
Java开发必知必会的MySQL核心知识点(一)-基础入门:从零开始认识数据库核心
从事研发这些年,我面试过上百位 Java 开发。有一个问题我几乎每次都问:"能讲讲 MySQL 的索引原理吗?"能答到 B+Tree 的不到一半,能讲清楚回表和覆盖索引的不到一成。
大多数的Java开发工作者,都把 MySQL 当成"会用就行"的工具,从没系统化地学习过它背后的原理。而实际上,索引、事务、锁、MVCC 这些知识,才是区分一个"能写代码的程序员"和"能解决问题的工程师"的关键。
本系列教程是我结合多年一线开发经验,专为 Java 开发人员梳理的 MySQL 知识体系。从架构到底层,从原理到面试,即使你现在对数据库的认识仅限于
SELECT * FROM,我也能带你一步一步,从入门到精通。
先看知识图谱:Java 开发者必知必会的 MySQL 核心知识点
正式出发前,先快速浏览一下我们要征服的全貌。受文章篇幅限制,我将这份MySQL学习文档,分为5篇文章。这张图你可以在学习过程中随时回来对照:
Java 开发者 MySQL 知识体系
├── 🟢 基础入门(本篇)
│ ├── MySQL 架构(Server 层 + 引擎层)
│ ├── SQL 执行流程(一条 SELECT 经历了什么)
│ └── 存储引擎对比(InnoDB vs MyISAM)
│
├── 🔵 核心进阶(第2篇)
│ ├── 索引原理(B+Tree、聚簇、覆盖、最左前缀)
│ ├── SQL 优化(EXPLAIN、分页、JOIN、排序)
│ └── 索引设计最佳实践
│
├── 🟡 深入理解(第3篇)
│ ├── 事务(ACID、隔离级别)
│ ├── 锁(行锁、间隙锁、临键锁、死锁)
│ └── MVCC(多版本并发控制)
│
├── 🟣 高级架构(第4篇)
│ ├── 日志系统(redo log、binlog、undo log)
│ ├── 主从复制与读写分离
│ └── 分库分表(ShardingSphere)
│
└── 🔴 实战面试(第5篇)
├── MyBatis-Plus 最佳实践
├── 连接池配置与慢 SQL 排查
├── 阿里开发规范
└── 12 道高频面试题精讲
阅读建议:如果你是完全的数据库小白,按顺序阅读效果最好。如果你已经有基础,可以跳到任何你感兴趣的一篇。
一、MySQL 架构概述
1.1 我们写的 SQL 去哪了?
作为 Java 开发,你大概率写过这样的代码:
List<UserPO> users = userDao.selectList(wrapper);MyBatis / MyBatis-Plus 底层帮我们发出了 SELECT * FROM user WHERE ...,这条 SQL 到达 MySQL 之后,经历了什么呢?让我们从 MySQL 的整体架构开始理解。
1.2 MySQL 整体架构图
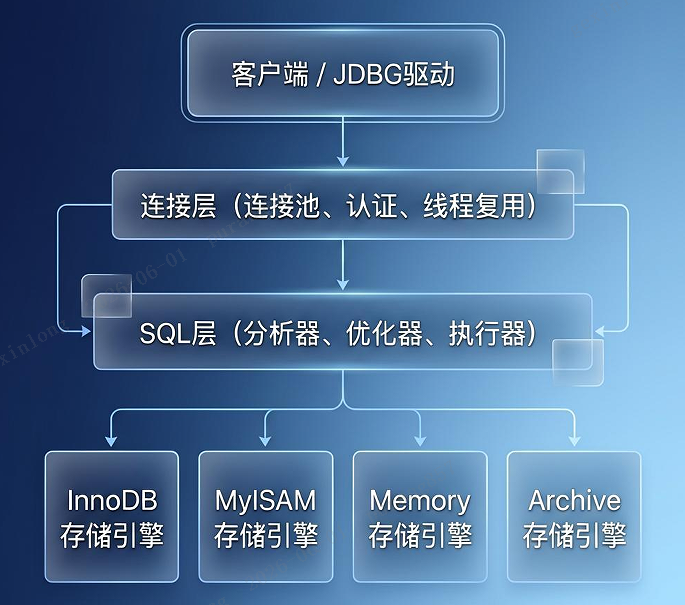
MySQL 采用分层架构,核心分两层:
- Server 层:负责连接管理、SQL 解析、查询优化等,不依赖具体引擎。简单说就是"脑子"。
- 存储引擎层:负责数据的实际存储和读取,采用插件式架构(像可插拔的 U 盘)。InnoDB 是目前的默认引擎,也是我们重点讨论的对象。
类比:把 MySQL 想象成一个餐厅——Server 层是大堂经理(接待客人、理解需求、规划上菜顺序),存储引擎是后厨(真正烹饪食物)。大堂经理不管后厨用什么锅,只负责把顾客的订单翻译成后厨能理解的指令。
1.3 一条 SELECT 语句的执行流程
SELECT * FROM user WHERE id = 1;这条简单语句在 MySQL 内部的完整旅程:
你的 Java 程序 ↓ JDBC 驱动发送 SQL 连接器 —— 建立连接、验证用户名密码、检查权限 ↓ 分析器 —— 词法分析(识别 SELECT、FROM 等关键字) → 语法分析(检查 SQL 语法是否正确) ↓ 优化器 —— 选择用哪个索引、决定 JOIN 顺序 → 生成执行计划(Explain 看到的就是这步的结果) ↓ 执行器 —— 调用存储引擎接口,逐行读取数据 ↓ 返回结果给客户端
面试小贴士:MySQL 8.0 移除了查询缓存。原因是——一旦表有写操作,缓存就失效了,高并发写入场景下维护缓存的成本反而比直接查还要大。这是个典型的"好心办坏事"的设计。
1.4 一条 UPDATE 语句的完整旅程
现在我们把难度提高一点。查询只读不写,那更新语句呢?
UPDATE user SET name = '张三' WHERE id = 1;这条语句的执行过程涉及到一个非常重要的机制——日志。你现在不需要完全理解每个日志的作用(第4篇会详细讲),这里先有个印象:
执行器找到 id=1 的行 ↓ InnoDB 将数据页加载到 Buffer Pool(内存缓冲区) ↓ 写入 undo log(记录旧值"李四",用于回滚) ↓ 修改 Buffer Pool 中的数据页(name 改成"张三") ↓ 写入 redo log buffer(记录"某数据页的 name 被改成张三") ↓ 写入 binlog(Server 层记录:user 表 id=1 的 name 从"李四"变成"张三") ↓ 事务提交完成
Buffer Pool 是 InnoDB 的内存缓存区,相当于 Redis 之于数据库的作用——数据先从磁盘读到内存,修改也在内存中完成,后台再慢慢刷回磁盘。这就是数据库能支撑高并发的关键设计之一。
了解了 SQL 在 MySQL 内部的执行过程,接下来我们看看"后厨"——不同的存储引擎有什么不同。这直接影响到你的表能做什么、不能做什么。
二、存储引擎对比:InnoDB vs MyISAM
2.1 为什么要关心存储引擎?
在建表时,你可能经常见到这样的语句:
CREATE TABLE user (
id BIGINT PRIMARY KEY,
name VARCHAR(50)
) ENGINE = InnoDB;ENGINE = InnoDB 就是指定存储引擎。MySQL 支持多种存储引擎,但 Java 开发 99.9% 的情况下都在和 InnoDB 打交道。为什么?看下面的对比就清楚了。
2.2 核心差异一览
| 特性 | InnoDB | MyISAM |
|---|---|---|
| 事务支持 | ✅ 支持 ACID | ❌ 不支持 |
| 行级锁 | ✅ 基于索引的行锁 | ❌ 只有表级锁 |
| 外键 | ✅ 支持 | ❌ 不支持 |
| 崩溃恢复 | ✅ redo log 保证 | ❌ 数据可能丢失 |
| MVCC(多版本) | ✅ 支持 | ❌ 不支持 |
| 全文索引 | MySQL 5.6+ 支持 | ✅ 原生支持 |
| 聚簇索引 | ✅ 数据按主键物理排序 | ❌ 数据和索引分开存储 |
| COUNT(*) 效率 | 需要扫描索引 | 直接读表元数据,极快 |
2.3 为什么生产环境一律用 InnoDB?
这是面试中的送分题。三个核心原因:
- 事务安全是第一需求:涉及订单、支付等关键业务场景,没有事务的数据操作就像没有安全带的高速赛车——出事就是大事。
- 并发性能:行级锁意味着不同用户可以同时修改不同的行,互不干扰。MyISAM 的表级锁则是一人改表、全员排队。
- 崩溃恢复:服务器突然断电?InnoDB 靠 redo log 能把已提交的数据找回来,MyISAM 只能祈祷。
一句话总结:MyISAM 适合的场景极其有限(只读日志表、数据仓库类场景),面向 Java 业务开发,选 InnoDB 就对了。
2.4 回顾与下一步
学完本篇,你应该能回答这些问题:
- MySQL 分几层架构?Server 层和引擎层分别负责什么?
- 一条 SELECT / UPDATE 在 MySQL 内部经历了哪些步骤?
- InnoDB 比 MyISAM 强在哪里?为什么它是默认选择?
- Buffer Pool 是做什么的?
如果你能流畅地回答出来,恭喜你,MySQL 的"骨架"你已经搭好了。
下一篇,我们将进入 MySQL 最核心、也是面试最爱问的领域——索引。你会学到为什么几千万的数据也能秒查、CREATE INDEX 的背后发生了什么、以及怎么写出"快速"的 SQL。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)