
Python全站链接爬虫GUI界面+实时过滤
·
Python全站链接爬虫:GUI界面 + 实时过滤
标签:#Python #NiceGUI #GUI #爬虫
日期:2026-05-20
摘要:本文介绍为全站链接爬虫添加 NiceGUI 图形界面,支持暂停时动态添加/删除过滤条件,让爬取过程更加灵活可控。
前言
在之前文章中,我们实现了支持过滤和断点续爬的链接爬虫。但在使用过程中,我发现一个问题:如果爬取过程中发现某个路径需要过滤,只能中断后修改代码重新开始。
为了解决这个问题,我用 NiceGUI 为爬虫添加了图形界面,支持在暂停状态下实时添加/修改过滤条件。
一、界面效果
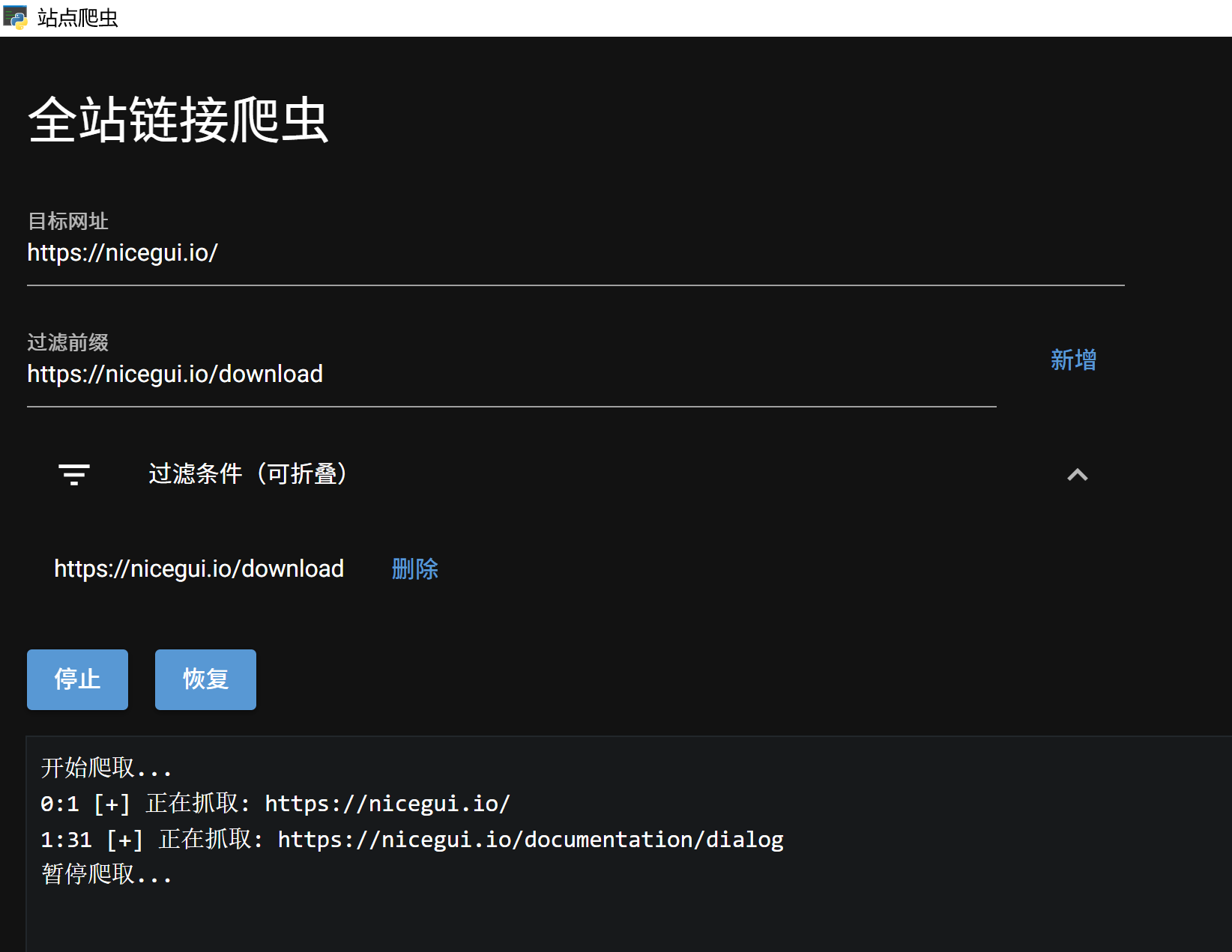
界面包含:
| 区域 | 说明 |
|---|---|
| 目标网址 | 输入要爬取的网站地址 |
| 过滤前缀 | 输入要过滤的 URL 前缀 |
| 过滤条件列表 | 可折叠展示当前所有过滤规则 |
| 开始/停止按钮 | 控制爬取进程 |
| 暂停/恢复按钮 | 暂停时可添加过滤条件 |
| 日志区域 | 显示爬取进度 |
二、核心实现
🎯 架构设计
┌─────────────────────────────────────────┐
│ UI 层 │
│ (NiceGUI - 输入、按钮、日志显示) │
└─────────────────────────────────────────┘
↕
┌─────────────────────────────────────────┐
│ Business 层 │
│ (爬取逻辑、过滤条件、暂停/停止控制) │
└─────────────────────────────────────────┘
🎯 暂停与恢复机制
通过事件对象控制爬取流程:
class Business:
def __init__(self):
self._stop_event = MyEvent() # 停止事件
self._pause_event = MyEvent() # 暂停事件
self.filters: list[str] = [] # 过滤条件
def start(self, url):
while unvisited and not self._stop_event.is_set():
self._pause_event.wait_disappear() # ⭐ 等待暂停解除
if self._stop_event.is_set(): break
# ... 爬取逻辑
def pause(self):
self._pause_event.set() # 设置暂停事件
def resume(self):
self._pause_event.clear() # 清除暂停事件
🎯 动态过滤
def add_filter(self, prefix):
self.filters.append(prefix)
# 过滤已访问链接中的匹配项
self._visited = {s for s in self._visited if not self._is_match(s)}
def _is_match(self, link):
return any(link.startswith(p) for p in self.filters)
三、完整源码
from typing import TypeVar
from nicegui import ui, app
from multiprocessing import freeze_support
from urllib.parse import urljoin, urlparse
from bs4 import BeautifulSoup
from my_playwright import MyPlaywright
import Common
from myevent import MyEvent
T = TypeVar('T')
class Meta(type):
@property
def single(cls: T) -> T:
if not hasattr(cls, '_instance'):
cls._instance = cls()
return cls._instance
class Business(metaclass=Meta):
'''业务逻辑'''
def __init__(self) -> None:
self.filters: list[str] = []
self._stop_event = MyEvent()
self._pause_event = MyEvent()
self._visited: set[str] = set()
def _save_to_markdown(self, links: set[str], output_path='internal_links.md'):
sorted_links = sorted(links)
chunk_size = 10
chunks = [sorted_links[i:i+chunk_size] for i in range(0, len(sorted_links), chunk_size)]
markdown = ['# 全站内部链接列表\n\n',
f'共发现 **{len(links)}** 条链接\n\n---\n\n']
for idx, chunk in enumerate(chunks, 1):
start = (idx - 1) * chunk_size + 1
markdown.append(f'### 第 {start}-{start+len(chunk)-1} 条链接\n\n')
for link in chunk:
markdown.append(f'{link}\n')
markdown.append('\n')
with open(output_path, 'w', encoding='utf-8') as f:
f.writelines(markdown)
@Common.run_in_thread
def start(self, url: str):
self._visited.clear()
unvisited = {url}
Ui.single.log('开始爬取...')
page = MyPlaywright(headless=True, accept_downloads=False).page
target_netloc = urlparse(url).netloc
self._stop_event.clear()
while unvisited and not self._stop_event.is_set():
self._pause_event.wait_disappear() # ⭐ 等待暂停解除
if self._stop_event.is_set(): break
url = next(iter(unvisited))
Ui.single.log(f'{len(self._visited)}:{len(unvisited)} [+] 正在抓取: {url}')
page.goto(url, wait_until='networkidle', timeout=30000)
page.wait_for_timeout(300)
html = page.content()
soup = BeautifulSoup(html, 'html.parser')
for a in soup.find_all('a', href=True):
href = a['href']
full_url = urljoin(url, href)
parsed = urlparse(full_url)
if parsed.netloc != target_netloc: continue
if '#' in full_url: continue
if parsed.scheme not in ('http', 'https'): continue
if full_url in self._visited: continue
if self._is_match(full_url): continue
unvisited.add(full_url)
self._visited.add(url)
unvisited.discard(url)
Ui.single.log(f'爬取完成,共 {len(self._visited)} 条链接')
if self._visited:
self._save_to_markdown(self._visited)
Ui.single.log('结果已保存到 internal_links.md')
def stop(self):
self._stop_event.set()
self._pause_event.clear()
def pause(self):
Ui.single.log('暂停爬取...')
self._pause_event.set()
def resume(self):
Ui.single.log('恢复爬取...')
self._pause_event.clear()
def _is_match(self, link: str) -> bool:
return any(link.startswith(p) for p in self.filters)
def add_filter(self, prefix: str):
self.filters.append(prefix)
self._visited = {s for s in self._visited if not self._is_match(s)}
class Ui(metaclass=Meta):
'''界面'''
def __init__(self) -> None:
self._log: ui.Log = None
self._url_input: ui.Input = None
self._btn_start_toggle: ui.Button = None
self._btn_pause: ui.Button = None
def _build_ui(self):
def _add_filter():
text = filter_input.value.strip()
Business.single.add_filter(text)
self._filter_list_ui.refresh()
ui.notify(f'已添加: {text}', type='positive')
ui.query('.nicegui-content').classes('flex flex-col h-screen p-4')
ui.markdown('### 全站链接爬虫')
self._url_input = ui.input('目标网址', value='https://nicegui.io/', placeholder='https://example.com/').classes('w-1/2')
with ui.row().classes('w-1/2 items-center'):
filter_input = ui.input('过滤前缀', placeholder='https://example.com/dir/').classes('flex-1')
ui.button('新增', on_click=_add_filter).props('flat')
with ui.expansion('过滤条件(可折叠)', icon='filter_list').classes('w-1/2'):
self._filter_list_ui()
with ui.row():
self._btn_start_toggle = ui.button('开始', on_click=self._toggle_start_stop)
self._btn_pause = ui.button('暂停', on_click=self._toggle_pause)
self._log = ui.log(max_lines=500).classes('w-full flex-1')
def log(self, msg: str):
self._log.push(msg)
def run(self):
freeze_support()
self._build_ui()
app.native.window_args['maximized'] = True
ui.run(native=True, dark=True, reload=False, title='站点爬虫')
def _toggle_start_stop(self):
if self._btn_start_toggle.text == '开始':
self._btn_start_toggle.text = '停止'
Business.single.start(self._url_input.value)
else:
self._btn_start_toggle.text = '开始'
Business.single.stop()
def _toggle_pause(self):
if self._btn_pause.text == '暂停':
self._btn_pause.text = '恢复'
Business.single.pause()
else:
self._btn_pause.text = '暂停'
Business.single.resume()
@ui.refreshable
def _filter_list_ui(self):
if not Business.single.filters:
ui.label('暂无过滤条件').classes('text-grey-5')
for i, rule in enumerate(Business.single.filters):
with ui.row().classes('items-center'):
ui.label(rule)
ui.button('删除', on_click=lambda idx=i: self._delete_filter(idx)).props('flat dense').classes('ml-2')
def _delete_filter(self, index: int):
removed = Business.single.filters.pop(index)
self._filter_list_ui.refresh()
ui.notify(f'已删除: {removed}', type='positive')
Ui.single.run()
四、使用流程
1. 输入目标网址: https://nicegui.io/
2. 点击"开始"
3. 发现不需要的路径: /5/ 版本页
4. 点击"暂停"
5. 在过滤前缀中输入: https://nicegui.io/5/
6. 点击"新增"
7. 点击"恢复"
8. 已访问的 /5/ 链接会被过滤掉
五、关键技术点
🔑 暂停机制
通过 MyEvent 实现线程间通信,MyEvent是我自己封装的事件类,可参考之前的文章:
# 暂停:设置事件
self._pause_event.set()
# 恢复:清除事件
self._pause_event.clear()
# 爬取循环中等待
self._pause_event.wait_disappear()
🔑 实时过滤
添加过滤条件时,自动从已访问列表中移除匹配项:
def add_filter(self, prefix):
self.filters.append(prefix)
self._visited = {s for s in self._visited if not self._is_match(s)}
六、总结
📌 要点回顾
- GUI 界面:用 NiceGUI 实现,代码即布局
- 暂停/恢复:通过事件对象控制爬取流程
- 实时过滤:暂停时可添加过滤条件,自动清理已访问列表
- 线程安全:使用
run_in_thread装饰器在后台执行爬取
📚 相关资源
- 上一篇文章:Python全站链接爬取工具优化:支持过滤和断点续爬
- NiceGUI 官方文档:https://nicegui.io
本文为本人原创,首发于掘金。
如果你有任何问题或想法,欢迎在评论区交流!
更多推荐
 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)