

搞懂MySQL中的SQL优化,就靠这篇文章了
✍大家好,我是默语,别名默语博主,擅长的技术领域包括Java、运维和人工智能。我的技术背景扎实,涵盖了从后端开发到前端框架的各个方面,特别是在Java 性能优化、多线程编程、算法优化等领域有深厚造诣。目前,我活跃在CSDN、掘金、阿里云和 51CTO等平台,全网拥有超过10万的粉丝,总阅读量超过1400 万。统一 IP 名称为默语或者默语博主。
搞懂MySQL中的SQL优化,就靠这篇文章了
博主 默语带您 Go to New World.
✍ 个人主页—— 默语 的博客👦🏻 优秀内容
《java 面试题大全》
《java 专栏》
《idea技术专区》
《spring boot 技术专区》
《MyBatis从入门到精通》
《23种设计模式》
《经典算法学习》
《spring 学习》
《MYSQL从入门到精通》数据库是开发者必会基础之一~
🍩惟余辈才疏学浅,临摹之作或有不妥之处,还请读者海涵指正。☕🍭
🪁 吾期望此文有资助于尔,即使粗浅难及深广,亦备添少许微薄之助。苟未尽善尽美,敬请批评指正,以资改进。!💻⌨
默语是谁?
大家好,我是 默语,别名默语博主,擅长的技术领域包括Java、运维和人工智能。我的技术背景扎实,涵盖了从后端开发到前端框架的各个方面,特别是在Java 性能优化、多线程编程、算法优化等领域有深厚造诣。
目前,我活跃在CSDN、掘金、阿里云和 51CTO等平台,全网拥有超过10万的粉丝,总阅读量超过1400 万。统一 IP 名称为 默语 或者 默语博主。我是 CSDN 博客专家、阿里云专家博主和掘金博客专家,曾获博客专家、优秀社区主理人等多项荣誉,并在 2023 年度博客之星评选中名列前 50。我还是 Java 高级工程师、自媒体博主,北京城市开发者社区的主理人,拥有丰富的项目开发经验和产品设计能力。希望通过我的分享,帮助大家更好地了解和使用各类技术产品,在不断的学习过程中,可以帮助到更多的人,结交更多的朋友.
我的博客内容涵盖广泛,主要分享技术教程、Bug解决方案、开发工具使用、前沿科技资讯、产品评测与使用体验。我特别关注云服务产品评测、AI 产品对比、开发板性能测试以及技术报告,同时也会提供产品优缺点分析、横向对比,并分享技术沙龙与行业大会的参会体验。我的目标是为读者提供有深度、有实用价值的技术洞察与分析。
搞懂MySQL中的SQL优化,就靠这篇文章了
在说优化之前需要先GET到以下知识点,这样便于后续的分析。看完这篇文章不仅要会如何优化,还要搞懂为什么这样优化。
半双工通信:MySQL的数据传输采用的是半双工通信,同一时间要么是客户端向服务端发送数据,要么是服务端向客户端发送数据,这两个动作不能同时发生。MySQL对客户端发送数据也有要求,一次发送所有数据,等服务端响应后才能发送下次数据。
顺序读写与随机读写:数据库数据都是要落盘的,由于磁盘物理结构,寻道时间过长,故顺序读写比随机读写效率高很多。如果不太懂,可以想想平时坐车,你是坐一趟车直达(顺序读写)好呢?还是各种换乘(随机读写)好呢?
结果缓存:MySQL对查询的结果是支持缓存的,默认关闭。(提示一下,对于频繁更新的数据尽量不要使用MySQL本身的缓存,缓存失效造成更多性能浪费)
SQL查询流程:客户端发送查询SQL,通过数据传输到服务端,优先查询结果缓存,如果未命中则先后通过解析器、预处理器、优化器、执行计划、执行引擎、存储引擎后得到结果放入内存中并返回给客户端。(后续专门写一篇文章介绍下)
索引(Index):帮助MySQL高效获取数据的数据结构,MySQL中大部分索引都使用多路平衡查找树。
在对索引优化之前,需要知道索引的具体结构。根据不同的存储引擎数据的存储结构也不一样,存储引擎主要使用的有InnoDB、MyISAM。本文主要讲InnoDB的索引优化。
InnoDB引擎索引说明
聚簇索引
每个表都有一个聚簇索引:
- 主键存在时以主键为聚簇索引,
- 主键不存在时,以第一个不含有null值的唯一索引作为聚簇索引
- 以上索引都不存在时,MySQL会创建一个隐藏字段rowid的聚簇索引。
每个表的数据按照聚簇索引而聚集在一起形成B+树。其中在最后的叶子节点挂载非索引数据,叶子节点之间存在有序的指针。
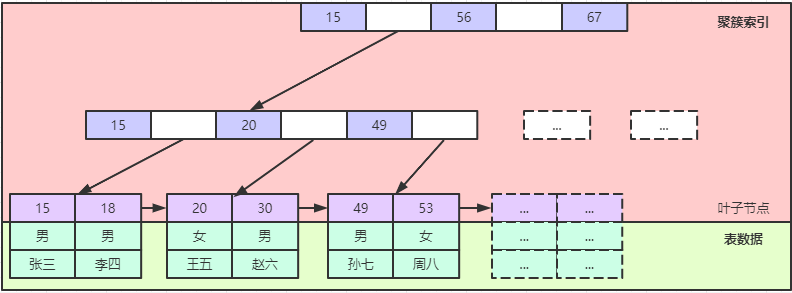
聚簇索引图示1
辅助索引
表中除了聚簇索引外其他非聚簇索引成为二级索引或者辅助索引,辅助索引中的叶子节点不再挂载非索引数据,而是存储聚簇索引的索引值

辅助索引图示2
联合索引
特殊的辅助索引:联合索引,B+树的节点存储的不是一个列数据,而是多个列数据,按照定义的顺序构成一个节点。
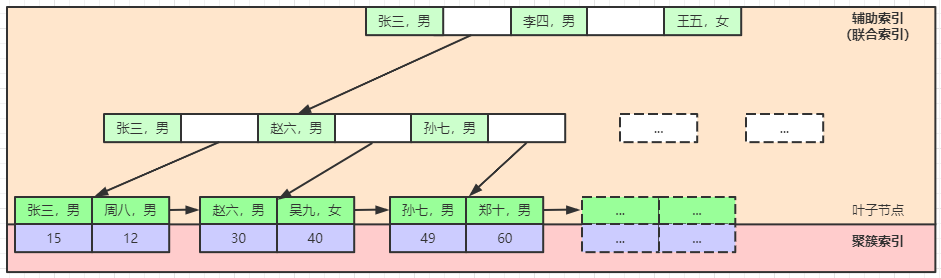
联合索引图示3
在对B+树存储结构有一定了解下,从实用角度来分析如何优化SQL。这也是SQL优化器要做的功能。
索引优化
主键的选择
首先了解B+树是有序多路平衡查找树,也就是插入之前需要排序的,为了平衡还需要拆页、旋转等操作。
先说顺序本身,顺序是比较之后的结果,如何比较?MySQL在建立数据的时候必须指定编码格式和排序方式,这时便有了比较顺序的方式。无论主键是何种类型,数字、字符串都会转换编码,然后排序。主键的可比较性决定了主键的效率
再说顺序意义,仔细观察聚簇索引图示1的叶子节点,也就是最后一层,这是一个有序的页(图示中放在一块的数据称为一页)列表。每次插入都是先确定主键的位置,然后才记录数据的,叶子节点的是否有序插入决定了主键的效率。主键的有序性决定的磁盘读写的有序性(顺序写比随机写效率高很多)。
以上两点足以说明MySQL中主键的有序性的重要性。所以选择主键优先选择有序主键,自增主键就是有序主键。当然也不要这么绝对,当数据量过小时这点效率差距是基本看不出来的。
顺便说下经常被问的UUID主键和自增主键的选择,在数据量过小或者业务刚性需求时,二者皆可。在数据量过大时,推荐自增主键,不仅仅因为有序性,还因为字符串的存储空间是大于整型的存储空间的。
排序的选择
前面说顺序,这里就使用下顺序,索引树的叶子节点本身就是有序的,在查询时order by越匹配该顺序则查询效率越高。因此在排序时,尽量按照所使用的索引进行排序,也因此全表查询时默认是主键排序。如果查询条件中涉及到了其他索引则默认以首个索引的顺序为主。如果不确定使用了什么索引,则应该主动指定排序列
同样基于以上,推荐在频繁排序或者分组的列上建立索引
索引树中数据如何获取
首先先明确一点,索引树中数据分为2种,1:索引树非叶子节点存储的是索引数据,2:索引叶子节点存储的是索引数据和表非索引数据。
其次也要明确:聚簇索引是一颗存有全表数据的索引树,每个表都是必有的。其他辅助索引每建立一个就会多一颗索引树,只是和图示一样叶子节点不存储数据
因此获取SQL查询数据应该从2个角度分析
- 从不同索引树角度
- 查询聚簇索引树
- 查询非聚簇索引树
- 从查询数据所在位置角度
- 查询索引树中非叶子节点数据(即索引数据),不查其他数据
- 查询叶子节点中的数据(包含索引和非索引数据)。
SQL索引优化注重点之一在数据所处位置
如果查询的数据全部在索引树非叶子节点(即查询索引列)时,此时效率是最高的,因为节点的有序性,通过高效算法能很快找到数据完成查询,这种查询称为覆盖索引查询。这点告诉使用者:尽量不要使用select *,同时也应该知道,如果一个表列全是索引,那一定会走索引。(别再说什么 not null 、!= 一定不走索引的问题了)
如果查询的数据不在索引树非叶子节点(即查询非索引列)时,注意此时SQL优化器很有可能会优化书写的SQL,导致最终执行的SQL和客户端传输的SQL不一致。
先说下此时正规的数据查找流程:
- 如果查询条件存在索引,则使用第一个索引条件列(优化后的)去首次加载数据行
- 索引为聚簇索引,则在聚簇索引树上,根据算法查询到索引所处的叶子节点位置,把该位置的对应数据获取即可
- 索引为非聚簇索引,则在非聚簇索引树上,根据算法查询引所处的叶子节点位置,获取到该位置上的聚簇索引值,然后拿到该值在聚簇索引树上定位其位置,再把聚簇索引树叶子节点上对应的数据获取即可。从非聚簇索引树再到聚簇索引树的过程称为回表。
- 如果查询条件不存在索引
- 由于没有索引,所以会去聚簇索引树的非叶子节点数据处进行全表扫描,逐个匹配,直至扫描完毕获取到数据返回
从聚簇索引中获取到的数据行,会加载到内存中,然后在进行
where其他条件的过滤,最后才返回过滤后的数据,
这点告诉使用者:where条件中首个条件应尽量精确匹配(例如主键、高离散度索引列)数据。
索引树的分裂、节点移除
索引树中每个页存储的数据个数是固定的,例如4个,当该页新增数据时,如果数据已满4个,则需要分裂为2个页,每页还是4个来保证。
节点移除时,索引树会进行旋转来达到平衡。具体流程可自行查询平衡树。这里只需要知道:索引树调整很浪费时间,开销很大。
因此频繁更新的列,不适合作为主键或者索引
最左匹配原则
问个索引优化,都说最左匹配原则,可是否知道为什么是最左匹配,如何匹配?
在上面说顺序时提到了如何排序,这里如何匹配也是类似,例如abc和abd如何匹配,这里说下通俗理解(不一定是实现),把这两个字符逐个通过编码、排序获取排序值,假设a编码后排序值为 32,b 编码后排序值为33,c 编码后排序值为 34,设d编码后排序值为35;匹配时先对a比较==,如果不等则不必再进行匹配,如果相等则比较b、然后c,最终发现35>34于是结果就是不匹配。第一步的a的匹配就是最左开始匹配原则。
最左匹配的应用:
-
like匹配,只有左边字符确定才能支持最左匹配原则,即不支持%xxx匹配。 -
联合索引匹配,联合索引中非叶子节点中数据存储是安装联合索引定义的顺序组合成一个节点的,例如
index0,index1,index2一旦顺序不对则不能进行匹配。但是记住一点:组合后的索引节点是按照一个节点在索引中排序的,也就是哪怕匹配了一个索引也是能提高效率的。例如:聚合索引a,b,c查询条件where a=1 and c=1,此时a=1是能走聚合索引的,但是c就不行了,此时等同于%c。这里也有个坑,会问这个查询是否走索引,回答是走索引(部分走也是走)。还有查询条件中遇到范围查询(like != > < 等)则会中止后续匹配。直接理解为联合索引就是一个拼接后的字符列索引,遇到范围查询则会导致开销指数级变大。
索引条件下推ICP
在索聚簇索引树查询数据行之前,匹配的数据行越少,越精确则查询效率越高。ICP(index_condition_pushdown)技术就是优化的这部分,旨在尽量减少数据行加载到内存中。在InnoDB引擎中ICP只支持联合索引,因为聚簇索引能直接锁定要查询的数据行,无法继续再筛选(聚簇索引只有一个索引),而联合索引则是至少2个索引,在第一个索引匹配的行数和后续其他联合索引匹配的行数处理后,再回表到聚簇索引树中查询数据,这样聚簇索引树中的数据行就会缩减,从而提高效率。ICP技术是默认开启的。explain提示信息为:Using index condition,设置参数为:index\_condition\_pushdown
ICP应用:
- 尽量建立聚合索引而不是多个单索引,
where条件后面按照聚合索引列作为条件
函数对索引条件的影响
内置函数
MySQL函数的contract,date_format,count等
函数区分为2种,1:该函数可以得到确定的结果,这种称为确定性函数,2:该函数不能得到确定的结果,具体的结果由参数决定,这种称为不确定性函数
表达式
计算表达式,1+1、2*3等
函数和表达式位置分为条件左侧和右侧,条件左侧即条件列,右侧为查询条件。
- 对于右侧:
- 确定性函数大部分可以使用索引,例如:
contract、pow - 不确定性函数基本不能使用索引,例如:
rand,uuid
- 确定性函数大部分可以使用索引,例如:
- 对于左侧:
- 一定导致索引失效,而且任何对左侧索引列的处理都会导致索引失效,包含编码格式、函数、表达式计算等。 例如:
where age + 10 = 30应写为where age = 30 + 10这种写法没问题,MySQL会自动优化为where age = 40
- 一定导致索引失效,而且任何对左侧索引列的处理都会导致索引失效,包含编码格式、函数、表达式计算等。 例如:
NULL的优化
MySQL支持索引列的null查询,且支持is not null和is null,属于范围查询。出现索引失效的一般都是因为回表开销过大导致的,毕竟数据为null为少数或者多数。
非空约束列的is null查询不会走索引,因为有比索引更高效的查询方式。
开销优化
MySQL的优化器是基于开销的,它对客户端的SQL会解析出多条同样效果的SQL,最终选择的是开销最小的SQL。基本所有的优化都基于此。
离散度体现的开销
例如:在性别sex列表建立索引,然而sex值只有0和1。如果表中数据全是男或者全是女,优化器会觉得全表扫描会由于索引查询,毕竟不用从索引树的根节点逐个比较。
开销大小对索引而已外观表现为索引列数据的离散度,离散度相当于count(distinct(column_name))/count(*)。对于这种离散度低的列不建议建立索引
全表扫描开销
例如:聚合索引a,b,c,在查询条件中使用where a=1 or d=1,这里d为非索引列,此时会导致匹配d时必须全表扫描,既然都全表扫描了说明索引树中的数据行都加载到了内存,因此没必要通过索引去过滤,定位聚簇索引树的位置了,于是最终采用的是全表扫描而不会走索引。注:如果表所有列都是索引则全表扫描也是走索引树扫描。覆盖索引优先级比全表扫描优先级高
联合索引顺序开销
例如:聚合索引a,b,c,在查询条件中书写顺序where a=1 and b=1 and c=1和书写顺序where c=1 and a=1 and b=1不影响索引使用,SQL优化器会分析出最小的开销,就是按照索引定义顺序来纠正查询条件。符合最左匹配原则才有意义。
其他索引优化
MySQL优化点很多,只是列一些常见的优化
隐式转换
字符串类型的列一定要加单引号’',否则会隐式转换为数字,导致索引失效
负向索引
负向索引(<> 、!= 、not in)有可能使用索引,但是大部分不会使用索引,这要基于SQL优化器优化了。例如对于索引列a,如果值全是1(离散度过低),此时<>1 、!=、not in(1) 都是会走索引的。注意不走索引便意味着全表扫描。
对于负向索引(not like) 一定不走索引。
强制索引
当SQL优化器优化后不是想要的SQL时,可以指定强制索引(force index(idx_name))来让SQL使用指定的索引查询,不一定会采用,只有多个执行计划中有这个索引的执行计划时才有效(毕竟强制一个不查询的索引也没意义)。
其他优化
查询结果越少越好
前面提到MySQL是半双工通信,客户端需要等待服务端处理好结果且返回之后才能继续。如果查询结果很大,会导致后续请求阻塞。故善用limit,不要select *,也注意insert into xxx select xxx这个select结果也是越少越好
子查询越少越好,最好不存在
子查询会导致多次查询数据行,浪费IO。个人建议即使多次请求也比子查询好。不仅能看懂,效率也不一定降低。
查询SQL越精确越好
SQL越精确,在进行查找时读取的数据行越少,查询效率越高。
尽量不要随机读取
基于磁盘性能,随机读取效率差,索引树查询开销大,不建议
常量查询效率比索引查询高
能使用常量查询的尽量使用常量查询
例如:只是确认是否存在,没必要查询其他字段
select 1 from user where name='xx' limit 1
例如 非空约束列查询is null
时间字段尽量使用数据库函数
虽然说大部分数据库和线上库都会统一时间,但是防止埋坑,而且数据库自身的效率会高点,当然这点性能没什么影响。如果没必要还是建议使用数据库自身的时间函数来填充时间字段。
update user set modify_time=now()
使用IN代替OR
针对同列的IN 和 OR 如果查询字段是索引列,则二者性能基本一致,否则In的效率随着数据量增大会比OR越来越高,
针对IN,MySQL会估算in范围的条数开销,in的范围越大开销越大,特别是不是唯一列的开销更大,此时可以考虑join等方式是否可以试下,毕竟in其实也是等值比较,join连接条件也是等值比较。当然也可以考虑exists
针对不同列的OR,例如where a=1 or b=1,会被优化为union,尽量主动书写union
select a,b from source where a=0 or b=2
推荐写法
select a,b from source where a=0
union
select a,b from source where b=2
In和Exists
使用IN时要保证IN中的总数据量小且in之后的数据量也很小才能操作其效率高。Exists则是exists语句中的数据量大,但是匹配后小则效率高。
在考虑in和exists时,思考下哪个遍历的少,哪个效率就高。
平时常见的索引优化暂时就罗列这些,一旦想起来再来补充吧!
补充
Like优化
经过数据验证,like在千万级数据时效率很差,反而没有instr函数效率高。
select xxx from xxx where xxx like '%abc%'
不如走索引的以下语句好
select xxx from xxx where xxx like 'abc%'
走索引的like不如以下语句好
select xxx from xxx where instr( xxx, 'abc' ) > 0

🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
如对本文内容有任何疑问、建议或意见,请联系作者,作者将尽力回复并改进📓;(联系微信:Solitudemind )
点击下方名片,加入IT技术核心学习团队。一起探索科技的未来,共同成长。


欢迎加入北京社区
更多推荐

 21
21 0
0- 0



 已为社区贡献168条内容
已为社区贡献168条内容

所有评论(0)