
Java 程序员第 29-04 阶段:大模型微调入门:小样本业务适配方案
二、微调方法全面解析
2.4 Adapter Tuning(适配器微调)
原理
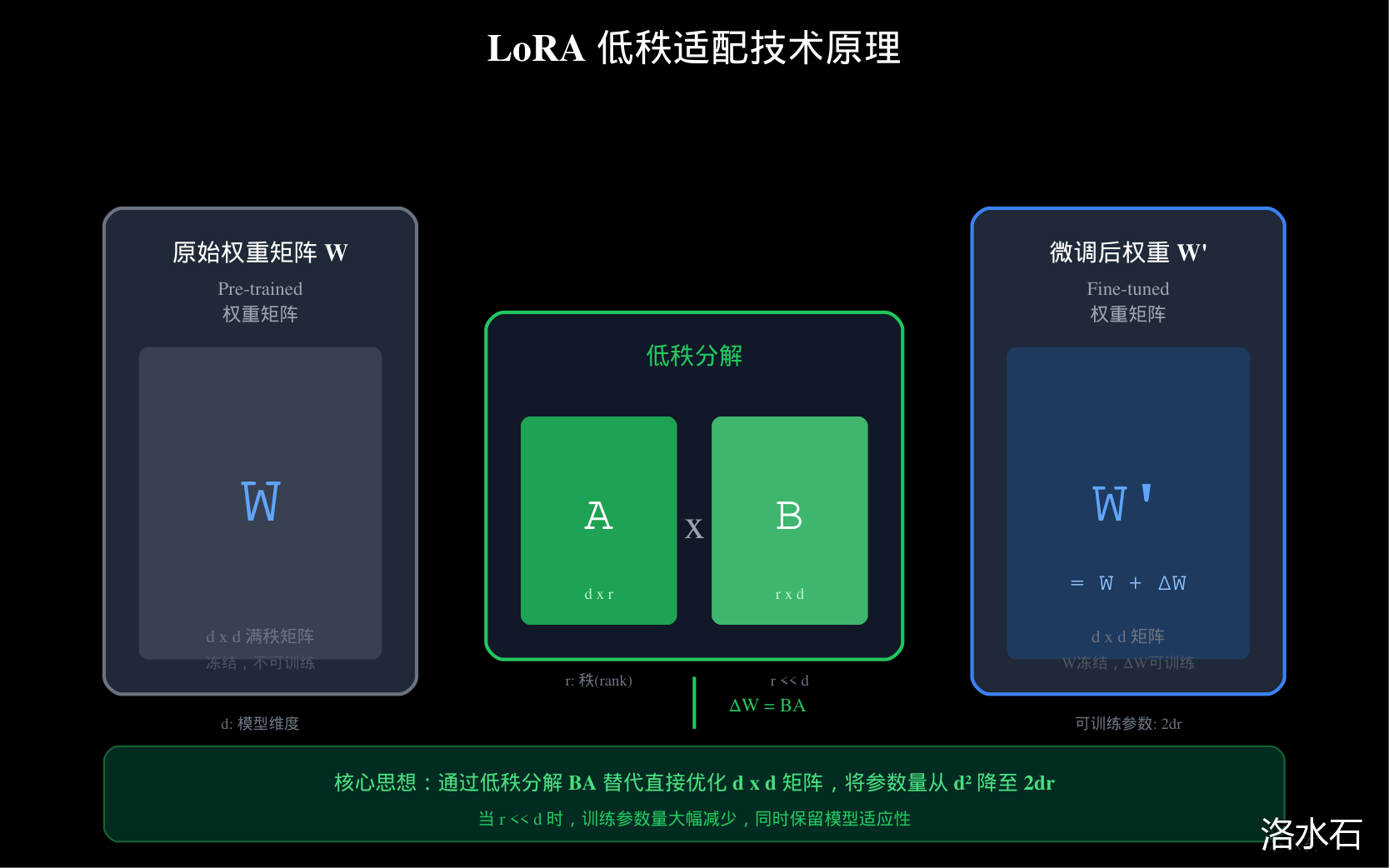
图2:LoRA低秩适配技术原理
Adapter Tuning 由 Google Research 提出,在 Transformer 层的 Feed-Forward 网络上并联小型适配器模块。适配器通常由两个线性层组成:先将特征映射到低维空间(down-project),再映射回高维空间(up-project)。
┌─────────────────────────────────────────────────────────────┐
│ 模型微调核心原理 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 预训练阶段 │
│ ┌─────────────┐ │
│ │ 海量通用数据 │ → 通用语言能力 + 广泛知识 │
│ │ (Web, Books) │ │
│ └─────────────┘ │
│ ↓ │
│ 微调阶段 │
│ ┌─────────────┐ │
│ │ 领域/业务数据│ → 领域专业能力 + 业务适配 │
│ │ (Domain Data) │ │
│ └─────────────┘ │
│ ↓ │
│ ┌─────────────┐ │
│ │ 微调后模型 │ → 通用能力 + 领域专业能力 │
│ └─────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────┐
│ Adapter 结构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ Input ──→ ┌─────────┐ │
│ │ Down │ (d → r) │
│ │ Project │ │
│ └────┬─────┘ │
│ ↓ │
│ ┌─────────┐ │
│ │ Non- │ │
│ │ Linear │ │
│ └────┬─────┘ │
│ ↓ │
│ ┌─────────┐ │
│ │ Up │ (r → d) │
│ │ Project │ │
│ └────┬─────┘ │
│ ↓ │
│ └────┼─────┘ │
│ ↓ │
│ Output ──→ (残差连接) │
│ │
└─────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────┐
│ 模型微调核心原理 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 预训练阶段 │
│ ┌─────────────┐ │
│ │ 海量通用数据 │ → 通用语言能力 + 广泛知识 │
│ │ (Web, Books) │ │
│ └─────────────┘ │
│ ↓ │
│ 微调阶段 │
│ ┌─────────────┐ │
│ │ 领域/业务数据│ → 领域专业能力 + 业务适配 │
│ │ (Domain Data) │ │
│ └─────────────┘ │
│ ↓ │
│ ┌─────────────┐ │
│ │ 微调后模型 │ → 通用能力 + 领域专业能力 │
│ └─────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
Adapter 与 LoRA 的区别
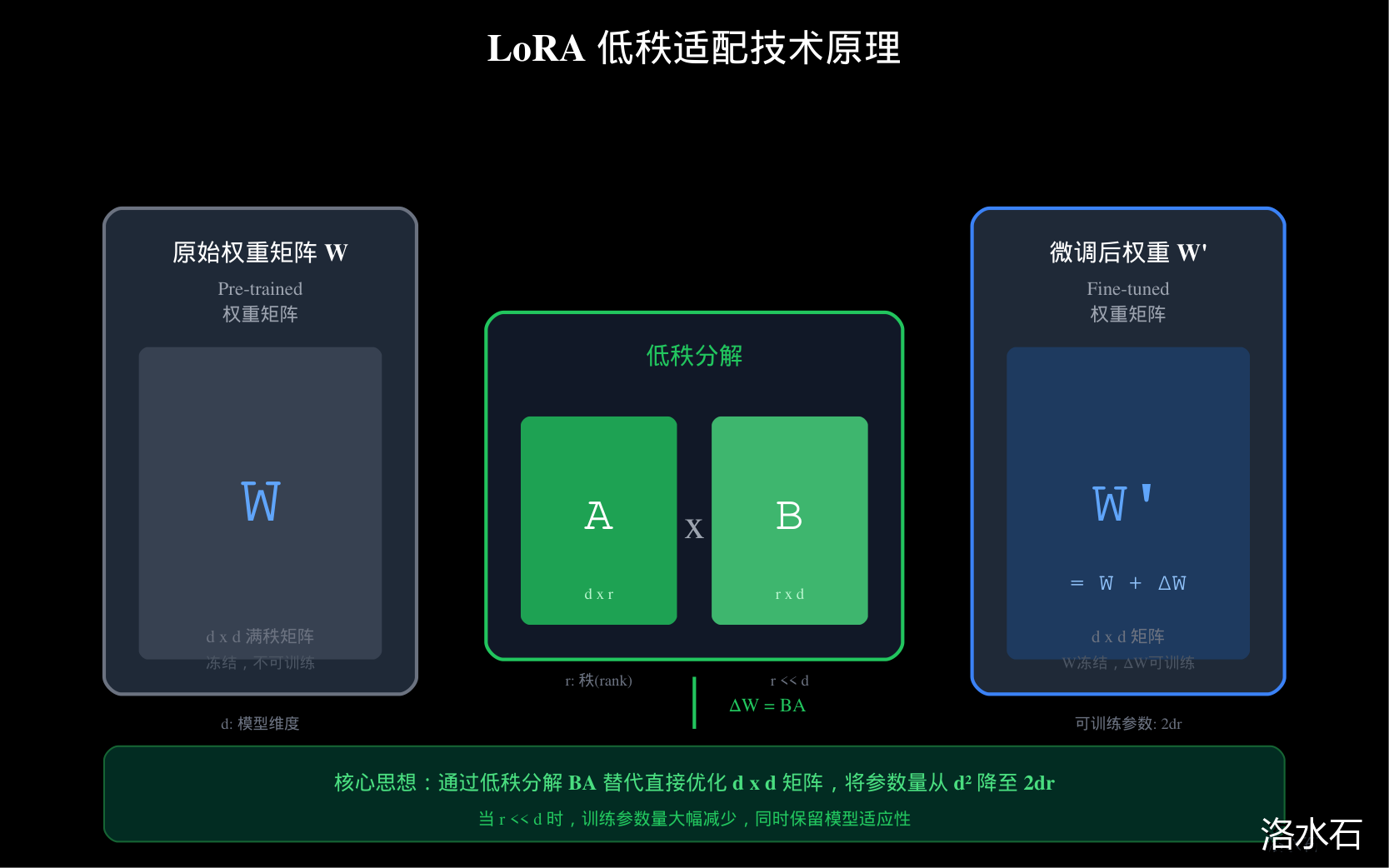
图2:LoRA低秩适配技术原理
|
问题类型 |
具体表现 |
||||
|
--------- |
--------- |
||||
|
**领域知识不足** |
在医疗、法律、金融等专业领域,可能给出不够准确甚至错误的答案 |
||||
|
**企业认知缺失** |
不了解特定企业的产品、服务、内部流程 |
||||
|
**输出格式不稳定** |
难以严格遵循业务要求的输出格式(如 JSON、XML) |
||||
|
**幻觉问题** |
对不确定的问题可能编造看似合理但实际错误的答案 |
||||
|
**推理成本高** |
通用模型参数量巨大,部署和推理成本高昂 |
||||
|
维度 |
提示工程 |
RAG |
微调 |
||
|
------ |
--------- |
----- |
------ |
||
|
**实现难度** |
低 |
中 |
高 |
||
|
**成本** |
低 |
中 |
高 |
||
|
**训练时间** |
无 |
无 |
数小时到数天 |
||
|
**知识更新** |
实时 |
实时 |
需重新训练 |
||
|
**任务适配** |
通用任务 |
知识问答 |
复杂推理/格式 |
||
|
**依赖数据量** |
少量示例 |
文档库 |
百条到数千条 |
||
|
**控制力** |
弱 |
中 |
强 |
||
|
**适用场景** |
通用对话、格式控制 |
知识库问答 |
领域适应、行为模式 |
||
|
参数 |
说明 |
常用值 |
|||
|
------ |
------ |
-------- |
|||
|
`r` |
低秩分解的秩,决定可训练参数量 |
4, 8, 16, 32 |
|||
|
`lora_alpha` |
缩放因子,通常设为 r 的 2 倍 |
8, 16, 32, 64 |
|||
|
`lora_dropout` |
LoRA 层的 dropout 概率 |
0.0, 0.1 |
|||
|
`target_modules` |
应用 LoRA 的模块 |
q_proj, v_proj, k_proj, o_proj |
|||
|
维度 |
LoRA |
QLoRA |
|||
|
------ |
------ |
------- |
|||
|
**模型精度** |
保持 FP16/BF16 |
量化到 INT4/INT8 |
|||
|
**显存占用** |
7B: ~10GB |
7B: ~5GB |
|||
|
**推理速度** |
正常 |
略慢(需反量化) |
|||
|
**微调效果** |
接近全量微调 |
略低于 LoRA |
|||
|
**硬件要求** |
RTX 3090+ |
RTX 2080+ |
|||
|
维度 |
Adapter |
LoRA |
|||
|
------ |
--------- |
------ |
|||
|
**结构** |
并联在 FFN 层 |
低秩分解替代 |
|||
|
**位置** |
需指定插入位置 |
任意位置 |
|||
|
**参数量** |
~3-5% |
~0.1-1% |
|||
|
**推理延迟** |
略高(串行计算) |
无(可合并) |
|||
|
**多任务** |
多适配器切换 |
多 LoRA 动态加载 |
|||
|
维度 |
Prefix Tuning |
Prompt Tuning |
|||
|
------ |
--------------- |
--------------- |
|||
|
**提示位置** |
每层 |
仅输入层 |
|||
|
**参数量** |
较大(k × layers) |
较小(k) |
|||
|
**效果** |
更好 |
略逊 |
|||
|
**适用场景** |
复杂任务 |
简单任务 |
|||
|
方法 |
可训练参数 |
GPU 显存 |
推理延迟 |
效果 |
实现复杂度 |
|
------ |
----------- |
--------- |
--------- |
------ |
----------- |
|
Full FT |
100% |
≥24GB |
无 |
最优 |
低 |
|
LoRA |
0.1-1% |
≥10GB |
无 |
接近全量 |
中 |
|
QLoRA |
0.1-1% |
≥6GB |
略高 |
良好 |
中 |
|
Adapter |
1-5% |
≥12GB |
略高 |
良好 |
中 |
|
Prefix |
0.1-3% |
≥10GB |
无 |
中等 |
中 |
|
P-tuning v2 |
0.1-3% |
≥10GB |
无 |
良好 |
高 |
|
数据集 |
说明 |
适用场景 |
|||
|
-------- |
------ |
--------- |
|||
|
**Alpaca** |
Stanford Alpaca 团队生成 |
通用指令微调 |
|||
|
**ShareGPT** |
用户对话数据 |
对话系统 |
|||
|
**FLAN** |
谷歌指令数据集集合 |
指令遵循 |
|||
|
** Dolly** |
Databricks 员工生成 |
领域适应 |
|||
|
**OpenAssistant** |
开源对话数据 |
对话系统 |
|||
|
检查项 |
方法 |
处理方式 |
|||
|
-------- |
------ |
--------- |
|||
|
**重复数据** |
哈希比对、相似度计算 |
去重 |
|||
|
**噪声数据** |
关键词过滤、长度分布分析 |
过滤 |
|||
|
**格式错误** |
JSON 解析、schema 验证 |
修正或过滤 |
|||
|
**隐私信息** |
正则匹配、NER 检测 |
脱敏或过滤 |
|||
|
**标注一致性** |
多人标注、交叉验证 |
重新标注 |
|||
|
类型 |
说明 |
||||
|
------ |
------ |
||||
|
ROUGE-N |
N-gram 召回率(ROUGE-1, ROUGE-2) |
||||
|
ROUGE-L |
最长公共子序列 |
||||
|
ROUGE-S |
Skip-gram 召回率 |
||||
|
维度 |
评估标准 |
||||
|
------ |
--------- |
||||
|
**相关性** |
回答是否切题 |
||||
|
**准确性** |
信息是否正确无误 |
||||
|
**完整性** |
是否完整回答问题 |
||||
|
**专业性** |
术语使用是否恰当 |
||||
|
**流畅性** |
表达是否通顺 |
||||
|
方案 |
特点 |
适用场景 |
|||
|
------ |
------ |
--------- |
|||
|
**vLLM** |
PagedAttention,吞吐量高 |
高并发推理 |
|||
|
**TGI** |
HuggingFace 官方,支持推理优化 |
通用部署 |
|||
|
**Text Generation Inference** |
Rust 实现,高效 |
生产环境 |
|||
|
**Ollama** |
本地部署,简单易用 |
本地开发 |
|||
|
**llama.cpp** |
纯 C/C++,CPU 友好 |
边缘部署 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
过拟合 |
数据量太少或训练轮次过多 |
增加数据、使用正则、增加 dropout |
|||
|
灾难性遗忘 |
全量微调破坏预训练知识 |
使用 LoRA/QLoRA 或保留预训练数据 |
|||
|
分布偏移 |
微调数据与预训练数据差异大 |
混合预训练数据一起训练 |
|||
|
质量不稳定 |
数据标注不一致 |
重新标注、数据清洗 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
OOM(显存溢出) |
batch size 过大或序列太长 |
减小 batch size、启用 gradient checkpointing、使用 QLoRA |
|||
|
Loss 不下降 |
学习率不合适或模型问题 |
调整学习率、检查数据格式 |
|||
|
Loss 爆炸 |
学习率过高或梯度问题 |
减小学习率、启用梯度裁剪 |
|||
|
NaN 损失 |
数值不稳定 |
使用混合精度训练、检查数据 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
重复生成 |
解码策略问题 |
调整 temperature、启用 repetition_penalty |
|||
|
生成截断 |
最大长度限制 |
增加 max_new_tokens |
|||
|
回答格式错误 |
Prompt 不够清晰 |
优化 Prompt,添加示例 |
|||
|
推理速度慢 |
模型过大或硬件不足 |
量化、使用更小模型 |
|||
|
趋势 |
说明 |
||||
|
------ |
------ |
||||
|
**更高效的方法** |
如 LoRA+、DoRA 等新方法不断涌现 |
||||
|
**多模态微调** |
图像、语音、文本联合微调 |
||||
|
**增量微调** |
高效利用新数据,不遗忘旧知识 |
||||
|
**自动化微调** |
AutoML + 微调,自动搜索最佳配置 |
||||
|
**端侧微调** |
在手机、IoT 设备上进行微调 |
|
问题类型 |
具体表现 |
||||
|
--------- |
--------- |
||||
|
**领域知识不足** |
在医疗、法律、金融等专业领域,可能给出不够准确甚至错误的答案 |
||||
|
**企业认知缺失** |
不了解特定企业的产品、服务、内部流程 |
||||
|
**输出格式不稳定** |
难以严格遵循业务要求的输出格式(如 JSON、XML) |
||||
|
**幻觉问题** |
对不确定的问题可能编造看似合理但实际错误的答案 |
||||
|
**推理成本高** |
通用模型参数量巨大,部署和推理成本高昂 |
||||
|
维度 |
提示工程 |
RAG |
微调 |
||
|
------ |
--------- |
----- |
------ |
||
|
**实现难度** |
低 |
中 |
高 |
||
|
**成本** |
低 |
中 |
高 |
||
|
**训练时间** |
无 |
无 |
数小时到数天 |
||
|
**知识更新** |
实时 |
实时 |
需重新训练 |
||
|
**任务适配** |
通用任务 |
知识问答 |
复杂推理/格式 |
||
|
**依赖数据量** |
少量示例 |
文档库 |
百条到数千条 |
||
|
**控制力** |
弱 |
中 |
强 |
||
|
**适用场景** |
通用对话、格式控制 |
知识库问答 |
领域适应、行为模式 |
||
|
参数 |
说明 |
常用值 |
|||
|
------ |
------ |
-------- |
|||
|
`r` |
低秩分解的秩,决定可训练参数量 |
4, 8, 16, 32 |
|||
|
`lora_alpha` |
缩放因子,通常设为 r 的 2 倍 |
8, 16, 32, 64 |
|||
|
`lora_dropout` |
LoRA 层的 dropout 概率 |
0.0, 0.1 |
|||
|
`target_modules` |
应用 LoRA 的模块 |
q_proj, v_proj, k_proj, o_proj |
|||
|
维度 |
LoRA |
QLoRA |
|||
|
------ |
------ |
------- |
|||
|
**模型精度** |
保持 FP16/BF16 |
量化到 INT4/INT8 |
|||
|
**显存占用** |
7B: ~10GB |
7B: ~5GB |
|||
|
**推理速度** |
正常 |
略慢(需反量化) |
|||
|
**微调效果** |
接近全量微调 |
略低于 LoRA |
|||
|
**硬件要求** |
RTX 3090+ |
RTX 2080+ |
|||
|
维度 |
Adapter |
LoRA |
|||
|
------ |
--------- |
------ |
|||
|
**结构** |
并联在 FFN 层 |
低秩分解替代 |
|||
|
**位置** |
需指定插入位置 |
任意位置 |
|||
|
**参数量** |
~3-5% |
~0.1-1% |
|||
|
**推理延迟** |
略高(串行计算) |
无(可合并) |
|||
|
**多任务** |
多适配器切换 |
多 LoRA 动态加载 |
|||
|
维度 |
Prefix Tuning |
Prompt Tuning |
|||
|
------ |
--------------- |
--------------- |
|||
|
**提示位置** |
每层 |
仅输入层 |
|||
|
**参数量** |
较大(k × layers) |
较小(k) |
|||
|
**效果** |
更好 |
略逊 |
|||
|
**适用场景** |
复杂任务 |
简单任务 |
|||
|
方法 |
可训练参数 |
GPU 显存 |
推理延迟 |
效果 |
实现复杂度 |
|
------ |
----------- |
--------- |
--------- |
------ |
----------- |
|
Full FT |
100% |
≥24GB |
无 |
最优 |
低 |
|
LoRA |
0.1-1% |
≥10GB |
无 |
接近全量 |
中 |
|
QLoRA |
0.1-1% |
≥6GB |
略高 |
良好 |
中 |
|
Adapter |
1-5% |
≥12GB |
略高 |
良好 |
中 |
|
Prefix |
0.1-3% |
≥10GB |
无 |
中等 |
中 |
|
P-tuning v2 |
0.1-3% |
≥10GB |
无 |
良好 |
高 |
|
数据集 |
说明 |
适用场景 |
|||
|
-------- |
------ |
--------- |
|||
|
**Alpaca** |
Stanford Alpaca 团队生成 |
通用指令微调 |
|||
|
**ShareGPT** |
用户对话数据 |
对话系统 |
|||
|
**FLAN** |
谷歌指令数据集集合 |
指令遵循 |
|||
|
** Dolly** |
Databricks 员工生成 |
领域适应 |
|||
|
**OpenAssistant** |
开源对话数据 |
对话系统 |
|||
|
检查项 |
方法 |
处理方式 |
|||
|
-------- |
------ |
--------- |
|||
|
**重复数据** |
哈希比对、相似度计算 |
去重 |
|||
|
**噪声数据** |
关键词过滤、长度分布分析 |
过滤 |
|||
|
**格式错误** |
JSON 解析、schema 验证 |
修正或过滤 |
|||
|
**隐私信息** |
正则匹配、NER 检测 |
脱敏或过滤 |
|||
|
**标注一致性** |
多人标注、交叉验证 |
重新标注 |
|||
|
类型 |
说明 |
||||
|
------ |
------ |
||||
|
ROUGE-N |
N-gram 召回率(ROUGE-1, ROUGE-2) |
||||
|
ROUGE-L |
最长公共子序列 |
||||
|
ROUGE-S |
Skip-gram 召回率 |
||||
|
维度 |
评估标准 |
||||
|
------ |
--------- |
||||
|
**相关性** |
回答是否切题 |
||||
|
**准确性** |
信息是否正确无误 |
||||
|
**完整性** |
是否完整回答问题 |
||||
|
**专业性** |
术语使用是否恰当 |
||||
|
**流畅性** |
表达是否通顺 |
||||
|
方案 |
特点 |
适用场景 |
|||
|
------ |
------ |
--------- |
|||
|
**vLLM** |
PagedAttention,吞吐量高 |
高并发推理 |
|||
|
**TGI** |
HuggingFace 官方,支持推理优化 |
通用部署 |
|||
|
**Text Generation Inference** |
Rust 实现,高效 |
生产环境 |
|||
|
**Ollama** |
本地部署,简单易用 |
本地开发 |
|||
|
**llama.cpp** |
纯 C/C++,CPU 友好 |
边缘部署 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
过拟合 |
数据量太少或训练轮次过多 |
增加数据、使用正则、增加 dropout |
|||
|
灾难性遗忘 |
全量微调破坏预训练知识 |
使用 LoRA/QLoRA 或保留预训练数据 |
|||
|
分布偏移 |
微调数据与预训练数据差异大 |
混合预训练数据一起训练 |
|||
|
质量不稳定 |
数据标注不一致 |
重新标注、数据清洗 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
OOM(显存溢出) |
batch size 过大或序列太长 |
减小 batch size、启用 gradient checkpointing、使用 QLoRA |
|||
|
Loss 不下降 |
学习率不合适或模型问题 |
调整学习率、检查数据格式 |
|||
|
Loss 爆炸 |
学习率过高或梯度问题 |
减小学习率、启用梯度裁剪 |
|||
|
NaN 损失 |
数值不稳定 |
使用混合精度训练、检查数据 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
重复生成 |
解码策略问题 |
调整 temperature、启用 repetition_penalty |
|||
|
生成截断 |
最大长度限制 |
增加 max_new_tokens |
|||
|
回答格式错误 |
Prompt 不够清晰 |
优化 Prompt,添加示例 |
|||
|
推理速度慢 |
模型过大或硬件不足 |
量化、使用更小模型 |
|||
|
趋势 |
说明 |
||||
|
------ |
------ |
||||
|
**更高效的方法** |
如 LoRA+、DoRA 等新方法不断涌现 |
||||
|
**多模态微调** |
图像、语音、文本联合微调 |
||||
|
**增量微调** |
高效利用新数据,不遗忘旧知识 |
||||
|
**自动化微调** |
AutoML + 微调,自动搜索最佳配置 |
||||
|
**端侧微调** |
在手机、IoT 设备上进行微调 |
|
问题类型 |
具体表现 |
||||
|
--------- |
--------- |
||||
|
**领域知识不足** |
在医疗、法律、金融等专业领域,可能给出不够准确甚至错误的答案 |
||||
|
**企业认知缺失** |
不了解特定企业的产品、服务、内部流程 |
||||
|
**输出格式不稳定** |
难以严格遵循业务要求的输出格式(如 JSON、XML) |
||||
|
**幻觉问题** |
对不确定的问题可能编造看似合理但实际错误的答案 |
||||
|
**推理成本高** |
通用模型参数量巨大,部署和推理成本高昂 |
||||
|
维度 |
提示工程 |
RAG |
微调 |
||
|
------ |
--------- |
----- |
------ |
||
|
**实现难度** |
低 |
中 |
高 |
||
|
**成本** |
低 |
中 |
高 |
||
|
**训练时间** |
无 |
无 |
数小时到数天 |
||
|
**知识更新** |
实时 |
实时 |
需重新训练 |
||
|
**任务适配** |
通用任务 |
知识问答 |
复杂推理/格式 |
||
|
**依赖数据量** |
少量示例 |
文档库 |
百条到数千条 |
||
|
**控制力** |
弱 |
中 |
强 |
||
|
**适用场景** |
通用对话、格式控制 |
知识库问答 |
领域适应、行为模式 |
||
|
参数 |
说明 |
常用值 |
|||
|
------ |
------ |
-------- |
|||
|
`r` |
低秩分解的秩,决定可训练参数量 |
4, 8, 16, 32 |
|||
|
`lora_alpha` |
缩放因子,通常设为 r 的 2 倍 |
8, 16, 32, 64 |
|||
|
`lora_dropout` |
LoRA 层的 dropout 概率 |
0.0, 0.1 |
|||
|
`target_modules` |
应用 LoRA 的模块 |
q_proj, v_proj, k_proj, o_proj |
|||
|
维度 |
LoRA |
QLoRA |
|||
|
------ |
------ |
------- |
|||
|
**模型精度** |
保持 FP16/BF16 |
量化到 INT4/INT8 |
|||
|
**显存占用** |
7B: ~10GB |
7B: ~5GB |
|||
|
**推理速度** |
正常 |
略慢(需反量化) |
|||
|
**微调效果** |
接近全量微调 |
略低于 LoRA |
|||
|
**硬件要求** |
RTX 3090+ |
RTX 2080+ |
|||
|
维度 |
Adapter |
LoRA |
|||
|
------ |
--------- |
------ |
|||
|
**结构** |
并联在 FFN 层 |
低秩分解替代 |
|||
|
**位置** |
需指定插入位置 |
任意位置 |
|||
|
**参数量** |
~3-5% |
~0.1-1% |
|||
|
**推理延迟** |
略高(串行计算) |
无(可合并) |
|||
|
**多任务** |
多适配器切换 |
多 LoRA 动态加载 |
|||
|
维度 |
Prefix Tuning |
Prompt Tuning |
|||
|
------ |
--------------- |
--------------- |
|||
|
**提示位置** |
每层 |
仅输入层 |
|||
|
**参数量** |
较大(k × layers) |
较小(k) |
|||
|
**效果** |
更好 |
略逊 |
|||
|
**适用场景** |
复杂任务 |
简单任务 |
|||
|
方法 |
可训练参数 |
GPU 显存 |
推理延迟 |
效果 |
实现复杂度 |
|
------ |
----------- |
--------- |
--------- |
------ |
----------- |
|
Full FT |
100% |
≥24GB |
无 |
最优 |
低 |
|
LoRA |
0.1-1% |
≥10GB |
无 |
接近全量 |
中 |
|
QLoRA |
0.1-1% |
≥6GB |
略高 |
良好 |
中 |
|
Adapter |
1-5% |
≥12GB |
略高 |
良好 |
中 |
|
Prefix |
0.1-3% |
≥10GB |
无 |
中等 |
中 |
|
P-tuning v2 |
0.1-3% |
≥10GB |
无 |
良好 |
高 |
|
数据集 |
说明 |
适用场景 |
|||
|
-------- |
------ |
--------- |
|||
|
**Alpaca** |
Stanford Alpaca 团队生成 |
通用指令微调 |
|||
|
**ShareGPT** |
用户对话数据 |
对话系统 |
|||
|
**FLAN** |
谷歌指令数据集集合 |
指令遵循 |
|||
|
** Dolly** |
Databricks 员工生成 |
领域适应 |
|||
|
**OpenAssistant** |
开源对话数据 |
对话系统 |
|||
|
检查项 |
方法 |
处理方式 |
|||
|
-------- |
------ |
--------- |
|||
|
**重复数据** |
哈希比对、相似度计算 |
去重 |
|||
|
**噪声数据** |
关键词过滤、长度分布分析 |
过滤 |
|||
|
**格式错误** |
JSON 解析、schema 验证 |
修正或过滤 |
|||
|
**隐私信息** |
正则匹配、NER 检测 |
脱敏或过滤 |
|||
|
**标注一致性** |
多人标注、交叉验证 |
重新标注 |
|||
|
类型 |
说明 |
||||
|
------ |
------ |
||||
|
ROUGE-N |
N-gram 召回率(ROUGE-1, ROUGE-2) |
||||
|
ROUGE-L |
最长公共子序列 |
||||
|
ROUGE-S |
Skip-gram 召回率 |
||||
|
维度 |
评估标准 |
||||
|
------ |
--------- |
||||
|
**相关性** |
回答是否切题 |
||||
|
**准确性** |
信息是否正确无误 |
||||
|
**完整性** |
是否完整回答问题 |
||||
|
**专业性** |
术语使用是否恰当 |
||||
|
**流畅性** |
表达是否通顺 |
||||
|
方案 |
特点 |
适用场景 |
|||
|
------ |
------ |
--------- |
|||
|
**vLLM** |
PagedAttention,吞吐量高 |
高并发推理 |
|||
|
**TGI** |
HuggingFace 官方,支持推理优化 |
通用部署 |
|||
|
**Text Generation Inference** |
Rust 实现,高效 |
生产环境 |
|||
|
**Ollama** |
本地部署,简单易用 |
本地开发 |
|||
|
**llama.cpp** |
纯 C/C++,CPU 友好 |
边缘部署 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
过拟合 |
数据量太少或训练轮次过多 |
增加数据、使用正则、增加 dropout |
|||
|
灾难性遗忘 |
全量微调破坏预训练知识 |
使用 LoRA/QLoRA 或保留预训练数据 |
|||
|
分布偏移 |
微调数据与预训练数据差异大 |
混合预训练数据一起训练 |
|||
|
质量不稳定 |
数据标注不一致 |
重新标注、数据清洗 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
OOM(显存溢出) |
batch size 过大或序列太长 |
减小 batch size、启用 gradient checkpointing、使用 QLoRA |
|||
|
Loss 不下降 |
学习率不合适或模型问题 |
调整学习率、检查数据格式 |
|||
|
Loss 爆炸 |
学习率过高或梯度问题 |
减小学习率、启用梯度裁剪 |
|||
|
NaN 损失 |
数值不稳定 |
使用混合精度训练、检查数据 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
重复生成 |
解码策略问题 |
调整 temperature、启用 repetition_penalty |
|||
|
生成截断 |
最大长度限制 |
增加 max_new_tokens |
|||
|
回答格式错误 |
Prompt 不够清晰 |
优化 Prompt,添加示例 |
|||
|
推理速度慢 |
模型过大或硬件不足 |
量化、使用更小模型 |
|||
|
趋势 |
说明 |
||||
|
------ |
------ |
||||
|
**更高效的方法** |
如 LoRA+、DoRA 等新方法不断涌现 |
||||
|
**多模态微调** |
图像、语音、文本联合微调 |
||||
|
**增量微调** |
高效利用新数据,不遗忘旧知识 |
||||
|
**自动化微调** |
AutoML + 微调,自动搜索最佳配置 |
||||
|
**端侧微调** |
在手机、IoT 设备上进行微调 |
|
问题类型 |
具体表现 |
||||
|
--------- |
--------- |
||||
|
**领域知识不足** |
在医疗、法律、金融等专业领域,可能给出不够准确甚至错误的答案 |
||||
|
**企业认知缺失** |
不了解特定企业的产品、服务、内部流程 |
||||
|
**输出格式不稳定** |
难以严格遵循业务要求的输出格式(如 JSON、XML) |
||||
|
**幻觉问题** |
对不确定的问题可能编造看似合理但实际错误的答案 |
||||
|
**推理成本高** |
通用模型参数量巨大,部署和推理成本高昂 |
||||
|
维度 |
提示工程 |
RAG |
微调 |
||
|
------ |
--------- |
----- |
------ |
||
|
**实现难度** |
低 |
中 |
高 |
||
|
**成本** |
低 |
中 |
高 |
||
|
**训练时间** |
无 |
无 |
数小时到数天 |
||
|
**知识更新** |
实时 |
实时 |
需重新训练 |
||
|
**任务适配** |
通用任务 |
知识问答 |
复杂推理/格式 |
||
|
**依赖数据量** |
少量示例 |
文档库 |
百条到数千条 |
||
|
**控制力** |
弱 |
中 |
强 |
||
|
**适用场景** |
通用对话、格式控制 |
知识库问答 |
领域适应、行为模式 |
||
|
参数 |
说明 |
常用值 |
|||
|
------ |
------ |
-------- |
|||
|
`r` |
低秩分解的秩,决定可训练参数量 |
4, 8, 16, 32 |
|||
|
`lora_alpha` |
缩放因子,通常设为 r 的 2 倍 |
8, 16, 32, 64 |
|||
|
`lora_dropout` |
LoRA 层的 dropout 概率 |
0.0, 0.1 |
|||
|
`target_modules` |
应用 LoRA 的模块 |
q_proj, v_proj, k_proj, o_proj |
|||
|
维度 |
LoRA |
QLoRA |
|||
|
------ |
------ |
------- |
|||
|
**模型精度** |
保持 FP16/BF16 |
量化到 INT4/INT8 |
|||
|
**显存占用** |
7B: ~10GB |
7B: ~5GB |
|||
|
**推理速度** |
正常 |
略慢(需反量化) |
|||
|
**微调效果** |
接近全量微调 |
略低于 LoRA |
|||
|
**硬件要求** |
RTX 3090+ |
RTX 2080+ |
|||
|
维度 |
Adapter |
LoRA |
|||
|
------ |
--------- |
------ |
|||
|
**结构** |
并联在 FFN 层 |
低秩分解替代 |
|||
|
**位置** |
需指定插入位置 |
任意位置 |
|||
|
**参数量** |
~3-5% |
~0.1-1% |
|||
|
**推理延迟** |
略高(串行计算) |
无(可合并) |
|||
|
**多任务** |
多适配器切换 |
多 LoRA 动态加载 |
|||
|
维度 |
Prefix Tuning |
Prompt Tuning |
|||
|
------ |
--------------- |
--------------- |
|||
|
**提示位置** |
每层 |
仅输入层 |
|||
|
**参数量** |
较大(k × layers) |
较小(k) |
|||
|
**效果** |
更好 |
略逊 |
|||
|
**适用场景** |
复杂任务 |
简单任务 |
|||
|
方法 |
可训练参数 |
GPU 显存 |
推理延迟 |
效果 |
实现复杂度 |
|
------ |
----------- |
--------- |
--------- |
------ |
----------- |
|
Full FT |
100% |
≥24GB |
无 |
最优 |
低 |
|
LoRA |
0.1-1% |
≥10GB |
无 |
接近全量 |
中 |
|
QLoRA |
0.1-1% |
≥6GB |
略高 |
良好 |
中 |
|
Adapter |
1-5% |
≥12GB |
略高 |
良好 |
中 |
|
Prefix |
0.1-3% |
≥10GB |
无 |
中等 |
中 |
|
P-tuning v2 |
0.1-3% |
≥10GB |
无 |
良好 |
高 |
|
数据集 |
说明 |
适用场景 |
|||
|
-------- |
------ |
--------- |
|||
|
**Alpaca** |
Stanford Alpaca 团队生成 |
通用指令微调 |
|||
|
**ShareGPT** |
用户对话数据 |
对话系统 |
|||
|
**FLAN** |
谷歌指令数据集集合 |
指令遵循 |
|||
|
** Dolly** |
Databricks 员工生成 |
领域适应 |
|||
|
**OpenAssistant** |
开源对话数据 |
对话系统 |
|||
|
检查项 |
方法 |
处理方式 |
|||
|
-------- |
------ |
--------- |
|||
|
**重复数据** |
哈希比对、相似度计算 |
去重 |
|||
|
**噪声数据** |
关键词过滤、长度分布分析 |
过滤 |
|||
|
**格式错误** |
JSON 解析、schema 验证 |
修正或过滤 |
|||
|
**隐私信息** |
正则匹配、NER 检测 |
脱敏或过滤 |
|||
|
**标注一致性** |
多人标注、交叉验证 |
重新标注 |
|||
|
类型 |
说明 |
||||
|
------ |
------ |
||||
|
ROUGE-N |
N-gram 召回率(ROUGE-1, ROUGE-2) |
||||
|
ROUGE-L |
最长公共子序列 |
||||
|
ROUGE-S |
Skip-gram 召回率 |
||||
|
维度 |
评估标准 |
||||
|
------ |
--------- |
||||
|
**相关性** |
回答是否切题 |
||||
|
**准确性** |
信息是否正确无误 |
||||
|
**完整性** |
是否完整回答问题 |
||||
|
**专业性** |
术语使用是否恰当 |
||||
|
**流畅性** |
表达是否通顺 |
||||
|
方案 |
特点 |
适用场景 |
|||
|
------ |
------ |
--------- |
|||
|
**vLLM** |
PagedAttention,吞吐量高 |
高并发推理 |
|||
|
**TGI** |
HuggingFace 官方,支持推理优化 |
通用部署 |
|||
|
**Text Generation Inference** |
Rust 实现,高效 |
生产环境 |
|||
|
**Ollama** |
本地部署,简单易用 |
本地开发 |
|||
|
**llama.cpp** |
纯 C/C++,CPU 友好 |
边缘部署 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
过拟合 |
数据量太少或训练轮次过多 |
增加数据、使用正则、增加 dropout |
|||
|
灾难性遗忘 |
全量微调破坏预训练知识 |
使用 LoRA/QLoRA 或保留预训练数据 |
|||
|
分布偏移 |
微调数据与预训练数据差异大 |
混合预训练数据一起训练 |
|||
|
质量不稳定 |
数据标注不一致 |
重新标注、数据清洗 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
OOM(显存溢出) |
batch size 过大或序列太长 |
减小 batch size、启用 gradient checkpointing、使用 QLoRA |
|||
|
Loss 不下降 |
学习率不合适或模型问题 |
调整学习率、检查数据格式 |
|||
|
Loss 爆炸 |
学习率过高或梯度问题 |
减小学习率、启用梯度裁剪 |
|||
|
NaN 损失 |
数值不稳定 |
使用混合精度训练、检查数据 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
重复生成 |
解码策略问题 |
调整 temperature、启用 repetition_penalty |
|||
|
生成截断 |
最大长度限制 |
增加 max_new_tokens |
|||
|
回答格式错误 |
Prompt 不够清晰 |
优化 Prompt,添加示例 |
|||
|
推理速度慢 |
模型过大或硬件不足 |
量化、使用更小模型 |
|||
|
趋势 |
说明 |
||||
|
------ |
------ |
||||
|
**更高效的方法** |
如 LoRA+、DoRA 等新方法不断涌现 |
||||
|
**多模态微调** |
图像、语音、文本联合微调 |
||||
|
**增量微调** |
高效利用新数据,不遗忘旧知识 |
||||
|
**自动化微调** |
AutoML + 微调,自动搜索最佳配置 |
||||
|
**端侧微调** |
在手机、IoT 设备上进行微调 |
|
问题类型 |
具体表现 |
||||
|
--------- |
--------- |
||||
|
**领域知识不足** |
在医疗、法律、金融等专业领域,可能给出不够准确甚至错误的答案 |
||||
|
**企业认知缺失** |
不了解特定企业的产品、服务、内部流程 |
||||
|
**输出格式不稳定** |
难以严格遵循业务要求的输出格式(如 JSON、XML) |
||||
|
**幻觉问题** |
对不确定的问题可能编造看似合理但实际错误的答案 |
||||
|
**推理成本高** |
通用模型参数量巨大,部署和推理成本高昂 |
||||
|
维度 |
提示工程 |
RAG |
微调 |
||
|
------ |
--------- |
----- |
------ |
||
|
**实现难度** |
低 |
中 |
高 |
||
|
**成本** |
低 |
中 |
高 |
||
|
**训练时间** |
无 |
无 |
数小时到数天 |
||
|
**知识更新** |
实时 |
实时 |
需重新训练 |
||
|
**任务适配** |
通用任务 |
知识问答 |
复杂推理/格式 |
||
|
**依赖数据量** |
少量示例 |
文档库 |
百条到数千条 |
||
|
**控制力** |
弱 |
中 |
强 |
||
|
**适用场景** |
通用对话、格式控制 |
知识库问答 |
领域适应、行为模式 |
||
|
参数 |
说明 |
常用值 |
|||
|
------ |
------ |
-------- |
|||
|
`r` |
低秩分解的秩,决定可训练参数量 |
4, 8, 16, 32 |
|||
|
`lora_alpha` |
缩放因子,通常设为 r 的 2 倍 |
8, 16, 32, 64 |
|||
|
`lora_dropout` |
LoRA 层的 dropout 概率 |
0.0, 0.1 |
|||
|
`target_modules` |
应用 LoRA 的模块 |
q_proj, v_proj, k_proj, o_proj |
|||
|
维度 |
LoRA |
QLoRA |
|||
|
------ |
------ |
------- |
|||
|
**模型精度** |
保持 FP16/BF16 |
量化到 INT4/INT8 |
|||
|
**显存占用** |
7B: ~10GB |
7B: ~5GB |
|||
|
**推理速度** |
正常 |
略慢(需反量化) |
|||
|
**微调效果** |
接近全量微调 |
略低于 LoRA |
|||
|
**硬件要求** |
RTX 3090+ |
RTX 2080+ |
|||
|
维度 |
Adapter |
LoRA |
|||
|
------ |
--------- |
------ |
|||
|
**结构** |
并联在 FFN 层 |
低秩分解替代 |
|||
|
**位置** |
需指定插入位置 |
任意位置 |
|||
|
**参数量** |
~3-5% |
~0.1-1% |
|||
|
**推理延迟** |
略高(串行计算) |
无(可合并) |
|||
|
**多任务** |
多适配器切换 |
多 LoRA 动态加载 |
|||
|
维度 |
Prefix Tuning |
Prompt Tuning |
|||
|
------ |
--------------- |
--------------- |
|||
|
**提示位置** |
每层 |
仅输入层 |
|||
|
**参数量** |
较大(k × layers) |
较小(k) |
|||
|
**效果** |
更好 |
略逊 |
|||
|
**适用场景** |
复杂任务 |
简单任务 |
|||
|
方法 |
可训练参数 |
GPU 显存 |
推理延迟 |
效果 |
实现复杂度 |
|
------ |
----------- |
--------- |
--------- |
------ |
----------- |
|
Full FT |
100% |
≥24GB |
无 |
最优 |
低 |
|
LoRA |
0.1-1% |
≥10GB |
无 |
接近全量 |
中 |
|
QLoRA |
0.1-1% |
≥6GB |
略高 |
良好 |
中 |
|
Adapter |
1-5% |
≥12GB |
略高 |
良好 |
中 |
|
Prefix |
0.1-3% |
≥10GB |
无 |
中等 |
中 |
|
P-tuning v2 |
0.1-3% |
≥10GB |
无 |
良好 |
高 |
|
数据集 |
说明 |
适用场景 |
|||
|
-------- |
------ |
--------- |
|||
|
**Alpaca** |
Stanford Alpaca 团队生成 |
通用指令微调 |
|||
|
**ShareGPT** |
用户对话数据 |
对话系统 |
|||
|
**FLAN** |
谷歌指令数据集集合 |
指令遵循 |
|||
|
** Dolly** |
Databricks 员工生成 |
领域适应 |
|||
|
**OpenAssistant** |
开源对话数据 |
对话系统 |
|||
|
检查项 |
方法 |
处理方式 |
|||
|
-------- |
------ |
--------- |
|||
|
**重复数据** |
哈希比对、相似度计算 |
去重 |
|||
|
**噪声数据** |
关键词过滤、长度分布分析 |
过滤 |
|||
|
**格式错误** |
JSON 解析、schema 验证 |
修正或过滤 |
|||
|
**隐私信息** |
正则匹配、NER 检测 |
脱敏或过滤 |
|||
|
**标注一致性** |
多人标注、交叉验证 |
重新标注 |
|||
|
类型 |
说明 |
||||
|
------ |
------ |
||||
|
ROUGE-N |
N-gram 召回率(ROUGE-1, ROUGE-2) |
||||
|
ROUGE-L |
最长公共子序列 |
||||
|
ROUGE-S |
Skip-gram 召回率 |
||||
|
维度 |
评估标准 |
||||
|
------ |
--------- |
||||
|
**相关性** |
回答是否切题 |
||||
|
**准确性** |
信息是否正确无误 |
||||
|
**完整性** |
是否完整回答问题 |
||||
|
**专业性** |
术语使用是否恰当 |
||||
|
**流畅性** |
表达是否通顺 |
||||
|
方案 |
特点 |
适用场景 |
|||
|
------ |
------ |
--------- |
|||
|
**vLLM** |
PagedAttention,吞吐量高 |
高并发推理 |
|||
|
**TGI** |
HuggingFace 官方,支持推理优化 |
通用部署 |
|||
|
**Text Generation Inference** |
Rust 实现,高效 |
生产环境 |
|||
|
**Ollama** |
本地部署,简单易用 |
本地开发 |
|||
|
**llama.cpp** |
纯 C/C++,CPU 友好 |
边缘部署 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
过拟合 |
数据量太少或训练轮次过多 |
增加数据、使用正则、增加 dropout |
|||
|
灾难性遗忘 |
全量微调破坏预训练知识 |
使用 LoRA/QLoRA 或保留预训练数据 |
|||
|
分布偏移 |
微调数据与预训练数据差异大 |
混合预训练数据一起训练 |
|||
|
质量不稳定 |
数据标注不一致 |
重新标注、数据清洗 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
OOM(显存溢出) |
batch size 过大或序列太长 |
减小 batch size、启用 gradient checkpointing、使用 QLoRA |
|||
|
Loss 不下降 |
学习率不合适或模型问题 |
调整学习率、检查数据格式 |
|||
|
Loss 爆炸 |
学习率过高或梯度问题 |
减小学习率、启用梯度裁剪 |
|||
|
NaN 损失 |
数值不稳定 |
使用混合精度训练、检查数据 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
重复生成 |
解码策略问题 |
调整 temperature、启用 repetition_penalty |
|||
|
生成截断 |
最大长度限制 |
增加 max_new_tokens |
|||
|
回答格式错误 |
Prompt 不够清晰 |
优化 Prompt,添加示例 |
|||
|
推理速度慢 |
模型过大或硬件不足 |
量化、使用更小模型 |
|||
|
趋势 |
说明 |
||||
|
------ |
------ |
||||
|
**更高效的方法** |
如 LoRA+、DoRA 等新方法不断涌现 |
||||
|
**多模态微调** |
图像、语音、文本联合微调 |
||||
|
**增量微调** |
高效利用新数据,不遗忘旧知识 |
||||
|
**自动化微调** |
AutoML + 微调,自动搜索最佳配置 |
||||
|
**端侧微调** |
在手机、IoT 设备上进行微调 |
|
问题类型 |
具体表现 |
||||
|
--------- |
--------- |
||||
|
**领域知识不足** |
在医疗、法律、金融等专业领域,可能给出不够准确甚至错误的答案 |
||||
|
**企业认知缺失** |
不了解特定企业的产品、服务、内部流程 |
||||
|
**输出格式不稳定** |
难以严格遵循业务要求的输出格式(如 JSON、XML) |
||||
|
**幻觉问题** |
对不确定的问题可能编造看似合理但实际错误的答案 |
||||
|
**推理成本高** |
通用模型参数量巨大,部署和推理成本高昂 |
||||
|
维度 |
提示工程 |
RAG |
微调 |
||
|
------ |
--------- |
----- |
------ |
||
|
**实现难度** |
低 |
中 |
高 |
||
|
**成本** |
低 |
中 |
高 |
||
|
**训练时间** |
无 |
无 |
数小时到数天 |
||
|
**知识更新** |
实时 |
实时 |
需重新训练 |
||
|
**任务适配** |
通用任务 |
知识问答 |
复杂推理/格式 |
||
|
**依赖数据量** |
少量示例 |
文档库 |
百条到数千条 |
||
|
**控制力** |
弱 |
中 |
强 |
||
|
**适用场景** |
通用对话、格式控制 |
知识库问答 |
领域适应、行为模式 |
||
|
参数 |
说明 |
常用值 |
|||
|
------ |
------ |
-------- |
|||
|
`r` |
低秩分解的秩,决定可训练参数量 |
4, 8, 16, 32 |
|||
|
`lora_alpha` |
缩放因子,通常设为 r 的 2 倍 |
8, 16, 32, 64 |
|||
|
`lora_dropout` |
LoRA 层的 dropout 概率 |
0.0, 0.1 |
|||
|
`target_modules` |
应用 LoRA 的模块 |
q_proj, v_proj, k_proj, o_proj |
|||
|
维度 |
LoRA |
QLoRA |
|||
|
------ |
------ |
------- |
|||
|
**模型精度** |
保持 FP16/BF16 |
量化到 INT4/INT8 |
|||
|
**显存占用** |
7B: ~10GB |
7B: ~5GB |
|||
|
**推理速度** |
正常 |
略慢(需反量化) |
|||
|
**微调效果** |
接近全量微调 |
略低于 LoRA |
|||
|
**硬件要求** |
RTX 3090+ |
RTX 2080+ |
|||
|
维度 |
Adapter |
LoRA |
|||
|
------ |
--------- |
------ |
|||
|
**结构** |
并联在 FFN 层 |
低秩分解替代 |
|||
|
**位置** |
需指定插入位置 |
任意位置 |
|||
|
**参数量** |
~3-5% |
~0.1-1% |
|||
|
**推理延迟** |
略高(串行计算) |
无(可合并) |
|||
|
**多任务** |
多适配器切换 |
多 LoRA 动态加载 |
|||
|
维度 |
Prefix Tuning |
Prompt Tuning |
|||
|
------ |
--------------- |
--------------- |
|||
|
**提示位置** |
每层 |
仅输入层 |
|||
|
**参数量** |
较大(k × layers) |
较小(k) |
|||
|
**效果** |
更好 |
略逊 |
|||
|
**适用场景** |
复杂任务 |
简单任务 |
|||
|
方法 |
可训练参数 |
GPU 显存 |
推理延迟 |
效果 |
实现复杂度 |
|
------ |
----------- |
--------- |
--------- |
------ |
----------- |
|
Full FT |
100% |
≥24GB |
无 |
最优 |
低 |
|
LoRA |
0.1-1% |
≥10GB |
无 |
接近全量 |
中 |
|
QLoRA |
0.1-1% |
≥6GB |
略高 |
良好 |
中 |
|
Adapter |
1-5% |
≥12GB |
略高 |
良好 |
中 |
|
Prefix |
0.1-3% |
≥10GB |
无 |
中等 |
中 |
|
P-tuning v2 |
0.1-3% |
≥10GB |
无 |
良好 |
高 |
|
数据集 |
说明 |
适用场景 |
|||
|
-------- |
------ |
--------- |
|||
|
**Alpaca** |
Stanford Alpaca 团队生成 |
通用指令微调 |
|||
|
**ShareGPT** |
用户对话数据 |
对话系统 |
|||
|
**FLAN** |
谷歌指令数据集集合 |
指令遵循 |
|||
|
** Dolly** |
Databricks 员工生成 |
领域适应 |
|||
|
**OpenAssistant** |
开源对话数据 |
对话系统 |
|||
|
检查项 |
方法 |
处理方式 |
|||
|
-------- |
------ |
--------- |
|||
|
**重复数据** |
哈希比对、相似度计算 |
去重 |
|||
|
**噪声数据** |
关键词过滤、长度分布分析 |
过滤 |
|||
|
**格式错误** |
JSON 解析、schema 验证 |
修正或过滤 |
|||
|
**隐私信息** |
正则匹配、NER 检测 |
脱敏或过滤 |
|||
|
**标注一致性** |
多人标注、交叉验证 |
重新标注 |
|||
|
类型 |
说明 |
||||
|
------ |
------ |
||||
|
ROUGE-N |
N-gram 召回率(ROUGE-1, ROUGE-2) |
||||
|
ROUGE-L |
最长公共子序列 |
||||
|
ROUGE-S |
Skip-gram 召回率 |
||||
|
维度 |
评估标准 |
||||
|
------ |
--------- |
||||
|
**相关性** |
回答是否切题 |
||||
|
**准确性** |
信息是否正确无误 |
||||
|
**完整性** |
是否完整回答问题 |
||||
|
**专业性** |
术语使用是否恰当 |
||||
|
**流畅性** |
表达是否通顺 |
||||
|
方案 |
特点 |
适用场景 |
|||
|
------ |
------ |
--------- |
|||
|
**vLLM** |
PagedAttention,吞吐量高 |
高并发推理 |
|||
|
**TGI** |
HuggingFace 官方,支持推理优化 |
通用部署 |
|||
|
**Text Generation Inference** |
Rust 实现,高效 |
生产环境 |
|||
|
**Ollama** |
本地部署,简单易用 |
本地开发 |
|||
|
**llama.cpp** |
纯 C/C++,CPU 友好 |
边缘部署 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
过拟合 |
数据量太少或训练轮次过多 |
增加数据、使用正则、增加 dropout |
|||
|
灾难性遗忘 |
全量微调破坏预训练知识 |
使用 LoRA/QLoRA 或保留预训练数据 |
|||
|
分布偏移 |
微调数据与预训练数据差异大 |
混合预训练数据一起训练 |
|||
|
质量不稳定 |
数据标注不一致 |
重新标注、数据清洗 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
OOM(显存溢出) |
batch size 过大或序列太长 |
减小 batch size、启用 gradient checkpointing、使用 QLoRA |
|||
|
Loss 不下降 |
学习率不合适或模型问题 |
调整学习率、检查数据格式 |
|||
|
Loss 爆炸 |
学习率过高或梯度问题 |
减小学习率、启用梯度裁剪 |
|||
|
NaN 损失 |
数值不稳定 |
使用混合精度训练、检查数据 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
重复生成 |
解码策略问题 |
调整 temperature、启用 repetition_penalty |
|||
|
生成截断 |
最大长度限制 |
增加 max_new_tokens |
|||
|
回答格式错误 |
Prompt 不够清晰 |
优化 Prompt,添加示例 |
|||
|
推理速度慢 |
模型过大或硬件不足 |
量化、使用更小模型 |
|||
|
趋势 |
说明 |
||||
|
------ |
------ |
||||
|
**更高效的方法** |
如 LoRA+、DoRA 等新方法不断涌现 |
||||
|
**多模态微调** |
图像、语音、文本联合微调 |
||||
|
**增量微调** |
高效利用新数据,不遗忘旧知识 |
||||
|
**自动化微调** |
AutoML + 微调,自动搜索最佳配置 |
||||
|
**端侧微调** |
在手机、IoT 设备上进行微调 |
|
问题类型 |
具体表现 |
||||
|
--------- |
--------- |
||||
|
**领域知识不足** |
在医疗、法律、金融等专业领域,可能给出不够准确甚至错误的答案 |
||||
|
**企业认知缺失** |
不了解特定企业的产品、服务、内部流程 |
||||
|
**输出格式不稳定** |
难以严格遵循业务要求的输出格式(如 JSON、XML) |
||||
|
**幻觉问题** |
对不确定的问题可能编造看似合理但实际错误的答案 |
||||
|
**推理成本高** |
通用模型参数量巨大,部署和推理成本高昂 |
||||
|
维度 |
提示工程 |
RAG |
微调 |
||
|
------ |
--------- |
----- |
------ |
||
|
**实现难度** |
低 |
中 |
高 |
||
|
**成本** |
低 |
中 |
高 |
||
|
**训练时间** |
无 |
无 |
数小时到数天 |
||
|
**知识更新** |
实时 |
实时 |
需重新训练 |
||
|
**任务适配** |
通用任务 |
知识问答 |
复杂推理/格式 |
||
|
**依赖数据量** |
少量示例 |
文档库 |
百条到数千条 |
||
|
**控制力** |
弱 |
中 |
强 |
||
|
**适用场景** |
通用对话、格式控制 |
知识库问答 |
领域适应、行为模式 |
||
|
参数 |
说明 |
常用值 |
|||
|
------ |
------ |
-------- |
|||
|
`r` |
低秩分解的秩,决定可训练参数量 |
4, 8, 16, 32 |
|||
|
`lora_alpha` |
缩放因子,通常设为 r 的 2 倍 |
8, 16, 32, 64 |
|||
|
`lora_dropout` |
LoRA 层的 dropout 概率 |
0.0, 0.1 |
|||
|
`target_modules` |
应用 LoRA 的模块 |
q_proj, v_proj, k_proj, o_proj |
|||
|
维度 |
LoRA |
QLoRA |
|||
|
------ |
------ |
------- |
|||
|
**模型精度** |
保持 FP16/BF16 |
量化到 INT4/INT8 |
|||
|
**显存占用** |
7B: ~10GB |
7B: ~5GB |
|||
|
**推理速度** |
正常 |
略慢(需反量化) |
|||
|
**微调效果** |
接近全量微调 |
略低于 LoRA |
|||
|
**硬件要求** |
RTX 3090+ |
RTX 2080+ |
|||
|
维度 |
Adapter |
LoRA |
|||
|
------ |
--------- |
------ |
|||
|
**结构** |
并联在 FFN 层 |
低秩分解替代 |
|||
|
**位置** |
需指定插入位置 |
任意位置 |
|||
|
**参数量** |
~3-5% |
~0.1-1% |
|||
|
**推理延迟** |
略高(串行计算) |
无(可合并) |
|||
|
**多任务** |
多适配器切换 |
多 LoRA 动态加载 |
|||
|
维度 |
Prefix Tuning |
Prompt Tuning |
|||
|
------ |
--------------- |
--------------- |
|||
|
**提示位置** |
每层 |
仅输入层 |
|||
|
**参数量** |
较大(k × layers) |
较小(k) |
|||
|
**效果** |
更好 |
略逊 |
|||
|
**适用场景** |
复杂任务 |
简单任务 |
|||
|
方法 |
可训练参数 |
GPU 显存 |
推理延迟 |
效果 |
实现复杂度 |
|
------ |
----------- |
--------- |
--------- |
------ |
----------- |
|
Full FT |
100% |
≥24GB |
无 |
最优 |
低 |
|
LoRA |
0.1-1% |
≥10GB |
无 |
接近全量 |
中 |
|
QLoRA |
0.1-1% |
≥6GB |
略高 |
良好 |
中 |
|
Adapter |
1-5% |
≥12GB |
略高 |
良好 |
中 |
|
Prefix |
0.1-3% |
≥10GB |
无 |
中等 |
中 |
|
P-tuning v2 |
0.1-3% |
≥10GB |
无 |
良好 |
高 |
|
数据集 |
说明 |
适用场景 |
|||
|
-------- |
------ |
--------- |
|||
|
**Alpaca** |
Stanford Alpaca 团队生成 |
通用指令微调 |
|||
|
**ShareGPT** |
用户对话数据 |
对话系统 |
|||
|
**FLAN** |
谷歌指令数据集集合 |
指令遵循 |
|||
|
** Dolly** |
Databricks 员工生成 |
领域适应 |
|||
|
**OpenAssistant** |
开源对话数据 |
对话系统 |
|||
|
检查项 |
方法 |
处理方式 |
|||
|
-------- |
------ |
--------- |
|||
|
**重复数据** |
哈希比对、相似度计算 |
去重 |
|||
|
**噪声数据** |
关键词过滤、长度分布分析 |
过滤 |
|||
|
**格式错误** |
JSON 解析、schema 验证 |
修正或过滤 |
|||
|
**隐私信息** |
正则匹配、NER 检测 |
脱敏或过滤 |
|||
|
**标注一致性** |
多人标注、交叉验证 |
重新标注 |
|||
|
类型 |
说明 |
||||
|
------ |
------ |
||||
|
ROUGE-N |
N-gram 召回率(ROUGE-1, ROUGE-2) |
||||
|
ROUGE-L |
最长公共子序列 |
||||
|
ROUGE-S |
Skip-gram 召回率 |
||||
|
维度 |
评估标准 |
||||
|
------ |
--------- |
||||
|
**相关性** |
回答是否切题 |
||||
|
**准确性** |
信息是否正确无误 |
||||
|
**完整性** |
是否完整回答问题 |
||||
|
**专业性** |
术语使用是否恰当 |
||||
|
**流畅性** |
表达是否通顺 |
||||
|
方案 |
特点 |
适用场景 |
|||
|
------ |
------ |
--------- |
|||
|
**vLLM** |
PagedAttention,吞吐量高 |
高并发推理 |
|||
|
**TGI** |
HuggingFace 官方,支持推理优化 |
通用部署 |
|||
|
**Text Generation Inference** |
Rust 实现,高效 |
生产环境 |
|||
|
**Ollama** |
本地部署,简单易用 |
本地开发 |
|||
|
**llama.cpp** |
纯 C/C++,CPU 友好 |
边缘部署 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
过拟合 |
数据量太少或训练轮次过多 |
增加数据、使用正则、增加 dropout |
|||
|
灾难性遗忘 |
全量微调破坏预训练知识 |
使用 LoRA/QLoRA 或保留预训练数据 |
|||
|
分布偏移 |
微调数据与预训练数据差异大 |
混合预训练数据一起训练 |
|||
|
质量不稳定 |
数据标注不一致 |
重新标注、数据清洗 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
OOM(显存溢出) |
batch size 过大或序列太长 |
减小 batch size、启用 gradient checkpointing、使用 QLoRA |
|||
|
Loss 不下降 |
学习率不合适或模型问题 |
调整学习率、检查数据格式 |
|||
|
Loss 爆炸 |
学习率过高或梯度问题 |
减小学习率、启用梯度裁剪 |
|||
|
NaN 损失 |
数值不稳定 |
使用混合精度训练、检查数据 |
|||
|
问题 |
原因 |
解决方案 |
|||
|
------ |
------ |
--------- |
|||
|
重复生成 |
解码策略问题 |
调整 temperature、启用 repetition_penalty |
|||
|
生成截断 |
最大长度限制 |
增加 max_new_tokens |
|||
|
回答格式错误 |
Prompt 不够清晰 |
优化 Prompt,添加示例 |
|||
|
推理速度慢 |
模型过大或硬件不足 |
量化、使用更小模型 |
|||
|
趋势 |
说明 |
||||
|
------ |
------ |
||||
|
**更高效的方法** |
如 LoRA+、DoRA 等新方法不断涌现 |
||||
|
**多模态微调** |
图像、语音、文本联合微调 |
||||
|
**增量微调** |
高效利用新数据,不遗忘旧知识 |
||||
|
**自动化微调** |
AutoML + 微调,自动搜索最佳配置 |
||||
|
**端侧微调** |
在手机、IoT 设备上进行微调 |
代码示例
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from datasets import load_dataset
# 加载预训练模型
model_name = "meta-llama/Llama-2-7b-hf"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 准备数据集
dataset = load_dataset("json", data_files="domain_data.jsonl")
dataset = dataset.map(lambda x: tokenizer(x["text"]), batched=True)
# 全量微调配置
training_args = TrainingArguments(
output_dir="./full_ft_model",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=2e-5,
fp16=True,
logging_steps=10,
save_steps=500,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
)
trainer.train()
from adapters import AdapterConfig, AdapterType
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-uncased")
添加 Adapter
adapter_config = AdapterConfig(
hidden_size=768,
adapter_size=64,
adapter_activation="relu",
adapter_reduction_factor=16,
)
model.add_adapter("domain_task", config=adapter_config)
激活适配器
model.train_adapter("domain_task")
推理时切换适配器
model.set_active_adapters("domain_task")
┌─────────────────────────────────────────────────────────────┐
│ 模型微调核心原理 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 预训练阶段 │
│ ┌─────────────┐ │
│ │ 海量通用数据 │ → 通用语言能力 + 广泛知识 │
│ │ (Web, Books) │ │
│ └─────────────┘ │
│ ↓ │
│ 微调阶段 │
│ ┌─────────────┐ │
│ │ 领域/业务数据│ → 领域专业能力 + 业务适配 │
│ │ (Domain Data) │ │
│ └─────────────┘ │
│ ↓ │
│ ┌─────────────┐ │
│ │ 微调后模型 │ → 通用能力 + 领域专业能力 │
│ └─────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
更多推荐
 7
7 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)