
Python 爬虫实战:B 站热门评论爬取 + 词云可视化分析
1、STAR展示
背景:B 站作为学习类视频的主流平台,其评论区蕴含大量用户真实反馈、学习需求与痛点,但海量评论文本缺乏结构化分析,难以直观提炼用户关注重点。
任务:为了精准挖掘用户核心诉求,我基于爬取保存的 B 站某视频评论数据,开展文本可视化分析,让用户关注点从无结构文本变为可直观查看的图表。
行动:数据清洗(去空值)、生成词云图展示整体关键词分布、统计并绘制高频词 TOP30 柱状图量化热度
结果:直观呈现用户关注重点,量化高频词汇,为需求分析提供有效数据支撑。
2、爬虫展示
本文按代码的顺序理清一遍思路生成笔记,并随时附上请求网页时开发者模式中找数据的图
(1)库导入阶段
import requests
import json
import time
import pandas as pd(2)请求头
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/148.0.0.0 Safari/537.36",
"Referer": "https://www.bilibili.com/video/BV1ZM4y1u7uF/",
"Cookie": "buvid3=3CD272C1-2A43-EBD3-27B5-209E29798E1526378infoc; b_nut=1774579526; _uuid=6105C6665-E2BB-BB4C-7FDE-6B810D538DF5E27931infoc; CURRENT_QUALITY=0; buvid_fp=692592d98b9767faa8acf46003571ed2; buvid4=00D8389E-2745-AEC5-BBF0-6A5A2DAF71BE30708-026032710-ekr0geIP93nCCpmsSPRtFA%3D%3D; home_feed_column=5; browser_resolution=1470-801; SESSDATA=8f72c39b%2C1794320391%2C431e7%2A52CjCJwxG12Z5Zi9Bu1oUDokSt6bL_I0lhTyGZMIDjwTzQcdrT2ef0BuJXLo4Adux-VIoSVkhFU2hBbzhfYjY4RG9SWDBZcGp6RWNJcDBXaVFYQmVUa3oyQWdoeUR1NU9SYWVIYjVrV0tPd3BoWEdRcFc1bU9UaW9BLXlQR3NVXzA0TnNtWlRldG5RIIEC; bili_jct=6e18546b62a5bb46e1800e22ee06061b; DedeUserID=1143175366; DedeUserID__ckMd5=0c88deb0fc9e5a80; theme-tip-show=SHOWED; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3NzkwMjc1OTksImlhdCI6MTc3ODc2ODMzOSwicGx0IjotMX0.7hw2rYu6aOrYDoa0qYNHlsYuwDd00oTBB0eKRexXx2w; bili_ticket_expires=1779027539; rpdid=|(J~|~JJYl)~0J'u~~)~Y)R|Y; bsource=search_bing; theme-avatar-tip-show=SHOWED; CURRENT_FNVAL=4048; sid=7pgvjua6; b_lsid=ADC87C9E_19E299414AF"
}目的:伪装成正常用户浏览器访问,顺利拿到数据,通过反爬验证
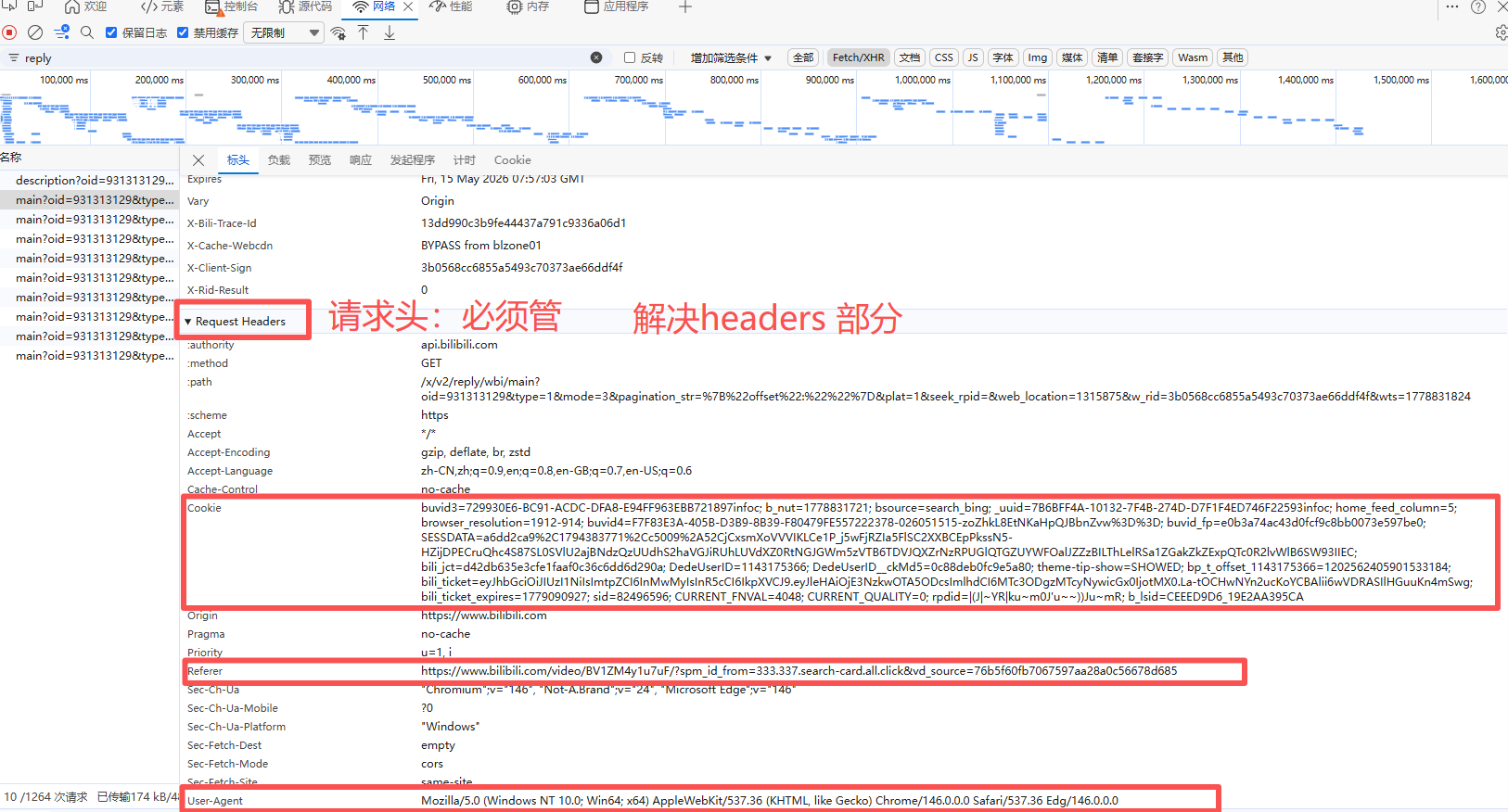
(3)请求网址
url = "https://api.bilibili.com/x/v2/reply/main"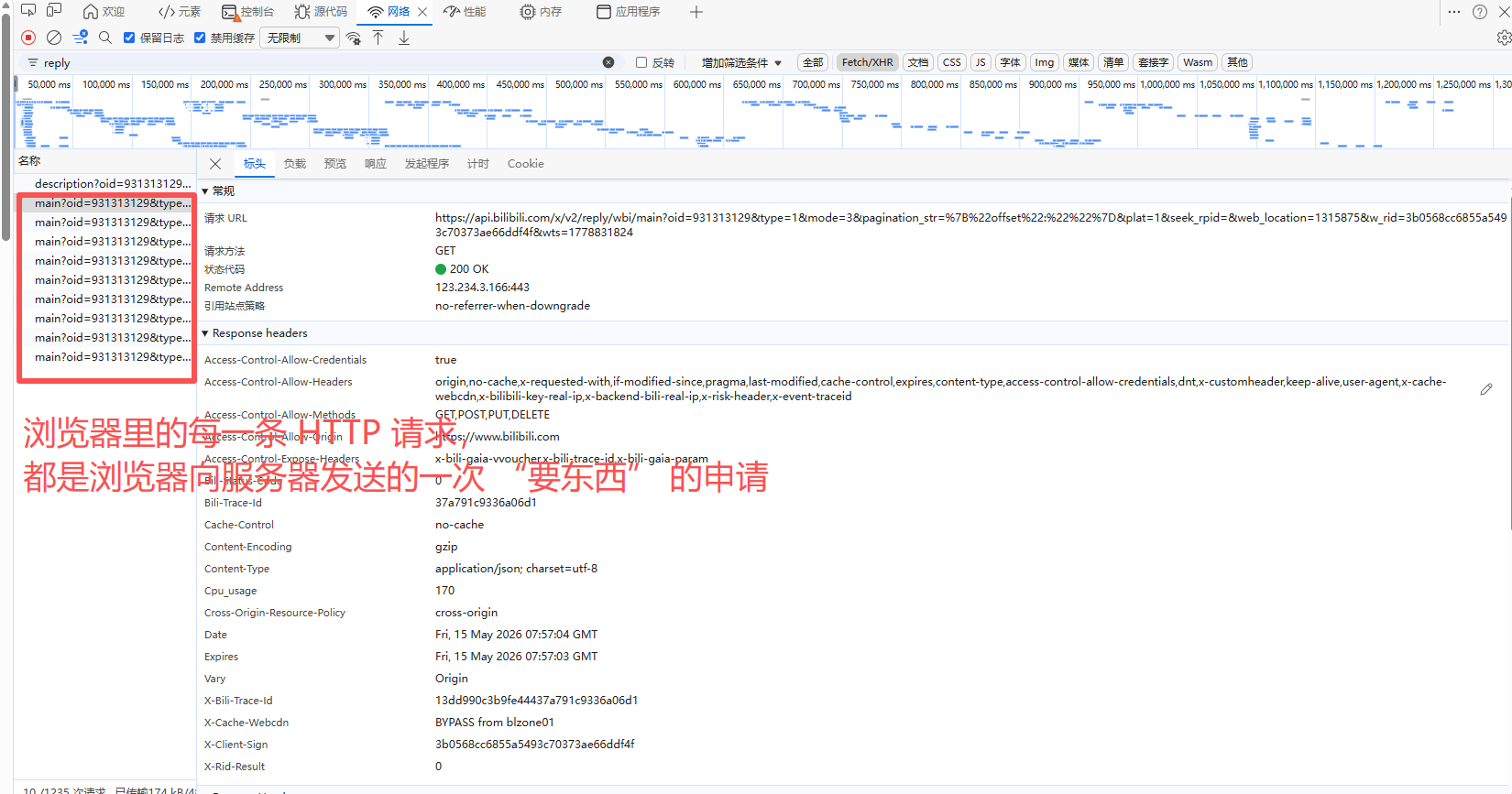
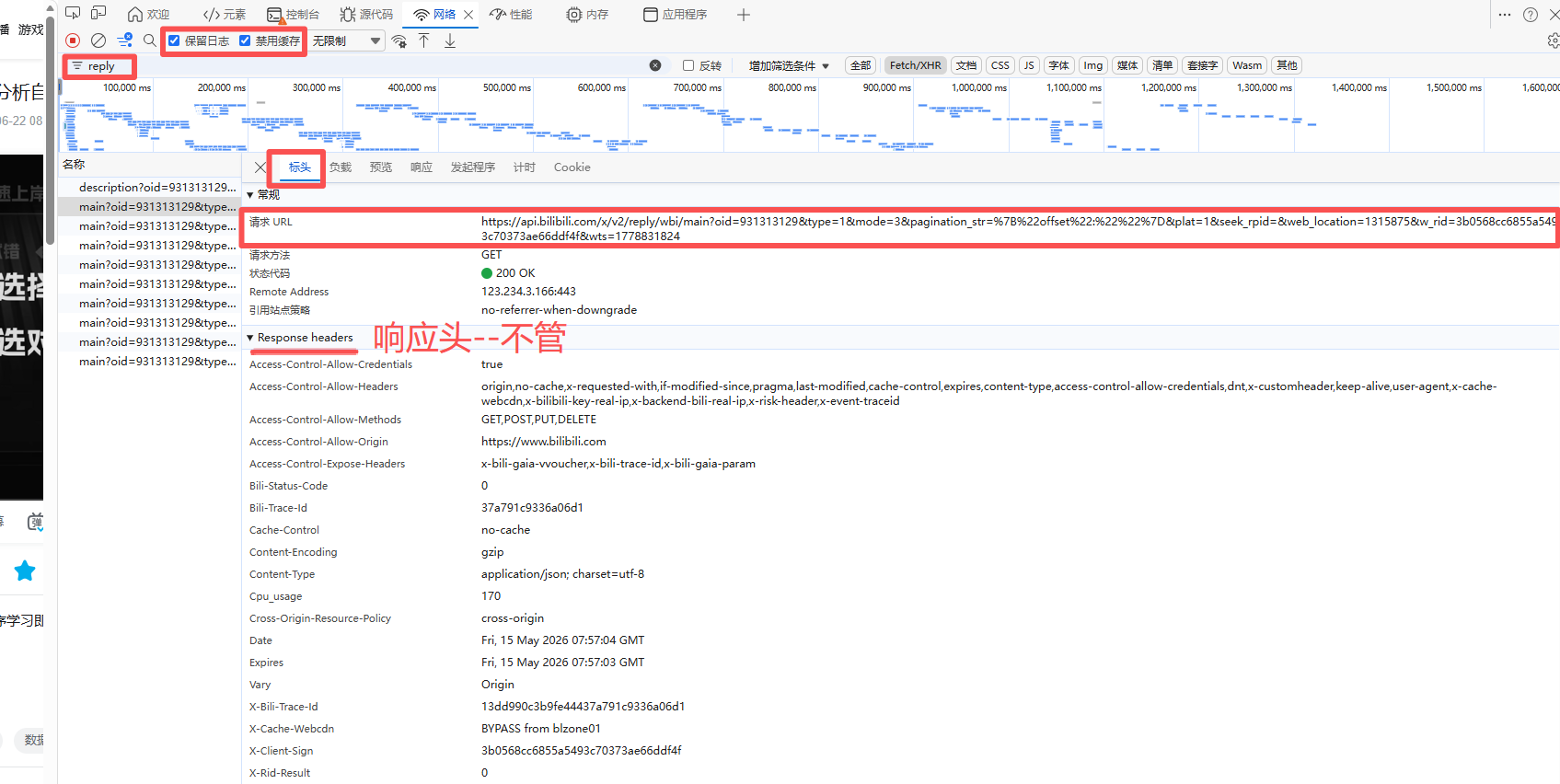
这里的请求url就是我们的目标网址


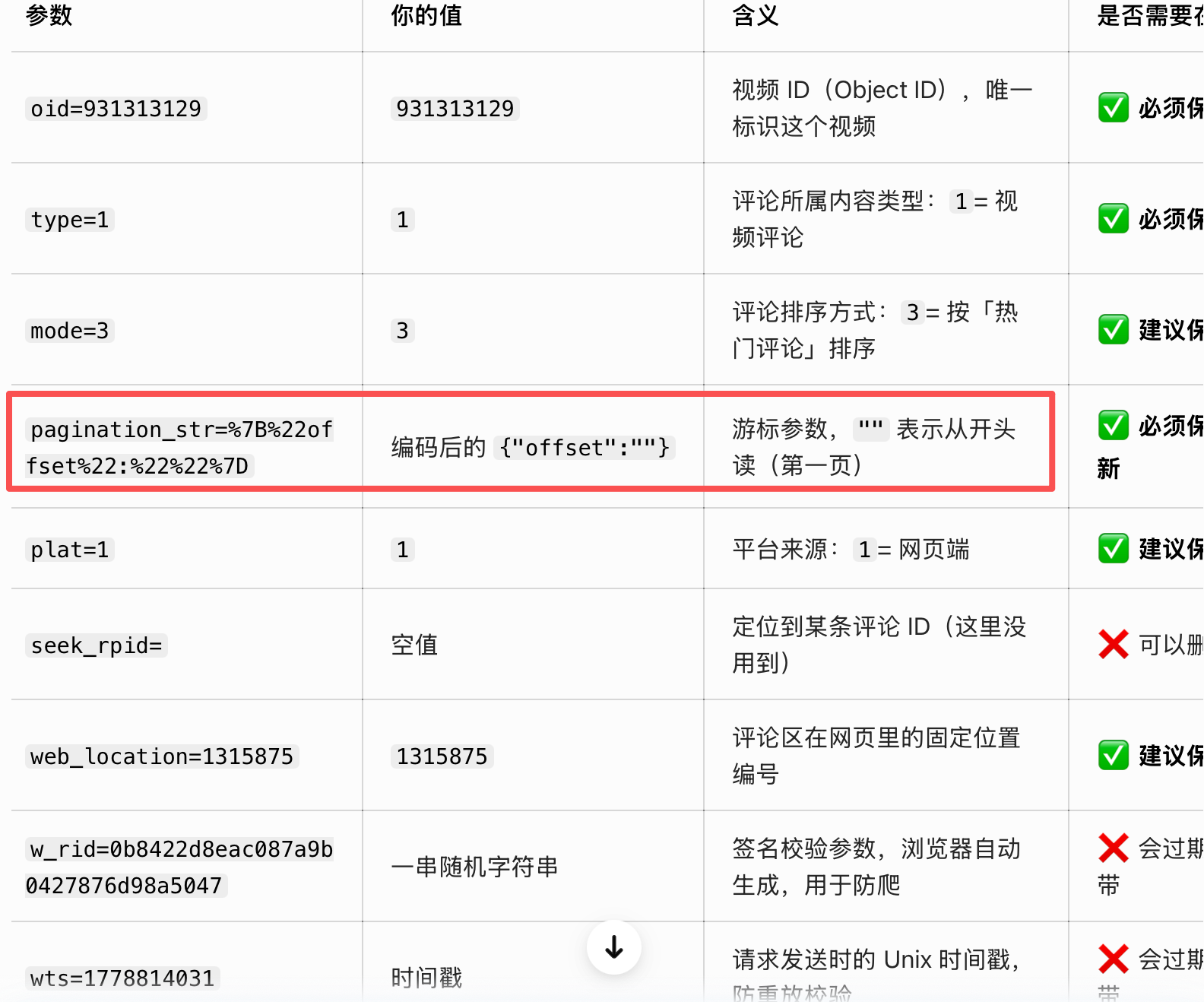
所以发送 GET 请求时,params就必须要带这些参数

后面从repiles记录里我们可以看到一个网址是只有20条评论记录的,要是想爬取到所有页面,必须通过游标参数做更新循环处理,这里先简单理解请求网址的结构,以及在哪里看的问题~
(4)初始化设置
all_comments = []
目的:用来存放后续爬下来的所有评论数据
page = 1目的:记录当前爬取的是第几页评论
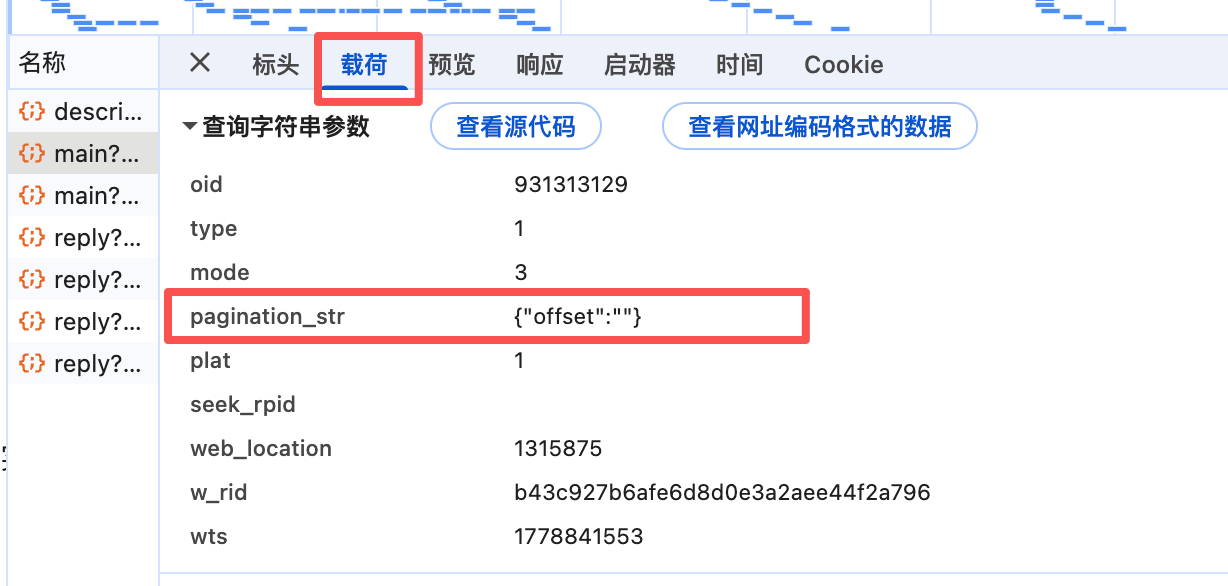
next_offset = ""分页游标初始化,从图中可以看出第一页的游标参数就为{"offset":""}
(5)发起 GET 请求,获取并解析评论数据
res = requests.get(url, headers=headers, params=params, timeout=10)
data = res.json()
res 是 requests.get() 返回的一个响应对象,里面的 res.text 是JSON 格式的字符串。JSON 是一种数据格式,长得像字典

data = res.json() 就是把 JSON 字符串转成 Python 字典,你才能取评论、翻页
(6)获取评论列表
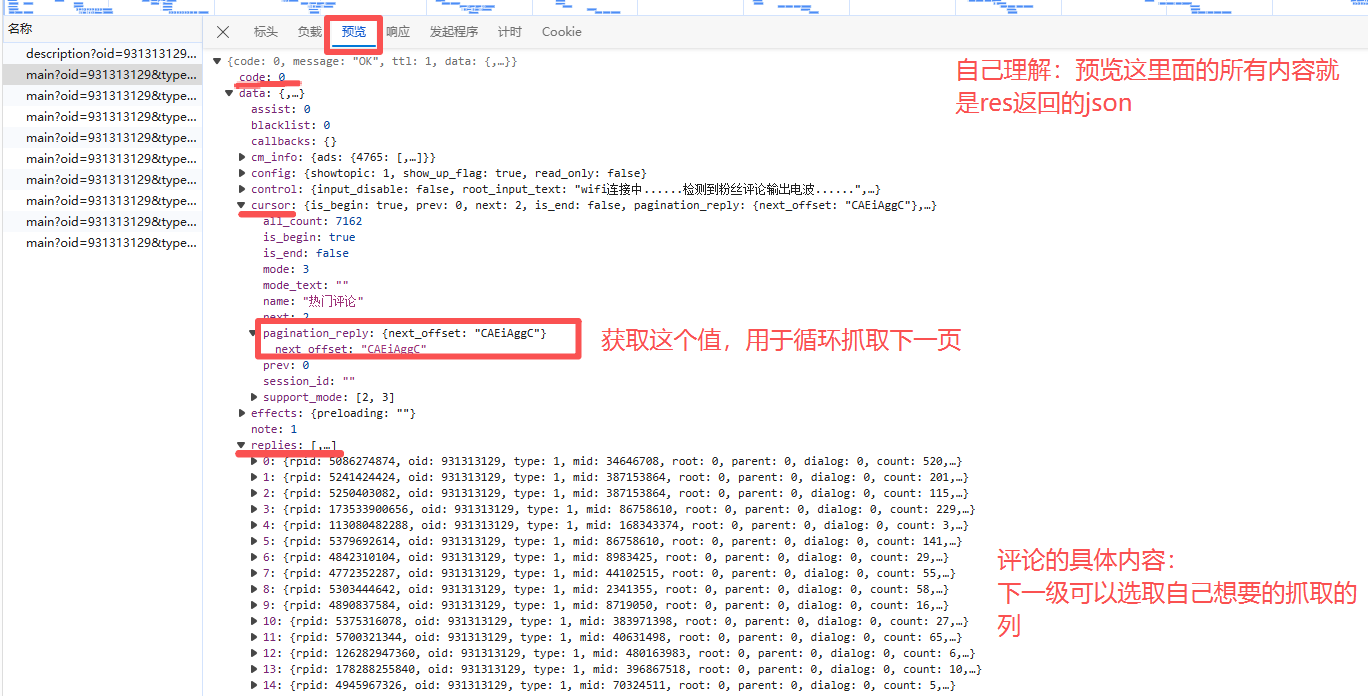
replies = data["data"]["replies"]get解析出来的data中有子集data,data的子级有replies,从上面“预览”的图可以清晰看出
(7)获取想要的列
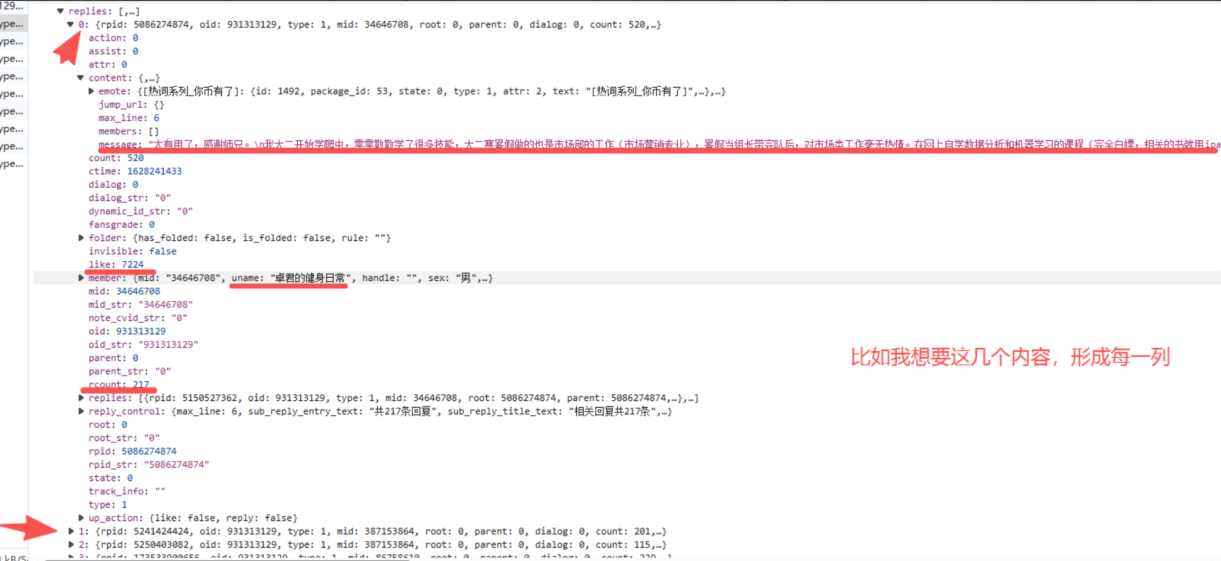
for r in replies:
all_comments.append({
"用户名": r["member"]["uname"],
"评论": r["content"]["message"],
"点赞": r["like"],
"回复": r["rcount"]
})
(8)提取分页游标,获取下一页请求参数
cursor = data["data"]["cursor"]
next_offset = cursor["pagination_reply"]["next_offset"]params里游标参数的值----"pagination_str": f'{{"offset":"{next_offset}"}}'
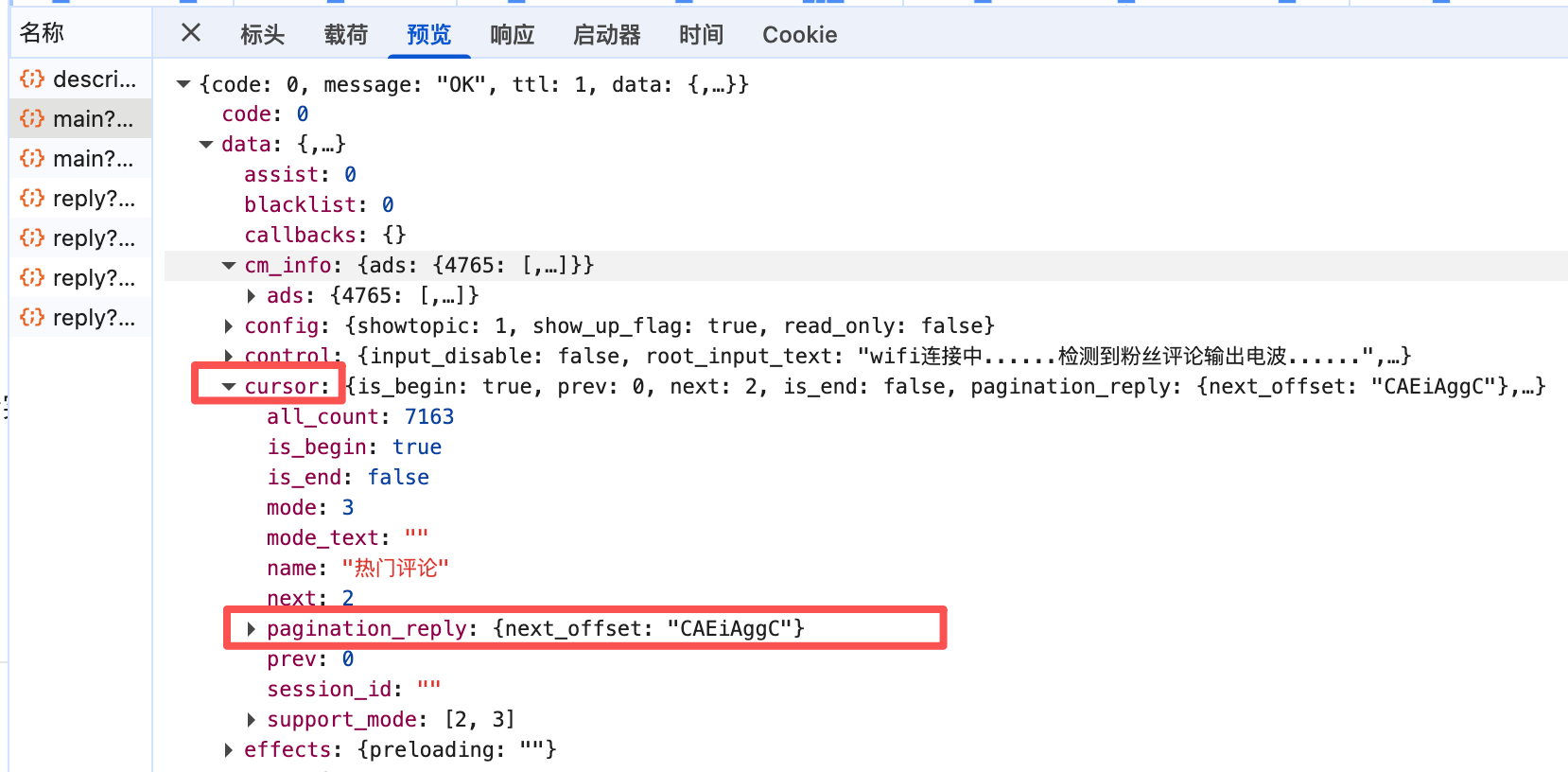
在“负载”里也能看出游标参数变化,最重要的是看出游标参数的格式
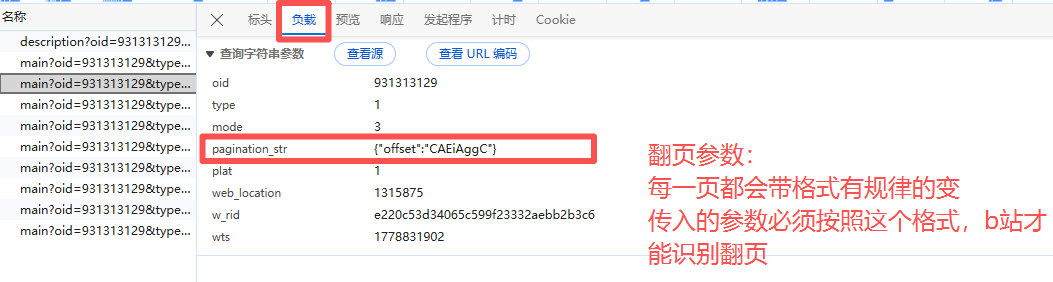
为什么url里翻页参数不是图上的样式,像乱码

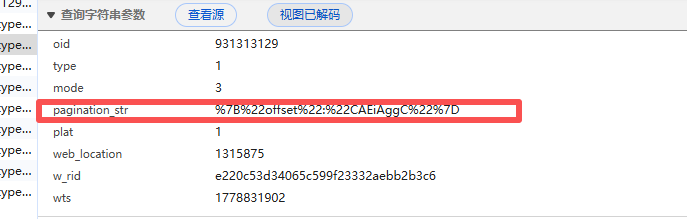
其实是一个东西
(9)导出excel
df = pd.DataFrame(all_comments)
df.to_excel("B站评论.xlsx", index=False)openpyxl = Python 生成 Excel 文件必须用的库,没有它就导不出 Excel。
所以要在终端输入pip install openpyxl
完整代码:
import requests
import json
import time
import pandas as pd
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/148.0.0.0 Safari/537.36",
"Referer": "https://www.bilibili.com/video/BV1ZM4y1u7uF/",
"Cookie": "buvid3=3CD272C1-2A43-EBD3-27B5-209E29798E1526378infoc; b_nut=1774579526; _uuid=6105C6665-E2BB-BB4C-7FDE-6B810D538DF5E27931infoc; CURRENT_QUALITY=0; buvid_fp=692592d98b9767faa8acf46003571ed2; buvid4=00D8389E-2745-AEC5-BBF0-6A5A2DAF71BE30708-026032710-ekr0geIP93nCCpmsSPRtFA%3D%3D; home_feed_column=5; browser_resolution=1470-801; SESSDATA=8f72c39b%2C1794320391%2C431e7%2A52CjCJwxG12Z5Zi9Bu1oUDokSt6bL_I0lhTyGZMIDjwTzQcdrT2ef0BuJXLo4Adux-VIoSVkhFU2hBbzhfYjY4RG9SWDBZcGp6RWNJcDBXaVFYQmVUa3oyQWdoeUR1NU9SYWVIYjVrV0tPd3BoWEdRcFc1bU9UaW9BLXlQR3NVXzA0TnNtWlRldG5RIIEC; bili_jct=6e18546b62a5bb46e1800e22ee06061b; DedeUserID=1143175366; DedeUserID__ckMd5=0c88deb0fc9e5a80; theme-tip-show=SHOWED; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3NzkwMjc1OTksImlhdCI6MTc3ODc2ODMzOSwicGx0IjotMX0.7hw2rYu6aOrYDoa0qYNHlsYuwDd00oTBB0eKRexXx2w; bili_ticket_expires=1779027539; rpdid=|(J~|~JJYl)~0J'u~~)~Y)R|Y; bsource=search_bing; theme-avatar-tip-show=SHOWED; CURRENT_FNVAL=4048; sid=7pgvjua6; b_lsid=ADC87C9E_19E299414AF"
}
url = "https://api.bilibili.com/x/v2/reply/main"
all_comments = []
page = 1
next_offset = ""
while True:
print(f"\n📖 正在读取第 {page} 页")
params = {
"oid": 931313129,
"type": 1,
"mode": 3,
"plat": 1,
"pagination_str": f'{{"offset":"{next_offset}"}}',
}
try:
res = requests.get(url, headers=headers, params=params, timeout=10)
data = res.json()
except:
print("请求失败")
break
if data.get("code") != 0:
print("错误:", data.get("message"))
break
replies = data["data"]["replies"]
for r in replies:
all_comments.append({
"用户名": r["member"]["uname"],
"评论": r["content"]["message"],
"点赞": r["like"],
"回复": r["rcount"]
})
print(f"第 {page} 页完成,累计:{len(all_comments)} 条")
# 最后一页判断
if not replies:
print("✅ 全部爬完!")
break
cursor = data["data"]["cursor"]
next_offset = cursor["pagination_reply"]["next_offset"]
page += 1
time.sleep(1.0)
df = pd.DataFrame(all_comments)
df.to_excel("B站评论.xlsx", index=False)
print(f"\n🎉 完成!共 {len(all_comments)} 条")【小插曲】
1、刚开始一直权限不足,换了一个老接口,就成功运行了



2、为什么总评论是7000多条,我只爬取到4000多条
:因为是一级评论,就是只算楼主的评论。楼中楼的评论都没爬!
3、词云图柱状图展示
代码如下:
import pandas as pd
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import Counter
import re
# Windows 系统专用:解决中文不显示、方框乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号 - 显示异常
# ---------------------- 1. 读取数据 ----------------------
df = pd.read_excel("B站评论.xlsx")
# 查看缺失值
print("=== 缺失值统计 ===")
print(df.isnull().sum())
# 删除评论为空的行
df = df.dropna(subset=["评论"])
# ---------------------- 3. 分词 + 停用词过滤 ----------------------
stop_words = {
"的", "了", "是", "我", "什么","哪里","你", "他", "在", "有", "就", "都", "也", "和", "这", "那",
"吧", "吗", "呀", "哦","请问", "嗯", "哈","有没有","哇","没有","师兄", "UP", "UP主","视频","可以","为什么","一下","打卡","还是","这个","怎么"
}
all_words = []
for text in df["评论"]:
words = jieba.lcut(text)
# 过滤:长度>1 + 不是停用词
words = [w for w in words if len(w) > 1 and w not in stop_words]
all_words.extend(words)
# ---------------------- 4. 生成词云图 ----------------------
wc = WordCloud(
font_path="msyh.ttc",
background_color="white",
width=1200, height=600,
max_words=150
)
wc.generate(" ".join(all_words))
plt.figure(figsize=(14, 7))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.title("B站评论词云图", fontsize=16)
wc.to_file("B站评论词云图.png")
plt.show()
# ---------------------- 5. 高频词柱状图 ----------------------
top30 = Counter(all_words).most_common(30)
words = [x[0] for x in top30]
counts = [x[1] for x in top30]
plt.figure(figsize=(14, 8))
plt.bar(words, counts, color="#4285F4")
plt.xlabel("词语")
plt.ylabel("出现次数")
plt.title("高频词 TOP30(从高到低)")
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.savefig(
'评论高频词 TOP30.png', # 保存的文件名
dpi=300, # 清晰度(300足够打印/使用)
bbox_inches='tight' # 自动裁剪掉多余的空白边,避免文字被截断
)
plt.show()
# ---------------------- 6. 输出TOP30词汇 ----------------------
for i, (word, cnt) in enumerate(top30, 1):
print(f"{i:2d}. {word:<6} {cnt:>4} 次")(1)词云图效果如下:

添加蒙版图片的词云图
可以将有白色背景的图片作为蒙版图片,而有图案的地方会被词云填充。
添加蒙版图片需要使用PIL库和numpy库,需提前下载安装。
本案例添加蒙版图片如下:

# 打开蒙版图片,生成Image对象
img = Image.open("蒙版.jpg") # 打开遮罩图片
# 生成蒙版
mask = np.array(img) # 将图片转换为数组
wc = WordCloud(
mask=mask,
font_path="msyh.ttc",
background_color="white",
width=1200, height=600,
max_words=150
)
wc.generate(" ".join(all_words))词云图效果如下:

(2)高频词 TOP30 柱状图如下:
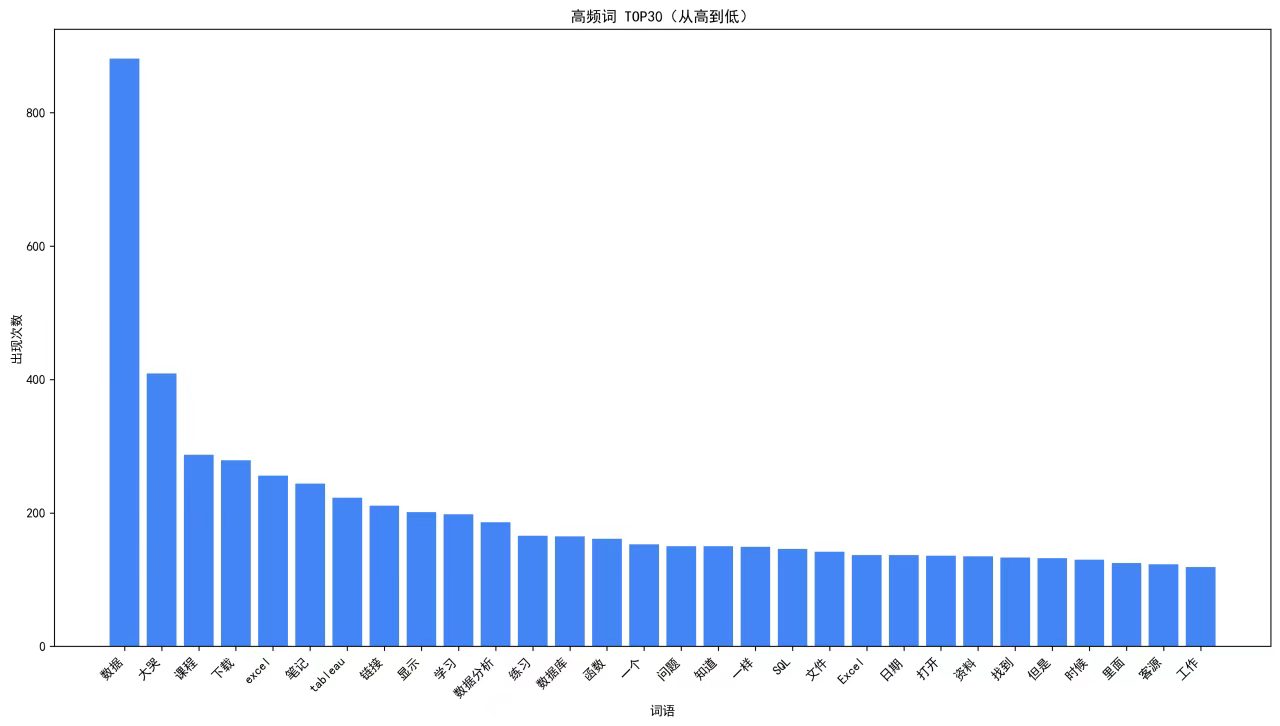
4、分析结论
基于本次 B 站数据分析教学视频评论的词云与高频词分析,可得出以下核心结论:
(1)用户画像与核心诉求(人群、需求)
评论受众以零基础数据分析入门学习者为主,核心诉求高度聚焦
- 工具层面:工具热度排序
Excel > Tableau > SQL > Python,清晰体现了零基础学习者的路径偏好。 - 学习层面:对「课程、笔记、可下载资料」等系统化学习资源有强烈需求,说明用户依赖结构化的教学内容。
- 目标层面:整体围绕「数据处理」展开,所有讨论都服务于数据分析的学习目标。
(2)核心痛点与情绪反馈(问题)
大哭、报错、打不开、问题等词汇的高频出现,反映出零基础学习者的典型困境。- 实操门槛高:在 Excel、SQL 的实际操作中频繁遇到报错、软件打不开等问题。
- 学习挫败感强:大量情绪性吐槽(如 “大哭”),说明入门阶段的学习体验较差,需要更友好的教学引导。
(3)教学优化方向(改进)
结合以上分析,后续教学内容可针对性优化:
- 强化 Excel 实操教学,增加报错排查、软件使用等问题的讲解。
- 提供配套的可下载笔记、资料,满足用户对系统化资源的需求。
- 降低入门门槛,增加情绪友好的引导内容,缓解用户的学习挫败感。
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)