
【高光谱图像数据处理实战】基于Python的ENVI图像交互式裁剪与光谱数据预处理
前言
在处理高光谱图像数据(Hyperspectral Imaging, HSI)时,我们常常需要面对两个核心问题:一是如何从庞大的三维数据立方体(Data Cube)中高效、准确地提取感兴趣区域(ROI);二是如何对提取出的一维光谱数据进行科学的预处理,以消除噪声和基线漂移。
本文将分享两个非常实用的 Python 脚本,分别解决上述两个痛点,涵盖了从交互式图像裁剪到一维光谱数据预处理的完整工作流。
在开始之前,请确保你的 Python 环境中安装了以下库:
pip install opencv-python spectral numpy pandas scipy openpyxl第一部分:基于 OpenCV 的 ENVI 图像交互式中心点裁剪
高光谱图像通常体积庞大(RAW + HDR 格式)。第一段代码实现了一个带有基础 GUI 的工具,它可以弹出文件夹选择框批量读取 RAW 图像,通过 OpenCV 提取单波段进行灰度显示,允许用户鼠标点击图像上的目标中心点,随后自动裁剪出一个 像素、包含全部波段的区域,并保存为轻量化的 格式。
代码亮点:
-
交互式选点:利用
cv2.setMouseCallback实现鼠标点击获取坐标,所见即所得。 -
逐波段读取(防内存溢出):没有直接将几 GB 的 RAW 文件全部读入内存,而是通过
img.read_band()配合循环逐波段切片,极大地降低了内存占用。 -
进度预览:裁剪完成后自动计算各波段均值,生成
.jpg预览图。 -
import cv2 as cv import spectral.io.envi as envi import numpy as np import os from tkinter import filedialog, Tk import spectral # 设置 ENVI 配置支持非小写的参数 spectral.settings.envi_support_nonlowercase_params = True # 创建Tkinter窗口并隐藏,用于优雅地调用文件选择对话框 root = Tk() root.withdraw() # 弹出对话框选择包含数据文件的文件夹路径 folder_path = filedialog.askdirectory(title='选择输入文件夹(包含RAW和HDR文件)') out_path = filedialog.askdirectory(title='选择输出文件夹') os.makedirs(out_path, exist_ok=True) print("=" * 50) print(f"输入文件夹: {folder_path}") print(f"输出文件夹: {out_path}") print("=" * 50) # 鼠标回调函数:手动标记中心点 def click_event(event, x, y, flags, param): global marked_point, image_raw_display, point_marked if event == cv.EVENT_LBUTTONDOWN and not point_marked: # 记录坐标(注意 OpenCV 和 numpy 的 x,y 对应关系) marked_point = (y, x) point_marked = True print(f"标记点:({y}, {x})") # 在原图像上绘制红色标记点 cv.circle(image_raw_display, (x, y), 5, (0, 0, 255), -1) cv.imshow('Original Image with Marked Points', image_raw_display) cv.waitKey(300) cv.destroyWindow('Original Image with Marked Points') # 统计总文件数 raw_files = [f for f in os.listdir(folder_path) if f.endswith('.raw')] print(f"找到 {len(raw_files)} 个RAW文件") # 遍历处理 for idx, filename in enumerate(raw_files, 1): print(f"\n[{idx}/{len(raw_files)}] 处理文件: {filename}") raw_file_path = os.path.join(folder_path, filename) name = filename[:-4] hdr_file_path = os.path.join(folder_path, filename[:-4] + '.hdr') if os.path.isfile(hdr_file_path): img = envi.open(hdr_file_path, raw_file_path) x, y = img.shape[:2] z = img.nbands print(f" 原始尺寸: {x} x {y} x {z}") # 生成预览图以供选点 preview_band = min(50, z - 1) image_data = img.read_band(preview_band) image_raw_display = np.uint8(image_data / np.max(image_data) * 255) marked_point = None point_marked = False cv.imshow('Original Image with Marked Points', image_raw_display) cv.setMouseCallback('Original Image with Marked Points', click_event) print(" 请在弹出的图像上点击目标中心点...") start_time = cv.getTickCount() while not point_marked: elapsed_time = (cv.getTickCount() - start_time) / cv.getTickFrequency() if elapsed_time > 30: # 30秒超时机制 print(" 30秒内未标记点,跳过该图像。") cv.destroyWindow('Original Image with Marked Points') break if cv.waitKey(10) == 27: # ESC键退出 print(" 用户取消标记,跳过该图像。") cv.destroyWindow('Original Image with Marked Points') break if not marked_point: print(" 未标记点,跳过") continue center_x, center_y = marked_point crop_size = 500 # 设定裁剪大小 # 计算裁剪边界,防止越界 start_x = max(center_x - crop_size // 2, 0) start_y = max(center_y - crop_size // 2, 0) end_x = min(center_x + crop_size // 2, x) end_y = min(center_y + crop_size // 2, y) band_start = 0 band_end = min(616, z) # 初始化空数组存储裁剪数据 cropped_image = np.zeros((end_x - start_x, end_y - start_y, band_end - band_start), dtype=np.float32) # 重点:逐波段读取,避免内存溢出 for band in range(band_start, band_end): band_data = img.read_band(band)[start_x:end_x, start_y:end_y] cropped_image[:, :, band - band_start] = band_data print(f" 裁剪后尺寸: {cropped_image.shape}") # 保存为 .npy 格式 output_npy_path = os.path.join(out_path, name + '.npy') np.save(output_npy_path, cropped_image) # 生成均值灰度预览图 mean_image = np.mean(cropped_image, axis=2) mean_image = (mean_image / mean_image.max() * 255).astype(np.uint8) cv.imwrite(os.path.join(out_path, name + '.jpg'), mean_image) print(f" ✓ 完成") else: print(f" ⚠ 缺少HDR文件,跳过") print("\n" + "=" * 50) print("所有文件处理完成!") print("=" * 50)结果
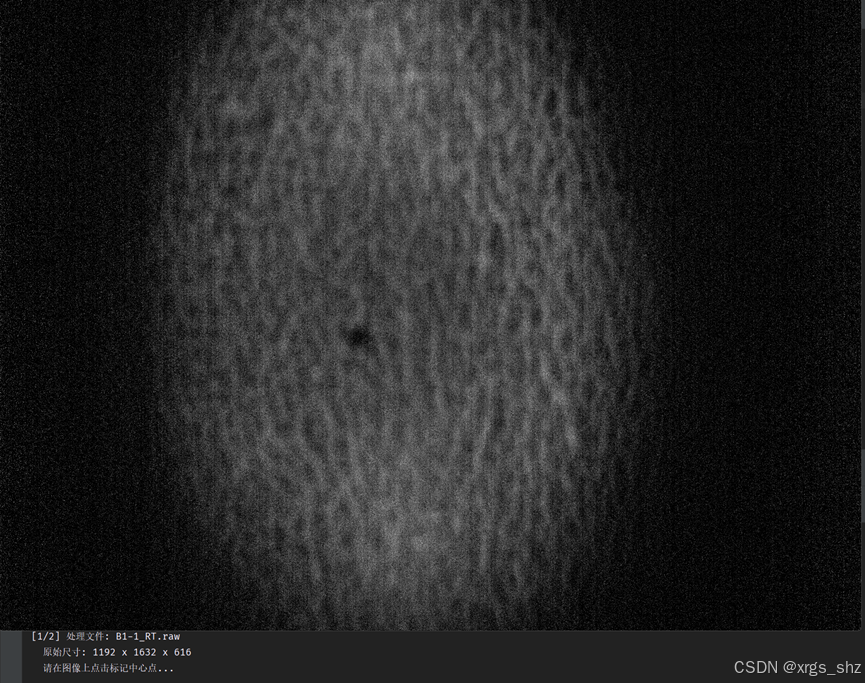
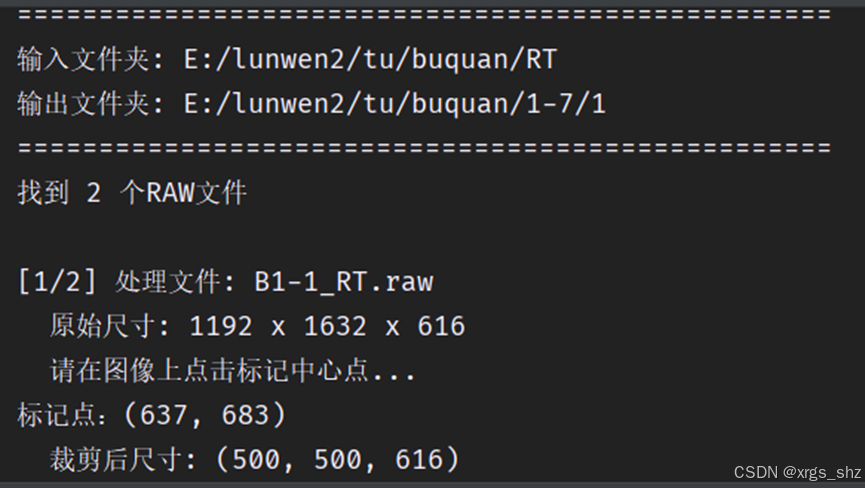

-
第二部分:一维光谱数据的预处理流水线
-
把高光谱图像整理成一维的光谱特征(例如提取平均光谱保存到 Excel 中)后,往往需要进行数学预处理以用于后续的机器学习/深度学习建模。第二段代码构建了一个高度可定制的预处理流水线。 可以通过简单地修改一个列表 ,让数据依次经过 SG平滑 -> SNV -> 一阶导数choices = [3, 1, 4]等操作,并自动根据处理流程重命名输出文件。
-
支持的预处理算法:
-
SNV (标准正态变换):消除表面散射影响。
-
MSC(多元散射校正):校正由于样品颗粒大小不同造成的散射。
-
Savitzky-Golay (SG) 平滑:去除高频噪声,保留光谱特征。
-
一阶/二阶导数:突出光谱吸收峰特征,消除基线平移。
-
Detrend (去趋势):消除由于仪器发热等引起的线性基线漂移。
-
import pandas as pd import numpy as np from scipy.signal import savgol_filter, detrend import os # ==================== 预处理方法定义 ==================== def snv(data): """标准正态变换 (SNV)""" mean = np.mean(data, axis=1, keepdims=True) std = np.std(data, axis=1, keepdims=True) std[std == 0] = 1e-8 return (data - mean) / std def msc(data): """多元散射校正 (MSC)""" n_samples, n_features = data.shape ref_spectrum = np.mean(data, axis=0) data_msc = np.zeros_like(data) for i in range(n_samples): fit = np.polyfit(ref_spectrum, data[i, :], 1, full=True) k, b = fit[0][0], fit[0][1] data_msc[i, :] = (data[i, :] - b) / k return data_msc def sg_smooth(data, window_length=15, polyorder=2): """Savitzky-Golay 平滑""" return savgol_filter(data, window_length=window_length, polyorder=polyorder, deriv=0, axis=1) def diff_1st(data): """一阶导数 (直接差分计算)""" return np.gradient(data, axis=1) def diff_2nd(data): """二阶导数 (直接差分计算)""" return np.gradient(np.gradient(data, axis=1), axis=1) def detrend_data(data): """去趋势 (消除基线漂移)""" return detrend(data, axis=1, type='linear') # ==================== 主程序逻辑 ==================== def main(input_file, choices): output_dir = os.path.dirname(input_file) base_name = os.path.basename(input_file) print(f"正在读取数据: {input_file} ...") try: df = pd.read_excel(input_file) except Exception as e: print(f"读取文件失败,请检查路径。错误信息: {e}") return # 分离元数据(前两列)和光谱数据(后续列) meta_data = df.iloc[:, :2] spectra_data = df.iloc[:, 2:].values band_names = df.columns[2:] print("正在进行光谱预处理...") # 构建操作映射字典 (函数, 缩写前缀, 描述) operations = { 1: (snv, "SNV", "SNV (标准正态变换)"), 2: (msc, "MSC", "MSC (多元散射校正)"), 3: (lambda d: sg_smooth(d, window_length=15, polyorder=2), "SG", "SG 平滑"), 4: (diff_1st, "1stDeriv", "一阶导数"), 5: (diff_2nd, "2ndDeriv", "二阶导数"), 8: (detrend_data, "Detrend", "去趋势 (消除基线漂移)") } if not choices or 7 in choices: processed_spectra = spectra_data final_prefix = "RAW" print("-> 正在应用: Raw (保持原始数据不作处理)") else: processed_spectra = spectra_data.copy() prefixes = [] # 兼容旧版本的组合逻辑 if 6 in choices: choices.remove(6) choices.extend([3, 1]) # SG -> SNV # 流水线执行 for c in choices: if c in operations: func, prefix_name, desc = operations[c] print(f"-> 正在应用: {desc}") processed_spectra = func(processed_spectra) prefixes.append(prefix_name) else: print(f"! 警告: 选项 {c} 无效,已跳过。") final_prefix = "_".join(prefixes) if prefixes else "RAW" # 动态生成输出文件名 if "RAW" in base_name: output_name = base_name.replace("RAW", final_prefix) else: output_name = f"{final_prefix}_{base_name}" # 重组数据并保存 df_processed_spectra = pd.DataFrame(processed_spectra, columns=band_names) df_final = pd.concat([meta_data, df_processed_spectra], axis=1) output_path = os.path.join(output_dir, output_name) print(f"正在保存处理后的数据至: {output_path} ...") df_final.to_excel(output_path, index=False) print("处理完成!") if __name__ == "__main__": # ==================== 配置区 ==================== input_file = r"E:\GouQi\data\RAW_GLS.xlsx" # 选择预处理方法 (支持列表组合,按顺序执行) # [3] 表示只做 SG平滑 # [3, 4] 表示先做 SG平滑,再做 一阶导数 # [3, 1, 4] 表示先SG平滑,再SNV,再一阶导数 choices = [3, 1, 8] # <--- 在这里传入包含步骤序号的列表 # ================================================ main(input_file, choices)为了直观检验预处理的效果,我们往往需要绘制光谱曲线。以下代码可以随机抽取几个样本,对比原始光谱(RAW)和经过 SG+SNV 处理后的光谱
-
import matplotlib.pyplot as plt def plot_spectra_comparison(raw_data, processed_data, band_names): plt.figure(figsize=(12, 5)) # 绘制原始光谱 plt.subplot(1, 2, 1) plt.plot(band_names, raw_data.T, alpha=0.3) plt.title("原始光谱 (RAW)") plt.xlabel("Wavelength (nm)") plt.ylabel("Intensity") # 绘制处理后光谱 plt.subplot(1, 2, 2) plt.plot(band_names, processed_data.T, alpha=0.3) plt.title("预处理后 (例如 SG + SNV)") plt.xlabel("Wavelength (nm)") plt.ylabel("Normalized Intensity") plt.tight_layout() plt.show()结果
-
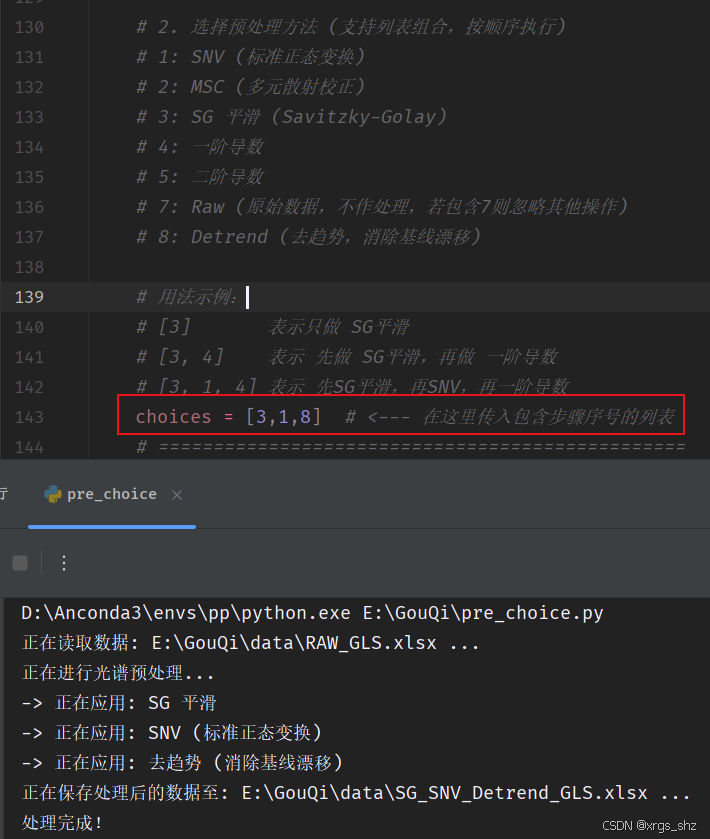
-
总结
这两段代码组合起来,几乎涵盖了实验室采集高光谱数据后到进行模型训练前的核心数据清洗步骤。 特别是内存友好的逐波段切片和基于字典的预处理流水线设计,不仅提高了代码的执行效率,也极大增强了可读性和可扩展性。
如果这篇内容对你的课题或项目有帮助,欢迎 点赞 + 收藏!有任何问题或优化建议,也欢迎在评论区留言讨论哦!
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)