一个数字 x 其实都是在给这个数字乘若干个 10,再加上 x,而若干个 10 其实就是 x 的位数个。
因此我们枚举的过程中,求出 i 的位数,就可以通过 pow(10,b) 函数方便地维护出当前这一项的数组值模 26 的结果了(其中 b 表示 i 的位数)。
只要结果为 0,就给答案加一,最后算出来应该是 76。 十二行代码写完
c, s = 0, 0
def getpow(v):
return 10 len(str(v))
for i in range(1, 2027):
s = s * getpow(i) + i
if s % 26 == 0:
c += 1
print(c)
P16261 [蓝桥杯 2026 省 Python/Java B 组] 干涉条纹
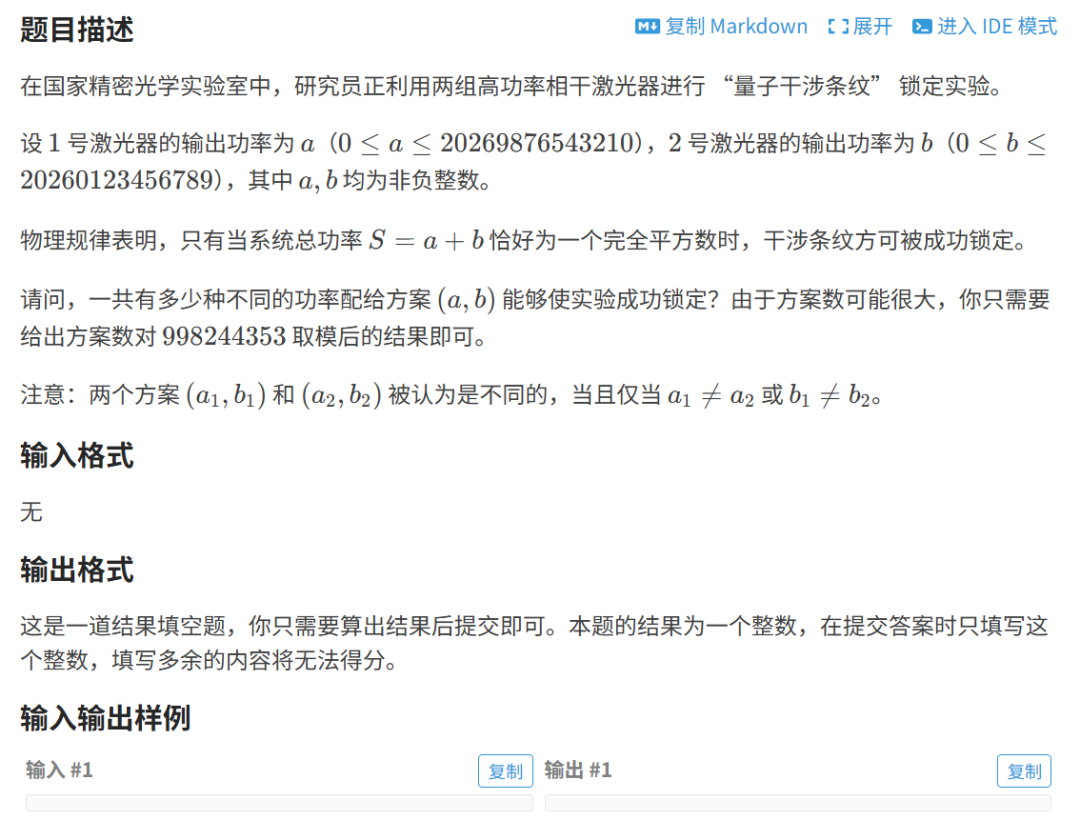 首先令 A=20269876543210,B=20260123456789
首先令 A=20269876543210,B=20260123456789
枚举这个平方数,可知是
令,则贡献为r - l + 1
最后算出315082704
import math
def main():
A = 20269876543210
B = 20260123456789
MOD = 998244353
S_max = A + B
# 计算各区间分界点的整数平方根
K1 = math.isqrt(B) # 最大的 k 使得 k^2 ≤ B
K2 = math.isqrt(A) # 最大的 k 使得 k^2 ≤ A
K3 = math.isqrt(S_max) # 最大的 k 使得 k^2 ≤ S_max
# 平方和公式: sum_{k=0}^{n} k^2 = n(n+1)(2n+1)//6
def sum_sq(n: int) -> int:
return n * (n + 1) * (2 * n + 1) // 6
ans = 0
# 第一段: k = 0 .. K1,贡献为 k^2 + 1
if K1 >= 0:
total1 = sum_sq(K1) + (K1 + 1)
ans = (ans + total1) % MOD
# 第二段: k = K1+1 .. K2,贡献为常数 B+1
if K2 > K1:
cnt2 = K2 - K1
total2 = cnt2 * (B + 1)
ans = (ans + total2) % MOD
# 第三段: k = K2+1 .. K3,贡献为 S_max - k^2 + 1
if K3 > K2:
cnt3 = K3 - K2
sum_sq_3 = sum_sq(K3) - sum_sq(K2) # ∑_{k=K2+1}^{K3} k^2
total3 = cnt3 * (S_max + 1) - sum_sq_3
ans = (ans + total3) % MOD
print(ans)
if __name__ == "__main__":
main()
P16262 [蓝桥杯 2026 省 Python B 组] 定制展示盘
 很简单,可以分解成两个大于等于 2 的数的乘积意味着是合数,暴力枚举输入之后的每个数,判断是否为合数即可。
很简单,可以分解成两个大于等于 2 的数的乘积意味着是合数,暴力枚举输入之后的每个数,判断是否为合数即可。
import math
def is_prime(x):
if x <= 2:
return (False,False,True)[x]
for i in range(2 , math.isqrt(x)+1):
if x % i == 0:
return False
return True
T = int(input())
for _ in range(T):
n = int(input())
if n <= 4:
print(4)
else:
if is_prime(n):
print(n+1)
else:
print(n)
P16263 [蓝桥杯 2026 省 Python B 组] 密室逃脱开关谜题
 个人认为这道题是省赛中python组最难的了,第一次做的时候用到暴力枚举只能跑到75。
个人认为这道题是省赛中python组最难的了,第一次做的时候用到暴力枚举只能跑到75。
这是一道数论方面的题,其旨在开关操作转化为线性代数中的线性方程组(异或方程组)问题具体解题步骤如下
1.利用数学建模建立开关与灯的异或关系
每盏灯的状态可以用 (关)或 (开)表示。由于目标是将所有灯置为 ,且按下同一个开关两次相当于没有按,我们可以建立如下关系:开关 的作用: 切换灯 和灯 。
线性方程组: 如果我们令 表示是否按下第 个开关,那么对于每一盏灯 ,其最终状态由所有控制它的开关决定:
注: 表示异或运算
2. 核心逻辑分析
2.1 奇偶性分类讨论
可以通过 if m & 1
将问题分成了 为奇数 和 为偶数 两种情况处理,
2.2 当 为偶数时
不妨令,其中是m的最大因子。
对于奇数编号的灯,由于 必为偶数,只有开关 能控制该灯的奇数部分。因此,所有奇数开关必须按下。对于偶数编号的灯,通过 的逐层递推:
- 当 时,该开关不需要按下。
- 符合该条件的 共有 个。
得出最少按键次数为
2.3当m为奇数时 由于 ,所以我们对每个 都连一条有向边 m后,得到的图会是若干个不相交的置换环。
那么问题转化为,从图上选若干条边,使得每个点的入度和出度之和均为 1。
这个等价于要求所有环的环长均为偶数,每个环上选不相邻的数量为环长一半的边即可。
有个特例是 0,它单独成一个环长为 1 的置换环,不过题目也说了按第 0 个开关只会切换一次状态,所以固定按一次 0 就行。
即可得到每个灯 恰好对应两个开关:和使用 Pollard-Rho 分解 ,校验 的阶若有解,结论通常为则代码返回(m + 1) >> 1
import sys
import math
import random
from typing import List, Tuple
# 使用更快的输入输出
input = sys.stdin.readline
def miller_rabin(n: int) -> bool:
"""优化的Miller-Rabin素数测试"""
if n < 4:
return n > 1
if n % 2 == 0:
return False
# 小素数快速检查
small_primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
for p in small_primes:
if n == p:
return True
if n % p == 0:
return False
# 计算d和s,使得n-1 = d * 2^s
d = n - 1
s = 0
while d % 2 == 0:
s += 1
d //= 2
# 测试基数
if n < 2047:
bases = [2]
elif n < 1373653:
bases = [2, 3]
elif n < 9080191:
bases = [31, 73]
elif n < 25326001:
bases = [2, 3, 5]
elif n < 3215031751:
bases = [2, 3, 5, 7]
elif n < 4759123141:
bases = [2, 7, 61]
elif n < 1122004669633:
bases = [2, 13, 23, 1662803]
elif n < 2152302898747:
bases = [2, 3, 5, 7, 11]
elif n < 3474749660383:
bases = [2, 3, 5, 7, 11, 13]
elif n < 341550071728321:
bases = [2, 3, 5, 7, 11, 13, 17]
else:
bases = [2, 325, 9375, 28178, 450775, 9780504, 1795265022]
for a in bases:
if a >= n:
continue
x = pow(a, d, n)
if x == 1 or x == n - 1:
continue
for _ in range(s - 1):
x = (x * x) % n
if x == n - 1:
break
else:
return False
return True
def gcd(a: int, b: int) -> int:
"""快速GCD"""
while b:
a, b = b, a % b
return a
def pollard_rho(n: int) -> int:
"""优化的Pollard-Rho算法"""
if n % 2 == 0:
return 2
if n % 3 == 0:
return 3
# 使用固定参数加速
while True:
c = random.randrange(1, n)
f = lambda x: (x * x + c) % n
x = y = 2
d = 1
while d == 1:
x = f(x)
y = f(f(y))
d = gcd(abs(x - y), n)
if d != n:
return d
def factorize(n: int) -> List[Tuple[int, int]]:
"""优化的因式分解"""
if n < 2:
return []
if miller_rabin(n):
return [(n, 1)]
# 小因数快速处理
small_factors = []
for p in [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]:
if n % p == 0:
cnt = 0
while n % p == 0:
cnt += 1
n //= p
small_factors.append((p, cnt))
if n > 1:
if miller_rabin(n):
small_factors.append((n, 1))
else:
# 对大数进行Pollard-Rho分解
m = pollard_rho(n)
c = 0
while n % m == 0:
c += 1
n //= m
factors = factorize(n) + factorize(m)
for i in range(len(factors)):
if factors[i][0] == m:
factors[i] = (m, factors[i][1] * c)
# 合并结果
factors.extend(small_factors)
factors.sort()
# 合并相同因数
result = []
for p, cnt in factors:
if result and result[-1][0] == p:
result[-1] = (p, result[-1][1] + cnt)
else:
result.append((p, cnt))
return result
return small_factors
def solve():
"""主解决函数"""
t_case = int(input())
out = []
for _ in range(t_case):
n, m = map(int, input().split())
n = min(n, m)
if n < m - (m & 1):
out.append("-1")
continue
if m & 1: # m是奇数
factors = factorize(m)
found = False
for p, _ in factors:
# 计算2是模p的原根
exp = (p - 1) // ((p - 1) & (1 - p))
if pow(2, exp, p) == 1:
out.append("-1")
found = True
break
if not found:
out.append(str((m + 1) >> 1))
else: # m是偶数
# 计算m的最大奇因数
lowbit = m & -m
result = m - m // lowbit
out.append(str(result))
sys.stdout.write("\n".join(out))
if __name__ == "__main__":
solve()
P16264 [蓝桥杯 2026 省 Python B 组] 奇偶博弈
 题目给出的替换规则其实是不对称的,这是解题的关键:规则1:如果 是奇数,必须变为 。这意味着奇数只有唯一的出路:变成一个偶数。
题目给出的替换规则其实是不对称的,这是解题的关键:规则1:如果 是奇数,必须变为 。这意味着奇数只有唯一的出路:变成一个偶数。
规则2:如果 是偶数,必须变为一个更小的偶数。由于最小的偶数是 ,当一个数变成 时,它就不能再被操作了。
推论: 一个大于 的奇数(如 )变成偶数后(如 ),对手可以继续将其减小;但 变成 后,该位置立刻“死掉”,无法再动。
那么在题目给定的初始条件下,所有数字都是正奇数。如果 :先手将其变为 (偶数)。后手可以将其减小到任何更小的偶数,甚至直接减到 。由于偶数减偶数还是偶数,这一系列操作其实不会改变这个数字作为“偶数”被消耗的过程。然而,题目中隐藏了一个极简的逻辑:任意大于 1 的奇数,其实都可以看作是一个可以无限“拉扯”的资源。
T = int(input())
for _ in range(T):
N = int(input())
W = list(map(int, input().split()))
cnt = W.count(1)
print('L' if cnt % 2 == 1 else 'Q')
P16265 [蓝桥杯 2026 省 Python B 组] 蓝小圈
 使用带权并查集,维护以下四个数组:
使用带权并查集,维护以下四个数组:
- parent[i]:用户 i 在并查集中的父节点。
- delta[i]:用户 i 相对于其父节点的调整值(用于处理合并时的差值)。
- own[i]:用户 i 的个人活跃度增量。
- group[fa]:以 fa 为根的连通块的整体活跃度增量。
对其进行建模分析
即可得出
import sys
sys.setrecursionlimit(1 << 25)
p = []
personal = []
delta = []
add = []
output = []
def find(x):
global p, delta
if p[x] != x:
orig_parent = p[x]
p[x] = find(p[x])
delta[x] += delta[orig_parent]
return p[x]
def union_sets(X, Y):
global p, delta, add
fx = find(X)
fy = find(Y)
if fx != fy:
p[fy] = fx
delta[fy] = add[fy] - add[fx]
def read_initial():
first_line = sys.stdin.readline()
while first_line.strip() == '':
first_line = sys.stdin.readline()
return map(int, first_line.split())
def init_arrays(N):
global p, personal, delta, add
p = list(range(N + 1))
personal = [0] * (N + 1)
delta = [0] * (N + 1)
add = [0] * (N + 1)
def read_command():
line = sys.stdin.readline()
while line.strip() == '':
line = sys.stdin.readline()
return line.split()
def process_command(parts):
global personal, add, output
op = int(parts[0])
if op == 1:
X = int(parts[1])
Y = int(parts[2])
union_sets(X, Y)
elif op == 2:
X = int(parts[1])
A = int(parts[2])
personal[X] += A
elif op == 3:
X = int(parts[1])
A = int(parts[2])
fx = find(X)
add[fx] += A
elif op == 4:
X = int(parts[1])
fx = find(X) # 原代码缺失此行
res = personal[X] + delta[X] + add[fx]
output.append(str(res))
def print_output():
print('\n'.join(output))
def main():
N, Q = read_initial()
init_arrays(N)
for _ in range(Q):
parts = read_command()
process_command(parts)
print_output()
main()
P16266 [蓝桥杯 2026 省 Python B 组] 星光共鸣

- 首先,我们要理解“星光共鸣”次数是怎么算的。
- 对于一段长度为 的连续全为 1 的子串,它包含的“全为 1 的连续子区间”数量为:
如果 o1 串是 111,长度 。
- 长度为 1 的子区间:[1,1], [2,2], [3,3] (3个)
- 长度为 2 的子区间:[1,2], [2,3] (2个)
- 长度为 3 的子区间:[1,3] (1个)
- 总共 次。
我们需要记录当前处理到了第几个位置、当前已经积累了多少次共鸣,以及当前末尾有多少个连续的 1(因为下一个 1 产生的贡献取决于当前的长度)。
定义dp[i][j][l]
- i:前 个位置(代码中通过 prev_dp 和 curr_dp 滚动数组优化掉了这一维)。
- j:当前总共产生的共鸣次数(若超过 则统一计为 )。
- l:当前末尾连续 1 的长度。
对于每一个状态,dp[j_prev][l_prev]
在当前位置均有两种选择
选择 A:放入 0 后果:连续的 1 被切断,末尾连续 1 的长度变为 0。
转移:curr_dp[j_prev][0] += prev_dp[j_prev][l_prev]。
选择 B:放入 1 后果:末尾连续 1 的长度增加 1,即 l_new = l_prev + 1。
贡献:根据前面的分析,这一次操作新增了 l_new 次共鸣。
转移:j_new = j_prev + l_new。
更新:curr_dp[min(K, j_new)][min(max_l, l_new)] += prev_dp[j_prev][l_prev]。
MOD = 109 + 7
N, K = map(int, input().split())
max_l = 20
prev_dp = [[0] * (max_l + 1) for _ in range(K + 1)]
prev_dp[0][0] = 1
for _ in range(N):
curr_dp = [[0] * (max_l + 1) for _ in range(K + 1)]
for j_prev in range(K + 1):
for l_prev in range(max_l + 1):
val = prev_dp[j_prev][l_prev]
if val == 0:continue
curr_dp[j_prev][0] = (curr_dp[j_prev][0] + val) % MOD
l_new = l_prev + 1
delta = l_new
j_new = j_prev + delta
if j_new > K:
j_new = K
if l_new > max_l:
l_new = max_l
curr_dp[j_new][l_new] = (curr_dp[j_new][l_new] + val) % MOD
prev_dp = curr_dp
print(sum(prev_dp[K][l] for l in range(max_l + 1)) % MOD)
P16267 [蓝桥杯 2026 省 Python B 组] 位数求和
 这道题结合了单调栈、二维几何计数以及贡献度分析 对于数组中的每一个数 ,有多少个区间是以它作为最大值的?
这道题结合了单调栈、二维几何计数以及贡献度分析 对于数组中的每一个数 ,有多少个区间是以它作为最大值的?
为了避免重复计算(当区间内有多个相同的最大值时),我们约定: 只负责那些“左侧严格小于它,右侧小于等于它”的区间。
- L[i]:左边第一个比 大的元素位置。
- R[i]:右边第一个比 大(或等于)的元素位置。
有效跨度:以 为最大值的区间,其左端点 ,右端点 。
- 令 (左侧可选长度)
- 令 (右侧可选长度)
对于确定的 ,我们要计算:
位数
令 (左侧偏移),(右侧偏移),则区间长度 。 那么这道题的问题的本质变成了:在一个 的矩形网格中,满足 的整数点 有多少个?
get_prefix(X, Y, t) 函数的功能就是计算矩形内满足 的点数。这是一个典型的二维几何切割问题,分为三种情况:
- 小三角形: 很小,直接求和。
- 平行四边形/梯形: 在中间段,面积线性增长。
- 补集法: 很大,用总点数减去右上角的缺失三角形。
由于长度 的位数()是阶梯型变化的(1-9 是 1 位,10-99 是 2 位…),我们可以用segments 进行分段统计:
- 找到长度在 之间的区间数量。
- 利用 get_prefix 函数通过差分(大范围减去小范围)得到该段内的点数。
- 总贡献 = 该位数下的区间数。
其实说白了就是一个关于k的分段函数:
import sys
MOD = 998244353
def get_prefix(X: int, Y: int, t: int) -> int:
"""
返回矩形 [0, X] × [0, Y] 中满足 x+y <= t 的点数。
"""
if t < 0:
return 0
total = (X + 1) * (Y + 1)
if t >= X + Y:
return total
m = min(X, Y)
M = max(X, Y)
if t <= m:
# 等差数列求和 1+2+...+(t+1)
return (t + 1) * (t + 2) // 2
if t <= M:
fm = (m + 1) * (m + 2) // 2
return fm + (t - m) * (m + 1)
# M < t < X+Y
d = X + Y - t
return total - d * (d + 1) // 2
def solve() -> None:
data = sys.stdin.buffer.read().split()
if not data:
return
it = iter(data)
n = int(next(it))
a = [0] + [int(next(it)) for _ in range(n)] # 1‑based
# 左边第一个大于 a[i] 的位置 (L[i])
L = [0] * (n + 2)
stack = []
for i in range(1, n + 1):
while stack and a[stack[-1]] <= a[i]:
stack.pop()
L[i] = stack[-1] if stack else 0
stack.append(i)
# 右边第一个大于等于 a[i] 的位置 (R[i])
R = [n + 1] * (n + 2)
stack.clear()
for i in range(n, 0, -1):
while stack and a[stack[-1]] < a[i]:
stack.pop()
R[i] = stack[-1] if stack else n + 1
stack.append(i)
# 预处理位数分段
max_len = n
max_k = len(str(max_len))
segments = [] # (k, low, high)
for k in range(1, max_k + 1):
low = 10 (k - 1)
high = min(10 k - 1, n)
if low > high:
continue
segments.append((k, low, high))
ans = 0
for i in range(1, n + 1):
X = i - L[i] - 1
Y = R[i] - i - 1
total = 0
for k, low, high in segments:
A = low - 1
B = high - 1
cnt = get_prefix(X, Y, B) - get_prefix(X, Y, A - 1)
total += k * cnt
ans = (ans + a[i] * total) % MOD
print(ans)
if __name__ == "__main__":
solve()
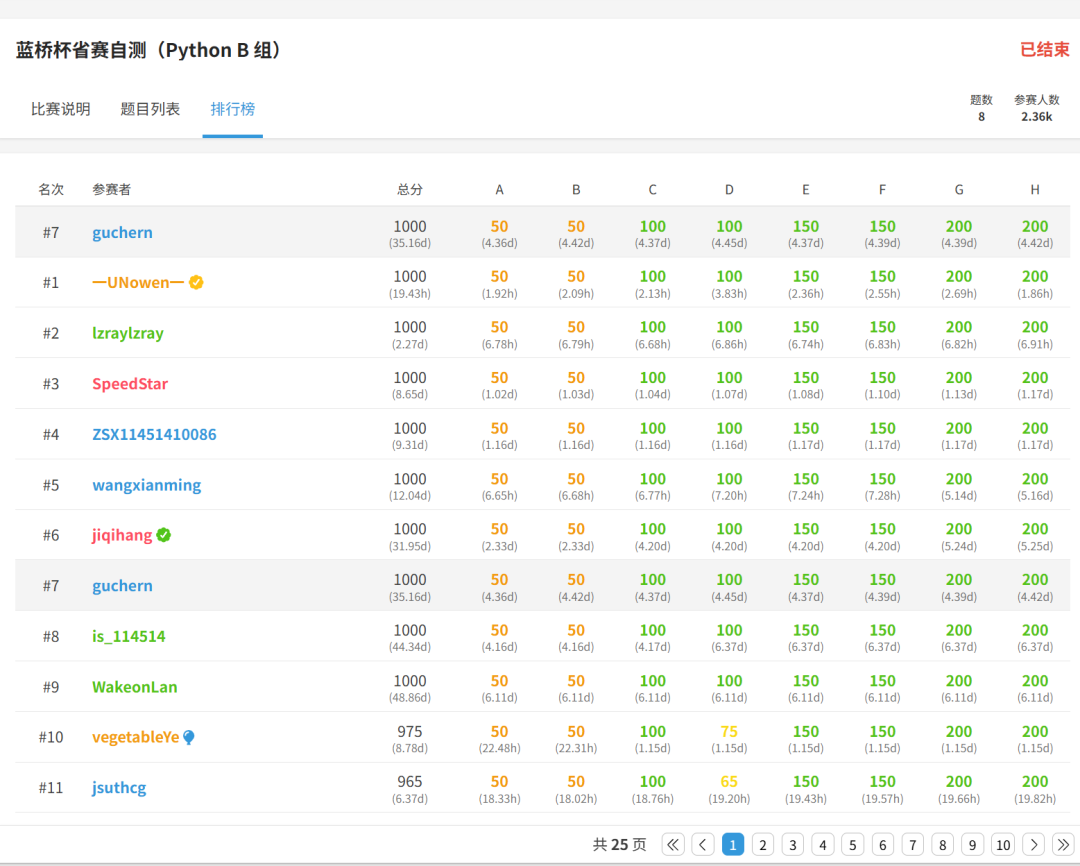
最后放一下排名和得分情况

欢迎加入北京社区
更多推荐



 8
8 0
0- 0



 已为社区贡献193条内容
已为社区贡献193条内容

所有评论(0)