
一文搞懂:可观测性三大支柱与OpenTelemetry实战——从“监控”到“可观测性”的思维跃迁
统一日志、指标和链路追踪是排查复杂问题的必要条件——不只是云原生,传统项目和AI智能体同样离不开
📌 写在前面
凌晨两点,值班手机突然响起——核心支付服务的成功率从99.9%骤降至87%。你打开监控面板,CPU、内存、网络一切正常;翻看告警列表,没有触发任何阈值;登录服务器手动排查,十多分钟后仍然毫无头绪。这种场景对每个开发者来说都不陌生。传统监控能告诉你“有异常”,却很难回答“异常在哪”和“为什么会异常”。可观测性正是为解决这一痛点而生。
从单体应用到微服务,从传统机房到云原生,再到如今的AI智能体应用,系统的复杂度在指数级增长。一个用户请求可能跨越十几个服务节点,一次AI推理可能经历LLM调用、向量检索、工具执行等多个环节。在这样的复杂度下,仅仅靠“看几个指标”已经远远不够了。
可观测性通过指标(Metrics)、日志(Logs)、链路追踪(Traces) 三大支柱,构建起系统的“实时三维全息影像”。而OpenTelemetry作为CNCF毕业的可观测性标准,让这一切变得触手可及。
这篇笔记,我们从“监控 vs 可观测性”的本质区别出发,拆解三大支柱各自扮演的角色与协同方式,并通过Spring Boot + OpenTelemetry实战,打通从理论到落地的完整路径。

1️⃣ 监控 vs 可观测性:一字之差,思维之别
很多人把“监控”和“可观测性”混为一谈,但它们有着本质的区别。
传统监控是“预设式”的。它只能回答“已知的已知”问题——CPU使用率是否超过阈值?接口错误率是否超标?这需要你提前定义好监控指标和告警规则。监控告诉你系统出了“问题”,但无法告诉你“为什么”。
可观测性是“探索式”的。它能够回答“未知的未知”问题——比如“为什么这个用户的请求在凌晨3点超时?”、“订单支付失败的根因是什么?”——无需提前预设查询条件。
一个形象的比喻:监控如同汽车仪表盘上的故障灯,它能告诉你发动机过热了(已知故障);而可观测性则允许你实时查看水温传感器数据、冷却液循环日志以及发动机控制单元的内部状态,从而理解“为什么过热”。
可观测性通过系统外部输出的三大支柱数据,构建起系统的“实时三维全息影像”,让你可以任意穿透、回溯、关联。它不仅能回答“系统是否在预期状态内运行”,更能回答“为什么会出问题”和“系统内部正在发生什么”。
| 维度 | 传统监控 | 可观测性 |
|---|---|---|
| 思维方式 | 预设式(已知问题) | 探索式(未知问题) |
| 回答的问题 | 系统是否健康? | 为什么出问题?内部发生了什么? |
| 数据来源 | 预设的指标和告警规则 | 三大支柱(指标+日志+链路) |
| 故障定位 | 告诉你有异常 | 帮你找到根因 |
2️⃣ 三大支柱:指标、日志、链路追踪
可观测性的三大支柱——指标(Metrics)、日志(Logs)、链路追踪(Traces) ——各自承担不同的角色,三者互补而非替代。
📊 指标(Metrics):系统的“体温计”
指标是随时间推移的数值测量,用于量化系统状态和业务健康度。CPU利用率、内存使用量、请求延迟、错误率等指标数据量小、采集频率高,适合用于实时监控和告警。
在云原生环境中,Prometheus已成为指标采集和存储的事实标准,配合Grafana进行可视化展示。
指标的局限性:指标数据只能告诉你“出了什么问题”,无法告诉你“为什么出问题”。
四大黄金指标是监控体系的基石:
-
流量(Traffic) :衡量系统负载,如QPS
-
延迟(Latency) :衡量系统响应速度,如P99延迟
-
错误(Errors) :衡量系统失败率
-
饱和度(Saturation) :衡量系统资源利用程度
📝 日志(Logs):系统的“黑匣子”
日志是离散的、带时间戳的事件记录,提供最详细的上下文信息。当指标异常触发告警后,运维人员通常需要查看日志来了解具体发生了什么。
日志的挑战:数据量大、格式不统一。结构化日志是解决这些问题的关键——使用JSON等格式统一日志输出,确保每一条日志都携带trace_id和span_id,以实现在三大支柱之间的自由跳转。
杭州某互联网金融公司在2025年完成了日志体系的重构,将原本散落在12个系统中的非结构化日志统一改造后,存储成本降低了40%,问题排查时间从平均35分钟压缩至10分钟以内。
🔗 链路追踪(Traces):请求的“路线图”
在微服务架构下,一个用户请求可能经过网关、认证服务、业务服务、数据库等多个微服务。链路追踪能够记录请求在各个服务间的调用路径和耗时,是定位性能瓶颈的关键工具。
OpenTelemetry作为CNCF旗下的标准项目,已在2026年成为链路数据采集的事实规范,得到了AWS、Google Cloud和阿里云等主流云厂商的全面支持。
链路的落地难点在于采样策略的设计——全量采集会产生巨大的存储开销,而过低的采样率又会遗漏关键故障。业界通行的做法是头部采样 + 尾部采样相结合:正常请求按1%到10%比例采样,对有错误或高延迟的异常请求则100%全量保留。
3️⃣ 三大支柱如何协同定位问题?
三大支柱各自解决不同层面的问题,形成完整的观测矩阵:
| 维度 | 指标(Metrics) | 日志(Logging) | 链路追踪(Tracing) |
|---|---|---|---|
| 问题类型 | 系统是否健康? | 发生了什么? | 请求经历了哪些服务? |
| 数据形式 | 数值(计数、耗时) | 文本(结构化日志) | 调用链(Span + TraceID) |
| 时间粒度 | 聚合(秒/分钟级) | 精确(单次事件) | 精确(单次请求) |
| 分析方式 | 监控、告警、趋势 | 搜索、过滤、上下文 | 调用链可视化、延迟分析 |
三者协同的价值链条是:Metrics告诉你“有问题” → Tracing告诉你“问题出在哪条链路上” → Logging告诉你“具体发生了什么”。
一个完整的排查场景:
-
指标面板显示P99延迟突然飙升 → 指标发现问题
-
点击该时间点,穿透到链路视图 → 链路定位环节
-
发现是“支付服务”调用“风控服务”耗时异常 → 链路定位服务
-
点击异常Span,直接跳转到该请求的上下文日志 → 日志定位根因
-
发现是风控服务的数据库连接池耗尽 → 找到根本原因
这种从宏观到微观的“下钻”体验,需要统一的数据基础设施支撑。CNCF在2026年云原生观测报告中统计,已经采用三要素统一方案的企业,平均故障修复时间比仅使用传统监控的企业缩短了72%。
4️⃣ OpenTelemetry:统一可观测性的“通用语言”
4.1 从碎片化到统一
在OpenTelemetry出现之前,可观测性领域是一片“碎片化”的战场。每个云厂商都有自己的监控方案:AWS用CloudWatch,Azure用Azure Monitor,GCP用Stackdriver。再加上第三方的APM工具,工程师们常常需要同时打开五六个仪表盘才能调试一个请求。
更糟糕的是,每个工具都要求不同的SDK和埋点方式,切换后端意味着重写整个插桩代码。结果是:碎片化的可见性、越来越长的故障恢复时间、越来越沮丧的工程师。
4.2 OpenTelemetry的使命
OpenTelemetry(简称OTel)正是为解决这些问题而生的。它是一个厂商中立的开源可观测性框架,旨在标准化遥测数据(指标、日志、链路)的采集、处理和导出。
核心价值:instrument once, export anywhere(一次插桩,随处导出)。
2026年5月21日,CNCF正式宣布OpenTelemetry毕业,标志着它已成为可观测性领域的事实标准。自项目成立以来,OpenTelemetry社区已拥有超过12,000名贡献者,来自2,800多家公司,项目活跃度在CNCF 240多个项目中排名第二,仅次于Kubernetes。
4.3 OpenTelemetry核心架构
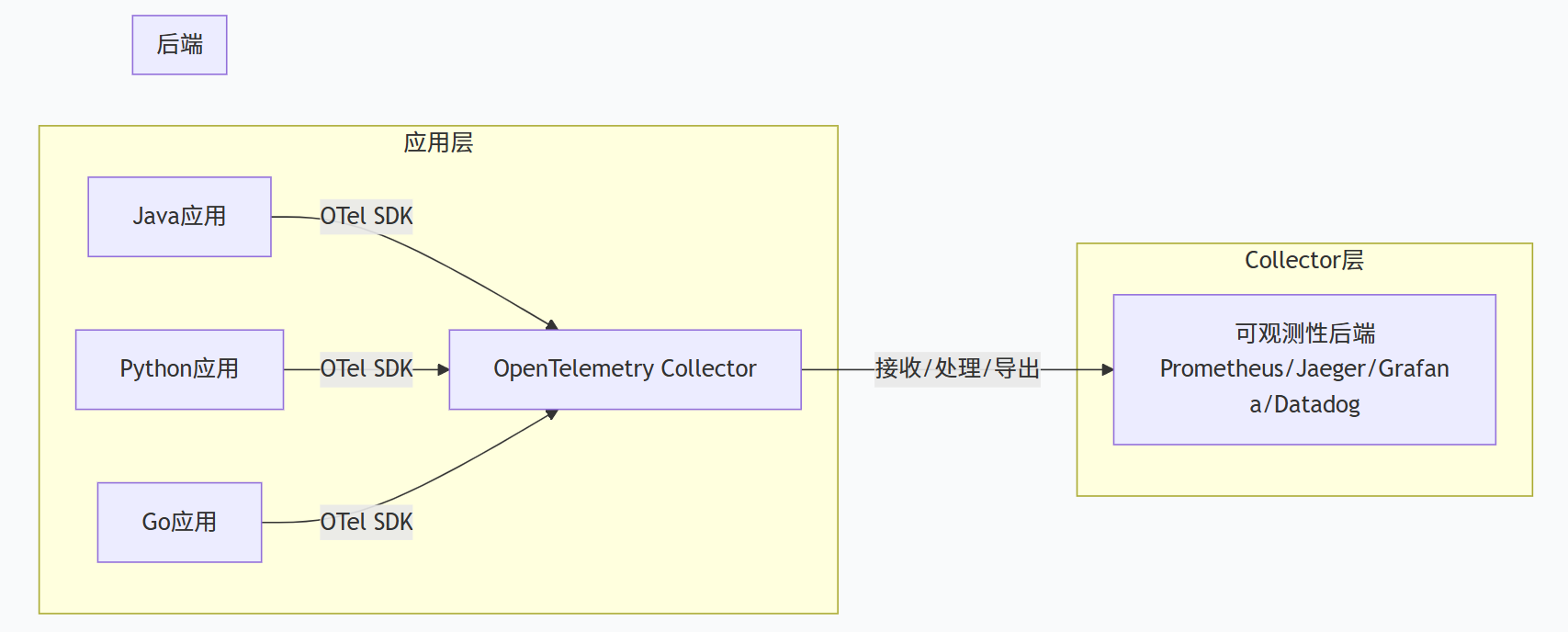
OpenTelemetry Collector是一个可执行文件,可以接收遥测数据、处理它、并将其导出到多个目标。它提供可插拔的架构,支持自定义和扩展功能。
Collector的部署通常有两种模式:
-
Agent模式:与应用同主机部署,采集本地遥测数据
-
Gateway模式:作为独立服务部署,统一接收和处理来自多个Agent的数据
5️⃣ Java + OpenTelemetry 实战:三种接入方式
对于Java/Spring Boot开发者,OpenTelemetry提供了三种接入方式:
| 方式 | Spring Boot版本 | 代码改动 | GraalVM支持 |
|---|---|---|---|
| Java Agent | 任意版本 | 零改动 | 不支持 |
| 社区Starter | 2.6+, 3.x | 少量 | 支持 |
| Spring Boot 4 Starter | 4.x | 极少 | 部分支持 |
5.1 方式一:Java Agent(零代码侵入,推荐)
Java Agent通过字节码技术自动插桩150+个库——Spring MVC、WebFlux、JDBC、JPA、Kafka、gRPC、HTTP客户端等——无需修改任何源代码。
使用步骤:
# 1. 下载agent
curl -L -O https://github.com/open-telemetry/opentelemetry-java-instrumentation/releases/latest/download/opentelemetry-javaagent.jar
# 2. 配置环境变量
export OTEL_SERVICE_NAME=my-spring-app
export OTEL_TRACES_EXPORTER=otlp
export OTEL_METRICS_EXPORTER=otlp
export OTEL_LOGS_EXPORTER=otlp
export OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317
# 3. 启动应用
java -javaagent:opentelemetry-javaagent.jar -jar my-spring-app.jar这种方式是大多数应用运行在JVM上的默认选择——启动时附加agent,无需代码改动即可获得链路、指标和日志。
5.2 方式二:社区Starter(细粒度控制)
如果需要GraalVM原生镜像支持或更细粒度的控制,可以使用社区Starter:
xml
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-spring-boot-starter</artifactId>
<version>2.13.3</version>
</dependency>5.3 方式三:Spring Boot 4官方Starter
Spring Boot 4带来了一等公民级的OpenTelemetry支持,通过spring-boot-starter-opentelemetry依赖提供自动配置和插桩。
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-opentelemetry</artifactId>
</dependency>这标志着Spring官方团队已将OpenTelemetry作为可观测性的标准方案。Spring Boot 4的模块化工作使得可以独立使用可观测性功能,而不需要引入完整的Actuator依赖。
5.4 自定义埋点:@WithSpan
对于需要细粒度追踪的业务逻辑,可以使用@WithSpan注解:
java
import io.opentelemetry.instrumentation.annotations.WithSpan;
import io.opentelemetry.instrumentation.annotations.SpanAttribute;
@Service
public class OrderService {
@WithSpan("processOrder")
public Order processOrder(
@SpanAttribute("orderId") Long orderId,
@SpanAttribute("userId") Long userId
) {
// 业务逻辑自动成为Span的一部分
return doProcess(orderId, userId);
}
}6️⃣ OpenTelemetry Collector:统一采集与分发
Collector是OpenTelemetry架构的核心组件,负责接收、处理和导出遥测数据。
6.1 Collector的核心能力
-
接收(Receivers) :通过OTLP协议接收来自各种应用的数据
-
处理(Processors) :添加元数据、采样、过滤、批处理
-
导出(Exporters) :导出到Prometheus、Jaeger、Grafana、Datadog等任意后端
6.2 Collector配置示例
yaml
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
timeout: 1s
send_batch_size: 1024
memory_limiter:
limit_mib: 512
exporters:
prometheus:
endpoint: "0.0.0.0:8889"
jaeger:
endpoint: jaeger:14250
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, memory_limiter]
exporters: [jaeger]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [prometheus]7️⃣ 传统项目、云原生与AI Agent的可观测性
可观测性不止适用于云原生微服务。它正在向更多领域延伸。
7.1 传统项目中的可观测性
即使是单体应用,可观测性同样重要。日志结构化、指标采集、请求追踪——这些实践同样能大幅提升传统项目的可维护性。
京东北美站的可观测性团队通过建立四层指标体系(基础设施层→应用层→业务层→用户体验层),将线上问题定位时间从平均22分钟压缩到了6分钟。
拥有完善可观测性体系的企业,平均故障恢复时间缩短了70%以上,年度计划外停机时间减少了60%以上。
7.2 云原生环境的可观测性
在Kubernetes环境中,OpenTelemetry Operator可以通过CRD实现Collector的自动化部署和管理。
云原生可观测性需要实现对应用性能、服务依赖、业务逻辑的全栈透视能力。从基础设施到容器编排层,从微服务到前端代码,建立覆盖全链路的观测。
7.3 AI Agent的可观测性(2026年新趋势)
随着AI Agent的普及,可观测性迎来了新的挑战。与传统应用监控不同,Agent可观测性需要回答三个核心问题:Agent的决策链是否可追溯?多Agent编排中的异常如何定位?
OpenTelemetry正在快速扩展对AI场景的支持:
-
GenAI语义约定:为LLM调用定义了标准化的
gen_ai.*属性——模型名称、Token数量、完成原因等 -
Agent链路追踪:每个工具调用、LLM调用、检索步骤都成为一个子Span,形成推理链的完整追踪
-
TraceAI等开源库:将LLM和Agent代码转化为结构化的OpenTelemetry链路
阿里巴巴与蚂蚁集团联合推出了LoongSuite GenAI可观测语义规范,在OpenTelemetry标准之上,为AI Agent、Skill、Token级推理等场景建立统一数据语言。
在Agent时代,系统“运行正常”不等于任务“做对了”。传统可观测聚焦稳定性,却无法评估语义正确性、推理合理性与业务效果。新的可观测性范式需要融合链路追踪、效果评估与根因归因,实现“观测→评估→优化”的闭环。
8️⃣ 总结:可观测性是复杂系统的“眼睛”
| 概念 | 一句话理解 |
|---|---|
| 可观测性 | 通过系统外部输出推断内部状态的能力 |
| 指标(Metrics) | 系统的“体温计”——量化系统状态,发现问题 |
| 日志(Logs) | 系统的“黑匣子”——记录事件详情,定位根因 |
| 链路追踪(Traces) | 请求的“路线图”——还原调用路径,定位瓶颈 |
| OpenTelemetry | 可观测性的“通用语言”——一次插桩,随处导出 |
三大支柱协同的价值链条:指标发现问题 → 链路定位环节 → 日志定位根因。三者组合起来,就是系统的“火眼金睛”。
可观测性不仅是排查Bug的手段,更是提升性能和效率的关键工具。从传统项目到云原生微服务,再到AI智能体应用,可观测性正成为复杂系统的“眼睛”——让你看得见、看得清、看得远。
更多推荐
 2
2 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)