
python之文件的只读操作
| 方法 | 返回类型 | 举例 |
|---|---|---|
f.read() |
字符串 (str) | "itheima itcast python\nitheima python..." |
f.readlines() |
列表 (list) | ["itheima itcast python\n", "itheima python..."] |
f.readline() |
字符串 (str) | "itheima itcast python\n" |
with open("word.txt", "r", encoding="UTF-8") as f:
作用:打开文件,给文件起个名字叫 f
-
"word.txt":要打开的文件名 -
"r":只读模式 -
encoding="UTF-8":使用UTF-8编码(支持中文) -
as f:把打开的文件对象赋值给变量f -
with:会自动关闭文件,不用手动写f.close()
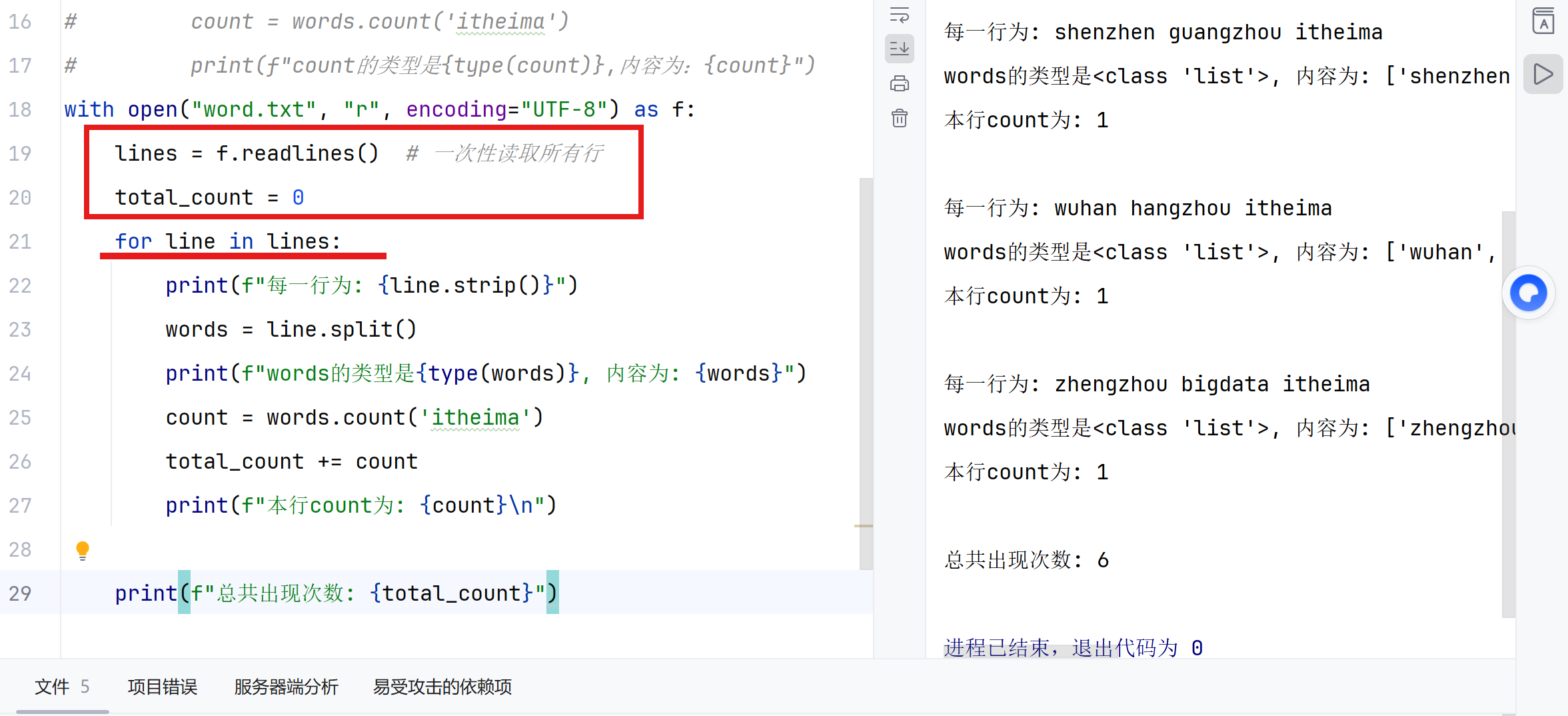
lines = f.readlines()
作用:一次性读取文件的所有行,保存到 lines 变量中
-
f.readlines()会返回一个列表 -
列表里的每个元素就是文件中的一行(字符串格式)
举例:假设 word.txt 内容是:
text
itheima itcast python itheima python itcast beijing shanghai itheima
那么 lines 的值是:
python
lines = [
"itheima itcast python\n", # 第1行(注意末尾有\n换行符)
"itheima python itcast\n", # 第2行
"beijing shanghai itheima\n" # 第3行
]
for line in lines:
作用:for 循环,依次取出 lines 列表中的每一行
-
第1次循环:
line = "itheima itcast python\n" -
第2次循环:
line = "itheima python itcast\n" -
第3次循环:
line = "beijing shanghai itheima\n"
lines的类型为列表,line的类型为字符串。
python
print(f"每一行为: {line.strip()}")
作用:打印当前行内容
-
line是当前行的字符串(末尾有\n换行符) -
.strip()是字符串方法,作用是去掉字符串开头和结尾的空白字符(包括空格、换行符\n、制表符等)
举例:
python
line = "itheima itcast python\n"
line.strip() # 结果是 "itheima itcast python"(去掉了末尾的\n)
line = " hello world \n"
line.strip() # 结果是 "hello world"(去掉了前后空格和\n)
为什么要用 .strip()?
-
直接打印
line会多一个空行(因为line末尾有\n,print()本身也会换行) -
用
.strip()去掉\n后,打印出来更美观
文件内容:
┌─────────────────────────────┐
│ itheima itcast python\n │ ← 第1行
│ itheima python itcast\n │ ← 第2行
│ beijing shanghai itheima\n │ ← 第3行
└─────────────────────────────┘
↓
f.readlines() 读取
↓
lines = [第1行, 第2行, 第3行] ← 这是一个列表
↓
for line in lines: ← 循环
↓
第1次循环:line = "itheima itcast python\n"
↓
line.strip() → "itheima itcast python"
↓
print() → 输出:每一行为: itheima itcast python
↓
第2次循环:line = "itheima python itcast\n"
↓
... 以此类推
| 方法 | 作用 |
|---|---|
f.readlines() |
一次性读所有行,返回列表 |
for line in lines |
循环遍历每一行 |
line.strip() |
去掉行首尾的空白字符(换行符、空格等) |
-
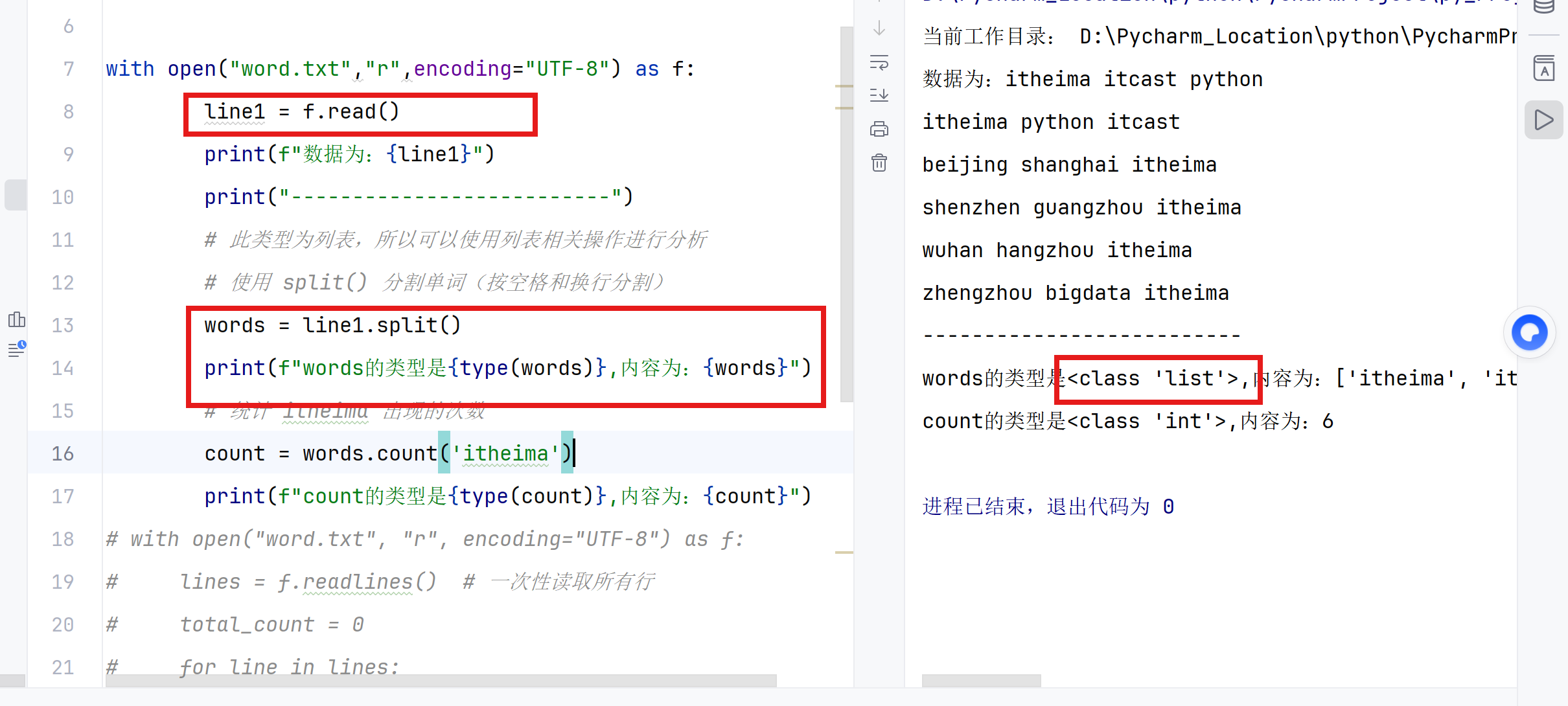
f.read()返回的确实是字符串 ✅ -
但是代码中的
words = line1.split()把字符串转换成了列表 ✅
line1 = f.read() # line1 是字符串 (str)
print(type(line1)) # 如果打印会显示 <class 'str'>
words = line1.split() # split() 方法把字符串拆分成列表
print(type(words)) # 打印显示 <class 'list'>
第1步:f.read() 返回字符串
python
line1 = f.read()
# line1 的内容是:
# "itheima itcast python\nitheima python itcast\nbeijing shanghai itheima\n..."
# ↑ 这是一个完整的字符串
第2步:.split() 把字符串拆分成列表
python
words = line1.split()
# .split() 的作用:按空白字符(空格、换行、制表符)切割字符串
# 返回一个列表
举例说明 .split() 的效果:
python
# 原始字符串
text = "itheima itcast python"
# 使用 split()
result = text.split()
print(type(result)) # <class 'list'>
print(result) # ['itheima', 'itcast', 'python']
文件内容(字符串形式):
"itheima itcast python\nitheima python itcast\nbeijing shanghai itheima\n..."↓ 使用 .split()
拆分后的列表:
['itheima', 'itcast', 'python', 'itheima', 'python', 'itcast',
'beijing', 'shanghai', 'itheima', 'shenzhen', 'guangzhou',
'itheima', 'wuhan', 'hangzhou', 'itheima', 'zhengzhou',
'bigdata', 'itheima']
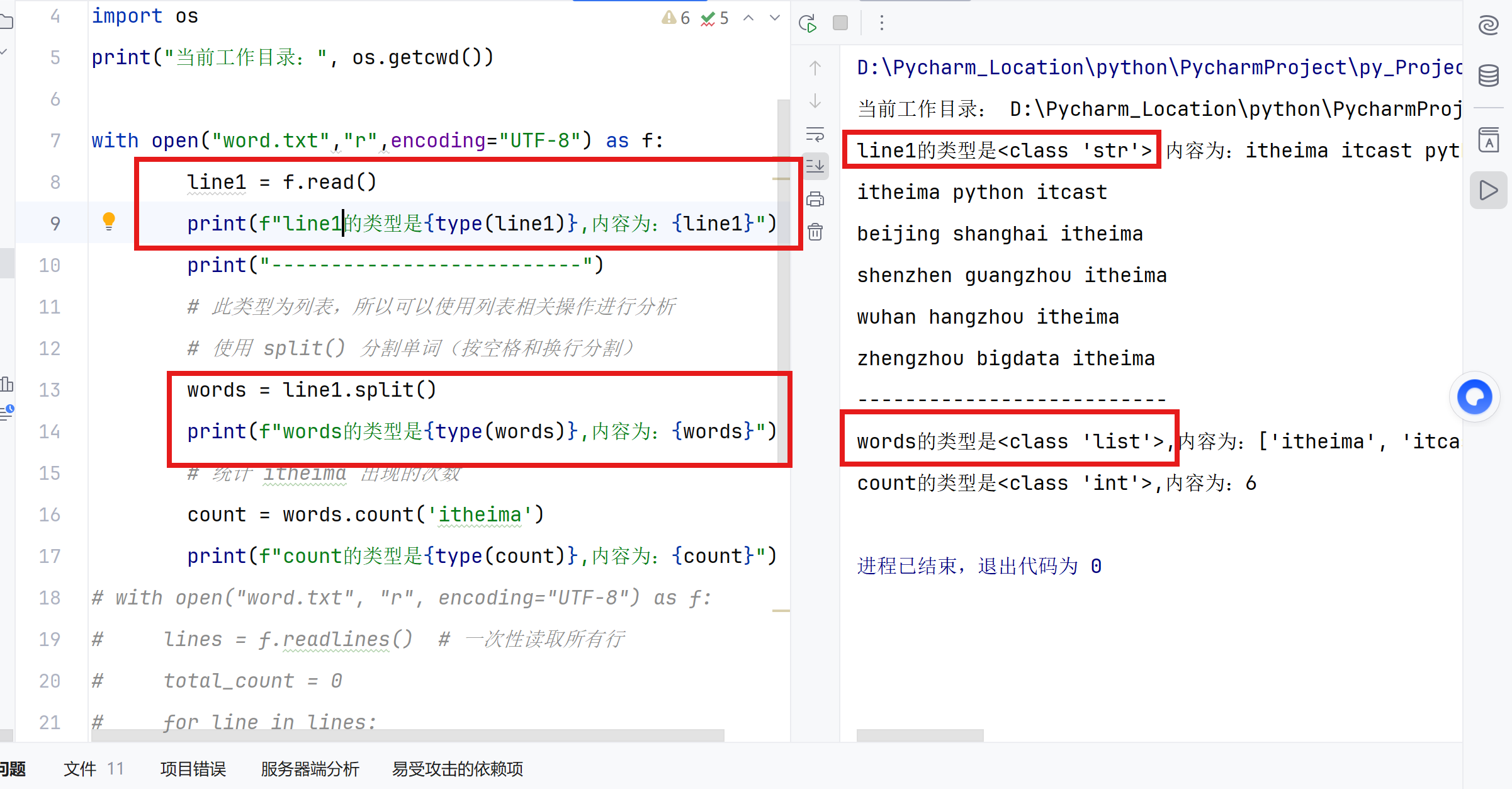
| 变量 | 类型 | 如何得到 |
|---|---|---|
line1 |
字符串 (str) | f.read() 直接返回 |
words |
列表 (list) | 对字符串使用 .split() 方法转换而来 |
记忆要点:
-
f.read()→ 字符串 -
字符串
.split()→ 列表 -
列表
.count()→ 统计次数
列表能拆分成字符串,字符串也可以拆分成列表
字符串变列表:用 .split()
python
# 字符串有 split() 方法 text = "itheima python itcast" words = text.split() # ✅ 正确 print(words) # ['itheima', 'python', 'itcast']
列表变字符串:用 .join()
python
# 字符串有 join() 方法,列表没有
words = ['itheima', 'python', 'itcast']
text = ' '.join(words) # ✅ 正确
print(text) # "itheima python itcast"
# 错误写法
text = words.join(' ') # ❌ 错误!列表没有 join() 方法
text = words.split() # ❌ 错误!列表没有 split() 方法
记忆技巧
-
.split()= 分割 → 把字符串切成列表(从整到碎) -
.join()= 连接 → 把列表粘成字符串(从碎到整)
text
字符串 ----------split()----------> 列表 ↑ ↓ └----------join()------------------┘
总结:
-
.split()只能字符串用(字符串→列表) -
.join()可以列表用,但调用对象是字符串(列表→字符串) -
列表不能直接用
.split(),会报错!
# 字符串 → 列表
s = "itheima python itcast"
print(f"原始字符串:{s}")
# 方法1:split() 按单词拆分
words = s.split()
print(f"split()后:{words}") # ['itheima', 'python', 'itcast']
# 方法2:list() 按字符拆分
chars = list(s)
print(f"list()后:{chars}") # ['i','t','h','e','i','m','a',' ','p',...]
print("---")
# 列表 → 字符串
# 用空格重新合并
new_s = ' '.join(words)
print(f"join()后:{new_s}") # "itheima python itcast"
# 验证是否和原来一样
print(f"是否相同:{s == new_s}") # True字符串的方法:
| 方法 | 作用 | 返回值 | 是否改变原字符串 |
|---|---|---|---|
split() |
分割成列表 | 列表 | 否(返回新列表) |
strip() |
去除两端字符 | 字符串 | 否(返回新字符串) |
-
split = 分裂 → 字符串变列表(一个变多个)
-
strip = 去除 → 去掉两端多余字符(长度变短)
这两个方法都不会修改原字符串(因为字符串是不可变的),而是返回新的字符串或列表。
更多推荐


 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)