
面试官:Mysql主从一致性问题如何优化?MySQL主从架构数据一致性保障策略深度解析
在分布式数据库架构设计中,MySQL主从复制是最常见的高可用解决方案之一。然而,在实际生产环境中,我们经常会遇到这样的场景:刚刚在主库完成的写操作,立即从从库查询却得不到最新的数据。这种现象背后的核心问题就是数据一致性与系统性能之间的平衡艺术。
MySQL主从架构数据一致性保障策略深度解析
作者:默语佬
专栏:数据库架构实战
发布时间:2025年9月
引言
在分布式数据库架构设计中,MySQL主从复制是最常见的高可用解决方案之一。然而,在实际生产环境中,我们经常会遇到这样的场景:刚刚在主库完成的写操作,立即从从库查询却得不到最新的数据。这种现象背后的核心问题就是数据一致性与系统性能之间的平衡艺术。
本文将从工程实践的角度,深入剖析MySQL主从架构中数据一致性问题的本质,并提供四种渐进式的解决方案,帮助架构师在不同业务场景下做出最优的技术决策。
问题本质:异步复制带来的数据时差
复制延迟的技术原理
在MySQL主从复制体系中,数据不一致的根本原因在于异步复制机制所带来的时间窗口问题。
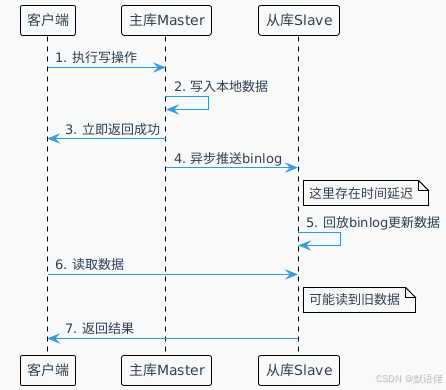
这种异步机制虽然保证了主库的高性能写入,但也引入了数据可见性延迟的问题。在实际生产环境中,这个延迟时间可能从几毫秒到几秒不等,具体取决于:
- 网络延迟:主从节点间的网络质量
- 从库性能:从库的硬件配置和负载情况
- binlog大小:单次同步的数据量
- 并发度:同时进行的复制线程数量
业务影响分析
数据一致性问题在不同业务场景下的影响程度截然不同:
高敏感场景:
- 金融交易系统:余额查询必须实时准确
- 电商库存管理:防止超卖问题
- 用户认证系统:权限变更需要立即生效
低敏感场景:
- 社交媒体:点赞数、评论数的轻微延迟
- 内容管理:文章浏览量、统计数据
- 日志分析:非实时性的数据分析需求
四种渐进式解决方案
基于不同的业务需求和技术复杂度,我们提供四种渐进式的解决方案:
方案一:容忍延迟
设计理念:业务能接受,就不做额外设计。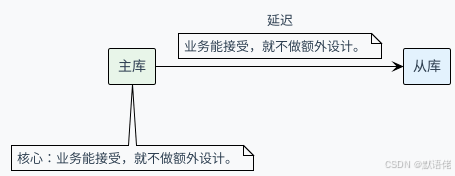
技术特点:
- 零额外成本:无需任何架构改动
- 最佳性能:主库写入性能达到最优
- 运维简单:保持原有架构的简洁性
适用场景评估: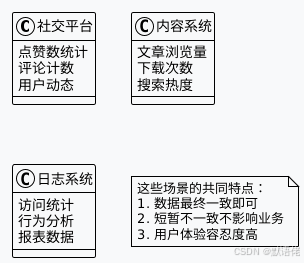
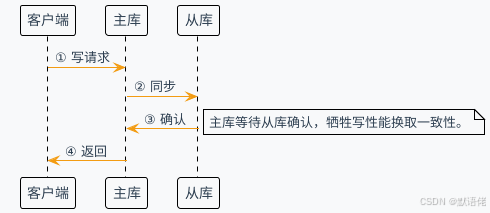
方案二:半同步复制
设计理念:主库等待从库确认,极性写性能换取一致性。
配置实现:
-- 在主库上启用半同步复制
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
SET GLOBAL rpl_semi_sync_master_enabled = 1;
SET GLOBAL rpl_semi_sync_master_timeout = 1000; -- 1秒超时
-- 在从库上启用半同步复制
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
性能权衡分析:
- 一致性提升:大幅缩短数据不一致窗口
- 写入延迟:增加网络往返时间成本
- 可用性影响:从库异常可能影响主库写入
方案三:强制读主
设计理念:读写全部走主库,保证强一致性。
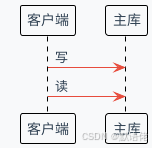
架构设计要点:

实现策略:
- 业务分层:核心业务读主,非核心业务读从
- 缓存前置:Redis承担大部分读流量
- 连接池隔离:主从库使用独立连接池
方案四:选择性读主
设计理念:引入缓存标记,智能路由请求。
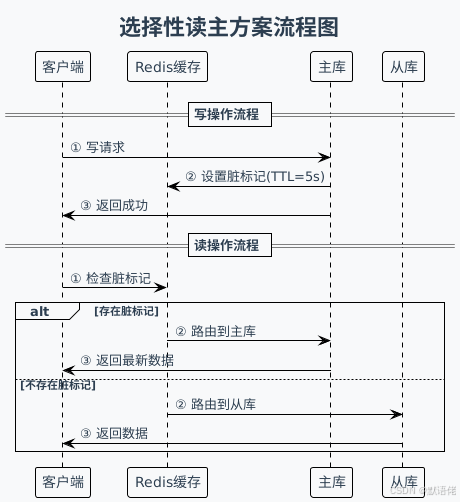
核心实现逻辑:
@Service
public class SmartReadService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private MasterDataSource masterDataSource;
@Autowired
private SlaveDataSource slaveDataSource;
/**
* 智能读取策略
*/
public User getUserById(Long userId) {
String dirtyKey = "user_dirty:" + userId;
// 检查脏标记
if (redisTemplate.hasKey(dirtyKey)) {
// 存在脏标记,读主库
return masterDataSource.selectUserById(userId);
} else {
// 无脏标记,读从库
return slaveDataSource.selectUserById(userId);
}
}
/**
* 更新用户信息
*/
@Transactional
public void updateUser(User user) {
// 1. 更新主库
masterDataSource.updateUser(user);
// 2. 设置脏标记,TTL为预估的主从延迟时间
String dirtyKey = "user_dirty:" + user.getId();
redisTemplate.opsForValue().set(dirtyKey, "1", 5, TimeUnit.SECONDS);
}
}
TTL时间设定策略:
- 保守策略:设置为平均延迟的2-3倍
- 监控驱动:基于实时监控数据动态调整
- 业务差异化:不同业务场景设置不同TTL
深度技术洞察
延迟监控与预警
在生产环境中,建立完善的延迟监控体系至关重要:
-- 监控主从延迟的SQL
SHOW SLAVE STATUS\G
-- 关键指标
-- Seconds_Behind_Master: 从库落后主库的秒数
-- Master_Log_File, Read_Master_Log_Pos: 主库binlog位置
-- Relay_Log_File, Relay_Log_Pos: 中继日志位置
监控告警策略: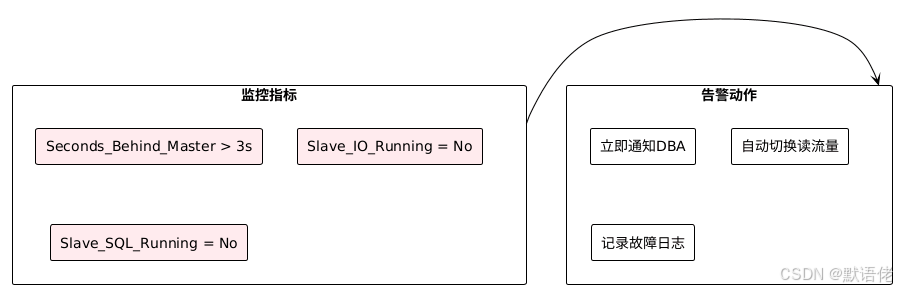
性能优化建议
主库优化:
- binlog格式:推荐使用ROW格式,减少从库回放复杂度
- 并行复制:启用多线程复制提升同步效率
- 网络优化:使用专用网络链路,降低网络延迟
从库优化:
- 硬件配置:SSD存储,充足内存
- 参数调优:适当调整
slave_parallel_workers - 索引策略:确保从库有足够的索引支持查询
容灾与故障处理
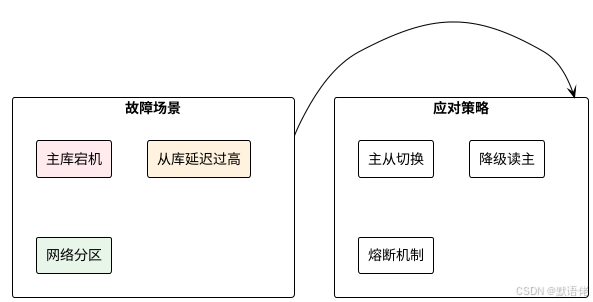
方案对比与选择指南
| 方案 | 一致性 | 性能影响 | 架构复杂度 | 适用场景 |
|---|---|---|---|---|
| 容忍延迟 | 最终一致 | 无影响 | 最简单 | 社交、内容类应用 |
| 半同步复制 | 强一致 | 写性能下降20-30% | 简单 | 内部系统、管理后台 |
| 强制读主 | 强一致 | 主库压力大 | 中等 | 金融、交易系统核心模块 |
| 选择性读主 | 强一致 | 最优平衡 | 最复杂 | 大型互联网应用 |
选择决策树
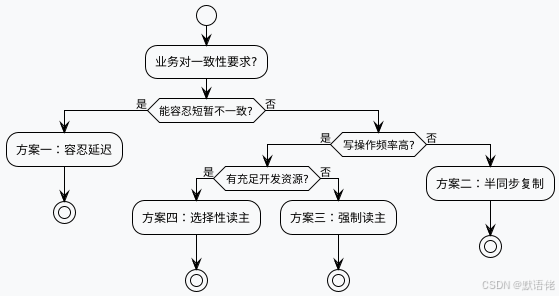
实战经验总结
最佳实践建议
- 渐进式演进:从简单方案开始,根据业务发展逐步演进
- 监控先行:在任何优化之前,先建立完善的监控体系
- 业务分层:不同重要级别的业务采用不同的一致性策略
- 容量规划:充分考虑主库承载能力,避免性能瓶颈
常见陷阱规避
- 过度设计:不要为了技术而技术,始终以业务需求为导向
- 监控盲区:忽视对延迟、错误率等关键指标的监控
- 缓存雪崩:Redis故障时的降级策略要提前规划
- 数据倾斜:注意某些热点数据的读写压力分布
总结
MySQL主从架构的数据一致性问题,本质上是CAP定理在实际业务中的具体体现。我们无法同时获得完美的一致性、可用性和分区容错性,只能在具体的业务场景下做出最适合的权衡。
从容忍延迟的佛系态度,到半同步复制的性能妥协,再到强制读主的简单粗暴,最后到选择性读主的精细化治理,这四种方案代表了架构设计中不同的权衡哲学。
真正优秀的架构师,不是那个能设计出最复杂系统的人,而是能够在复杂的业务需求中找到最简单、最有效解决方案的人。没有最好的架构,只有最合适的架构。
关于作者:默语佬,CSDN博主,专注于分布式系统架构设计与实践。如果这篇文章对您有帮助,欢迎点赞、收藏和关注!
相关文章推荐:
- 《深入理解MySQL InnoDB存储引擎》
- 《分布式事务解决方案全景解析》
- 《Redis集群架构设计与实践》

欢迎加入北京社区
更多推荐



 22
22 0
0- 0



 已为社区贡献112条内容
已为社区贡献112条内容

所有评论(0)