
IPv6时代如何做全球ip地址查询?字段兼容、位置解析与业务落地指南
摘要
IPv6普及后,全球ip地址查询要同时处理 IPv4、IPv6和双栈网络。文章用跨境 SaaS 登录场景说明字段兼容、位置解析和代码接入思路。
一、IPv6流量进来后,旧字段先出问题
IPv6普及后,很多团队第一次遇到的问题不是“能不能查到IP”,而是原来的 IP字段、缓存表、风控规则还能不能继续用。过去只按IPv4长度校验、只存 varchar(15)、只在订单表里记录国家字段的系统,在移动网络、海外访问和云厂商出口流量里会越来越吃力。
公开数据已经能说明趋势。Google IPv6 统计页面长期显示,全球访问Google 的用户中已有相当比例通过IPv6连接;APNIC也持续发布各经济体IPv6能力测量。对业务系统来说,这意味着全球ip地址查询不能只处理IPv4,还要稳定支持IPv6、双栈网络和运营商分配变化。
一个常见场景是跨境SaaS登录。用户在新加坡出差,用手机网络访问后台,日志里出现IPv6地址;旧系统因为字段过短,直接截断或写入失败,后面的“异地登录提醒”“区域服务分发”“审计日志”都会受影响。更稳的做法是先完成地址类型识别,再调用查询服务返回国家、省州、城市、运营商、ASN、连接类型等字段。
二、先判断IP版本,再请求查询接口
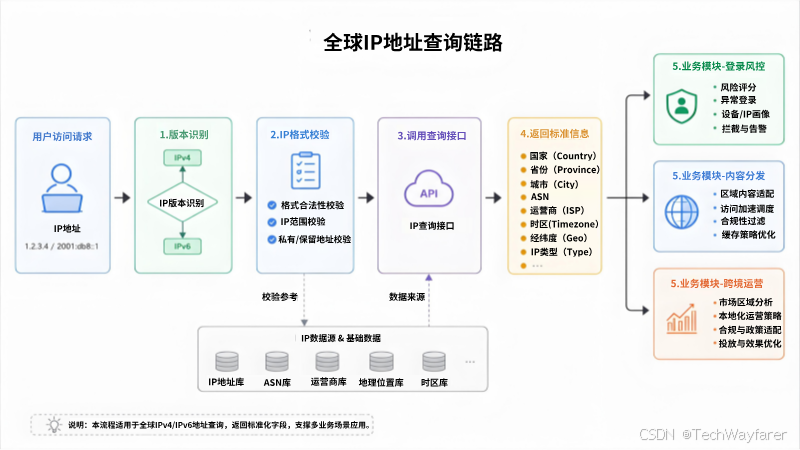
全球ip地址查询中IPv4和IPv6字段兼容流程图
这段示例适合放在登录服务、网关层或日志清洗任务里。它先用 ipaddress 标准库识别 IPv4/IPv6,再把规范化后的 IP 传给查询接口;接口地址和返回字段请按实际文档替换。
import ipaddress
import os
import requests
API_KEY = os.getenv("IPDATA_KEY")
API_URL = "https://api.ipdatacloud.com/v2/query" # 替换为实际接口
def query_ip(ip: str) -> dict:
ip_obj = ipaddress.ip_address(ip)
resp = requests.get(API_URL, params={"ip": str(ip_obj), "key": API_KEY}, timeout=2)
resp.raise_for_status()
data = resp.json()
return {
"ip": str(ip_obj),
"ip_version": ip_obj.version,
"country": data.get("country"),
"region": data.get("region"),
"city": data.get("city"),
"asn": data.get("asn"),
"isp": data.get("isp")
}
print(query_ip("2408:8207:1234::1"))三、上线前,缓存和监控要先想清楚
落地时建议做三件事。第一,数据库字段用 varchar(45) 或二进制结构存储IP,避免IPv6被截断。第二,日志、风控、画像系统统一保存ip_version,这样后续排查IPv6命中率更直接。第三,缓存策略按“IP段、运营商、更新时间”设计,不要把单次查询结果长期当成不变事实。
如果企业需要把查询结果接入登录风控、内容分发或跨境运营,可以把IP数据云这类服务放在网关或业务中台层,统一输出规范字段。这样应用侧不用重复适配 IPv4/IPv6,后续新增风险画像、异常网络识别、IDC识别时也更容易扩展。
全球ip地址查询在IPv6时代不是一个简单接口问题,而是数据模型问题。谁先把字段、缓存和策略层理顺,谁就能在跨境访问、移动网络和云上流量里少踩很多坑。
上线前还可以做一次历史日志回放。把近7到14天的访问IP抽样,分别统计 IPv4、IPv6、IPv4 映射地址、内网地址和解析失败地址的占比,再看失败样本集中在哪些入口。很多团队会发现,失败不是接口能力不足,而是埋点、队列、数据仓库中间某一层仍按IPv4处理。这个排查成本不高,却能提前避免线上报表断层。
字段设计也要留出扩展空间。建议至少保存 ip_raw、ip_normalized、ip_version、country_code、region、city、asn、isp、updated_at 和 source。如果业务有风控需求,再增加 usage_type、risk_level、is_risky_network 等字段。这样同一条查询结果既能服务用户体验,也能进入安全审计和BI分析。
在缓存策略上,IPv6不建议简单按单个地址永久缓存。运营商和移动网络的分配会变化,海外云厂商出口也可能调整。更可控的做法是设置短周期缓存,并保留数据更新时间。对于登录提醒、城市默认值这类低风险功能,可以接受分钟级到小时级缓存;对支付风控、账号保护等敏感链路,应优先使用实时查询或更短 TTL。
到这一步,IPv6兼容不是为了追新技术,而是为了不丢数据、不误判用户、不让业务规则在新网络环境下失效。把全球ip地址查询做成基础能力后,后续无论是跨境SaaS、内容分发还是风控审计,都能复用同一套结果。
还有一个容易被忽略的点是监控。建议把查询成功率、IPv6解析失败率、接口耗时、缓存命中率做成看板。一旦某个运营商或国家的失败率突然升高,研发能第一时间判断是接口、网络还是上游数据变化,而不是等用户投诉后才排查。
四、写在最后
IPv6时代的全球ip地址查询,真正难点不在于多调一次接口,而在于字段、缓存、日志和风控规则能不能一起兼容。先把底层数据做稳,后面的登录提醒、服务分发和风险识别才不会反复返工。
数据来源
- Google IPv6 Statistics
- APNIC Labs IPv6 Measurement
- IANA IPv6 Address Space Registry
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)