
Java 转大模型开发:把学习路线变成作品集
聊《Java 转大模型开发:把学习路线变成作品集》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
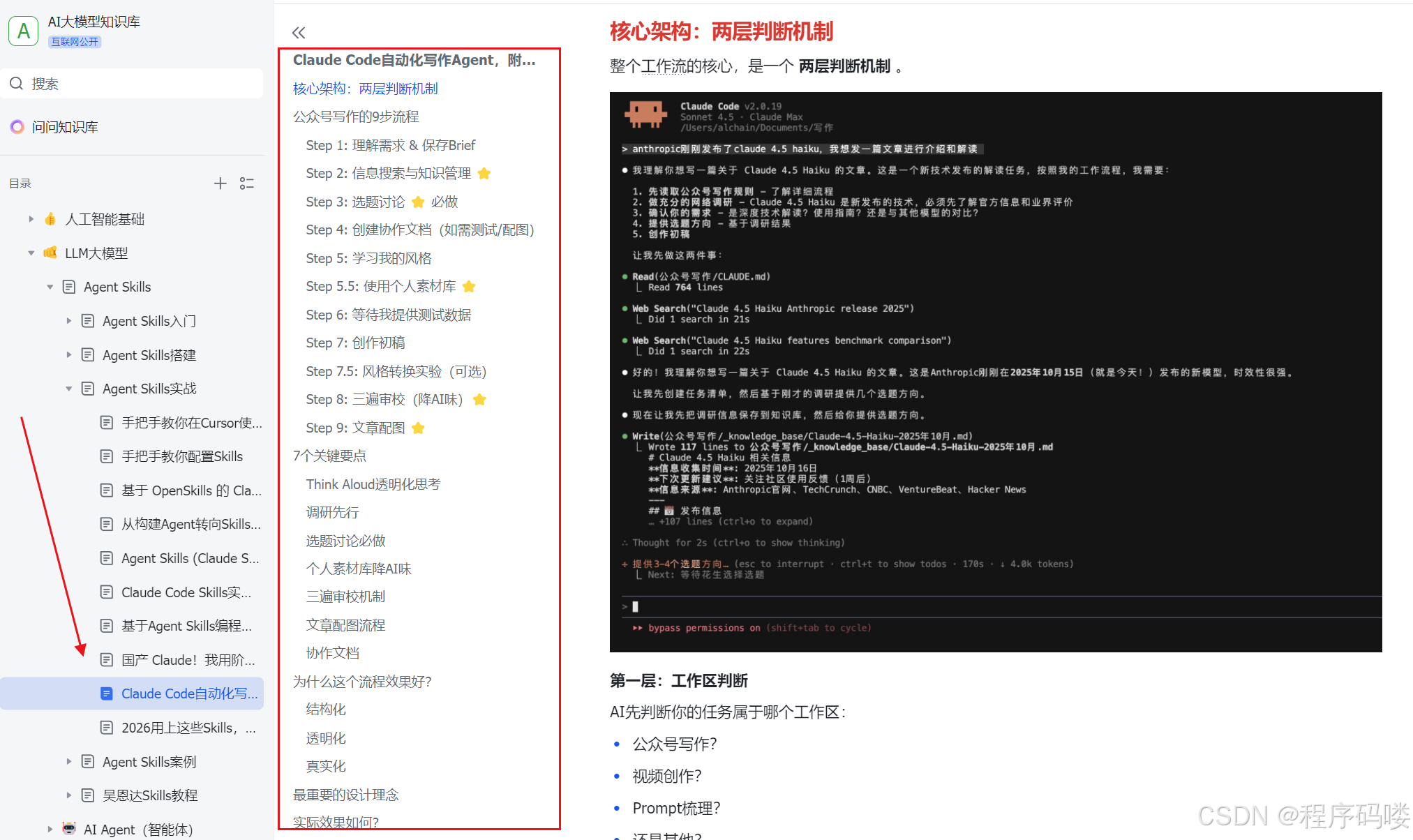
最近后台收到不少私信,问得最多的就是:“我是做了五年 Java 后端的,现在大模型这么火,我该怎么转?是不是要去啃深度学习数学?”
我的回答通常只有一句:别去卷算法底层,去做应用层。
对于 Java 开发者来说,最大的误区就是把“大模型开发”等同于“训练模型”。事实上,目前企业里 90% 的需求都是基于现有 API 做应用集成、RAG(检索增强生成)或者 Agent 编排。你不需要懂反向传播,你需要的是如何把 LLM 变成一个稳定、可控、能处理复杂业务逻辑的软件组件。
这篇文章不谈虚的概念,直接聊聊怎么把你的 Java 工程能力迁移到大模型领域,并把这些学习过程包装成面试官一眼就能看懂的作品集。
目录
- Java 开发者的优势:被低估的工程壁垒
- 需要补齐的 AI 技能:从 API 调用到思维转变
- Spring AI 与 LangChain4j:选哪个?
- 项目练习:打造可展示的作品集
- 面试准备:如何讲述你的转型故事
- 总结
Java 开发者的优势:被低估的工程壁垒
很多转行的朋友容易陷入“技术自卑”,觉得自己是半路出家。其实,大模型应用开发目前最大的痛点不是“模型不够聪明”,而是“系统不够稳定”。
LLM 的输出具有概率性,这意味着你的应用必须处理幻觉、超时、并发控制和数据一致性。这些恰恰是 Java 后端开发者的强项:
1. 类型安全与工程规范:Python 脚本虽然灵活,但在大型微服务架构中,Java 的强类型检查和成熟的框架生态(如 Spring Boot)能保证系统的可维护性。
2. 高并发处理:大模型推理往往耗时较长,如何在不阻塞主线程的情况下处理大量用户请求,Java 的异步编程(WebFlux 或 CompletableFuture)有着天然优势。
3. 生态系统:Spring 社区正在快速跟进 AI 集成,这意味着你可以用熟悉的开发模式去接入新能力。
所以,不要试图去和搞 NLP 的博士比数学,你要比的是谁能把 LLM 更稳地嵌入到企业级业务流中。
需要补齐的 AI 技能:从 API 调用到思维转变
从 Java 转到 LLM 开发,技能树的变化主要集中在以下三点,按优先级排序:
1. Prompt Engineering 的结构化思维
以前写 SQL 或配置规则引擎,现在写 Prompt。这不是简单的聊天,而是逻辑指令。你需要学会如何定义 System Message 来约束输出格式,如何处理 Few-shot 示例来提高准确率。
2. RAG 基础架构
这是目前 B 端落地最成熟的场景。你需要理解向量数据库(Vector DB)的工作原理。Key Concepts 包括:Embedding 模型的选择、Chunking 策略(切片大小对语义完整性的影响)、以及 Hybrid Search(关键词+向量混合检索)。
3. 评估与监控
传统后端看日志,LLM 应用看“效果”。你需要知道如何评估生成的答案质量(是否引用了错误源文?是否遵循了指令?)。工具链上,LangSmith 或 Arize Phoenix 是常用的观察平台。

Spring AI 与 LangChain4j:选哪个?
作为 Java 开发者,生态选择至关重要。目前主要两个选择:LangChain4j 和 Spring AI。
- LangChain4j:社区活跃,API 设计贴近 Python 版 LangChain,功能更新快,支持的功能点(如 ChatMemory, Tool Calling)非常多。
- Spring AI:Spring 官方出品,理念是“让 AI 成为 Spring 的一等公民”。它抽象了各种厂商的接口,如果你深度使用 Spring Cloud 全家桶,Spring AI 的集成会更无缝,且更符合 Java 的 Bean 管理习惯。
个人建议:如果你已经在用 Spring Boot,优先看 Spring AI。它的 ChatClient 设计非常优雅,且与 Spring 的其他模块(如 Security, Data)结合得很好。
这里展示一下使用 Spring AI 进行简单对话的代码结构,感受一下它是如何融入传统 Java 开发的:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class AIController {
@Autowired
private ChatClient chatClient;
@GetMapping("/ask")
public String ask(@RequestParam String question) {
// 利用 Spring AI 的 DSL 风格构建请求
return chatClient.prompt()
.user(question)
.system("你是一个专业的 Java 技术顾问,请用简洁的代码片段回答。")
.call().content();
}
}可以看到,这和写一个普通的 REST 接口没有任何本质区别,只是在中间加了一层 AI 的处理逻辑。
项目练习:打造可展示的作品集
简历上写“熟悉 RAG”是没用的,你需要一个拿得出手的项目。我建议做一个 “企业内部知识库助手” 的 Mini 版。
这个项目看似简单,但能涵盖你 80% 的面试考点。具体实施时,请按以下步骤拆解,并将每个步骤的成果单独提交到 GitHub:
1. 文档解析模块:实现一个 Service,读取 PDF/Markdown,使用 Apache PDFBox 或 LangChain4j 的 Document Loader 进行切分。亮点:展示你对非结构化数据处理的能力。
2. 向量化存储:接入 Milvus 或 pgvector。编写单元测试,证明你能正确地将文本转化为向量并存入数据库。亮点:展示对向量索引的理解。
3. 检索增强链路:实现一个 Query Rewriter(查询重写),将用户的口语化提问转换为更适合检索的关键词,然后进行混合检索。亮点:这是解决 RAG 召回率低的核心技巧。
4. 结果组装与渲染:将检索到的片段作为 Context 喂给 LLM,并要求 LLM 标注引用来源。亮点:展示你对幻觉抑制的实践。
避坑指南:不要试图从头写一个完整的 UI。用 Swagger 或 Postman 调通接口,重点展示后端逻辑的健壮性。如果在面试中能演示出“当检索内容不足时,系统如何优雅地回答‘不知道’而不是胡编乱造”,这比单纯的高准确率更有价值。
面试准备:如何讲述你的转型故事
面试时,面试官可能会问:“你为什么从 Java 转行?你觉得你的劣势是什么?”
错误回答:“我觉得 Java 没前途,大模型是风口。”
推荐回答:“我发现自己在后端工程中,越来越频繁地遇到需要处理非结构化数据和复杂逻辑推理的场景。Java 的传统范式在处理这些需求时显得笨重。我主动学习了 Spring AI 和 RAG 架构,发现我的工程化能力可以很好地弥补 AI 应用落地时的稳定性短板。我想成为一名专注于 AI 工程化落地的后端工程师。”
在自我介绍中,务必强调你的 “工程化视角”:
- 你关注延迟优化(如异步流式输出)。
- 你关注成本控制(如缓存常用 Embedding)。
- 你关注安全性(如 Prompt Injection 防护)。
这些都是纯算法背景候选人容易忽略,而业务方极度看重的点。
总结
Java 转大模型开发,不是推翻重来,而是技能树的延伸。你的核心竞争力在于如何用软件工程的方法论,去驯服一个不确定的 AI 模型。
现在的市场不缺会调 API 的人,缺的是能把 AI 能力做成稳定、可观测、低成本的服务的工程专家。把你在学习过程中写的每一个 Demo、解决的每一个 Bug、优化的每一次检索,都变成 Git 上的 Commit 和文档。
这就是最好的作品集。开始动手吧,别等到“准备好”了再出发,大模型的应用场景迭代速度,比你想象的更快。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。

如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。

更多推荐
 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)