
Python + MySQL 数据分析项目实战:基于模拟招聘数据的数据分析师岗位画像分析
本文使用模拟招聘数据,主要用于跑通数据分析项目的完整流程,包括数据生成、数据清洗、MySQL 数据库存储、SQL 查询分析和 Python 可视化展示。本文结论不代表真实招聘市场分布,后续将进一步替换为公开招聘平台真实岗位数据,完善岗位画像分析结果。
一、项目背景
作为一名应用统计学方向的本科生,我未来的职业目标更倾向于数据分析师方向。数据分析师并不是单纯会使用某一种工具的岗位,而是一个综合性较强的职业方向。它通常要求从业者具备数据获取、数据清洗、数据库查询、统计分析、可视化表达和业务理解等能力。为了更加清楚地理解数据分析师岗位所需要的能力,我尝试搭建一个小型数据分析项目。本项目围绕“数据分析师岗位能力画像”展开,通过模拟招聘岗位数据,完整跑通从数据准备到分析结论输出的过程。这个项目的重点不在于直接得出真实招聘市场结论,而在于通过项目实践训练数据分析工作的基础流程,为后续使用真实岗位数据开展职业画像分析打基础。
二、项目目标
本项目主要完成以下几个目标:
构建一份结构化的数据分析师岗位数据集;
使用 pandas 对岗位数据进行清洗和字段处理;
将清洗后的数据导入 MySQL 数据库;
使用 SQL 对岗位数据进行查询分析;
使用 Python 生成可视化图表;
从岗位画像分析中反推数据分析师所需能力;
三、项目技术路线
本项目的整体技术路线如下:
模拟岗位数据生成 ↓ pandas 数据清洗 ↓ MySQL 数据库存储 ↓ SQL 查询分析 ↓ matplotlib 可视化展示 ↓ 岗位能力画像总结 ↓ 个人职业规划启发项目主要使用的技术包括:
Python pandas MySQL SQL matplotlib DBeaver PyCharm通过这个流程,可以初步模拟数据分析师在实际工作中常见的“数据整理—数据库存储—查询分析—图表展示—结论输出”过程。
四、项目目录结构
本项目目录结构如下:
data_analyst_job_analysis │ ├── data │ ├── raw │ │ └── data_analyst_jobs_raw.csv │ └── processed │ └── data_analyst_jobs_cleaned.csv │ ├── docs │ └── csdn_article.md │ ├── output │ ├── figures │ │ ├── city_avg_salary.png │ │ ├── city_job_count.png │ │ ├── education_count.png │ │ ├── industry_count.png │ │ └── skill_frequency.png │ └── skill_frequency.csv │ ├── sql │ └── job_analysis_queries.sql │ └── src ├── config.py ├── 01_create_demo_data.py ├── 02_clean_data.py ├── 03_import_to_mysql.py └── 04_visualize.py其中:
data/raw用于存放原始岗位数据;
data/processed用于存放清洗后的数据;
src用于存放 Python 代码;
sql用于存放 SQL 查询脚本;
output/figures用于存放可视化图表;
docs用于存放项目说明或文章草稿。五、数据字段设计
本项目设计的数据字段如下:
字段名 含义 job_title 岗位名称 company 公司名称 city 城市 salary 薪资区间 education 学历要求 experience 经验要求 skills 技能要求 industry 所属行业 avg_salary_k 平均月薪,单位 K skill_count 技能数量 这些字段基本覆盖了岗位画像分析中比较常见的几个维度,包括城市分布、薪资水平、学历要求、经验要求、行业分布和技能需求。
六、数据生成
本项目使用模拟岗位数据,目的是先跑通完整的数据分析流程。后续通过进一步学习会将这部分替换为公开招聘平台中合规采集或手工整理的真实岗位数据。
数据生成部分的主要思路是:
设置城市、岗位名称、行业、学历、经验、技能等候选列表;
随机组合生成岗位数据;
自动生成薪资区间;
将薪资区间转换为平均薪资;
保存为 CSV 文件。
部分核心代码如下:
import pandas as pd from pathlib import Path import random random.seed(2026) BASE_DIR = Path(__file__).resolve().parent.parent raw_dir = BASE_DIR / "data" / "raw" raw_dir.mkdir(parents=True, exist_ok=True) cities = ["北京", "上海", "深圳", "杭州", "南京", "广州", "苏州", "成都", "武汉", "西安"] job_titles = [ "数据分析师", "商业数据分析师", "用户数据分析师", "市场数据分析师", "金融数据分析师", "经营分析师", "BI数据分析师", "数据产品分析师" ] skill_pool = [ "Python", "SQL", "Excel", "pandas", "NumPy", "Tableau", "Power BI", "数据可视化", "统计分析", "回归分析", "机器学习", "A/B测试", "用户画像", "指标体系", "漏斗分析", "SPSS", "R", "数据清洗", "市场调研", "业务分析" ]薪资区间生成与平均薪资计算代码如下:
def make_salary(): low = random.choice([6, 8, 10, 12, 15, 18, 20]) high = low + random.choice([4, 6, 8, 10, 12]) return f"{low}-{high}K" def parse_salary(salary): salary = salary.replace("K", "") low, high = salary.split("-") return round((int(low) + int(high)) / 2, 2)生成后,原始数据保存到:
data/raw/data_analyst_jobs_raw.csv七、数据清洗
数据清洗是数据分析项目中非常关键的一步。本项目主要进行了以下处理:
删除重复数据;
删除关键字段缺失的数据;
对文本字段进行标准化处理;
将薪资区间转换为平均薪资;
统计每个岗位的技能数量;
保存清洗后的数据。
薪资解析代码如下:
import pandas as pd import re def parse_salary(salary): if pd.isna(salary): return None salary = str(salary).upper().replace(" ", "") match = re.search(r"(\d+)-(\d+)K", salary) if match: low = int(match.group(1)) high = int(match.group(2)) return round((low + high) / 2, 2) return None技能数量统计代码如下:
def count_skills(skills): if pd.isna(skills): return 0 items = re.split(r"[,,、\s]+", str(skills)) items = [item.strip() for item in items if item.strip()] return len(items)数据清洗后保存到:
data/processed/data_analyst_jobs_cleaned.csv运行结果如下:
原始数据量:80 清洗后数据量:80说明当前模拟数据质量较完整,清洗过程中没有发生数据丢失。
八、MySQL 数据库存储
为了模拟真实数据分析岗位中常见的“数据库存储—SQL 查询”流程,本项目将清洗后的 CSV 数据导入 MySQL。首先创建数据库和数据表:
CREATE DATABASE IF NOT EXISTS job_analysis DEFAULT CHARACTER SET utf8mb4; CREATE TABLE job_analysis.data_analyst_jobs ( id INT PRIMARY KEY AUTO_INCREMENT, job_title VARCHAR(100), company VARCHAR(100), city VARCHAR(50), salary VARCHAR(50), education VARCHAR(50), experience VARCHAR(50), skills TEXT, industry VARCHAR(100), avg_salary_k DECIMAL(10, 2), skill_count INT );数据库配置文件
config.py如下:DB_CONFIG = { "host": "localhost", "port": 3306, "user": "root", "password": "******", "database": "job_analysis", "charset": "utf8mb4" }将清洗后的数据导入 MySQL 的核心代码如下:
import pandas as pd import mysql.connector from pathlib import Path from config import DB_CONFIG BASE_DIR = Path(__file__).resolve().parent.parent csv_path = BASE_DIR / "data" / "processed" / "data_analyst_jobs_cleaned.csv" def import_data_to_mysql(): df = pd.read_csv(csv_path) conn = mysql.connector.connect(**DB_CONFIG) cursor = conn.cursor() cursor.execute("TRUNCATE TABLE data_analyst_jobs;") insert_sql = """ INSERT INTO data_analyst_jobs ( job_title, company, city, salary, education, experience, skills, industry, avg_salary_k, skill_count ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s) """ values = [] for _, row in df.iterrows(): values.append(( row["job_title"], row["company"], row["city"], row["salary"], row["education"], row["experience"], row["skills"], row["industry"], float(row["avg_salary_k"]), int(row["skill_count"]) )) cursor.executemany(insert_sql, values) conn.commit() print(f"成功导入 MySQL:{len(values)} 条数据") cursor.close() conn.close()运行结果如下:
准备导入数据量:80 条 成功导入 MySQL:80 条数据这说明清洗后的岗位数据已经成功写入 MySQL 数据库。
九、SQL 查询分析
数据导入 MySQL 后,可以使用 SQL 对岗位数据进行分析。
1. 查看数据总量
SELECT COUNT(*) AS total_count FROM data_analyst_jobs;查询结果为:
total_count = 80说明当前数据库中共有 80 条岗位数据。
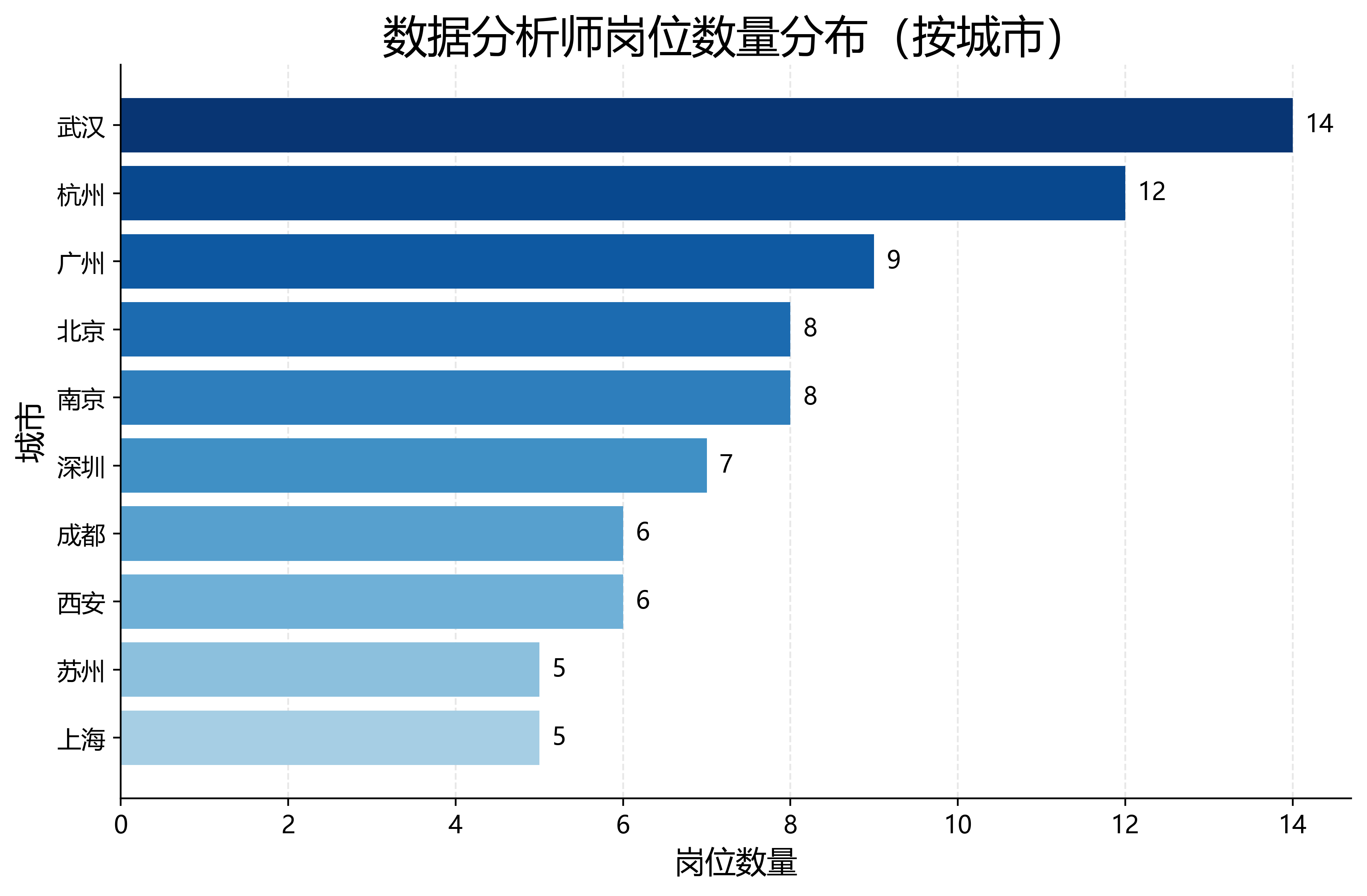
2. 不同城市岗位数量分布
SELECT city, COUNT(*) AS job_count FROM data_analyst_jobs GROUP BY city ORDER BY job_count DESC;这一步用于分析不同城市的数据分析师岗位数量。
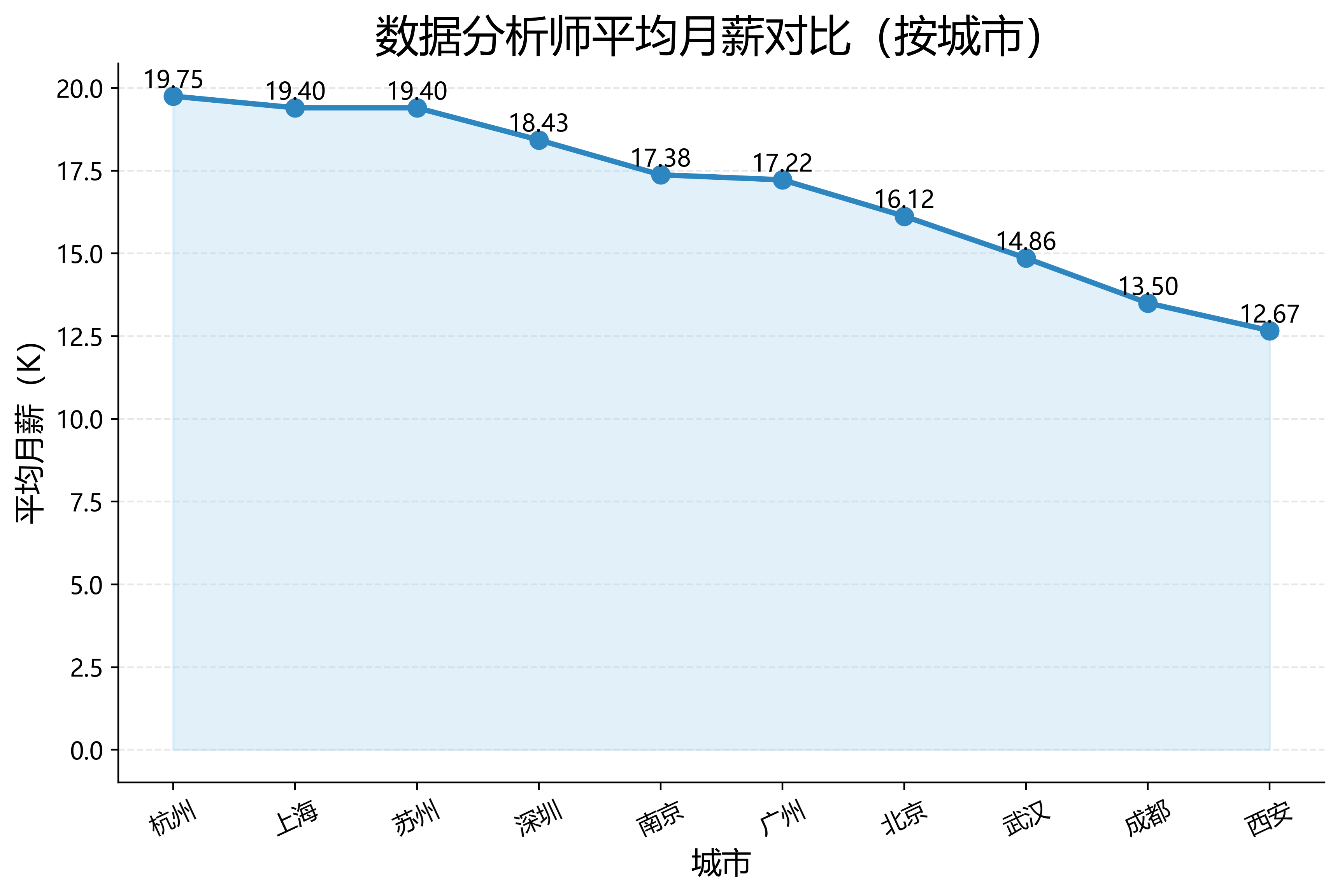
3. 不同城市平均薪资
SELECT city, ROUND(AVG(avg_salary_k), 2) AS avg_salary_k FROM data_analyst_jobs GROUP BY city ORDER BY avg_salary_k DESC;这一步用于分析不同城市的数据分析师平均月薪水平。
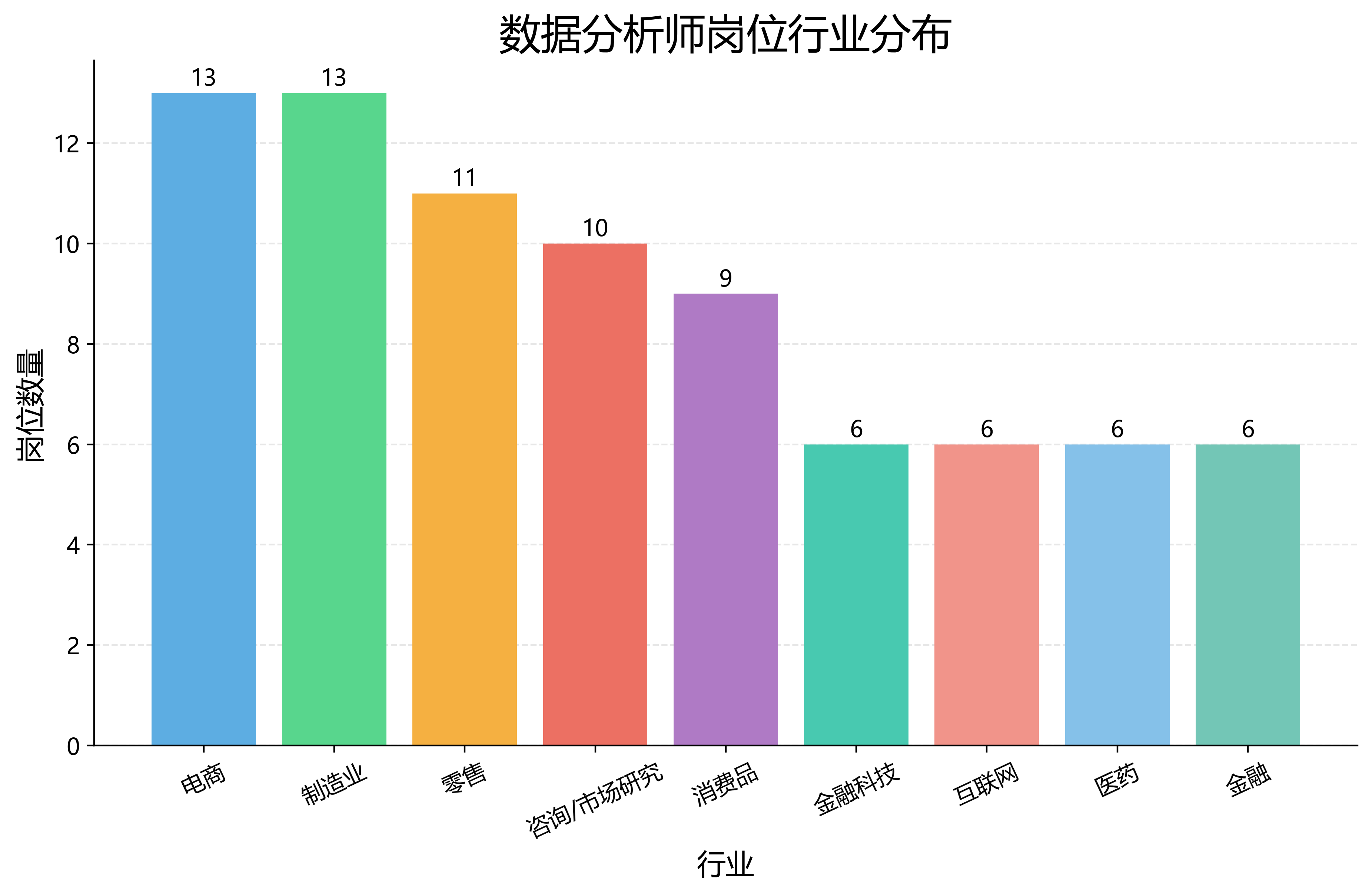
4. 不同行业岗位数量
SELECT industry, COUNT(*) AS job_count FROM data_analyst_jobs GROUP BY industry ORDER BY job_count DESC;这一步用于分析数据分析师岗位在不同行业中的分布情况。
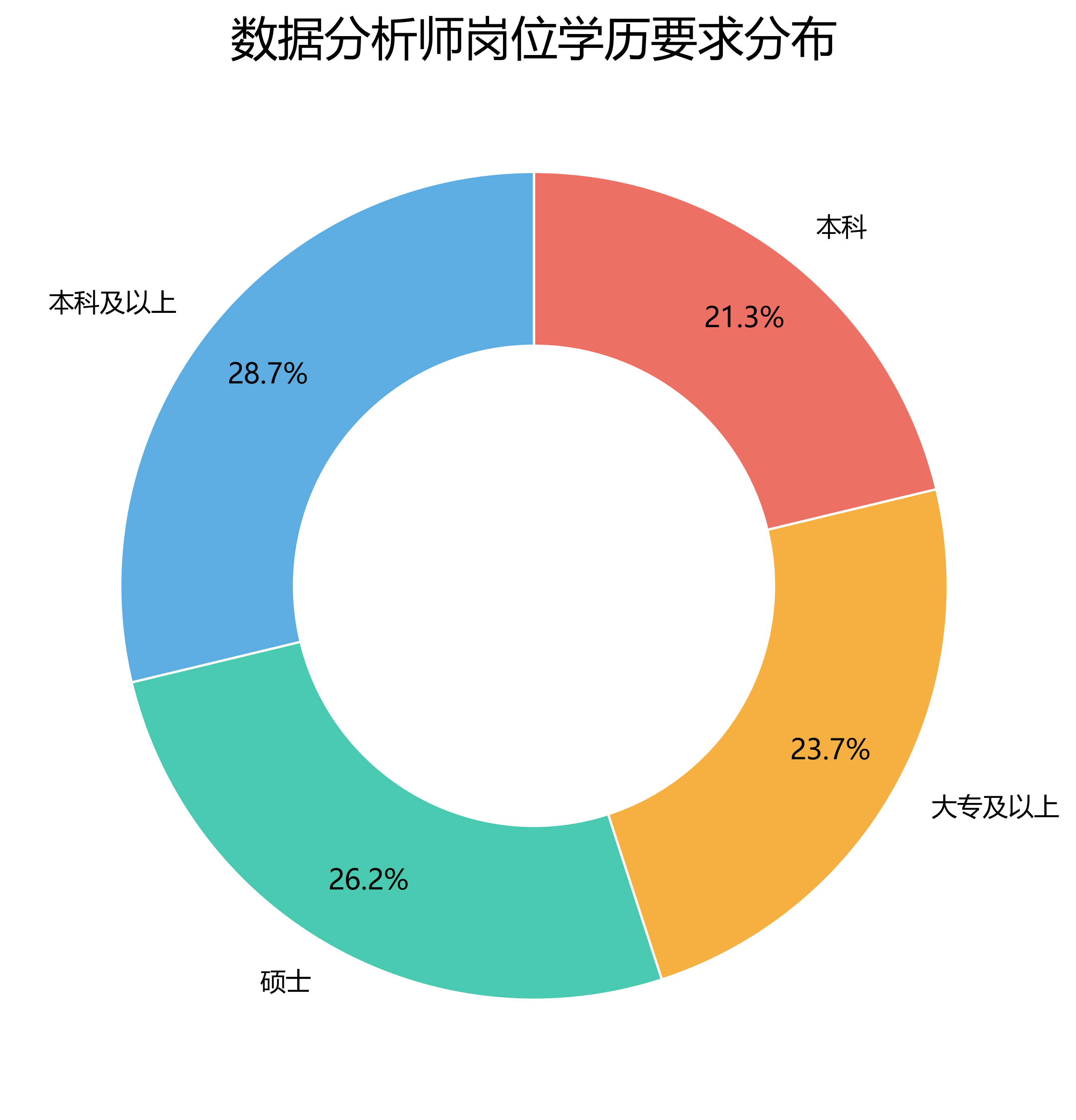
5. 学历要求分布
SELECT education, COUNT(*) AS job_count FROM data_analyst_jobs GROUP BY education ORDER BY job_count DESC;这一步用于分析数据分析师岗位对学历背景的要求。
6. 技能关键词筛选
查询要求 Python 的岗位:
SELECT job_title, company, city, salary, skills FROM data_analyst_jobs WHERE skills LIKE '%Python%';查询同时要求 Python 和 SQL 的岗位:
SELECT job_title, company, city, salary, skills FROM data_analyst_jobs WHERE skills LIKE '%Python%' AND skills LIKE '%SQL%';通过 SQL 查询可以看出,数据分析师岗位通常不是单一工具导向,而是同时涉及编程、数据库、统计分析和可视化表达等多方面能力。
十、Python 可视化展示
完成 MySQL 数据库存储后,本项目使用 Python 从 MySQL 读取数据,并用 matplotlib 进行可视化展示。从 MySQL 读取数据的代码如下:
import pandas as pd import mysql.connector from config import DB_CONFIG def read_data_from_mysql(): conn = mysql.connector.connect(**DB_CONFIG) sql = """ SELECT * FROM data_analyst_jobs; """ df = pd.read_sql(sql, conn) conn.close() print(f"从 MySQL 读取数据成功,共 {len(df)} 条。") return df最终生成的图表包括:
city_job_count.png city_avg_salary.png education_count.png industry_count.png skill_frequency.png运行结果如下:
从 MySQL 读取数据成功,共 80 条。 城市岗位数量分布图已保存 城市平均薪资对比图已保存 学历要求分布图已保存 行业分布图已保存 技能词频统计图已保存 全部图表生成完成十一、可视化结果分析
1. 城市岗位数量分布
从当前模拟数据看,不同城市的数据分析师岗位数量存在一定差异。城市岗位数量分布图可以帮助我们理解岗位机会在城市之间的分布情况。后续替换为真实招聘数据后,这一图表可以用于判断未来求职时重点关注的城市。
2. 城市平均月薪对比
城市平均月薪对比图展示了不同城市之间的数据分析师平均薪资差异。虽然当前数据为模拟数据,但该图表形式后续可以直接应用到真实岗位数据中,用于分析城市薪资水平差异。对于职业规划来说,薪资并不是唯一指标,但它可以作为判断城市发展机会和岗位价值的重要参考维度之一。
3. 学历要求分布
学历要求分布图用于观察岗位对学历背景的要求。数据分析师岗位通常对本科及以上学历有一定要求,部分偏金融、算法或高级分析方向的岗位可能更倾向硕士学历。作为应用统计学本科生,当前专业背景与数据分析岗位具有较强相关性,后续还需要进一步提升统计建模、编程和项目实践能力。
4. 行业分布
行业分布图显示,数据分析师岗位并不局限于互联网行业,在电商、制造业、金融、零售、咨询、医药等行业中也有应用场景。这说明数据分析能力具有较强的行业迁移性。对于应用统计学专业学生来说,数据分析师方向并不是只能进入互联网行业,也可以结合金融、咨询、市场研究、制造业数字化、医药数据分析等不同场景进行发展。
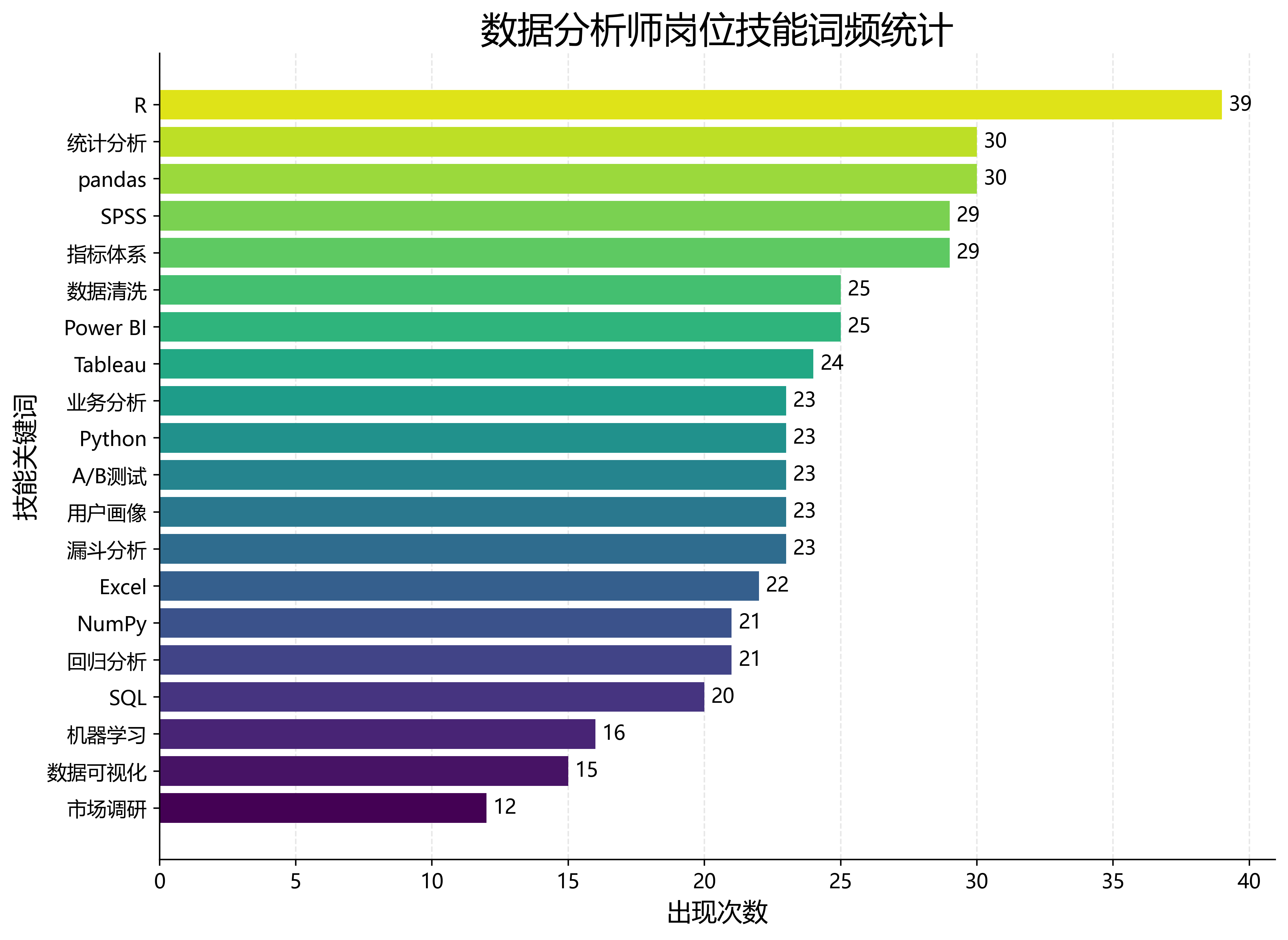
5. 技能词频统计
技能词频图是本项目中最能体现职业规划价值的一张图。通过统计岗位描述中出现的技能关键词,可以观察数据分析师岗位对 Python、SQL、Excel、pandas、统计分析、数据可视化等能力的要求。当前模拟数据中的具体排序不代表真实市场结论,但这种分析方法后续可以直接迁移到真实招聘数据上,判断数据分析师岗位最核心的能力要求。
十二、项目阶段性结论
通过本项目,可以得到以下阶段性认识。
第一,数据分析师岗位不是单一工具岗位,而是复合型岗位。它通常需要同时具备数据处理、数据库查询、统计分析、可视化展示和业务理解等能力。
第二,Python 和 SQL 是数据分析师能力体系中的重要组成部分。Python 更偏向数据清洗、自动化处理和建模分析,SQL 更偏向结构化数据查询和业务取数。
第三,数据可视化能力非常重要。仅仅完成数据处理并不够,还需要把分析结果转化为直观、清晰、可解释的图表。
第四,应用统计学专业背景与数据分析师岗位具有较强关联。概率论、数理统计、回归分析、抽样调查、市场调查与分析等课程内容,都可以与数据分析师岗位能力要求形成衔接。
十三、对个人职业规划的启发
对我个人而言,这个项目的意义不仅是完成一次 Python 和 MySQL 练习,更重要的是把职业目标和项目实践结合起来。
我未来希望向数据分析师方向发展,而本项目帮助我更清楚地认识到后续需要补强的能力:
继续巩固统计学基础,包括概率论、数理统计、回归分析等;
系统学习 Python 数据分析库,如 NumPy、pandas、matplotlib 等;
深入学习 SQL,掌握分组查询、条件筛选、多表连接等常见操作;
增强数据可视化表达能力;
完成更多真实数据分析项目,逐步形成个人作品集;
后续将模拟岗位数据替换为真实招聘数据,完善岗位画像分析结论。
这也让我意识到,职业规划不能只停留在“想做什么”,还要通过项目实践不断验证自己是否具备目标岗位所要求的能力。
十四、项目不足与后续优化方向
当前项目仍然有一些不足。
第一,当前数据为模拟数据,不能直接代表真实招聘市场。后续需要通过公开招聘平台手工整理或合规采集真实岗位数据。
第二,当前样本量只有 80 条,后续可以扩展到 100 条以上真实岗位数据,提高分析结果的参考价值。
第三,技能词频统计仍然较为基础,后续可以加入中文分词、词云图和技能共现分析。
第四,可以增加学历、经验与薪资之间的交叉分析,例如分析不同学历要求下的平均薪资差异。
第五,可以增加个人能力差距雷达图,将岗位要求和自身能力进行对比,从而形成更清晰的学习计划。
后续优化路线如下:
模拟数据流程版 ↓ 真实岗位数据版 ↓ 岗位能力画像增强版 ↓ 个人能力差距分析版 ↓ 职业规划大赛展示版十五、项目总结
本文基于模拟招聘数据,搭建了一个数据分析师岗位画像分析项目。项目完整覆盖了数据生成、数据清洗、MySQL 存储、SQL 查询分析和 Python 可视化展示等环节。虽然当前数据仍然是模拟数据,但这个项目已经帮助我跑通了数据分析师岗位常见的基础技术流程。后续我将进一步整理公开招聘平台中的真实岗位数据,对城市分布、薪资水平、学历要求、行业分布和技能需求进行更真实的分析。通过这个项目,我更加明确了数据分析师方向的能力要求,也进一步坚定了后续学习 Python、pandas、SQL、数据可视化和统计建模的计划。
标签建议填: ```text Python, MySQL, SQL, pandas, 数据分析, 数据可视化, 职业规划
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)