
HuggingFace 发了份 AI Agent 词汇表,专治术语混乱
Harness、Scaffold,以及那些值得搞清楚的 AI Agent 术语
原文 Hugging Face Blog:Harness, Scaffold, and the AI Agent Terms Worth Getting Right
链接:https://huggingface.co/blog/agent-glossary
一个领域跑得太快的时候,常常会出现这样的情况:词汇更新的速度,远远超过了大家对这些词到底是什么意思的共识。术语开始变得模糊,在不同场景里被反复借用,或者干脆成了某个从没人讲清楚的概念的简称。AI Agent 这个领域眼下正在经历这一幕——各种概念被搅在一起,有的被改了名,还有的火了几个月之后又悄无声息地消失了。
这对新人来说挺劝退的,就连想跟上最新进展的从业者也常常一头雾水。ICLR 2026 结束后,本文作者之一 ariG23498 发了一条推,把这种困惑形容得相当到位:
“Agent 语境下的 ‘harness’ 和 ‘scaffold’ 到底指什么?我在 ICLR 现场听了一堆解释,但始终没搞明白,为什么这些说法就是收敛不到一个统一的解释上。”
这篇术语表,就是笔者想为这些反复出现、却一直没有清晰一致解释的词找个落脚点的尝试。它不打算做成囊括这个领域所有术语的大词典,而是把火力集中在那些最容易被混淆、被换着花样用,或者被默认"这还用解释吗"、实际上根本不简单的概念上。
这里面大部分术语,无论你是在搭 Agent、部署 Agent,还是单纯用一用 Claude Code、Codex 或者 Hermes Agent 这类工具,都会撞上。最后一节讲的是训练模型时才会碰到的概念,如果你不在那条线上干活,这部分了解一下即可。
这些术语里有不少其实还没有公认的定义,不同框架对同一个词的用法也各不相同。这篇东西的目的不是去强推一套"唯一正确"的说法,而是给出一个好用的心智模型,让大家讨论起来不至于鸡同鸭讲。
废话不多说,开始。
Model(模型)
模型就是那个 LLM:文本进,文本出(比如 Claude、Qwen、GPT、Kimi、DeepSeek……)。它光杆司令一个,两次调用之间没有记忆,也没有循环。模型可以表达"我想调用某个工具"的意图,但真要把这个工具执行起来,得靠 harness。它回答一个 prompt,然后就停了。给它套上 scaffolding 和 harness,它才变成一个 Agent。
Scaffolding(脚手架)
围绕模型、用来定义其行为的那一层:系统提示词、工具说明、模型的输出怎么被解析、它在多个步骤之间记住些什么(也就是上下文管理)。这一层塑造了模型如何看待世界、如何在其中行动——不管是训练阶段还是推理阶段都是如此。
像 Claude Code、Codex、Antigravity CLI 这些产品,会把整个东西统称为 harness。Claude Code 自家文档里就直说了:"Claude Code 充当的是围绕 Claude 的 Agent harness。"这是 harness 的宽泛用法——指代除了模型之外的一切。Scaffold 和 harness 之间的区分,在你需要把它们分开来推理时(比如在训练流水线里)最为关键。你还会听到有人把 “scaffold” 用得更宽泛,涵盖 harness 所依赖的任何基础设施:hooks、运行时配置,甚至目录结构。
有些产品(比如 Claude Code、Codex)和它们厂商自家的模型是深度绑定的。另一些(比如 Antigravity CLI、Hermes Agent)则允许你接入任意模型。
Harness(执行框架)
Agent 内部的执行层:它调用模型、处理模型发出的工具调用、决定什么时候该停下。Harness 才是真正让 Agent 跑起来的东西。而前面讲的 scaffolding,是模型据以工作的依据——它的指令、它的工具、它的格式。
Harness engineering(Harness 工程) 就是把这一层设计好的功夫:决定 Agent 何时该停,错误如何处理,以及用什么样的护栏把它框在正道上。这套功夫在训练和推理两端都适用。Addy Osmani 的文章和 OpenAI 关于用 Codex 做开发的复盘,都是从推理这一侧讲这件事的。
到了评估阶段,同样的模式会以 eval harness(评估框架) 的形式出现:它不去收集训练数据,而是在某个模型 checkpoint 上跑一组固定的场景,记录各项指标,而不去更新权重。
有些框架会用 orchestrator(编排器) 来指代一个更高层的控制器,负责协调多个 Agent 之间的工作。和驱动单个模型走完执行循环的 harness 不同,orchestrator 把一个个 Agent 当作整体单元来调度,每个 Agent 各自跑着自己的 harness(见后文的 Sub-agents)。
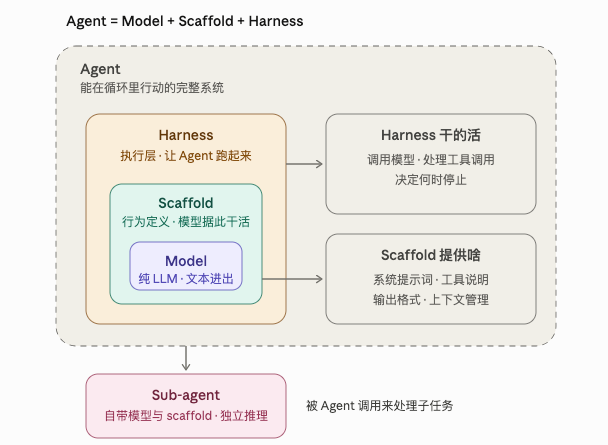
Agent(智能体)
这个词源自强化学习。在 RL 里,agent 不过是一个函数:接收一个观察(observation),返回一个动作(action)。环境收下这个动作,再返回一个新的观察,如此循环往复。这个循环,至今仍是 LLM Agent 运作方式的核心。
到了 LLM 的世界,这个词的含义被拓宽了。一个 Agent,是模型加上让它能够"行动"而非仅仅"回应"的一切。它把单纯的文本生成,变成了某种能够在循环中行动的东西:接收信息、决定怎么做、再对结果采取行动。
拿编程 Agent 当个具体例子。系统提示词、工具说明,以及模型遵循的输出格式,这些构成了 scaffolding。那个调用模型、处理工具调用、决定何时停止的循环,就是 harness。到了训练阶段,harness 还会并行地跑很多个这样的循环,把结果喂回去更新模型。
社区里通常把它概括成一句话:Agent = Model + Harness(可参考 Vtrivedy10 和 Will Brown 的推文)。一句话:你要么是模型,要么就是 harness。而 harness 和 scaffold 之间那点最容易让人犯迷糊的微妙区别,正是上面两节要解决的问题。
人们谈论 Claude Code、Codex 或者 Cursor 这些产品时,指的其实是搭在某个特定模型之上、和它一起设计与调优的某个特定 harness。两款产品用着同一个底层模型,体验却可能天差地别,原因就在于它们的 harness 做了不同的取舍。反过来,把一个更好的模型塞进同一个 harness,体验同样会变。模型、harness、产品,这是三个不同的东西。
Context Engineering(上下文工程)
设计往 Agent 上下文窗口里塞什么:模型在每一步看到什么——系统提示词、工具说明、对话历史、检索来的知识。这不是一锤子买卖:随着模型不断运行,前面的轮次会影响后续调用里塞进去的内容,而 harness 会在整个运行过程中主动管理这件事。它在训练和推理两端都适用,但搞砸的代价天差地别。训练时,模型看到什么,直接决定它学到什么——搞错了,你就得重新训练。推理时,它无非就是一段文本:改个提示词,重新部署就行。
记忆(memory)也是这幅图景的一部分。短期记忆是单次运行中留在上下文窗口里的东西:对话历史、工具结果、之前的推理。长期记忆则跨会话存续,存在外部,按需检索,在需要的时候再注入回上下文里。
Policy(策略)
策略,指的是一个 Agent 所遵循的行为方式:给定任何一种情境,它定义了采取每个可能动作的概率。在 LLM 系统里,这套策略有一部分被学进了模型权重里,但其行为同样取决于外围的 scaffolding 和 harness。同一个模型,因提示词、工具、记忆和执行循环的不同,表现可以截然不同。
策略不等于 Agent。策略定义的是行为;Agent 是那个在环境中真正采取行动的完整系统。把一个 checkpoint 套上 scaffolding 和 harness 部署出去,你就得到了一个 Agent,而它的行为就是策略。
Tool Use(工具调用)
Agent 伸手够到自身之外的方式:API、代码解释器、数据库、网页搜索、文件系统。模型以一种结构化的格式表达"我要用某个工具"的意图。现代推理 API 把这件事做成了一等公民:harness 直接收到这个调用,再把它路由到对应的函数。结果被喂回上下文,循环继续。
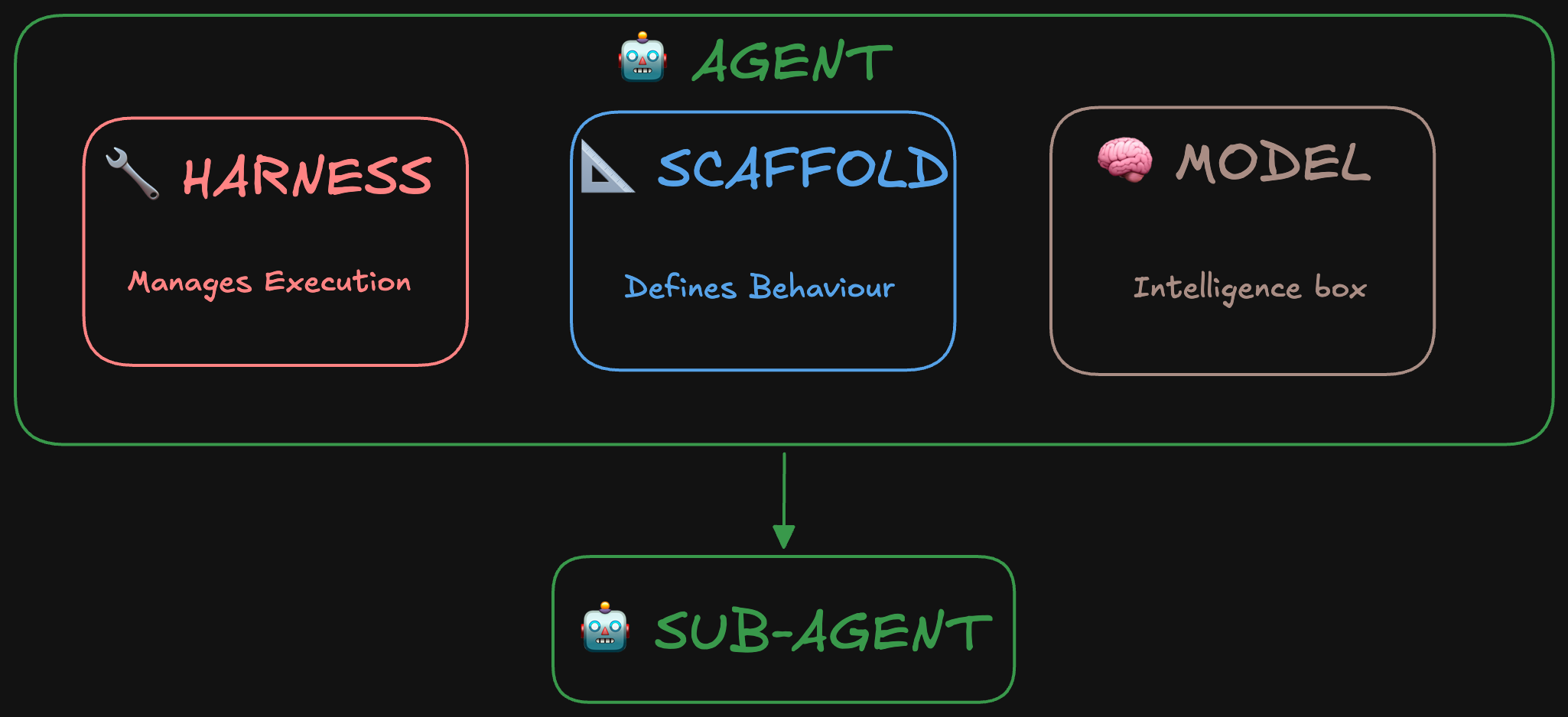
Skills(技能)
可复用、结构化的知识包,让多步骤任务得以完成。如果说一个**工具(tool)是一个动作(“执行这条命令”),那么一个技能(skill)**打包的就是达成某个目标所需的全部东西(“排查这个 bug、形成假设、写出修复方案”)。技能可以在不同 Agent 之间移植,按需加载。Tool、skill 和 sub-agent 之间的界线,在不同框架里会来回挪动。
Sub-agents(子智能体)
由另一个 Agent 调用来处理某个具体子任务的 Agent。它有自己的模型和 scaffold,独立推理,然后返回一个结果。调用它的那个 Agent,不需要知道它内部是怎么运作的。这一点正是 sub-agent 区别于工具(一次函数调用)或技能(打包好的知识)的地方:一个 sub-agent 自己就能推理、调用工具,甚至再去调用更多的 sub-agent。调用它的那个 Agent,有时也被称为 orchestrator(编排器)。
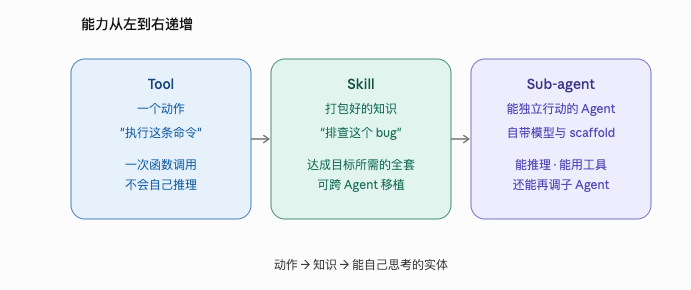
Training(训练)
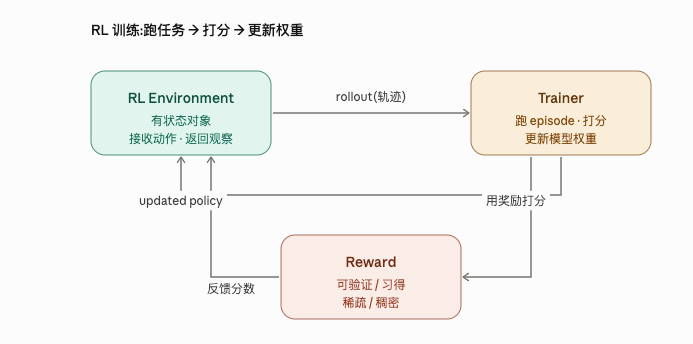
上面那些术语,无论你是在训练还是部署都用得上。接下来这四个则是训练专属——在训练中,Agent 会跑一遍遍任务、被打分,然后更新其模型的权重。所有针对 LLM 的 RL 训练系统,都是围绕同一条流水线搭起来的:
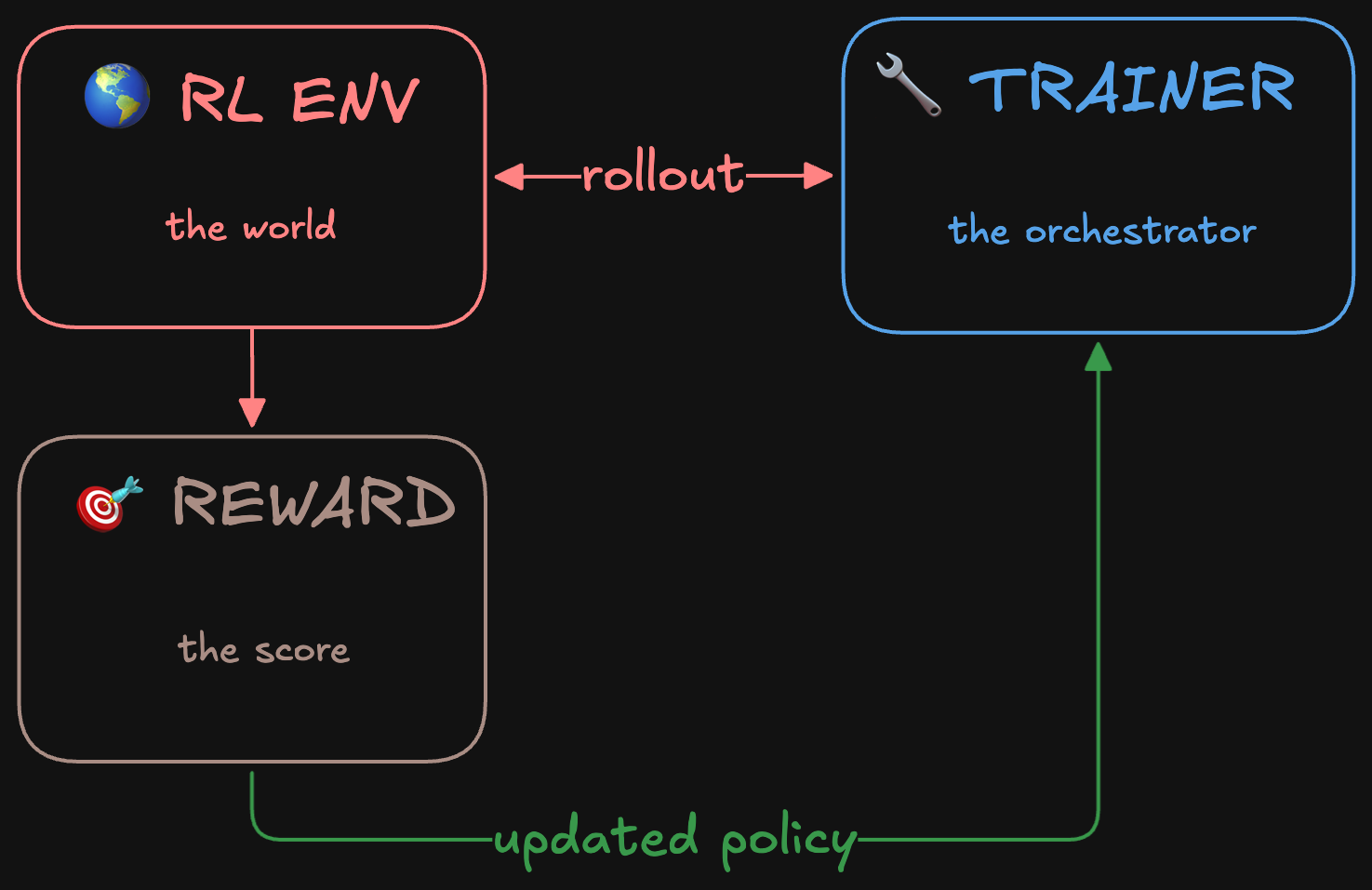
RL Environment(强化学习环境)
环境,就是任何你能与之交互的东西:一个有状态的对象,接收一个动作作为输入,更新自己的内部状态,再返回一个观察。在 LLM 语境下,动作通常就是工具调用。文件系统是个简单的例子:touch foo.txt 这个动作通过创建文件更新了状态,而返回的观察可能就是更新后的文件列表。各个框架对它的定义不尽相同。
Trainer(训练器)
训练器是让 Agent 变得更强的那个东西:它跑很多次 Agent episode,给结果打分,再用这些分数去更新内部模型的权重。TRL 的 GRPOTrainer 就是个具体例子——单单一个类,就把 episode 生成、奖励打分和权重更新全包了。
Rollout(回合 / 轨迹)
一次 rollout,是 Agent 从头到尾完整跑一遍:它看到了什么、做了什么、在每一步又拿到了什么奖励。视语境不同,它也被叫做 trajectory(轨迹) 或 trace(踪迹)。这就是 RL 算法用来学习的原始数据。
Reward(奖励)
那个用来告诉训练算法"模型是不是在变好"的分数。它可以是可验证的(测试通过/失败、答案是否匹配),也可以是习得的(人类偏好、LLM-as-judge);可以是稀疏的(一个 episode 结束时给一个分),也可以是稠密的(每一步都给分)。这正是训练器用来实打实更新内部模型权重的依据。
Rubrics(评分细则) 把奖励拆成若干带权重的明确维度,而不是揉成一个单一的数字。OpenEnv 和 Verifiers 把 rubrics 实现成了可以组合的对象(WeightedSum、Sequential、Gate)。
写在最后
很多定义眼下都还在流动之中。社区里也有人提出了不少有意思的补充视角——比如有人觉得应该明确区分"编程 Agent / Agent CLI(命令行应用)““Agent Definition(描述 Agent 行为的蓝图文件,类似 Java 里的 class)“和"Agent Instance(从 Definition 实例化出来的运行进程,类似 Java 里的 object)”;也有人追问:那 MCP 又该摆在这整套体系的哪个位置?对此一个挺到位的回答是:MCP 本质上是一套标准化协议,它让 Tool Use 到 Harness 之间的连接变得更干净、更具互操作性——这篇术语表讲的是 Agent 们"做什么”,而 MCP 是一份规范,讲的是它们如何跨不同厂商和实现、可靠地把工具调用这件事"做好”。
说到底,术语这东西,越精确、越有明确的技术指向,就越好用。
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)