
昇腾平台多模态大模型微调实战之旅
本文分享了在昇腾平台微调Qwen2.5-VL多模态模型的实战经验。首先介绍了MindSpeedMM套件的优势,包括硬件优化、预置模型和完整文档。随后详细阐述了环境搭建的关键步骤,包括驱动安装、CANN配置和Python环境设置。重点讲解了权重转换、数据处理和微调参数配置等核心环节,特别强调了并行策略选择、显存优化技巧和训练监控方法。最后通过推理验证展示了微调效果,证明该方法能有效提升模型性能。文章
最近我在昇腾平台上完成了一次多模态模型微调实践,将Qwen2.5-VL模型在自定义数据集上进行了微调。
这个过程让我深刻体会到:多模态微调不仅仅是"加载模型-喂数据-等结果"那么简单,背后涉及环境配置、权重转换、数据处理等诸多细节。
今天就把这段实战经历分享出来,希望能帮助想要入门多模态微调的朋友少踩些坑。
1 为什么选择MindSpeed MM套件
在开始动手之前,我其实对比过几个多模态训练框架。
最终选择MindSpeed MM,主要看中三点:第一是它对昇腾硬件做了深度优化,训练性能确实比通用框架快不少;第二是预置了30+主流多模态模型,Qwen2.5-VL、InternVL这些热门模型都开箱即用;第三是文档相对完善,遇到问题能找到解决思路。
MindSpeed MM套件的架构设计挺清晰:底层是CANN和PyTorch适配层,中间是MindSpeed Core加速库(提供并行、内存、通信优化),上层分为LLM、MM、RL三个套件。
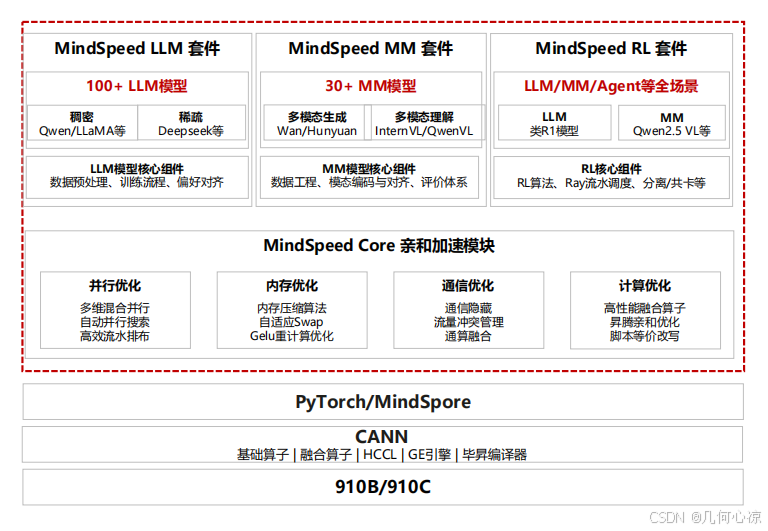
多模态套件覆盖了视图生成(像OpenSora、HunyuanVideo)、视图理解(像Qwen2-VL、InternVL)和全模态模型(像Qwen2.5-Omni)。

不同版本的MindSpeed MM对应的PyTorch、torch_npu、CANN版本是严格绑定的。
我一开始图省事直接装了最新版torch,结果跑起来各种报错,后来严格按配套表安装才解决。版本不匹配真的是大坑!
2 环境搭建,细节决定成败
环境准备这一步看似简单,实际上藏着不少坑。我的服务器是Atlas 800T A2,系统是ARM架构的Linux。
整个环境搭建分四步走。
- 驱动和固件安装
要装NPU驱动和固件。
这两个必须配套,我下载的是Ascend HDK 25.2.0版本:
# 安装驱动
bash Ascend-hdk-*-npu-driver_*.run --full --force
# 安装固件
bash Ascend-hdk-*-npu-firmware_*.run --full
安装过程中有个细节:如果系统之前装过旧版驱动,一定要先卸载干净再装新版,否则可能出现驱动冲突。
我第一次就是因为没卸载彻底,导致npu-smi命令识别不到卡。
- CANN安装的正确姿势
CANN(Compute Architecture for Neural Networks)是昇腾的异构计算架构。
安装顺序很重要:先装toolkit,再装kernels,最后装nnal。
每装一个都要source环境变量:
# 安装toolkit
bash Ascend-cann-toolkit_8.2.RC1_linux-aarch64.run --install
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 安装kernels
bash Ascend-cann-kernels-*_8.2.RC1_linux-aarch64.run --install
# 安装nnal(注意需要先source才能装)
bash Ascend-cann-nnal_8.2.RC1_linux-aarch64.run --install
source /usr/local/Ascend/nnal/atb/set_env.sh
这里有个教训:第一次我装完toolkit没source环境变量就直接装nnal,结果提示找不到依赖。后来才明白,nnal的安装依赖toolkit的环境变量。
- Python环境和依赖库
(1)用conda创建了独立环境,Python选3.10版本(官方推荐):
conda create -n mm_env python=3.10
conda activate mm_env
(2)安装torch和torch_npu。
这两个包要从昇腾官网下载对应ARM版本的whl文件,不能直接pip install:
pip install torch-2.7.1-cp310-cp310-manylinux_2_28_aarch64.whl
pip install torch_npu-2.7.1*-cp310-cp310-manylinux_2_28_aarch64.whl
(3)拉取代码仓并安装MindSpeed加速库:
git clone https://gitee.com/ascend/MindSpeed.git
cd MindSpeed
git checkout 6d63944cb2470a0bebc38dfb65299b91329b8d92
pip install -r requirements.txt
pip install -e .
(4)还要编译安装apex库。这个库提供了混合精度训练等优化,建议从源码编译而不是直接pip安装,性能会更好。
整个环境安装下来大概需要1-2小时,建议在tmux或screen里进行,避免因为网络中断前功尽弃。
3 权重转换,不可忽视的一步
环境搞定后,我从Hugging Face下载了Qwen2.5-VL-7B-Instruct的预训练权重。但这个权重不能直接用于MindSpeed MM训练,需要先转换格式。
为什么要转换?因为MindSpeed MM修改了部分网络结构的命名,并且支持Pipeline Parallel(流水线并行),需要把权重切分到不同卡上。
转换命令如下:
mm-convert Qwen2_5_VLConverter hf_to_mm \
--cfg.mm_dir "ckpt/mm_path/Qwen2.5-VL-7B-Instruct" \
--cfg.hf_config.hf_dir "ckpt/hf_path/Qwen2.5-VL-7B-Instruct" \
--cfg.parallel_config.llm_pp_layers [[12,16]] \
--cfg.parallel_config.vit_pp_layers [[32,0]] \
--cfg.parallel_config.tp_size 1这里几个参数的含义:
- mm_dir:转换后的保存路径
- hf_dir:原始Hugging Face权重路径
- llm_pp_layers:语言模型在每张卡上的层数分配
- vit_pp_layers:视觉编码器在每张卡上的层数分配
- tp_size:Tensor Parallel的并行度
我一开始把llm_pp_layers配置成[[28]](所有层放一张卡),结果训练时显存直接爆了,后来改成[[12,16]](分两张卡),问题才解决。
这说明合理的并行配置对显存管理至关重要。
4 数据处理,格式转换的艺术
多模态模型的数据处理比纯文本模型复杂,因为要同时处理图像和文本。我使用的是COCO2017数据集+LLaVA-Instruct-150K描述文件。
数据准备分三步:
1. 下载COCO2017图像数据集,解压到./data/COCO2017
2. 下载LLaVA-Instruct-150K的json描述文件到./data/
3. 运行数据转换脚本:python examples/qwen2vl/llava_instruct_2_mllm_demo_format.py
转换脚本会把原始json转成MindSpeed MM要求的格式。
转换后的数据长这样:
{
"conversations": [
{"from": "human", "value": "<image>\nWhat is in this image?"},
{"from": "gpt", "value": "A cat sitting on a couch."}
],
"image": "COCO_train2017_000000001234.jpg"
}
修改data.json配置文件,指定数据集路径:
{
"dataset_param": {
"preprocess_parameters": {
"model_name_or_path": "./ckpt/hf_path/Qwen2.5-VL-7B-Instruct"
},
"basic_parameters": {
"dataset_dir": "./data",
"dataset": "./data/mllm_format_llava_instruct_data.json",
"cache_dir": "./data/cache_dir"
}
}
}有个小技巧,如果只是想快速验证流程,可以在data.json里设置max_samples参数,比如只读100条数据,这样调试时能快速迭代,等确认没问题再放开限制。
5 开始微调,参数配置与启动
微调脚本finetune_qwen2_5_vl_7b.sh里有几个关键配置:
# 权重加载和保存路径
LOAD_PATH="ckpt/mm_path/Qwen2.5-VL-7B-Instruct"
SAVE_PATH="save_dir"
# 训练参数
GPT_ARGS="
--no-load-optim \
--no-load-rng \
--no-save-optim \
--no-save-rng \
"
# 日志和保存间隔
OUTPUT_ARGS="
--log-interval 1 \
--save-interval 5000 \
--log-tps \这里no-load-optim和no-save-optim表示不加载/保存优化器状态,可以节省时间和磁盘空间,但如果要断点续训,就需要把这些参数去掉。
save-interval 5000表示每5000步保存一次权重。我一开始设置成500,结果发现因为分布式优化器的权重文件特别大(几十GB),频繁保存严重拖慢训练速度,后来改成5000才合理。
单机8卡启动命令:
export NPUS_PER_NODE=8
export NNODES=1
bash examples/qwen2.5vl/finetune_qwen2_5_vl_7b.sh启动后会看到类似这样的日志:
iteration 100/10000 | consumed samples: 800 | elapsed time per iteration (ms): 1250.5 | learning rate: 1.000E-05 | global batch size: 8 | loss: 2.345 | grad norm: 1.234
从日志可以看到当前迭代步数、loss、学习率等信息,我观察到前几百步loss下降很快,之后趋于平缓,这是正常现象。
第一次训练建议先跑几百步,观察loss是否正常下降、显存是否溢出、日志是否有异常。确认没问题后再跑完整流程,避免浪费时间。
6 视觉编码器重计算,性能与显存的权衡
默认配置下,Qwen2.5-VL会冻结视觉编码器(ViT)只训练语言模型部分,但如果想微调ViT,显存可能不够。这时可以启用重计算(Recomputation)来降低显存占用。
重计算的原理是:前向传播时不保存中间激活值,反向传播时重新计算。
这样用时间换空间,显存占用降低但训练速度会变慢。
在model.json里配置重计算有两种模式:
(1)Full模式(重计算所有组件):
{
"vision_encoder": {
"recompute_granularity": "full",
"recompute_method": "uniform",
"recompute_num_layers": 16
}
}
(2)Selective模式(只重计算attention):
{
"vision_encoder": {
"recompute_granularity": "selective"
}
}我的实测结果:full模式能节省约30%显存,但训练速度降低约15%;selective模式节省约15%显存,速度降低约5%。具体选哪种要根据显存和时间预算来权衡。
7 推理验证,检验微调效果
训练完成后,用推理脚本来验证效果:
bash examples/qwen2.5vl/inference_qwen2_5_vl_7b.sh
推理配置文件inference_qwen2_5_vl_7b.json里要指定:
- tokenizer路径(原始Hugging Face权重路径)
- 模型权重路径(转换后的权重路径)
我用训练后的模型测试了几张COCO图片,发现描述质量确实比原始模型好,特别是对细节的描述更准确,这说明微调生效了。
多模态大模型微调确实比纯文本模型复杂,但掌握这套流程后,换其他模型(比如InternVL、CogVideoX)也是类似的。
昇腾平台的MindSpeed MM套件把很多底层优化封装好了,只需要关注数据和业务逻辑,开发效率还是挺高的。

欢迎加入北京社区
更多推荐


 73
73 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)