
python之json的折线图
一、JSON 数据处理
1.1 JSONP 格式处理
问题: 从网页获取的数据往往是 JSONP 格式(带函数调用),不是标准 JSON。
javascript
// ❌ JSONP 格式(不能直接解析)
jsonp_1629344292311_69436({
"data": [...]
});
// ✅ 标准 JSON 格式(可以解析)
{
"data": [...]
}
解决方案:
python
import json
# 读取原始数据
f_us = open("美国.txt", "r", encoding="UTF-8")
us_data = f_us.read()
f_us.close()
# 去掉不合JSON规范的开头
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
# 去掉不合JSON规范的结尾(去掉 ");")
us_data = us_data[:-2]
# JSON转Python字典
us_dict = json.loads(us_data)
1.2 常用方法
| 方法 | 说明 | 示例 |
|---|---|---|
json.loads() |
JSON字符串 → Python字典 | json.loads('{"name":"张三"}') |
json.dumps() |
Python字典 → JSON字符串 | json.dumps({"name":"张三"}) |
replace() |
替换字符串中的内容 | "abc".replace("a", "A") |
[:-2] |
切片,去掉最后2个字符 | "abc"[:-2] → "a" |
二、Pyecharts 折线图
2.1 完整模板
python
from pyecharts.charts import Line
from pyecharts import options as opts
# 1. 创建折线图对象
line = Line()
# 2. 添加数据
line.add_xaxis(x_data) # x轴数据(日期)
line.add_yaxis("系列名称", y_data) # y轴数据(数值)
# 3. 设置全局配置
line.set_global_opts(
title_opts=opts.TitleOpts(title="图表标题"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
xaxis_opts=opts.AxisOpts(name="X轴名称"),
yaxis_opts=opts.AxisOpts(name="Y轴名称")
)
# 4. 生成HTML文件
line.render("文件名.html")
2.2 完整示例(多国对比)
python
import json
from pyecharts.charts import Line
from pyecharts import options as opts
# 读取三国数据
def load_data(file_path, callback_name):
with open(file_path, "r", encoding="UTF-8") as f:
data = f.read()
data = data.replace(callback_name, "")
data = data[:-2]
return json.loads(data)
# 加载数据
us_dict = load_data("美国.txt", "jsonp_1629344292311_69436(")
jp_dict = load_data("日本.txt", "jsonp_1629350871167_29498(")
in_dict = load_data("印度.txt", "jsonp_1629350745930_63180(")
# 提取数据
us_trend = us_dict["data"][0]["trend"]
jp_trend = jp_dict["data"][0]["trend"]
in_trend = in_dict["data"][0]["trend"]
x_data = us_trend["date"][:314] # 共用x轴
us_y_data = us_trend["confirm"][:314]
jp_y_data = jp_trend["confirm"][:314]
in_y_data = in_trend["confirm"][:314]
# 生成图表
line = (
Line(init_opts=opts.InitOpts(width="1200px", height="600px"))
.add_xaxis(x_data)
.add_yaxis("美国", us_y_data)
.add_yaxis("日本", jp_y_data)
.add_yaxis("印度", in_y_data)
.set_global_opts(
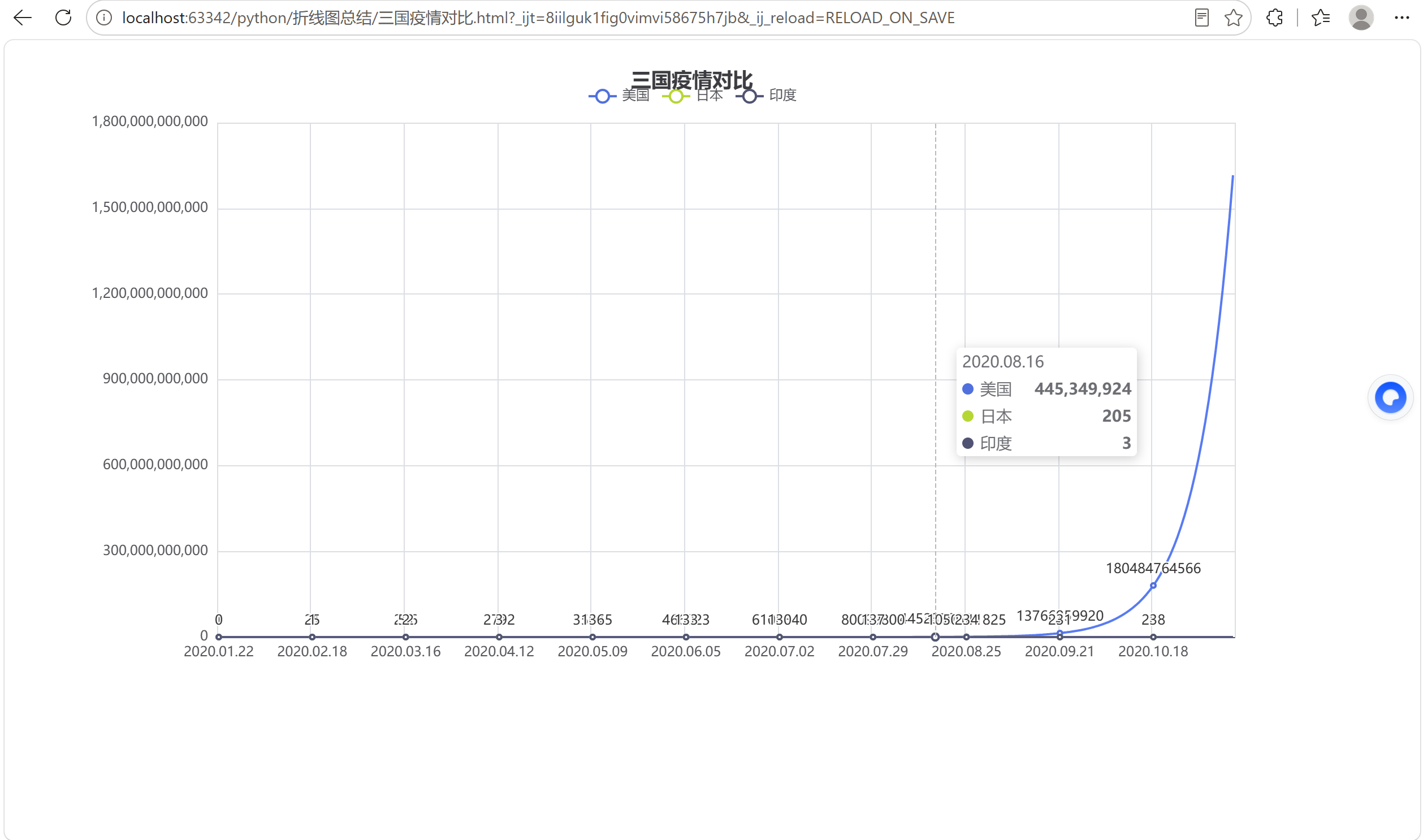
title_opts=opts.TitleOpts(title="三国疫情对比"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
legend_opts=opts.LegendOpts(pos_top="5%")
)
)
line.render("三国疫情对比.html")
print("✅ 图表已生成!")
补充:
# 读取三国数据 def load_data(file_path, callback_name): with open(file_path, "r", encoding="UTF-8") as f: data = f.read() data = data.replace(callback_name, "") data = data[:-2] return json.loads(data)这是啥意思啊
📖 逐句详解
这是一个自定义函数,用来重复做同一件事(读取、清洗、解析JSON数据)。
🔍 逐行拆解
1️⃣ 函数定义
python
def load_data(file_path, callback_name):
-
def= 定义函数 -
load_data= 函数名(你自己起的,意思是"加载数据") -
(file_path, callback_name)= 两个参数,调用函数时需要传入
2️⃣ 打开并读取文件
python
with open(file_path, "r", encoding="UTF-8") as f:
data = f.read()
拆解:
-
with open(...) as f:= 打开文件,用完后自动关闭(安全写法) -
file_path= 文件路径(函数参数传进来的) -
"r"= 只读模式 -
encoding="UTF-8"= 用UTF-8编码读取(支持中文) -
data = f.read()= 读取文件全部内容,存入变量data
举例:
python
# 如果调用时传入 file_path = "美国.txt"
# 相当于执行:
with open("美国.txt", "r", encoding="UTF-8") as f:
data = f.read()
3️⃣ 去掉不合JSON规范的开头
python
data = data.replace(callback_name, "")
拆解:
-
data.replace(旧内容, 新内容)= 把旧内容替换成新内容 -
callback_name= 要替换掉的JSONP函数名(函数参数传进来的) -
""= 替换成空字符串(相当于删除)
举例:
python
# 假设 data = 'jsonp_123({"name":"美国"})'
# callback_name = "jsonp_123("
data = data.replace("jsonp_123(", "")
# 结果:data = '{"name":"美国"})'
4️⃣ 去掉不合JSON规范的结尾
python
data = data[:-2]
拆解:
-
[:-2]= 切片操作,去掉最后2个字符 -
因为JSONP格式结尾通常是
);,要去掉
举例:
python
# data = '{"name":"美国"});'
data = data[:-2]
# 结果:data = '{"name":"美国"}'
5️⃣ 解析JSON并返回
python
return json.loads(data)
拆解:
-
json.loads(data)= 把JSON字符串转换为Python字典 -
return= 把转换后的字典返回给调用者
🎯 完整流程示例
调用函数
python
import json
us_dict = load_data("美国.txt", "jsonp_1629344292311_69436(")
执行过程
python
# 第1步:打开"美国.txt",读取内容
# data = 'jsonp_1629344292311_69436({"data":[{"name":"美国"}]});'
# 第2步:去掉开头
# data = data.replace("jsonp_1629344292311_69436(", "")
# data = '{"data":[{"name":"美国"}]});'
# 第3步:去掉结尾
# data = data[:-2]
# data = '{"data":[{"name":"美国"}]}'
# 第4步:JSON转字典并返回
# return json.loads(data)
# 返回:{"data": [{"name": "美国"}]}
💡 为什么要用函数?
❌ 不用函数(重复代码)
python
# 读取美国数据
with open("美国.txt", "r", encoding="UTF-8") as f:
us_data = f.read()
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
us_data = us_data[:-2]
us_dict = json.loads(us_data)
# 读取日本数据(重复同样操作)
with open("日本.txt", "r", encoding="UTF-8") as f:
jp_data = f.read()
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
jp_data = jp_data[:-2]
jp_dict = json.loads(jp_data)
# 读取印度数据(再次重复)
with open("印度.txt", "r", encoding="UTF-8") as f:
in_data = f.read()
in_data = in_data.replace("jsonp_1629350745930_63180(", "")
in_data = in_data[:-2]
in_dict = json.loads(in_data)
问题:代码重复3次,又长又难维护!
✅ 用函数(简洁优雅)
python
def load_data(file_path, callback_name):
with open(file_path, "r", encoding="UTF-8") as f:
data = f.read()
data = data.replace(callback_name, "")
data = data[:-2]
return json.loads(data)
# 一行代码读取一个国家数据
us_dict = load_data("美国.txt", "jsonp_1629344292311_69436(")
jp_dict = load_data("日本.txt", "jsonp_1629350871167_29498(")
in_dict = load_data("印度.txt", "jsonp_1629350745930_63180(")
优点:
-
✅ 代码更短
-
✅ 逻辑清晰
-
✅ 修改一处,全部生效
-
✅ 可以重复使用
2.3 常用配置项
| 配置 | 作用 | 示例 |
|---|---|---|
TitleOpts |
标题 | title_opts=opts.TitleOpts(title="标题") |
TooltipOpts |
鼠标悬停提示 | tooltip_opts=opts.TooltipOpts(trigger="axis") |
LegendOpts |
图例 | legend_opts=opts.LegendOpts(pos_top="5%") |
AxisOpts |
坐标轴 | xaxis_opts=opts.AxisOpts(name="日期") |
DataZoomOpts |
缩放滑块 | datazoom_opts=[opts.DataZoomOpts()] |
MarkPointOpts |
标记点(最大/最小) | markpoint_opts=opts.MarkPointOpts(data=[...]) |
MarkLineOpts |
标记线(平均线) | markline_opts=opts.MarkLineOpts(data=[...]) |
三、Pyecharts 地图
3.1 基础地图

python
from pyecharts.charts import Map
from pyecharts import options as opts
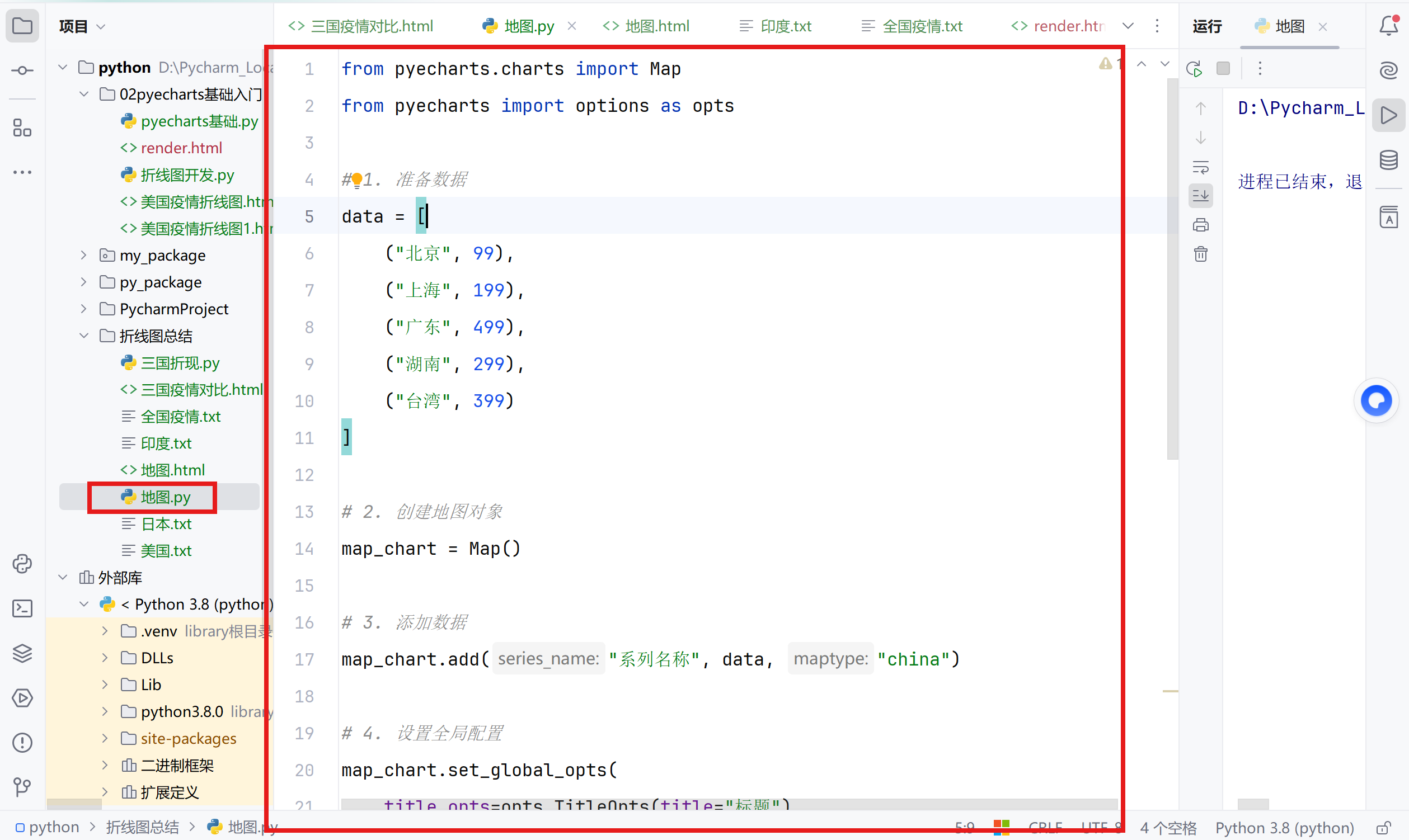
# 1. 准备数据
data = [
("北京", 99),
("上海", 199),
("广东", 499),
("湖南", 299),
("台湾", 399)
]
# 2. 创建地图对象
map_chart = Map()
# 3. 添加数据
map_chart.add("系列名称", data, "china")
# 4. 设置全局配置
map_chart.set_global_opts(
title_opts=opts.TitleOpts(title="标题"),
visualmap_opts=opts.VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min": 1, "max": 99, "label": "1-99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "label": "100-999人", "color": "#FFFF99"},
{"min": 1000, "label": "1000以上", "color": "#CC3333"}
]
)
)
# 5. 生成文件
map_chart.render("地图.html")
3.2 全国疫情地图完整示例
python
import json
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.options import TitleOpts, VisualMapOpts
# 1. 读取数据
with open("全国疫情.txt", "r", encoding="UTF-8") as f:
raw_data = f.read()
# 2. 去掉JSONP包装
raw_data = raw_data.replace("jsonp_1629344292311_69436(", "")
raw_data = raw_data[:-2]
# 3. 解析JSON
data_dict = json.loads(raw_data)
# 4. 提取各省数据
children = data_dict["areaTree"][0]["children"]
data_list = []
for province in children:
name = province["name"]
confirm = province["total"]["confirm"]
data_list.append((name, confirm))
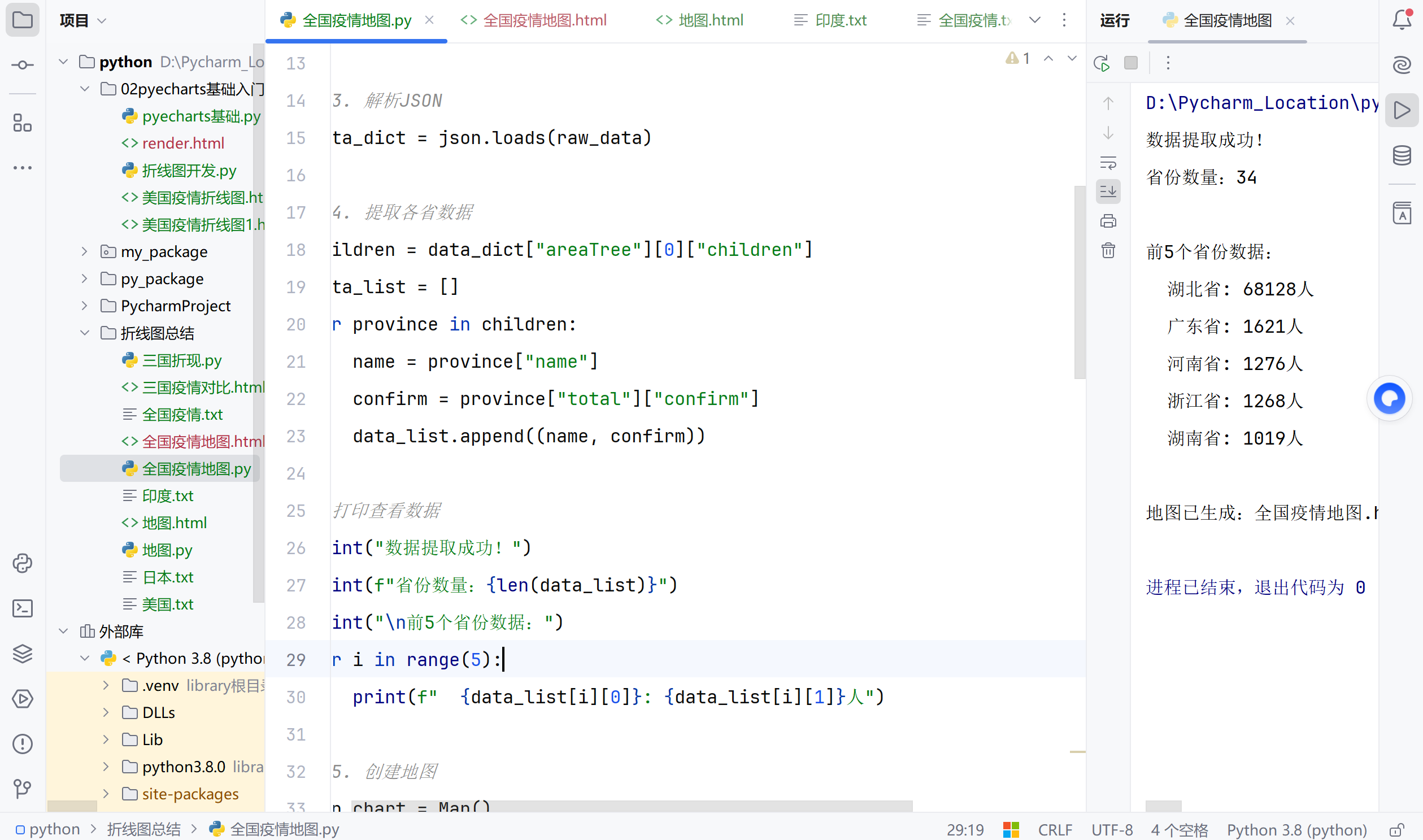
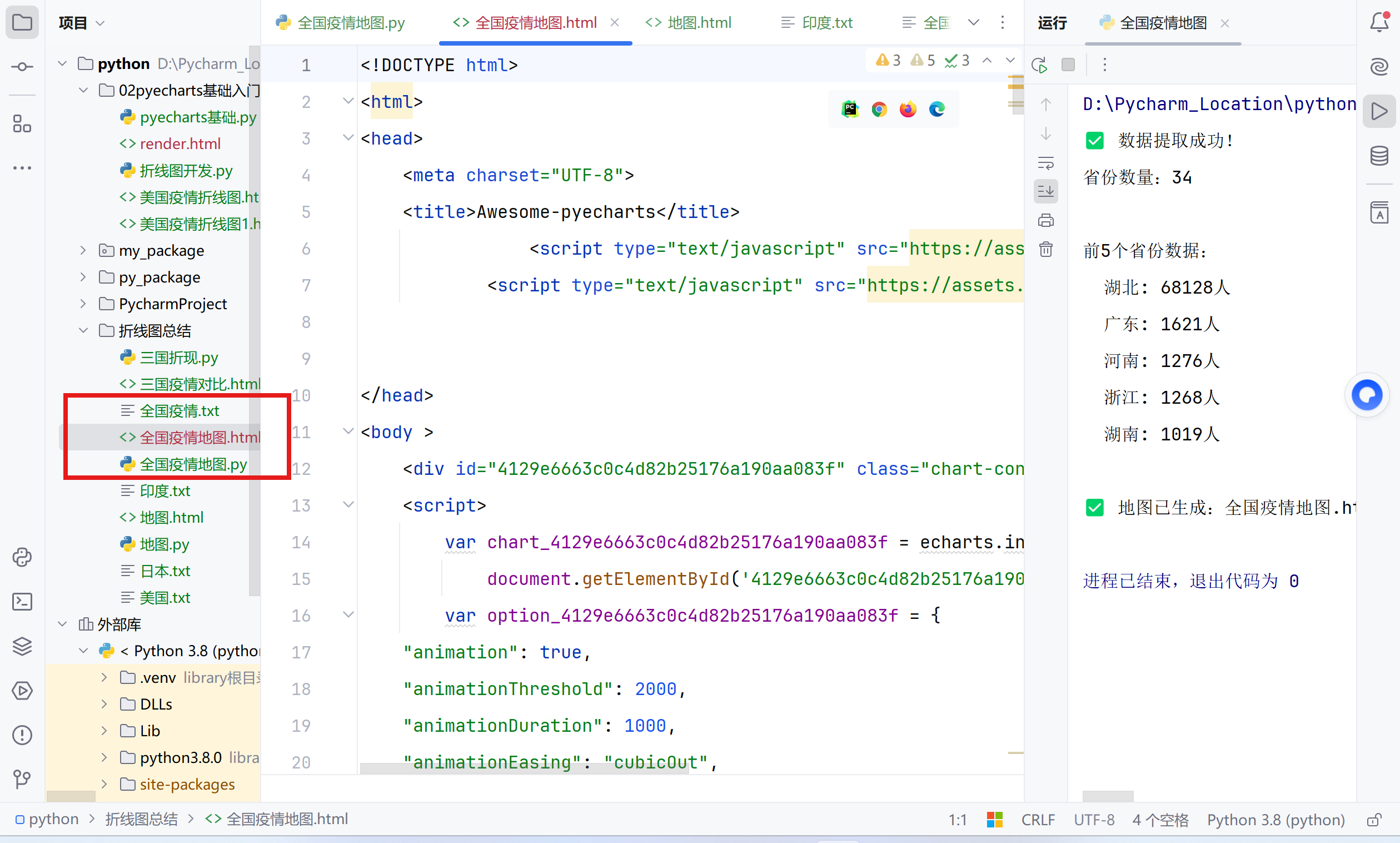
# 打印查看数据
print("数据提取成功!")
print(f"省份数量:{len(data_list)}")
print("\n前5个省份数据:")
for i in range(5):
print(f" {data_list[i][0]}: {data_list[i][1]}人")
# 5. 创建地图
map_chart = Map()
# 6. 添加数据
map_chart.add("各省确诊人数", data_list, "china")
# 7. 设置全局配置
map_chart.set_global_opts(
title_opts=TitleOpts(
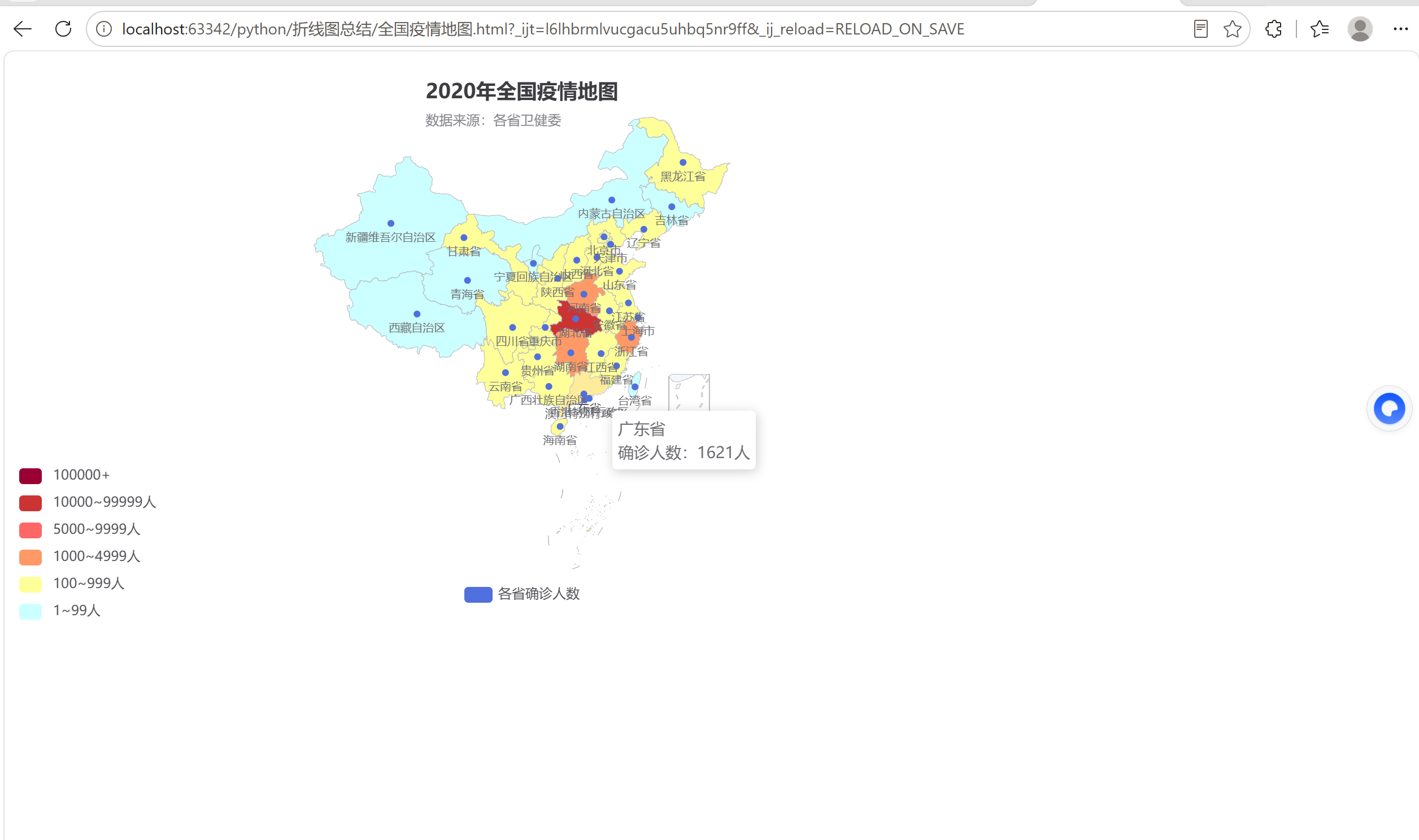
title="2020年全国疫情地图",
subtitle="数据来源:各省卫健委",
pos_left="center"
),
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min": 1, "max": 99, "label": "1~99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "label": "100~999人", "color": "#FFFF99"},
{"min": 1000, "max": 4999, "label": "1000~4999人", "color": "#FF9966"},
{"min": 5000, "max": 9999, "label": "5000~9999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "label": "10000~99999人", "color": "#CC3333"},
{"min": 100000, "label": "100000+", "color": "#990033"}
]
),
tooltip_opts=opts.TooltipOpts(
trigger="item",
formatter="{b}<br/>确诊人数:{c}人" # 直接用字符串,不需要 f-string
)
)
# 8. 设置系列配置
map_chart.set_series_opts(
label_opts=opts.LabelOpts(
is_show=True,
font_size=10
)
)
# 9. 生成HTML文件
map_chart.render("全国疫情地图.html")
print("\n地图已生成:全国疫情地图.html")
四、数据提取模式
4.1 标准数据结构
你的数据通常长这样:
json
{
"data": [
{
"name": "国家名",
"trend": {
"date": ["2020.01.22", "2020.01.23", ...],
"confirm": [1, 2, 3, ...]
}
}
]
}
4.2 提取数据模板
python
# 提取趋势数据 trend = data_dict["data"][0]["trend"] # 提取日期(x轴) x_data = trend["date"][:315] # 取前315天 # 提取确诊数(y轴) y_data = trend["confirm"][:315] # 取前315天
4.3 数据验证
python
# 查看数据长度
print(f"日期数量:{len(x_data)}")
print(f"确诊数量:{len(y_data)}")
# 查看前几条数据
print(f"前3个日期:{x_data[:3]}")
print(f"前3个确诊数:{y_data[:3]}")
# 查看数据统计
print(f"最大值:{max(y_data)}")
print(f"最小值:{min(y_data)}")
print(f"平均值:{sum(y_data) / len(y_data):.0f}")
五、常用技巧
5.1 文件操作
python
# 方法1:使用 with 语句(推荐,自动关闭)
with open("文件.txt", "r", encoding="UTF-8") as f:
data = f.read()
# 方法2:手动打开和关闭
f = open("文件.txt", "r", encoding="UTF-8")
data = f.read()
f.close()
5.2 多个文件处理
python
# 批量读取多个文件
files = {
"美国": "jsonp_1629344292311_69436(",
"日本": "jsonp_1629350871167_29498(",
"印度": "jsonp_1629350745930_63180("
}
data_dicts = {}
for country, callback in files.items():
with open(f"D:/{country}.txt", "r", encoding="UTF-8") as f:
data = f.read()
data = data.replace(callback, "")
data = data[:-2]
data_dicts[country] = json.loads(data)
5.3 链式调用(pyecharts特色)
python
line = (
Line()
.add_xaxis(x_data)
.add_yaxis("系列名", y_data)
.set_global_opts(...)
.set_series_opts(...)
)
六、常见错误及解决
| 错误 | 原因 | 解决 |
|---|---|---|
FileNotFoundError |
文件不存在 | 检查文件路径和文件名 |
JSONDecodeError |
JSON格式错误 | 检查是否去除了JSONP包装 |
KeyError |
字典键不存在 | 检查数据结构,确认键名正确 |
IndexError |
列表索引超出范围 | 检查数据长度,确认有足够数据 |
| 控制台无输出 | 没有使用print | 添加print语句查看数据 |
| 图表不显示 | 没有调用render() | 确保调用了 .render() |
总结:
🎯 折线图开发三步曲
python
# 第1步:提取数据(数据准备) # 第2步:添加数据(配置图表) # 第3步:绘制图表(生成HTML)
📊 三步详细说明
| 步骤 | 做什么 | 关键代码 | 说明 |
|---|---|---|---|
| 第1步:提取数据 | 从文件读取并解析数据 | json.loads() |
把数据从文件变成Python能用的格式 |
| 第2步:添加数据 | 把数据放入图表对象 | .add_xaxis() .add_yaxis() |
告诉图表要画什么 |
| 第3步:绘制图表 | 生成HTML文件 | .render() |
把图表保存为网页文件 |
更多推荐


 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)