
K8s Prometheus,针对Java的完美监控方案
K8s Prometheus,针对 Java 的完美监控方案
GC 停顿导致接口超时,排查时发现 JVM 老年代占用率飙到 90%——如果你的 Java 应用在 K8s 上是个"黑盒",再大的集群也算力浪费。本文用完整实战,让你的 JVM 指标在 Grafana 里一览无余。
一、一个 GC 卡顿,查了三天
“应用又超时了。”
凌晨两点,值班手机响了。监控图显示:接口 P99 延迟从 50ms 跳到了 3 秒,持续了整整两分钟,然后又恢复了。
老李查了三天,翻遍了日志、看了 CPU、查了网络,什么都没发现。最后有人提醒了一句:看一眼 GC 日志。
结果发现,Full GC 停了 2.1 秒。再深挖,每次 G1 垃圾回收老年代占用率飙升到 98% 时,就会触发一次大停顿。
问题找到了,但更扎心的是——为什么这些 JVM 指标,没有人提前看到?
这就是 Java 应用在 K8s 上的典型困境:CPU 和内存看得见,堆内存、GC 次数、线程数全是盲区。
二、Java 监控的本质:看穿 JVM
要让 Java 应用被完美监控,核心是解决一个矛盾:
JVM 的运行时状态,藏在 JMX(Java Management Extensions)里。Prometheus 不认识 JMX,它只认 /metrics 端点。
这就需要一个"翻译官"——把 JMX 的 MBean 数据,转换成 Prometheus 的指标格式。
2.1 两种主流方案对比
| 方案 | 原理 | 侵入性 | JVM 指标 | 业务指标 | 推荐场景 |
|---|---|---|---|---|---|
| client_java | SDK 直接暴露指标 | 需要改代码 | ✅ 开箱即用 | ✅ 可自定义 | Spring Boot/新项目(首选) |
| JMX Exporter | Java Agent 无侵入 | 不改代码 | ✅ 完整暴露 | ❌ 受限 | 老应用/无法改代码 |
选型结论:能改代码用
client_java(Micrometer),不能改代码用 JMX Exporter。混着用也行,不冲突。
2.2 JVM 指标清单
打通之后,能拿到哪些核心指标?
| 分类 | 关键指标 | 什么情况该报警 |
|---|---|---|
| 堆内存 | jvm_memory_bytes_used / _max |
老年代占用率 > 85%,连续 3 个采集周期 |
| GC | jvm_gc_pause_seconds(耗时)/ jvm_gc_pause_seconds_count(次数) |
Full GC 耗时 > 1s,或 1 分钟内 Full GC 超过 3 次 |
| 线程 | jvm_threads_live_threads / jvm_threads_peak |
线程数超过阈值,或线程数持续增长不回落 |
| 类加载 | jvm_classes_loaded |
类加载数异常增长(内存泄漏征兆) |
| CPU/内存 | system_cpu_usage / jvm_memory_* |
容器 CPU 限流率过高 |
三、整体架构图
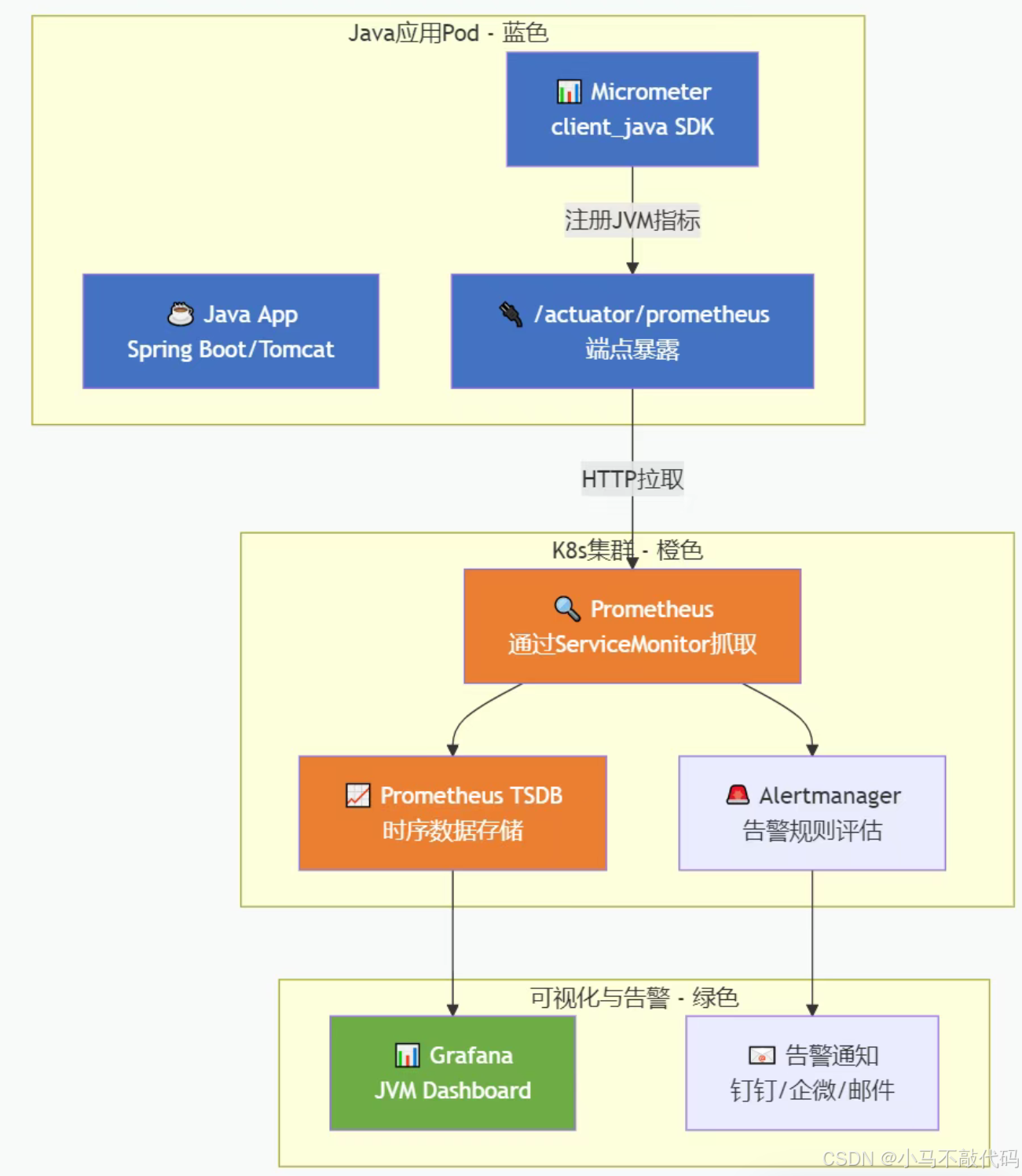
- 蓝色:Java 应用层——代码里用 Micrometer 注册 JVM 指标,暴露 HTTP 端点
- 橙色:Prometheus 层——通过 K8s 服务发现自动抓取
- 绿色:展示层——Grafana 大盘展示,告警通知触达
四、实战:Spring Boot 应用完美接入
4.1 第一步:添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
就这两行,Spring Boot 会自动配置好 /actuator/prometheus 端点。
4.2 第二步:开启端点暴露
# application.properties
management.endpoints.web.exposure.include=health,info,prometheus
management.endpoint.prometheus.enabled=true
management.metrics.export.prometheus.enabled=true
如果想看更详细的线程和内存数据,加两行配置:
management.metrics.enable.process.files=true
management.metrics.enable.process.uptime=true
4.3 第三步:本地验证
# 启动应用后,访问端点
curl http://localhost:8080/actuator/prometheus | head -30
返回的数据应该包含以下 JVM 指标开头的内容:
jvm_memory_used_bytes
jvm_gc_pause_seconds
jvm_threads_live_threads
有这些,就说明暴露成功了。
4.4 第四步:打包镜像并部署到 K8s
Dockerfile:
FROM openjdk:17-jdk-slim
COPY target/*.jar app.jar
ENTRYPOINT ["java", "-jar", "/app.jar"]
K8s Deployment(关键:加注解):
apiVersion: apps/v1
kind: Deployment
metadata:
name: java-app
spec:
template:
metadata:
annotations:
prometheus.io/scrape: "true" # Prometheus 来抓我
prometheus.io/path: "/actuator/prometheus"
prometheus.io/port: "8080"
labels:
app: java-app
spec:
containers:
- name: app
image: harbor.internal/java-app:latest
ports:
- containerPort: 8080
name: http
这三行 prometheus.io 注解是核心——告诉 Prometheus:“我的指标在 8080 端口的 /actuator/prometheus 路径上”。
4.5 第五步:配置 Prometheus 采集(ServiceMonitor)
如果使用 Prometheus Operator,创建一个 ServiceMonitor:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: java-app-monitor
spec:
selector:
matchLabels:
app: java-app # 和 Deployment 的标签对齐
endpoints:
- port: http # 对应 Service 的端口名
path: /actuator/prometheus
interval: 15s
namespaceSelector:
matchNames:
- default
创建后,Prometheus 会自动发现这个应用并开始抓取。
4.6 第六步:Grafana 导入 JVM 监控面板
Grafana 官方社区有现成的 JVM 仪表盘,ID 是 4701 或 8563:
登录 Grafana → 左侧 + 号 → Import
输入 Dashboard ID:8563(JVM 仪表盘)
选择 Prometheus 数据源
点击 Import
能看到堆内存占用趋势、GC 耗时分布、线程数变化——排查性能问题从"猜"变成了"看"。
五、Prometheus 监控图解读(实战场景)
当应用稳定运行后,你会看到这样几个关键监控图:
5.1 堆内存监控图
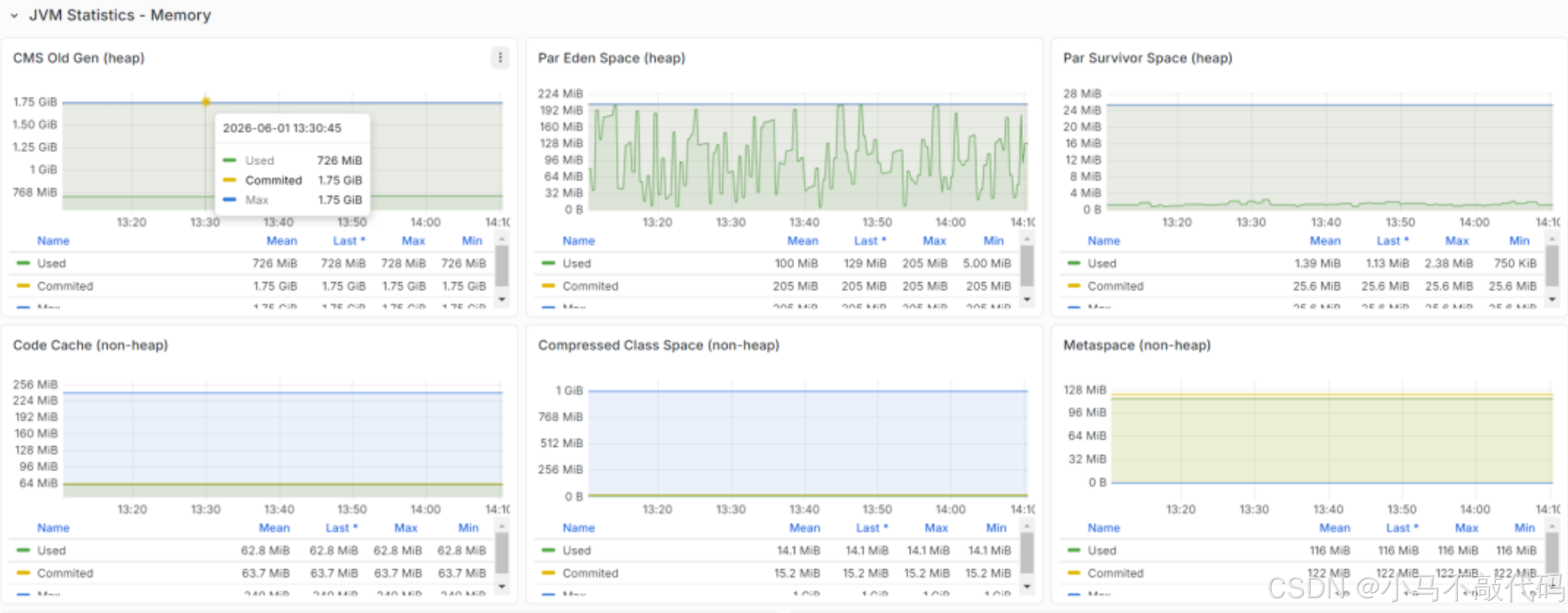
- 正常模式:锯齿状,每次 GC 后内存回落
- 危险信号:锯齿底部越来越高,说明有内存泄漏
5.2 GC 耗时监控图
报警阈值:Full GC 暂停超过 1 秒,或一分钟内 Young GC 次数超过 10 次。
5.3 线程数监控图
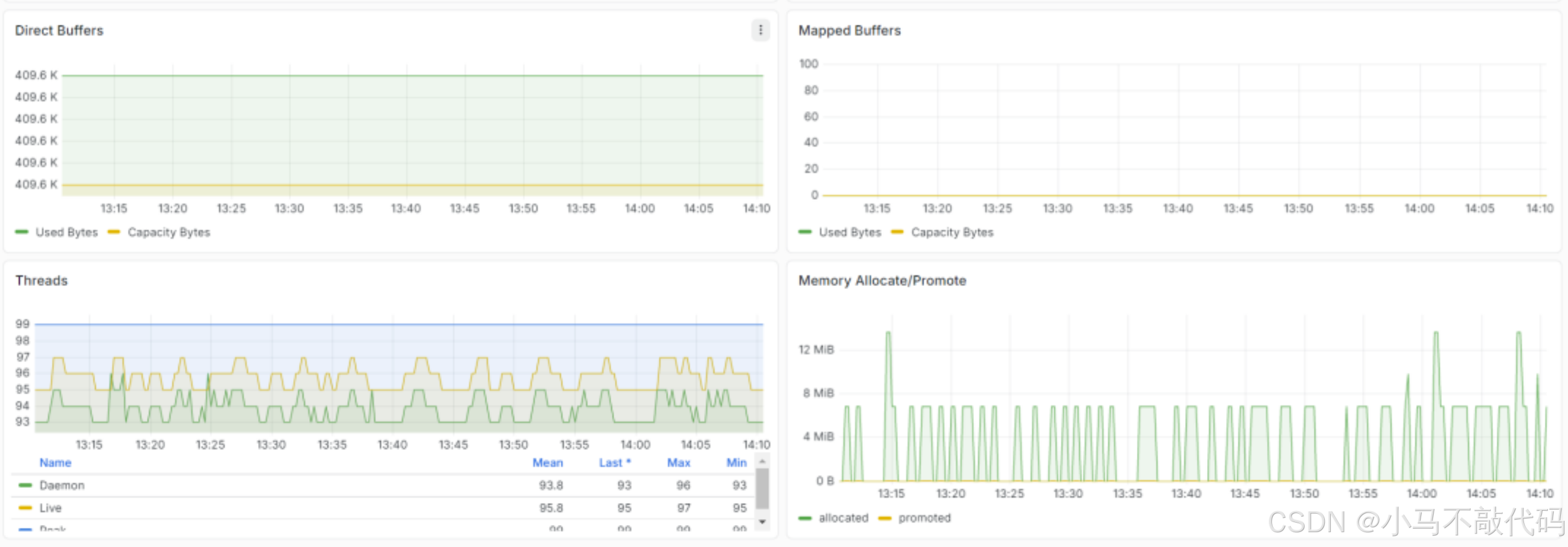
危险信号:线程数阶梯式持续增长不回落,大概率线程泄漏。
六、告警规则配置
有了指标,就要配告警。Prometheus 告警规则如下:
groups:
- name: jvm-alerts
rules:
# 老年代占用超 85%,持续 5 分钟
- alert: JVM_OldGenHighUsage
expr: (sum(jvm_memory_bytes_used{area="heap"}) / sum(jvm_memory_bytes_max{area="heap"})) > 0.85
for: 5m
annotations:
summary: "老年代占用率 {{ $value | humanizePercentage }}"
# Full GC 耗时超 1 秒
- alert: JVM_FullGCLongPause
expr: histogram_quantile(0.95, jvm_gc_pause_seconds_bucket{action="end of major GC"}) > 1
for: 1m
annotations:
summary: "Full GC 暂停 {{ $value }}秒"
# 线程数超阈值
- alert: JVM_HighThreadCount
expr: jvm_threads_live_threads > 500
for: 10m
annotations:
summary: "线程数 {{ $value }},超过阈值 500"
# 容器 CPU 限流(重要!避免 Java 踩坑)
- alert: Container_CPU_Throttling
expr: rate(container_cpu_cfs_throttled_seconds_total[5m]) > 0.5
annotations:
summary: "Pod 被 CPU 限流,考虑调整 Requests/Limits"
最后一条告警对 Java 特别重要。很多 Java 应用在容器里"感觉慢",其实是被 Cgroup 限流了,而 JVM 默认不感知容器的 CPU 限制,需要用
-XX:ActiveProcessorCount或升级 JDK 版本解决。
七、老项目怎么办?JMX Exporter 无侵入方案
如果你的 Java 应用是老项目,不方便加依赖改代码,可以用 JMX Exporter 以 Java Agent 方式运行。
Dockerfile:
FROM openjdk:8-jdk
# 下载 JMX Exporter
ADD https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/1.0.1/jmx_prometheus_javaagent-1.0.1.jar /agent.jar
# 配置文件(最简单的配置:暴露所有指标)
ADD jmx-config.yaml /jmx-config.yaml
# 启动时挂载 agent
ENTRYPOINT ["java", "-javaagent:/agent.jar=8088:/jmx-config.yaml", "-jar", "app.jar"]
jmx-config.yaml:
rules:
- pattern: ".*"
这样完全不用改代码,应用启动时自动挂载 agent,暴露 /metrics 端口。
八、总结
K8s 上监控 Java 应用,核心就是一句话:让 JVM"开口说话",让 Prometheus"听得懂"。
- Micrometer 方案:2 行依赖 + 2 行配置 + Grafana 导入面板,Java 新项目的监控标配
- JMX Exporter 方案:不改代码,加个 agent 就搞定,老项目的救命稻草
这三类指标必须监控:
- 堆内存占用率(防 OOM)
- GC 暂停时间(防接口超时)
- 线程数(防线程泄漏)
那个 GC 卡顿查了三天的故事,后续是:
监控配好之后,团队发现——老年代占用率 85% 时就会触发一次 Full GC。他们简单调整了 JVM 参数,把堆内存从 2GB 升到 3GB,GC 停顿就消失了。如果有监控,这个问题早在两周前就会被发现和拦截。
这就是完美监控的意义——不是出了问题能快速定位,而是问题发生之前,你已经知道了。
更多推荐
 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)