
Java 程序员第 40 阶段08:从零搭建 Java 大模型完整项目,高可用架构与性能优化
前言
大模型 API 服务对可用性和性能有极高要求,任何响应延迟或服务中断都会直接影响用户体验和企业业务。本篇文章深入讲解 Sentinel 熔断降级配置、Redis 分布式缓存高可用、MySQL 主从复制与读写分离、接口限流与排队合并策略、异步化与线程池优化等核心主题,配套四张技术架构图帮助读者构建高可用、高性能的大模型服务架构。
────────────────────────────────────────────────────────────
一、Sentinel 熔断降级配置
1.1 熔断器模式核心原理
熔断器模式是防止雪崩效应的关键机制。熔断器有三种状态:Closed(关闭)——正常请求通过,失败计数累加;Open(打开)——所有请求快速失败,返回降级响应;Half-Open(半开)——尝试放行少量请求,若成功则恢复关闭状态,否则继续保持打开。
1.2 Sentinel 快速入门
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.6</version>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-transport-simple-http</artifactId>
<version>1.8.6</version>
</dependency>
1.3 熔断降级规则配置
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeRule;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeRuleManager;
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import java.util.Arrays;
public class SentinelDegradeConfig {
public static void initDegradeRules() {
DegradeRule degradeRule = new DegradeRule("llmApi")
.setGrade(RuleConstant.DEGRADE_GRADE_RT) // 按 RT 熔断
.setCount(2000) // 阈值:2秒
.setSlowRatioThreshold(0.5) // 50% 慢调用比例
.setMinRequestAmount(5) // 最小请求数
.setStatIntervalMs(60000) // 统计窗口:1分钟
.setTimeWindow(30); // 熔断时长:30秒
DegradeRule exceptionRule = new DegradeRule("llmApiException")
.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO)
.setCount(0.3) // 30% 异常比例
.setMinRequestAmount(5)
.setTimeWindow(60);
DegradeRuleManager.loadRules(Arrays.asList(degradeRule, exceptionRule));
}
}
1.4 Sentinel + Spring Boot 集成
@Aspect
@Component
public class SentinelAspect {
@Around("@annotation(SentinelResource)")
public Object around(ProceedingJoinPoint pjp, SentinelResource annotation) throws Throwable {
String resourceName = annotation.value();
Entry entry = null;
try {
entry = SphU.entry(resourceName);
return pjp.proceed();
} catch (BlockException e) {
// 触发限流或熔断,执行降级逻辑
return handleBlock(annotation.fallback());
} finally {
if (entry != null) {
entry.exit();
}
}
}
private Object handleBlock(String fallbackName) {
// 返回降级响应
return "{\"error\":\"service_degraded\",\"message\":\"服务暂时繁忙,请稍后重试\"}";
}
}
@SentinelResource(value = "chatCompletion", fallback = "chatFallback")
public ChatResponse chat(ChatRequest request) {
return llmService.chat(request);
}
public ChatResponse chatFallback(ChatRequest request, Throwable t) {
// 降级逻辑:返回缓存结果或友好提示
return ChatResponse.degraded("服务降级,请稍后重试");
}
────────────────────────────────────────────────────────────
二、Redis 分布式缓存高可用
2.1 Redis Cluster 架构
Redis Cluster 采用槽(Slot)分片机制,3 主 3 从架构下,每个主节点负责 5460 个槽,通过 Gossip 协议进行节点间通信,实现自动故障转移。
┌─────────────────┐
│ Redis Cluster │
│ (3 主 3 从) │
└────────┬────────┘
│
┌──────────┬──────────┬─┴─┬──────────┬──────────┐
│Master-1 │Master-2 │Master-3│Replica-1│Replica-2│Replica-3│
│ Slot:0- │Slot:5460-│Slot:10922-│ (同步) │ (同步) │ (同步) │
│ 5460 │ 10922 │ 16383 │ │ │ │
└──────────┴──────────┴──────────┴─────────┴─────────┴─────────┘
2.2 多级缓存设计
大模型场景推荐多级缓存架构:L1 本地缓存——Caffeine(Guava Cache 替代品),存储热点数据,毫秒级访问;L2 分布式缓存——Redis Cluster,存储共享数据,支持跨节点访问;L3 持久化存储——MySQL,存储最终数据。
@Configuration
public class CacheConfig {
@Bean
public Cache<String, Object> localCache() {
return Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(1, TimeUnit.MINUTES)
.recordStats()
.build();
}
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
return template;
}
}
@Service
public class LlmCacheService {
@Autowired
private Cache<String, Object> localCache;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
private static final String CACHE_PREFIX = "llm:";
public Object getResponse(String prompt) {
String key = hashPrompt(prompt);
// L1: 本地缓存
Object cached = localCache.getIfPresent(key);
if (cached != null) {
return cached;
}
// L2: Redis 缓存
cached = redisTemplate.opsForValue().get(CACHE_PREFIX + key);
if (cached != null) {
localCache.put(key, cached); // 回填 L1
return cached;
}
return null;
}
public void cacheResponse(String prompt, Object response) {
String key = hashPrompt(prompt);
redisTemplate.opsForValue().set(CACHE_PREFIX + key, response, 1, TimeUnit.HOURS);
localCache.put(key, response);
}
}
2.3 缓存策略选择
|
策略 |
原理 |
适用场景 |
一致性 |
|
Cache-Aside |
应用主导读写,缓存旁路 |
读多写少 |
最终一致 |
|
Read-Through |
缓存自动加载 |
简化应用逻辑 |
最终一致 |
|
Write-Through |
同步写缓存和存储 |
数据一致性要求高 |
强一致 |
|
Write-Behind |
异步写回 |
写入性能要求高 |
最终一致 |
────────────────────────────────────────────────────────────
三、MySQL 主从复制与读写分离
3.1 主从复制原理
MySQL 主从复制基于 Binlog 实现,主库将所有写操作记录到 Binlog,从库通过 I/O 线程读取主库 Binlog 并写入 Relay Log,SQL 线程重放 Relay Log 实现数据同步。
复制模式对比:异步复制——主库提交事务后立即返回,不等待从库确认;半同步复制——主库等待至少一个从库确认才提交;组复制(MGR)——基于 Paxos 协议实现多主复制。
3.2 ShardingSphere 读写分离配置
spring:
shardingsphere:
datasource:
ds-master:
url: jdbc:mysql://192.168.1.10:3306/llm_db
username: root
password: ***
ds-slave-0:
url: jdbc:mysql://192.168.1.11:3306/llm_db
username: root
password: ***
ds-slave-1:
url: jdbc:mysql://192.168.1.12:3306/llm_db
username: root
password: ***
rules:
readwrite-splitting:
data-sources:
prd_ds:
writeDataSourceName: ds-master
readDataSourceNames:
- ds-slave-0
- ds-slave-1
loadBalancerName: round_robin
loadBalancers:
round_robin:
type: ROUND_ROBIN
3.3 分库分表设计
// 按 user_id 分库分表
@ShardingAlgorithm(value = ModShardingAlgorithm.class, props = {
@Property(name = "sharding-count", value = "4")
})
public class UserOrderTable implements ShardingTable {
@Override
public String doSharding(String targetTable, Collection<String> availableTargetTables,
ShardingValue<String> shardingValue) {
String userId = shardingValue.getValue();
int tableIndex = Math.abs(userId.hashCode()) % 4;
return targetTable + "_" + tableIndex;
}
}
// 使用 ShardingSphere-JDBC
try (Connection conn = dataSource.getConnection()) {
PreparedStatement ps = conn.prepareStatement(
"SELECT * FROM chat_history WHERE user_id = ?");
ps.setLong(1, userId);
ResultSet rs = ps.executeQuery();
}
────────────────────────────────────────────────────────────
四、接口限流与排队合并策略
4.1 令牌桶算法实现
令牌桶算法是 API 限流最常用的方案,允许一定程度的突发流量。
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.ReentrantLock;
public class TokenBucketRateLimiter {
private final long capacity; // 桶容量
private final long refillRate; // 每秒补充令牌数
private final AtomicLong tokens;
private final AtomicLong lastRefillTime;
private final ReentrantLock lock = new ReentrantLock();
public TokenBucketRateLimiter(long capacity, long refillRate) {
this.capacity = capacity;
this.refillRate = refillRate;
this.tokens = new AtomicLong(capacity);
this.lastRefillTime = new AtomicLong(System.nanoTime());
}
public boolean tryAcquire() {
lock.lock();
try {
refill();
if (tokens.get() > 0) {
tokens.decrementAndGet();
return true;
}
return false;
} finally {
lock.unlock();
}
}
private void refill() {
long now = System.nanoTime();
long lastTime = lastRefillTime.get();
long elapsed = now - lastTime;
// 计算应该补充的令牌数
long tokensToAdd = (elapsed * refillRate) / 1_000_000_000L;
if (tokensToAdd > 0) {
long newTokens = Math.min(capacity, tokens.get() + tokensToAdd);
tokens.set(newTokens);
lastRefillTime.set(now);
}
}
public long availableTokens() {
refill();
return tokens.get();
}
}
4.2 Redis + Lua 原子限流
@Service
public class RedisRateLimiter {
@Autowired
private StringRedisTemplate redisTemplate;
private static final String RATE_LIMIT_SCRIPT =
"local key = KEYS[1] " +
"local limit = tonumber(ARGV[1]) " +
"local window = tonumber(ARGV[2]) " +
"local current = redis.call('INCR', key) " +
"if current == 1 then redis.call('EXPIRE', key, window) end " +
"return current <= limit and 1 or 0";
public boolean isAllowed(String userId, int limit, int windowSeconds) {
String key = "rate_limit:" + userId;
Long result = redisTemplate.execute(
(RedisCallback<Long>) conn ->
conn.eval(
RATE_LIMIT_SCRIPT.getBytes(),
RedisScript.of(String.class),
Collections.singletonList(key),
String.valueOf(limit),
String.valueOf(windowSeconds)
)
);
return result != null && result == 1L;
}
}
4.3 请求合并策略
对于相同 Prompt 的多个请求,可以合并为一个 LLM 调用,显著降低成本和延迟。
@Service
public class PromptMergingService {
private final ConcurrentHashMap<String, CompletableFuture<String>> pendingRequests = new ConcurrentHashMap<>();
private final ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor();
public CompletableFuture<String> getResponse(String prompt) {
String key = hashPrompt(prompt);
// 检查是否有正在处理的相同请求
CompletableFuture<String> existing = pendingRequests.get(key);
if (existing != null) {
return existing; // 复用进行中的请求
}
// 创建新请求
CompletableFuture<String> future = new CompletableFuture<>();
CompletableFuture<String> existing2 = pendingRequests.putIfAbsent(key, future);
if (existing2 != null) {
return existing2; // 已被其他线程创建
}
// 延迟合并窗口(例如 50ms)
scheduler.schedule(() -> {
pendingRequests.remove(key);
executeAndComplete(key, prompt, future);
}, 50, TimeUnit.MILLISECONDS);
return future;
}
private void executeAndComplete(String key, String prompt, CompletableFuture<String> future) {
try {
String response = llmService.chat(prompt);
future.complete(response);
} catch (Exception e) {
future.completeExceptionally(e);
}
}
private String hashPrompt(String prompt) {
try {
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[] hash = md.digest(prompt.getBytes(StandardCharsets.UTF_8));
return Base64.getEncoder().encodeToString(hash).substring(0, 16);
} catch (NoSuchAlgorithmException e) {
return prompt.hashCode() + "";
}
}
}
────────────────────────────────────────────────────────────
五、异步化与线程池优化
5.1 异步调用设计
大模型 API 调用通常是 IO 密集型操作,异步化可以显著提升系统吞吐量。
@Service
public class AsyncLLMService {
@Async("llmExecutor")
public CompletableFuture<ChatResponse> chatAsync(ChatRequest request) {
return CompletableFuture.supplyAsync(() -> {
try {
return llmService.chat(request);
} catch (Exception e) {
throw new CompletionException(e);
}
});
}
// 批量异步调用
public CompletableFuture<List<ChatResponse>> batchChatAsync(List<ChatRequest> requests) {
List<CompletableFuture<ChatResponse>> futures = requests.stream()
.map(this::chatAsync)
.collect(Collectors.toList());
return CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]))
.thenApply(v -> futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()));
}
}
@Configuration
public class AsyncConfig {
@Bean("llmExecutor")
public Executor llmExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(200);
executor.setKeepAliveSeconds(60);
executor.setThreadNamePrefix("llm-async-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}
5.2 线程池优化策略
核心参数调优原则:
- CPU 密集型任务:核心线程数 = CPU 核心数 + 1,减少上下文切换
- IO 密集型任务:核心线程数 = CPU 核心数 * 2 或更高,充分利用等待时间
- 大模型场景:IO 密集型 + 等待时间长,建议核心线程数设为 2 * CPU 核心数,队列不宜过大
// 动态线程池配置
@Configuration
public class DynamicThreadPoolConfig {
@Value("${llm.thread.core:10}")
private int corePoolSize;
@Value("${llm.thread.max:50}")
private int maxPoolSize;
@Value("${llm.thread.queue:200}")
private int queueCapacity;
@Bean("llmTaskExecutor")
public TaskExecutor llmTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setThreadNamePrefix("llm-");
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.setAwaitTerminationSeconds(60);
// 拒绝策略:使用调用者线程执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}
5.3 CompletableFuture 组合调用
@Service
public class LLMCompositionService {
public ChatResponse chatWithFallback(String prompt, List<String> models) {
// 尝试多个模型,任一成功即返回
List<CompletableFuture<ChatResponse>> futures = models.stream()
.map(model -> tryModel(prompt, model))
.collect(Collectors.toList());
return futures.stream()
.map(CompletableFuture::orTimeout)
.map(f -> f.exceptionally(ex -> ChatResponse.fallback()))
.map(CompletableFuture::join)
.filter(r -> !r.isFallback())
.findFirst()
.orElse(ChatResponse.fallback());
}
private CompletableFuture<ChatResponse> tryModel(String prompt, String model) {
return CompletableFuture.supplyAsync(() -> llmService.chat(prompt, model))
.orTimeout(10, TimeUnit.SECONDS)
.exceptionally(ex -> {
log.warn("Model {} failed: {}", model, ex.getMessage());
return ChatResponse.fallback();
});
}
}
────────────────────────────────────────────────────────────
六、高可用架构设计总结
6.1 整体架构图
┌─────────────────┐
│ 用户请求 │
└────────┬────────┘
│
┌────────▼────────┐
│ API 网关 │
│ (限流/鉴权) │
└────────┬────────┘
│
┌──────────────────────────┼──────────────────────────┐
│ │ │
┌───────▼───────┐ ┌───────▼───────┐ ┌───────▼───────┐
│ Sentinel │ │ Redis │ │ MySQL │
│ (熔断降级) │ │ Cluster │ │ (读写分离) │
└───────────────┘ │ (缓存/会话) │ └───────────────┘
└───────────────┘
│
┌────────▼────────┐
│ LLM 服务集群 │
│ (多模型备选) │
└─────────────────┘
6.2 关键设计要点
熔断降级:配置合理的 RT 阈值和异常比例,避免雪崩扩散。缓存策略:多级缓存 + 合适的过期时间,平衡一致性与性能。读写分离:读操作路由到从库,写操作路由到主库,减轻主库压力。限流排队:令牌桶 + 请求合并,控制并发并提高吞吐量。异步化:充分利用 IO 等待时间,提高资源利用率。
────────────────────────────────────────────────────────────
总结
本文从熔断降级、缓存高可用、数据库读写分离、限流排队、异步优化五个维度,全面讲解了大模型 API 高可用架构与性能优化的核心技术与工程实践。通过合理的架构设计和参数调优,读者可以构建响应迅速、稳定可靠的大模型服务系统,为用户提供流畅的 AI 体验。
附:配套技术图解
图1:Sentinel 熔断降级架构图
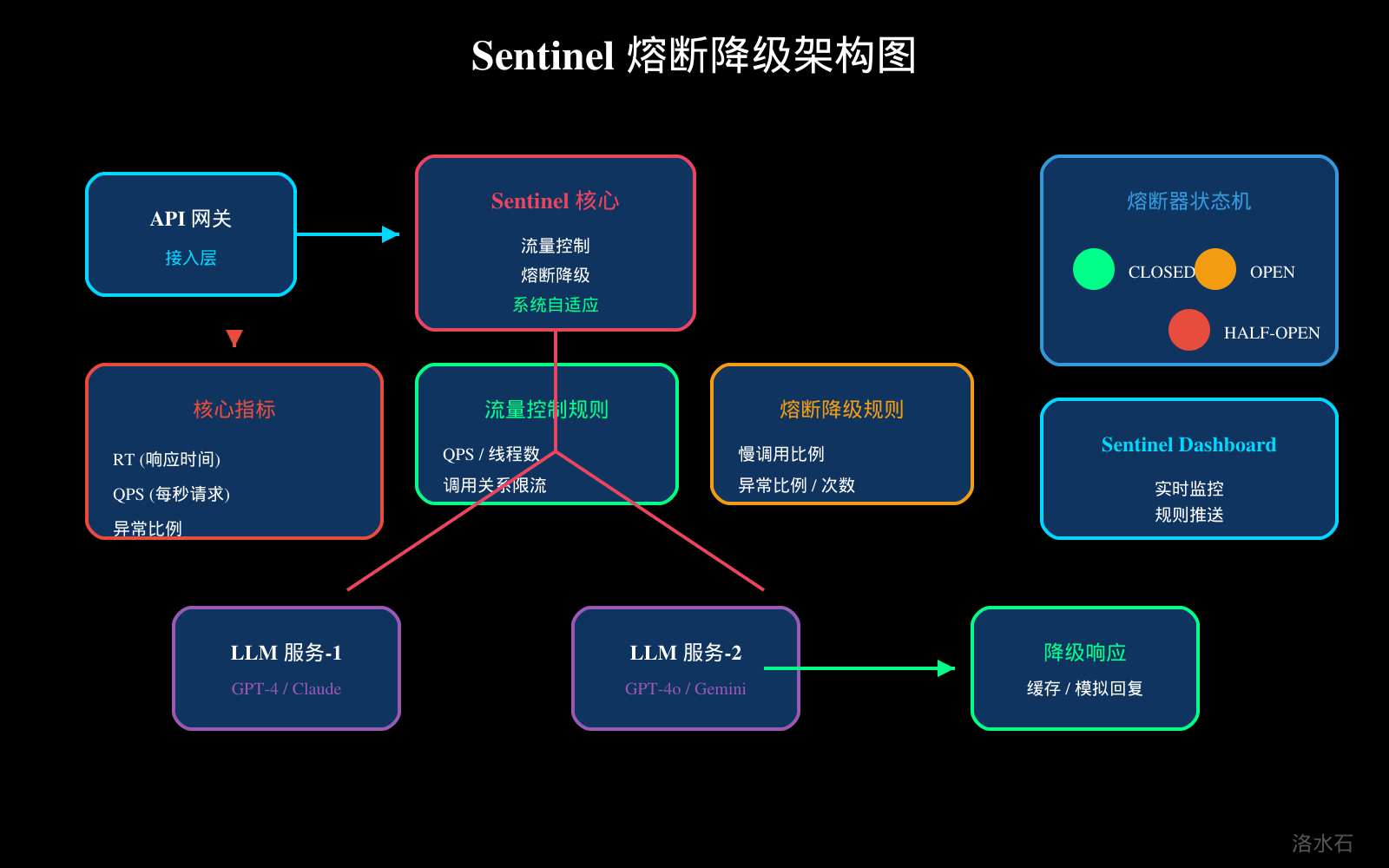
图1:Sentinel 熔断降级与限流架构
图2:Redis 分布式缓存高可用架构图
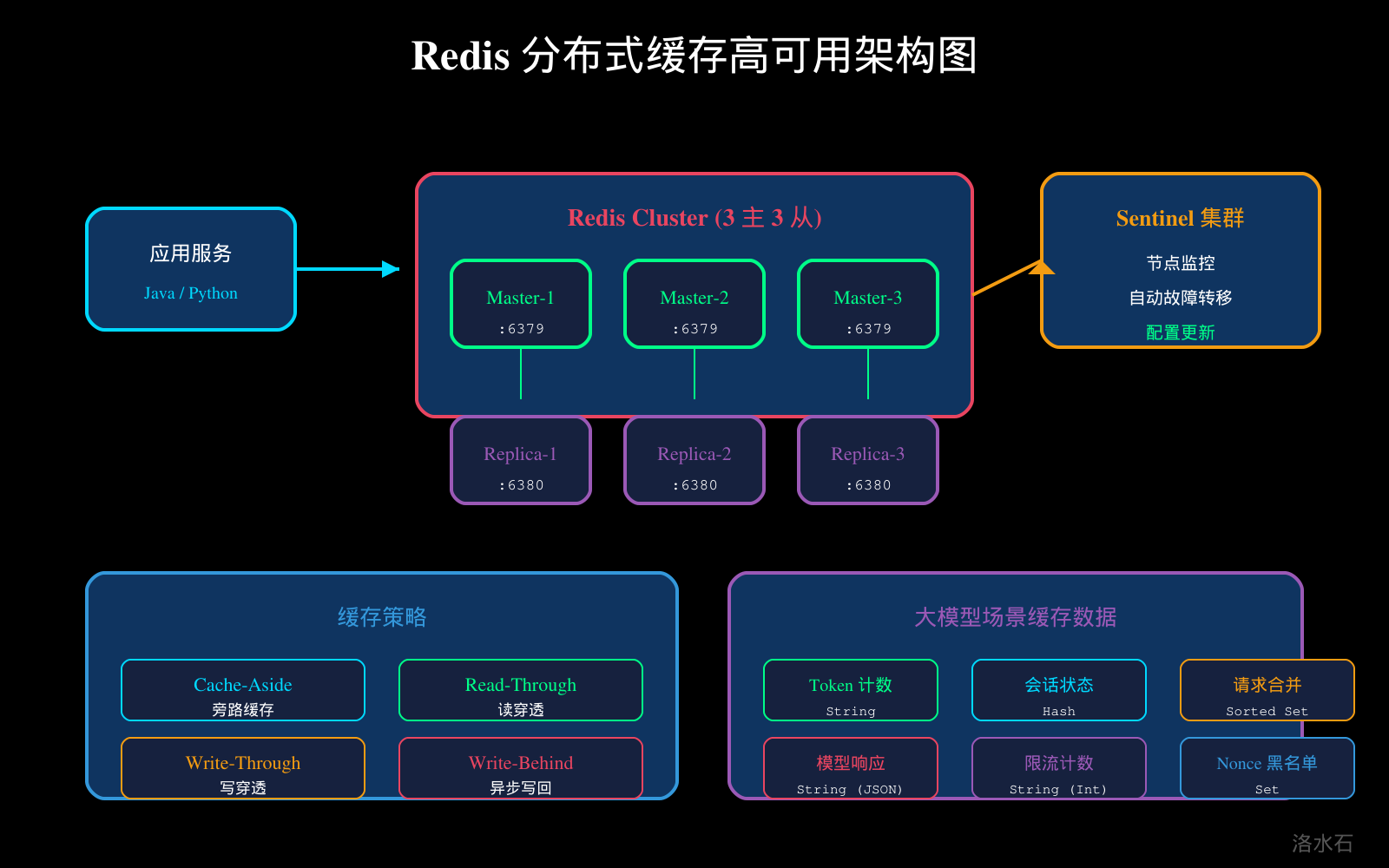
图2:Redis Cluster 高可用与缓存策略架构
图3:MySQL 主从复制架构图
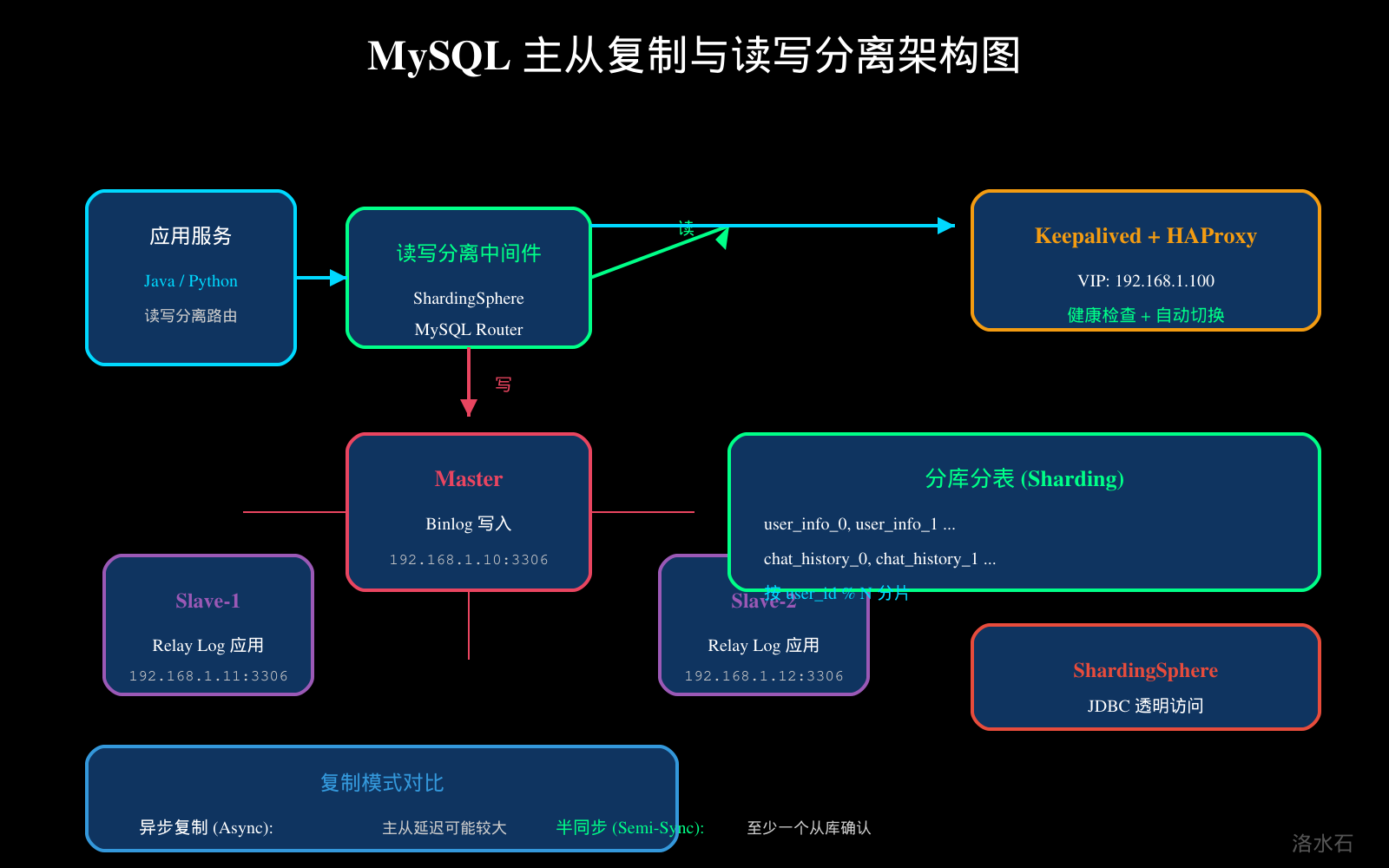
图3:MySQL 主从复制与读写分离架构
图4:接口限流与排队合并策略图
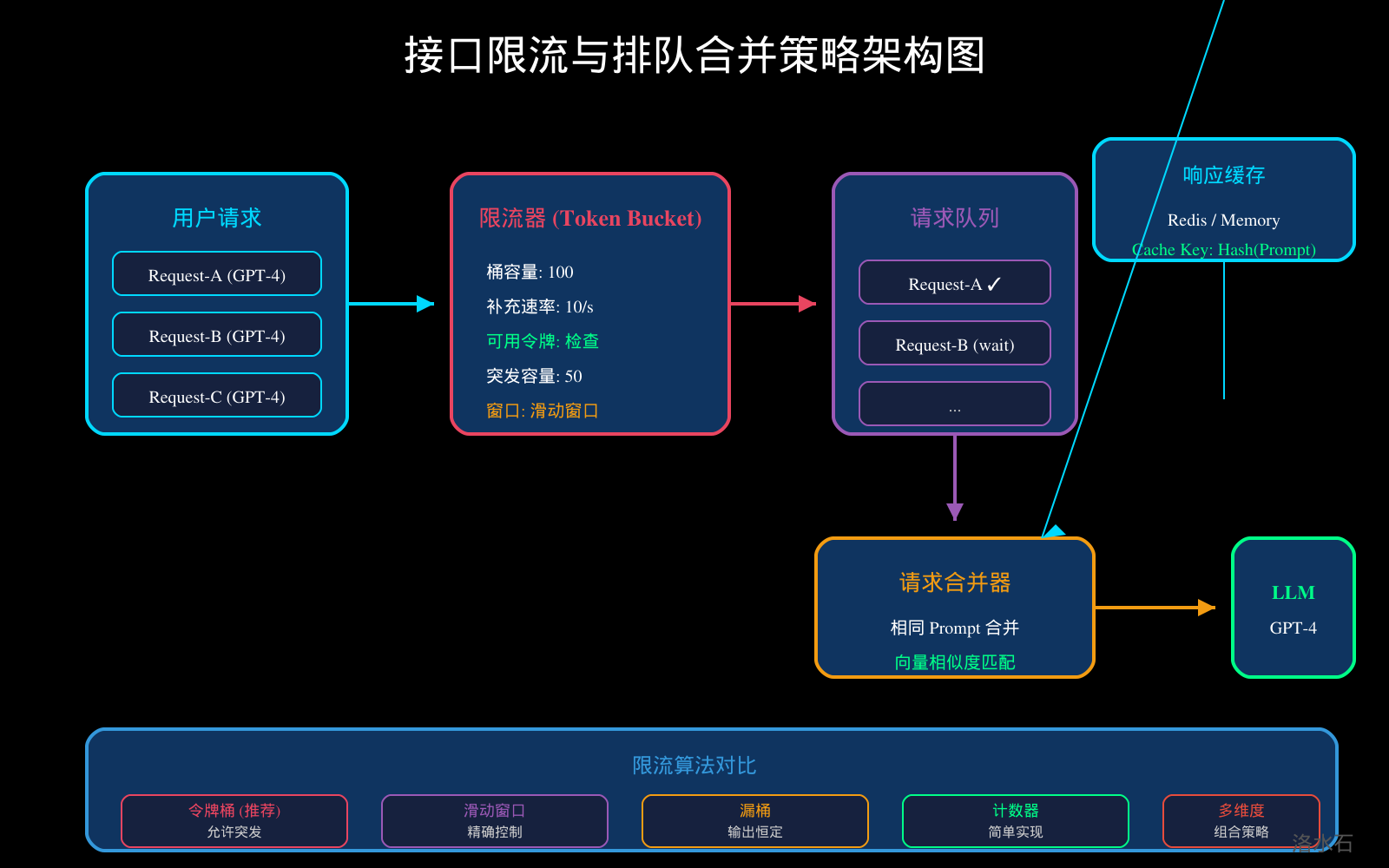
图4:限流算法与请求合并策略架构
更多推荐
 6
6 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)