
AIGC(生成式AI)试用 53 -- 个人知识库 DocsGpt(Agent)
- Agent
智能体是具备自主感知、记忆、决策、交互与执行能力的智能系统,是人工智能产品及服务的重要形态。 -- 豆包
AI 智能体是能够感知并响应其所处环境、采取行动以实现预设目标的自动化实体。五大核心能力界定:
- 自主感知:可主动 / 被动从环境中获取并理解信息,无需人类逐次手动输入
- 记忆:可存储、检索和复用历史信息,保证行为与上下文的连贯性
- 决策:可自主拆解任务、规划执行路径、选择行动方案
- 交互:可与人类、其他智能体、系统设备进行双向协同沟通
- 执行:可调用外部工具、软件系统或硬件设备,实际改变环境状
感知输入 → 记忆检索 → 决策生成 → 行动执行 → 反馈学习 -- CSDN AI助手 -
agent是强化版的prompt?agent 与 prompt 的区别
- Agent = 大模型 + 记忆模块 + 工具集(Tool/Skills) + 规划引擎 + 安全机制 + 各类内置 Prompt 指令 -- 豆包
- Prompt:一问一答;A跟他:一问+思考+确认+决策+执行+答案/结果
- Agent = 高度自治、自驱的Prompt + 任务执行/实现
- 个人理解:好的prompt(清晰 明确)是agent的基础,然而单纯的prompt不可能构成agent -
最简Agent实现
API_URL = { "answer_new" : f"http://localhost:7091/api/answer", "models_getlist" : f"http://localhost:7091/api/models", "conversations_getlist" : f"http://localhost:7091/api/get_conversations", "conversations_getsingle" : f"http://localhost:7091/api/get_single_conversation", "conversations_rename" : f"http://localhost:7091/api/update_conversation_name", }1)感知输入 , select model + question ai
--> select Model --> creat new conversation --> rename conversation# check model list, to file "model_id" def get_model(): url = API_URL["models_getlist"] model_list = [] response = requests.get(url) result = response.json() for model in result['models']: mn = f"Model_Name: {model['display_name']}, Model_Id: {model['id']}" model_list.append([mn]) return model_list # creat new blan conversation without any question def creat_new_chat(): url = API_URL["answer_new"] payload = { "question": f"", ## "history": chat_history, ## "conversation_id": "6a2524f29404e7c57b19e98b", ## "prompt_id": "", ## "chunks": 2, ## "retriever": "", ## "api_key": "string", ## "agent_id": "string", ## "active_docs": "", ## "isNoneDoc": True, ## "save_conversation": True, ## "visibility": "hidden", "model_id": "docsgpt-local", ## "passthrough": passthrough, ## "temperature": 0.0, ## "top_k": 5, } response = requests.post(url, json=payload) # get conversations list def get_conversations(): url = API_URL["conversations_getlist"] conversation_list = [] response = requests.get(url) result = response.json() ## print(f"--> Conversation: {response}\n{result}") for conversation in result: cn = {"Conversaton_Name": f"{conversation['name']}", "Conversaton_Id": f"{conversation['id']}"} conversation_list.append(cn) print(f"--> {conversation_list}") return conversation_list # get single conversation, for creat_new_chat() used def get_single_conversation(covid): url = API_URL["conversations_getsingle"] response = requests.get(f"{url}?id={covid}") result = response.json() return result # rename conversion name, make sure show clear def rename_chat(chat_name): url = API_URL["conversations_rename"] conversation_list = get_conversation() covid = conversation_list[0]['Conversaton_Id'] payload = { "id": covid, "name": chat_name, } requests.post(url, json=payload) return covid2)记忆检索 , history + compress
--> store user question + assitant(system reply) --> compress store减少上下文容量(减少token使用,减少理解偏差)# ask question, get history def chat(prompt): url = API_URL["answer_new"] question = prompt.strip() chat_history = [] passthrough = { "Time": time.ctime(), "sysprompt": "以中文回复以下问题:", # 分析以下问题,如问题不明确则列出不明确之处,如问题明确则输出结果 } payload = { "question": f"{passthrough['sysprompt']}{question }", "history": chat_history, "conversation_id": "6a39310ac2149c3dbc243a04", ## "prompt_id": "", "chunks": 2, "retriever": "", ## "api_key": "string", ## "agent_id": "string", "active_docs": "", "isNoneDoc": True, "save_conversation": True, ## "visibility": "hidden", "model_id": "docsgpt-local", "passthrough": passthrough, "temperature": 0.0, "top_k": 5, } chat_history.append( {"role": "user", "content": question} ) # call AI Answer response = requests.post(url, json=payload) if response.status_code == 200: result = response.json() # add question reply into history chat_history.append({"role": "assistant", "content": result['answer']}) return result['answer'] else: return f"{response.status_code}, Error" # compress conversation history, keep context def compress(chat_history : list): message_json = json.dumps(chat_history, ensure_ascii=False) ## if len(message_json) <= 10000: ## return messages prompt = f"压缩以下对话历史,保留核心信息和关键事实,去除冗余,不能超过100个字符:\n{message_json}" result = chat(prompt) return result # loop conversation, build basic agent construction def chat_loop(): url = API_URL["answer_new"] while True: # while loop, different for chat() question = input("\nPlease input your question:").strip() chat_history = [] passthrough = { "Time": time.ctime(), "sysprompt": "以中文回复以下问题:", # 分析以下问题,如问题不明确则列出不明确之处,如问题明确则输出结果 } payload = { "question": f"{passthrough['sysprompt']}{question }", "history": chat_history, "conversation_id": "6a39310ac2149c3dbc243a04", ## "prompt_id": "", "chunks": 2, "retriever": "", ## "api_key": "string", ## "agent_id": "string", "active_docs": "", "isNoneDoc": True, "save_conversation": True, ## "visibility": "hidden", "model_id": "docsgpt-local", "passthrough": passthrough, "temperature": 0.0, "top_k": 5, } chat_history.append( {"role": "user", "content": question} ) # quit conversation ## if user_input == "/quit": ## print("End Agent >>") ## break # call AI Answer response = requests.post(url, json=payload) if response.status_code == 200: result = response.json() # add question reply into history chat_history.append({"role": "assistant", "content": result['answer']}) return result['answer'] else: return f"{response.status_code}, Error"3)决策生成 , think + select tool
- 生成tool --> 按格式生成--- name: read-json-file description: | 读取json文件时使用 tags: read, json 适用:json文件读取 license: rz01 metadata: author: roy zhu version: "0.1" --- ## 技能概述 读取json格式文件时使用。例如: - 读取json文件 - 提取json文件内容 ## 执行步骤 1. 打开json文件 2. 读取json文件 3. 分析json文件内容 4. 关闭json文件 ## 注意事项 - 读取异常给出提示 ## Examples- 选择/执行tool --> 路由,参考 (4 封私信 / 30 条消息) 第六章:手搓 Skill 系统 —— 能力模块化与编排 - 知乎 或 LLM大模型源码
# 文件目录 │ skills-map.json # skill map list │ └─read-json-file # skill: read-json-file │ changelog.md │ metadata.json │ readme.md │ SKILL.md # core for skill description │ ├─assets ├─examples │ skills.md │ ├─references ├─scripts │ read_json_file.py │ └─tests 1) SKILL.md --> read-json-file 2) skills-map.json { "read-json-file": "read json file,读取json文件" } 3) python: read json file def read_json_file(file_name:str) -> str: """读json文件""" try: with open(file_name, "r", encoding="utf-8") as f: data = json.load(f) return data ## return f.read() except Exception as e: return f"fail:{str(e)}" 4-1) tool(skill) route: get and select skill --> 此处仅为模拟方式,通过skill关键字与prompt及answer的包含关系确定skill的选择 def get_skills(): skills = read_json_file("./skills/skills-map.json") def get_skill_name(): return list(skills.keys) def get_skill_values()->list: return list(skills.values) return skills 4-1) 选中skill,读入skill.md内容,执行选中skill操作 def sel_skill(query): for skill in get_skills(): if skill in query or get_skills()[skill] in query or query in skill or query in get_skills()[skill]: return read_md_file(f"./skills/{skill}/skill.md") else: return "cannot get skill."4)反馈学习, chat loop
1) 循环对话 - 使用while循环,当出现特定指令,如 /quit 时通出 - 使用LLM工具所提供的函数,调用指定的 chat(conversation) ID持续对话 2) 压缩上下文,存入 system prompt / user prompt / assisttan promt chat_history = [] chat_history.append( {"role": "system", "content": sysprmpt} ) chat_history.append( {"role": "user", "content": question} ) chat_history.append( {"role": "assistand", "content": answer} ) def compress(chat_history : list): message_json = json.dumps(chat_history, ensure_ascii=False) ## if len(message_json) <= 10000: ## return messages prompt = f"压缩以下对话历史,保留核心信息和关键事实,去除冗余,不能超过100个字符:\n{message_json}" result = chat(prompt) # get chat reply: chat_history return result - DocsGPT Agent
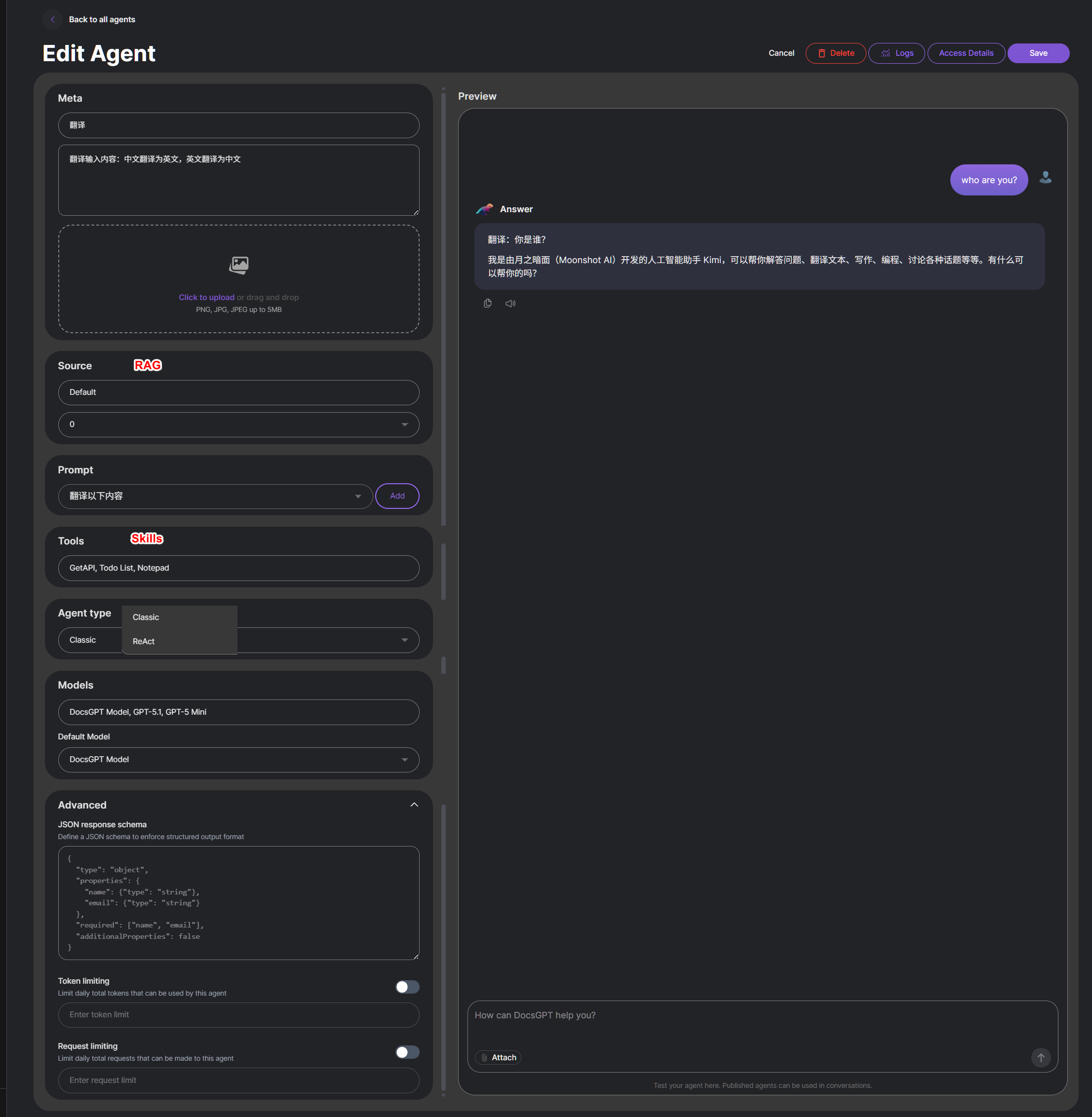
- 最简单省事的方式,使用大模型工具提供的agent 和 skill
参考:
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)