
Python 进阶知识八 -- 完结
·
22. 闭包
当内层函数使用外层函数的变量 同时外层函数将内存函数作为返回 此时内层函数就叫做闭包函数
def 外层函数(传入参数1):
def 内层函数(传入参数2):
print(f"{传入参数1}+{传入参数2}")
return 内层函数
# 此时当我们调用外层函数
fn = 外层函数(传入参数值1) # => return给fn的是 内层函数
# 所以当我们使用fn时 相当于使用了内层函数 此时传入参数1也固定在调用外层函数时传入的那个值
fn(传入参数值2)当我们想在闭包中修改外层函数的变量时候 可以在内层函数中添加 nonlocal 外层变量名 即可修改
def outer(num1):
def inter(num2):
nonlocal num1
num1 += num2
print(num1)
return inter
fn = outer(1)
fn(2) # 得到3
fn(2) # 得到5 因为外层变量num1已经修改为323. 装饰器
装饰器也是一种闭包 作用是 在不破坏函数原有代码和功能的情况下 为目标函数添加新功能
def 外层函数(目标函数):
def 内层函数():
想要在原函数基础上添加的功能
原函数()
想要在原函数基础上添加的功能
return 内层函数
def 原函数():
执行体(原有功能)
# 此时当调用外层函数时将原函数作为参数传入
fn = 外层函数(原函数)
fn()def outer(func):
def inter():
print("睡觉了")
func()
print("睡醒了")
return inter
def sleep():
import random
import time
print("睡眠中..")
time.sleep(random.randint(1,5)) # time.sleep()让程序暂停一段时间 random.randint(1,5)随机生成一个[1,5]之间的数
fn = outer(sleep)
fn()def 外层函数(目标函数):
def 内层函数():
想要在原函数基础上添加的功能
原函数()
想要在原函数基础上添加的功能
return 内层函数
@外层函数
def 原函数():
执行体(原有功能)
sleep()def outer(func):
def inter():
print("睡觉了")
func()
print("睡醒了")
return inter
@outer
def sleep():
import random
import time
print("睡眠中..")
time.sleep(random.randint(1,5)) # time.sleep()让程序暂停一段时间 random.randint(1,5)随机生成一个[1,5]之间的数
sleep()24. 设计模式
a. 单例模式
当我们想要将一个类(如工具类等) 只获取它唯一的类实例对象 从而能够持续复用它 而不是每次使用都重新构建一次类实例对象 节省内存和创建对象的开销
class StrTools:
pass
t1 = StrTools()
t2 = StrTools()
print(t1,t2)
# 结果
# <__main__.StrTools object at 0x7fc8f456cd10>
# <__main__.StrTools object at 0x7fc8f456cc80>
# 所以是分别构建了两个实例对象class StrTools:
pass
strtool = StrTools()from 引用类所在文件 import StrTools
t1 = StrTools
t2 = StrTools
print(t1,t2)
# 结果同在一个地址下 这样就避免了 实现的是一个功能 但反复构建实例对象的开销以及内存的不必占用b. 工厂模式
当需要构建大量类实例对象时 可使用统一的工厂模式构建 这样可以
- 大批量创建对象时有统一的接口 易于维护
- 当发生修改的时候 仅修改工厂类即可
class Person():
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
worker = Worker()
student = Student()
teacher = Teacher()
worker1 = Worker()
worker2 = Worker()
# 像这样的构建方式 如果某一个类的构建方式改变 我们需要一个一个去改class Person():
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
class Factory:
def get_person(self,p_type):
if p_type == 'w':
return Worker()
elif p_type == 's':
return Student()
else:
return Teacher()
f = Factory()
worker = f.get_person('w')
student = f.get_person('s')
teacher = f.get_person('t')25. 多线程
- 进程就是一个程序 运行在系统之上 便称他为一个运行进程 并分配进程ID方便管理
- 线程是归属于进程的 一个进程可以开启多个线程 执行不同的工作 是进行的实际工作的最小单位
- 操作系统可同时运行多个进程 -- 多任务运行
- 一个进程内可运行多个线程 -- 多线程进行
- 进程之间的内存是隔离的 也就是都拥有自己的内存空间 不可互相访问
- 而线程之间是内存共享的 一个进程的内存空间是被它中的所有线程所共享的
多线程编程 - threading模块
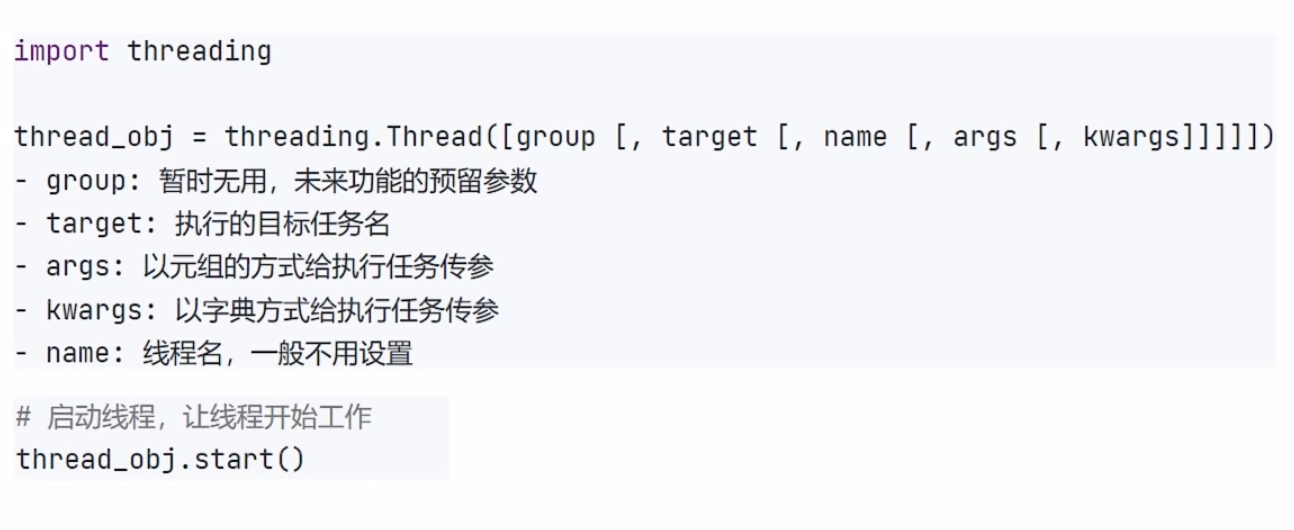
import time
def sing(msg):
while True:
print(msg)
time.sleep(1)
def dance(msg):
while True:
print(msg)
time.sleep(1)
if __name__ == '__main__':
sing('我在唱歌')
dance('我在跳舞')
# 此处我的本意是想让两个交替进行执行 但是实际上因为是单线程的 只会等另一个执行完
# 从而导致dance()并不会执行import time
import threading
def sing(msg):
while True:
print(msg)
time.sleep(1)
def dance(msg):
while True:
print(msg)
time.sleep(1)
if __name__ == '__main__':
sing_thread = threading.Thread(target=sing, args=('我在唱歌',))
dance_thread = threading.Thread(target=dance, kwargs={"msg" : "我在跳舞"})
# 让每一个线程开始运行
sing_thread.start()
dance_thread.start()
# 此时才会达到两个线程并行运行的结果26. 网络编程
socket 进程之间通信的工具 -- 即当两个进程之间需要传递数据时 可以通过socket完成通信
socket -- 服务端开发
-- 等待其它进程的连接、可接收发来的消息、可回复消息
"""
socket服务端
"""
import socket
# 创建socket对象
socket_server = socket.socket()
# 绑定ip地址和端口
socket_server.bind(("localhost", 8080)) # bind() - 接收一个参数 这个参数必须是一个地址元组
# 监听连接
socket_server.listen(1) # listen方法的参数表示允许多少个(整数)客户端连接到服务器,超过这个数量的连接请求会被拒绝
# 等待客户端连接
# result : tuple = socket_server.accept() # accept方法会阻塞程序 直到有客户端连接到服务器为止
# conn = result[0] # 获取连接对象
# address = result[1] # 获取客户端地址
# 当有客户端连接到服务器时,accept方法会返回一个元组
# 包含两个元素:一个是新的socket对象,用于与客户端通信;另一个是客户端的地址信息
conn , address = socket_server.accept()
print("客户端连接成功,地址为:", address)
while True :
# 接收客户端发送的数据
data : str = conn.recv(1024).decode("utf-8") # recv方法的参数表示一次最多接收多少字节的数据,返回值是一个字节对象,需要使用decode方法将其解码为字符串
print("接收到客户端数据:", data)
# 发送数据给客户端
msg = input("请输入要发送给客户端的数据:")
if msg == "exit" :
print("服务器已关闭!")
break
conn.send(msg.encode("utf-8")) # send方法用于发送数据给客户端 encode方法将字符串编码为字节对象
print("数据发送成功!")
# 关闭连接
conn.close() # 关闭与客户端的连接
socket_server.close() # 关闭服务器socket对象socket -- 客户端开发
-- 主动连接服务端、可发送消息、可接收消息
"""
socket客户端
"""
import socket
# 创建socket对象
socket_client = socket.socket()
# 连接服务器
socket_client.connect(("localhost", 8080)) # connect() - 接收一个参数 这个参数必须是一个地址元组
# 发送数据给服务器
while True:
# 发送消息给服务器
send_msg = input("请输入要发送给服务器的数据:")
if send_msg == "exit":
print("客户端已关闭!")
break
socket_client.send(send_msg.encode("utf-8")) # send方法用于发送数据给服务器 encode方法将字符串编码为字节对象
print("数据发送成功!")
# 接收服务器发送的数据
recv_data = socket_client.recv(1024).decode("utf-8") # recv方法的参数表示一次最多接收多少字节的数据,返回值是一个字节对象,需要使用decode方法将其解码为字符串
print("接收到服务器数据:", recv_data)
# 关闭连接
socket_client.close()27. 正则表达式
re模块匹配
"""
正则表达式匹配
"""
import re
s = "roy is a good boy"
double = "lanlan roy lanlan lanlan"
# match函数 -- 从头开始匹配
# 从字符串的起始位置开始匹配,如果匹配成功,返回一个Match对象,否则返回None
print("---match函数---")
result = re.match("roy", s) # ("roy"是正则表达式,s是要匹配的字符串)
print(result) # <re.Match object; span=(0, 3), match='roy'> span表示匹配的字符串在原字符串中的位置,match表示匹配的字符串
result = re.match("is", s)
print(result) # None 因为"roy"不是字符串s的起始位置,所以匹配失败,返回None
# search函数 -- 从任意位置匹配
# 从字符串的任意位置开始匹配,如果匹配成功,返回一个Match对象,否则返回None
print("---search函数---")
result = re.search("is", s)
print(result) # <re.Match object; span=(4, 6), match='is'>
result = re.search("lanlan ", s)
print(result) # None 因为"lanlan "在字符串s中不存在,所以匹配失败,返回None
# findall函数 -- 查找所有匹配的字符串
# 在字符串中查找所有匹配的字符串,返回一个列表,如果没有找到匹配的字符串,返回一个空列表
print("---findall函数---")
result = re.findall("lanlan", double)
print(result) # ['lanlan', 'lanlan', 'lanlan'] 因为字符串double中有三个"lanlan",所以返回一个包含三个"lanlan"的列表
result = re.findall("haha ", double)
print(result) # [] 因为"haha "在字符串double中不存在,所以返回一个空列表
元字符匹配
元字符匹配
记得要在字符串前面加上r,表示原始字符串,这样就不需要对反斜杠进行转义了
单字符匹配
- . -- 匹配除换行符以外的任意单个字符 \. - 匹配点本身
- [] -- 匹配括号内的任意一个字符
- \d -- 匹配任意一个数字字符 即[0-9]
- \D -- 匹配任意一个非数字字符
- \s -- 匹配任意一个空白字符 包括空格、制表符、换行符等
- \S -- 匹配任意一个非空白字符
- \w -- 匹配任意一个字母、数字或下划线字符 即[a-zA-Z0-9_]
- \W -- 匹配任意一个非字母、数字或下划线字符
数量匹配
- * -- 匹配前一个字符出现0次或多次
- + -- 匹配前一个字符出现1次或多次
- ? -- 匹配前一个字符出现0次或1次
- {n} -- 匹配前一个字符出现n次
- {n,} -- 匹配前一个字符出现至少n次
- {n,m} -- 匹配前一个字符出现至少n次,至多m次
边界匹配
- ^ -- 匹配字符串的开头
- $ -- 匹配字符串的结尾
- \b -- 匹配单词的边界
- \B -- 匹配非单词的边界
分组匹配
- | -- 匹配左右任意一个表达式
- () -- 将()中的字符作为一个分组
import re
# 匹配账号 -- 只能由字母和数字组成 长度限制6-10位
print("---账号匹配---")
rule = '^[0-9a-zA-Z]{6,10}$' # 代表 从字符串的开头开始匹配 只能由数字和字母组成 且[0-9a-zA-Z]字符只能出现6-10次 然后到字符串的结尾结束匹配
s = "lanlan roy"
result = re.findall(rule,s)
print(result) # [] 因为字符串s中有空格,所以不满足规则,返回一个空列表
# 匹配QQ号 -- 只能由数字组成 长度限制5-12位 不能以0开头
print("---QQ号匹配---")
rule = '^[1-9][0-9]{4,11}$' # 代表 从字符串的开头开始匹配 只能由数字组成 且[0-9]字符只能出现4-11次 不能以0开头 然后到字符串的结尾结束匹配
s = "0123456789"
result = re.findall(rule,s)
print(result) # [] 因为字符串s以0开头,所以不满足规则,返回一个空列表
# 匹配邮箱地址 -- 只允许qq、163和gmail三种邮箱 账号只能由字母、数字和下划线组成
# abc.efg.hij@qq.com.cn
# abc@163.com
print("---邮箱地址匹配---")
# 当规则中有分组()时 findall函数返回的元组中 是每一个分组所匹配到的字符串
# 所以此时需要将整个规则用()括起来 这样findall函数返回的元组中 就只有一个元素 就是整个规则匹配到的字符串
# rule = r'(^\w+(\.\w+)*@(qq|163|gmail)(\.\w+)+$)'
# 或者可以直接改成用match函数来匹配
rule = r'^\w+(\.\w+)*@(qq|163|gmail)(\.\w+)+$'
s = "abc@163.com"
result = re.match(rule,s)
print(result) # [('','163','.com')] 因为字符串s满足规则28. 递归
递归是 在满足条件的情况下 函数自己调用自己的一种特殊编程技巧
需要注意的是:
- 递归一定要有退出的条件 否则会陷入一直调用自己的无限循环
- 同时当调用了自己后 一定要用变量去接收调用后返回的数据 否则就只是在调用 但并没获得调用的结果
import os
# 列出该路径下的内容
print(os.listdir("D:/test")) # 结果 某文件 某文件夹...
# 判断指定路径是不是文件夹
print(os.path.isdir("D:/test/a")) # True/False
# 判断该路径是否存在
print(os.path.exists("D:/test")) # True/False"""
递归目录遍历
"""
import os
def get_files_recursion_from_dir(path):
"""
从指定的文件夹中 使用递归的方式获取所有的文件路径
:param path : 判断的文件夹路径
:return : list 所有的文件路径列表 如果没有文件 则返回一个空列表[]
"""
file_list = []
if os.path.exists(path):
for file in os.listdir(path):
new_path = path +"/" + file
if os.path.isdir(new_path):
file_list += get_files_recursion_from_dir(new_path)
else:
file_list.append(new_path)
else:
print("路径不存在")
return []
return file_list
if __name__ == '__main__':
files = get_files_recursion_from_dir("D:/6")
print(files)
"""
最终返回
['D:/6/1.txt', 'D:/6/2.txt', 'D:/6/3.txt',
'D:/6/a/a1.txt', 'D:/6/a/a2.txt', 'D:/6/a/a3.txt',
'D:/6/a/aa/aa1.txt', 'D:/6/a/aa/aa2.txt', 'D:/6/a/aa/aa3.txt',
'D:/6/b/b1.txt', 'D:/6/b/b2.txt', 'D:/6/b/b3.txt']
"""更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)