
Java面试经验累积
一、Java语言
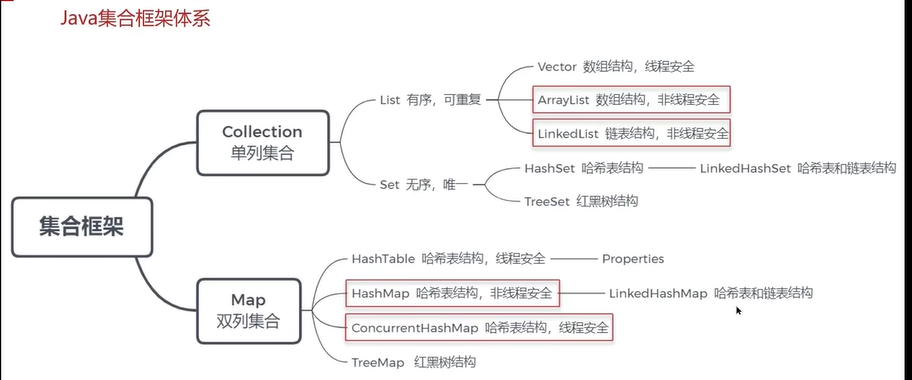
标红的内容是面试常问的。
1.1 ArrayList
1.查询、插入和删除时间复杂度
ArrayList底层是数组。根据索引查询元素的时间复杂度为o(1),未知索引根据值查询的时间复杂度为o(n)。插入和删除元素的时间复杂度为o(n)。
2.关键源码分析

补充:在 Java 中,transient 是一个变量修饰符,标记某个字段不参与序列化过程。当对象被序列化(比如写入文件或通过网络传输)时,被 transient 修饰的字段会被 跳过,不会保存其值;在反序列化时,该字段会被赋予其类型的默认值(例如 int 为 0,Object 为 null)

上图中的构造方法的参数是Collection对象,将其转换为数组,然后将数组的地址赋给elementData。
添加数据的源码: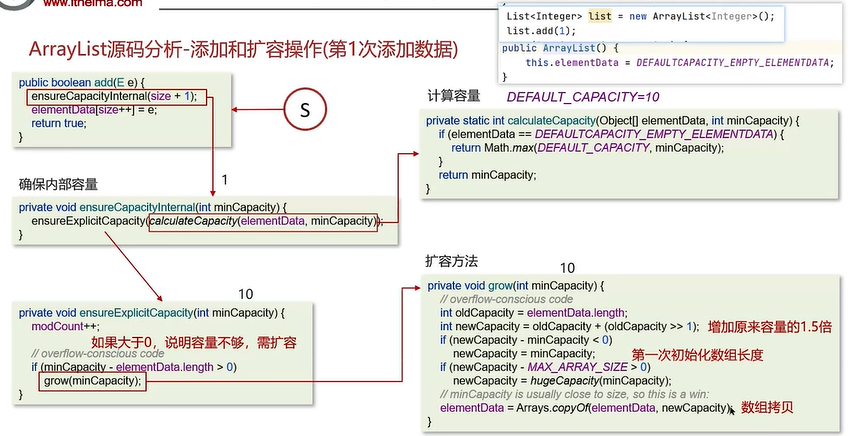
注意:ArrayList中的size属性作用是一个计数器(默认值为0), 在每次集合内容发生变化时(增、删、清空、批量操作)被重新赋值,它是一个实时维护的“元素计数器”,与底层数组容量无关。底层数组容量elementData的长度为elementData.length。
Q1:ArrayList底层的实现原理是什么?

Q1补充:ArrayList list = new ArrayList(10)中的list扩容了几次?

从一个带有整型参数的构造方法的源码可以看出,在初始化时直接new了一个大小为10的数组,没有扩容。
Q2:如何实现数组和List之间的转换?

Q2补充:用Arrays.asList转List后,如果修改了数组内容,list受影响吗?
答案是受影响。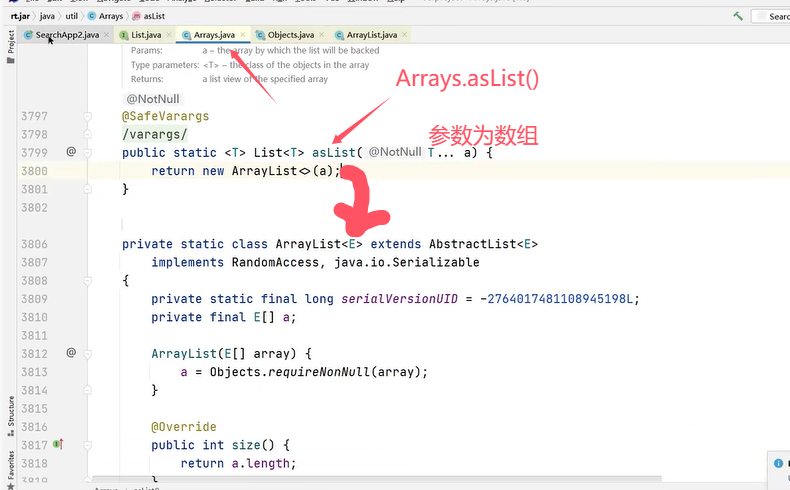
没有新建List,只是涉及对象的引用,并没有创建新的对象,指向的是同一个地址。
注意:可以看到Arrays类中有一个静态内部类ArrayList(包路径为java.util.Arrays.ArrayList),与java.util.ArrayList包路径中的ArrayList是是两个完全不同的类。
它们主要的区别如下:
性能优势:
如果只是把数组当作 List 来遍历或读取,Arrays.asList() 不需要复制数据,内存和时间开销都极小。
例子:
String[] arr = {"A", "B", "C"};
List<String> list = Arrays.asList(arr);
// ✅ 可以读取
System.out.println(list.get(0)); // A
// ✅ 可以修改已有元素(会影响原数组)
list.set(1, "X");
System.out.println(arr[1]); // X
// ❌ 不能改变长度
list.add("D"); // 抛出 UnsupportedOperationException
list.remove(0); // 抛出 UnsupportedOperationException
List用toArray转数组后,如果修改了List内容,数组受影响吗?
答案是不受影响。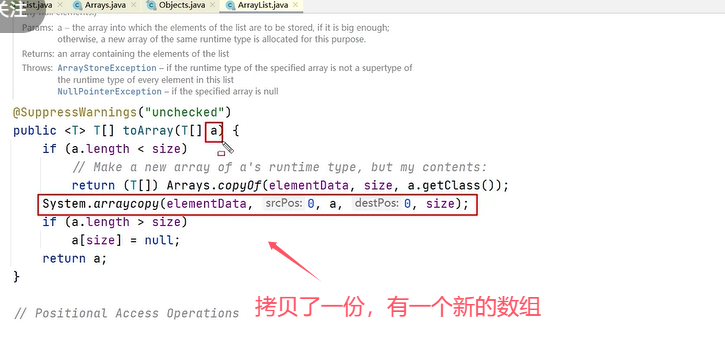

补充:LinkedList
LinkedList的底层实现是链表。
单向链表的查询、插入和删除的时间复杂度:
(1)查询头结点的时间复杂度为o(1),查询其他节点的时间复杂度为o(n)。
(2)添加和删除头结点为o(1),添加和删除其他节点的时间复杂度是o(n)。
双向链表的查询、插入和删除的时间复杂度:
(1)查询头、尾结点的时间复杂度为o(1),查询节点的平均时间复杂度为o(n)。查询给定节点的前驱结点的时间复杂度为o(1)。
(2)添加和删除头结点为o(1),添加和删除其他节点的时间复杂度是o(n)。给定节点增删的时间复杂度为o(1)。
LinkedList底层是双向链表,不能通过下标查询。
Q3:ArrayList和LinkedList的区别?
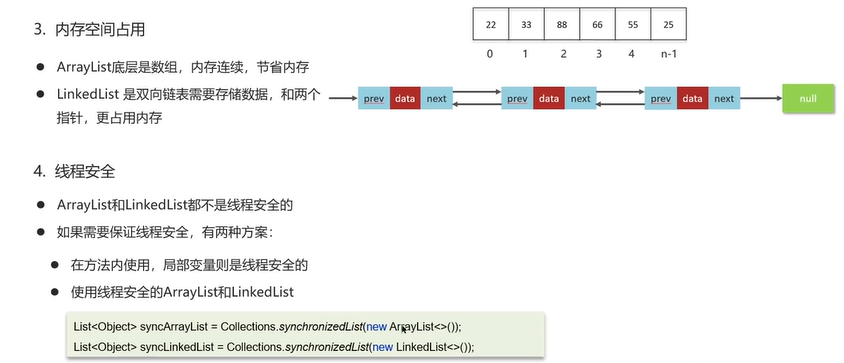
从四个方面回答,底层数据结构、操作数据的效率、内存空间占用、线程安全。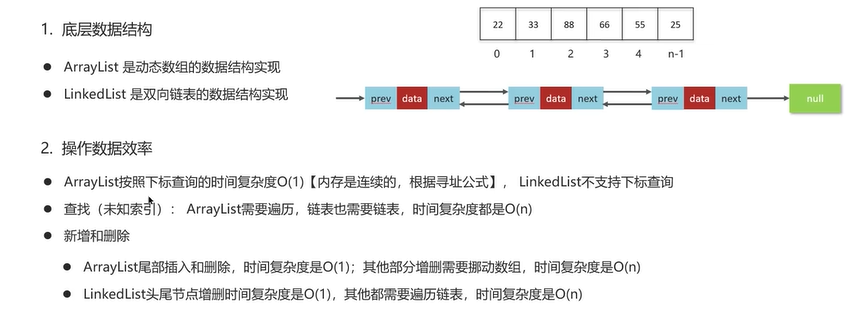
1.2 HashMap
红黑树
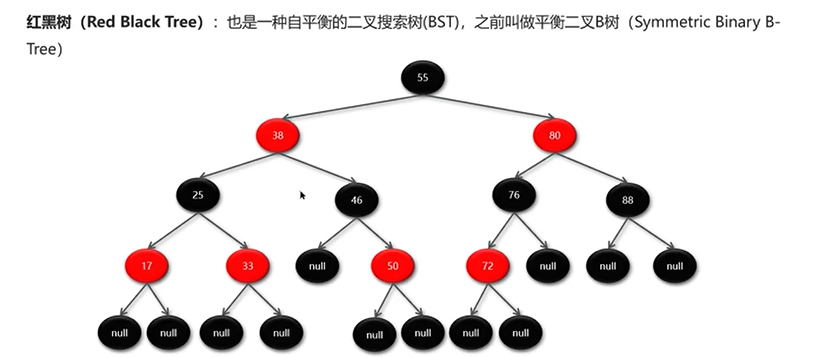
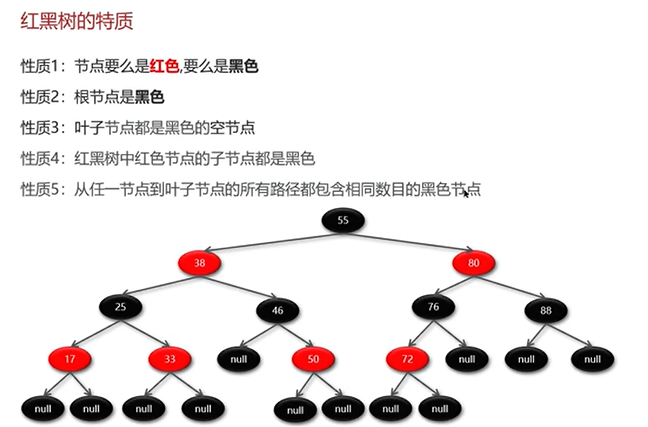
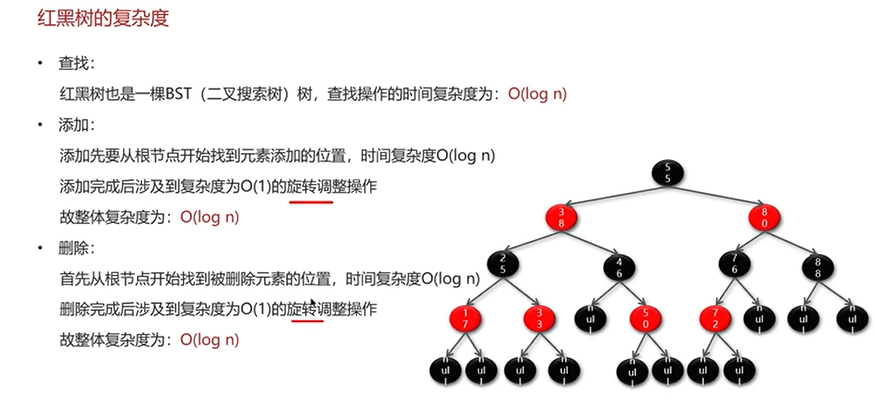
红黑树就是一种保证平衡的二叉搜索树,所有的红黑规则都是希望红黑树能够保证平衡。
普通的二叉搜索树不能保持平衡,,可能会影响查找效率,例如
Q1: HashMap底层原理

核心组件:
Node<K,V>[] table:哈希桶数组,每个元素是一个链表或红黑树的头节点
int threshold:扩容阈值(capacity * loadFactor)
float loadFactor:负载因子,默认0.75(时间和空间的权衡)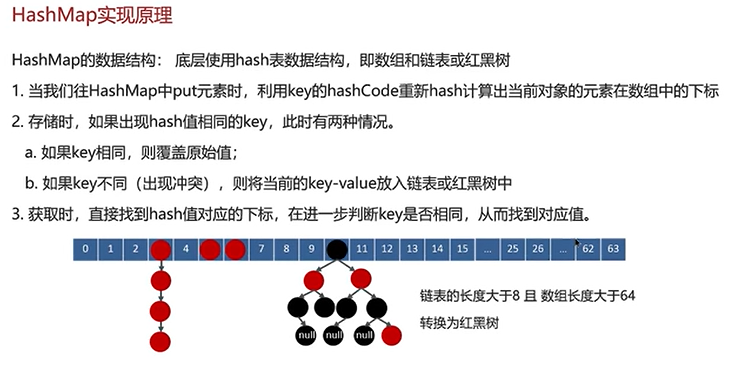
标准回答
HashMap的底层原理:
“HashMap在JDK 1.8之后,底层采用数组+链表+红黑树的数据结构。put元素时,先通过hashCode()计算哈希值,再用扰动函数(高16位异或低16位)让分布更均匀,然后通过(length-1) & hash计算数组下标。如果该位置为空,直接插入;不为空则遍历链表,存在相同key就覆盖,没有就尾插。当链表长度超过8且数组长度超过64时,链表会转为红黑树提升查询效率。当元素个数超过容量×负载因子(默认0.75)时,会2倍扩容,并重新计算每个元素的位置。”
HashSet的底层原理:
“HashSet底层就是基于HashMap实现的。往HashSet添加元素时,实际上是作为HashMap的key存储,而value是一个固定的静态对象PRESENT。利用了HashMap的key唯一性来实现Set的去重特性。”
哈希冲突的解决:
“HashMap采用链地址法解决哈希冲突。当多个key计算出同一个数组索引时,它们会以链表形式存储在同一位置。JDK 1.8之后,当链表长度超过8且数组长度超过64时,链表会转为红黑树,防止极端情况下查询性能退化到O(n)。另外,HashMap还通过扰动函数、2的幂容量、合理的负载因子等手段来减少哈希冲突的发生。”
Q2:HashMap的put方法的具体流程
先来进行源码分析。
HashMap的属性: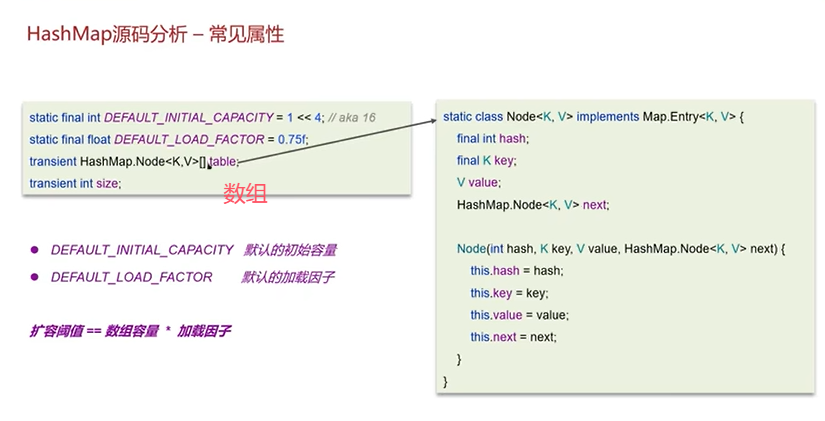
构造函数:
可以看到,只是初始化了加载因子(无参的构造函数中,设置了默认的加载因子为0.75),没有初始化数组。
Q3:讲一下HashMap的扩容原理
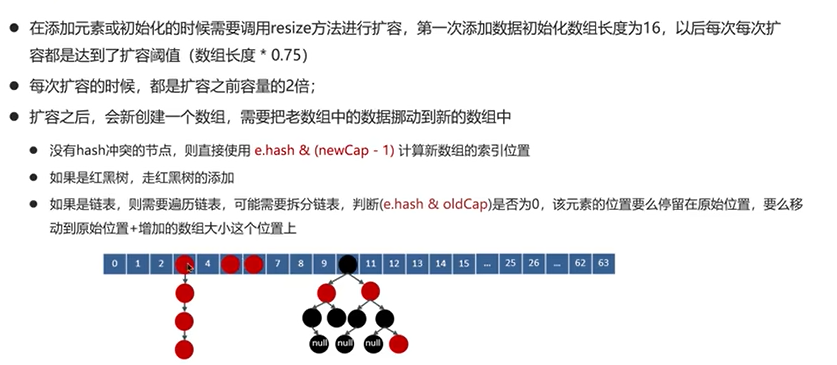
Q4:HashMap的寻址算法
问题的意思是怎么找到数组的索引。
先来看看put()方法计算元素下标方式:
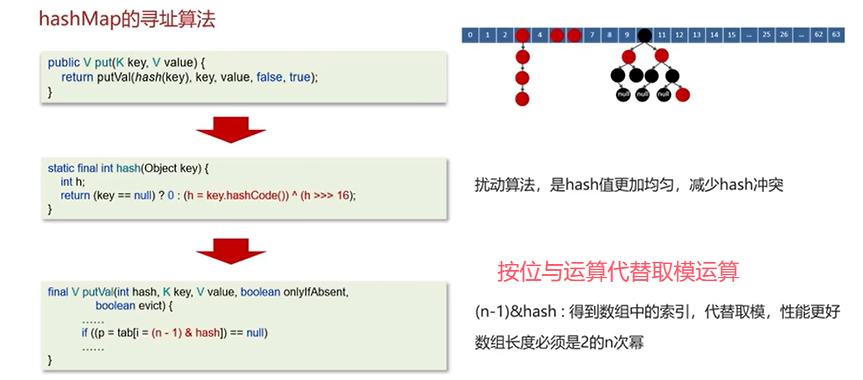

Q4补充:为何HashMap的数组长度一定是2的幂次方?

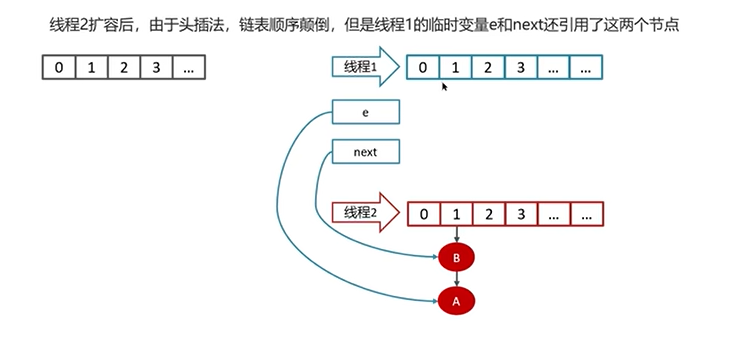
Q5:HashMap在1.7情况下的多线程死循环问题
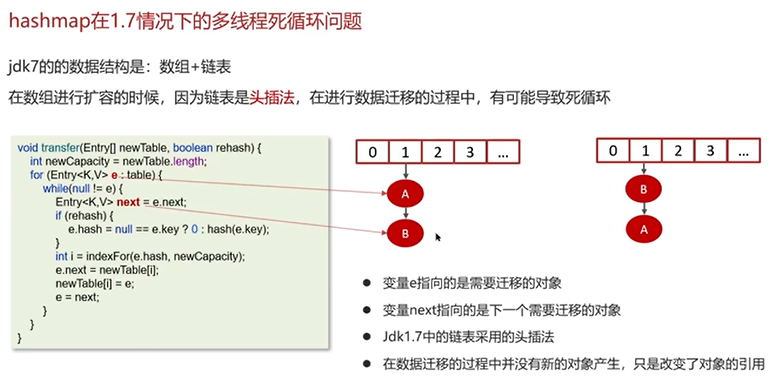
一个实例演示: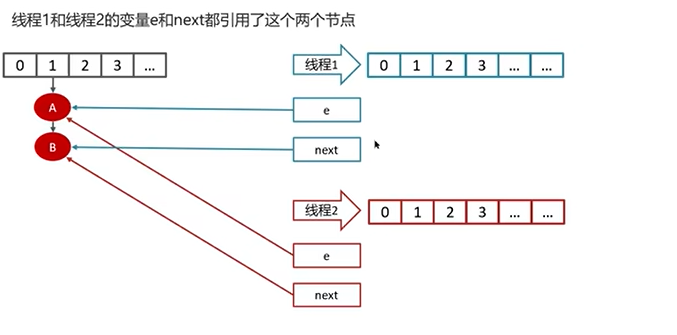
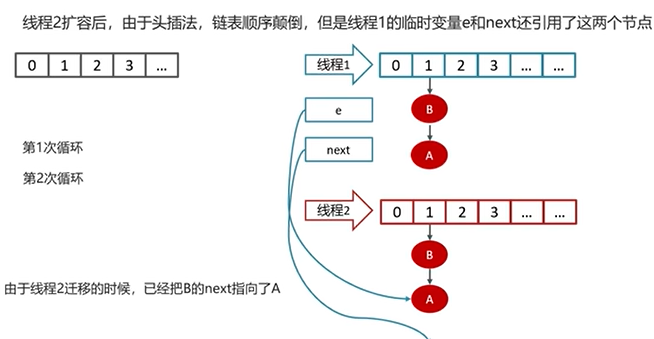
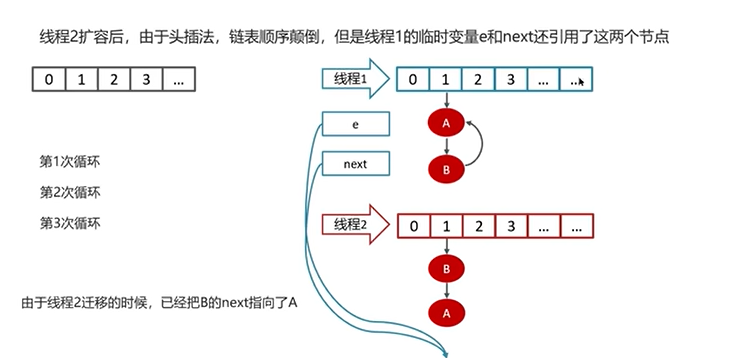

1.2.2 HashSet底层原理
核心答案:HashSet底层就是基于HashMap实现的。
// HashSet源码(简化)
public class HashSet<E> {
private transient HashMap<E, Object> map;
private static final Object PRESENT = new Object(); // 占位对象
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT) == null; // value固定为PRESENT
}
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
}
关键点:
HashSet的"元素"就是HashMap的key
HashMap的value固定为一个静态常量PRESENT(占位对象,不存储实际数据)
利用HashMap的key不重复特性,实现Set的去重功能
哈希冲突怎么解决?
① 链地址法(拉链法) —— 主要方案
数组每个位置是一个链表(或红黑树)
冲突的元素放在同一个链表中
优点:简单,适合大多数场景
缺点:链表过长时性能下降(已用红黑树优化)
② 开放地址法 —— HashMap不用
冲突后继续找下一个空位(线性探测/二次探测/双重哈希)
例子:ThreadLocalMap采用这个方式
HashMap不用原因:删除时标记复杂,不适合高并发
③ 再哈希法 —— HashMap不用
准备多个哈希函数,冲突后换一个
HashMap不用原因:计算开销大
④ 建立公共溢出区 —— HashMap不用
冲突的元素统一放另一个区域
HashMap是线程安全的吗?怎么实现线程安全?
"不是。可以用ConcurrentHashMap(推荐)、Collections.synchronizedMap()(性能较差)、或Hashtable(不推荐)。
为什么String、Integer适合作为HashMap的key?
“因为它们是不可变类,重写了hashCode()和equals()且保证一致性。自定义对象作为key时必须重写这两个方法,否则无法正确比较。”
LinkedHashMap
LinkedHashMap继承自HashMap,它在HashMap的基础上,使用双向链表维护了键值对的插入顺序或访问顺序,使得迭代顺序与插入顺序或访问顺序一致。由于它继承自HashMap,在多线程并发访问时,同样会出现与HashMap类似的线程安全问题。
二、Spring和Springboot
补充:代理对象
我们知道Spring的AOP(面向切面编程)是基于动态代理实现的,spring的动态代理包括JDK动态代理和CGLIB动态代理。Spring的AOP两种动态代理都会采用。在默认情况下,Spring AOP会智能选择:
(1)JDK动态代理。如果目标对象实现了接口,Spring默认使用 JDK动态代理。代理对象会实现目标对象的所有接口。基于 Java 原生反射机制。
(2)CGLIB动态代理。如果目标对象没有实现任何接口,Spring会使用 CGLIB动态代理。代理对象会成为目标对象的子类。基于 ASM字节码操作库,在运行时动态生成字节码。
两者的原理:
(1)JDK动态代理:核心是java.lang.reflect.Proxy类和InvocationHandler接口。你只需定义一个InvocationHandler,在其中编写“前置/后置”增强逻辑,然后用Proxy.newProxyInstance生成代理对象。当调用代理对象的方法时,所有调用都会被路由到你定义的invoke方法中,从而实现对目标方法的拦截和增强。
(2)CGLIB动态代理:核心是Enhancer类和MethodInterceptor接口。你可以通过Enhancer设置目标类为父类,并绑定一个MethodInterceptor。当调用代理对象方法时,intercept方法会被触发,你可以在这里执行增强逻辑,并通过MethodProxy调用父类(即目标类)的原始方法。
需要注意的是,如果你使用的是Spring Boot,它的自动配置会将默认的代理策略改为使用CGLIB。这意味着在Spring Boot项目中,即使目标类实现了接口,AOP代理默认也会使用CGLIB,以实现更统一的代理行为。
还要搞清楚代理对象的含义。@Aspect注解的类本身不是代理对象,而是定义代理逻辑的“切面类”。Spring在运行时动态创建出来的一个代理对象,它会把目标类“包装”起来,并在调用目标方法的前后,去执行切面类里定义的那些通知逻辑。一个实例如下。
切面类:
@Aspect
@Component
public class LogAspect {
// 这只是一个普通类,定义了“在调用前打印日志”这个规则
@Before("execution(* com.example.service.*.*(..))")
public void logBefore() {
System.out.println("记录日志...");
}
}
目标类:
@Service
public class UserService {
public void saveUser() {
System.out.println("保存用户信息");
}
}
实际运行时:
// 从Spring容器获取的是“代理对象”
UserService proxy = applicationContext.getBean(UserService.class);
proxy.saveUser();
// 此时执行顺序:
// 1. 代理对象拦截到调用
// 2. 执行 LogAspect 中的 logBefore() 方法(记录日志)
// 3. 代理对象再调用 目标对象(UserService)的 saveUser() 方法(保存用户信息)
可以通过打印类名来验证对象是否被代理:
// 在Spring容器中获取UserService
UserService service = context.getBean(UserService.class);
System.out.println(service.getClass().getName());
如果输出是 com.example.service.UserService,那它就是目标类(但通常不会是这种情况)。
如果输出是 com.sun.proxy.$Proxy 或 …EnhancerBySpringCGLIB…,那它就是代理对象。
而 LogAspect 的类名打印出来,始终是原本的 com.example.aspect.LogAspect,没有任何代理后缀。
另外,默认情况下,Spring容器中的每个Bean并不会自动拥有代理对象。只有在以下两种情况下,Spring才会为一个Bean创建代理对象。场景一:AOP切面匹配。场景二:特定注解标记(事务、缓存等)@Transactional:为方法开启事务管理。@Cacheable / @CacheEvict:提供缓存功能。@Async:让方法异步执行。
Q1: 为什么有了Spring,还要有springboot?
“这是一个很好的问题。Spring和Spring Boot不是竞争关系,而是增强关系。
Spring是一个轻量级的Java开发框架,提供了IoC、AOP、数据访问、MVC等核心能力。但在早期,使用Spring配置非常繁琐,需要写大量XML,还要手动管理依赖版本、部署WAR包到Tomcat。
Spring Boot正是为了解决这些痛点而生的。它的核心理念是‘约定大于配置’,通过自动配置和起步依赖,让开发者能快速启动和运行Spring应用。
具体区别体现在四个方面:
自动配置:根据classpath中的jar包自动注册Bean,原来几百行的XML配置现在几乎为零。
起步依赖:预置了兼容的版本集合,比如引入spring-boot-starter-web就自动带上了Tomcat、Spring MVC、Jackson等,无需担心版本冲突。
内嵌容器:不需要单独安装Tomcat,直接打包成JAR用java -jar运行,极大简化部署。
生产就绪:提供了Actuator模块,可以方便地监控健康状态、Metrics、环境信息等。
但要注意,Spring Boot并没有替代Spring,它只是在Spring之上做了一层封装。实际上,Spring Boot应用底层依然是Spring Framework的IoC容器和AOP等核心功能。
Q2: spring框架中的bean是单例的吗?spring框架中的单例bean是线程安全的吗?
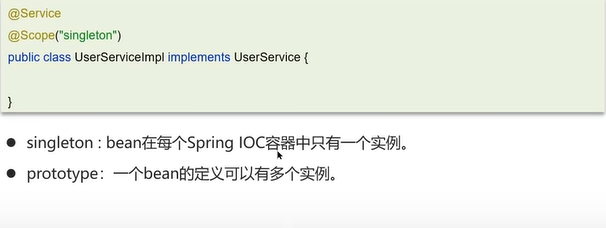
spring框架中可以通过使用@Scope注解来设置bean是否是单例的。如果不设置@Scope则默认是单例的。若是@Scope设置为prototype则这个bean是多例的。
注意:spring中的单例bean不是线程安全的。例如下面的Controller类:
当有多个请求到这个controller类时,主要的线程安全问题是这个成员变量count(方法getById()的参数id是局部变量,没有线程安全问题)。对于成员变量private UserService userService,它是一个无状态的类(比如Service类和DAO类),是否是无状态即该成员变量是否可以被修改,显然UserService不能被修改,不能被修改的类就是无状态的类,无状态的类不会有线程安全问题。所以在某种程度上,spring的单例bean是线程安全的。在平时的开发过,要尽量避免添加可修改的类。
问题答案如下:
Q3:什么是AOP,项目中有没有使用到AOP?
AOP称为面向切面编程,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。
其实,spring的事务底层实现原理就是AOP,AOP的底层用的是动态代理。
常见的AOP使用场景:
(1)记录操作日志
(2)缓存处理
(3)Spring中内置的事务处理
来说一下使用AOP来记录操作日志的思路。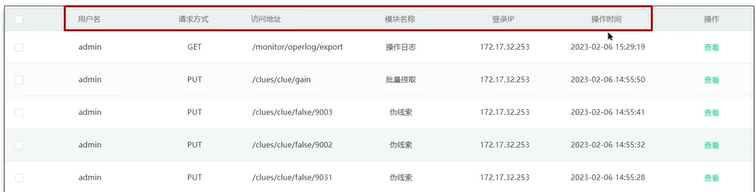
需求是将用户的访问信息(包括用户名、请求方式、访问地址、模块名称、登录IP和操作时间等)存储到数据库的日志表中。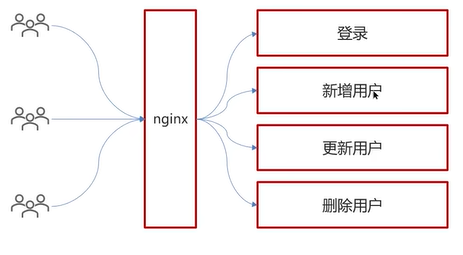
以新增用户为例,可以使用AOP的环绕通知做一个切面(这个用户是一个公共的处理,登录、新增、更新、删除做一个公共的处理)。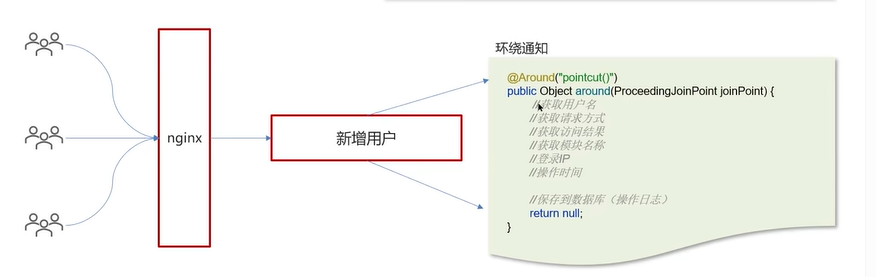
看看项目结构: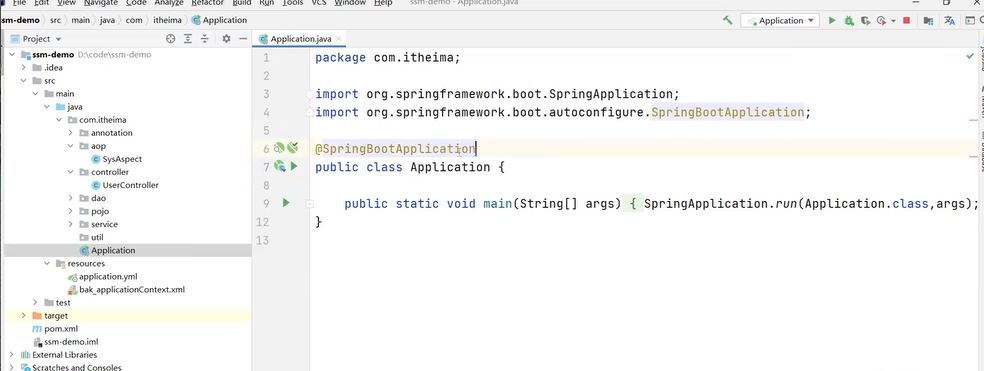
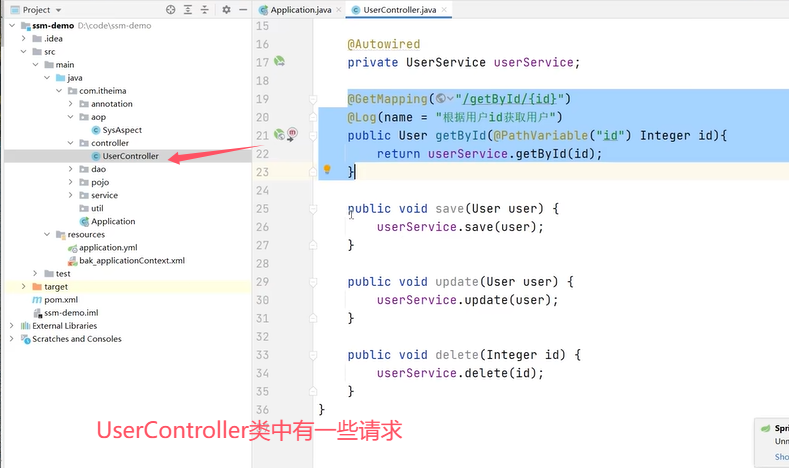
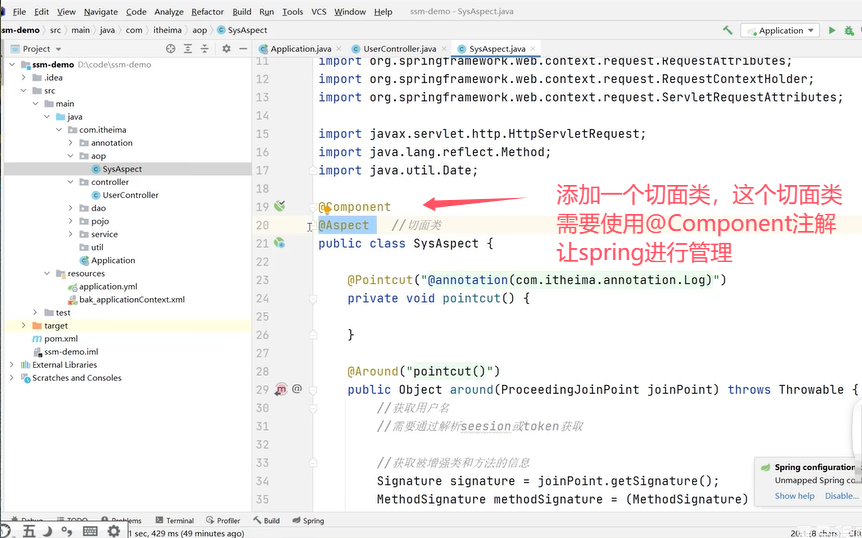
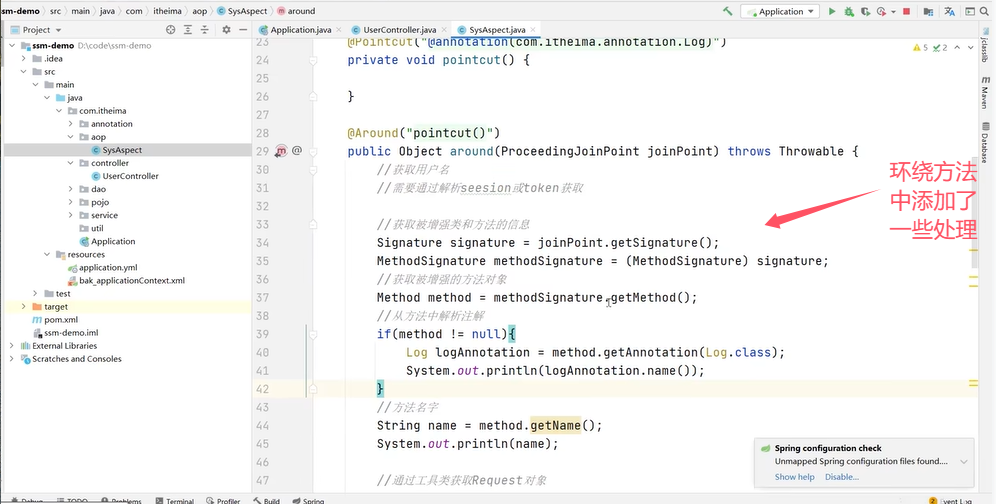
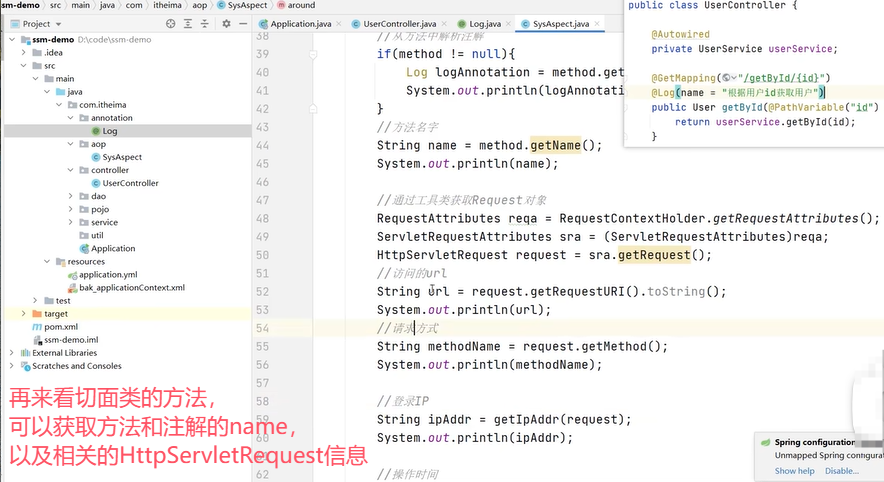
上面的环绕方法中通过ProceedingJoinPoint参数对象获取到了被增强类和方法的信息。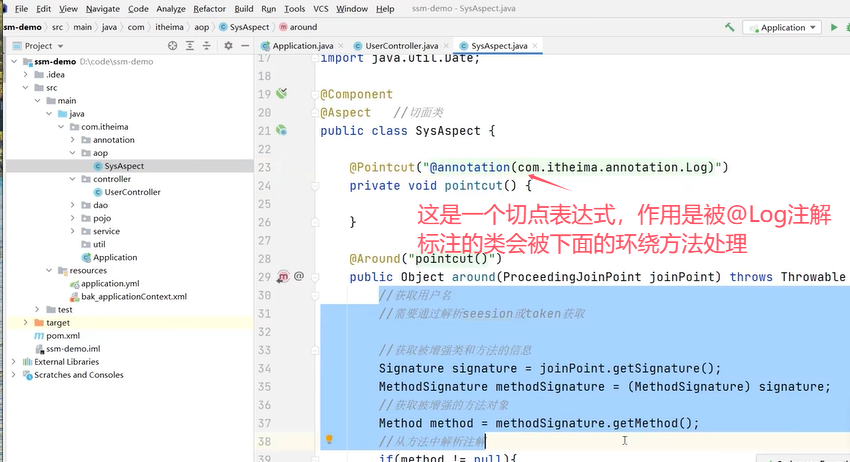
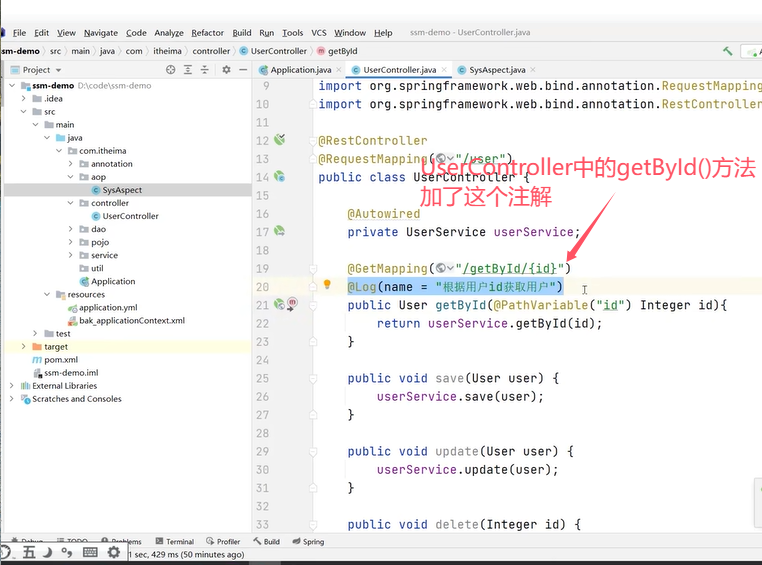
这个@Log注解是一个自定义的注解: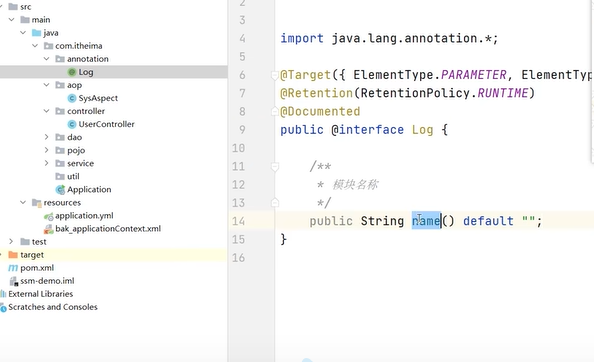
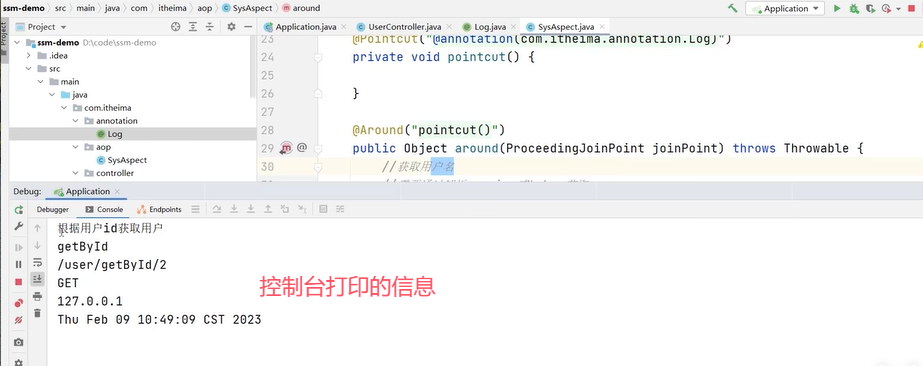
Q4:spring中的事务是如何实现的?
Spring支持编程式事务管理和声明式事务管理两种方式。一般用到的是声明式事务。
(1)编程式事务控制:需使用TransactionTemplate来进行实现,对业务代码有侵入性,项目中很少使用。
(2)声明式事务:声明式事务管理建立在AOP之上,其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
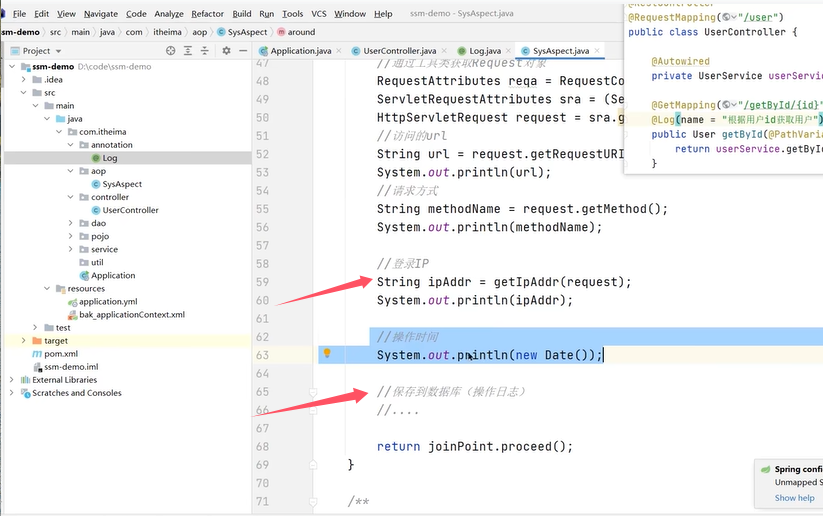
例如,对于保存用户的功能,
joinPoint.proceed()就是去执行业务的方法,即保存用户的操作。在执行业务方法之前开启事务、提交事务,在方法执行出错时回滚事务。
需要在保存用户的方法上加一个**@Transactional**注解。
Q5:spring中事务失效的场景有哪些?
3种比较常见的场景:异常捕获处理、抛出检查异常、非public方法。
1.异常捕获处理
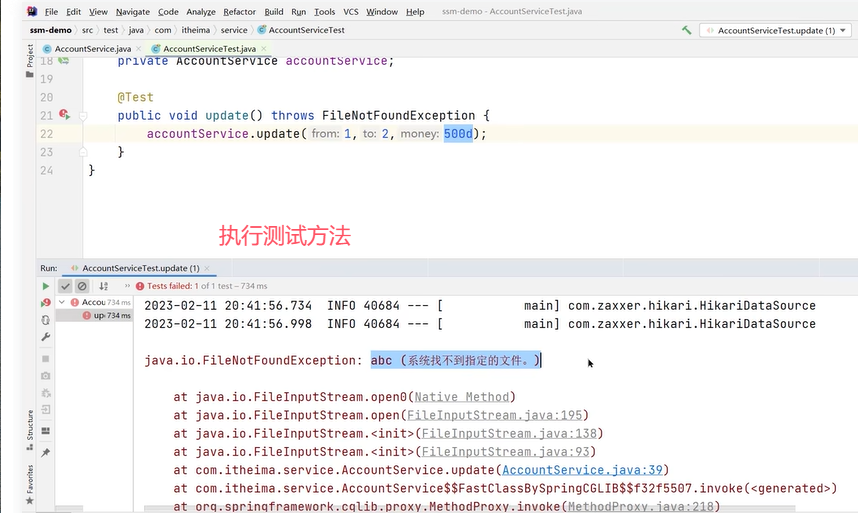
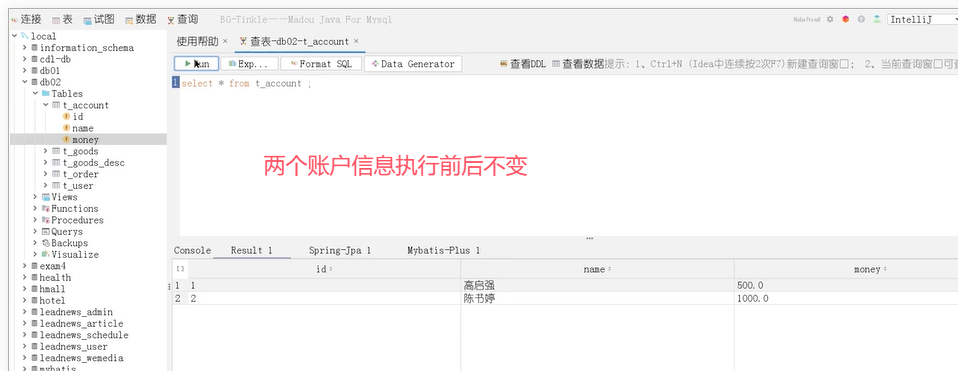
下面是一个转账的方法。Integer from是转账的账户,Integer to是被转帐的账户,Double money是转账金额。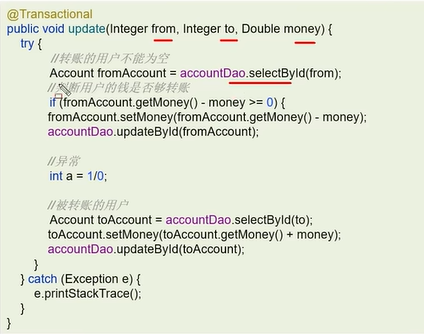
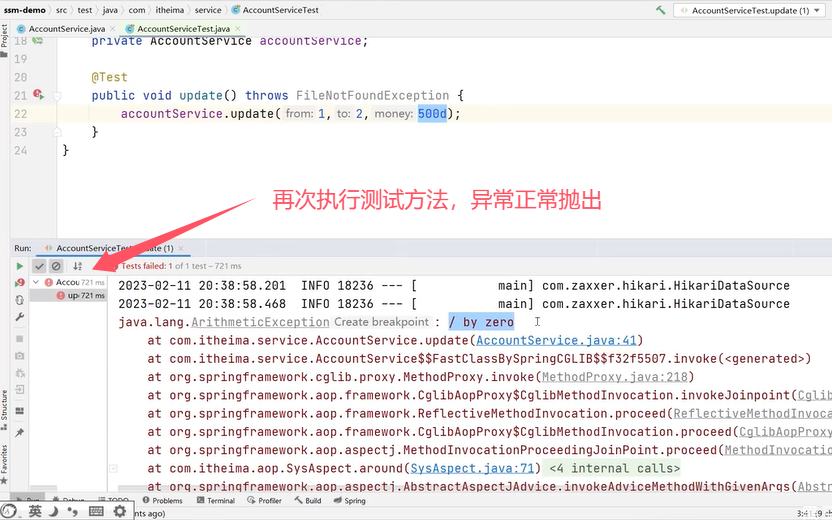
可以看到在业务逻辑中加了一个操作–除以0(int a=1/0)。加了@Transactional后该方法被事务管理,当异常抛出之后,try-catch和事务管理两者都会进行事务的回滚,异常捕获处理可能会导致事务失效。
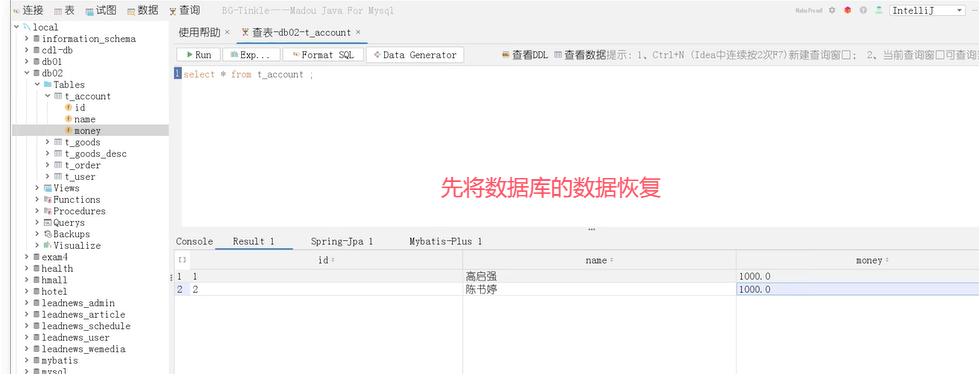
演示: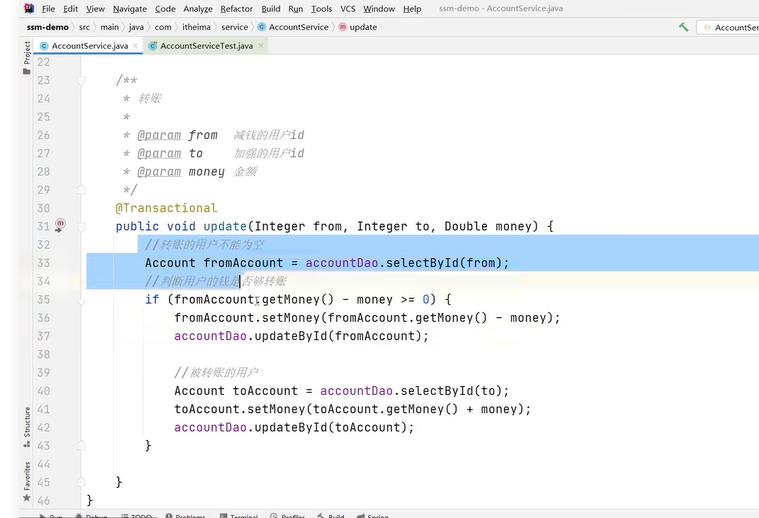
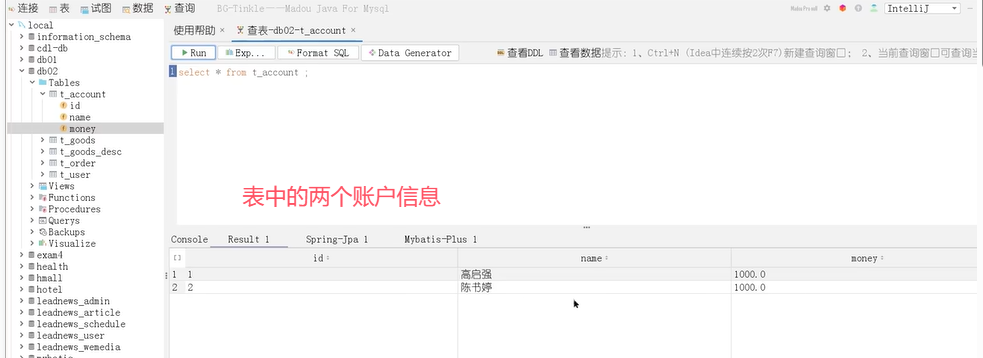
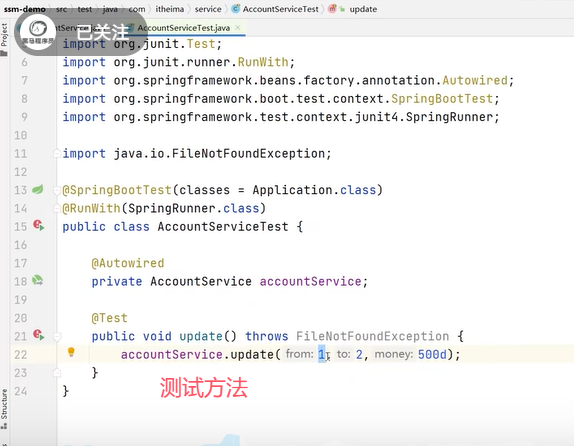
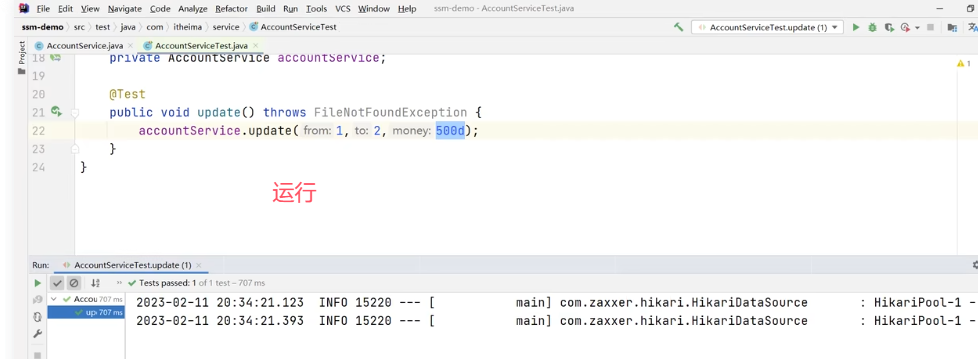
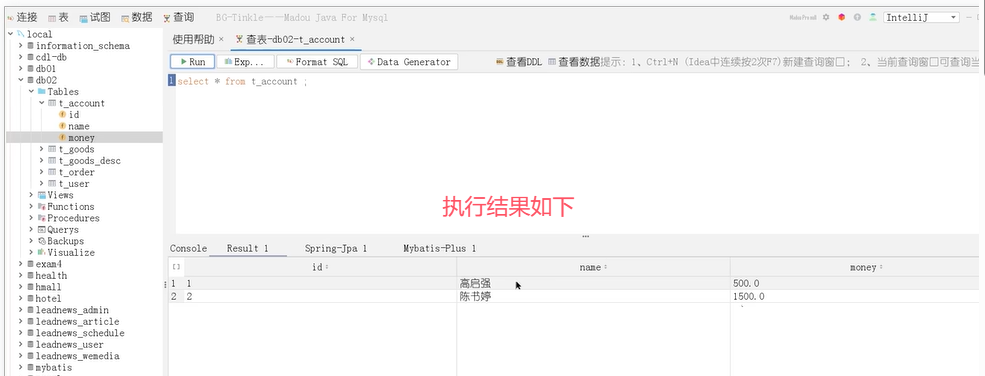
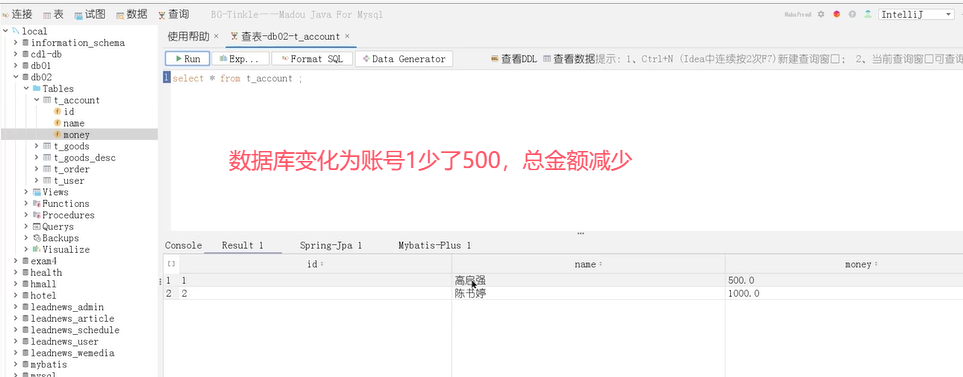
接下来添加异常操作: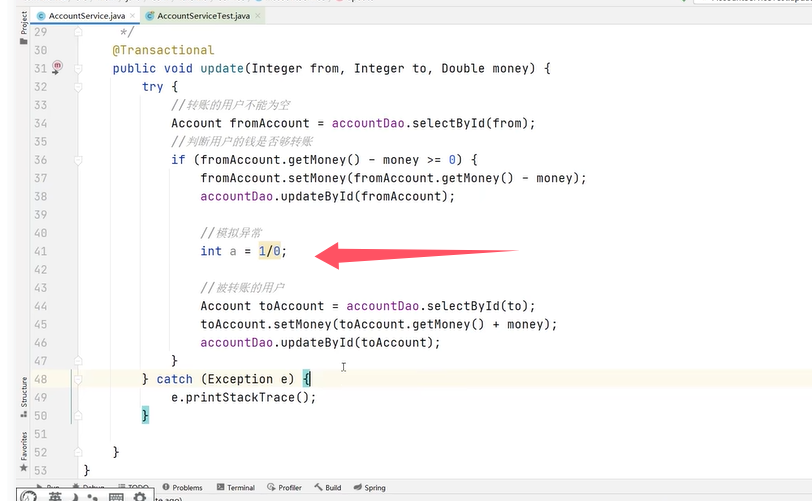
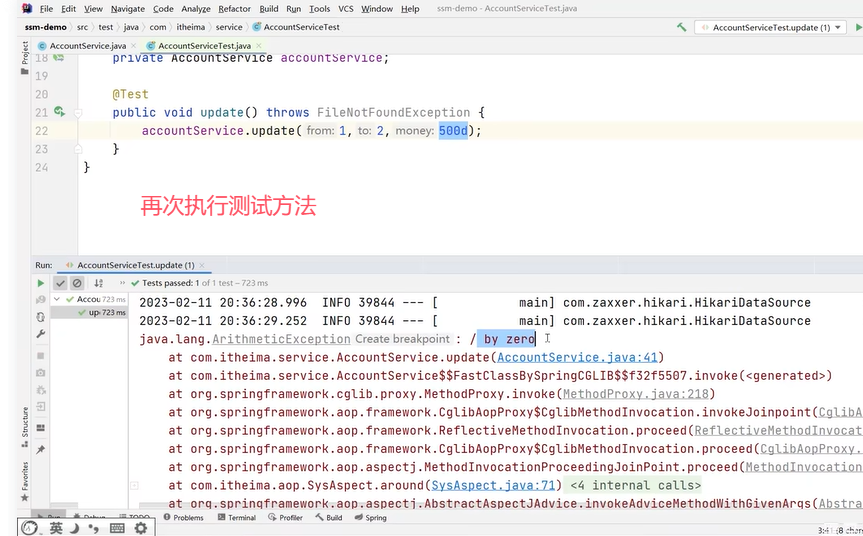
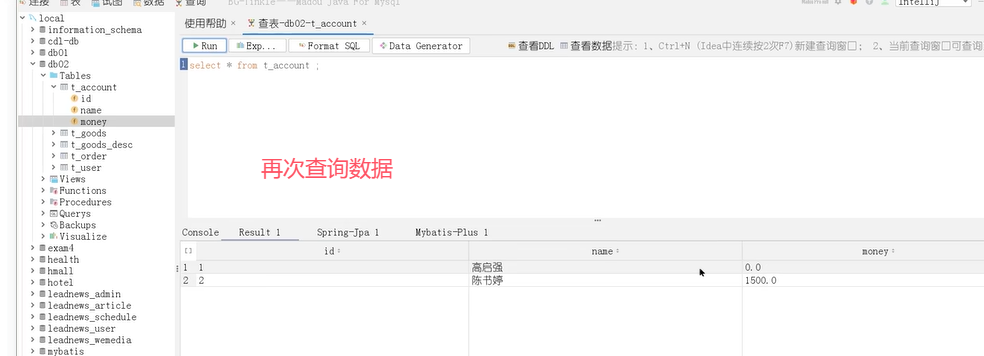
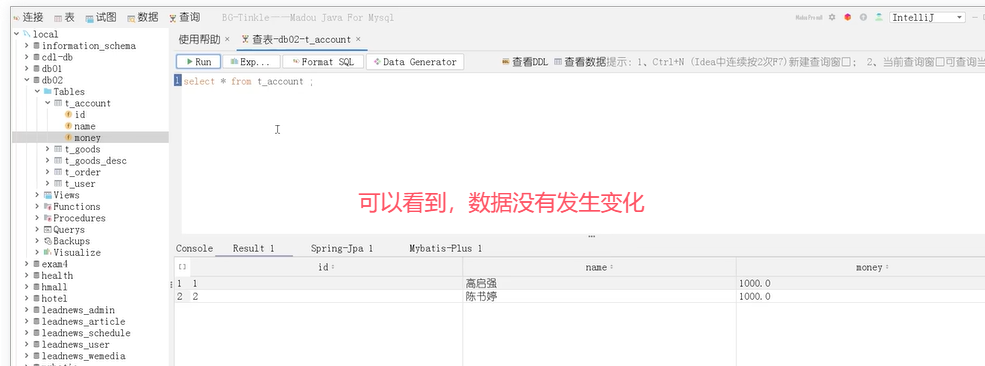
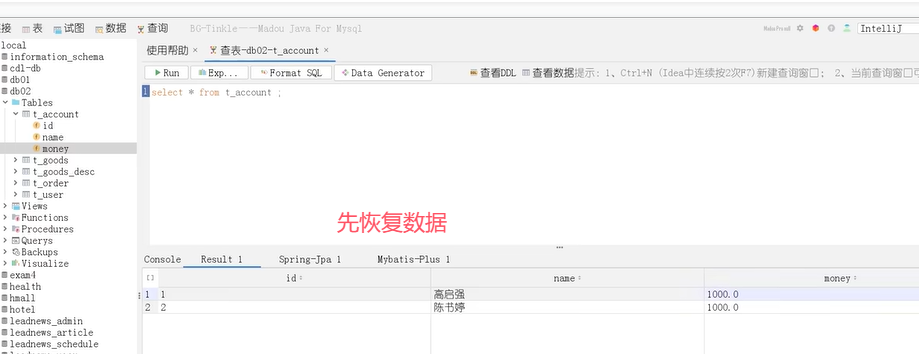
可以看到,账户1被扣了500元,总金额少了。这种情况就是导致事务失效了。
原因是事务通知只有捉到了目标抛出的异常,才能进行后续的回滚操作。如果目标自己处理掉异常,事务通知无法知悉。
解决方法是在catch快添加throw new RuntimeException(e)将异常抛出。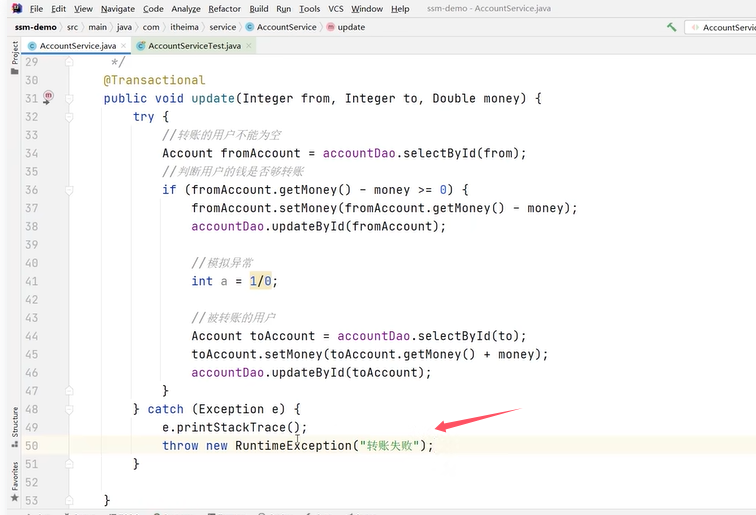
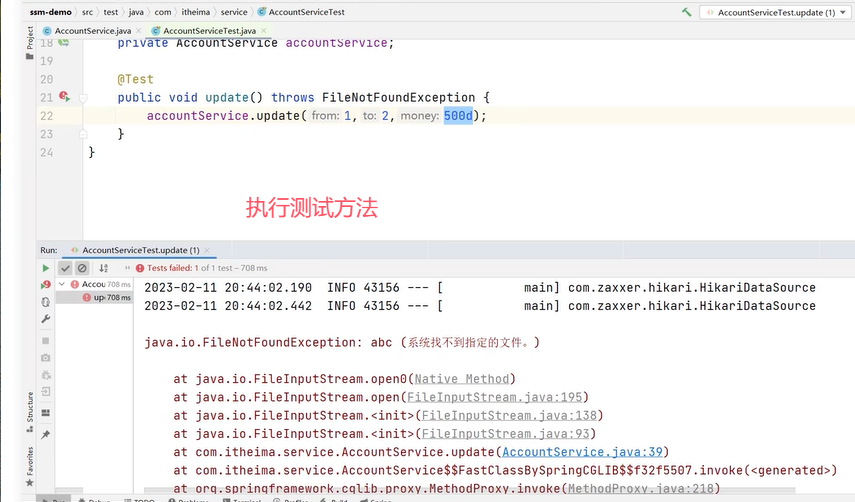
2.抛出检查异常

演示: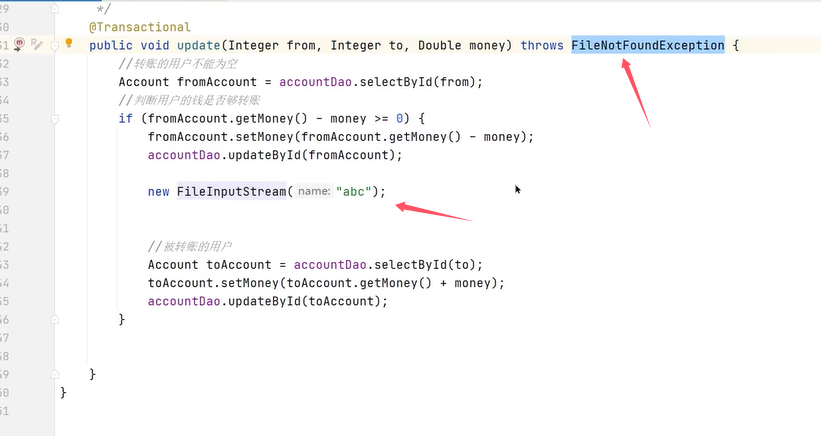
原因是spring默认只会回滚非检查异常RuntimeException(非受控异常)。
解决方式是配置rollbackFor属性
这样只要有异常就会进行回滚。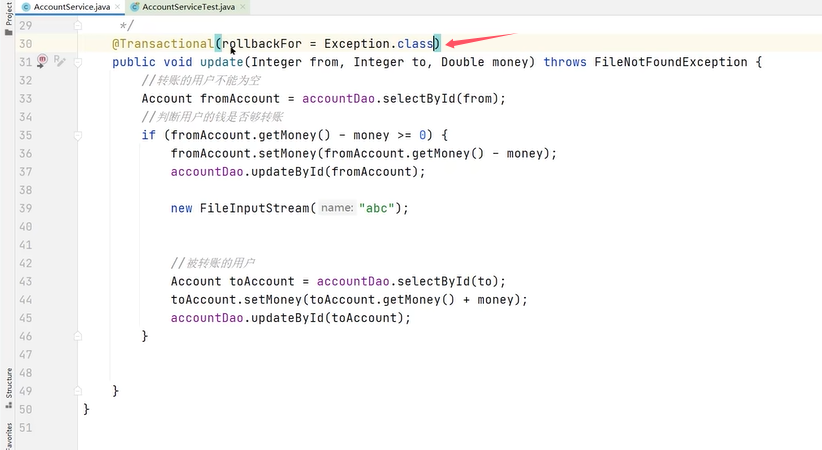
3.非public方法
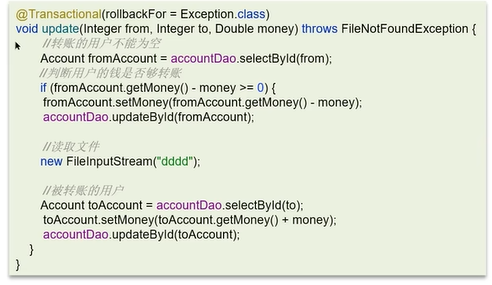
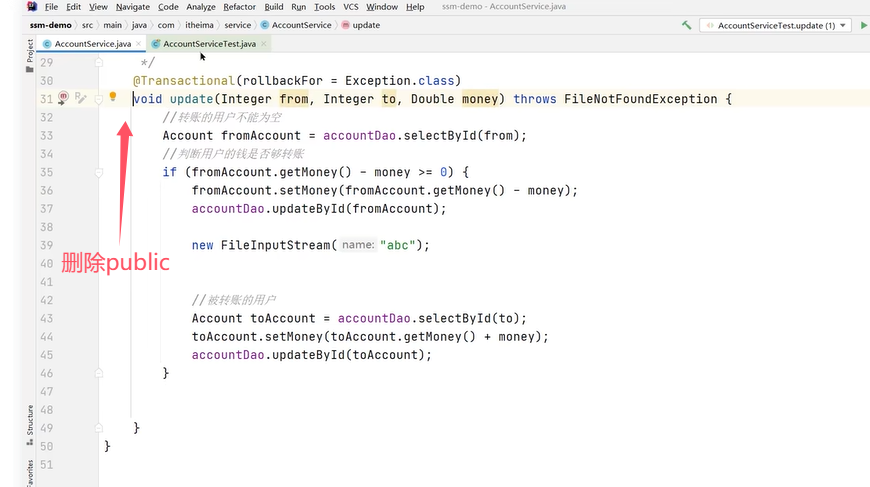
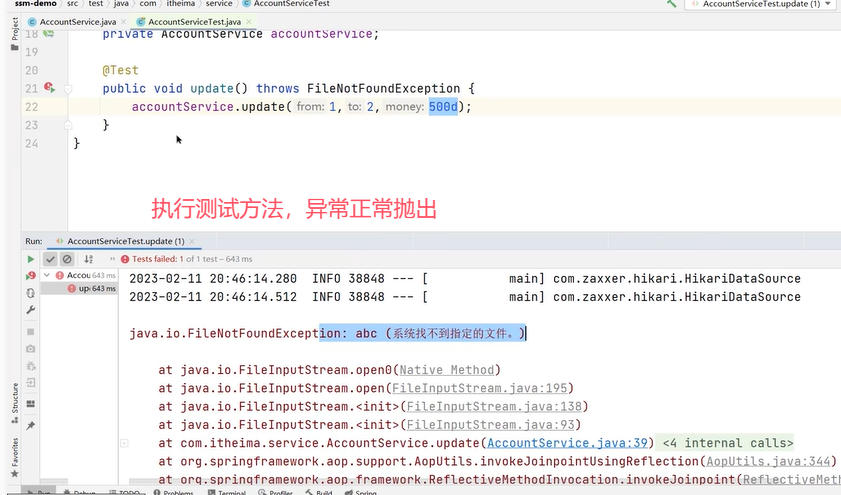
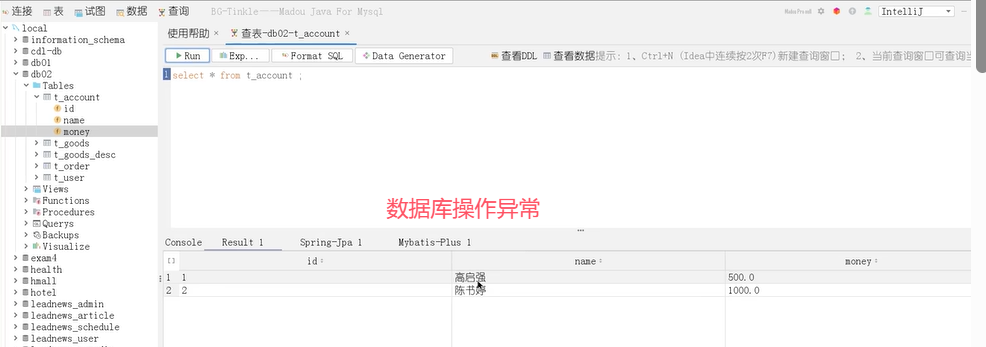
原因是spring为方法创建代理、添加事务通知,前提条件都是该方法时public的。
解决方法是把方法改为public。
Q6:spring的bean的生命周期
bean:spring容器在进行实例化时,会将xml配置的的信息封装成一个BeanDefinition对象,spring根据BeanDefinition来创建Bean对象,里面有很多的属性用来描述Bean。
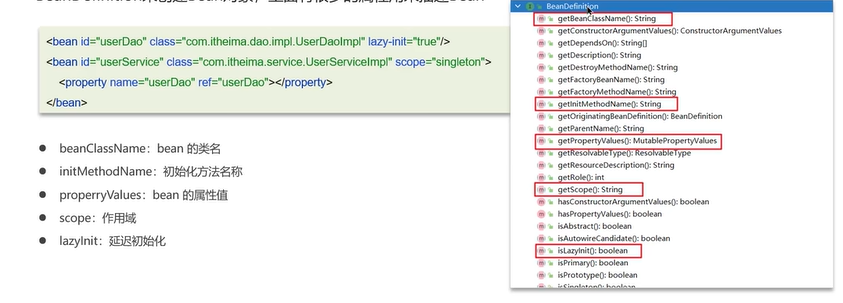
BeanDefinition中属性和方法就是在Bean的生命周期过程中使用。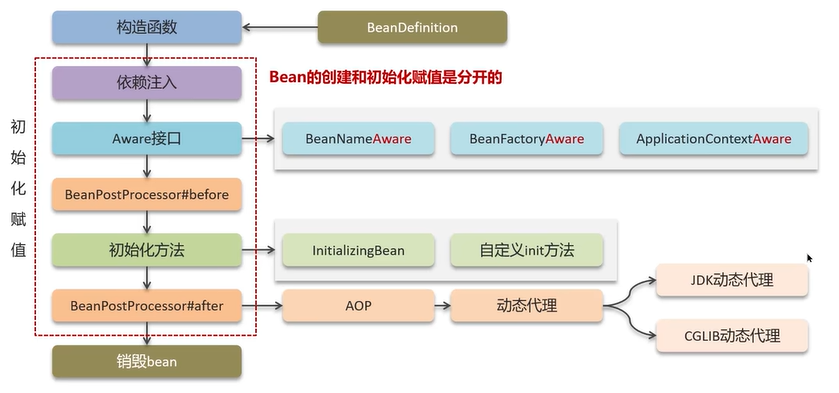
说明:
(0)构造函数是创建bean的过程,赋值操作由后面的步骤完成。
(1)依赖注入:像@AutoWired标注的属性和@Value标注的属性。
(2)Aware接口:若是Bean实现了相关接口(常见的有BeanNameAware获取bean名称、BeanFactoryAwware创建bean工厂、ApplicationContextAware容器的上下文),需要重写相关方法。
(3)BeanPostProcessor#before:是bean的后置处理器,用来增强bean的功能。在初始化方法调用之前进行回调。这个后处理器在bean的生命周期中非常重要。
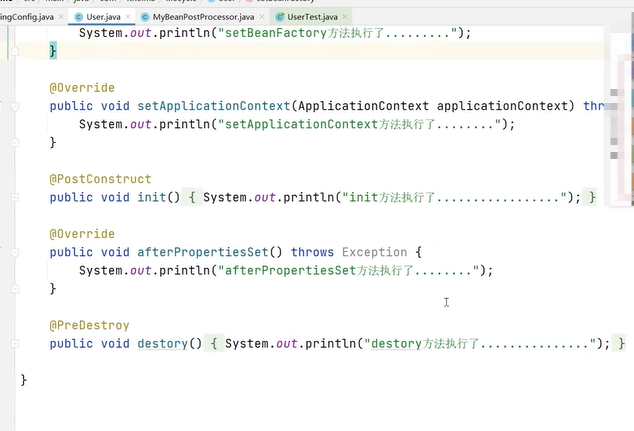
(4)InitializingBean 接口需要实现的方法是afterPropertiesSet()。 @PostConstruct 注解是自定义的init()方法。
(5)BeanPostProcessor#after:是bean的后置处理器,用来增强bean的功能。在初始化方法调用之后进行回调。
注:bean的初始化赋值按照上面的步骤一步步完成。
(6)容器关闭后需要销毁bean。
演示: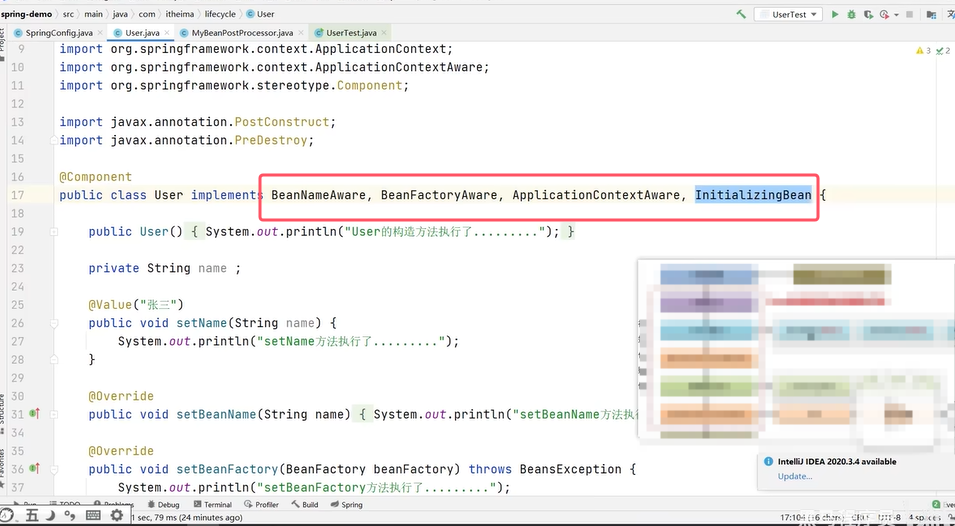
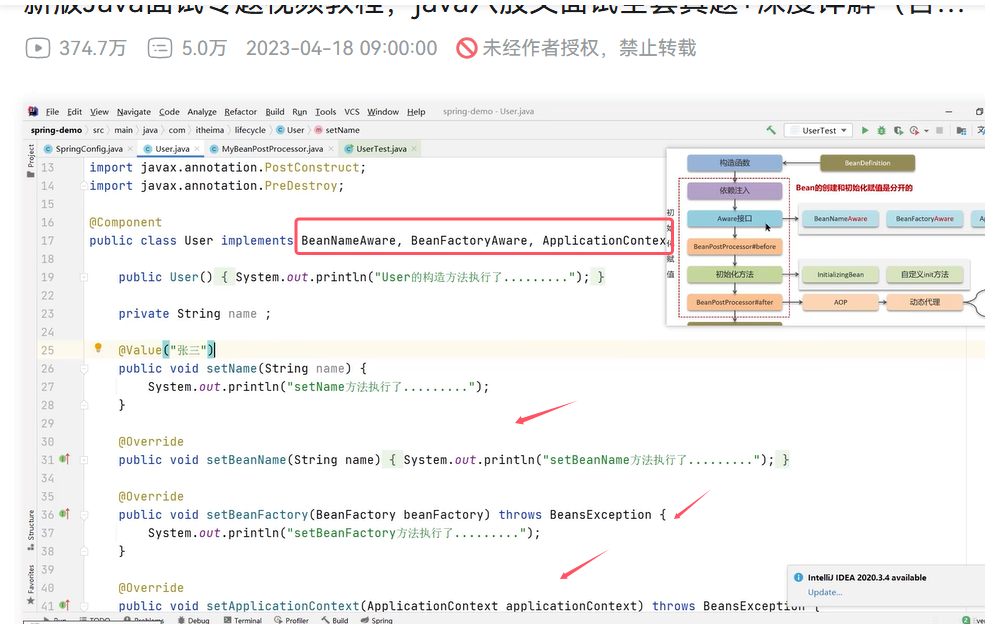
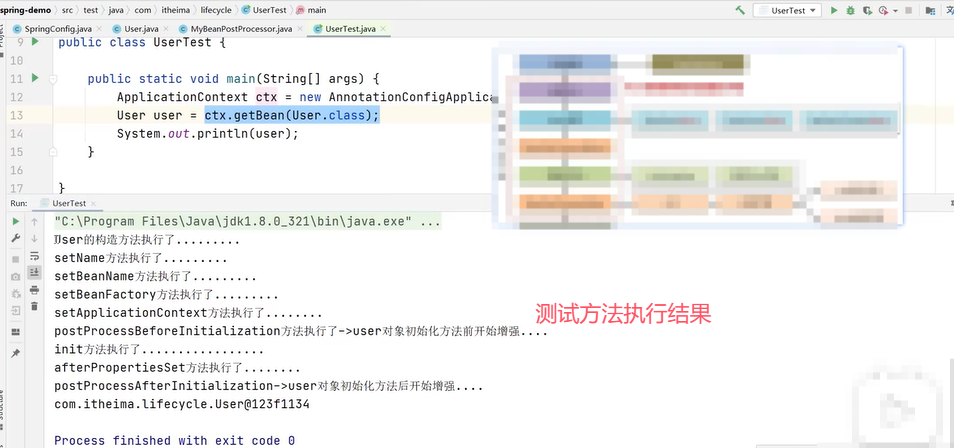
上图中的@PostConstruct注解的init()方法就是生命周期中的初始化方法阶段的自定义init方法。
User类继承了InitializingBean接口,内部重写了afterPropertiesSet()。
加了@PreDestory注解的方法在容器关闭bean销毁的时候执行。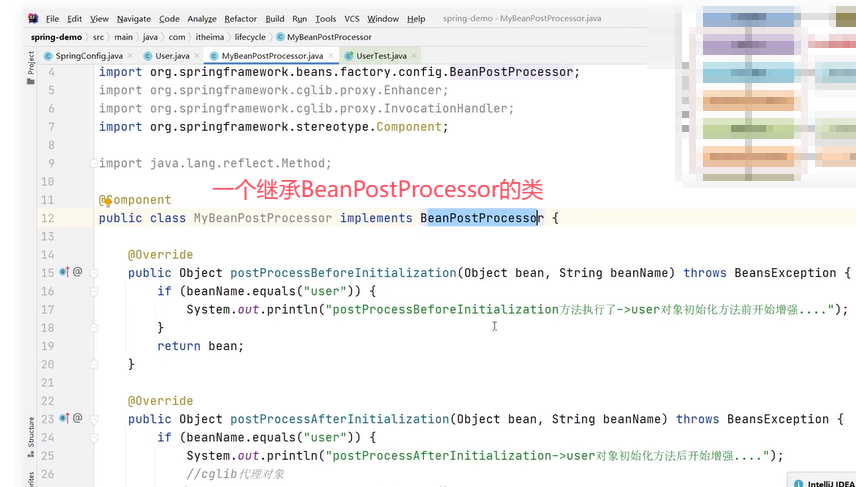
上图中MyBeanPostProcessor类中实现的postProcessBeforeInitialization()就是生命周期中的BeanPostProcessor#before,postProcessAfterInitialization()就是BeanPostProcessor#after,这两个会加到beanName=user的对象的生命周期上。
可以看到destroy方法没有被执行,bean没有被销毁。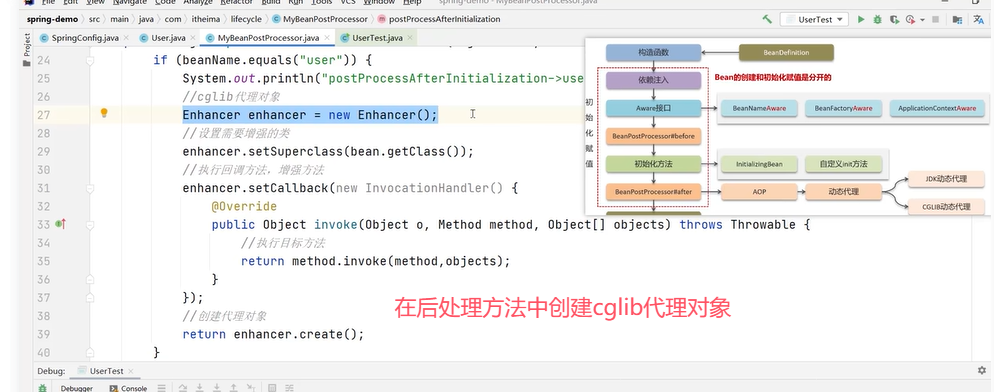
上述对象在后置处理器postProcessorAfterInitialization()中对bean进行增加,bean不再是一个原始对象,而是一个代理对象。
Q7:spring的循环依赖(循环引用)?

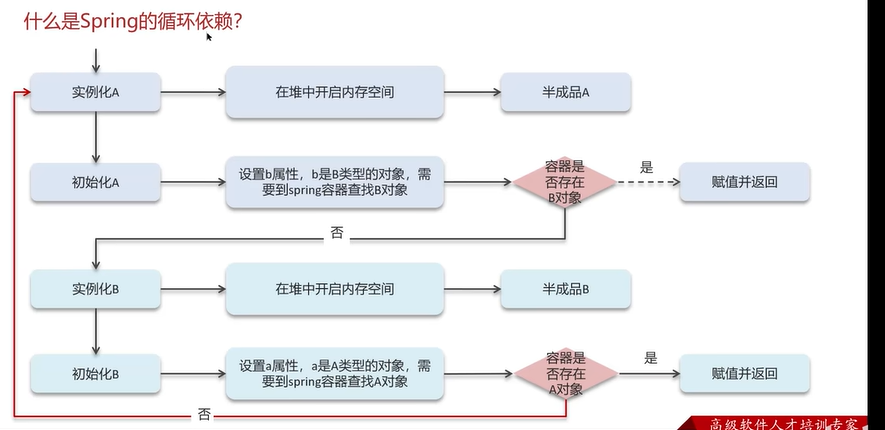
可以看到,在实例化A和B的过程中会产生死循环(实例化A找不到B,启动实例化B的子过程,实例化B的子过程又找不到实例A,又会启动实例化A的过程)。spring框架解决了大部分的循环依赖的问题。
二级缓存中存储的是半成品对象。
使用一级缓存和二级缓存可以解决循环依赖的问题: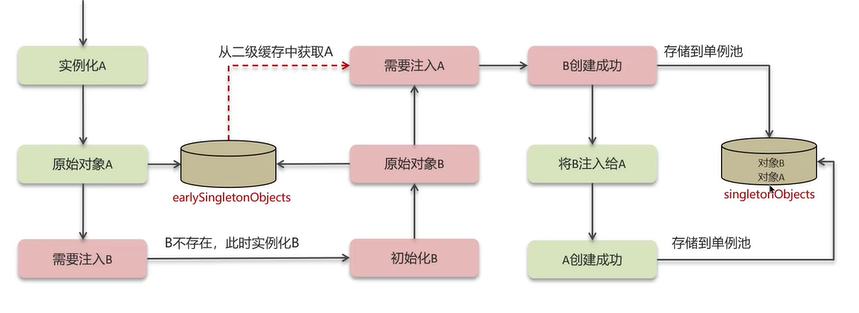
若是一个对象是被增强的代理对象,则需要使用三级缓存。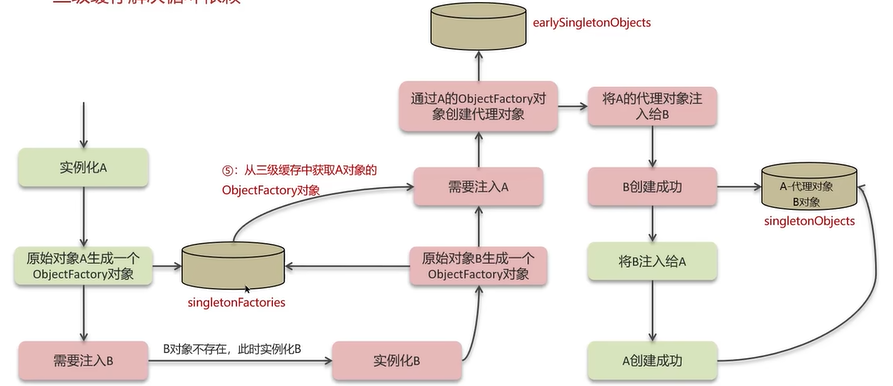
三级缓存不能解决通过构造器初始化的循环依赖问题,
解决方法是加注解@Lazy:

Q8:springmvc执行流程
springmvc的执行流程是这个框架最核心的内容,分为两种情况:
(1)视图阶段(老旧JSP等),前后端不分离
(2)前后端分离阶段(接口开发,异步)
1.视图阶段JSP
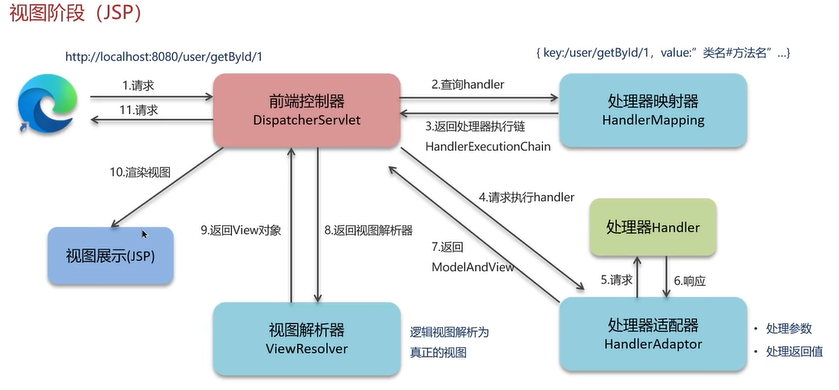
说明:
(1)前端控制器DispatcherServlet相当于一个调度中心,所有的请求都需要经过这个调度中心,DispatcherServlet是被tomcat容器初始化的。当这个类被加载之后,在内部就加载了一些组件类(处理器映射器HandlerMapping、视图解析器ViewResolver、处理器适配器HandlerAdaptor),这些组件都在前端控制器DispatcherServlet中加载。
(2)当有请求到前端控制器时,先走第一个组件处理器映射器HandlerMapping,查询handler(当前某一个控制器Controller的某一个方法),返回的是处理器执行链HandlerExecutionChain(可能添加方法之前的拦截器方法)。
(3)若是没有拦截器,前端控制器DispatcherServlet则会执行处理器适配器HandlerAdaptor,处理器适配器找到具体的方法去执行(处理器适配器会处理传递给方法的参数、处理方法返回值),执行完后会返回ModelAndView给处理器适配器HandlerAdaptor,处理器适配器HandlerAdaptor再返回给前端控制器。
(4)前端控制器接收到ModelAndView后再去找视图解析器ViewResolver,让视图解析器把逻辑视图转为真正的视图,视图解析器返回View对象。
2.前后端分析阶段
现在大部分是前后端分离开发,后台返回的都是json数据,不再返回ViewAndModel。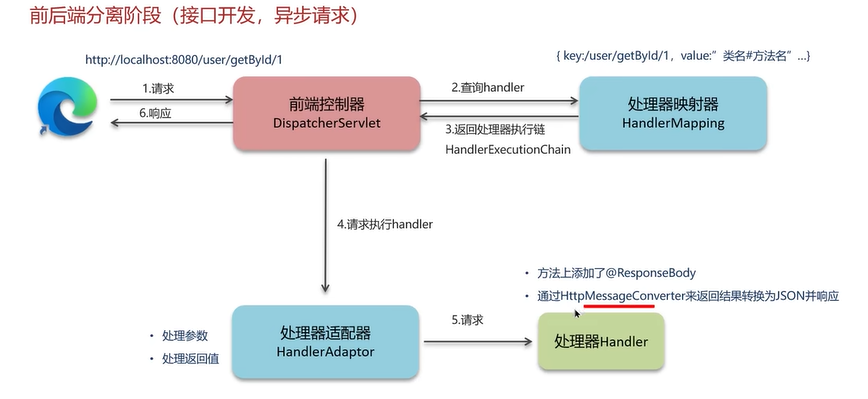
处理器handler将执行方法的返回值通过HttpMessageConverter将返回结果转换为JSON并响应。

Q9:springboot自动配置原理
springboot的自动配置原理主要依赖于@SpringBootApplication注解。
@SpringBootApplication注解还依赖于3个注解。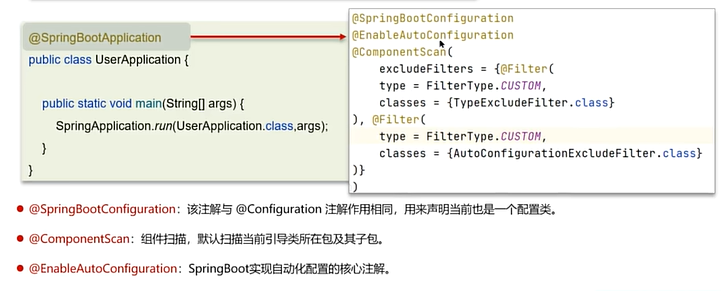
这3个注解中和自动配置有关的是@EnableAutoConfiguration注解,源码如下: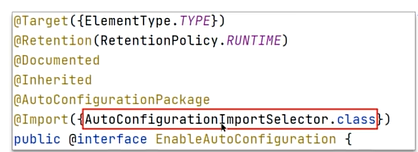
可以看到,通过@Import({AutoConfigurationImportSelector.class})导入了自动配置的选择器,它会去加载一个文件(META-INF下的spring.factories),把文件里的内容统一加载到spring容器中。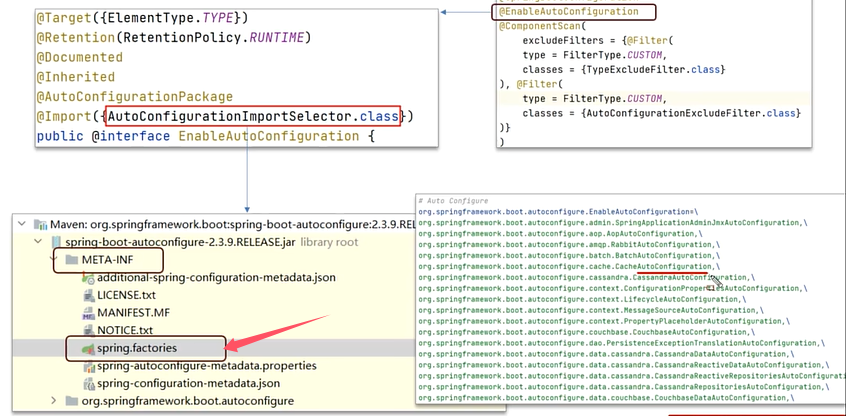
spring.factories文件中很多都是以AutoConfiguration结尾(自动配置的类),可以看到有缓存Cache、rabbitmq、aop、redis等等。这里的自动配置类不是都会加载。例如,对于RedisAutoConfiguration类,
@ConditionOnClass({RedisOperations.class}) 注解定义了加载条件:只有当 RedisOperations 类的字节码文件存在于类路径中时,才会加载 RedisAutoConfiguration 配置类。当我们引入了 Redis 相关的起步依赖(如 spring-boot-starter-data-redis)后,RedisOperations.class 便会被自动引入,从而满足条件,触发自动配置。
可以看到RedisAutoConfiguration类中redisTemplate()方法有一个返回值RedisTemplate<Object, Object>,方法上方有一个注解@Bean,@Bean注解的作用是把当前方法的返回值放到spring容器中,在自己的业务层就可以用@Autowired的注入RedisTemplate对象。方法上方的@ConditionalOnMissingBean(name={“redisTemplate”})回去判断容器中有无redisTemplate对象,若有则不执行该方法。
Q10:spring、springboot、springmvc常见的注解



三、Java多线程
(一)基础知识
Q1:如何得知线程池被占满了,如何解决?
1. 通过 ThreadPoolExecutor 提供的方法主动判断
(1)getActiveCount()(正在执行任务的线程数,不包括空闲线程):返回正在执行任务的线程数(约数)。如果它等于 getPoolSize()(当前线程池中的线程总数,包括空闲和忙碌的),说明所有线程都在忙碌。
(2)getQueue().size()(任务队列中等待执行的任务数量):返回任务队列中等待的任务数量。如果这个值大于0且getActiveCount()接近getMaximumPoolSize()(线程池允许创建的最大线程数,容量上限),说明线程池已经很繁忙。
(3)getPoolSize() 与 getMaximumPoolSize() 比较:当前线程数等于最大线程数时,说明已无法创建更多线程。
示例代码:
ThreadPoolExecutor executor = ...;
if (executor.getPoolSize() == executor.getMaximumPoolSize()
&& executor.getQueue().size() > 0) {
System.out.println("警告:线程池可能已满,队列中积压了" + executor.getQueue().size() + "个任务");
}
2. 观察拒绝策略的触发
当线程池达到maximumPoolSize且队列满时,再提交新任务会触发RejectedExecutionHandler。
显式捕获异常:提交任务时用try-catch捕获RejectedExecutionException,从而得知线程池已满。
自定义拒绝策略:实现RejectedExecutionHandler接口,在rejectedExecution方法里记录日志、发出告警或进行降级处理。
示例代码:
// 自定义拒绝策略,记录被拒绝的任务
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(2),
new ThreadPoolExecutor.AbortPolicy() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
System.out.println("线程池已满!当前活跃线程:" + e.getActiveCount());
// 这里可以触发告警或降级逻辑
}
});
3. 外部监控与告警
(1)暴露Metrics指标:通过Micrometer(结合Prometheus + Grafana)等工具,持续监控threadpool.active、threadpool.queue.size等指标,设置阈值告警(例如队列大小>1000持续5分钟)。
(2)使用Arthas等诊断工具:运行threadpool命令或通过watch命令动态查看线程池状态。
(3)JMX监控:ThreadPoolExecutor提供了getPoolSize()、getActiveCount()、getTaskCount()等标准MBean,可通过JConsole或VisualVM实时查看。
那么线程池满了该怎么办?
(1)增加最大线程数:调大maximumPoolSize(需结合CPU密集/IO密集型评估)。
(2)增大队列容量:适当调大workQueue的capacity,但注意会提高内存压力。
(3)优化拒绝策略:使用CallerRunsPolicy让提交任务的线程帮忙执行,作为反压机制;或者使用DiscardPolicy丢弃不重要任务。
(4)任务降级与熔断:改为异步写入消息队列(如Kafka/RocketMQ),由后台慢慢处理;或者直接返回“当前繁忙,请稍后重试”。
Q2:Runnable和Callable有什么区别?

Q3:run()和start()有什么区别?

Q4:线程有哪些状态,状态之间如何转换?


加锁的情况会发生阻塞blocked:
调用wait()进入等待状态(waiting)的线程:
进入计时等待状态(TIMED_WAITING)的线程:
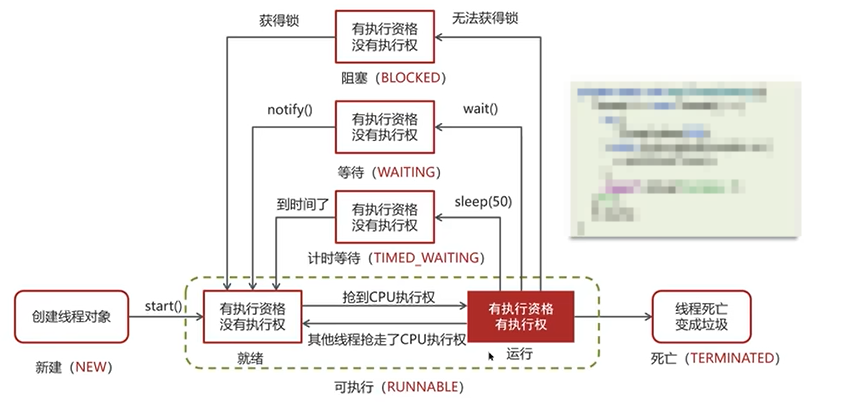

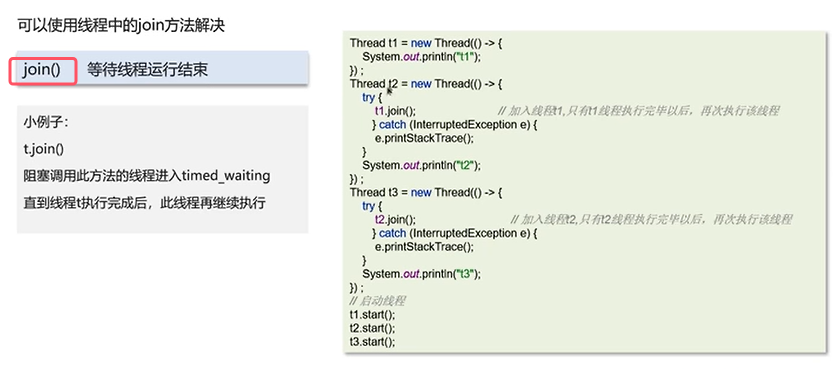
Q5:新建T1,T2,T3三个线程,如何保证它们按顺序执行?
Q6:notify()和notifyAll()的区别?

一个例子: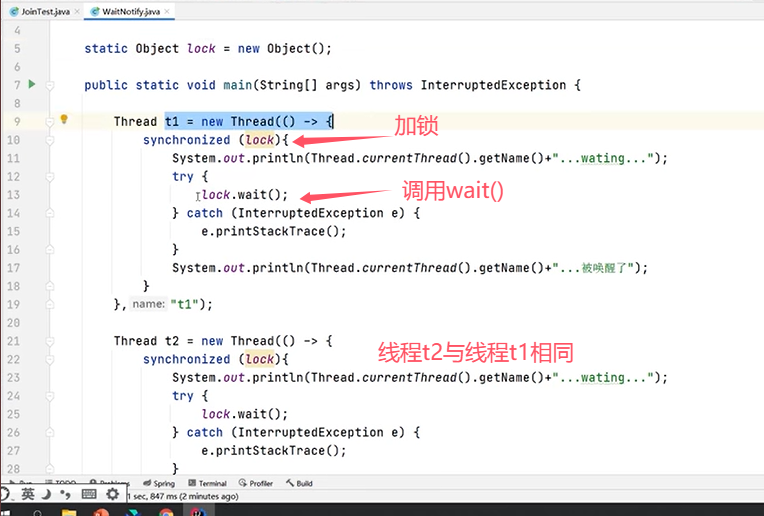
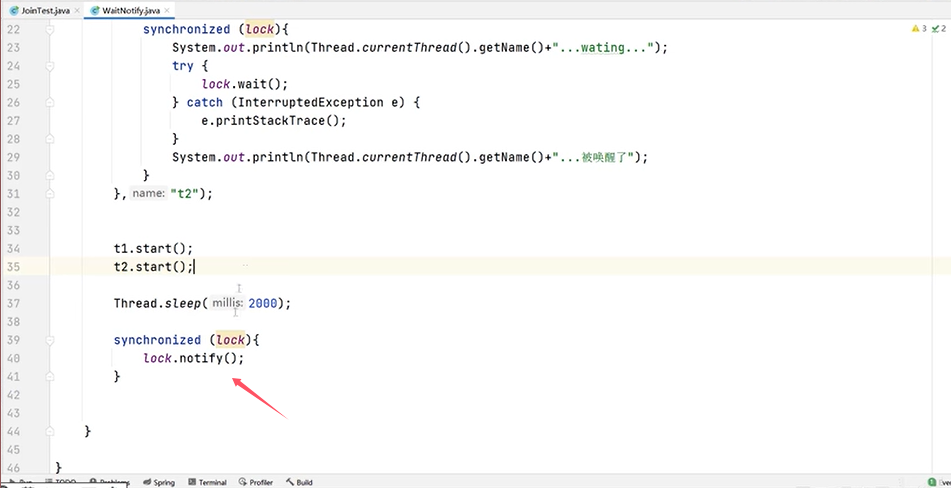
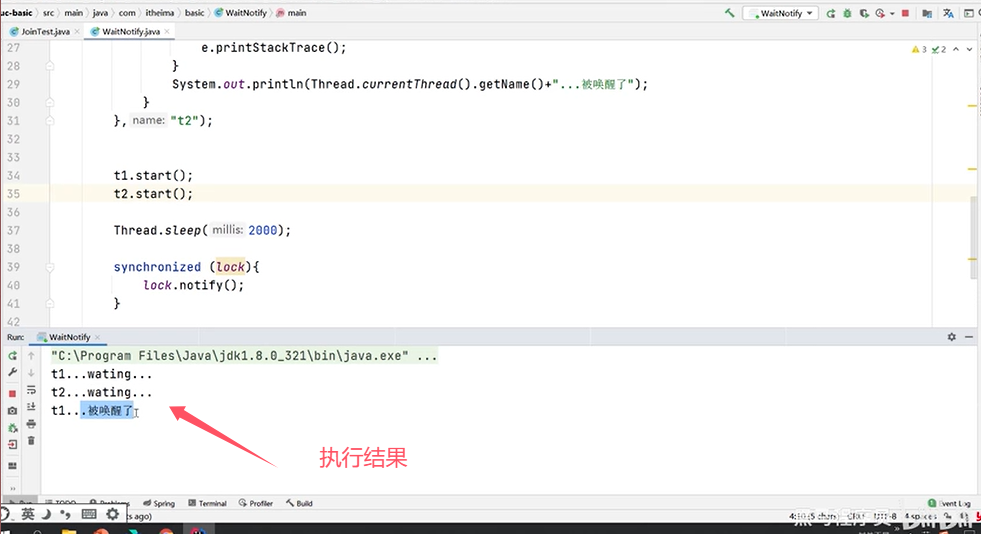
若是改成notifyAll():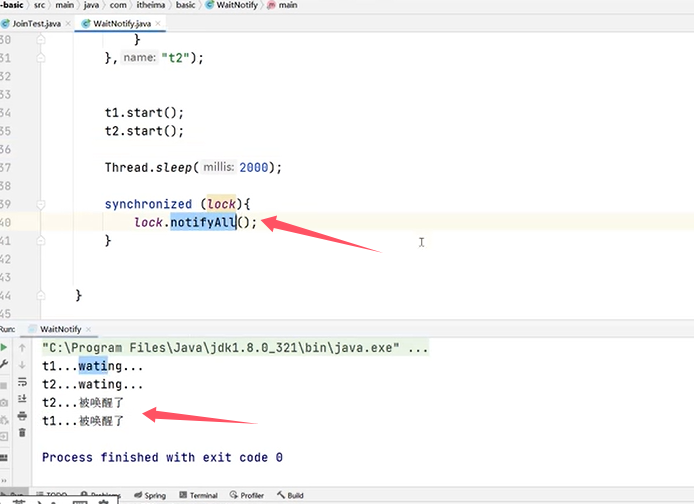
Q7:java中wait()和sleep()的区别?

对于不同点中的锁特性,举个例子如下: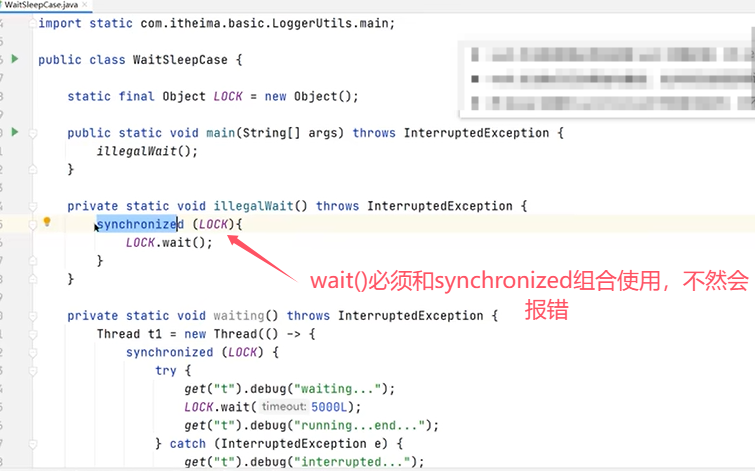
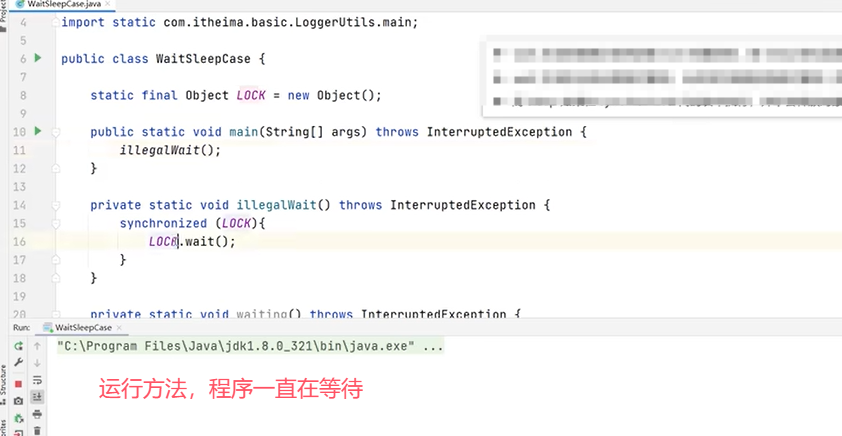
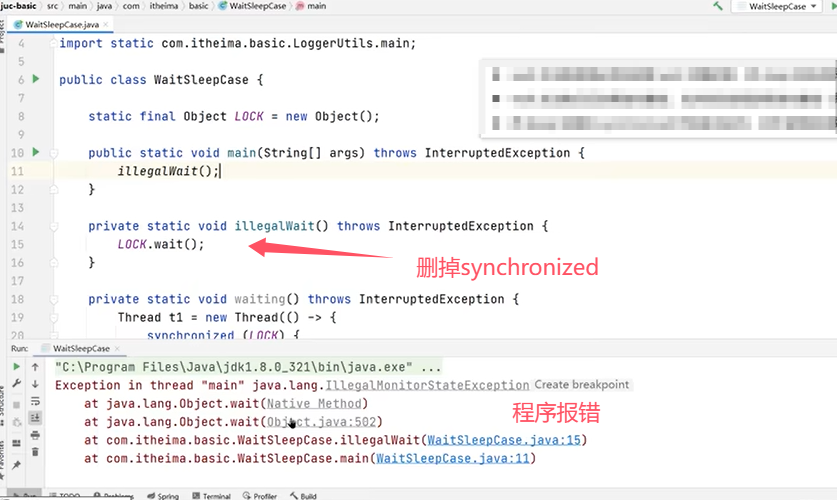
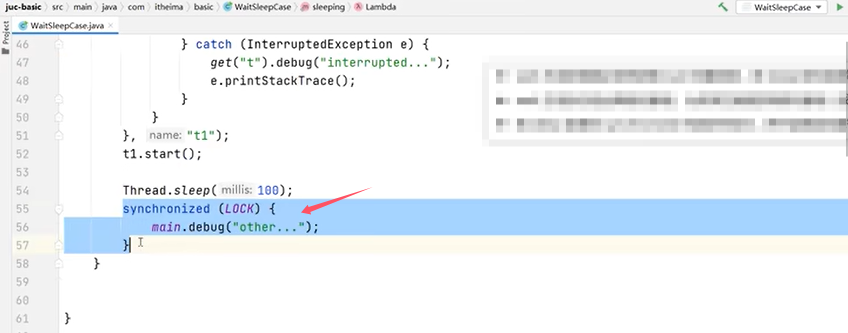
再看一个例子: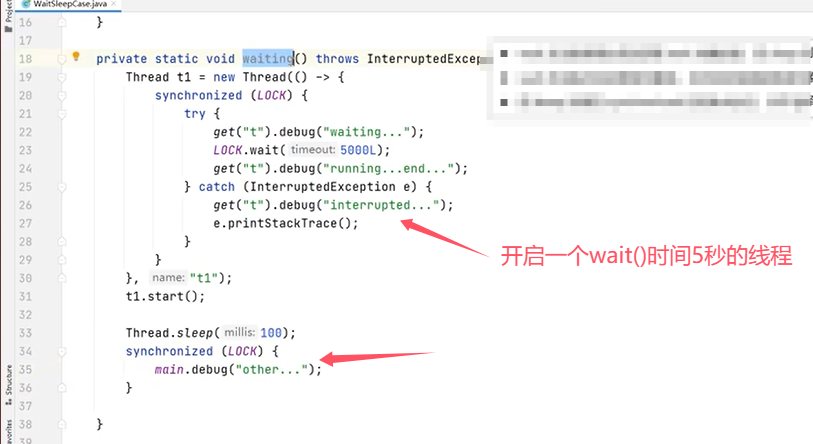
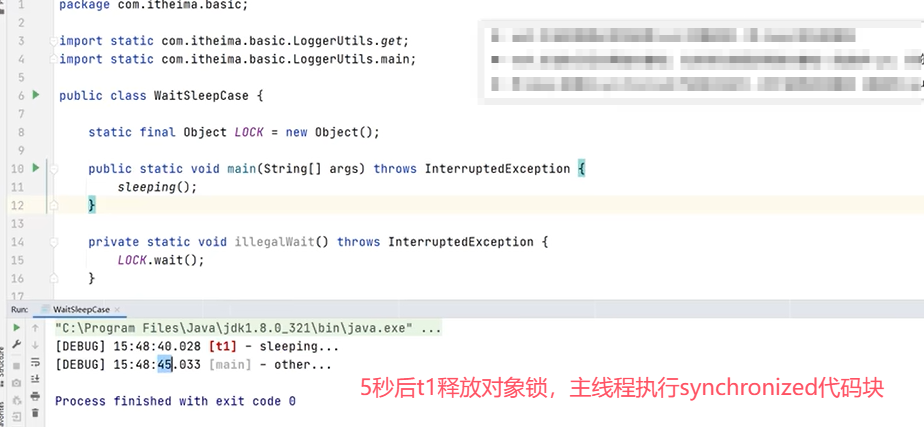
上图中的代码主程序和线程都使用了synchronized去获取LOCK锁对象,所以只能运行一个。主要是为例验证线程t1在执行了wait()之后会释放LOCK锁对象,主线程的synchronized中的代码块会正常执行。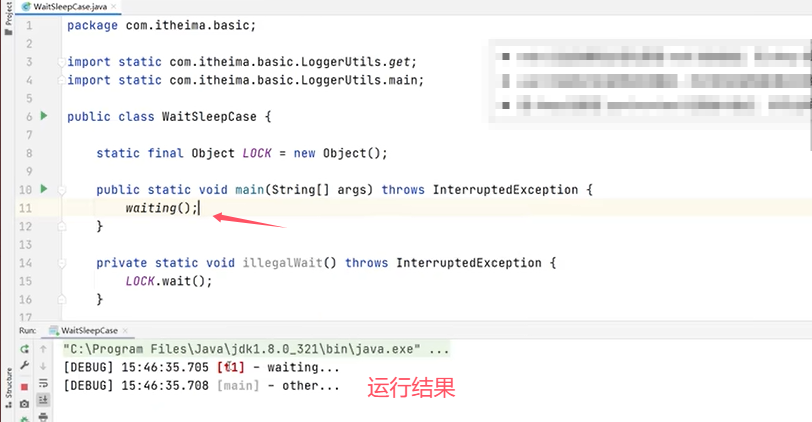

再看使用sleep()的例子: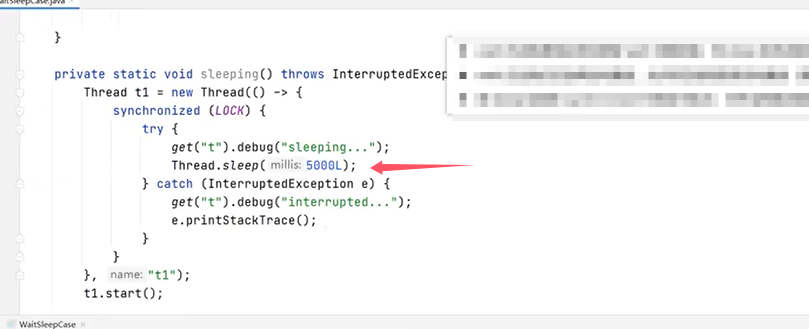

Q8:如何停止一个正在运行的线程?

先看一个“使用退出标志让线程正常退出”的例子: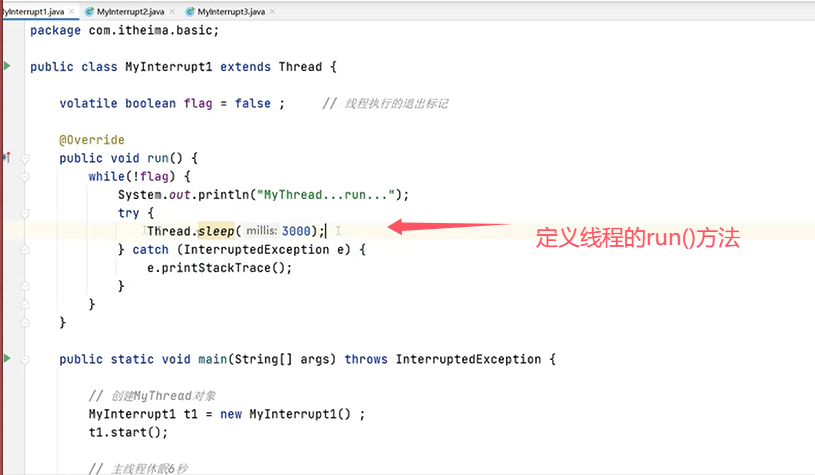
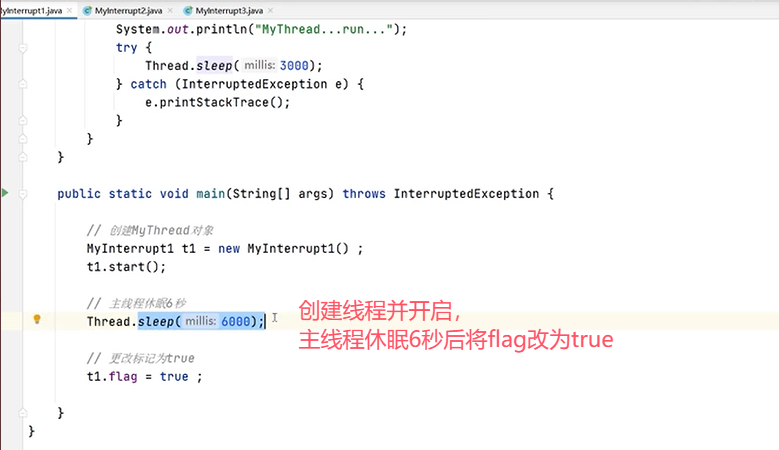
可以看到,flag改为true之后线程t1执行完自动退出。
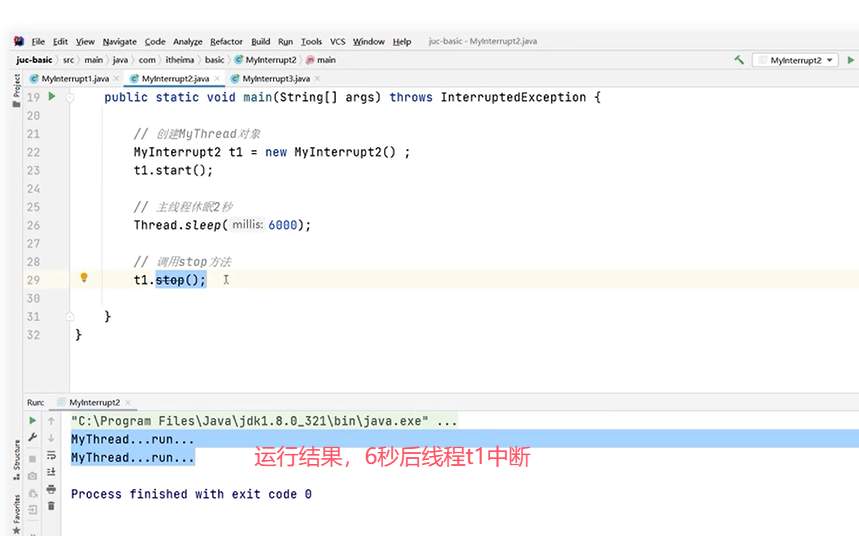
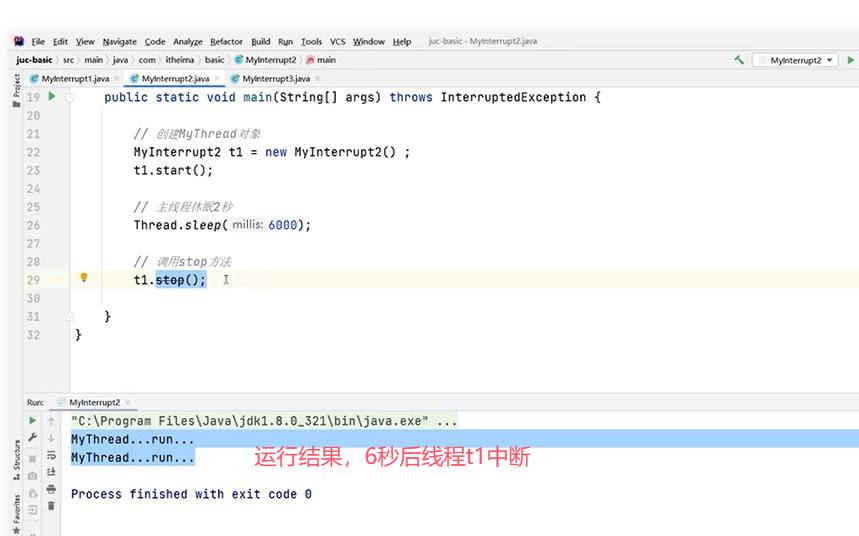
来看一个stop()的例子。
再来看使用interrupt()的两种情况: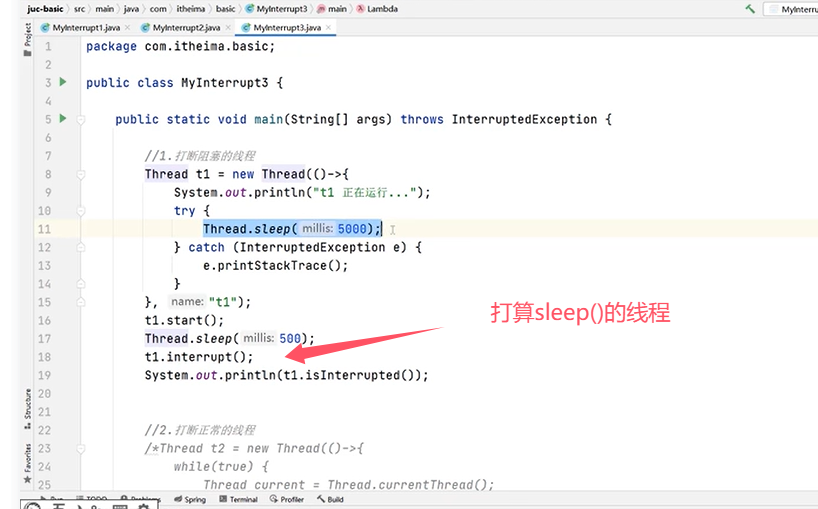
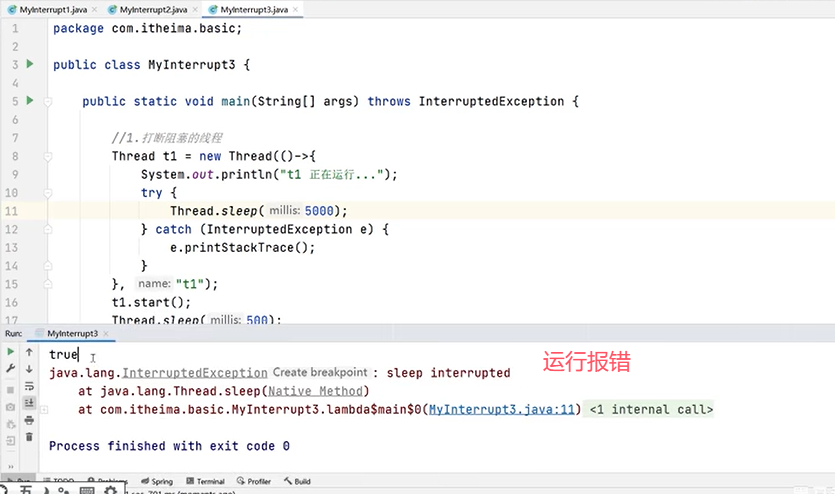
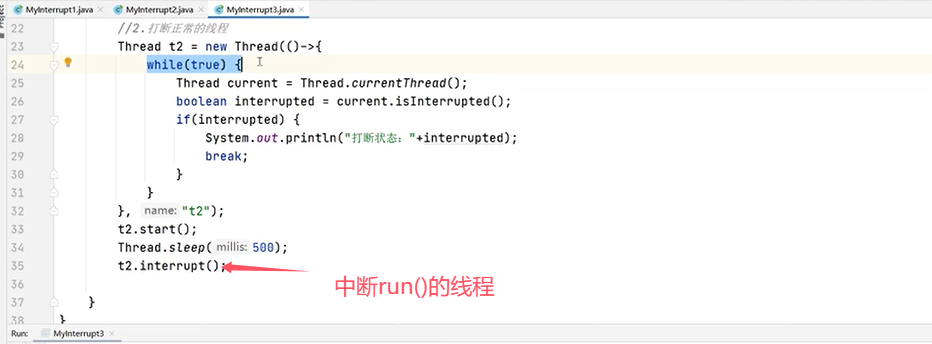
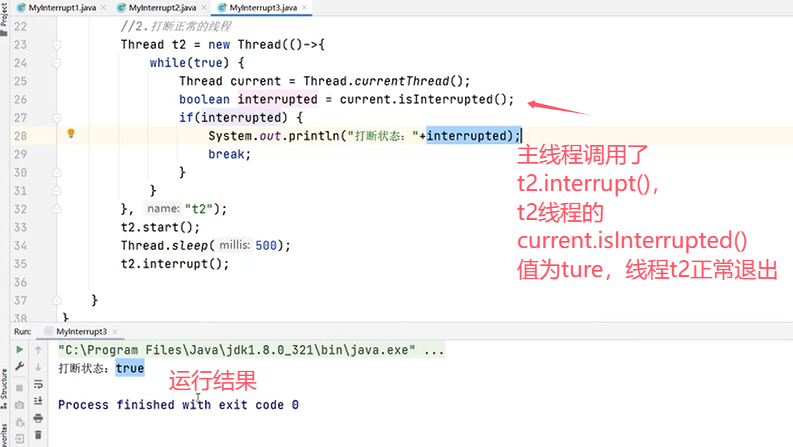
(二)线程安全
Q1:synchronized关键字的底层原理?

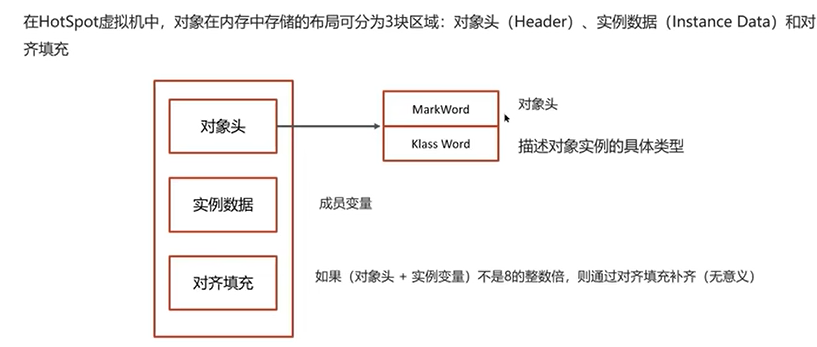
synchronized的底层实现是monitor。
上面有两次monitorexit是因为有隐式的try-catch处理异常。
Monitor即为监视器,是由jvm提供,c++语言实现。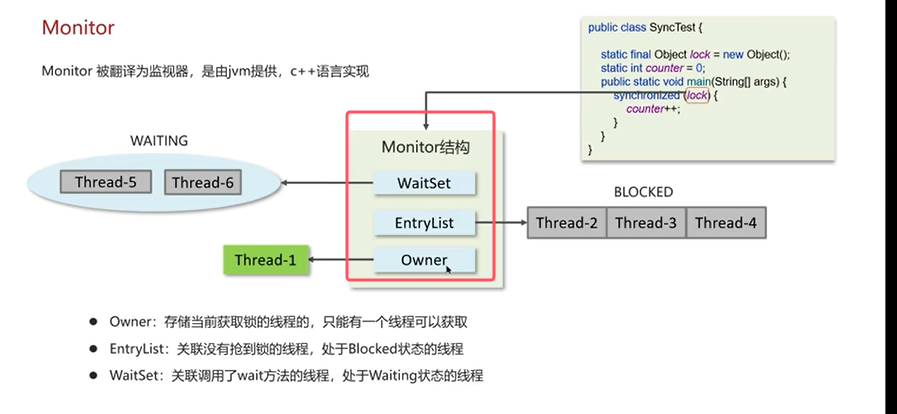
Monitor有3个属性(WaitSet、EntryList和Owner)。上图中的代码中synchronized使用了一个对象锁Object lock,会将该对象锁与monitor进行关联,然后判断Monitor的属性owner是否为null,如果为null则让当前线程直接拥有,则当前线程拥有了对象锁,且monitor只能关联一个线程。再来的线程需要去EntryList中进行等待,等待的线程的状态为Blocked,线程1执行完释放锁,则会唤醒EntryList中的线程。注意EntryList中的线程并没有排队,线程1释放锁后哪个线程抢到了锁那个线程执行代码块。当一个线程调用了wait()后会处于等待状态,线程进入Monitor的属性WaitSet中。
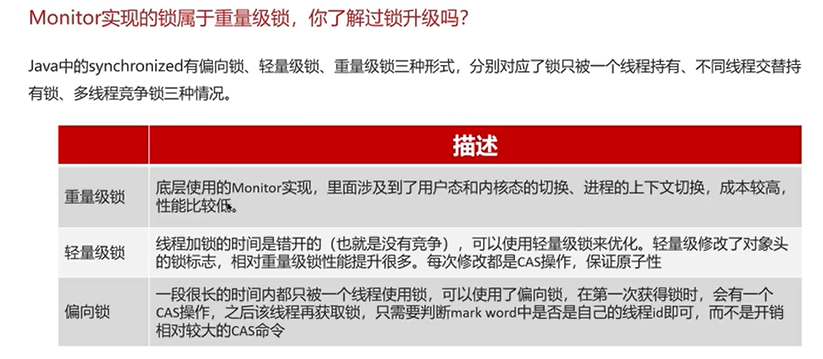
Q1补充:monitor是一个重量级锁,了解过锁升级吗?





Q2:谈一谈JMM(Java内存模型)?

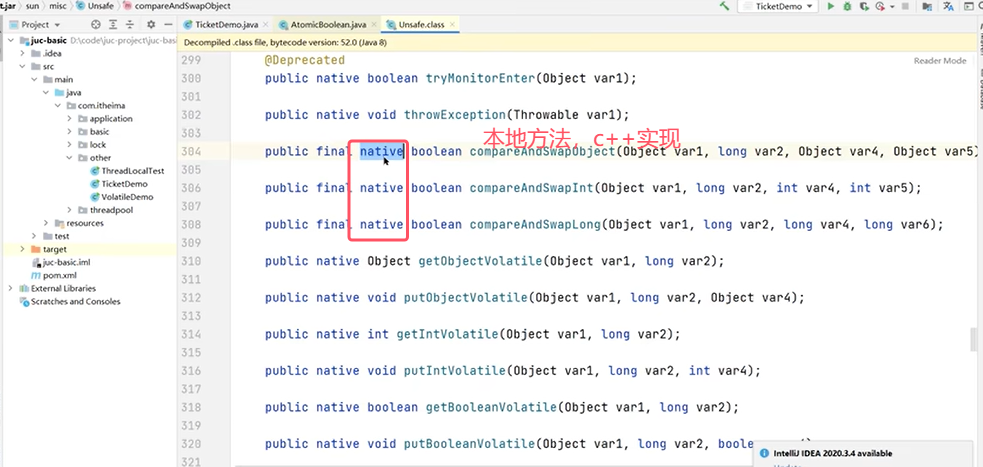
Q3:CAS你知道吗?





Q4:谈谈对volatile的理解?

对第二点进行详细讲述:
对于上述代码,按理说只有3种情况:
但是,可能出现第四种情况:
出现这种情况的原因是编译器对actor1中的两行代码进行了重排,先执行第二行代码。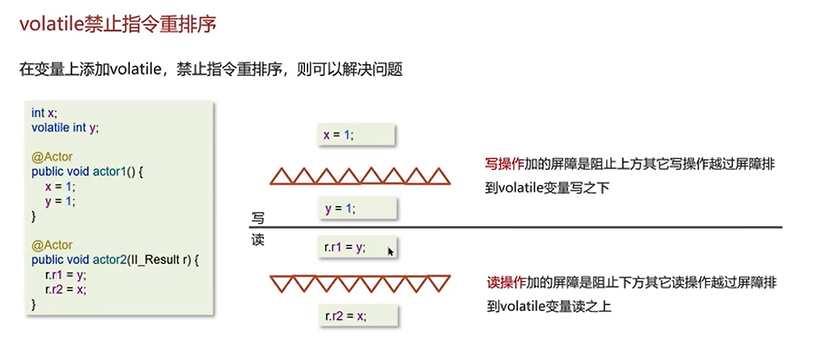
上图中的例子若是把volatile加到x,则还是会发生指令重排序的问题。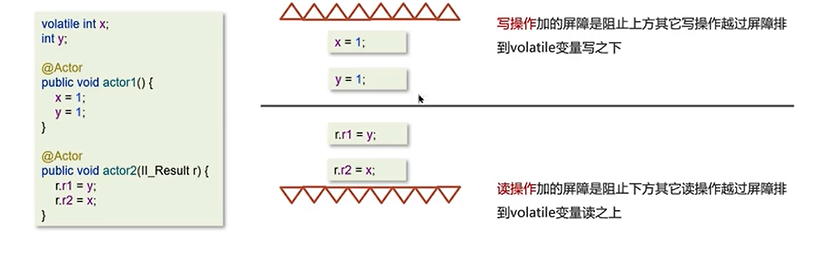
若是x,y都加上volatile也可以,但是性能会降低。
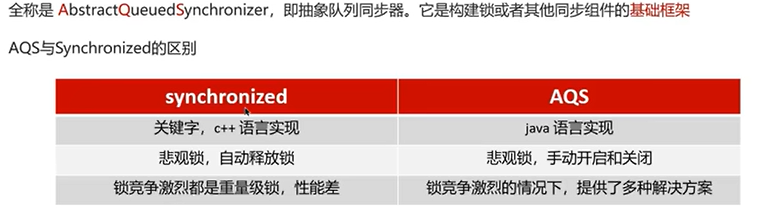
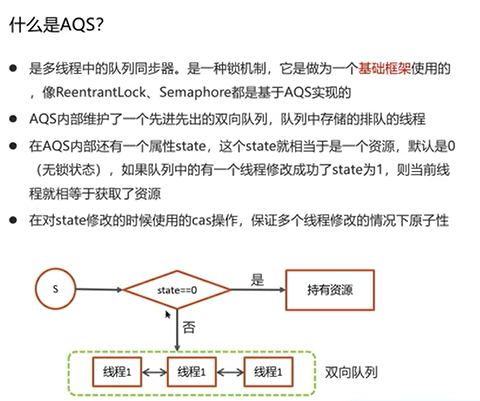
Q5:什么是AQS?

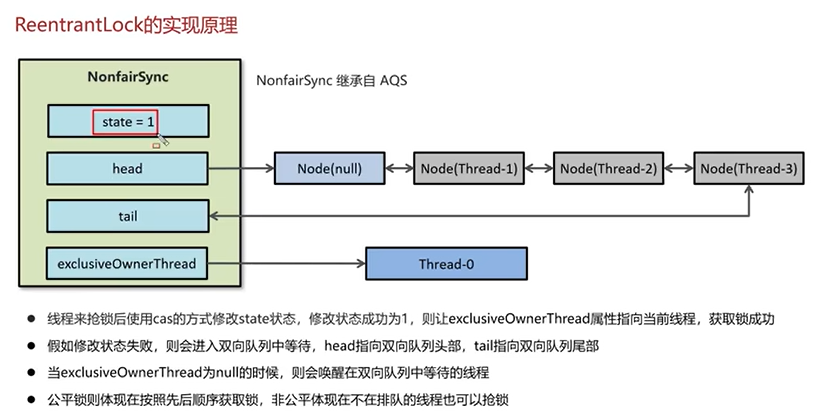
Q6:ReentrantLock的实现原理?

代码写法如下:



Q7:synchronized与Lock的区别?
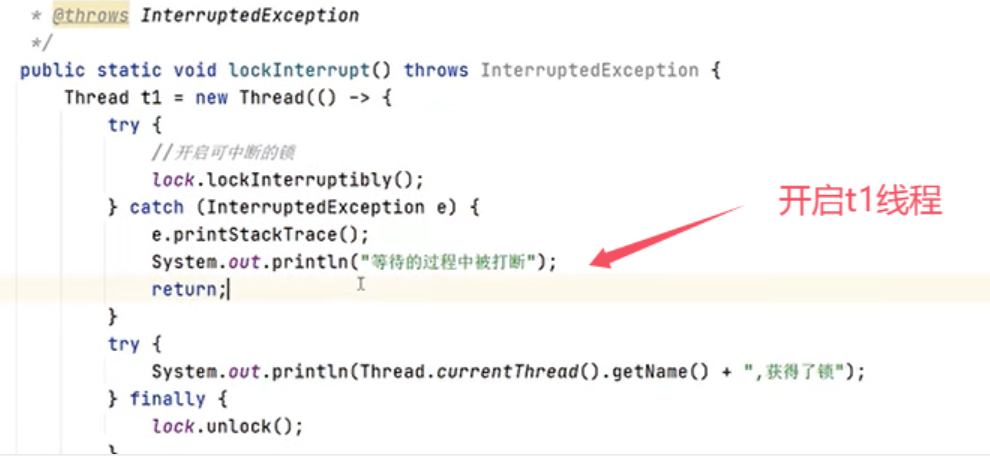
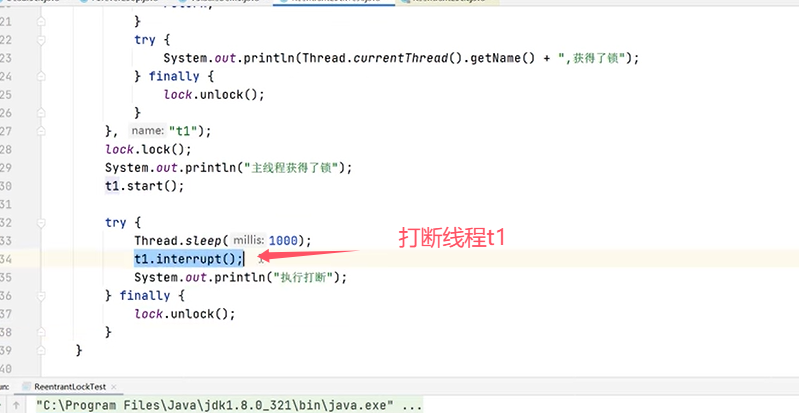
验证lock锁是“可打断”的: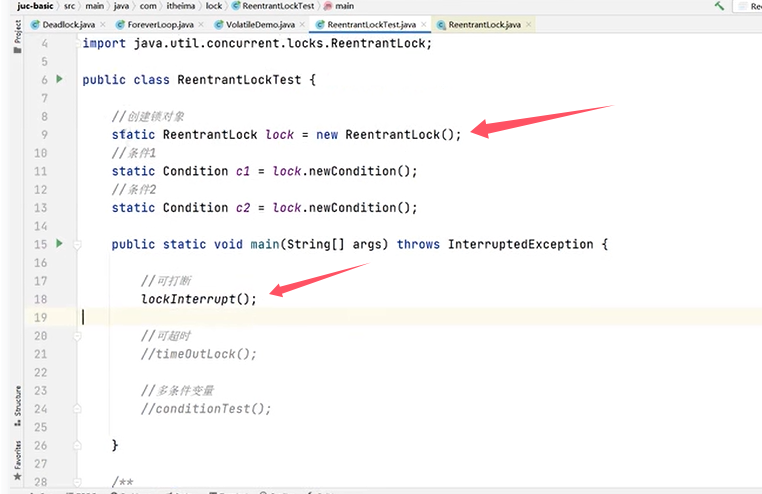
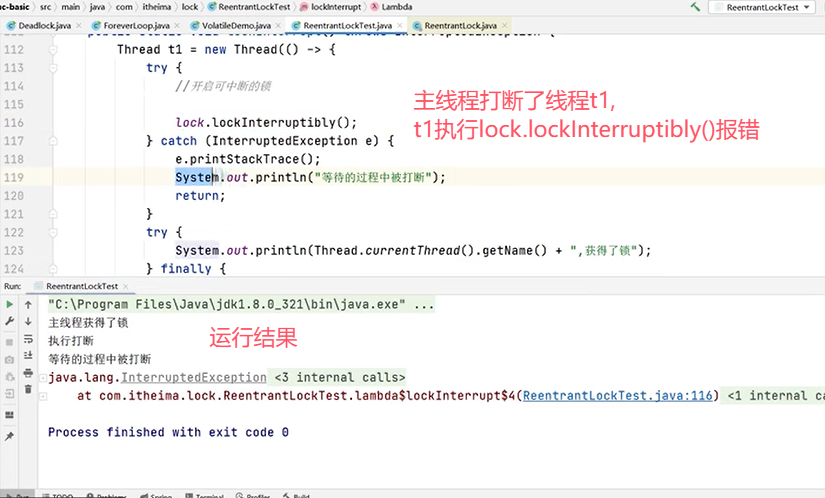
验证Lock锁是“可超时”的:
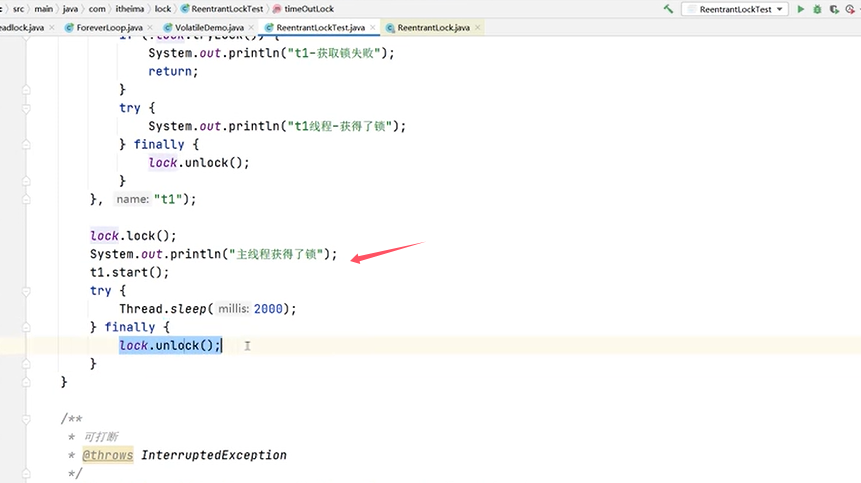
主线程先拿到了锁才开启了线程t1,线程t1获取不到锁。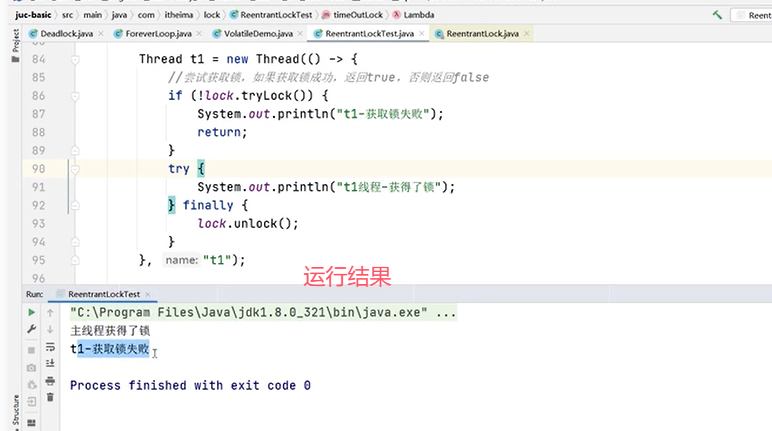
修改代码: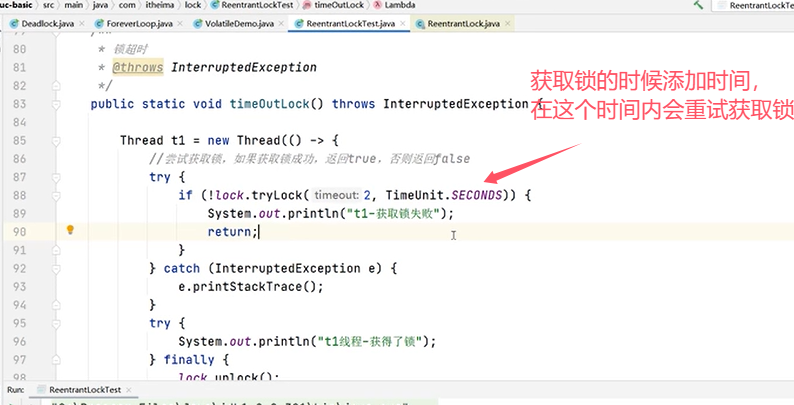
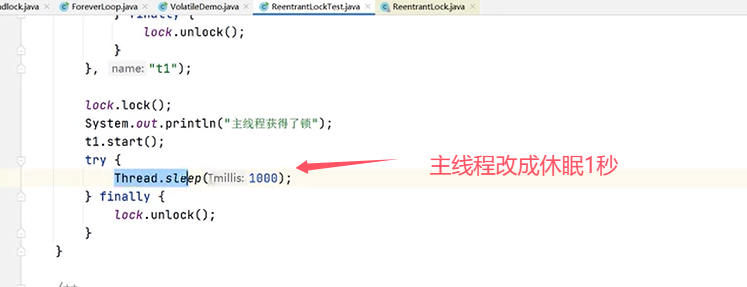
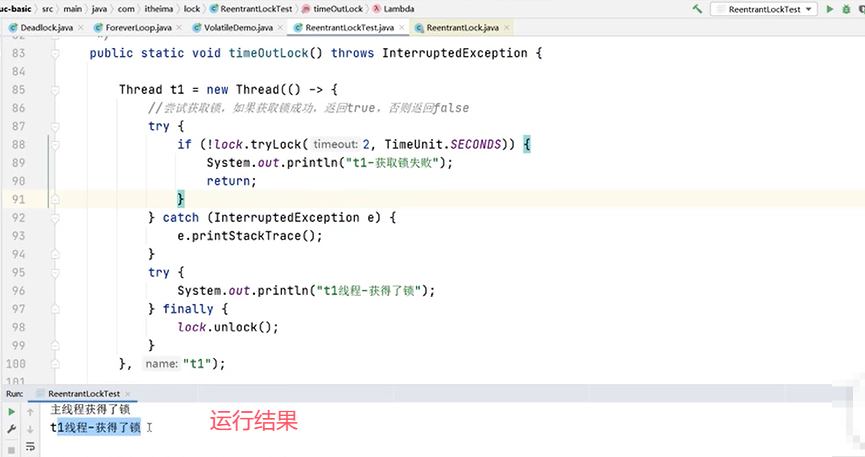
再来验证“多条件变量”:
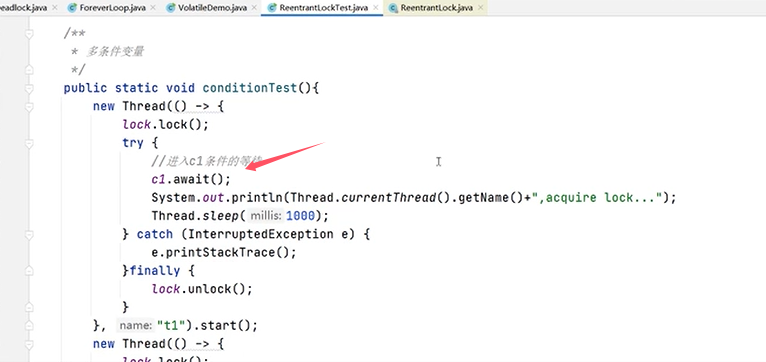
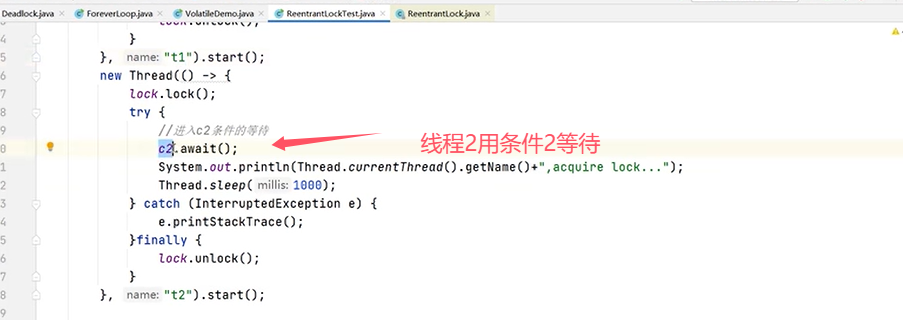
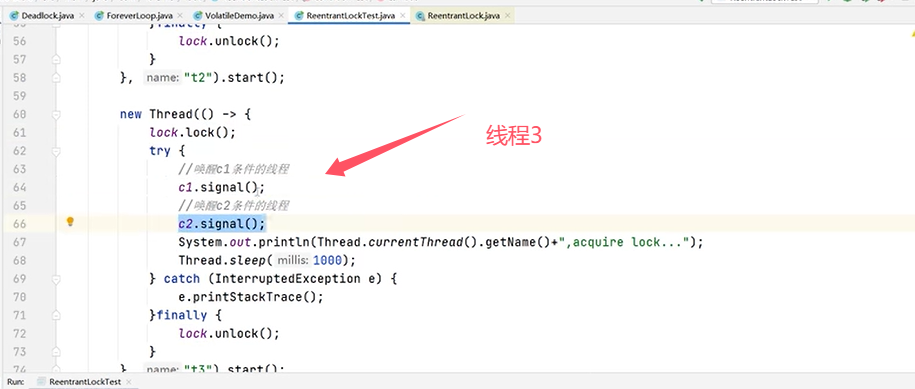
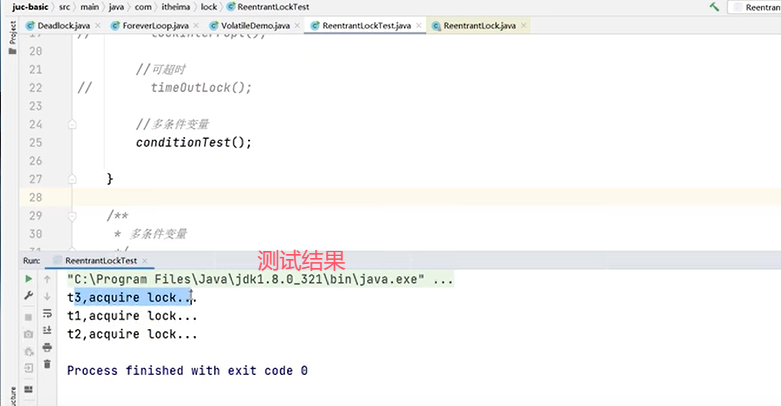
可以再修改代码,把线程2的条件也改成c1: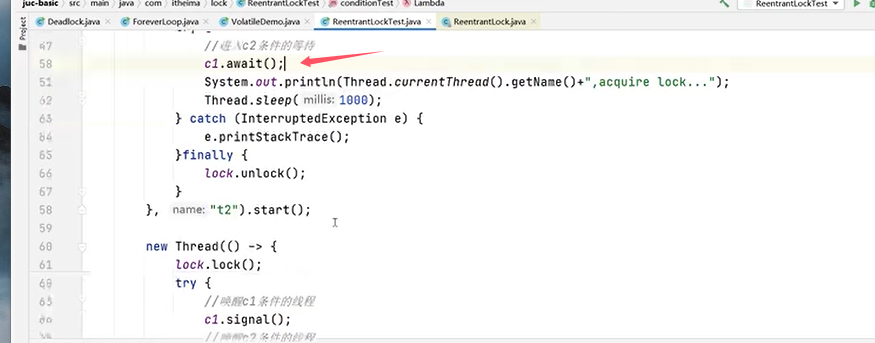
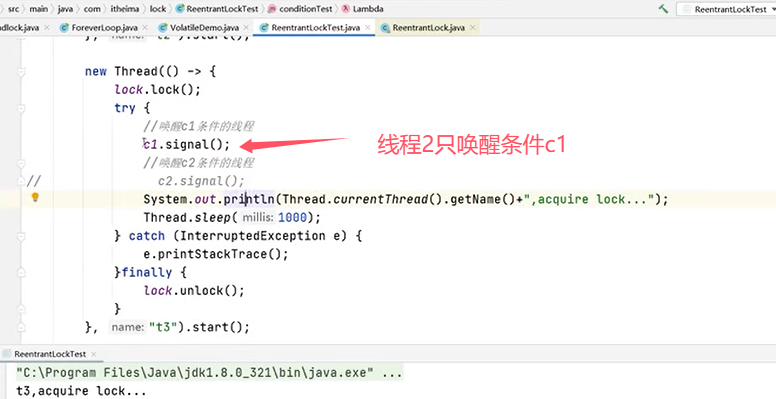
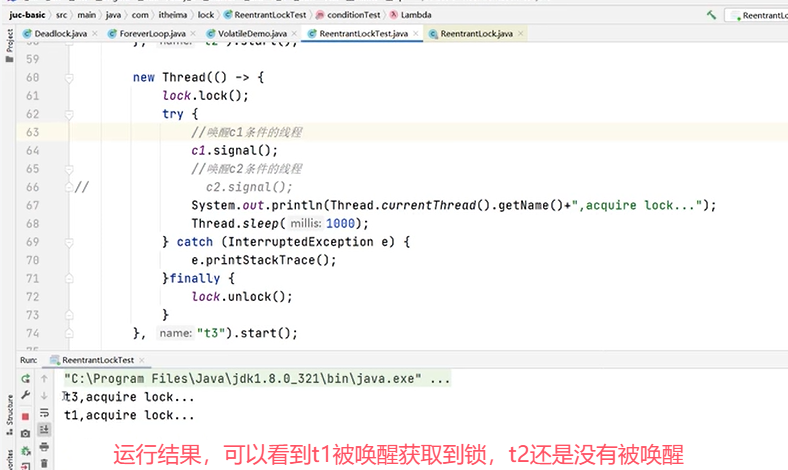
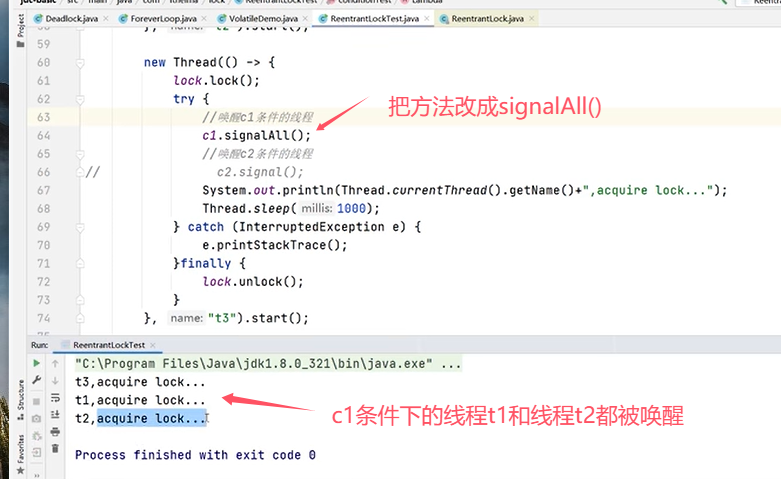
上例中的运行结果为,线程3拿到锁之后调用signal()方法,线程1和线程2也拿到锁。(signal()类似于notify(),signalAll()类似于notifyAll())。
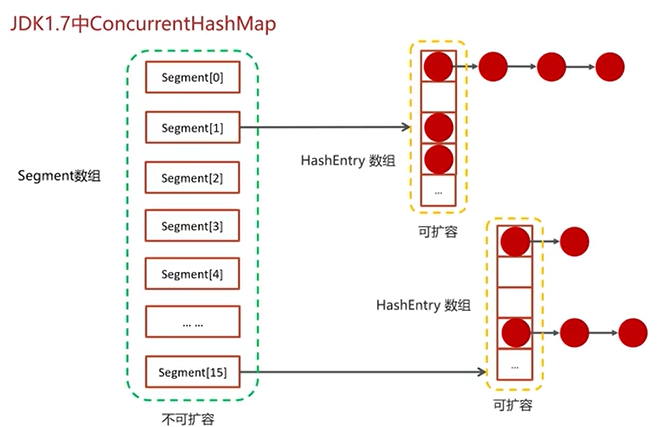
Q8:聊一下ConcurrentHashMap?

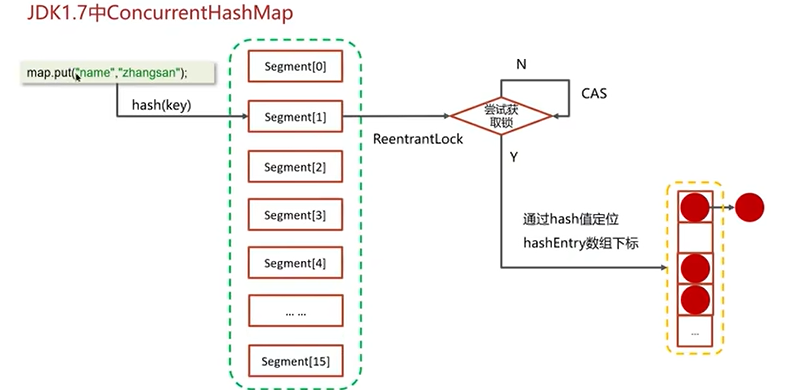
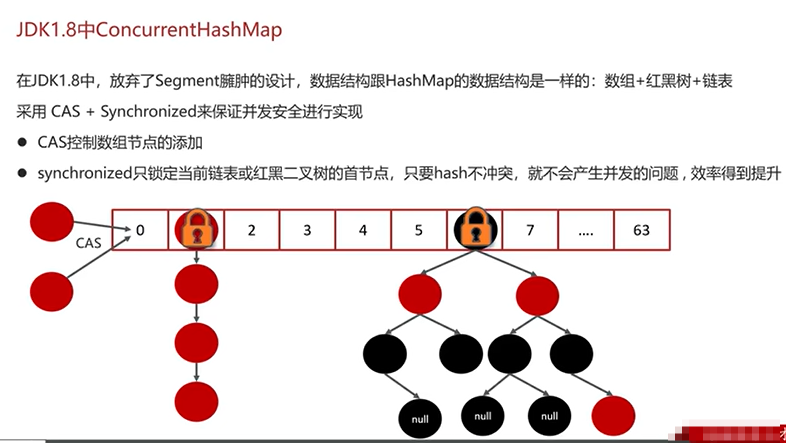

Q9:导致并发程序出现问题的根本原因?
(Java程序中怎么保证多线程的执行安全)




(三)线程池
Q1:线程池的核心参数?

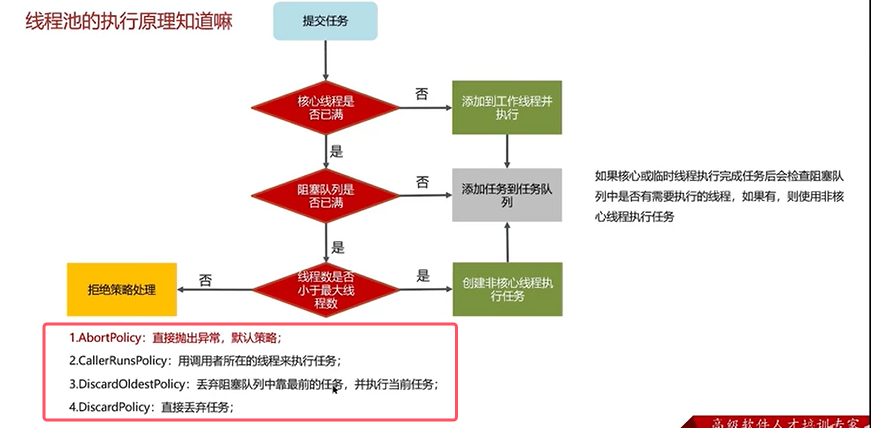
Q2:线程池有哪些常见的阻塞队列?

说明:(1)DelayedWorkQueue在入队时设置出队时间。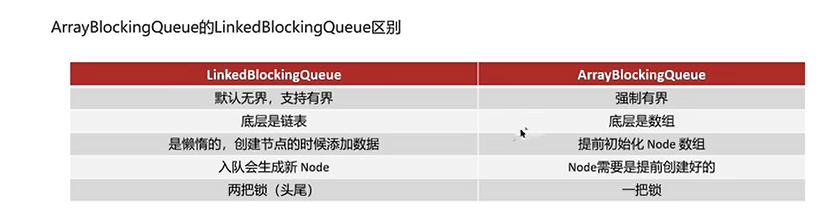
说明:
(1)LinkedBlockingQueue的两把锁的意思是,在链表的头结点和尾结点个有一个锁,一边入队、一边出队。ArrayBlockingQueue只有一把锁,入队和出队都是这一把锁。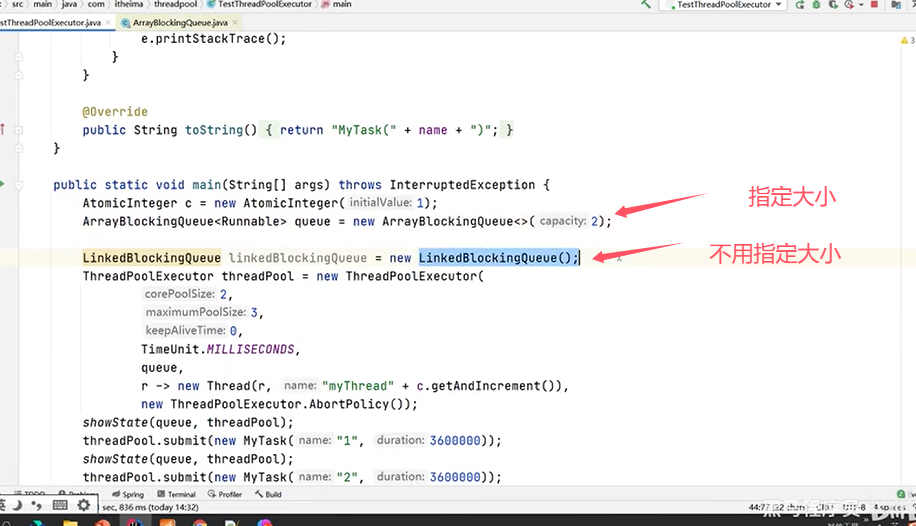
Q3:如何确定核心线程数?


Q4:线程池的种类有哪些?
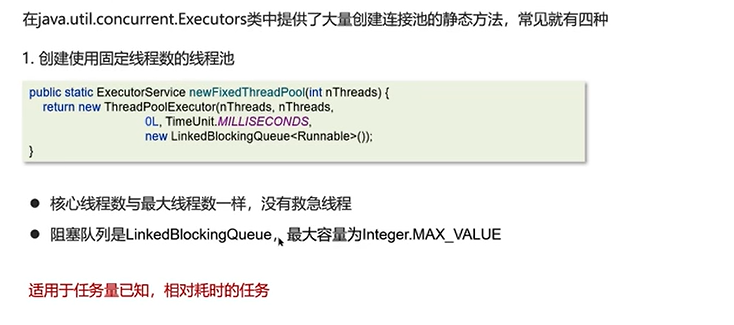
1.创建使用固定线程数的线程池newFixedhreadPool
一个例子: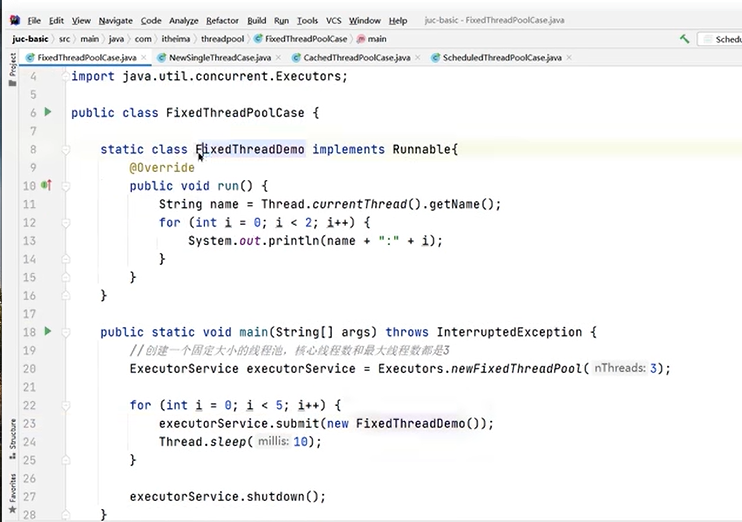
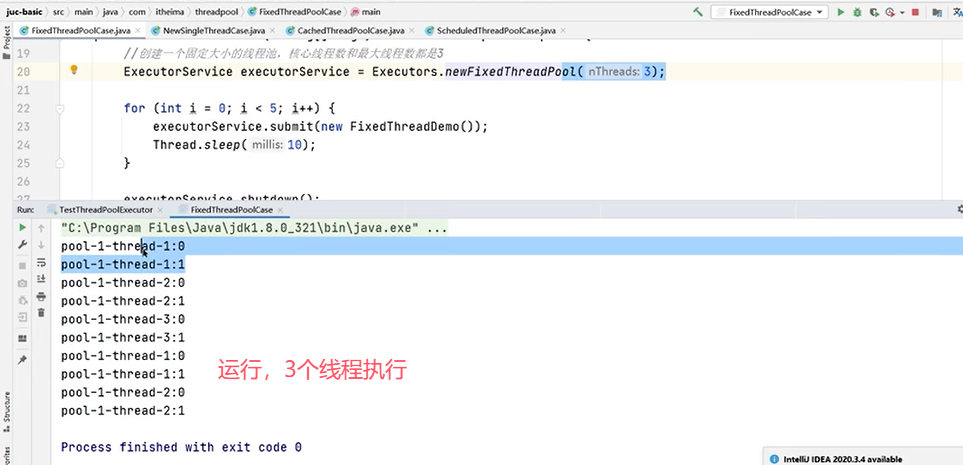
2.单线程化的线程池newSingleThreadExecutor

一个例子: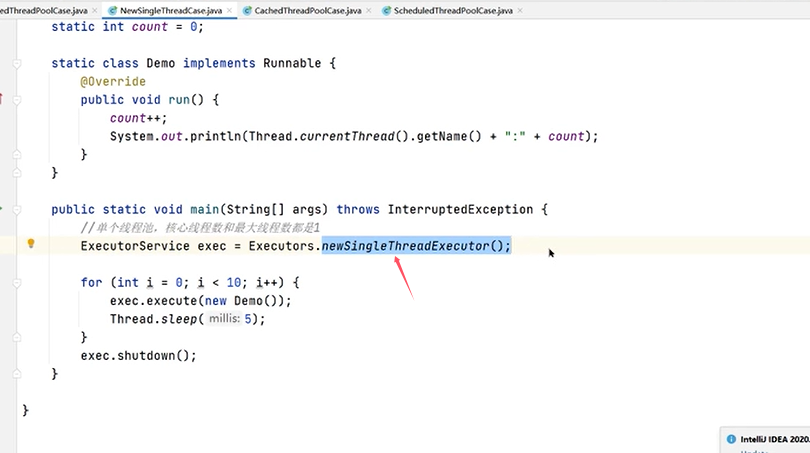
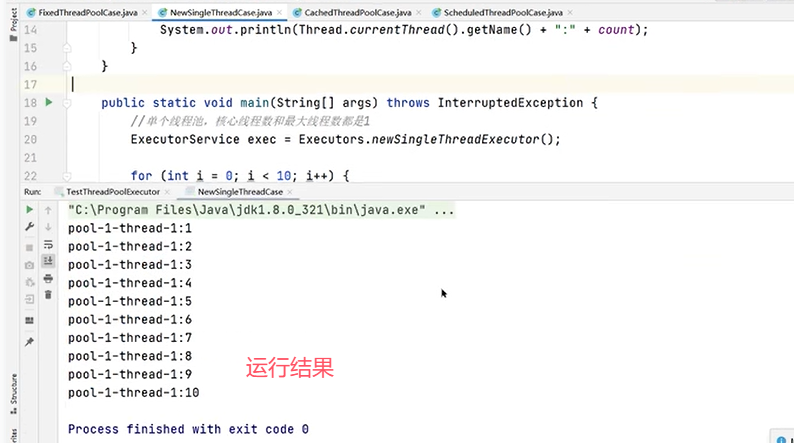
可以看到只有一个线程在执行。
3.可缓存线程池newCachedThreadPool

一个例子: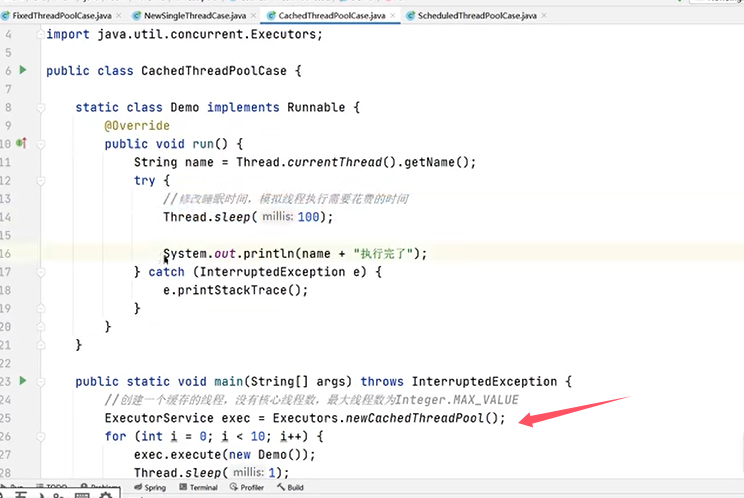
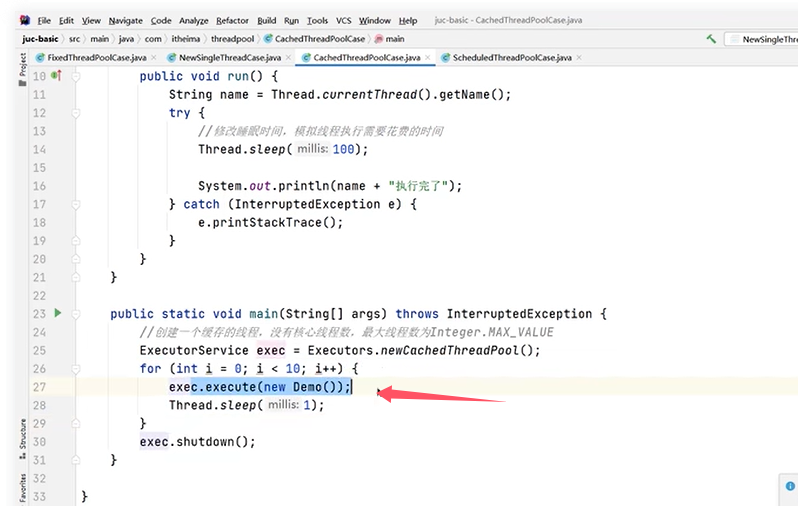
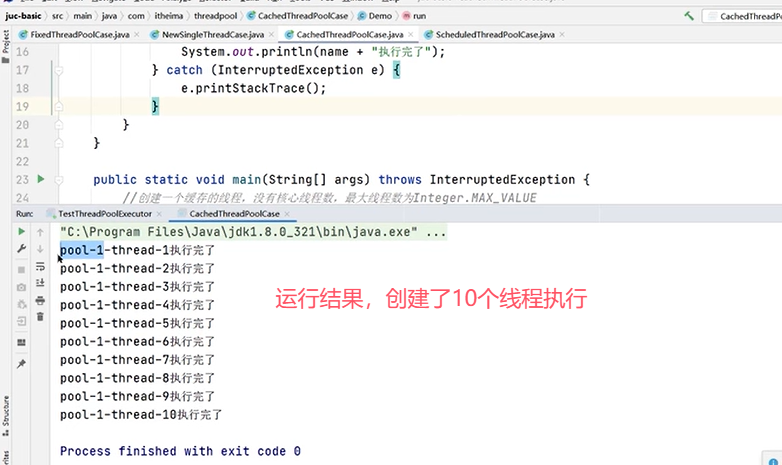
4.提供了"延迟"和"周期执行"功能的ScheduledThreadPoolExecutor
一个例子: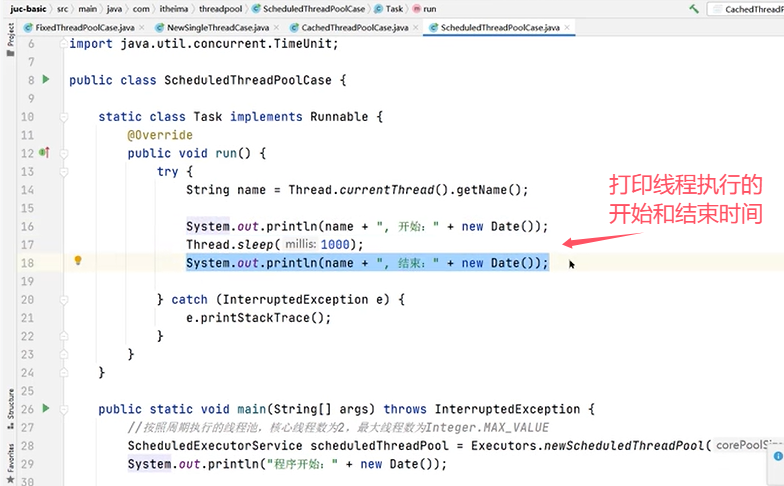
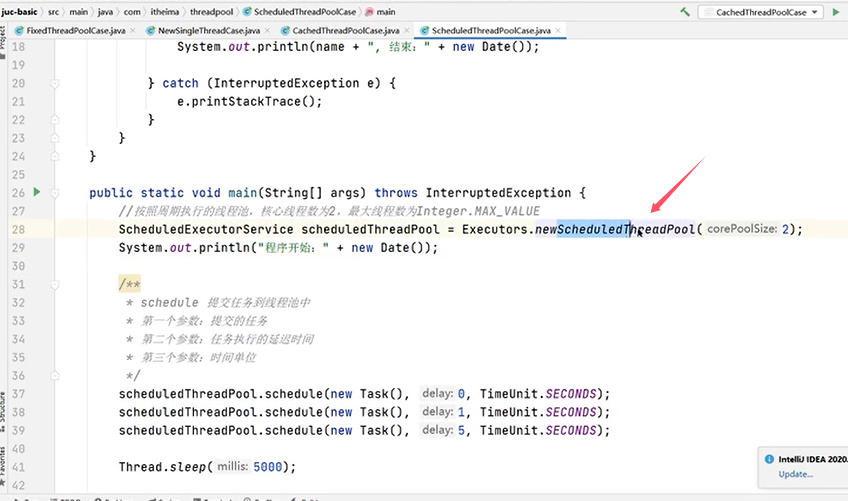
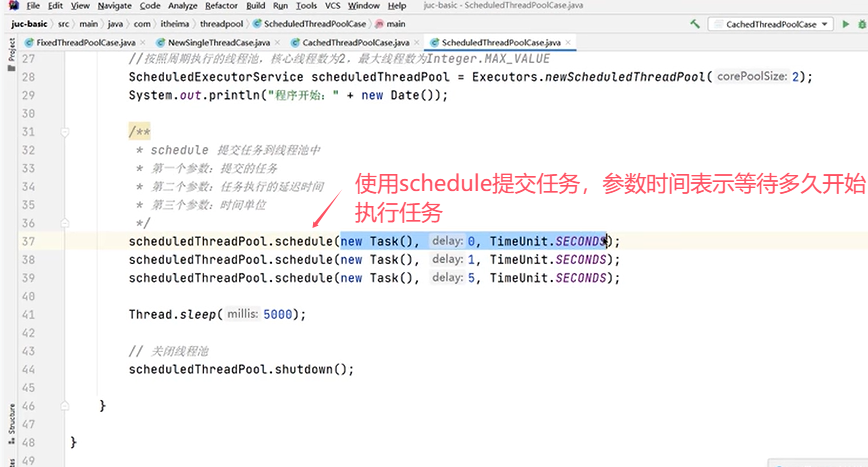
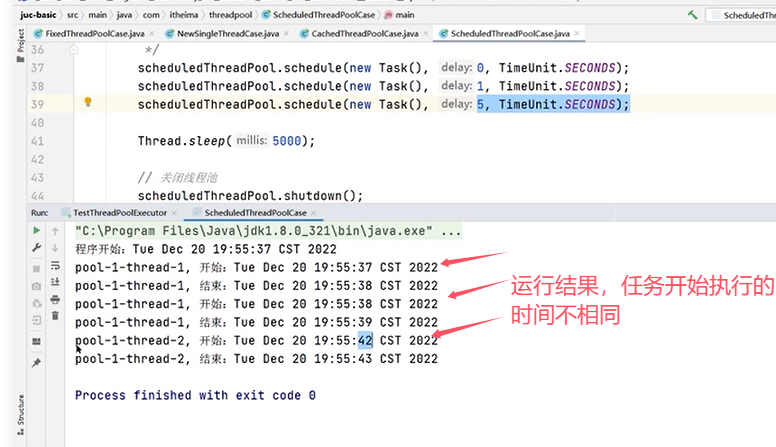
再看一个设置为周期执行的例子:
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledThreadPoolExample {
public static void main(String[] args) {
// 创建一个支持定时任务的线程池,核心线程数为2
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(2);
// 1. 使用 scheduleAtFixedRate: 固定频率
// 参数: 任务, 首次延迟, 周期, 时间单位
scheduler.scheduleAtFixedRate(() -> {
long start = System.currentTimeMillis();
System.out.println("固定频率任务开始: " + start);
try {
// 模拟任务执行耗时 2 秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("固定频率任务结束,耗时: " + (System.currentTimeMillis() - start) + "ms");
}, 0, 1, TimeUnit.SECONDS); // 首次立即执行,之后每1秒尝试启动一次
// 2. 使用 scheduleWithFixedDelay: 固定延迟
scheduler.scheduleWithFixedDelay(() -> {
long start = System.currentTimeMillis();
System.out.println("固定延迟任务开始: " + start);
try {
// 模拟任务执行耗时 2 秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("固定延迟任务结束,耗时: " + (System.currentTimeMillis() - start) + "ms");
}, 0, 1, TimeUnit.SECONDS); // 首次立即执行,之后每次执行完等待1秒再启动
}
}

Q5:为什么不建议使用Executors创建线程池?

(四)使用场景
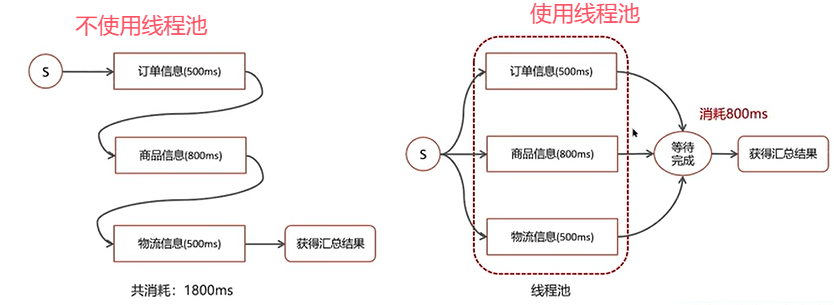
Q1:线程池使用场景?
项目中哪里用到了线程池?


Q2:如何控制某个方法允许并发访问线程的数量?


Q3:谈谈你对ThreadLocal的理解?
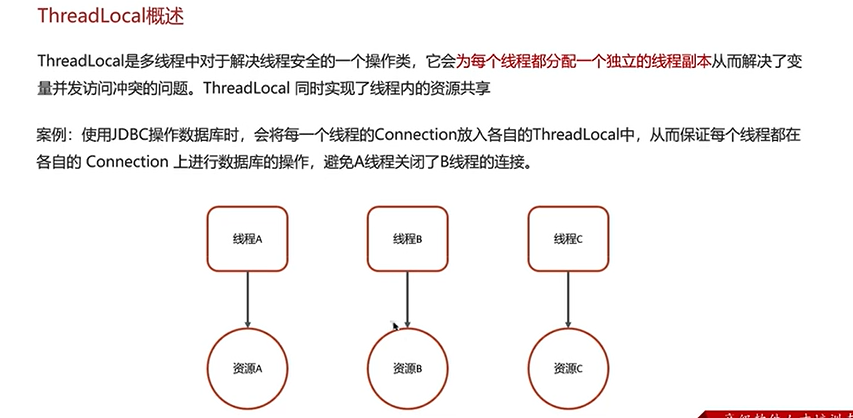
一个例子: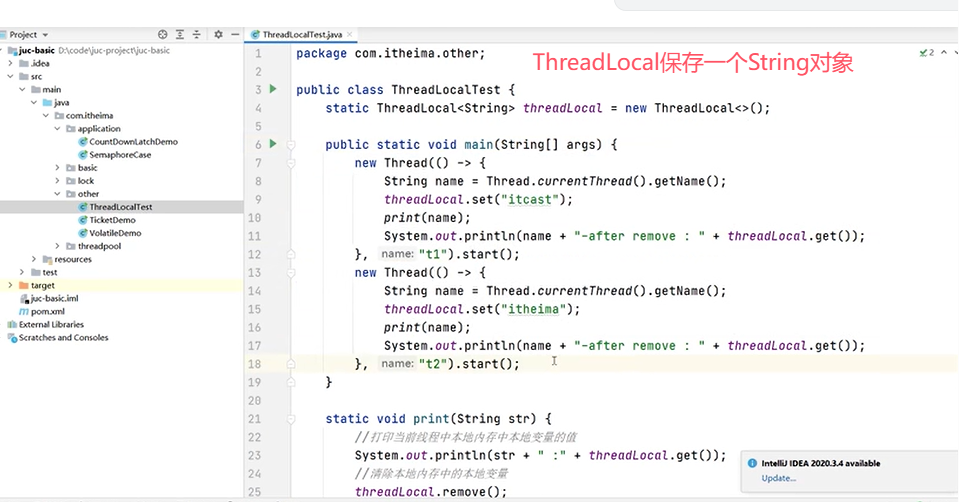
线程1和线程2都先后执行set、remove和get方法。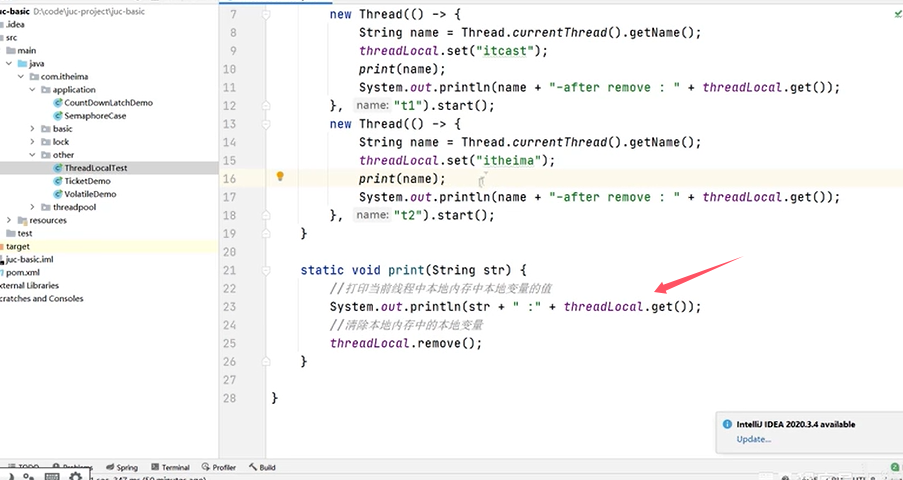
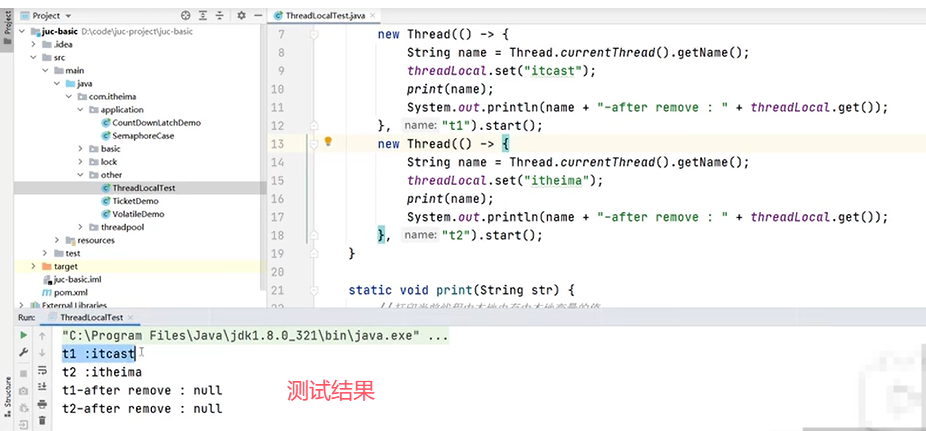
可以看到,同一个线程内都可以通过ThreadLocal获取到对应的String对象并进行相关操作,线程之间互相隔离。
ThreadLocal中的数据底层是存在ThreadLocalMap中的。
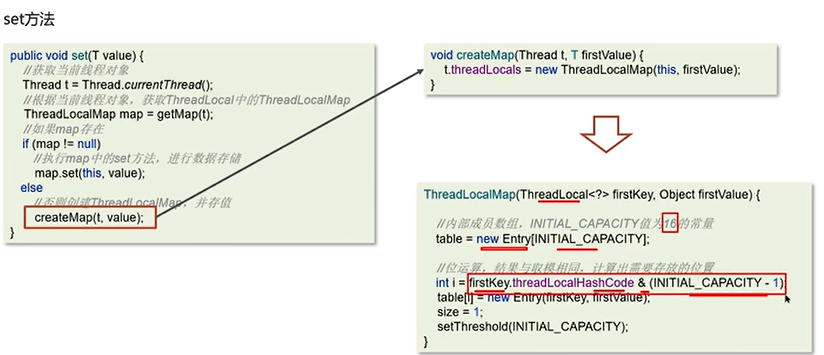

Q3补充:ThreadLocal的内存泄露问题?



四、中间件
4.1 redis
4.1.1 如何保证redis和mysql的强一致性?
在真实的互联网生产环境中,几乎无法保证,也不需要保证Redis和MySQL数据的“强一致性”。追求强一致性(即任何时刻两者数据都绝对相同)会带来巨大的性能开销和系统复杂度,通常得不偿失。更务实的做法是追求“最终一致性”。面试官问这个问题,其实是希望考察你是否了解CAP理论,以及在实际项目中如何根据业务场景选择合适的一致性方案。
CAP定理。在分布式系统中,一致性、可用性、分区容错性三者最多只能同时满足两个。
分区容错性:是分布式系统的必选项,因为网络总是可能出问题。
可用性:我们希望系统始终能对外提供服务。
一致性:追求强一致性,往往需要牺牲可用性(比如,在数据同步期间锁定资源,不对外服务)。
因此,大部分互联网系统为了保证高可用,会选择AP(可用性+分区容错性),而放弃强一致性,转而追求最终一致性。
1.常见的(但不够好)解决方案
面试时,可以先说出最常见的两种方案,并指出它们的致命缺陷,这能体现你的思考深度。
先更新MySQL,再删除/更新Redis(最常见)
这是最常用的策略,但无法保证强一致性。
2. 生产级的可靠方案:基于Binlog的最终一致性
缓存只作为读加速,写入以MySQL为准,然后通过监听MySQL的Binlog来异步更新或删除缓存。
这个方案的核心思想是:让MySQL成为唯一的事实来源.
3.业务真的要求“强一致性”
这时,不能依赖“Redis + MySQL”这种组合来保证强一致性。正确的做法是:
放弃使用缓存:直接读MySQL。MySQL的ACID特性才是强一致性的正确保障。
使用分布式锁:读写请求都先获取同一个Key的分布式锁(如Redis的RedLock或ZooKeeper),保证同一时刻只有一个请求在操作这个数据。这会严重影响性能和吞吐量。
版本号校验:在Redis中存储数据时,同时存储版本号(或时间戳)。更新时,使用CAS(Compare-And-Swap)操作,只有当传入的版本号与Redis当前版本号一致时才允许覆盖。这只能解决并发写冲突,不能保证与MySQL的绝对一致。
Q1:redis集群有哪些方案?

(1)主从复制
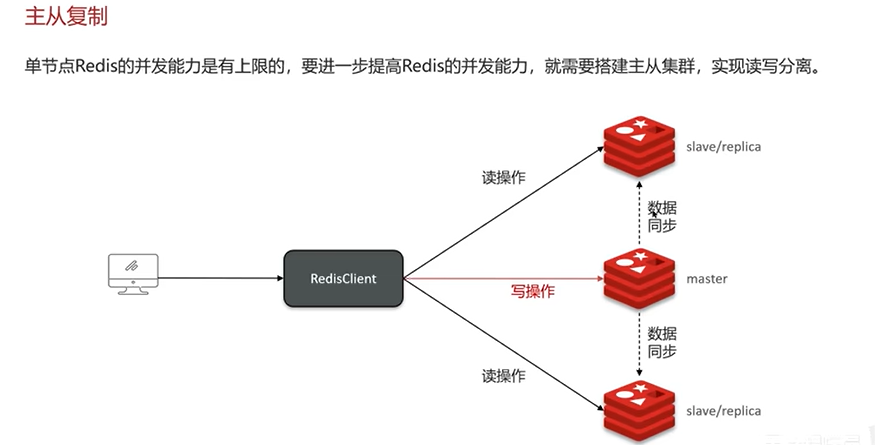
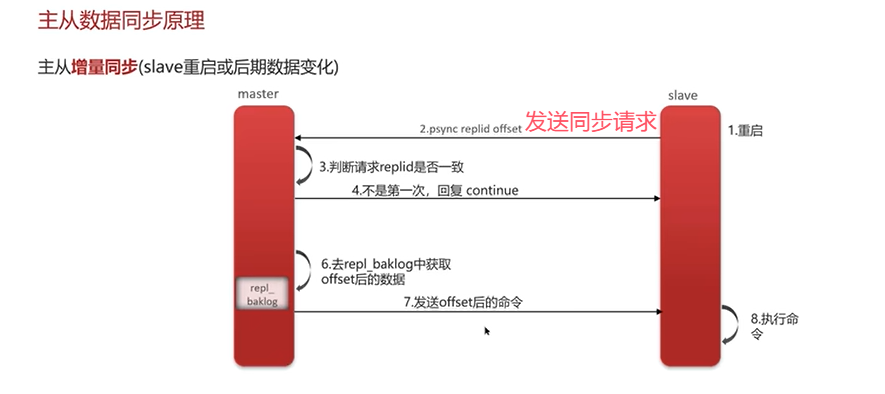
主节点的写操作执行完后需要把数据同步给从节点。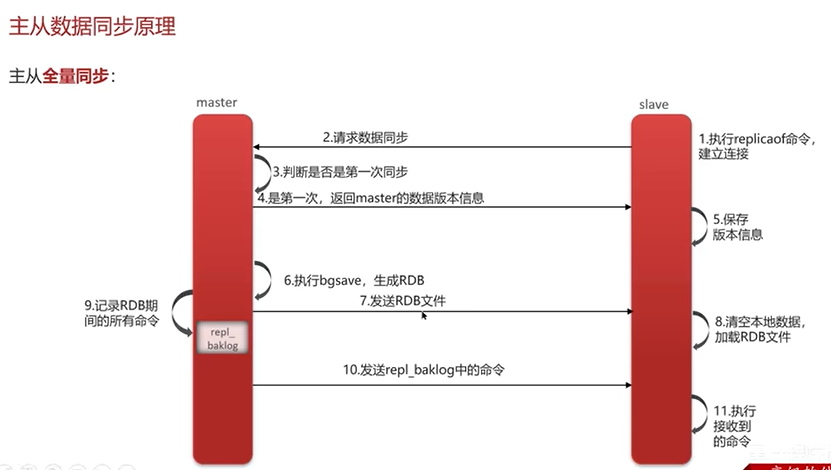


(2)哨兵模式
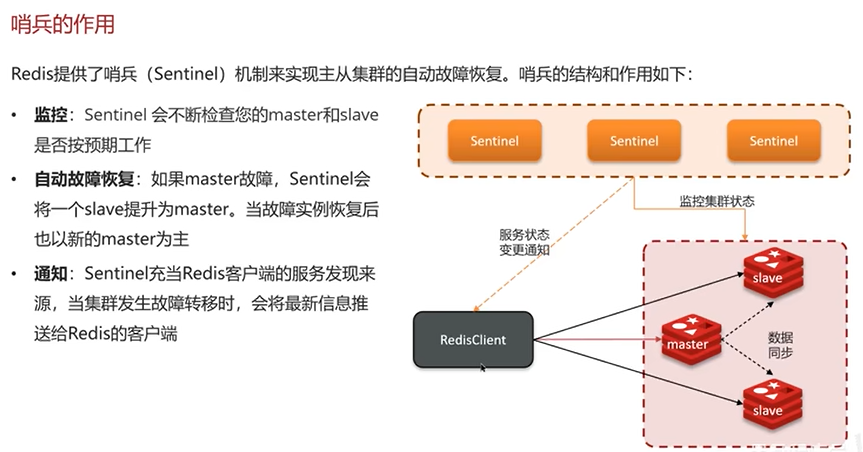


(3)分片集群




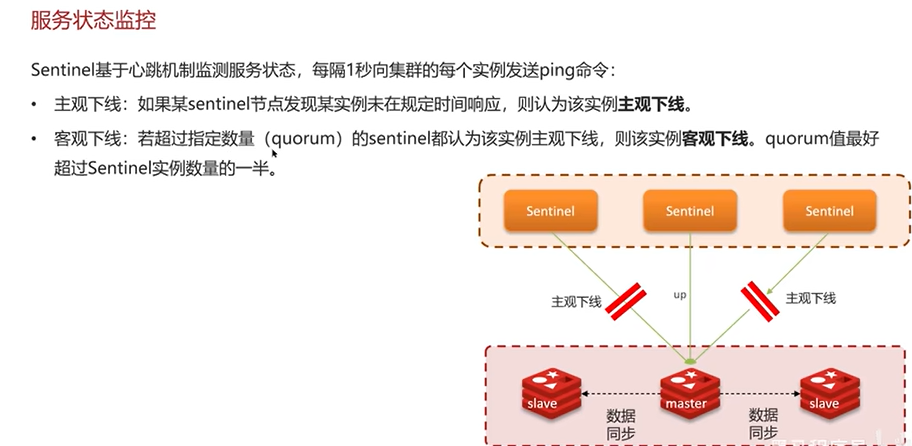
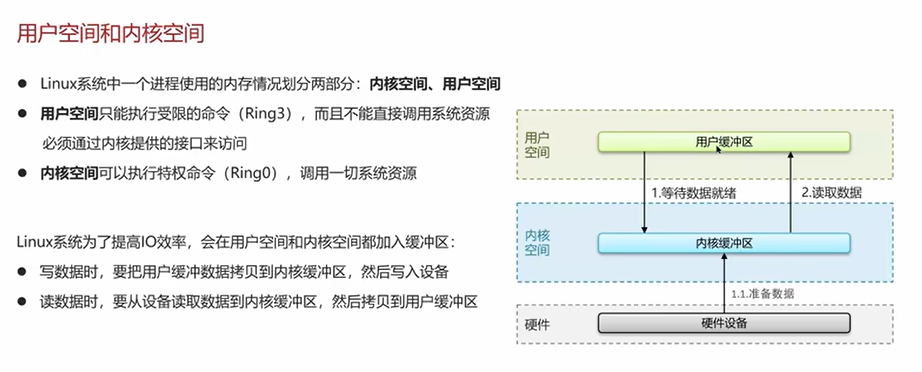
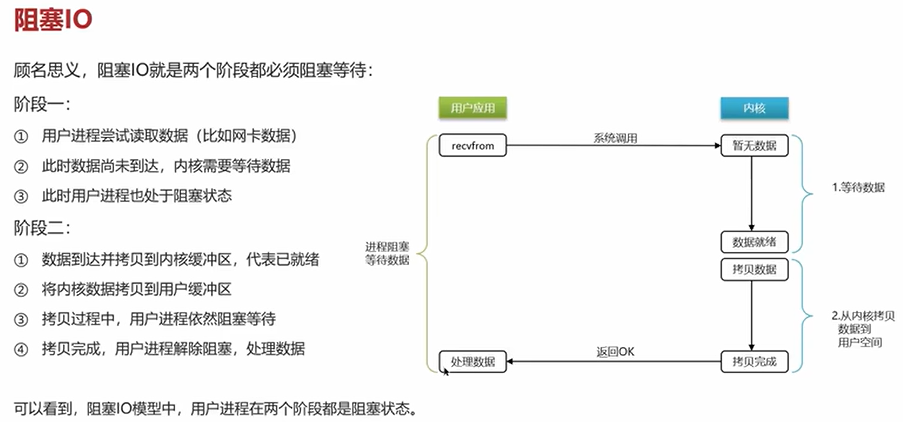
Q2:Redis是单线程的,但是为什么还是那么快?

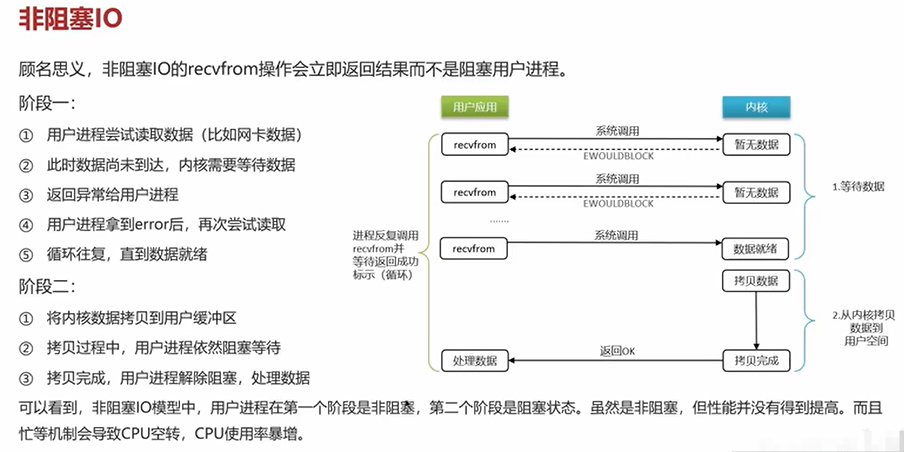
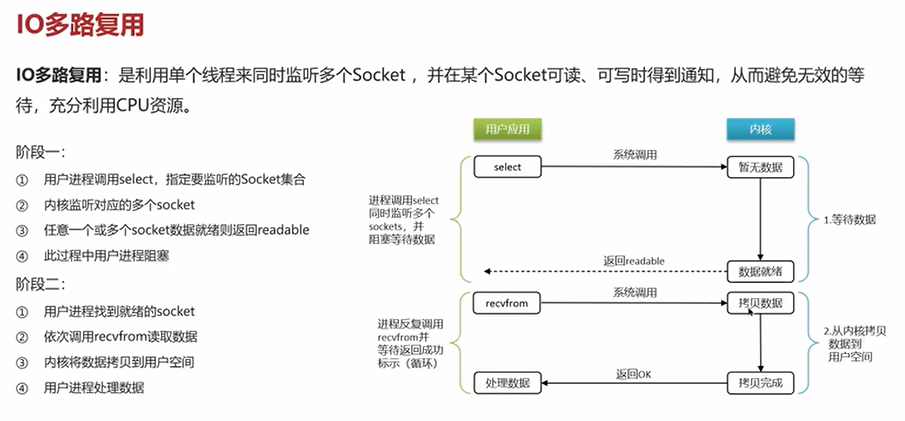
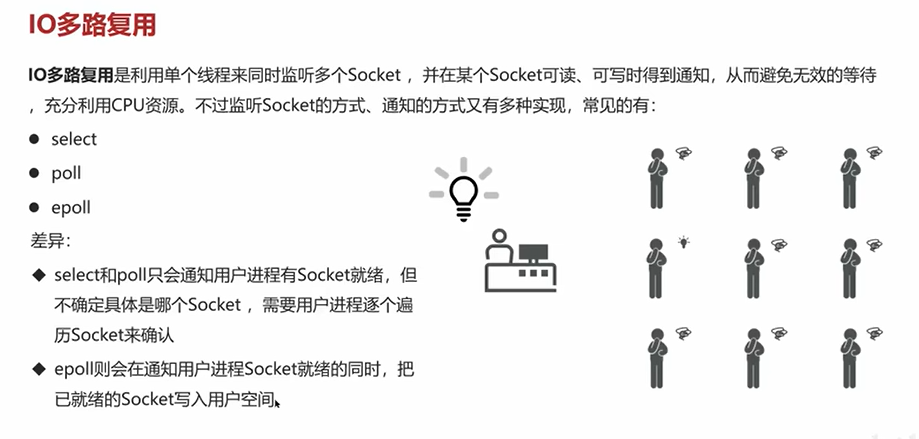
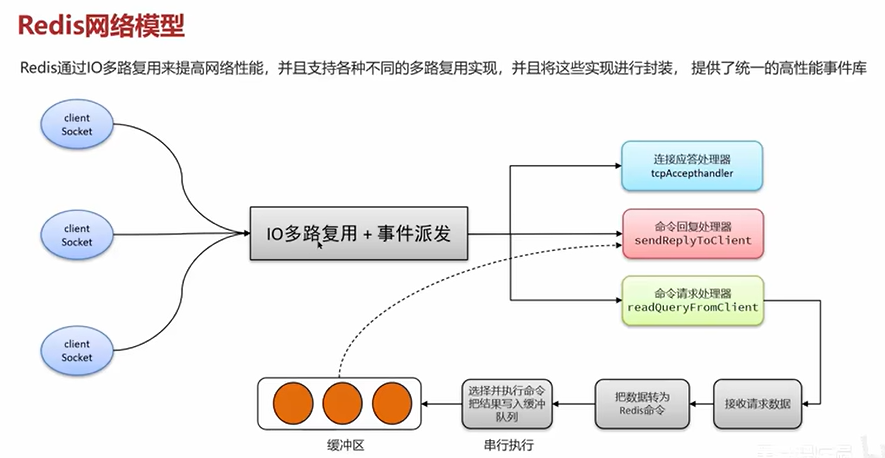

4.2 rabbitmq
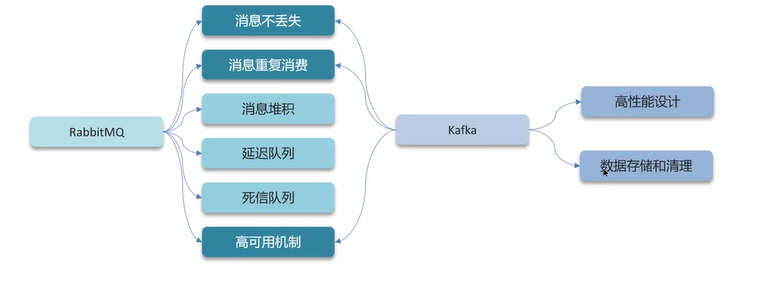
kafka的吞吐量极高,可以达到百万级别。
Q1:RabbitMQ如何保证消息不丢失?
rabbitmq的使用场景包括异步发送(验证码、短信、邮件…)、MySQL和Redis及ES之间的数据同步、分布式事务、削峰填谷。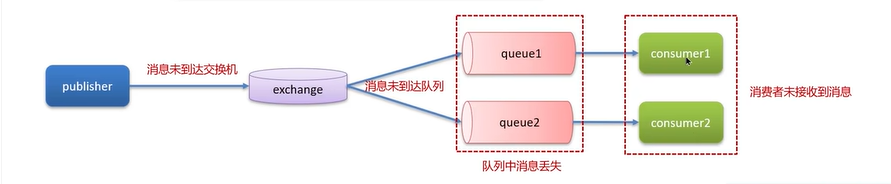
有3个层面会导致消息丢失:
(1)生产者发送的消息未达到交换机exchange或未到达队列。
(2)mq宕机导致消息丢失。
(3)消费者服务宕机导致消息丢失。
对于问题(1),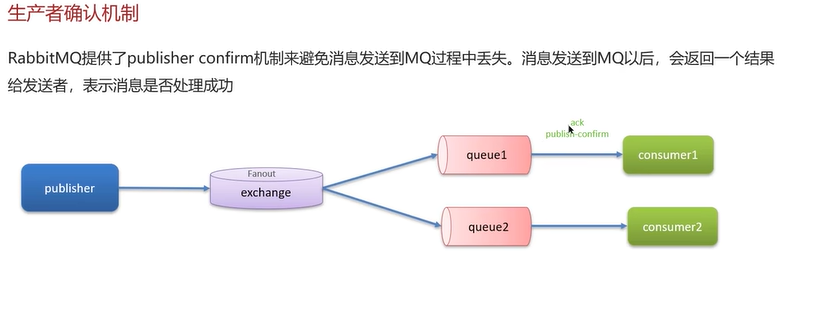
当消息正常发送到队列后会返回一个publish-confirm ack(ack即acknowledge)给生产者,如果消息发送失败(有两种情况,发送到交换机失败和发送到队列失败),会返回两种提示信息publish-confirm nack和publish-return ack。
对于问题(2),是开启mq持久化。
对于问题(3),使用消费者确认机制。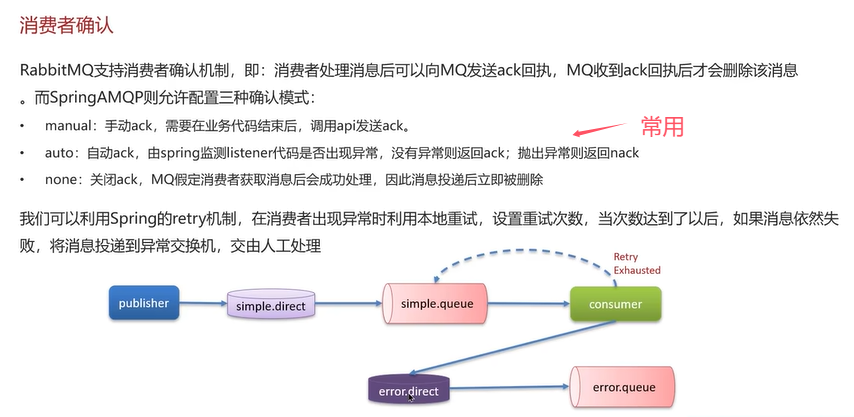

Q2:RabbitMQ消息重复消费问题如何解决?
一般是由网络抖动或者消费者宕机导致。
例如,当消费者消费完消息后突然宕机,还没有完成自动确认。
唯一标识ID由消费者检查ID是否存在。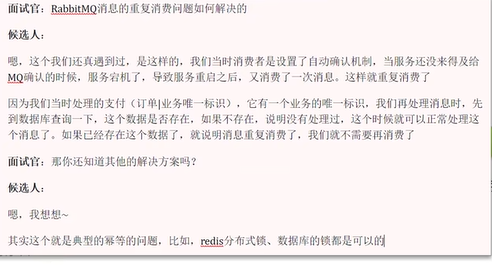
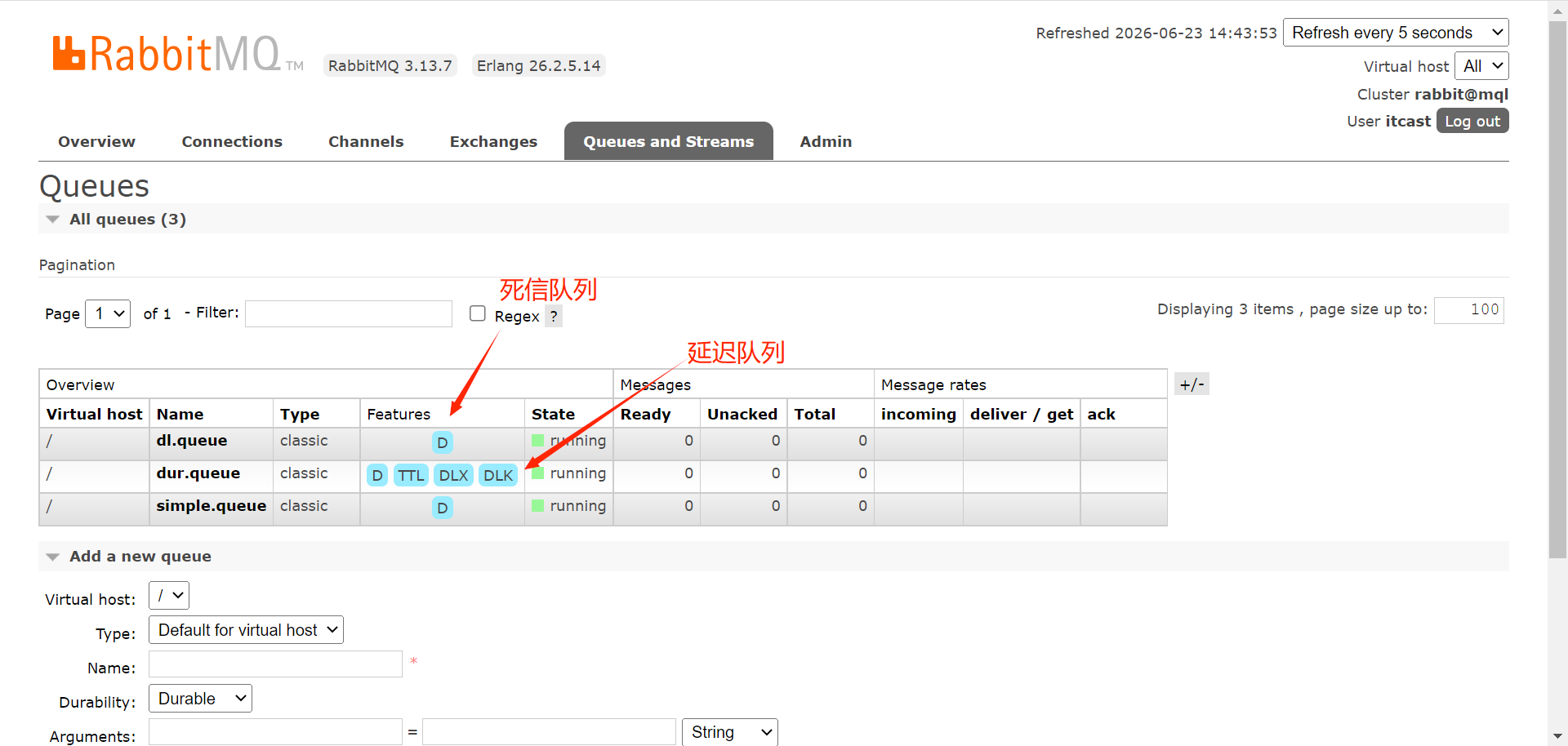
Q3:RabbitMQ延迟队列有了解过吗?RabbitMQ种死信交换机呢?
延时队列的使用场景为超市订单、定时发布等。
延迟队列=死信交换机+TTL(生存时间)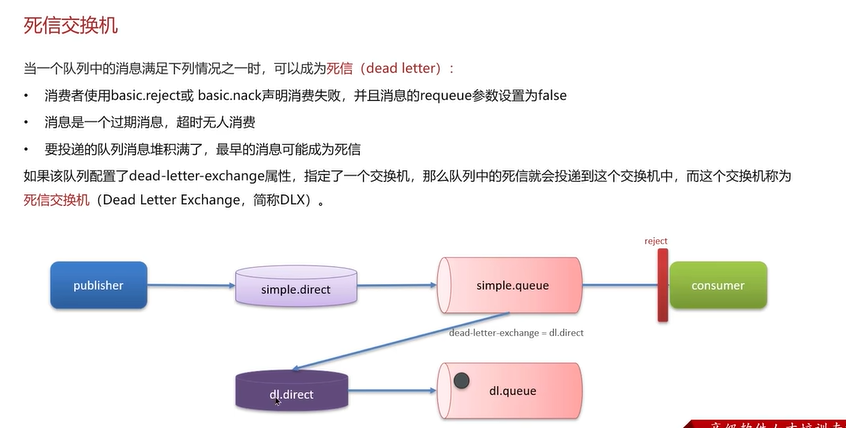
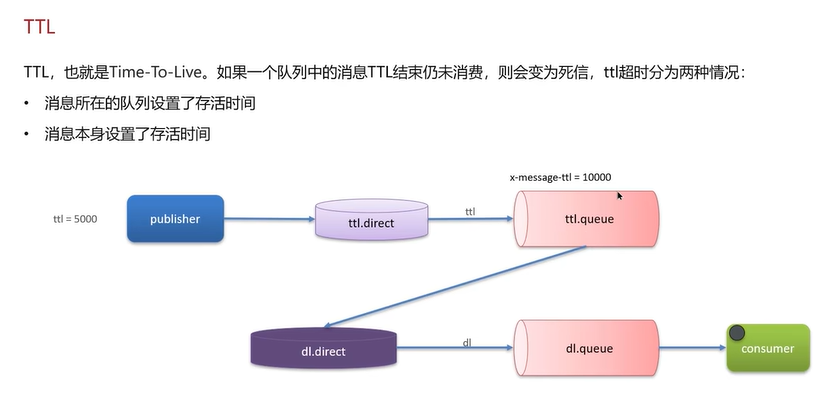
延迟时间以消息队列存活时间和消息本身存活时间的较小值。
用一个例子说明死信队列的使用:
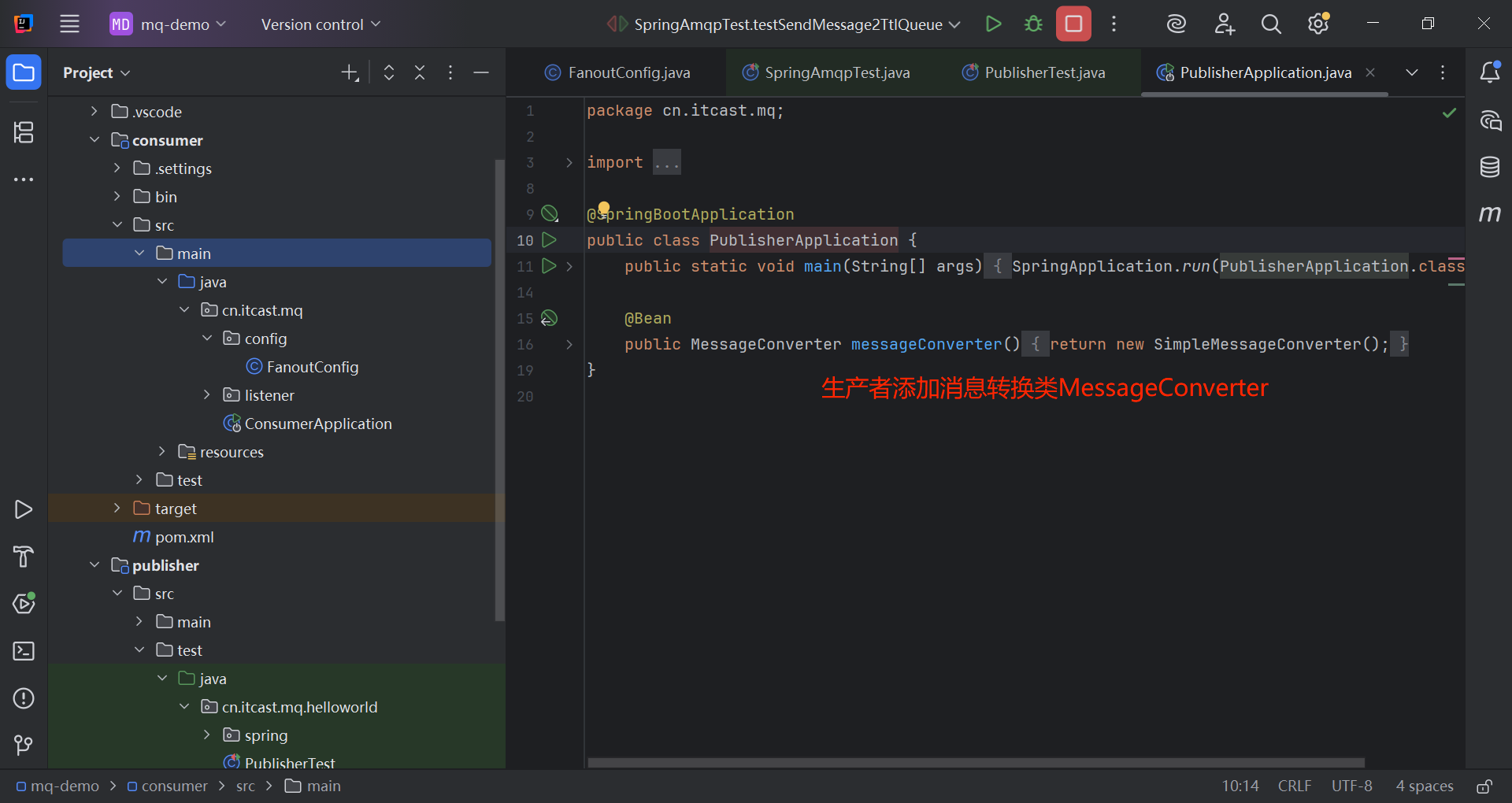
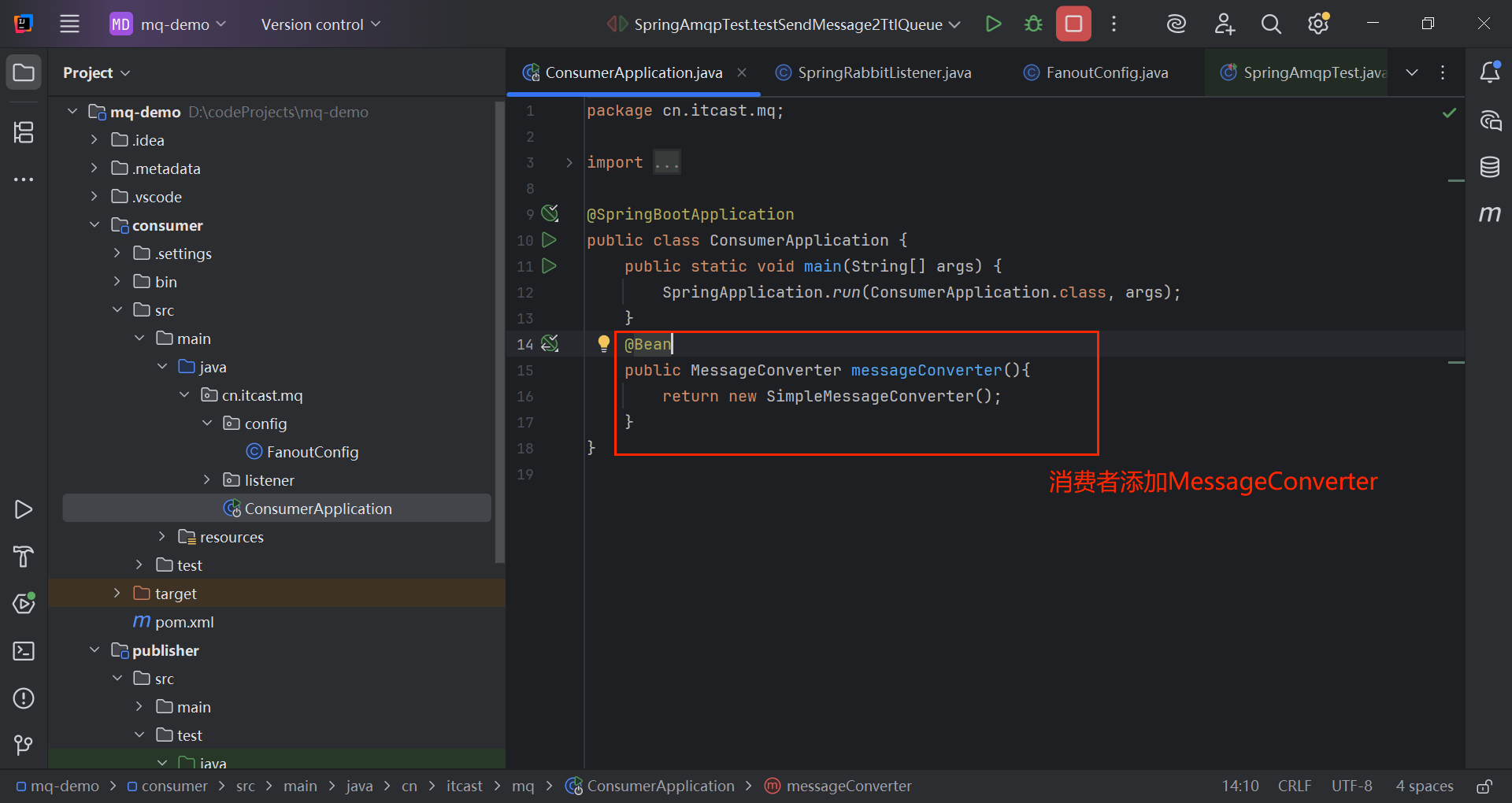
@Bean
public MessageConverter messageConverter(){
return new SimpleMessageConverter();
}
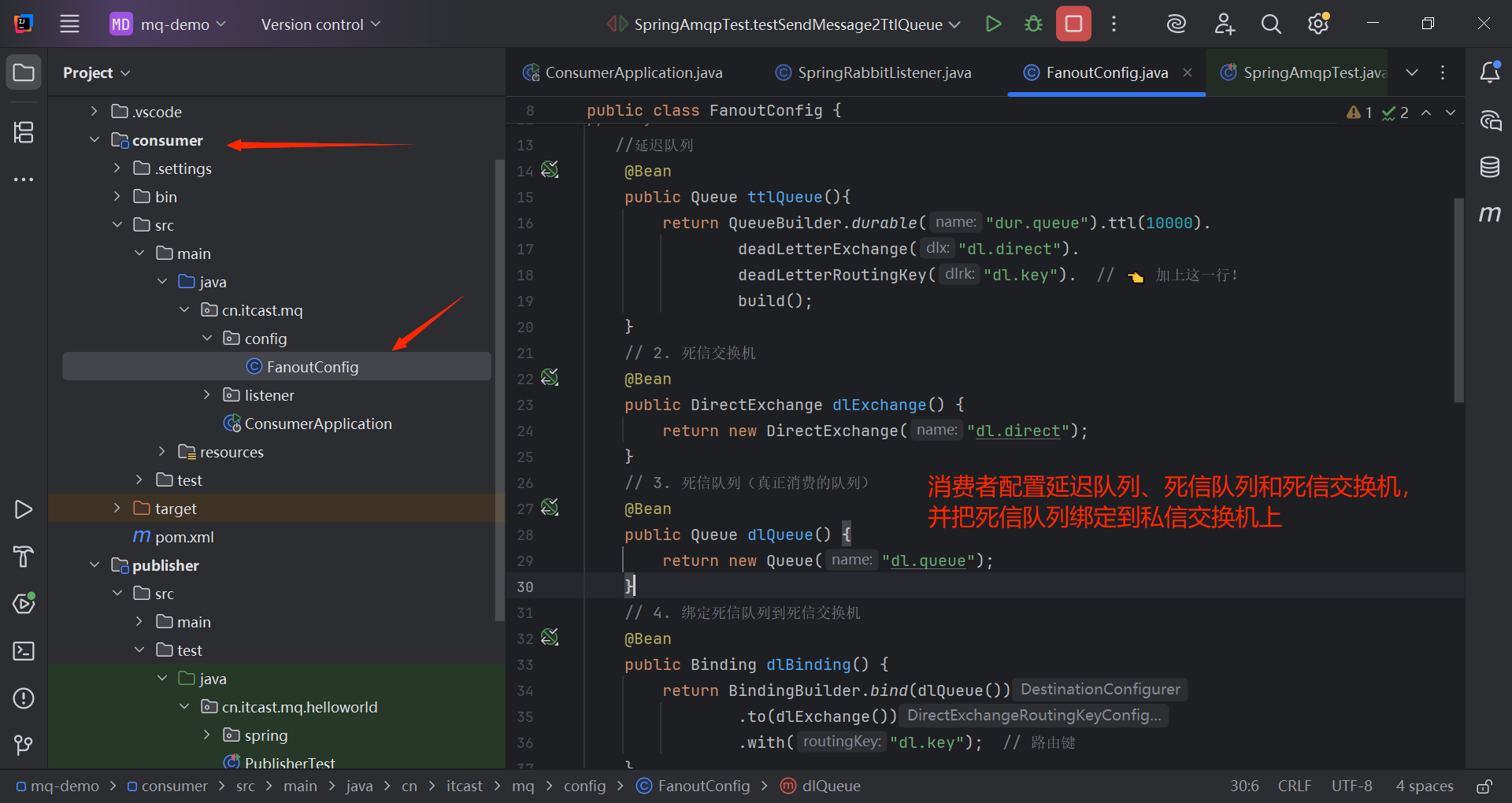
//延迟队列
@Bean
public Queue ttlQueue(){
return QueueBuilder.durable("dur.queue").ttl(10000).
deadLetterExchange("dl.direct").
deadLetterRoutingKey("dl.key"). // 👈 加上这一行!
build();
}
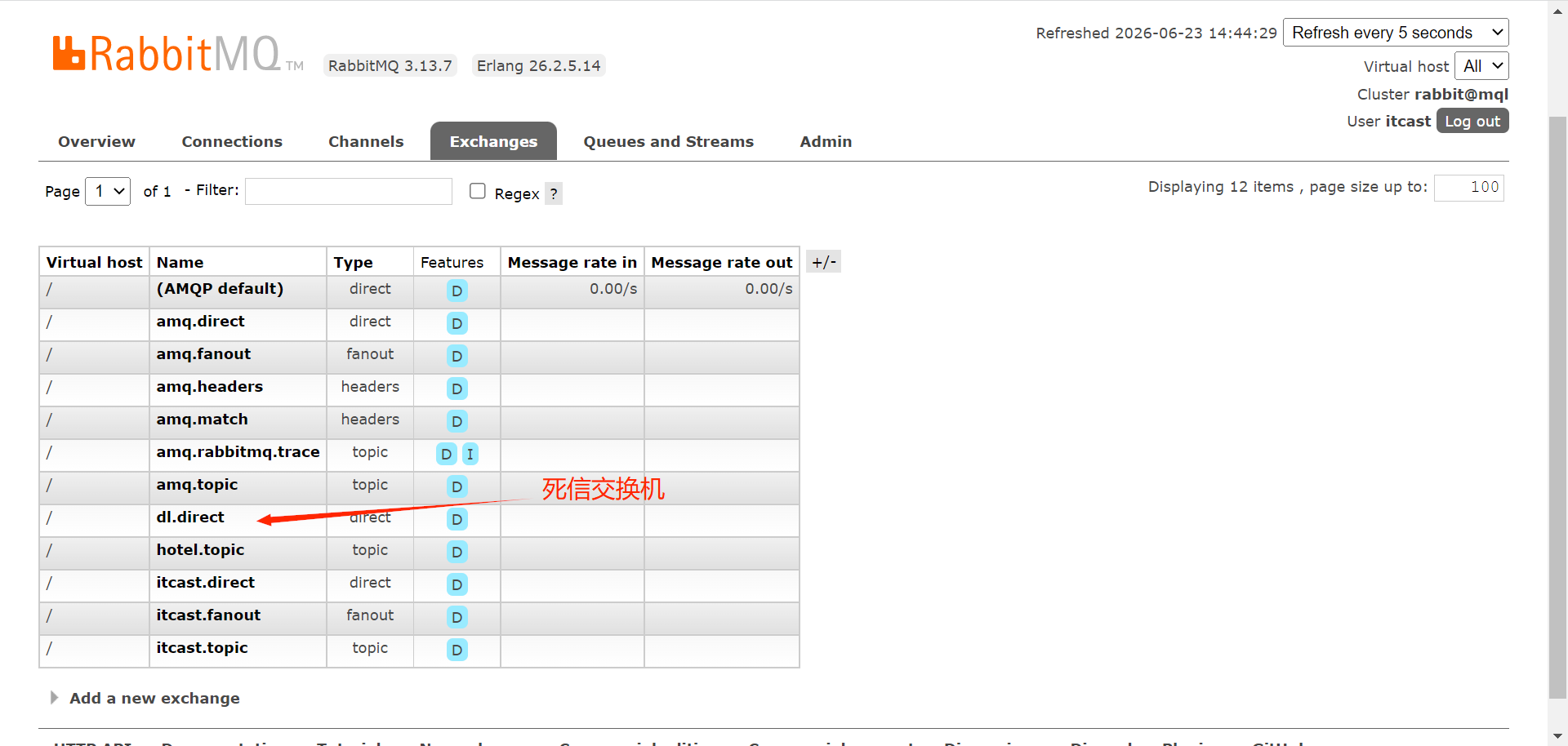
// 2. 死信交换机
@Bean
public DirectExchange dlExchange() {
return new DirectExchange("dl.direct");
}
// 3. 死信队列(真正消费的队列)
@Bean
public Queue dlQueue() {
return new Queue("dl.queue");
}
// 4. 绑定死信队列到死信交换机
@Bean
public Binding dlBinding() {
return BindingBuilder.bind(dlQueue())
.to(dlExchange())
.with("dl.key"); // 路由键
}
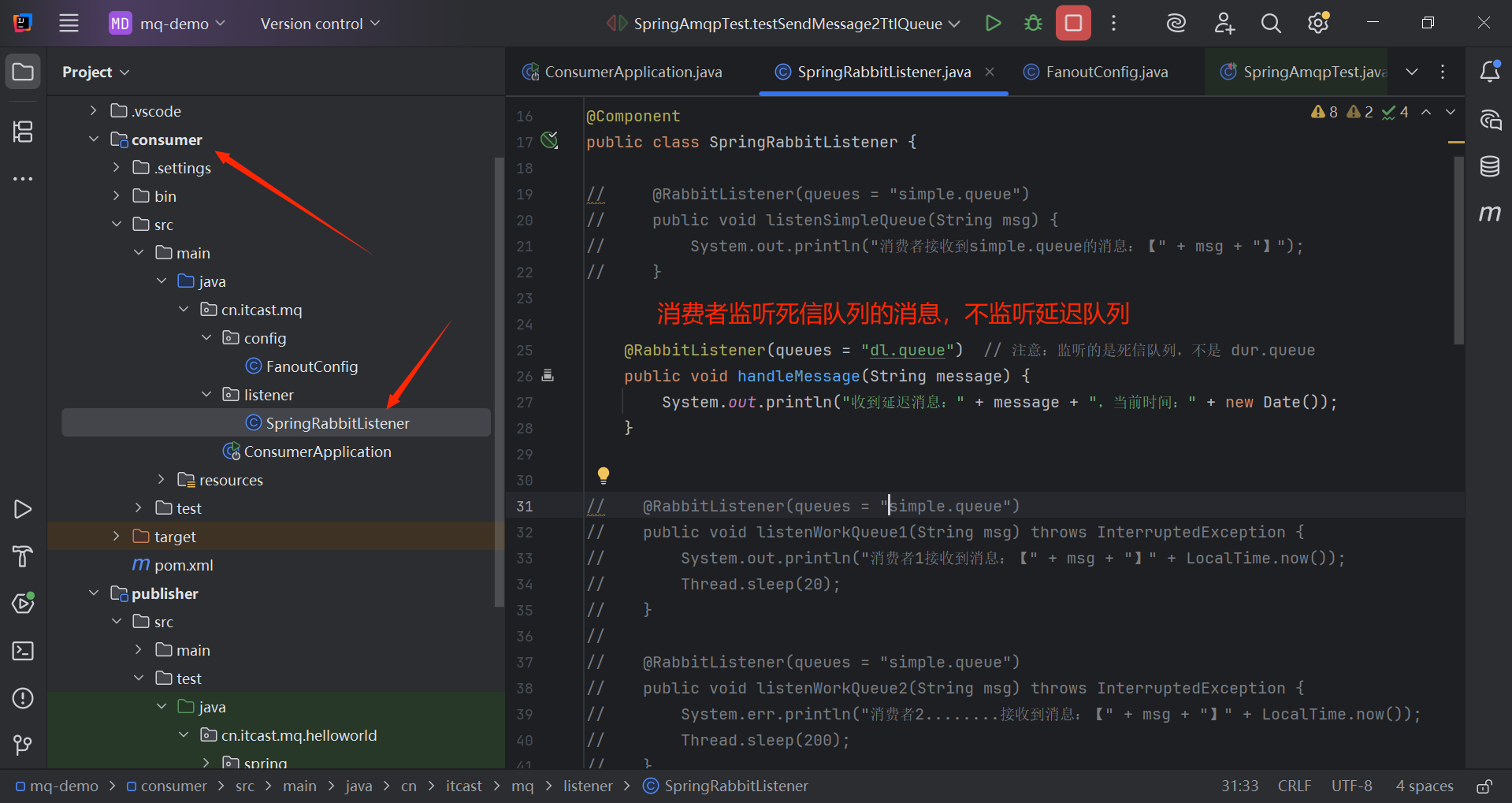
@RabbitListener(queues = "dl.queue") // 注意:监听的是死信队列,不是 dur.queue
public void handleMessage(String message) {
System.out.println("收到延迟消息:" + message + ",当前时间:" + new Date());
}
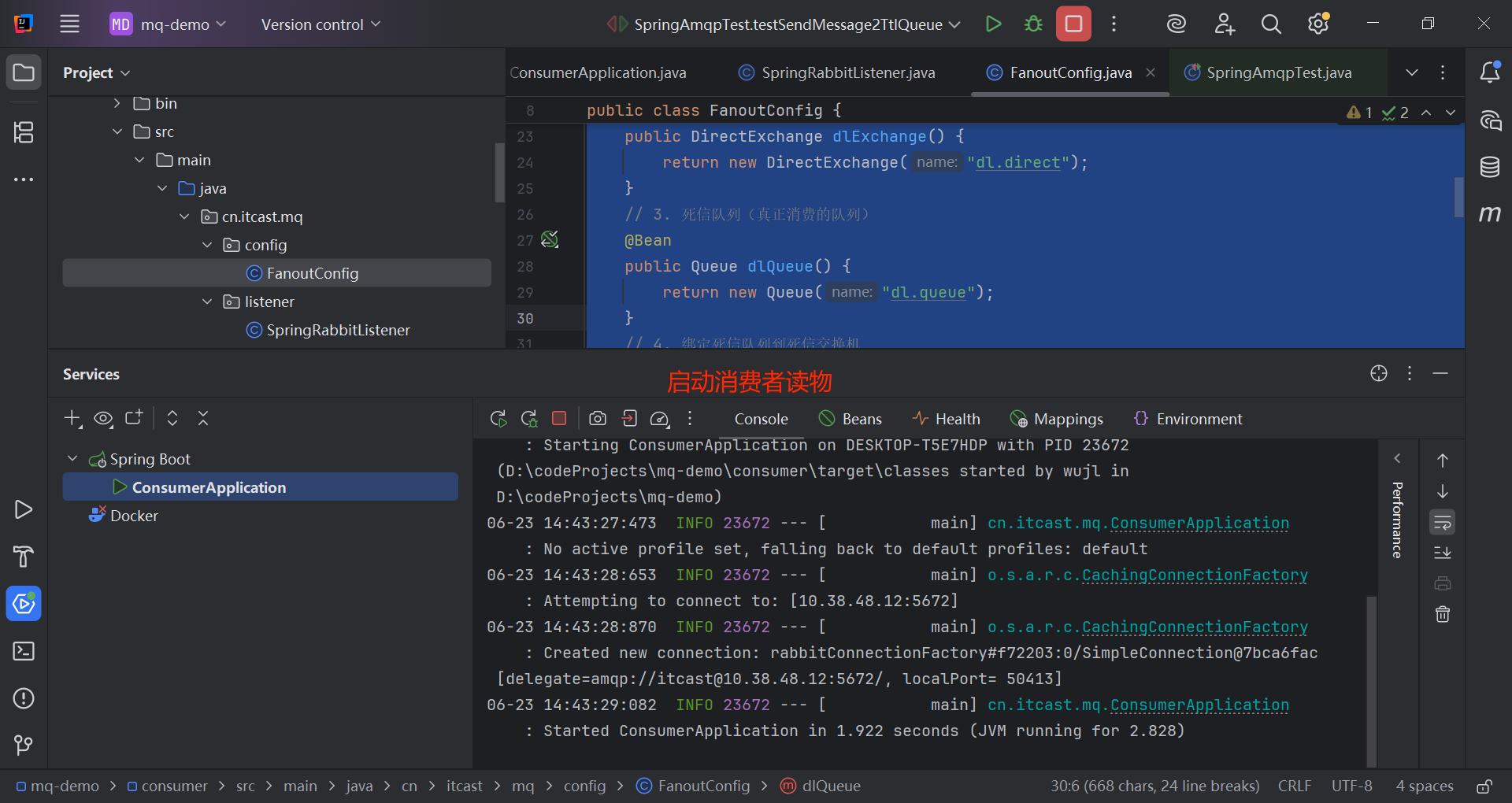
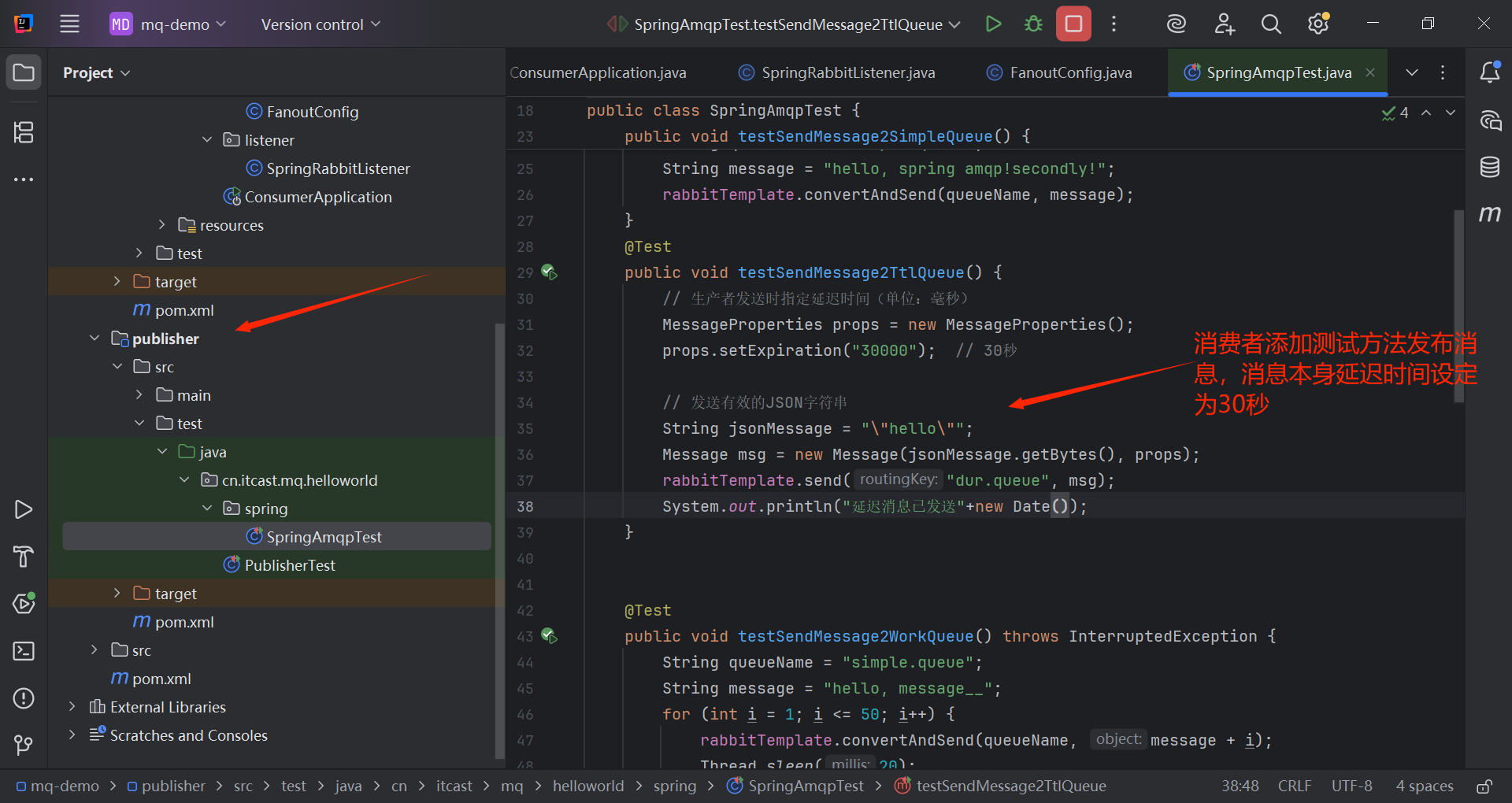
@Test
public void testSendMessage2TtlQueue() {
// 生产者发送时指定延迟时间(单位:毫秒)
MessageProperties props = new MessageProperties();
props.setExpiration("30000"); // 30秒
// 发送有效的JSON字符串
String jsonMessage = "\"hello\"";
Message msg = new Message(jsonMessage.getBytes(), props);
rabbitTemplate.send("dur.queue", msg);
System.out.println("延迟消息已发送"+new Date());
}
运行测试方法发送消息: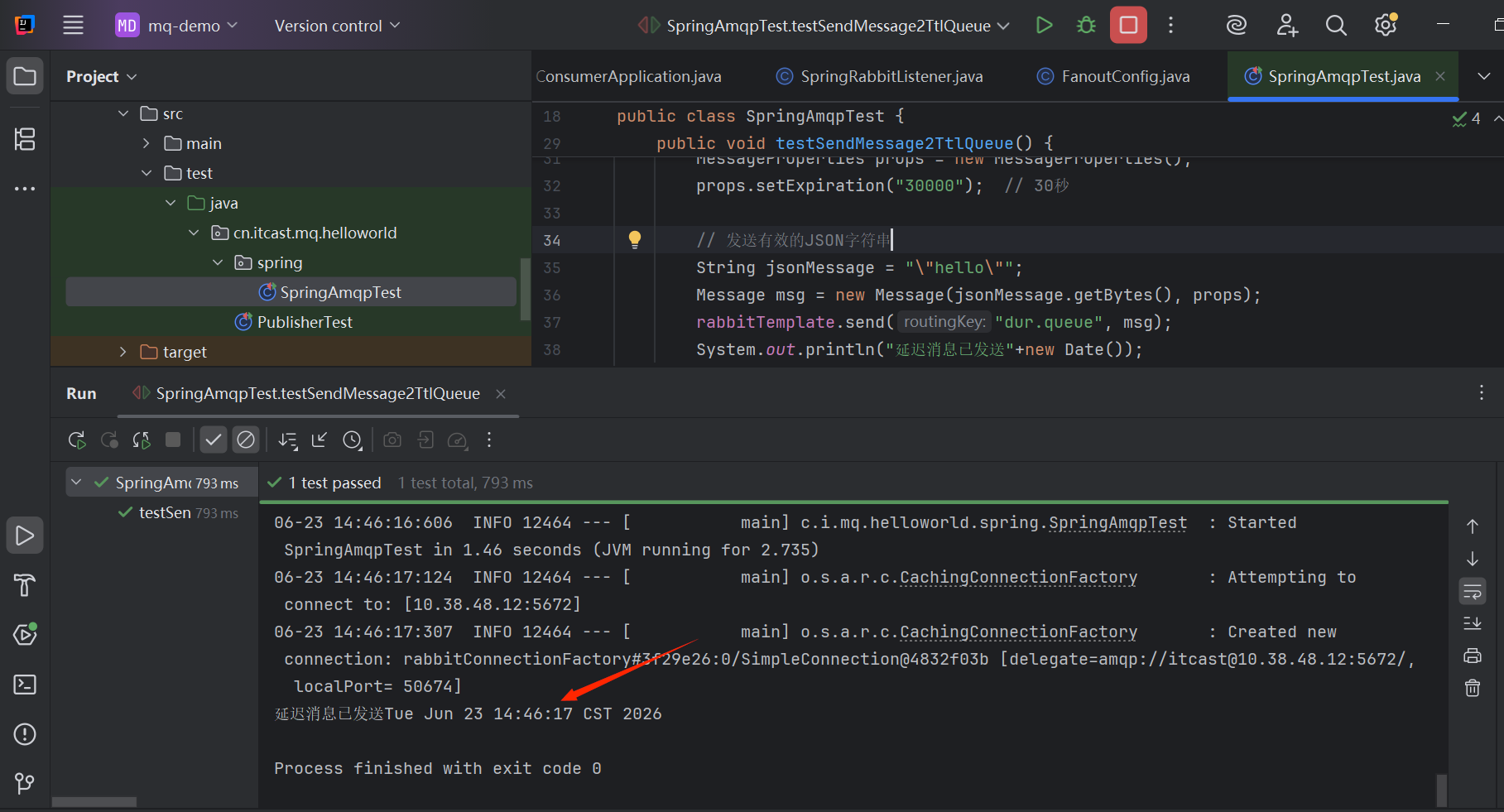
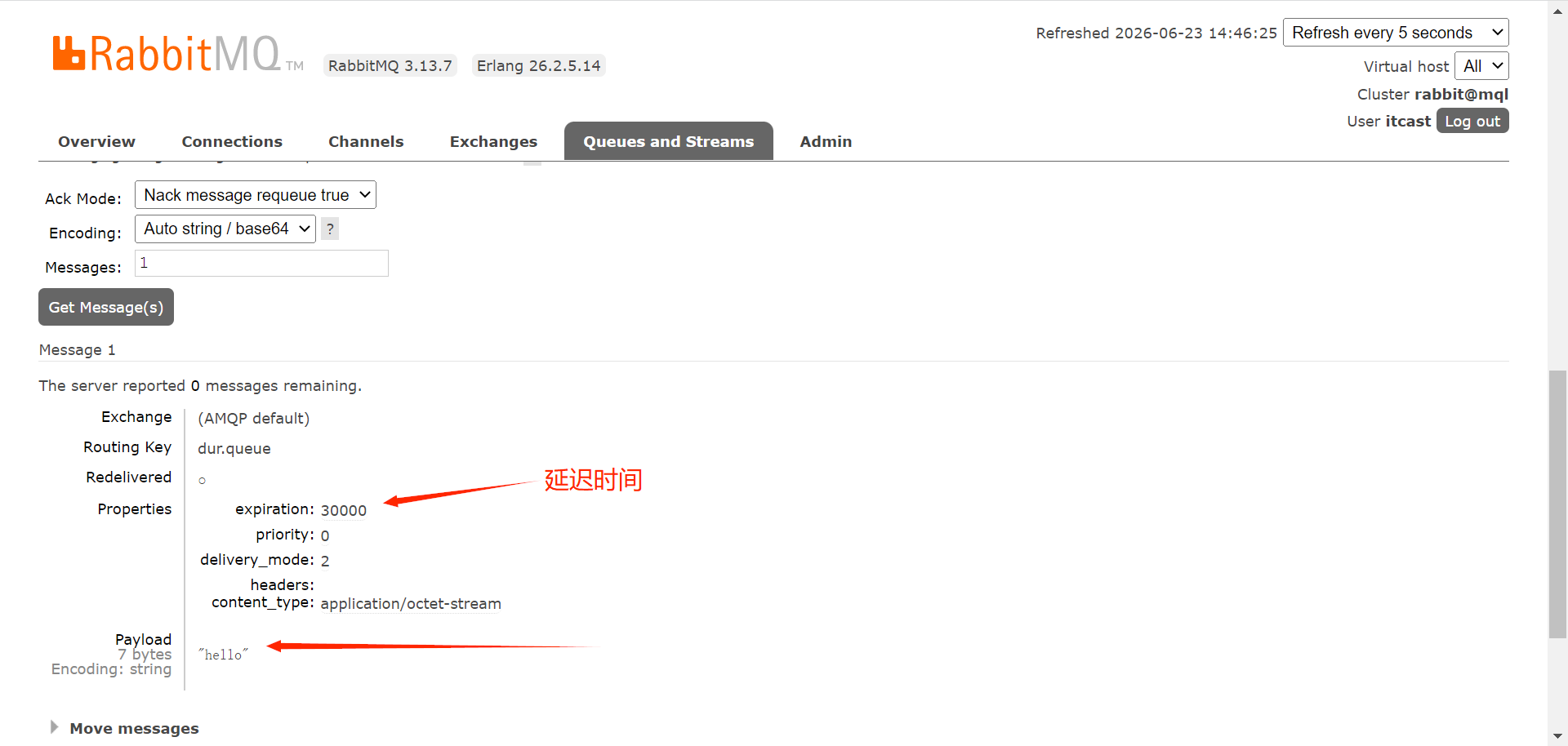
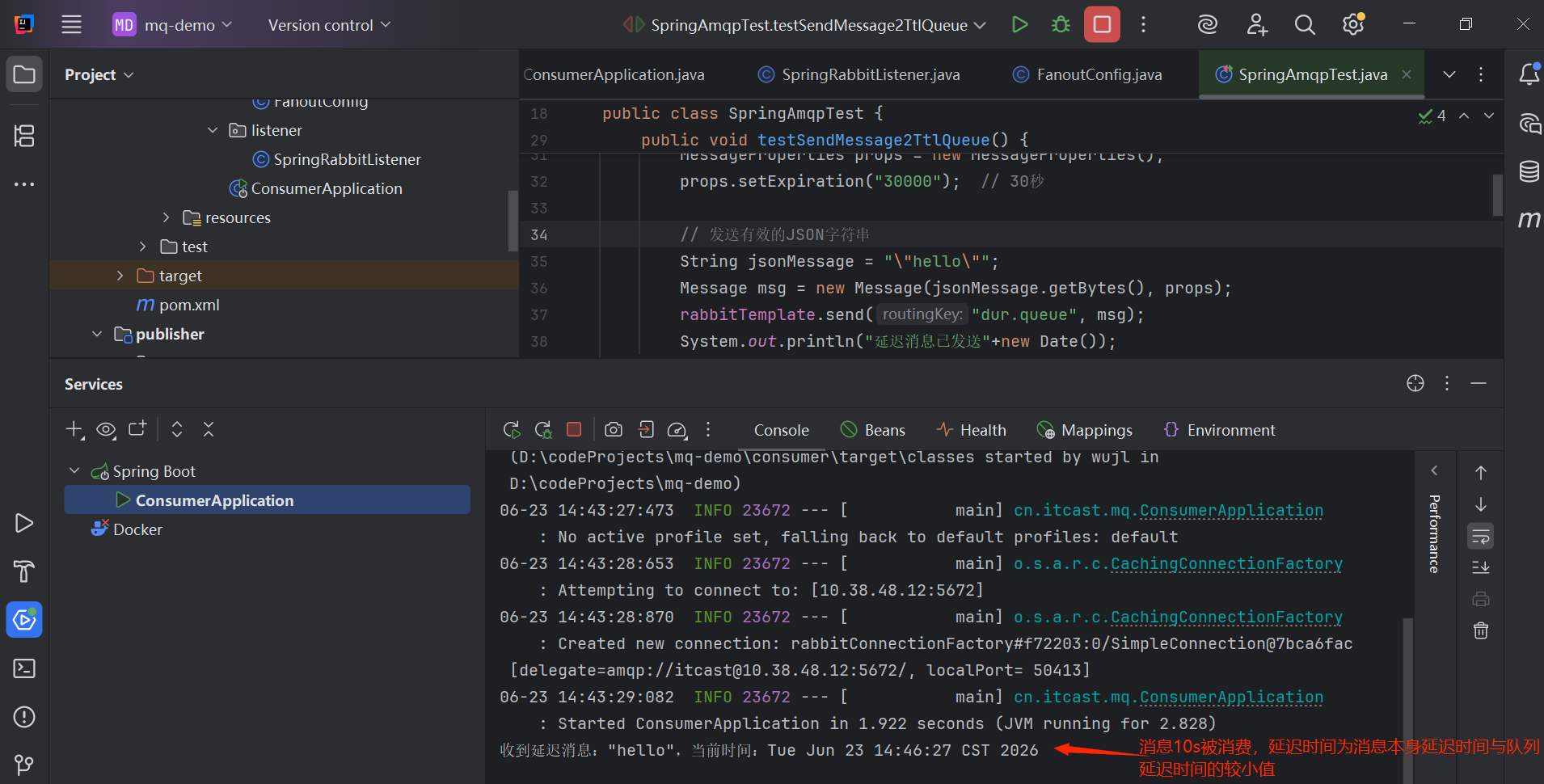
RabbitMQ中还有另一种实现延迟队列的方法,使用延迟队列插件,可以安装到rabbitmq。
安装完延迟队列的插件后使用延迟队列很简单: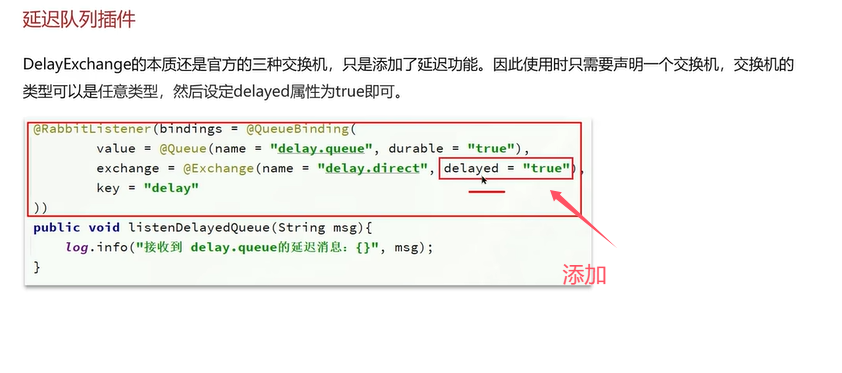
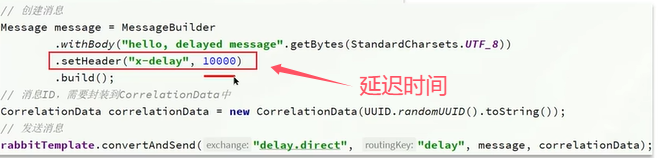

Q4:RabbitMQ如果有100万消息堆积在MQ,如何解决?
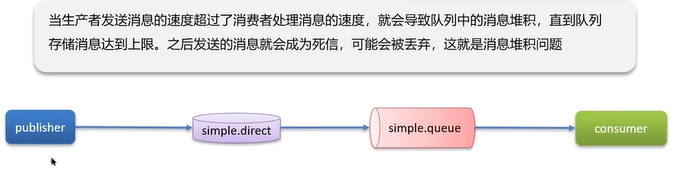

对于第3中解决思路:

Q5:RabbitMQ的高可用机制?
在生产环境中,使用集群来保证高可用性,包括普通集群镜像集群、冲裁队列。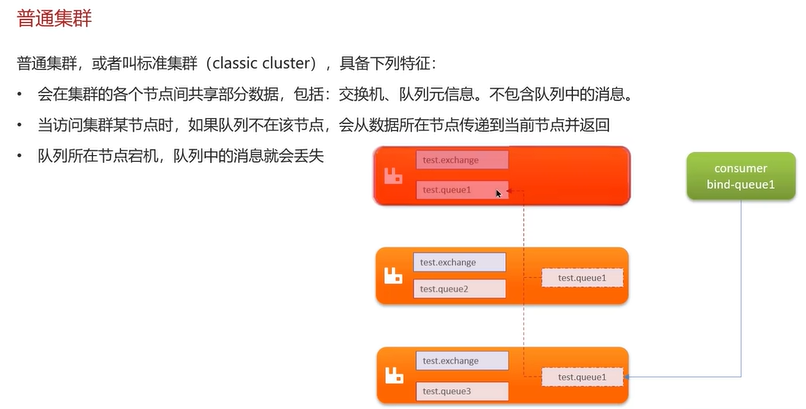
普通集群很少采用。
镜像集群存在一个问题,主机点数据更新后还未来得及给镜像节点同步数据就宕机了,这种情况很少见,解决方式是使用仲裁队列。


4.3 kafka
Q1:kafka是如何保证消息不丢失?
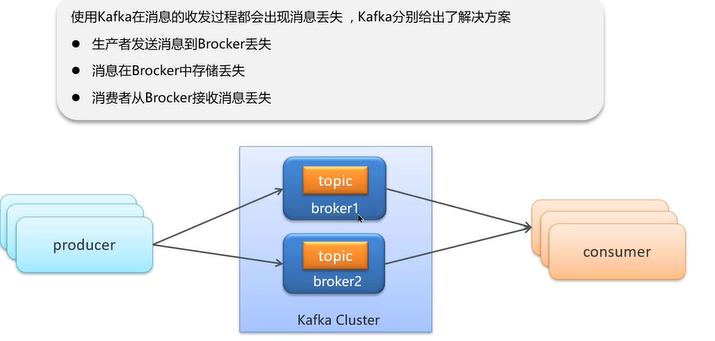
三种消息丢失的情况解决方法如下:
五、MySQL数据库
1.索引失效的情况
从MySQL执行引擎的视角,讲清楚“为什么”会失效。核心原理一句话:MySQL优化器判断走索引的“代价”比全表扫描还大,或者优化器无法从索引中有效缩小数据范围(优化器通过统计信息(Cardinality)估算, 不需要执行实际查询)时,就会放弃使用索引。
下面是最常见的10种索引失效情况,按从高频到低频排序:
1. 最左前缀法则失效(最常见)
这是联合索引最核心的规则。比如有一个联合索引 (name, age, city):
有效:name = ‘A’、name = ‘A’ and age = 20、name = ‘A’ and age = 20 and city = ‘BJ’
失效:跳过最左边的列,例如 age = 20(没带name),city = ‘BJ’(没带name和age)。
部分失效:name = ‘A’ and city = ‘BJ’ → 只会用name这一部分,city的索引无法用(因为跳过了age)。
2. 在索引列上做了计算、函数或类型转换
函数:WHERE DATE(create_time) = ‘2024-01-01’ → 对create_time用了DATE()函数,索引失效。应改为 create_time BETWEEN ‘2024-01-01 00:00:00’ AND ‘2024-01-01 23:59:59’。
计算:WHERE id + 1 = 10 → 对索引列id做了加法,失效。应改为 id = 9。
类型隐式转换:WHERE phone = 13800001234,但phone字段是varchar类型。MySQL会把数字转成字符串比较,相当于 CAST(phone AS UNSIGNED) = 13800001234,导致失效。应改为 WHERE phone = ‘13800001234’。
3. 使用 LIKE 且通配符 % 在开头
WHERE name LIKE ‘%张三’ → 失效,因为MySQL不知道前面是什么字符,无法从B+树的根节点开始定位。
WHERE name LIKE ‘张三%’ → 有效,可以走索引。
WHERE name LIKE ‘%张三%’ → 一定失效。
4. 使用 OR 连接条件
当OR的两边不全是有索引的列时,索引会失效。
失效例子:WHERE name = ‘张三’ OR age = 20,如果age没有索引,MySQL会放弃索引走全表扫描。
有效(但少见):WHERE name = ‘张三’ OR id = 20,且name和id都有索引,MySQL可能会用index_merge(索引合并)。
5. NOT 操作(<>、!=、NOT IN、NOT EXISTS)
对于普通索引,<> 表示“不等于”,结果集非常大,优化器认为走索引意义不大,通常走全表扫描。
特例:如果某个值占了99%的数据,<>那个值反而只查1%的数据,理论上可能走索引,但一般不建议依赖这种优化。
!=与<>完全一样。
NOT IN —— 最差,有 NULL 陷阱。
-- 假设 subquery 返回 (1, 2, NULL)
SELECT * FROM main WHERE id NOT IN (SELECT id FROM sub);
-- 实际返回:空集!(因为 NULL 参与 NOT IN 会整体变成 UNKNOWN)
因为 NOT IN 遇到 NULL 时,整个条件变成 UNKNOWN,所以查不到任何数据。这往往不是你想要的结果。
NOT EXISTS —— 相对最好
SELECT * FROM main m
WHERE NOT EXISTS (SELECT 1 FROM sub s WHERE s.id = m.id);
优点:
没有 NULL 问题:子查询只要存在一行匹配就返回,不受 NULL 影响。
优化器更友好:MySQL 8.0+ 会将 NOT EXISTS 优化为 Anti Join,可能使用 main 表和 sub 表的索引进行半连接扫描。
能提前终止:对 main 的每一行,子查询找到第一条匹配就停止,不需要扫描全部 sub 数据。
6. 使用 IS NULL 或 IS NOT NULL
IS NULL:对于普通列,通常可以走索引。
IS NOT NULL:大概率失效,因为匹配的行数太多。但如果NULL值极少(比如只有1行是NULL,其他都是值),也可能走索引。
7.IN 或 EXISTS 中的子查询数据量过大
如果IN后面的子查询返回大量结果(比如几万行),MySQL可能认为全表扫描更快,从而不走索引。
另外,IN列表中的值很多(比如上万个)也会导致优化器放弃索引。
9. 范围查询后,后面的列无法使用索引(联合索引)
对于联合索引 (a, b, c):
WHERE a = 1 AND b > 10 AND c = 3 → a能用到索引,b能用到索引(范围),c失效(因为B+树中,b变成范围后,c不再有序)。
解决方案:调整索引顺序,把等值查询的列放前面,范围查询的列放后面。
如何确认索引失效?
使用 EXPLAIN 分析:看type字段,如果是ALL就是全表扫描(失效);ref或range通常有效;possible_keys有值但key是NULL说明优化器放弃了。
2. 存储引擎
数据库存储引擎是底层负责数据的存储、提取、事务、索引等核心操作的软件模块。它决定了数据如何组织、如何加锁、是否支持事务、如何优化查询。
常见存储引擎对比: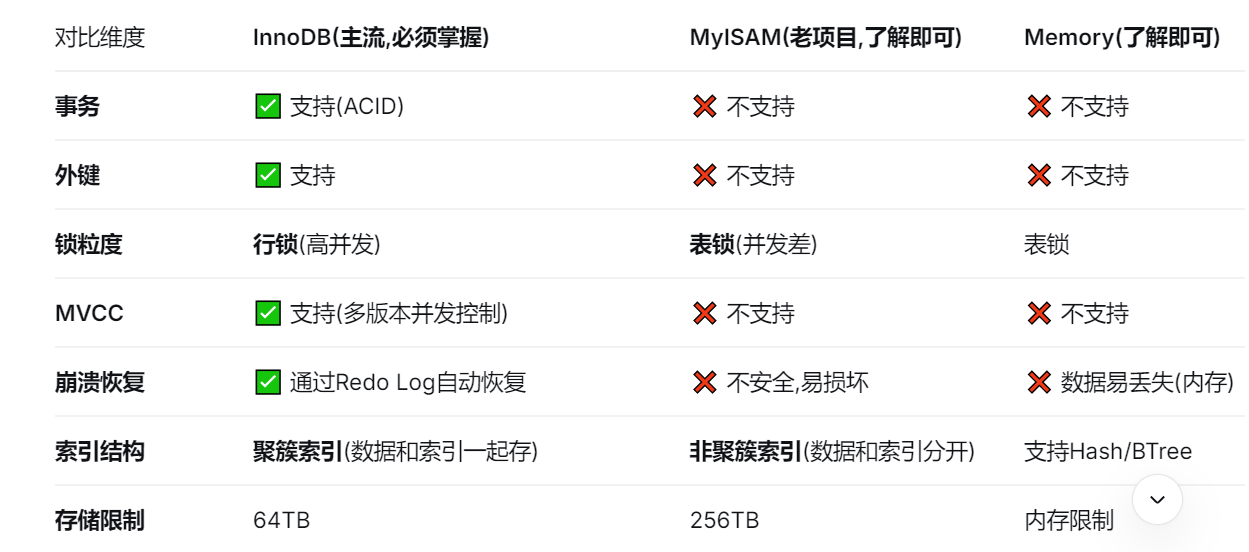
为什么InnoDB成为MySQL 5.5+的默认引擎?
因为现代互联网应用高并发、需要事务、需要崩溃恢复。MyISAM的表锁在高并发写场景下是灾难,而InnoDB的行锁+MVCC能支撑数千并发。另外,InnoDB的聚簇索引让主键查询极快,Redo Log保证了断电不丢数据。
InnoDB的核心特点
1. 聚簇索引(Clustered Index)——面试高频
原理:
InnoDB的表数据本身就是一颗B+树,主键索引的叶子节点直接存储完整的数据行。
二级索引的叶子节点存储的是主键值(而不是数据行的指针)。
影响:
✅ 主键查询极快(一次B+树查找直接拿到数据)
✅ 范围查询性能好(数据按主键物理排序)
❌ 二级索引查询需要回表(查两次B+树)
❌ 主键最好是自增整数(避免页分裂)
2.事务与ACID——怎么保证的?
MVCC原理(加分点):
“InnoDB为每行记录增加两个隐藏列:DB_TRX_ID(最后修改的事务ID)、DB_ROLL_PTR(回滚指针,指向Undo Log)。读操作时,通过可见性算法,只读取事务ID <= 当前事务ID且未删除的版本,从而实现非阻塞读。”
3. 锁机制——行锁怎么实现的?
记录锁:锁住某一行
间隙锁:锁住某个范围(防止幻读)
Next-Key锁:记录锁+间隙锁,RR隔离级别下解决幻读
面试官常问: “InnoDB的行锁是锁索引还是锁数据?”
“锁的是索引。如果WHERE条件用到了索引,就锁索引记录;如果没有走索引,InnoDB会锁全表(因为要扫描所有聚簇索引)。这就是为什么更新操作一定要走索引!”
Q1:如何查看当前表的引擎?
SHOW TABLE STATUS WHERE Name = 'your_table';
SHOW CREATE TABLE your_table;
Q2:如何修改表的引擎?
ALTER TABLE your_table ENGINE = InnoDB;
Q3:InnoDB的B+树为什么比B树更适合?
“B+树非叶子节点不存数据,可以存更多索引项,树高更低(一般2-3层),减少磁盘I/O。且叶子节点有双向指针,范围查询更高效。”
Q4:MyISAM真的完全没用了吗?
“不是。在只读数据仓库、日志分析、报表导出场景下,MyISAM的读性能和压缩能力仍有优势。但MySQL 8.0后,MyISAM被标记为废弃,未来可能移除。”
六、JVM
6.1 JMM
JMM的核心抽象是主内存和工作内存。所有变量存储在主内存,每个线程有自己的工作内存,线程对变量的操作必须在工作内存中完成,然后通过主内存进行线程间通信。
基于这个模型,JMM提供了三大特性保证:
原子性:由synchronized、Lock、Atomic类保证;
可见性:由volatile、synchronized、final保证;
有序性:由volatile和happens-before规则保证。
其中,happens-before是JMM的核心规则。比如volatile变量的写发生在读之前,锁的释放发生在获取之前。只要两个操作满足happens-before关系,第一个操作的结果对第二个操作就是可见的,编译器也不会做有害的重排序。
volatile是如何保证可见性的?
"底层通过内存屏障实现。写volatile变量时,会在写操作前后插入StoreStore和StoreLoad屏障,强制将工作内存的修改刷新到主内存;读volatile变量时,会在读操作前后插入LoadLoad和LoadStore屏障,强制从主内存重新加载。同时,这些屏障也禁止了指令重排序。
volatile能保证原子性吗?
“不能。比如volatile int count; count++不是原子的,因为它分为读-改-写三步。保证原子性需要用synchronized或AtomicInteger。”
64位的long/double有什么特殊?
“JVM允许将64位读写拆成两个32位操作,可能读到‘半个变量’。但通过volatile修饰或用AtomicLong可以保证原子性。”
问题
(一)JVM组成
Q1:能详细介绍Java堆吗?

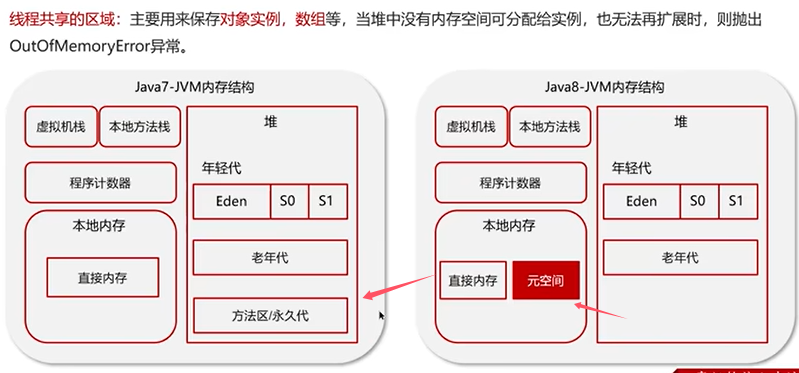

Q2:什么是虚拟机栈?


Q3:堆栈的区别?

Q4:解释一下方法区?
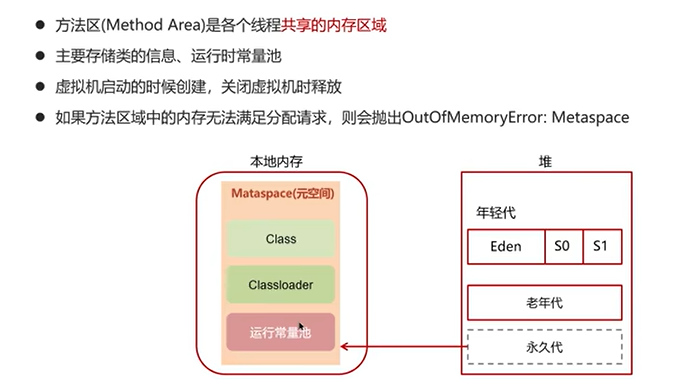

Q5:你听过直接内存吗?

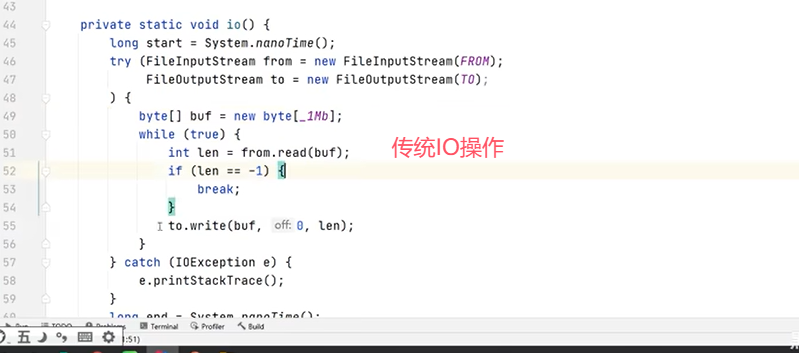
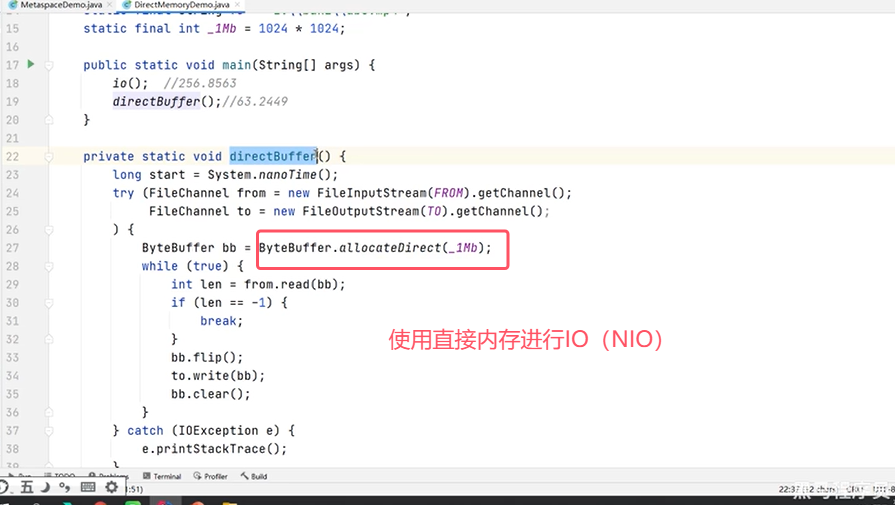
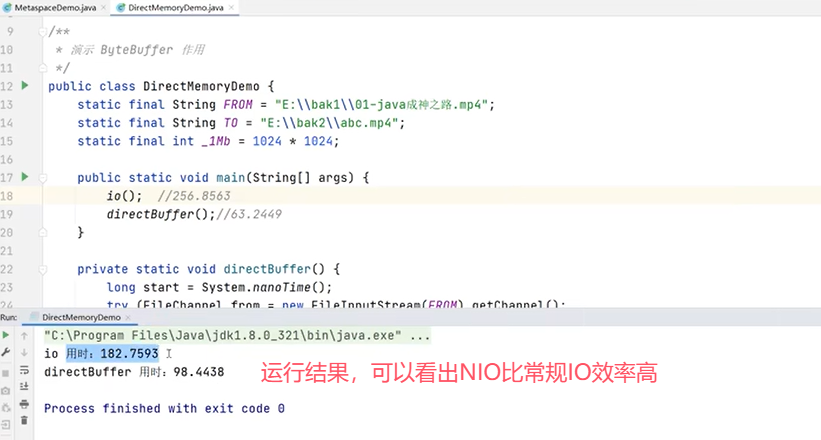
用一个“拷贝文件”的例子来对比常规IO和NIO的区别: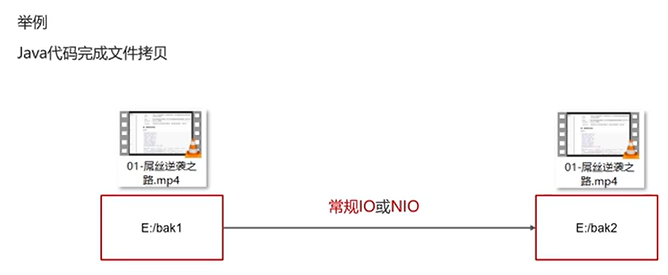
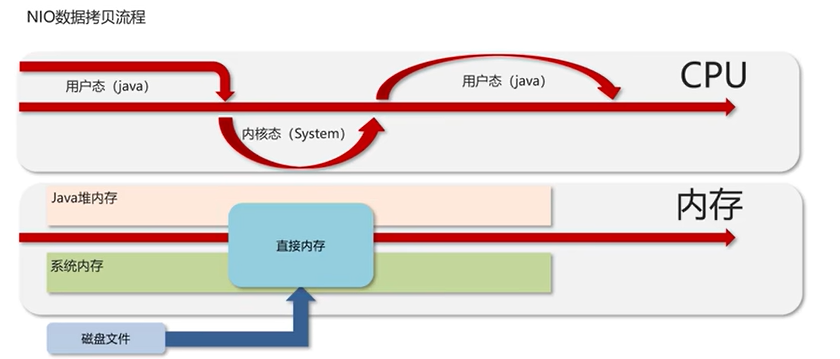

(二)类加载器
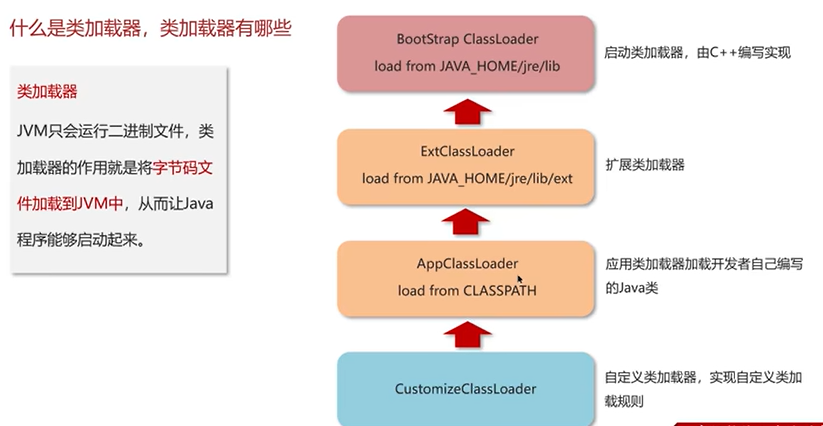
Q1:什么是类加载器,类加载器有哪些?

Q2:什么是双亲委派模型?


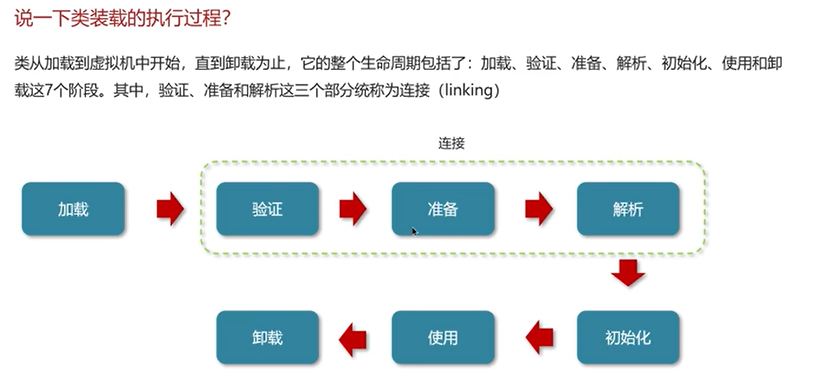
Q3:说一下类装载的执行过程?
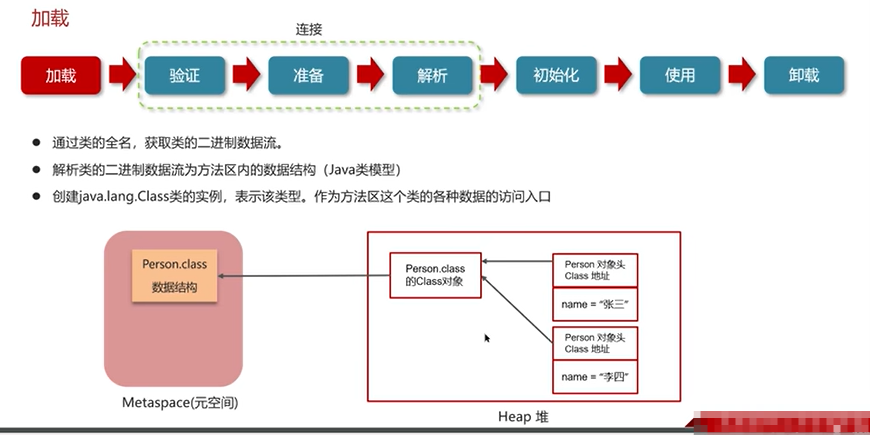
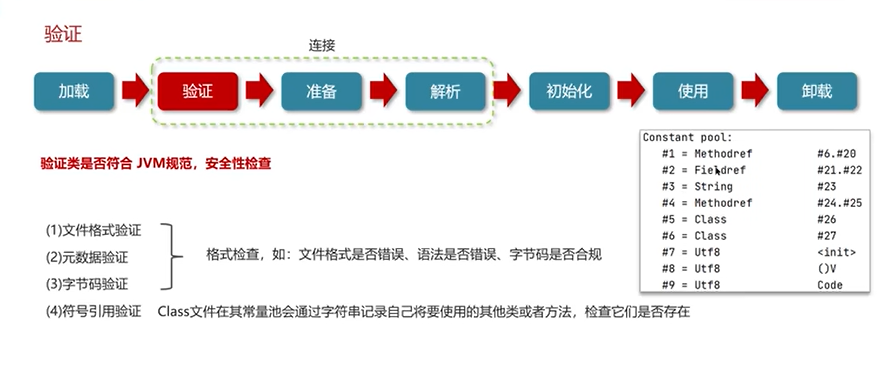
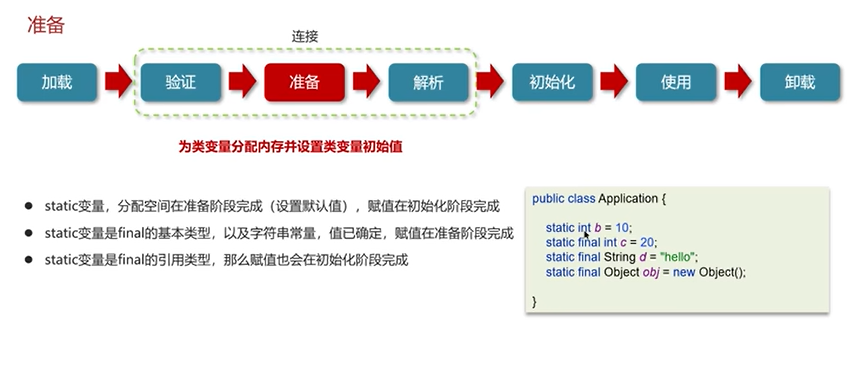
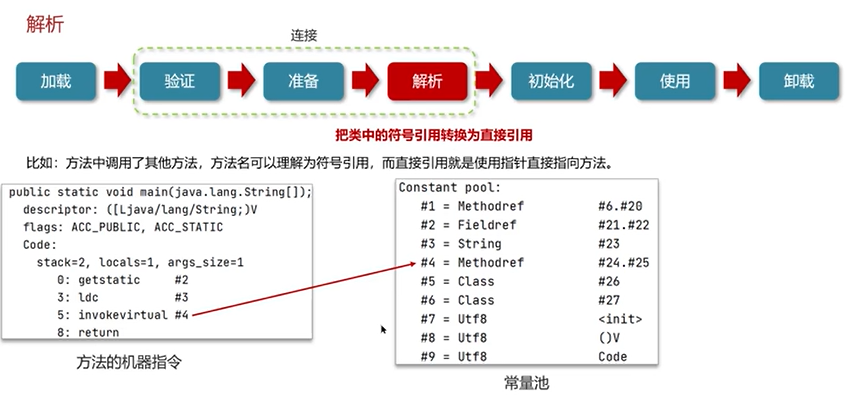
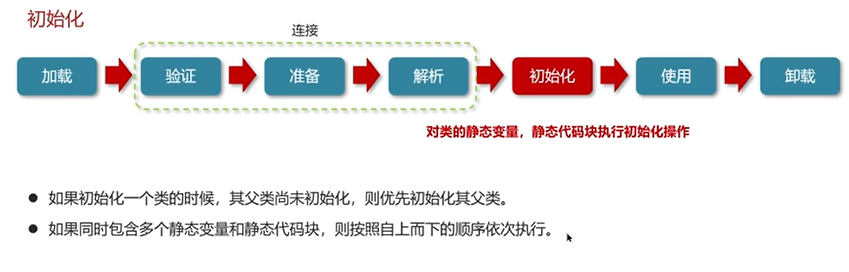
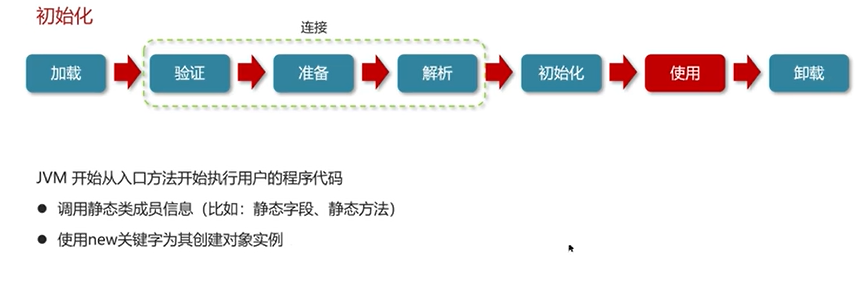
(三)垃圾回收
Q1:对象什么时候可以被垃圾器回收?
(垃圾回收主要是对堆)。
如果一个或多个对象没有任何的引用指向它了,那么这个对象现在就是垃圾,如果定位了垃圾,则有可能会被垃圾回收器回收。
判断垃圾有两种分析方法:引用计数法和可达性分析算法。现在的虚拟机都采用可达性分析算法。
Q2:哪些对象可以作为GC Root?

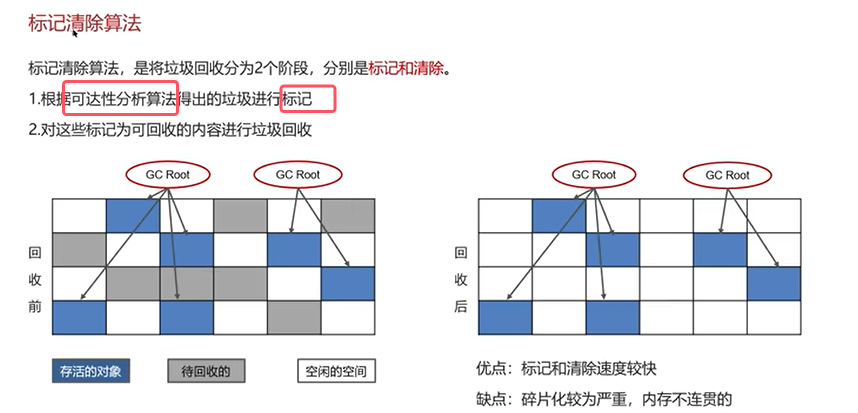
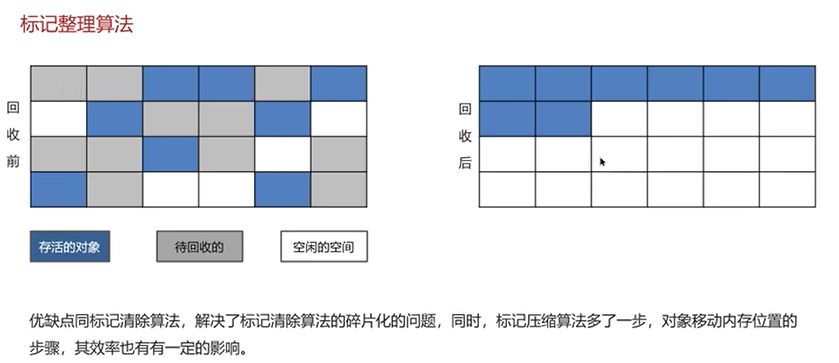
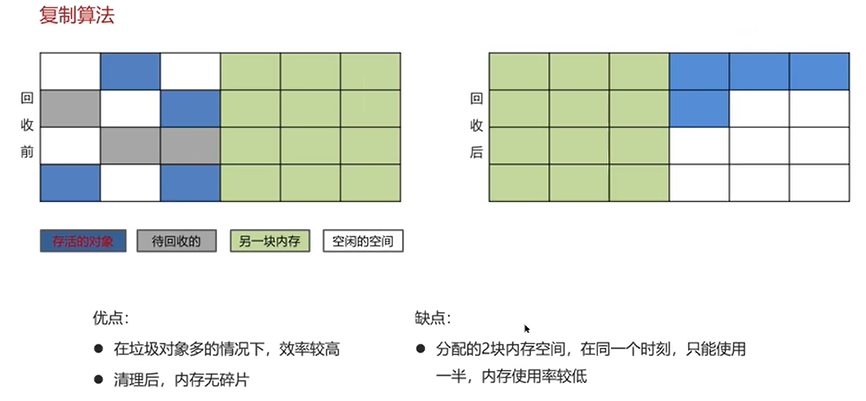
Q3:JVM垃圾回收算法有哪些?

Q4:说一下JVM中的分代回收?
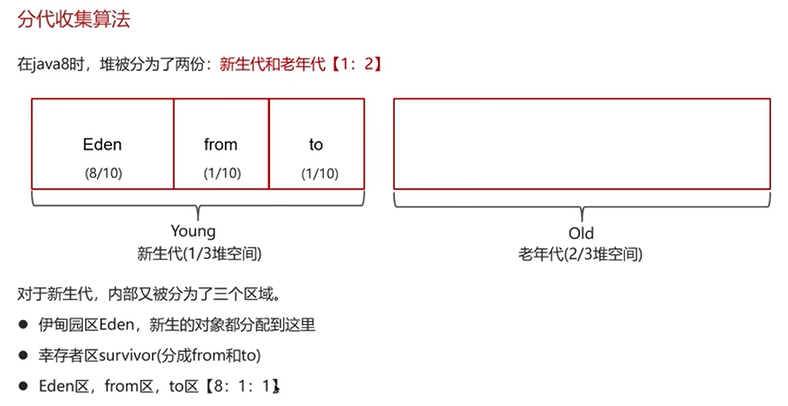

Q5:MinorGC、Mixed GC和FullGC的区别是什么?

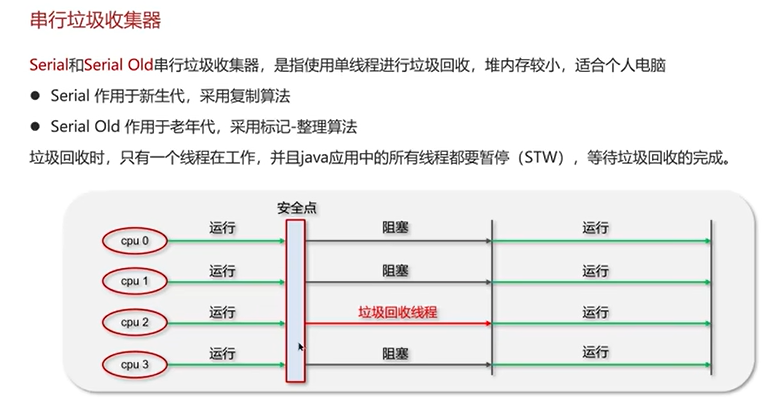
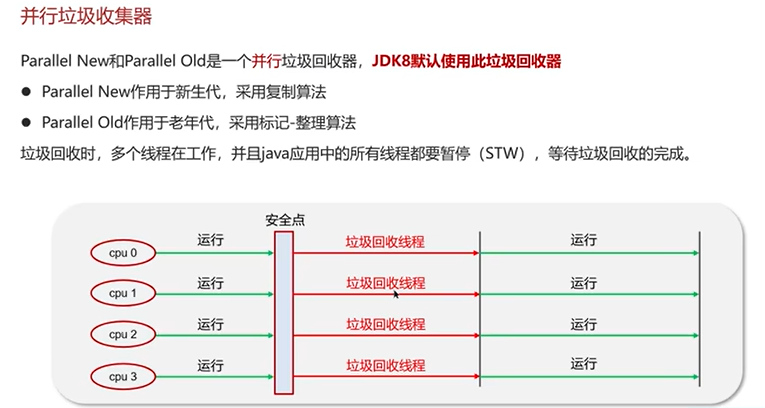
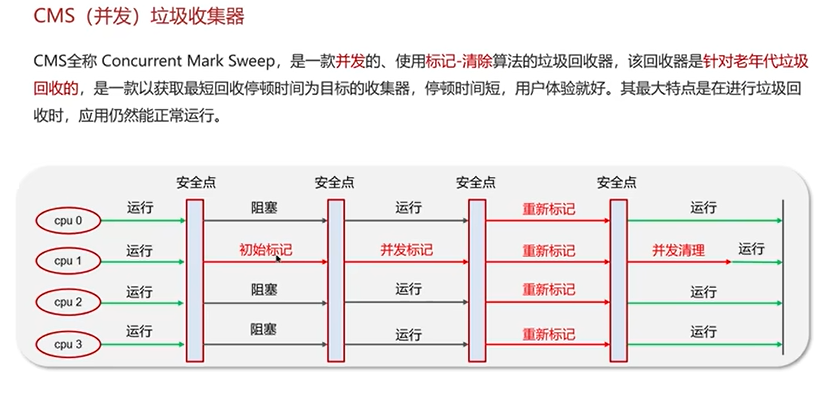
Q6:说一下JVM有哪些垃圾回收器?

G1垃圾回收器
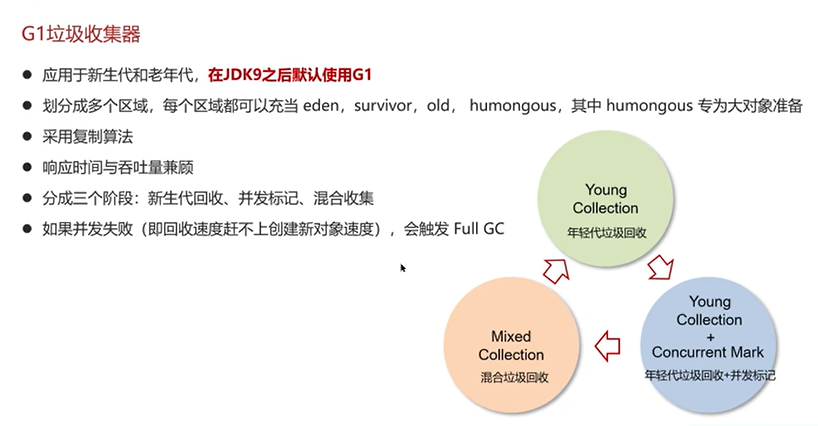


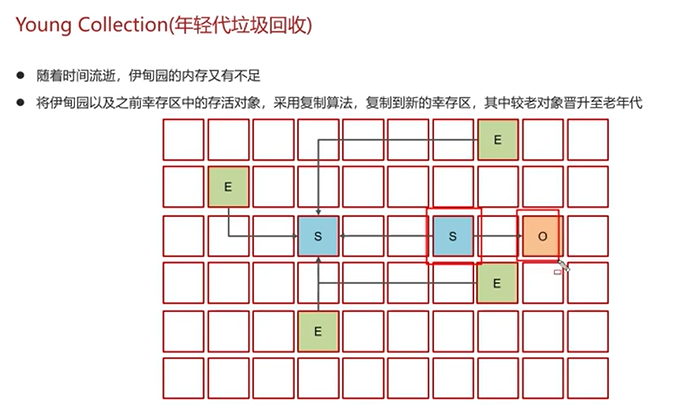

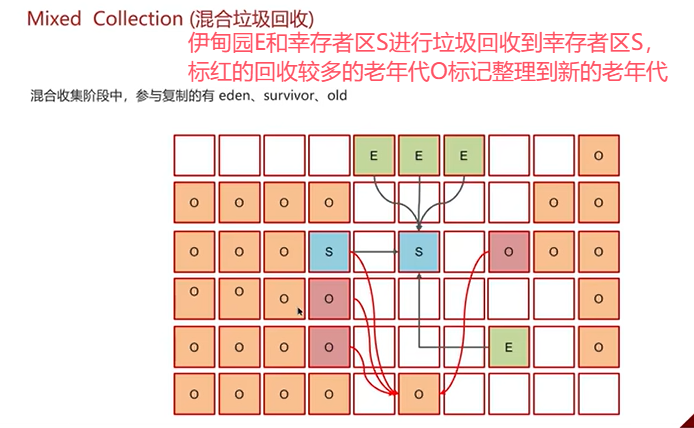
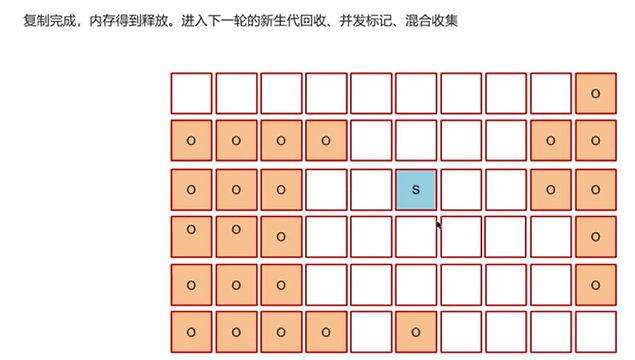

Q7:强引用、软引用、弱引用、虚引用的区别?
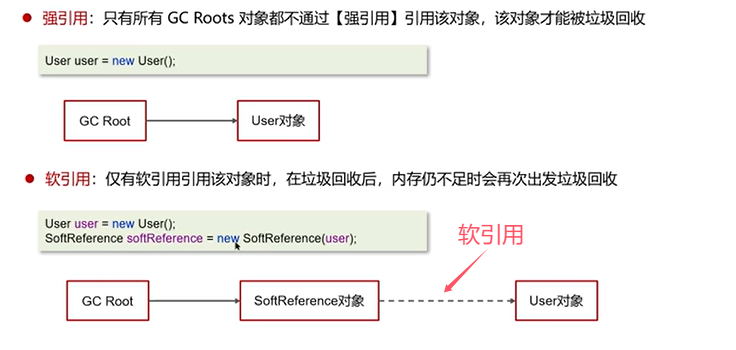

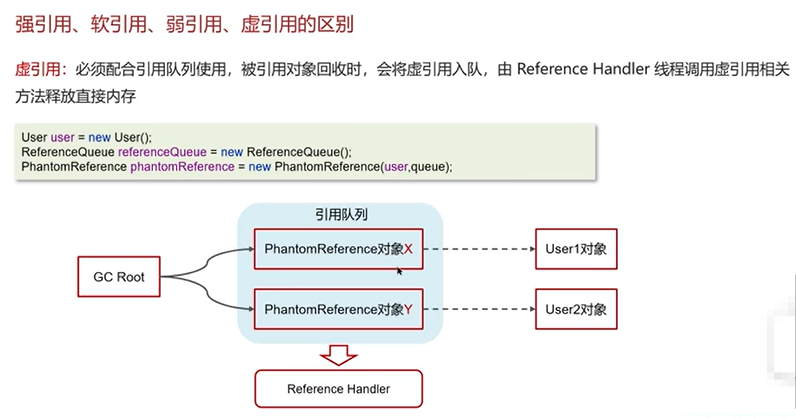
弱引用和若应用也可以通过引用队列进行回收。
(四)JVM实践
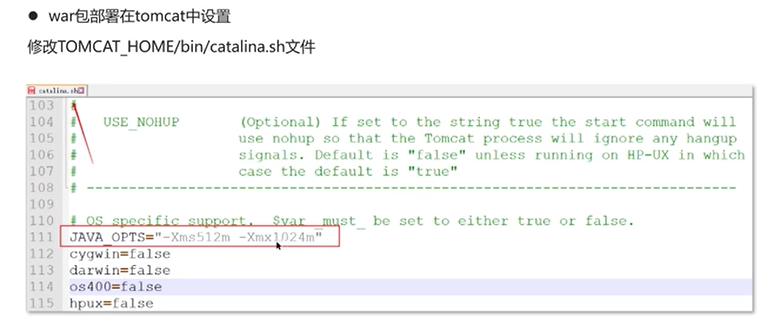
Q1:JVM调优的参数可以在哪里设置参数值?
(IDEA中设置的参数都是临时的)

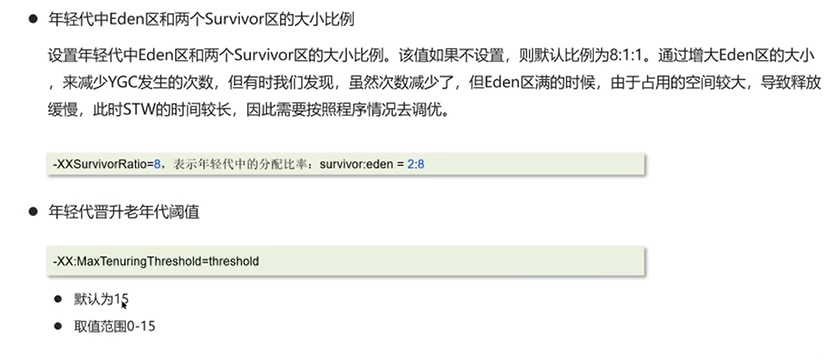
Q2:JVM调优的参数有哪些?

常见的有:



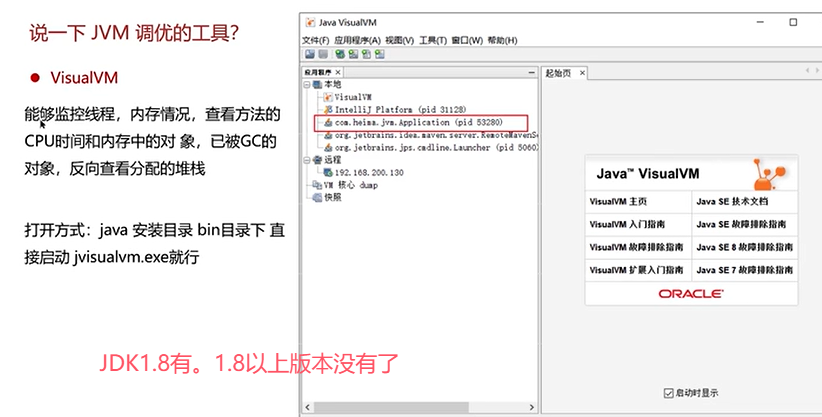
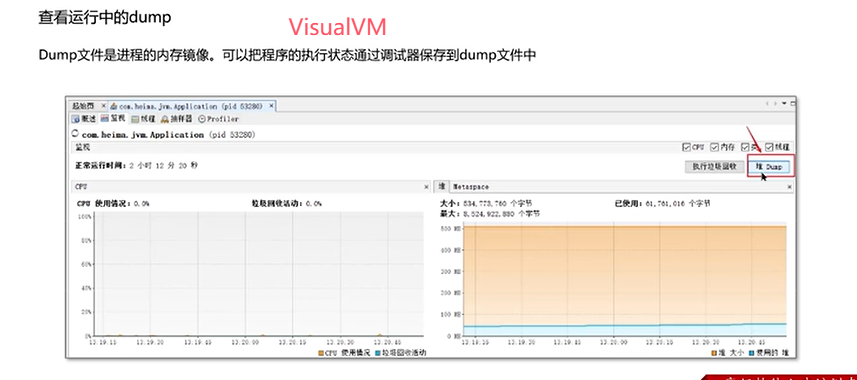
Q3:说一下JVM调优的工具?



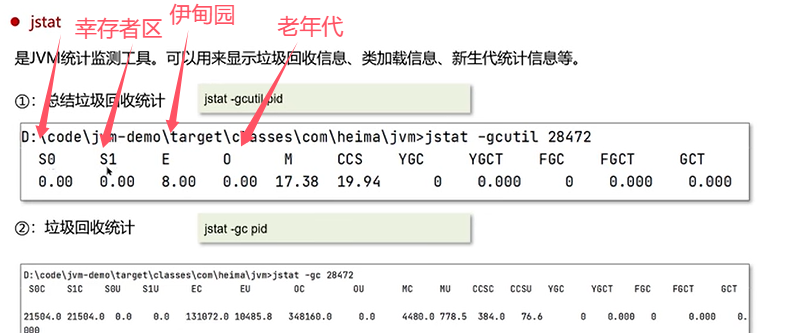
可视化工具: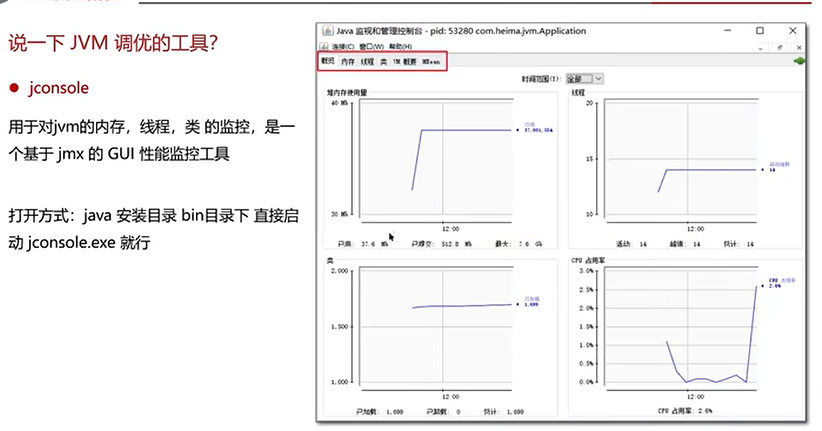
Q4:java内存泄漏的排查思路?
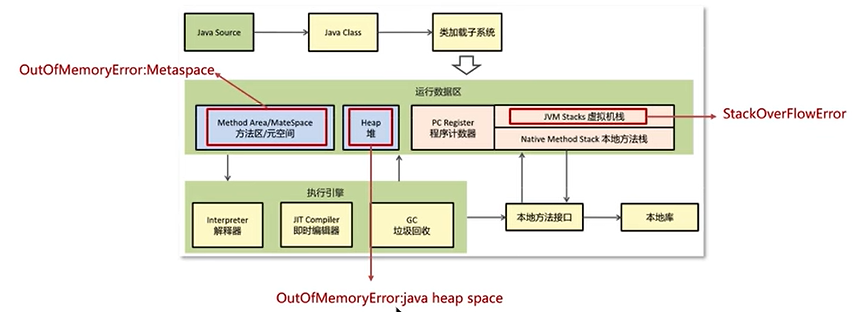
内存泄漏会出现在虚拟机栈(递归造成)、方法区(动态加载的类太多)和堆(大的对象一直存活)。面试官比较关心的是堆的内存泄漏。
一个例子: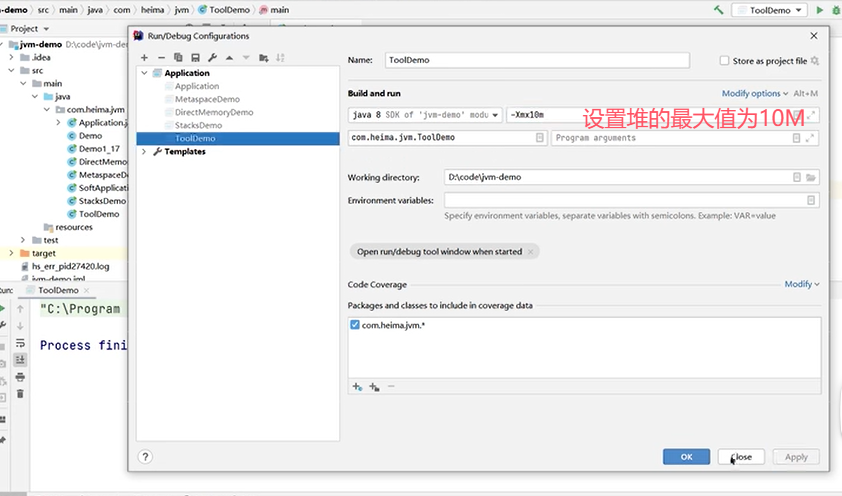
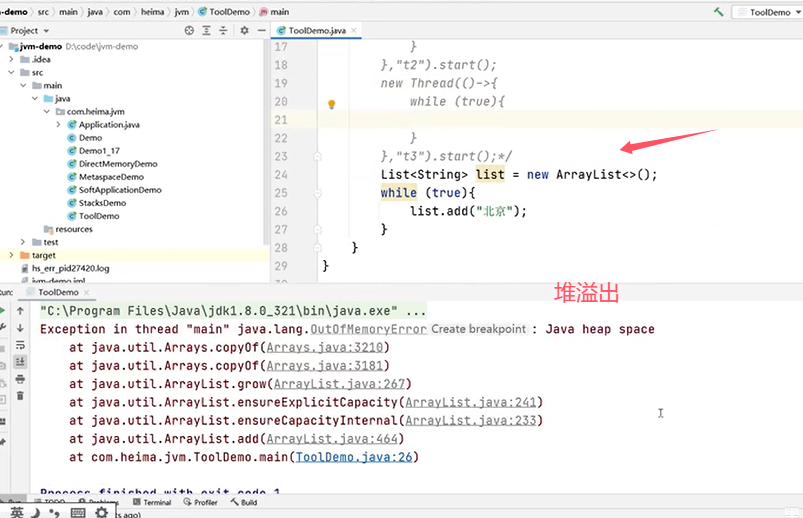
排查思路:
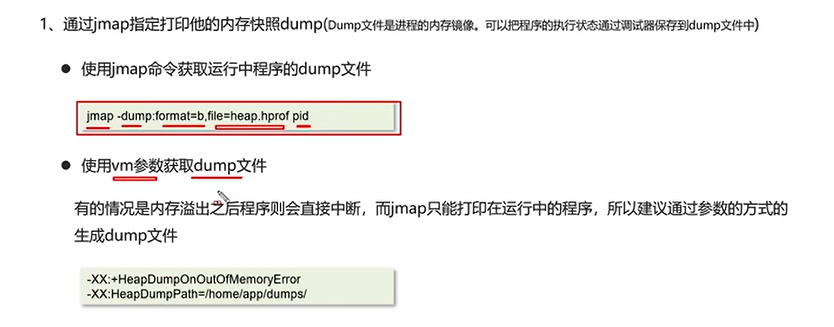
例如,对于刚才的例子: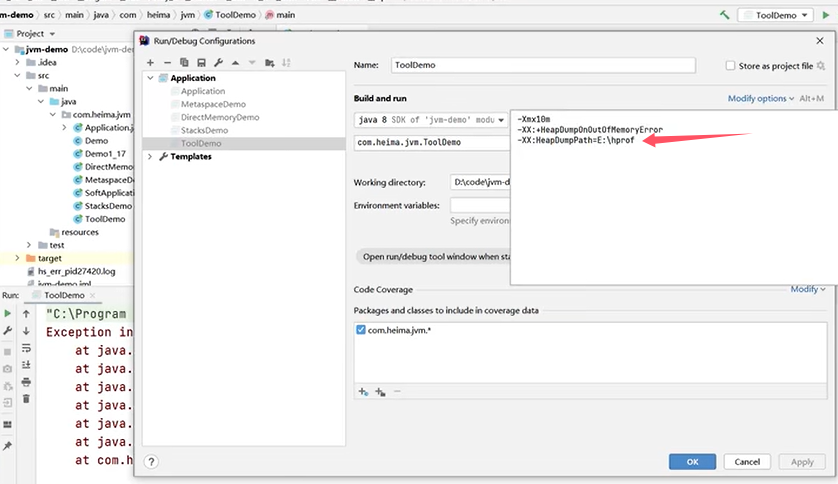
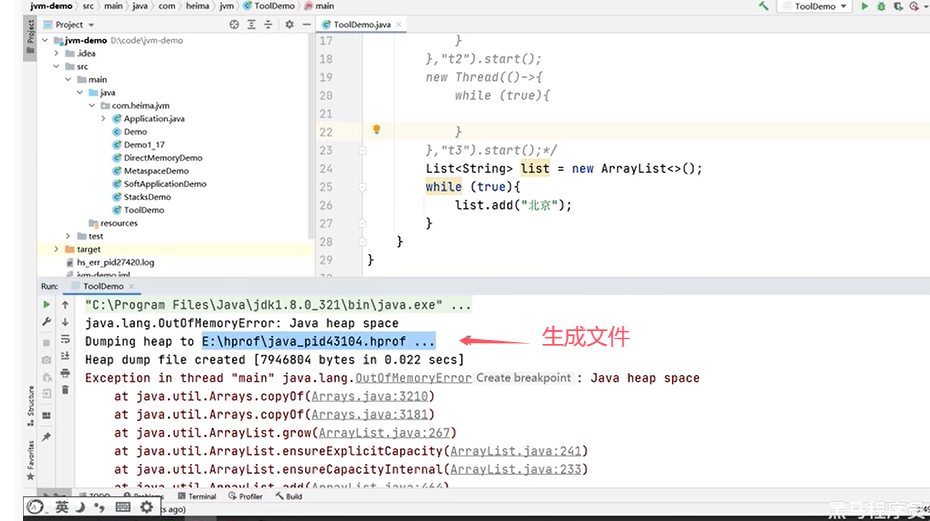
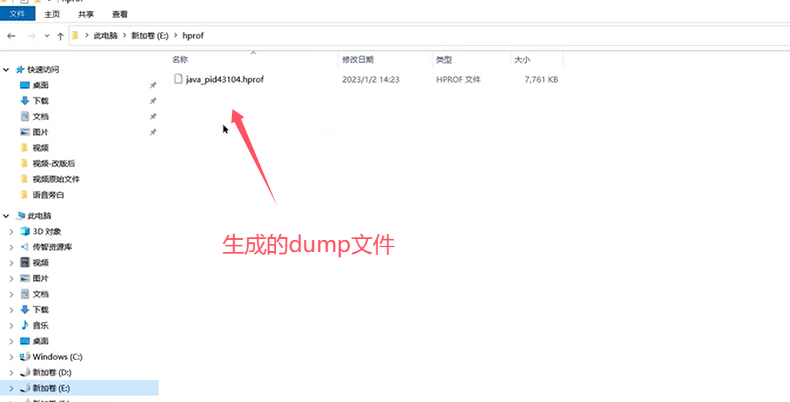
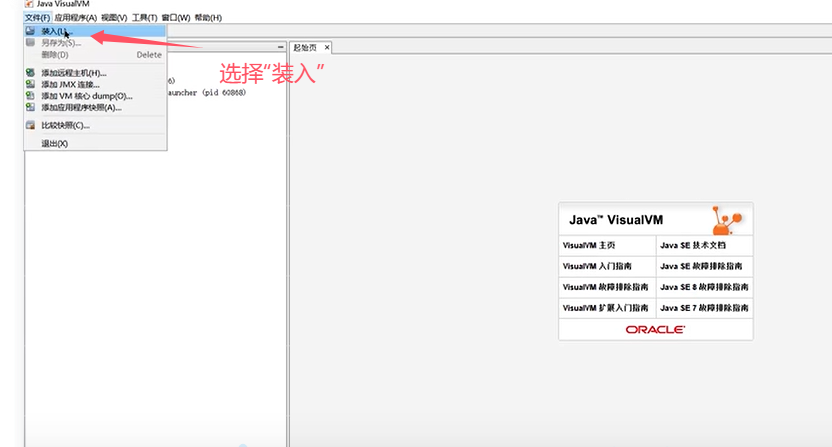
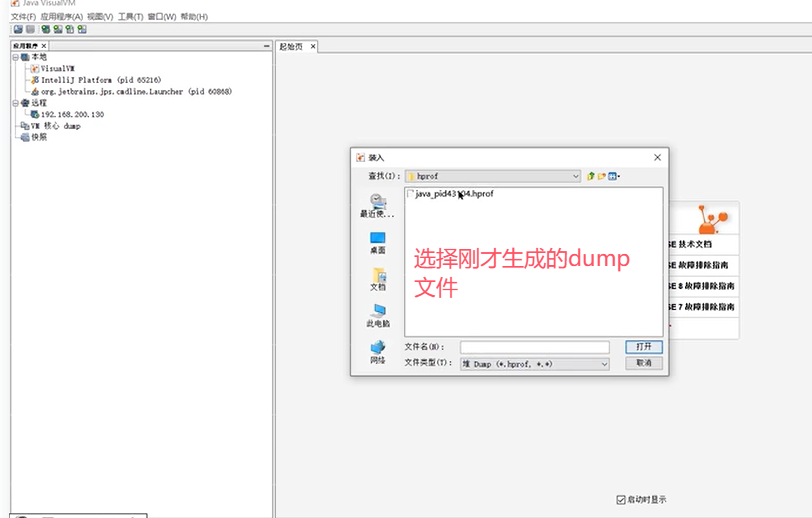
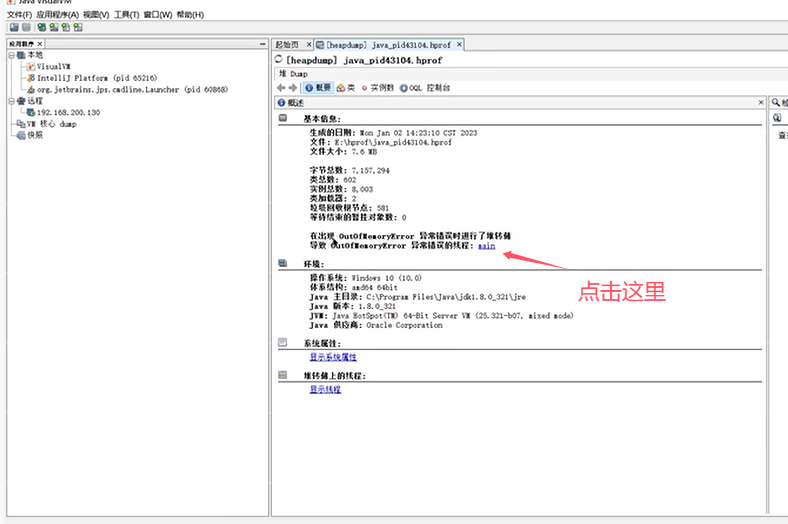
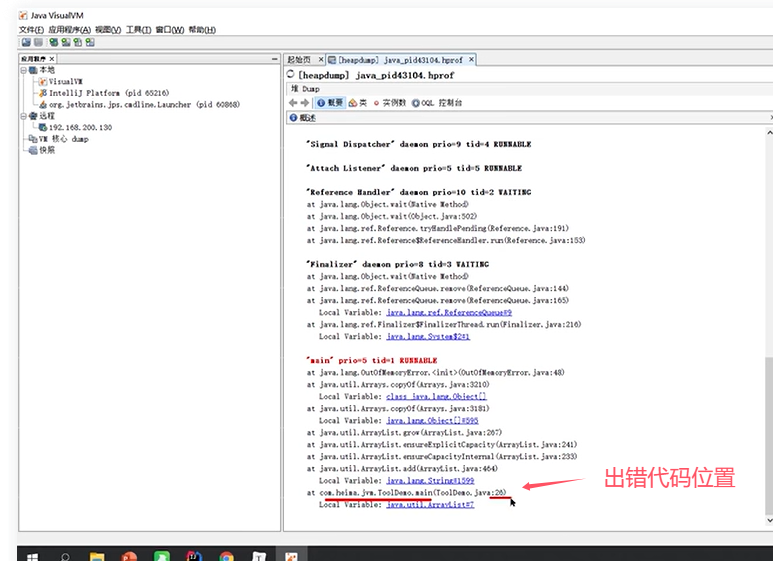
Q5:CPU飙高的排查方案和思路?
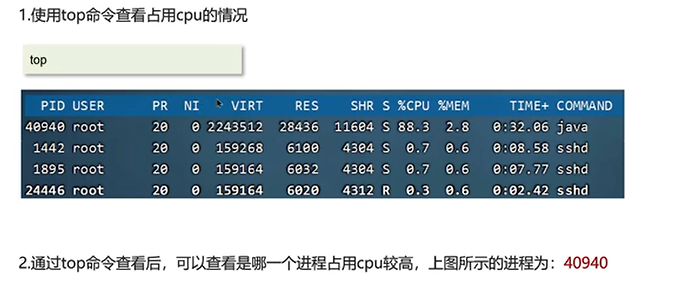
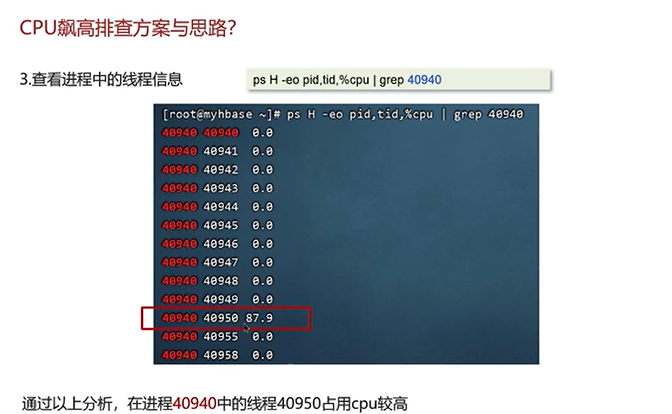

可以看到上图中的线程thread1的信息定位到代码位置。
七、分布式事务解决方案Seata
7.1 使用分布式事务解决方案seata在生产上会遇到哪些问题?
Seata虽然解决了分布式事务的痛点,但在生产环境中并非无脑使用。它引入了新的复杂度,主要会面临性能开销、高并发锁竞争、脏数据处理、部署运维四大类问题。下面我分别展开。
八、Mybatis
Q1:Mybatis执行流程
首先需要读取核心配置文件mybatis-config.xml。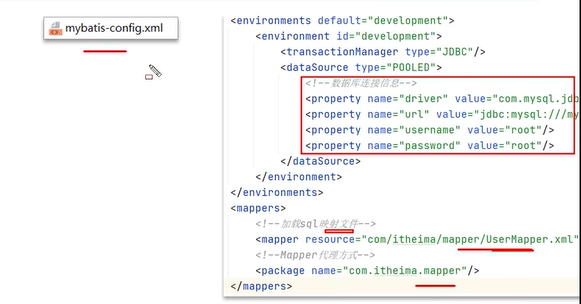
接下来需要操作数据库。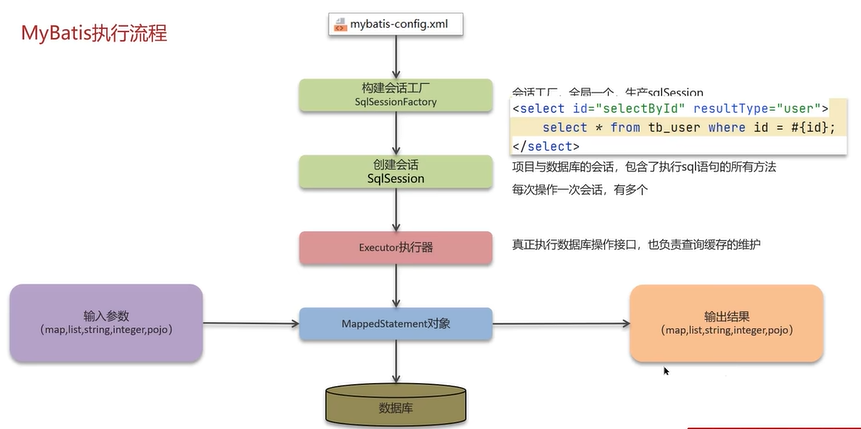
Mybatis通过SqlSession对象操作数据库,该对象有SqlSessionFactory创建,真正操作数据库的是Executor执行器,同时也复杂查询缓存的维护。MappedStatement对象负责读取配置文件中的sql语句,如下图: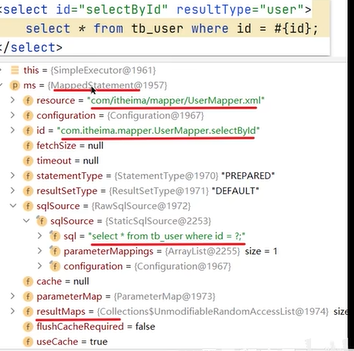

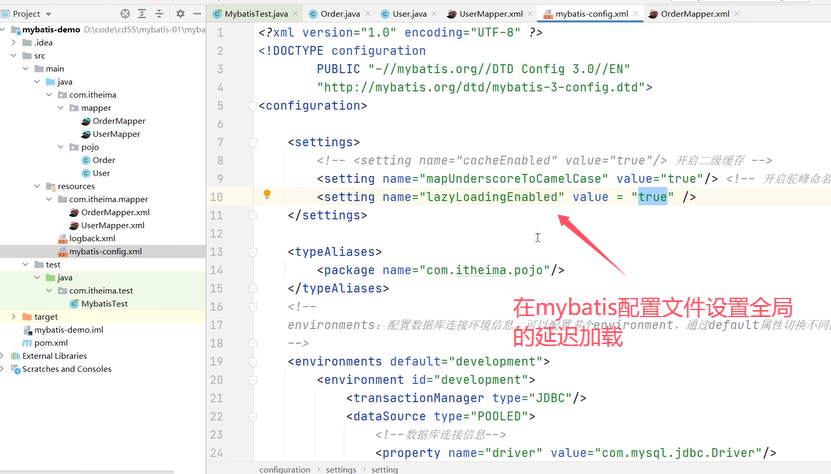
Q2:Mybatis是否支持延迟加载?
Mybatis支持延迟加载,但是默认不开启。
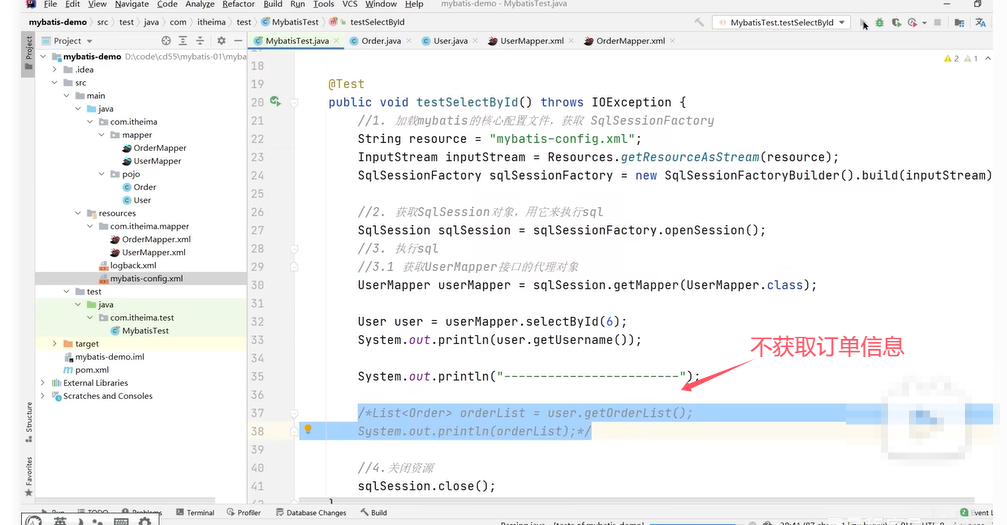
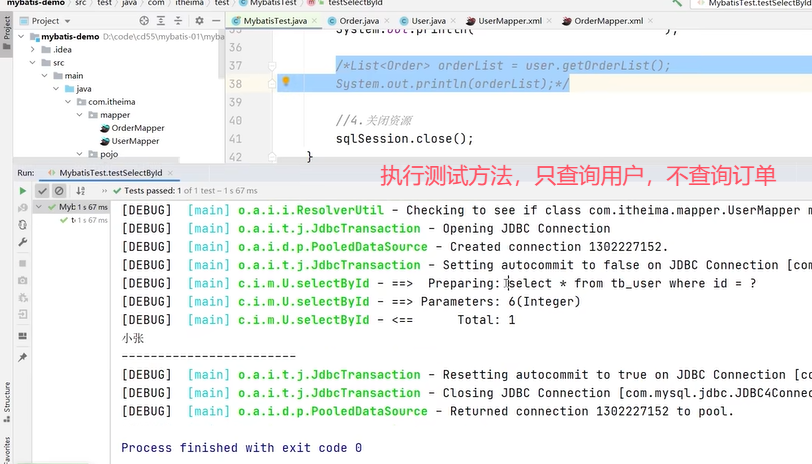
用一个例子来说明延迟加载的含义:
演示: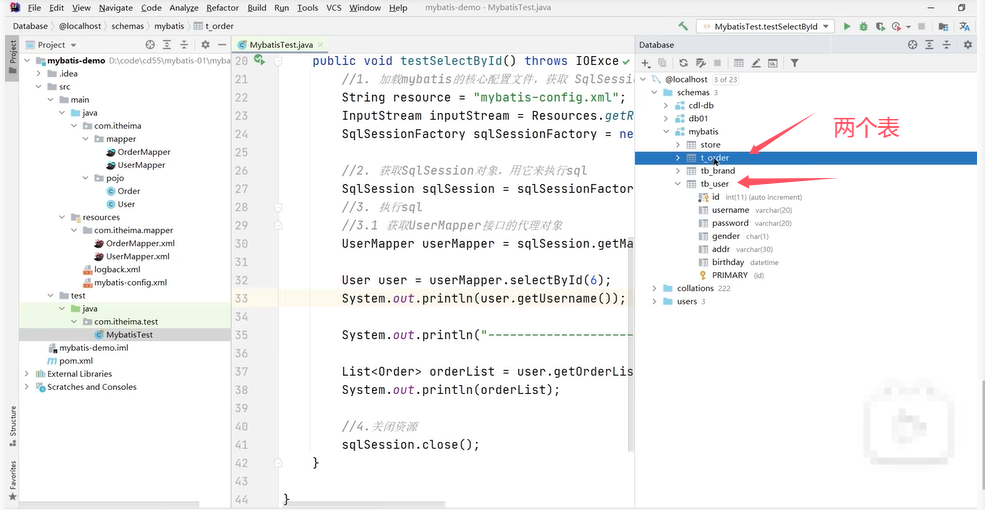
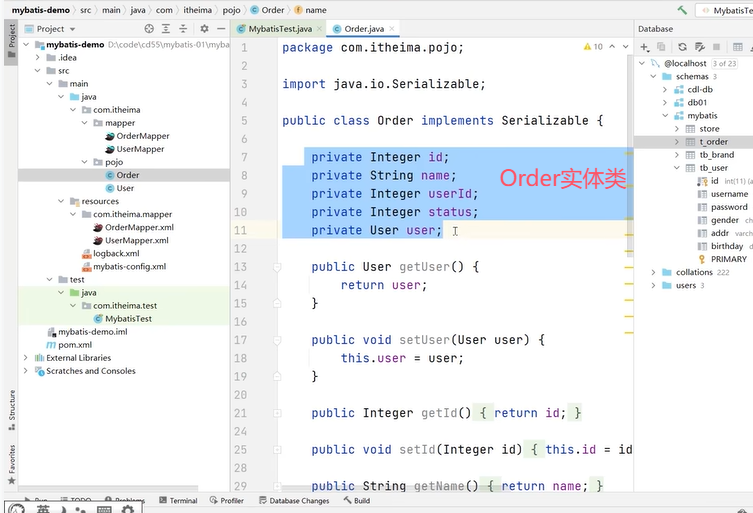
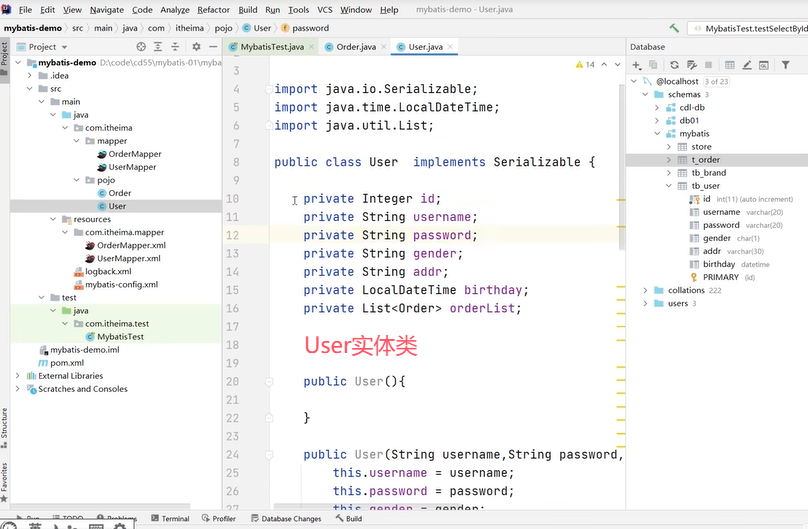
User中有一个属性orderList。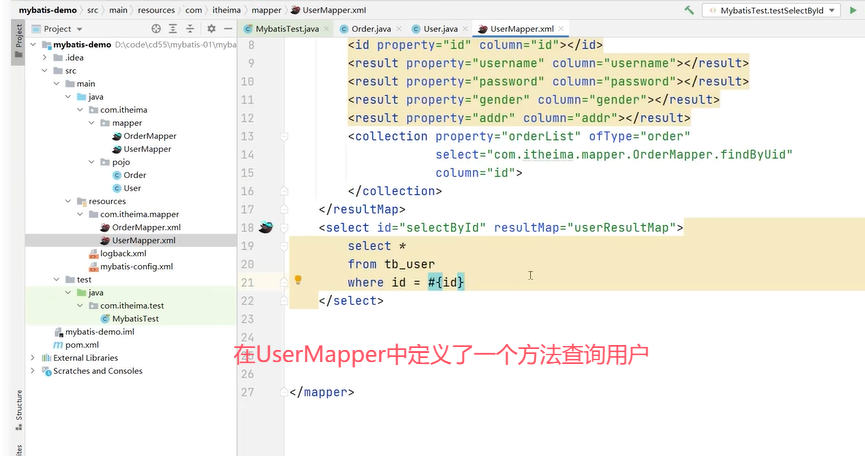
可以看到查询用户的返回值类型自定义,在上方的resultMap中使用到了标签定义,select属性指向OrderMapper中的findByUid()。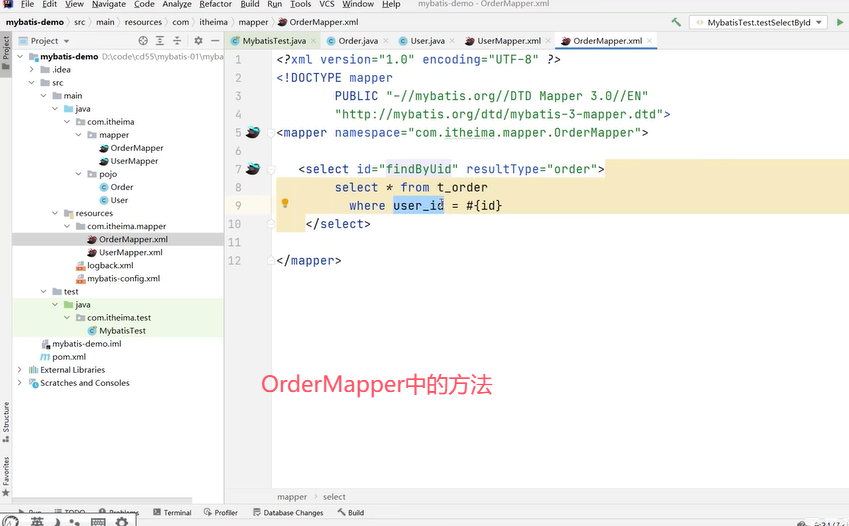
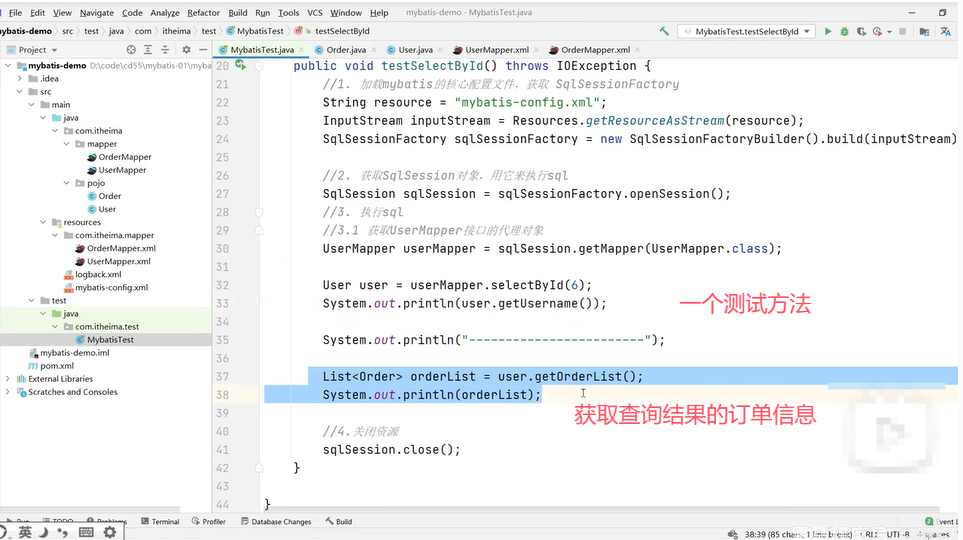
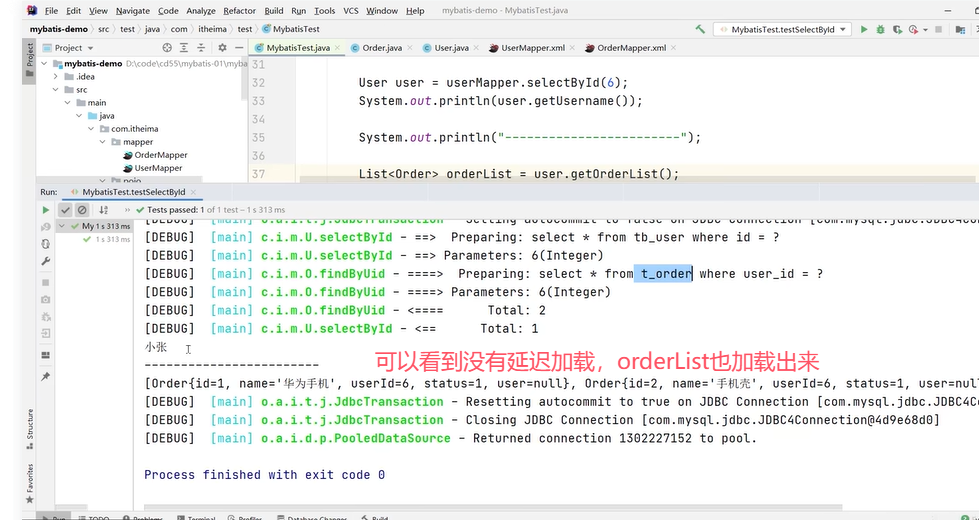
实现延迟加载的方法如下: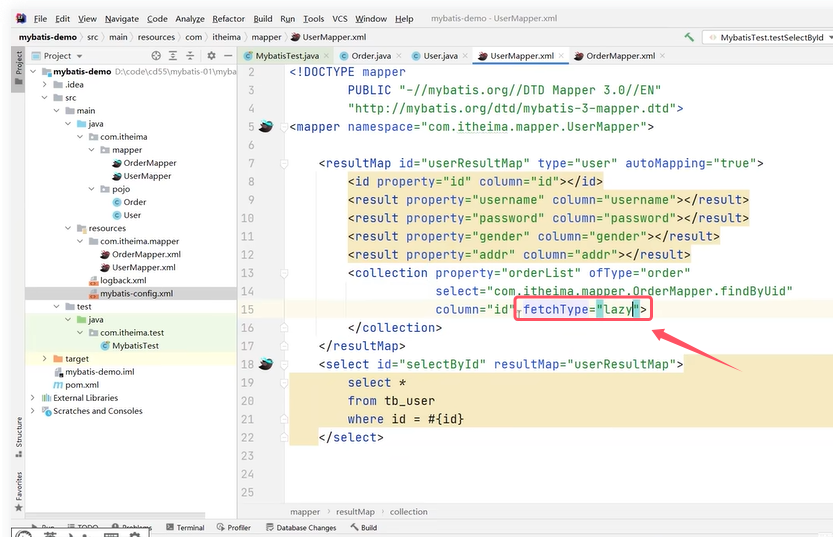
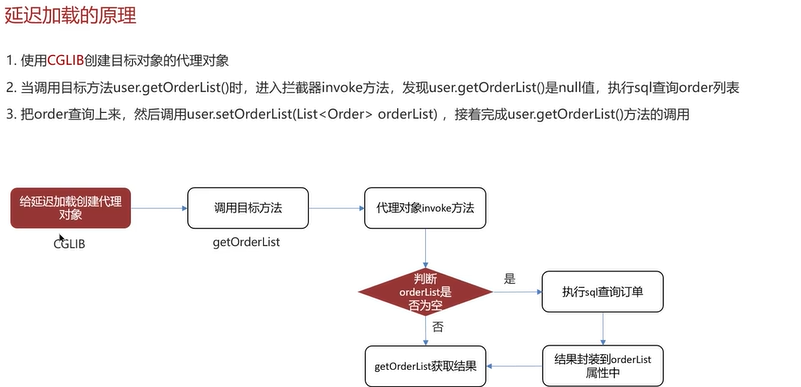

Q3:Mybatis的一级、二级缓存用过吗?
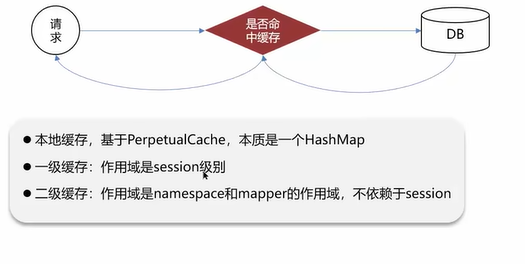
一级缓存和二级缓存都是基于本地缓存实现的。
演示: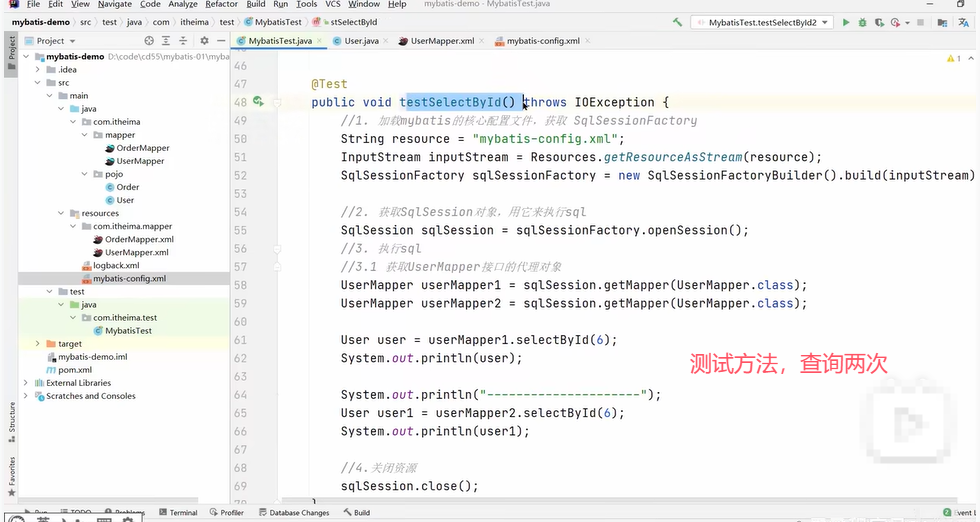
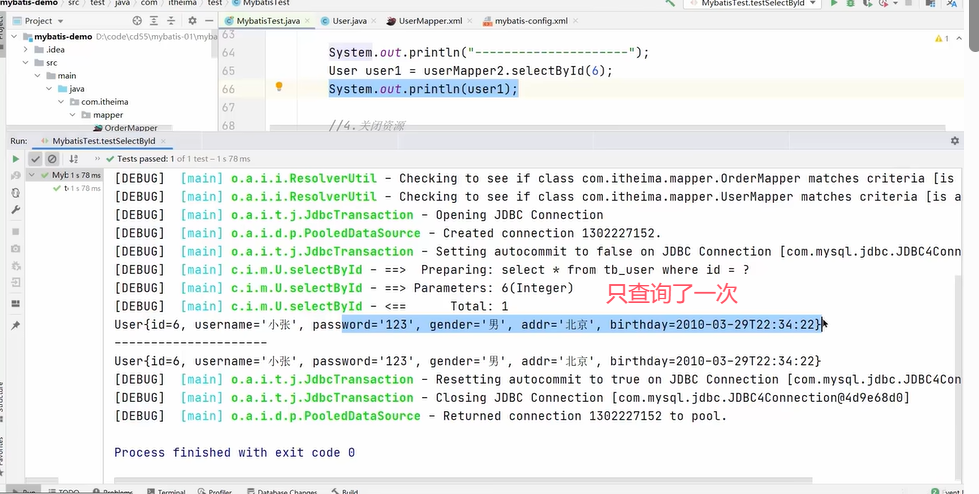
因为上面两个UserMapper的代理对象是同一个SqlSession,会使用一级缓存。若是不同的SqlSession,不会使用一级缓存,会查询两次。
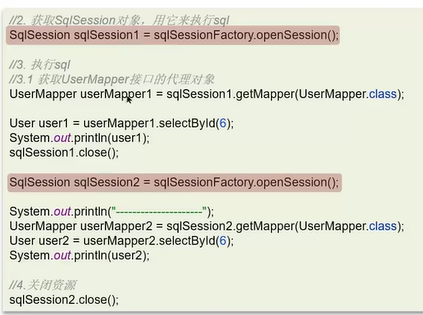
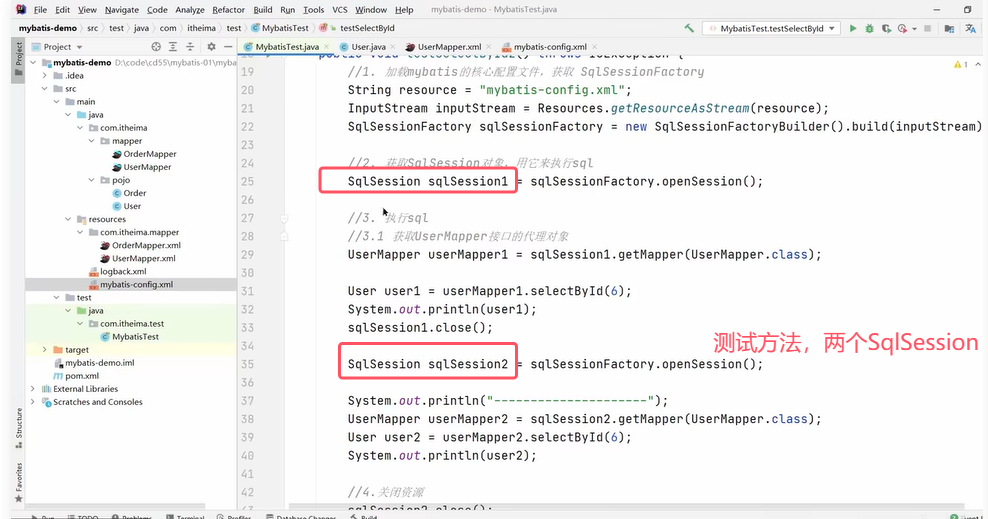
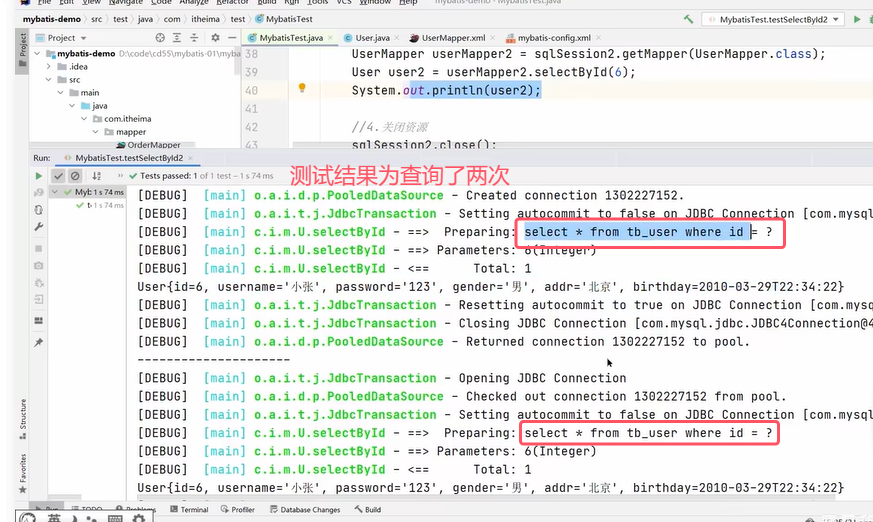
不同SqlSession实现只查询一次需要开启二级缓存。开启二级缓存的方式: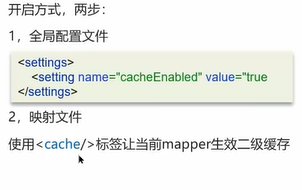
实现: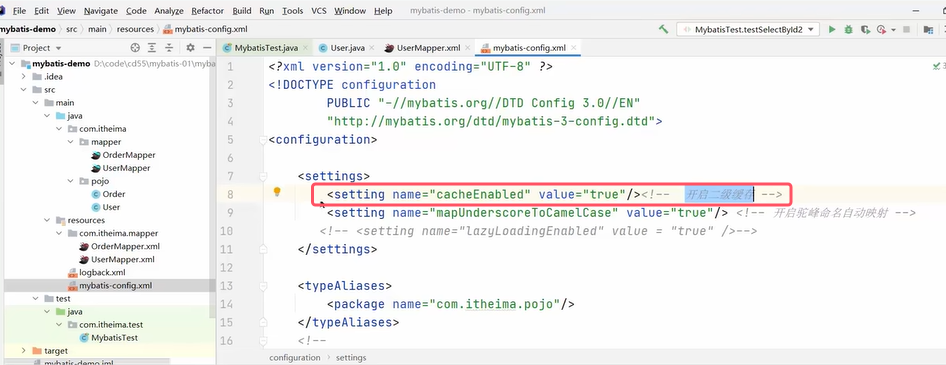
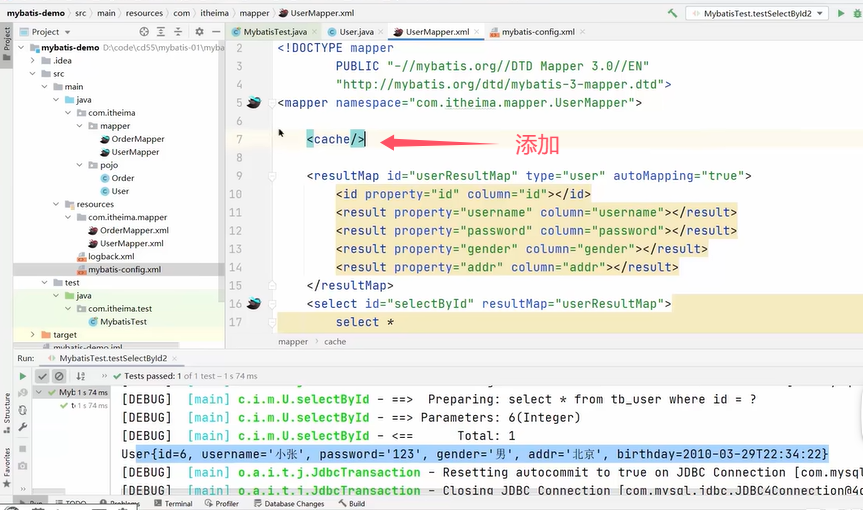
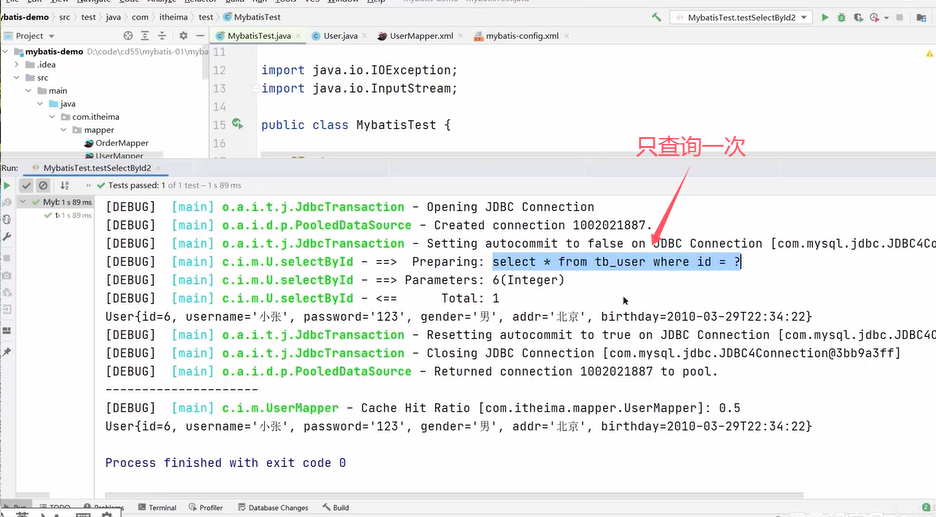

对于第3点,可以看到二级缓存开启的测试用例中需要把SqlSession1的会话关闭再开启SqlSession2的会话。
九、springcloud
(一)理论相关
Q1:springcloud的5大组件有哪些?
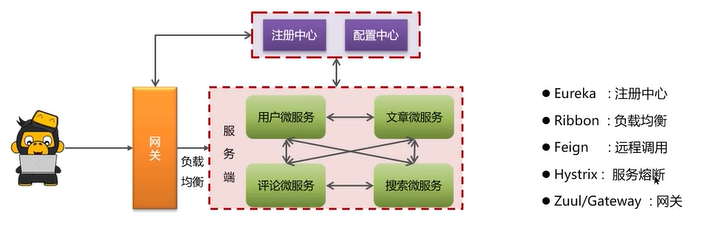
除了图中的5个,springcloud还包括组件-配置中心nacos。
Q2 springcloud如何实现服务注册发现?
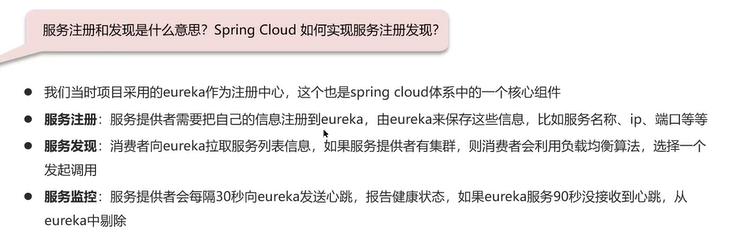
Q3:nacos与eureka的区别?

说明:AP模式是高可用模式,CP模式是强一致性模式。
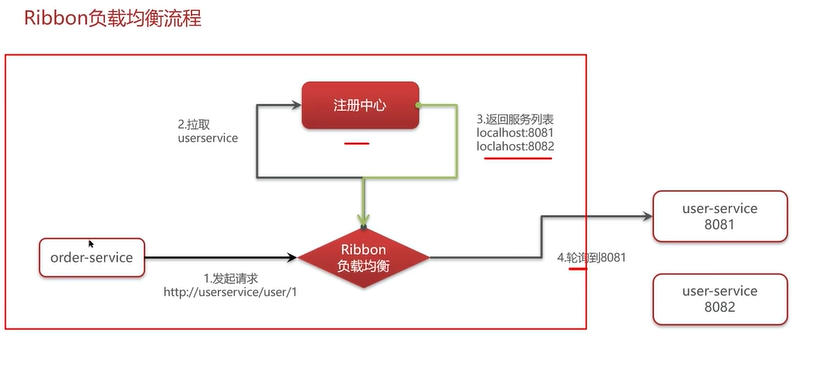
Q4:项目中的负载均衡是如何实现的?
其他相关问题: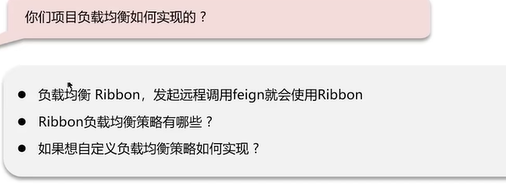

注意:面试时能说出标红的策略即可。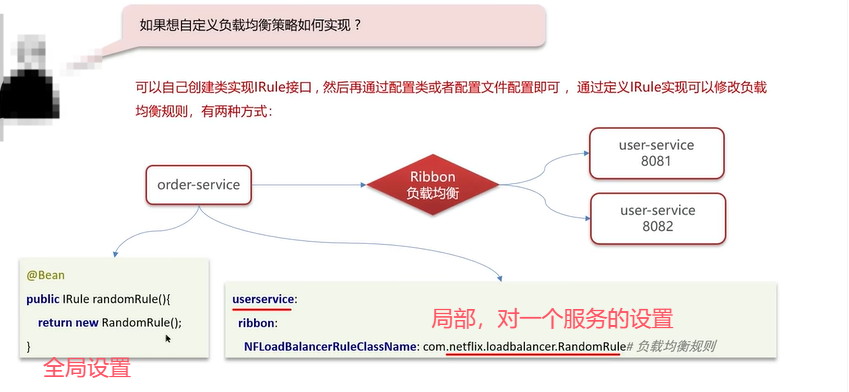

Q5:什么是服务雪崩,怎么解决这个问题?
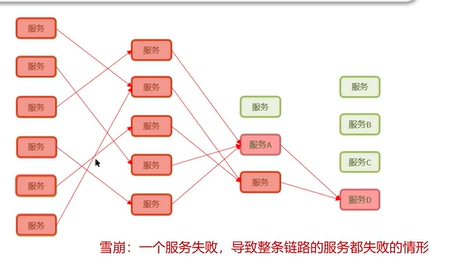
解决方案:熔断降级和限流。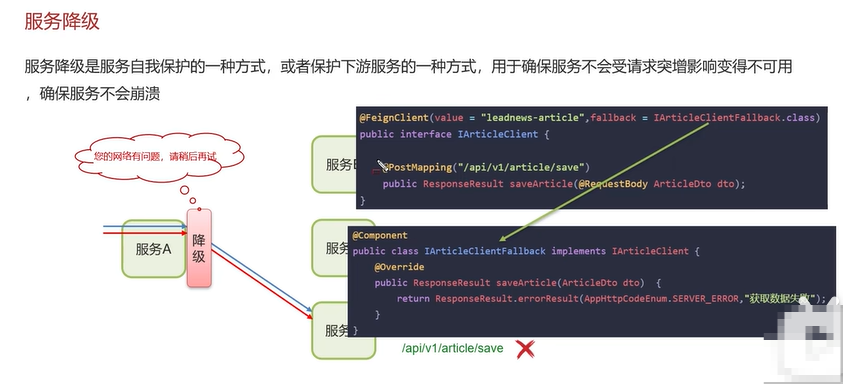
上面图中的代码实例表示,若是服务可以正常访问,走的是IArticleClient中的saveArticle()进行feign的远程调用。若是请求抛异常,就会走IArticleClientFallback的saveArticle()的降级逻辑,返回“获取数据失败”的错误信息。
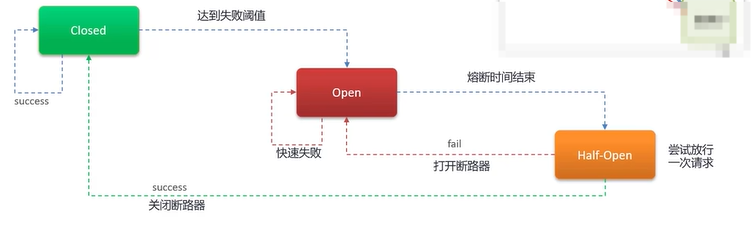

Q6:微服务是怎么监控的?
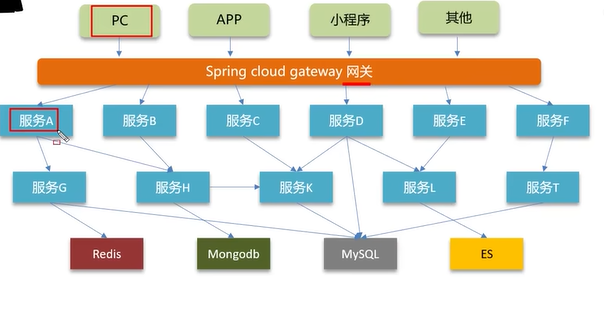
微服务的请求是多链路的,定位是哪个节点出问题比较困难,需要做监控。有的解决方法是Springboot-admin、prometheus+Grafana、zipkin、skywalking。
以skywalking为例(类似于sentinel)。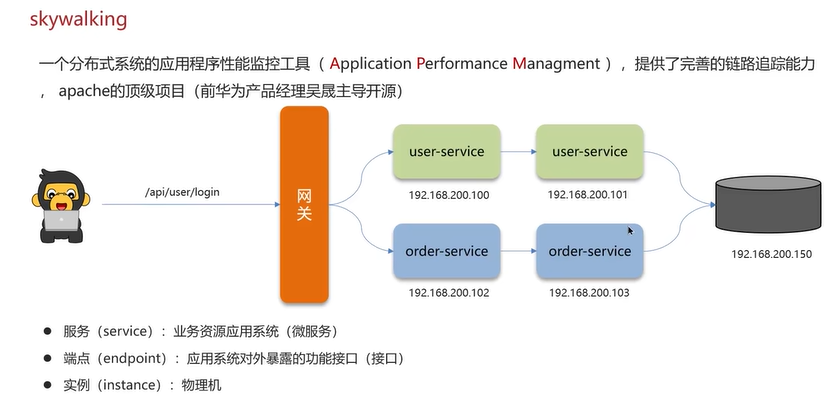
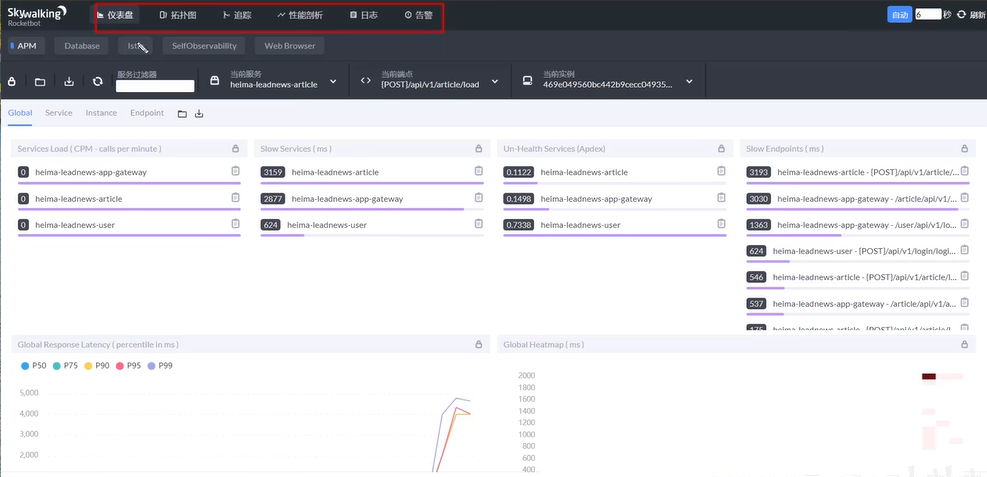
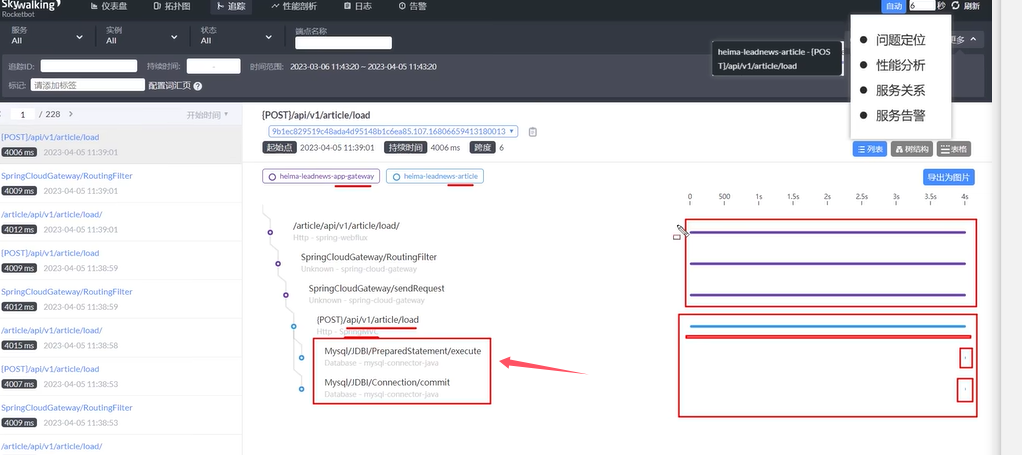

(二)业务相关
Q7:你们项目有没有做过限流,怎么做的?
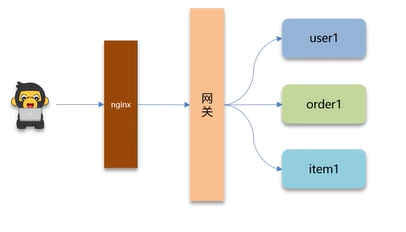
nginx反向代理(根据用户请求分发到不同的服务器)到网关(gateway,springboot中包含),网关路由到各个微服务。
限流的目的是应对突发流量和防止用户恶意刷接口。
说明:网关是gateway,拦截器是spring中实现了HandlerInterceptor接口的类。例子如下:
package com.hmdp.utils;
import com.hmdp.dto.UserDTO;
import com.hmdp.entity.User;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import javax.xml.ws.handler.Handler;
public class LoginInterceptor implements HandlerInterceptor {
//业务执行之前执行
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//1.获取session
HttpSession session = request.getSession();
//2.获取session中的用户
Object user = session.getAttribute("user");
//3.判断用户是否存在
if(user==null){
//4.不存在,拦截
response.setStatus(401);
return false;
}
//5.存在,保存用户信息到ThreadLocal
UserHolder.saveUser((User)user);
//6.放行
return true;
}
//业务执行完毕执行
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
//移除用户
UserHolder.removeUser();
}
}
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginInterceptor())////配置拦截器
.excludePathPatterns(
"/user/code",
"/user/login",
"/blog/hot",
"/shop/**",
"/shop-type/**",
"upload/**",
"voucher/**"
);////配置拦截路径
}
}
面试的时候重点说的是Nginx和网关。
Nginx中提供了两种限流方式,分别是控制速率(突发流量)和控制并发连接数。
控制速率使用的是漏桶算法,上图中的水滴代表请求的流量,漏桶存储请求,漏桶以固定速率露出请求,多余请求等待或抛弃。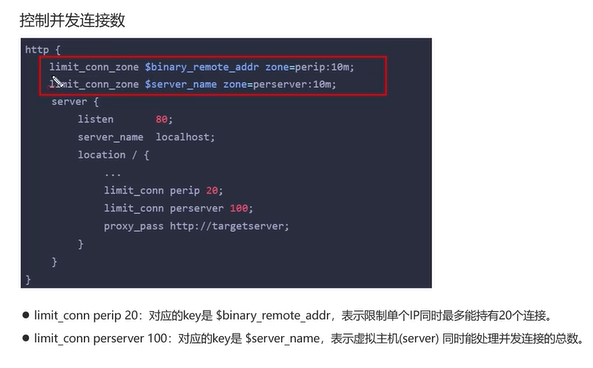


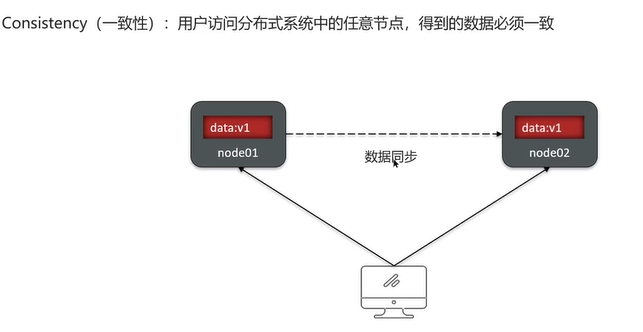
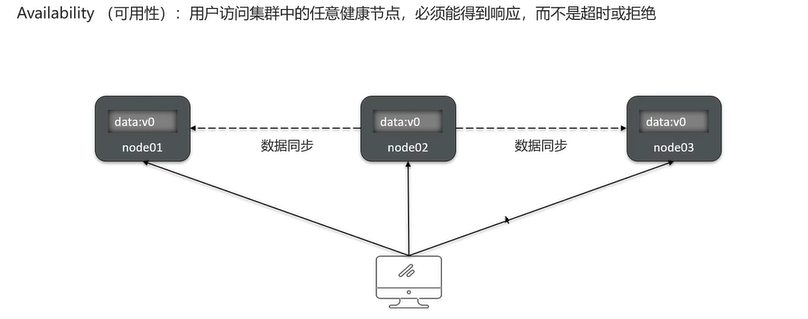
Q8:解释一下CAP和BASE?

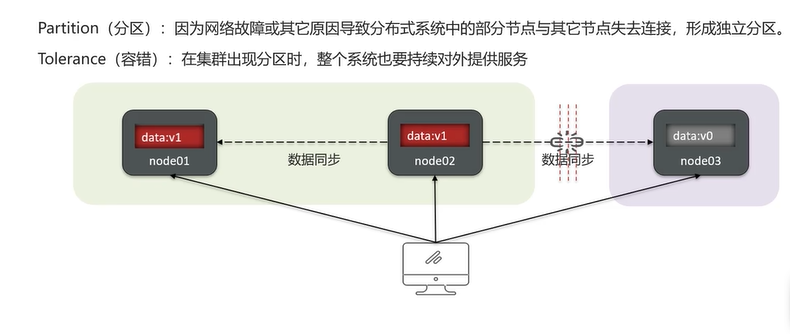
上图中节点node03因为网络故障或其他原因断开连结,node01与node02是一个分区,node03是一个分区。此时有请求修改了node02的数据,node02把数据同步到node01,但不能同步给noe03,出现了数据同步不一致的问题。分区的容错性必然存在(个别服务出现故障系统还是得对外提供服务),若是一定要满足数据一致性,则需要在访问node03时等待网络恢复、node02把数据同步node03,node03再把数据返回。这时需要访问node03时需要等待,阻塞了,node03不可用,不满足可用性。
BASE理论是对CAP一种解决思路。

Q9:你们采用哪种分布式事务解决方案?
说明:分布式事务中每一个微服务就是一个RM(资源管理器),各自的事务即分支事务。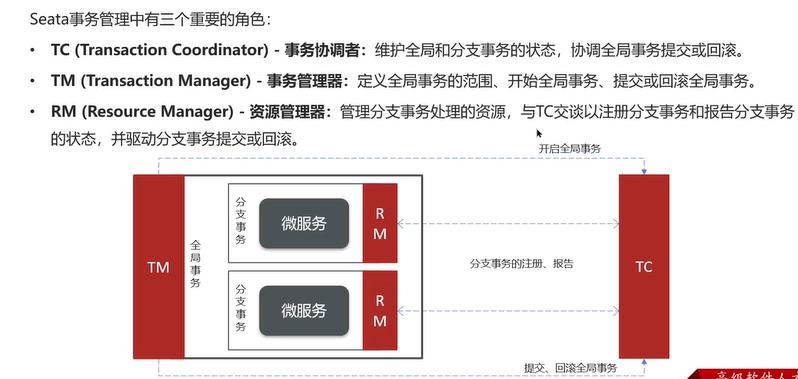
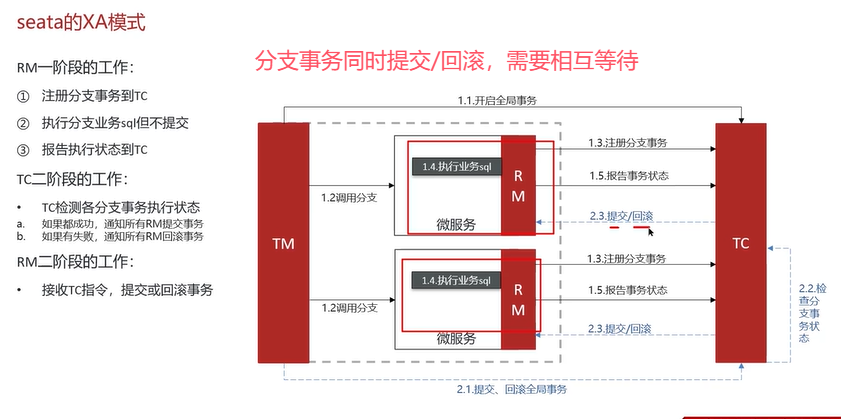
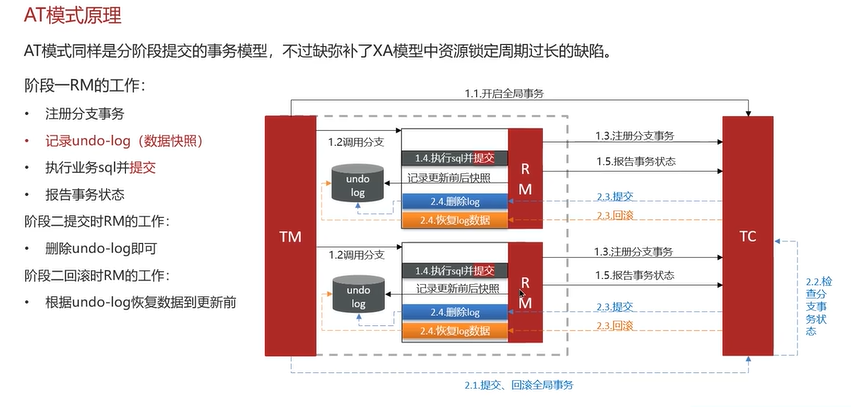
AT模式是Seata默认的模式。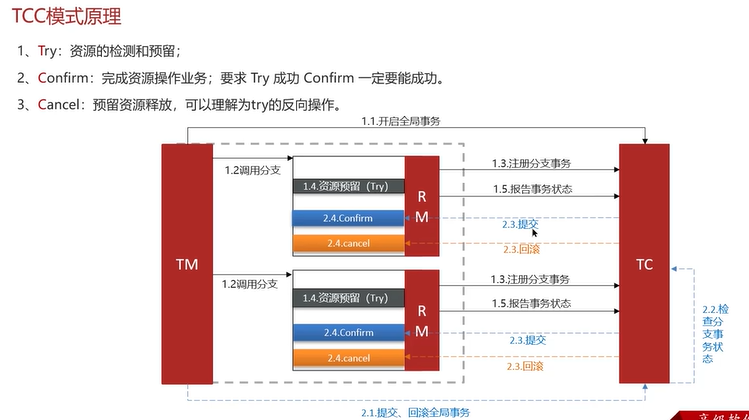
TCC模式的问题是RM的try、confirm和cancel需要通过代码的方式实现。
再来说一下MQ解决分布式事务的问题: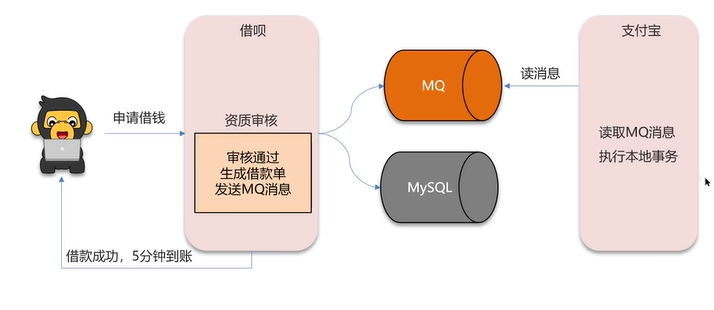
例如上图中的例子,用户向借呗申请借钱,审核通过之后支付宝的余额会增加。但是借呗和支付宝不是一个服务,这时可以使用MQ解决分布式事务的问题,借呗申请通过后生成借款单并通过MQ发送消息,支付宝读取到消息后直接去增加支付宝余额。但是这里有问题,因为可能支付宝增加余额时出现了异常,这种情况需要手动处理。
Q10:分布式服务的接口幂等性如何设计?
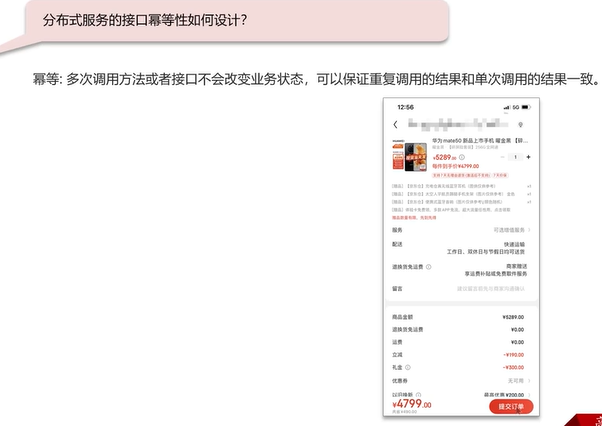
例如上图,用户点击多次“提交订单”只生成一个订单。
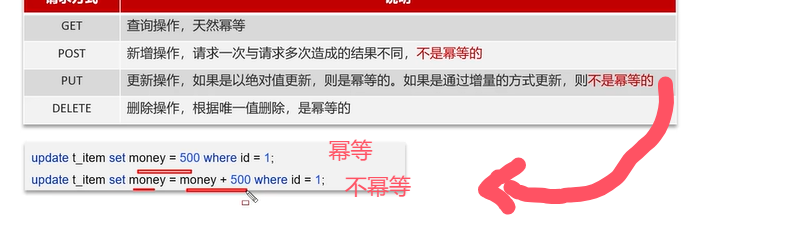
解决幂等性问题的方法:其实解决这个问题就是类似于用redis解决同一用户重复领取优惠券的问题。
说明:
(1)数据库唯一索引是指给表字段加唯一索引。
(2)token+redis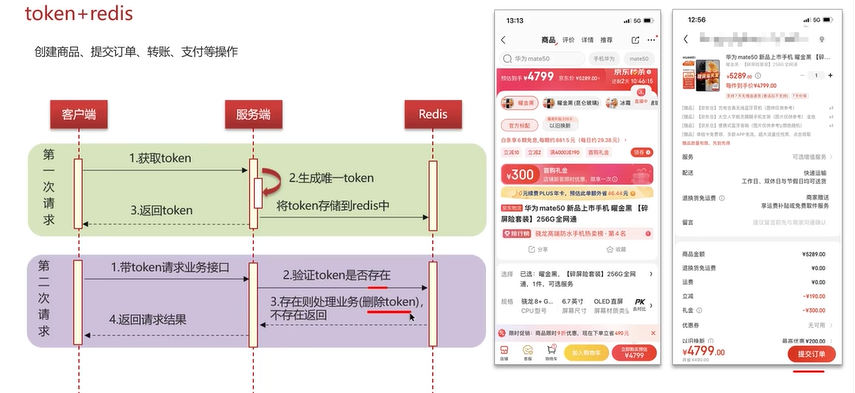
(3)分布式锁

Q11:你们项目中使用什么分布式任务调度?
常用xxl-job进行分布式任务调度。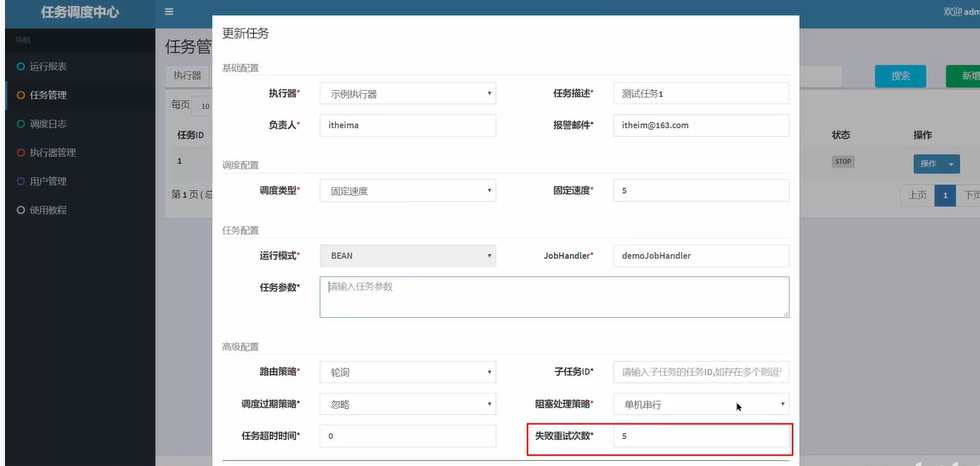

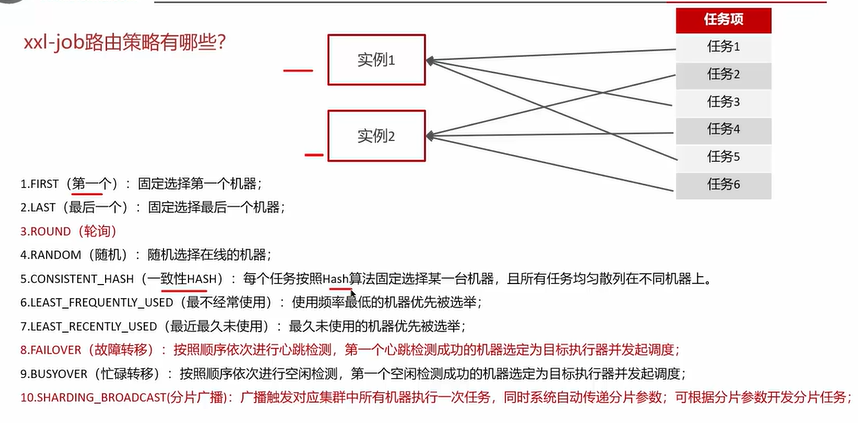
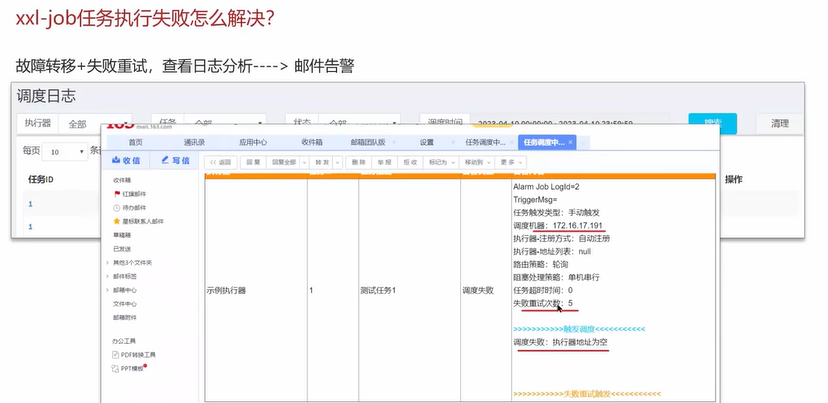


补充:其他非技术问题
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)