
基于 ModelEngine构建文章智能处理器
摘要:本文基于ModelEngine低代码平台构建"文章智能处理器",实现学术论文的高效解析与摘要生成。通过智能表单节点采集用户需求,文件提取节点解析论文内容,IF条件节点实现动态分支处理,结合大模型节点生成结构化Markdown摘要。该方案将摘要生成时间从1小时缩短至60秒,支持PDF/Word/TXT多格式输入,输出包含研究背景、方法、结论等模块的标准化学术摘要。平台可视化
引言
在学术研究数字化浪潮下,如何高效处理海量论文文档并提取核心信息,成为科研工作者与知识管理者的核心诉求。ModelEngine 作为低代码可视化应用编排平台,以 “拖拽式节点编排 + 大模型能力集成” 的创新模式,为这类场景提供了高效解决方案。本文以 “文章智能处理器” 的全流程构建为例,深度拆解从需求定义到应用落地的可视化编排实践,展现 ModelEngine 在大模型应用开发中的独特优势。
一、实践背景与需求全景定义
学术工作者在论文研读中面临三重效率瓶颈:信息获取低效(逐字阅读耗时)、摘要质量参差(人工撰写主观且耗时,自动化工具能力不足)、知识管理不便(摘要格式不规范难以沉淀)。基于此,我们依托 ModelEngine 构建的 “文章智能处理器” 需满足以下核心需求:
- 多格式兼容:支持 PDF、Word、TXT 等主流论文格式的上传与内容解析;
- 智能摘要生成:调用大模型生成结构化摘要,涵盖研究背景、核心方法、实验结论、创新点等模块;
- 格式标准化:以 Markdown 格式输出摘要,适配知识管理与社区分享场景;
- 需求分支处理:区分 “仅解析文档内容” 与 “生成结构化摘要” 两种用户需求,实现流程动态分支;
**平台地址:** https://modelengine-ai.net/#/home
依次进入下列界面
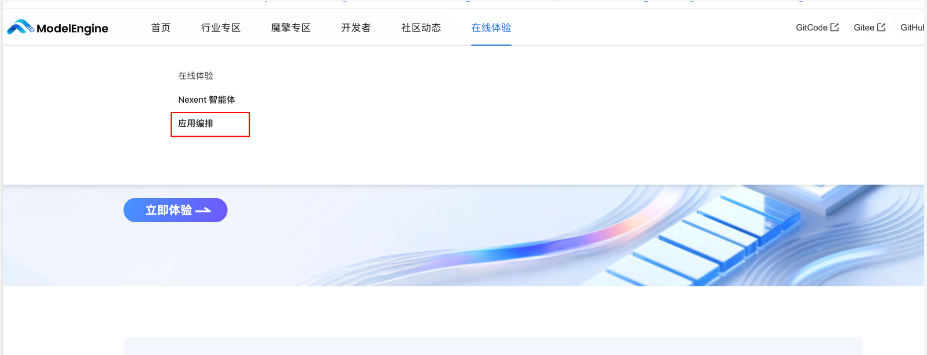
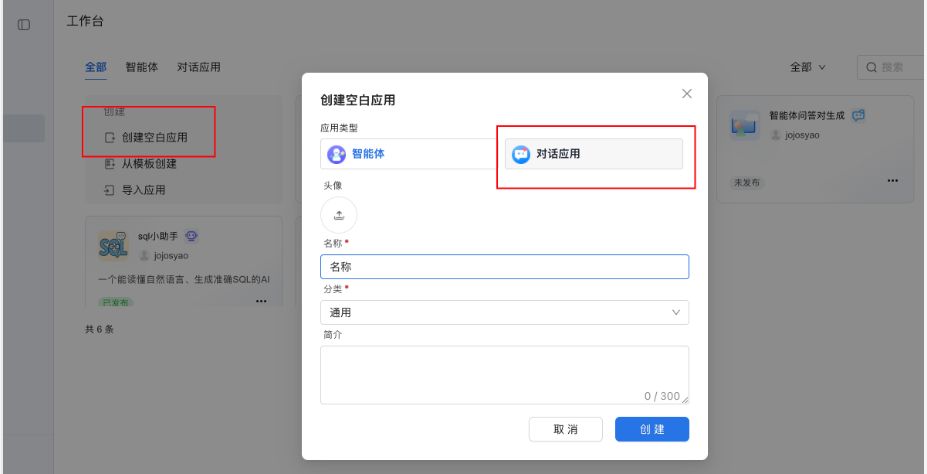
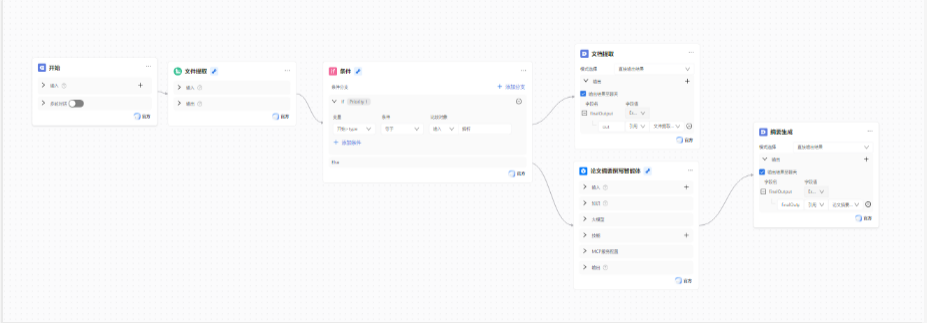
二、应用编排核心框架:基础节点的选型与串联
ModelEngine 的核心优势在于可视化节点编排,我们通过以下核心节点的组合,搭建文章智能处理的基础工作流。
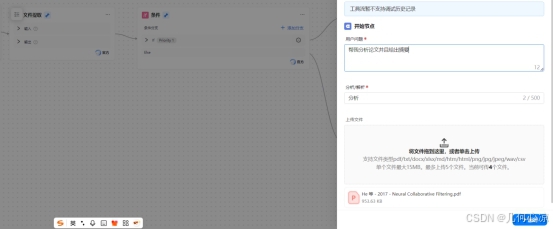
(一)智能表单节点:用户需求的结构化采集
智能表单是用户与应用的 “交互入口”,需承载 “文件上传” 与 “需求类型选择” 两大功能。
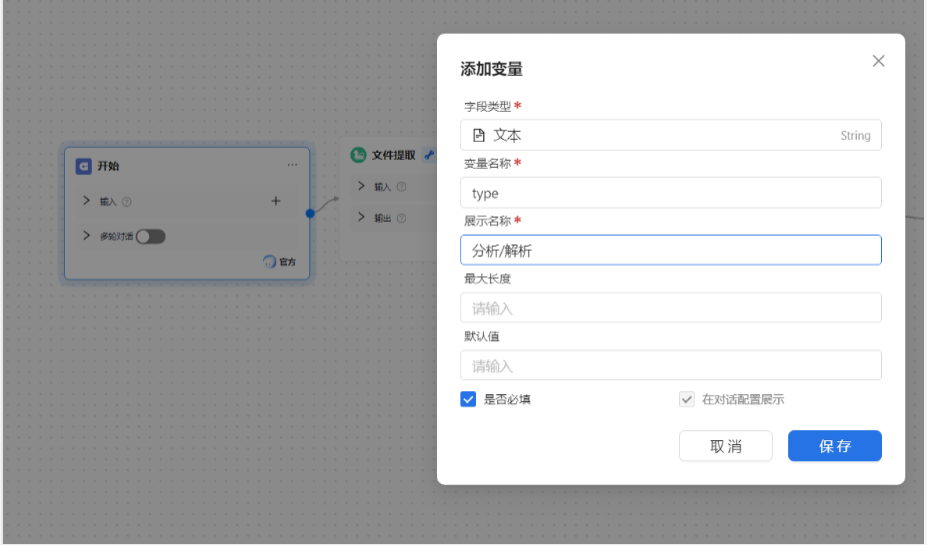
字段设计:
「文件上传字段」:支持 PDF/Word/TXT 等格式,单文件最大 15MB,最多上传 5 个文件;
「需求类型字段」:通过下拉选择框提供 “分析 / 摘要”“仅解析内容” 两个选项,对应后续不同处理分支。
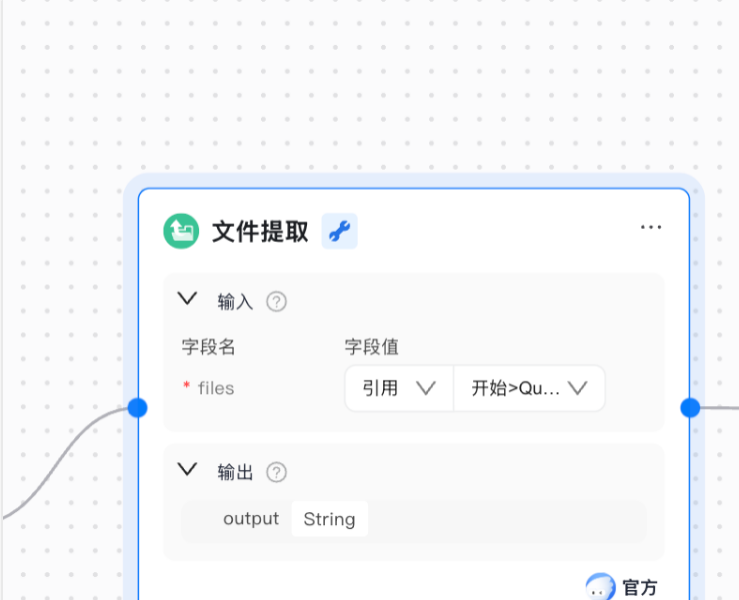
(二)文件提取节点:论文内容的自动化解析
“文件提取” 节点是内容处理的核心入口,负责将上传的论文文件解析为纯文本。
参数配置:
「输入字段」:关联智能表单的 “文件上传字段”,获取用户上传的论文文件;
「输出字段」:定义为 docContent,存储解析后的论文文本,为大模型提供输入。
(三)IF 条件节点:需求分支的动态路由
为区分 “仅解析内容” 和 “生成结构化摘要” 两种需求,需通过 “IF 条件节点” 实现流程分支。
条件配置:
「判断变量」:关联智能表单的 “需求类型字段”(变量名 type);
「分支逻辑」:若 type == 分析,则进入 “大模型摘要生成” 分支;若为 “解析”,则进入 “直接输出解析结果” 分支。
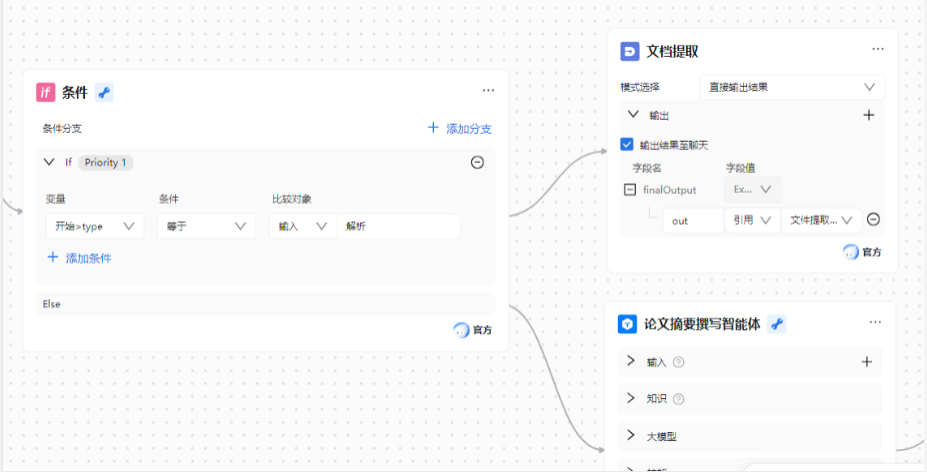
(四)大模型节点:参数与 Prompt 优化
“大模型” 节点是论文摘要智能化的核心,需通过精细化的 Prompt 设计与参数调优,确保摘要质量。
模型与参数选型
模型选择:选用通义千问 Qwen/2.5-XX 系列模型,其在长文本理解、学术专业术语解析上表现优异;
核心参数:
「温度(Temperature)」:设置为 0.3,平衡摘要的 “准确性” 与 “创造性”,避免因温度过高导致信息失真;
「最大 tokens」:根据论文篇幅设置为 2000-3000,确保长论文摘要的完整输出。
系统提示词:明确大模型角色为 “学术论文摘要专家”,约束输出风格与格式。
```
请你作为一名专业的学术论文摘要生成助手,基于以下论文内容,按照指定格式生成结构化摘要:
[论文内容]
{{docContent}}
### 格式要求
请严格按照以下 Markdown 格式输出,每个模块内容控制在合理篇幅:
# 论文标题:[请从论文中提取准确标题]
## 一、研究背景
- 阐述论文研究的问题由来、现有研究不足
- 说明本研究的必要性
- 字数建议:150-200 字
## 二、核心方法
- 详细描述研究采用的理论、技术、实验设计
- 突出方法的创新性与可操作性
- 字数建议:200-250 字
## 三、实验结论
- 说明实验的数据集、评估指标
- 呈现核心实验结果(如性能提升、规律发现等)
- 字数建议:150-200 字
## 四、创新点
- 总结论文在方法、视角、应用等方面的独特贡献
- 对比现有研究,明确创新边界
- 字数建议:100-150 字
### 注意事项
- 所有内容需基于论文原文,不得编造信息
- 专业术语需准确保留,确保学术严谨性
- 语言风格简洁明了,避免冗余表述
```
三、调试
应用编排完成后,需通过多维度调试确保功能稳定与体验流畅。
验证 IF 条件节点的分支流转是否准确:
测试操作:分别选择 “分析” 和 “解析” 两个选项,观察流程执行路径;
(一)直接解析
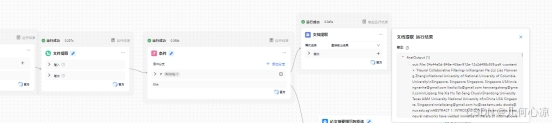
从结果来看能够正确解析成功
(二)分析摘要
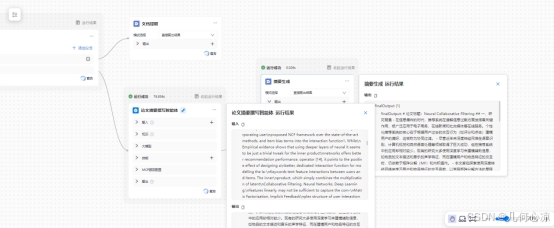
测试结果:type选择 “解析” 时,流程跳过大模型节点,直接输出解析后的文本,满足轻量化需求;选择 “分析” 时,流程完整执行大模型摘要生成逻辑,分支流转准确。
四、应用价值与场景拓展
基于 ModelEngine 构建的论文摘要阅读器,在学术场景中具备多重价值:
效率提升:将单篇论文摘要生成时间从 “人工 1 小时” 压缩至 “平台 60 秒”,效率提升 60 倍;
质量保障:结构化摘要涵盖研究背景、方法、结论、创新点,比传统摘要信息维度更完整;
知识沉淀:Markdown 格式与历史存储功能,助力科研团队构建标准化知识库。
此外,该应用可进一步拓展场景:
学术社交:对接学术社区 API,实现 “摘要生成 - 社区分享” 一站式流程;
科研辅助:集成 “关键词提取”“文献引用分析” 等插件,打造科研全流程工具;
教育场景:为学生提供论文精读辅助,快速把握文献核心价值。
结论
ModelEngine 以可视化编排打破了 “大模型应用开发需深厚技术储备” 的壁垒,本文通过 “论文摘要阅读器” 的实践,完整呈现了从 “需求定义 - 节点编排 - 大模型集成 - 调试优化” 的全流程。这种 “低代码 + 大模型” 的融合模式,为学术、企业知识管理等领域的智能化升级提供了可复制的路径。未来,随着 ModelEngine 自定义插件生态与智能表单能力的持续迭代,其在垂直领域的应用潜力将进一步释放,推动更多场景的效率革命。

欢迎加入北京社区
更多推荐

 17
17 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)