
Python爬虫实战:手撸一个去哪儿网景点采集工具,含断点续爬+MySQL入库,代码开源
阿弥陀佛,贫僧法号“重启试试”,专治各种“没数据可用”的疑难杂症。
前阵子在做旅游网站数据分析系统,最头疼的就是——没数据。
景点名称、英文名、评分、攻略数、评论数、经纬度……这些东西网上都有,但要一条条复制,手动得干到天黑。
于是写了个小爬虫,专门从去哪儿网抓景点数据,跑了几天,效果还行。
今天把代码开源出来,有需要的施主自取。
声明:代码仅供学习参考,请勿大规模爬取或商用,尊重网站 robots.txt 协议。爬虫有风险,操作需谨慎。
一、这个爬虫能爬什么?
| 字段 | 说明 |
|---|---|
| cn_tit | 景点中文名 |
| en_tit | 景点英文名 |
| lat / lng | 经纬度坐标 |
| strategy_sum | 攻略数量 |
| comment_sum | 评论数量 |
| ranking_sum | 景点排名 |
| total_star | 评分(百分比) |
| desbox | 景点简介 |
| href | 详情页链接 |
| src | 封面图链接 |
爬下来的数据长这样:
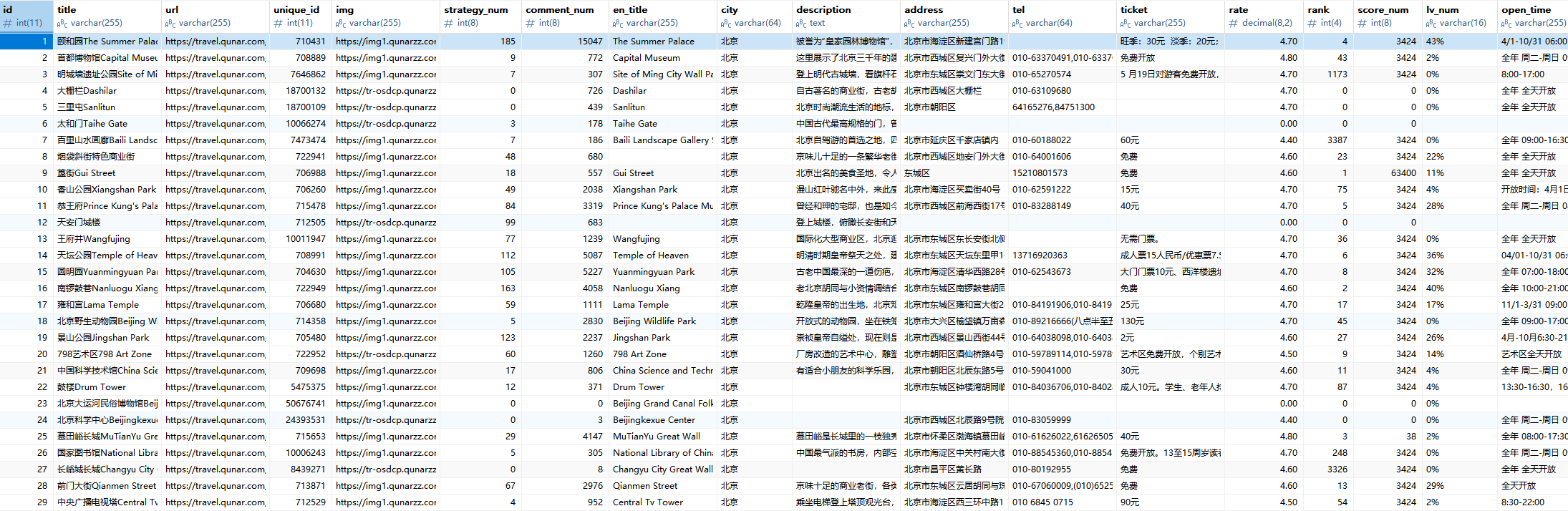
数据量看你自己需求,爬几百条够分析用,爬几千条也能撑起一个推荐系统。
二、核心代码讲解
整个爬虫分为三个核心模块:获取城市链接 → 爬取景点列表 → 数据清洗与存储。贫僧拆开来给施主们看看。
1. 获取城市目的地链接
去哪儿网每个城市都有一个独立的目的地页面,先拿到这个入口,后面才能爬景点。
def get_place_url(search_word):
url_search = 'https://travel.qunar.com/place/'
req = requests.get(url_search, headers=headers)
soup = BeautifulSoup(req.text, 'lxml')
url_place = soup.find('div', class_="contbox current").find_all('li')
dict_place = {}
for i in url_place:
dict_place[i.text] = i.find('a')['href']
place_url = dict_place[search_word]
return place_url
核心逻辑:解析首页的城市列表,把城市名和对应的 URL 路径做成字典,传入城市名就能拿到该城市的景点列表页入口。
2. 爬取景点列表 + 字段提取
拿到城市入口后,拼接分页 URL,逐页爬取景点数据。
def spider_sights(page_num, search_word):
place_url = get_place_url(search_word)
temp_list = place_url + '-jingdian-1-'
place_sights_list = []
for i in range(page_num, page_num + 3):
place_sights_list.append(temp_list + str(i))
sights_data = []
for url in place_sights_list:
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml').find('ul', class_="list_item clrfix").find_all('li')
for i in soup:
data = {}
data['lat'] = i['data-lat']
data['lng'] = i['data-lng']
data['cn_tit'] = i.find('span', class_="cn_tit").text
data['en_tit'] = i.find('span', class_="en_tit").text
data['strategy_sum'] = i.find('div', class_="strategy_sum").text
data['comment_sum'] = i.find('div', class_="comment_sum").text
data['ranking_sum'] = i.find('span', class_="ranking_sum").text
data['total_star'] = i.find('span', class_="total_star").find('span')['style'].split(':')[1]
data['href'] = i.find('a')['href']
data['src'] = i.find('img')['src']
sights_data.append(data)
return pd.DataFrame(sights_data)
关键点:景点评分 total_star 存在 CSS 的 style 属性里(width: 80% 表示 80 分),需要用 split(':')[1] 截取出来,这一步处理不好很容易报错。
3. 数据清洗 + 写入
爬下来的数据不能直接用,需要做字段筛选、重命名、类型转换,然后写入 CSV 或数据库。
def data_process(result, columns_key, columns_rename):
columns_key = eval(columns_key)
columns_rename = eval(columns_rename)
df = pd.DataFrame(columns=columns_key)
result = pd.concat([df, result])
result = result[columns_key][:line_num]
result.columns = columns_rename
result = result.astype(str)
# 写入 CSV(追加模式)
if output_csv:
if os.path.exists('./sights_info.csv'):
result.to_csv('./sights_info.csv', header=False, index=True, encoding="utf-8", mode='a')
else:
result.to_csv('./sights_info.csv', header=True, index=True, encoding="utf-8")
# 写入数据库
if write_database:
engine = create_engine('mysql+pymysql://{0}:{1}@{2}:{3}/{4}'.format(
user, password, host, port, database))
pd.io.sql.to_sql(result, table_name, engine, if_exists='append', index=False)
数据清洗是爬虫最重要的一环。去哪儿网的字段命名比较乱,比如 strategy_sum 存的是“攻略数”,comment_sum 存的是“评论数”,拿到后要自己做映射和重命名。
三、几个实用设计
1. 增量爬取 + 断点续爬
每次爬完会记录城市和已爬页数,存到 cache_data.pkl 里。下次再爬同一个城市,自动从断点继续,不用从头开始。
if not os.path.exists("./cache_data.pkl"):
with open("./cache_data.pkl", "wb") as f:
pickle.dump({}, f)
with open("./cache_data.pkl", "rb") as f:
flag_result = pickle.load(f)
if search_word in flag_result:
page_num = flag_result[search_word]
else:
page_num = 1
爬完后更新页数
flag_result[search_word] = page_num + 1
with open("./cache_data.pkl", "wb") as f:
pickle.dump(flag_result, f, 0)
这样即使爬到一半中断了,重新运行也会接着爬,不用重新开始。
2. 随机城市 + Cookie 配置
每次请求时,如果不指定城市,程序会从城市列表里随机选一个,分散请求,降低被封的概率。
if request.args.get('search_word') and request.args.get('search_word') != '':
search_word = request.args.get('search_word')
else:
search_word = random.choice([
'北京', '上海', '重庆', '天津', '厦门', '福州',
'漳州', '泉州', '龙岩', '三明', '南平', '宁德',
'莆田', '杭州', '宁波', '嘉兴'
])
Cookie 单独放在 cookie_config.py 中管理,方便失效后替换,不用改主程序。
3. Flask 接口封装
爬虫通过 Flask 框架封装成了 HTTP 接口,支持通过 GET 请求触发。
@app.route('/spider', methods=['post', 'get'])
def fun():
# 爬虫主逻辑
return api_return + ' ' + time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
调用方式:
http://127.0.0.1:5001/spider?search_word=北京
四、完整源码获取
源码已打包,包含:
spider.py—— 爬虫主程序cookie_config.py—— Cookie 配置文件config.ini—— 数据库和运行参数配置requirements.txt—— 依赖库清单
获取方式:
- 点赞 👍、收藏 ⭐、评论 “想要景点爬虫”
- 私信贫僧,发送“景点爬虫”
贫僧看到后会第一时间回复!
五、说两句大实话
爬虫这东西,写起来不难,但跑起来全是坑:
- 人家网站改版了,CSS 类名一变,你代码就废了
- Cookie 过期了,请求直接 403
- 爬太快,IP 被封了
所以这个代码只是给你一个能跑的起点。真要长期用,还得自己维护。
但做个毕设、跑个 demo、攒点数据做分析,够用了。
数据是推荐系统的燃料。没有数据,算法再好也跑不起来。
阿弥陀佛,数据能爬就行 🙏
贫僧的 CSDN 签名:
全栈和尚 · 毕设辅导请私信 · 阿弥陀佛,代码能跑就行 🙏
本文发布于 CSDN,代码仅供学习参考,请勿用于商业用途或大规模爬取。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)