




- @songhuangong123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
BM25算法实战指南:从原理到Python应用 摘要:BM25是Elasticsearch等主流搜索引擎的核心排序算法,相比TF-IDF具有两大优势:解决词频无限增长问题和文档长度归一化处理。本文首先解析BM25的核心原理,包括IDF权重、词频增益和长度归一化三个关键组件,以及k1和b两个重要参数。然后通过Python实战演示了从英文到中文搜索的实现过程,重点展示了如何结合jieba分词器处理中文
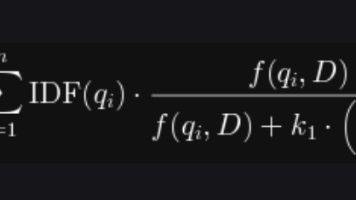
C++多线程编程中,lambda捕获方式的选择直接影响线程安全性。使用[&]引用捕获可能导致悬空引用问题,当外层函数返回后,线程访问的栈内存可能已被销毁,引发未定义行为。相比之下,显式值捕获(如[this, var1, var2])会创建独立副本,确保线程安全。最佳实践建议:1)优先显式列出捕获变量;2)共享数据修改需使用智能指针和同步原语;3)避免隐式捕获。核心原则是保证对象生命周期覆盖线程执行
本文是 LangChain Expression Language (LCEL) 系列文章的开篇,聚焦于 **Tool(工具)** 的定义、自定义方式,以及一个有趣的实验:当工具"说谎"时,Agent 会如何反应?
目前用于**图像分割的**数据集,我目前接触到的用的比较多的有:1 PASCAL VOC2 COCO3 YOLO4 Halcon自己的格式(其实就是Halcon字典类型)
本文介绍了LangChain中ChatPromptTemplate的核心用法,包括: 对话模板的必要性:解决LLM无状态问题,实现多轮对话记忆 三种核心消息类型:系统消息、用户消息和AI回复 基础使用方法:通过元组列表或专用模板对象创建对话 多轮对话实现:使用MessagesPlaceholder动态插入历史记录 实际应用场景:结合少样本学习、RAG检索构建专业对话系统 文章通过机床维护专家的具体
本文介绍了LangChain框架的核心概念和使用方法。LangChain通过将语言模型操作拆分为模块化组件并用"链"串联,实现流水线式处理。文章以翻译助手为例,对比了普通分步写法和链式写法:普通写法步骤清晰但代码冗长,链式写法通过管道符|串联组件,代码简洁高效。重点讲解了输出解析器(StrOutputParser)的作用,它能从模型返回的复杂对象中提取纯文本内容。两种写法各有优
本文深入解析了LangChain框架中Runnable链式调用的核心机制,重点剖析了itemgetter、管道符|和RunnableLambda的用法与设计原理。主要内容包括: itemgetter作为Python标准库的数据提取工具,本质是可调用对象,用于从字典/列表中提取值 管道符|通过运算符重载实现链式编排,LangChain采用"左包右不包"策略:左边自动包装为Runn
摘要: 大模型调用方式中,流式输出(边生成边返回)适合用户交互场景,降低等待焦虑;批量调用(打包并行处理)适合后台任务,提升效率。两者各有优劣:流式输出首字延迟低但后端复杂,批量调用吞吐量高但需统一输入格式。实际应用中,聊天机器人、长文本生成推荐流式输出;文档批量处理、数据标注推荐批量调用。两者也可组合使用,兼顾体验与效率。选择时需根据场景需求权衡,而非技术本身。
ChatPromptTemplate 是 LangChain 中专门用来组装聊天消息的"模板引擎",它能让你像填空题一样,把变量插进预设的对话结构里,告别手动拼接字符串的混乱时代。
摘要: 推荐系统面临相关性与多样性的根本矛盾:过度追求相关性会导致信息茧房,而单纯强调多样性则降低用户体验。MMR算法(最大边际相关性)通过数学公式平衡两者,每次选择物品时既考虑与用户的相关性,又惩罚与已选物品的相似性。关键参数lambda控制权衡比例,算法采用贪婪迭代策略实现高效计算。MMR已广泛应用于RAG、推荐系统等领域,并被主流框架原生支持,但其存在贪婪策略局限性和参数敏感问题。进阶方法如