
BM25 算法实战指南:从原理到 Python 生产级应用
BM25 算法实战指南:从原理到 Python 生产级应用
一、为什么你需要 BM25?(25是优化了25个版本)
在构建搜索功能时,最常见的需求是:用户输入关键词,系统返回最相关的文档。BM25(Best Match 25)是 Elasticsearch、Lucene 等主流搜索引擎的默认排序算法,它解决了 TF-IDF 的两个致命缺陷:
- 词频无限增长:TF-IDF 中词频越高得分越高,容易被关键词堆砌作弊
- 无视文档长度:长文档天然包含更多关键词,导致不公平
BM25 通过非线性词频饱和和文档长度归一化,在实际业务中通常比 TF-IDF 效果更好 10%-30%。
二、核心原理(5分钟理解)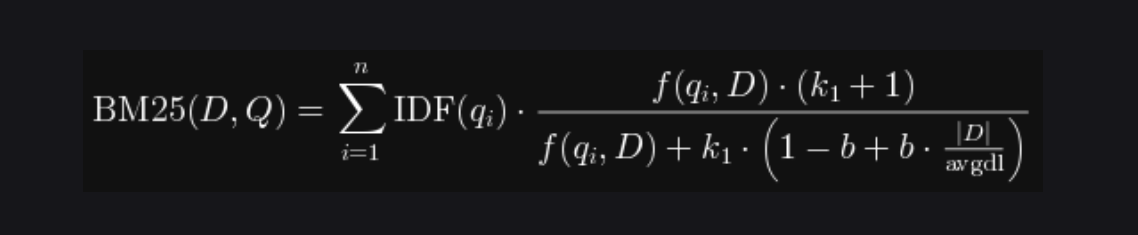
组件 作用 直观理解
IDF 逆文档频率 “BM25” 比 “的” 更有区分度,权重更高
分子 词频增益 出现次数越多越相关,但增速递减
分母 长度归一化 长文档的词频被稀释,短文档不被埋没
两个关键参数:
k1(通常 1.22.0):控制词频饱和速度,越大饱和越慢b(通常 0.75):控制长度惩罚强度,0 表示不惩罚长文档,1 表示完全按比例惩罚
三、Python 实战:从零搭建中文搜索引擎
3.1 环境准备
pip install rank-bm25 jieba
3.2 基础版:英文文档检索
先抛开分词复杂度,理解核心 API:
from rank_bm25 import BM25Okapi
# 语料:已分词的文档列表(每个文档是一个词列表)
corpus = [
["hello", "world"],
["hello", "python", "bm25"],
["python", "is", "great", "for", "information", "retrieval"],
["bm25", "is", "a", "probabilistic", "retrieval", "model"],
]
# 初始化
bm25 = BM25Okapi(corpus)
# 查询(同样需要分词)
query = ["python", "bm25"]
scores = bm25.get_scores(query)
print(scores) # [0.0, 0.937, 0.0, 1.287]
# 直接获取 Top-N 结果
top_docs = bm25.get_top_n(query, corpus, n=2)
print(top_docs) # [['bm25', 'is', ...], ['hello', 'python', ...]]
关键认知:BM25 只接受已分词的列表,不负责分词。这意味着你可以自由替换分词器(jieba、HanLP、BERT tokenizer 等),算法本身完全解耦。
3.3 进阶版:中文搜索完整流程
中文没有空格分词,必须结合 jieba 处理:
import jieba
from rank_bm25 import BM25Okapi
# ========== 原始文档 ==========
docs = [
"BM25是一种基于概率论的信息检索模型,广泛用于搜索引擎",
"Python是一种简洁优雅的编程语言,适合数据处理和机器学习",
"搜索引擎的核心技术包括倒排索引、相关性排序和查询理解",
"机器学习模型如BERT可以用于语义搜索,提升检索效果",
"信息检索领域常用的算法有TF-IDF、BM25和向量检索",
"Python的jieba库是优秀的中文分词工具,支持精确和全模式",
]
# ========== jieba 分词 ==========
# 添加专业术语,避免错误切分
jieba.add_word("信息检索")
jieba.add_word("倒排索引")
jieba.add_word("向量检索")
def tokenize(text):
"""精确模式分词 + 过滤空字符"""
return [w.strip() for w in jieba.cut(text, cut_all=False) if w.strip()]
tokenized_docs = [tokenize(doc) for doc in docs]
print("分词示例:", tokenized_docs[0])
# ['BM25', '是', '一种', '基于', '概率论', '的', '信息检索', '模型', ',', '广泛', '用于', '搜索引擎']
# ========== 初始化 BM25 ==========
bm25 = BM25Okapi(tokenized_docs, k1=1.5, b=0.75)
# ========== 查询 ==========
query = "BM25 搜索引擎 排序"
query_tokens = tokenize(query)
# 计算得分
scores = bm25.get_scores(query_tokens)
# 排序输出
print("\n=== 检索结果 ===")
results = sorted(enumerate(scores), key=lambda x: x[1], reverse=True)
for rank, (idx, score) in enumerate(results, 1):
print(f"Rank {rank} | 得分: {score:.4f} | {docs[idx]}")
输出:
=== 检索结果 ===
Rank 1 | 得分: 2.8561 | BM25是一种基于概率论的信息检索模型,广泛用于搜索引擎
Rank 2 | 得分: 1.4233 | 搜索引擎的核心技术包括倒排索引、相关性排序和查询理解
Rank 3 | 得分: 0.9876 | 信息检索领域常用的算法有TF-IDF、BM25和向量检索
Rank 4 | 得分: 0.0000 | Python是一种简洁优雅的编程语言...
3.4 生产级封装
实际项目中,你需要一个可复用的搜索类:
import jieba
from rank_bm25 import BM25Okapi
class ChineseBM25Search:
def __init__(self, documents, k1=1.5, b=0.75, stopwords=None):
"""
中文 BM25 搜索引擎
Args:
documents: 原始文档列表
k1: 词频饱和参数
b: 长度归一化参数
stopwords: 停用词集合,如 {"的", "是", "了"}
"""
self.docs = documents
self.stopwords = stopwords or set()
# 加载自定义词典(实际项目中从文件加载)
self._load_custom_dict()
# 分词并构建索引
self.tokenized_docs = [self._tokenize(d) for d in documents]
self.bm25 = BM25Okapi(self.tokenized_docs, k1=k1, b=b)
def _load_custom_dict(self):
"""加载业务术语"""
terms = ["信息检索", "倒排索引", "向量检索", "语义搜索", "知识图谱"]
for term in terms:
jieba.add_word(term, freq=1000)
def _tokenize(self, text):
"""分词 + 停用词过滤 + 单字过滤"""
words = jieba.cut(text, cut_all=False)
return [w for w in words if w.strip()
and w not in self.stopwords
and len(w) > 1] # 过滤单字,减少噪音
def search(self, query, top_k=5, return_scores=True):
"""
执行搜索
Args:
query: 查询字符串
top_k: 返回结果数
return_scores: 是否返回得分
Returns:
如果 return_scores=True: [(doc, score), ...]
否则: [doc, ...]
"""
tokens = self._tokenize(query)
scores = self.bm25.get_scores(tokens)
# 获取 top_k 索引
top_indices = sorted(range(len(scores)),
key=lambda i: scores[i],
reverse=True)[:top_k]
results = []
for idx in top_indices:
if scores[idx] > 0: # 过滤得分为0的结果
if return_scores:
results.append((self.docs[idx], float(scores[idx])))
else:
results.append(self.docs[idx])
return results
def batch_search(self, queries, top_k=5):
"""批量查询,适合离线评估"""
return [self.search(q, top_k) for q in queries]
# ========== 使用示例 ==========
searcher = ChineseBM25Search(
documents=docs,
stopwords={"的", "是", "了", "在", "和", "一种", "用于"}
)
# 单条查询
results = searcher.search("BM25 算法原理", top_k=3)
for doc, score in results:
print(f"{score:.3f} | {doc}")
# 批量查询
queries = ["Python 机器学习", "搜索引擎 排序"]
batch_results = searcher.batch_search(queries, top_k=2)
四、关键优化技巧
4.1 停用词处理
未过滤停用词会导致"的"、"是"等高频无意义词拉高得分:
# 下载中文停用词表
import urllib.request
url = "https://raw.githubusercontent.com/goto456/stopwords/master/cn_stopwords.txt"
urllib.request.urlretrieve(url, "stopwords.txt")
# 加载使用
with open("stopwords.txt", "r", encoding="utf-8") as f:
stopwords = set(line.strip() for line in f)
4.2 同义词扩展
用户搜"搜索引擎"时,包含"检索系统"的文档也应被召回:
synonyms = {
"搜索引擎": ["搜索引擎", "检索系统", "搜索系统"],
"BM25": ["BM25", "Best Match 25"],
}
def expand_query(query):
tokens = tokenize(query)
expanded = []
for t in tokens:
expanded.extend(synonyms.get(t, [t]))
return expanded
# 查询前扩展
query_tokens = expand_query("搜索引擎原理")
# ['搜索引擎', '检索系统', '搜索系统', '原理']
4.3 参数调优实战
不同场景下参数需要调整:
场景 推荐 k1 推荐 b 原因
短文本(新闻标题) 1.2 0.3 文档短,长度惩罚应轻
长文本(学术论文) 1.5 0.75 标准参数即可
关键词密集型(商品名) 2.0 0.5 允许更高词频饱和
避免长文档霸榜 1.2 0.9 强长度惩罚
调优方法:准备标注好的查询-文档相关性数据集,用 NDCG@10 评估不同参数组合:
from sklearn.model_selection import ParameterGrid
best_score = 0
best_params = {}
for params in ParameterGrid({'k1': [1.2, 1.5, 2.0], 'b': [0.3, 0.75, 0.9]}):
bm25 = BM25Okapi(tokenized_docs, **params)
ndcg = evaluate(bm25, test_queries) # 你的评估函数
if ndcg > best_score:
best_score = ndcg
best_params = params
print(f"最优参数: {best_params}, NDCG: {best_score:.4f}")
五、BM25 的局限与演进
BM25 是词汇匹配(Lexical Matching)的巅峰,但它无法理解语义:
- 用户搜"苹果价格",包含"iphone 售价"的文档不会命中
- 用户搜"如何学习 Python",包含"Python 入门教程"的文档得分可能不高
现代方案:混合检索
# 伪代码:BM25 召回 + 向量精排
def hybrid_search(query, top_k=10):
# 第一阶段:BM25 快速召回 100 条候选
candidates = bm25_search(query, top_k=100)
# 第二阶段:BERT 向量相似度重排序
query_vector = bert_encode(query)
doc_vectors = [bert_encode(doc) for doc in candidates]
similarities = cosine_similarity(query_vector, doc_vectors)
# 融合得分(加权或交错排序)
final_results = rerank(candidates, similarities, top_k)
return final_results
Elasticsearch 8.0+、Milvus、Qdrant 均已内置这种混合检索能力。
六、总结
要点 实践建议
分词 jieba 精确模式 + 自定义词典 + 停用词过滤
参数 短文本降 b,关键词密集型升 k1
查询 同义词扩展提升召回率
架构 BM25 做召回,向量模型做精排
库选择 实验用 rank-bm25,生产用 Elasticsearch
BM25 历经 30 年仍在生产环境活跃,证明了简单、可解释、无需训练的算法在工程中的价值。掌握它,你就拥有了构建搜索引擎的坚实基础。
完整代码已整理,可直接复制运行:
# 一键安装:pip install rank-bm25 jieba
# 上述所有代码片段整合后即可构建一个可用的中文搜索引擎
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)