
为什么我要用 C# 构建数据库引擎
反对 C# 的理由(让我们直面它吧)
在我阐述理由之前,让我诚实地列出所有反对选择 C# 的理由。这些是现实存在的担忧,而非“稻草人”谬论。
- GC 是非确定性的:它可以在任何时候暂停你的所有线程。对于一个承诺微秒级延迟的数据库引擎来说,一次 10 毫秒的 Gen2(第 2 代)回收是灾难性的——这超出了你延迟预算的 10,000 倍。
- 你无法控制内存布局:托管堆决定了对象的存放位置。GC 可以在压缩过程中移动它们。你无法保证 B+ 树节点位于缓存行边界上,也无法保证你的页面缓存缓冲区不会在事务中途被重新定位。
- JIT(即时编译)预热是真实存在的:对任何方法的第一次调用都要支付编译成本。在数据库引擎中,启动后的第一个事务不应该比稳定状态慢 100 倍。
- 虚函数分发和边界检查会增加开销:每次数组访问都有隐藏的边界检查。每次接口调用都要经过虚函数表(vtable)。在处理数百万实体的热点循环中,这些纳秒级的开销会不断累积。
这些都是合理的问题。我不会假装它们不存在。但这就是大多数人忽略的一点:现代 C# 对每一个问题都有对应的解决方案。
大多数人不知道的 C# 另一面
很多开发者熟悉的 C# 是类、垃圾回收和 LINQ。但这只是语言的一半。.NET Runtime 团队在过去十年里逐步建立了另一面能力,而这部分看起来和许多人想象中的 C# 很不一样。
unsafe 提供接近 C 级别的控制:原始指针、指针运算、栈上缓冲区的 stackalloc、固定大小数组等。JIT 可以生成与 C 中相同类型的底层指令。
GCHandle.Alloc(Pinned) 可以让 GC 在关键位置变得不再相关。开发者可以固定字节数组,让 GC 不移动它们。Typhon 的整个页缓存都是固定内存;GC 不触碰、不扫描、不移动它。对引擎核心而言,它就是一个固定地址上的原始字节区。
ref struct 可以消除热路径上的堆分配。ref struct 不能逃逸到堆,只能存在于栈上,并在作用域结束时消失。Typhon 的实体访问器 EntityRef 是一个 96 字节的 ref struct,目标是零分配、零 GC 压力。
受约束泛型可以提供真正的单态化(Monomorphization)。当代码写成 where T : unmanaged 时,JIT 能为每个类型参数生成单独的原生代码路径。sizeof(T) 会成为常量,无用分支会被消除。这接近 Rust 泛型带来的优化效果:不是运行时分派,而是编译期专门化。
硬件原语(Hardware intrinsics)是一等公民。System.Runtime.Intrinsics 提供 Vector256、Sse42.Crc32、BitOperations.TrailingZeroCount 等能力。它们对应 C/C++ 中可用的 SIMD 指令,并且带有运行时特性检测,可以在不支持相关指令的平台上回退。
[StructLayout(Explicit)] 则可以精确控制内存布局:字段偏移、填充、大小等,你可以控制每一个字节。缓存行对齐、防止伪共享(False-sharing)、位打包(Bit-packing)——这些功能一应俱全。
这不是“C# 试图成为 C”,而是 C# 在其顶级的托管生态系统之上,提供了一个真正的系统级编程层。
Typhon 实际是什么样
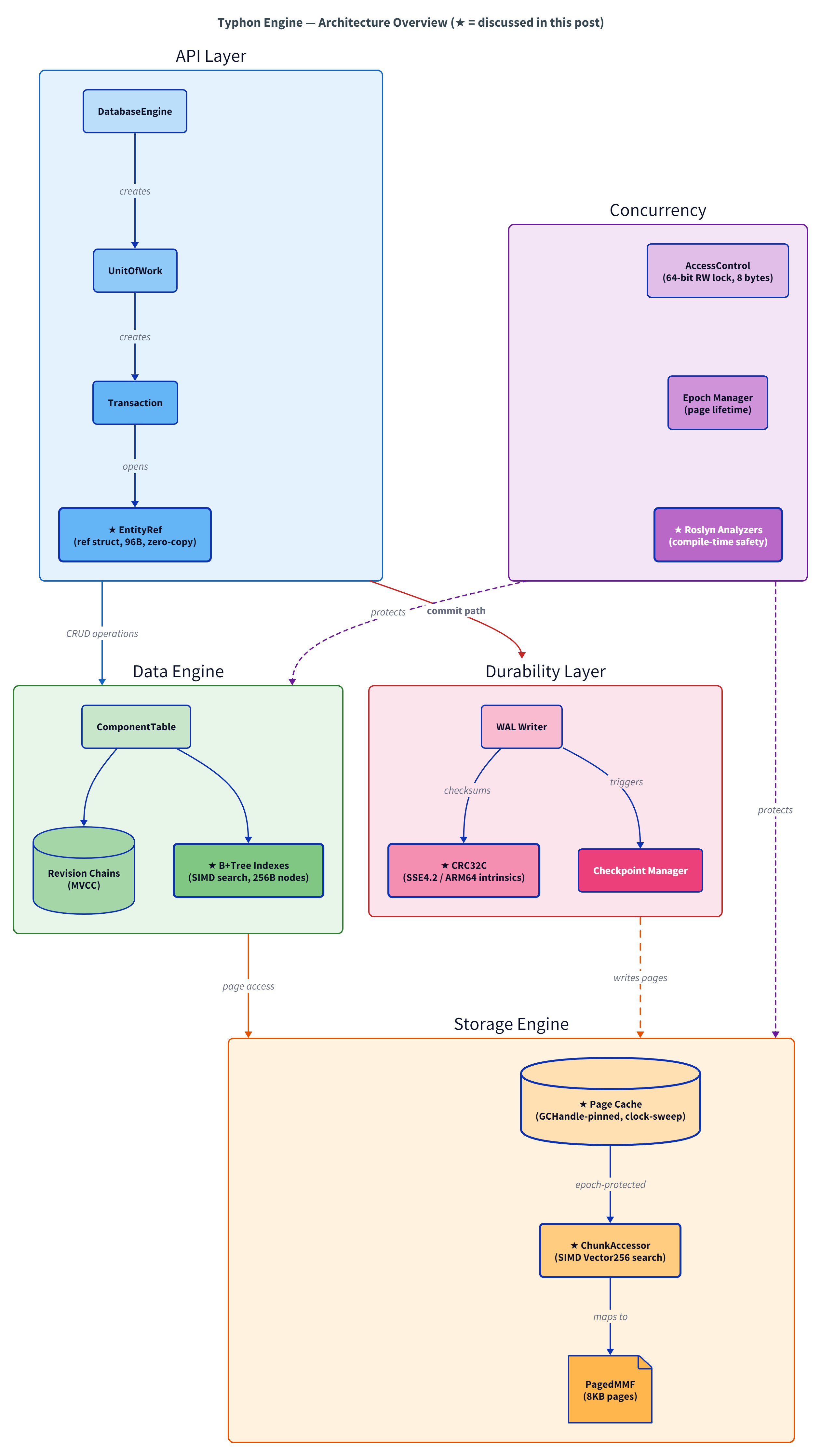
硬件加速的 WAL 校验和
写入预写日志(WAL)的每个页面都需要 CRC32C 校验和。这是它在 C# 中的样子——直接按名字调用 CPU 指令:
private static uint ComputePartial(uint crc, ReadOnlySpan<byte> data)
{
if (Sse42.X64.IsSupported) return ComputeSse42X64(crc, data);
if (Sse42.IsSupported) return ComputeSse42X32(crc, data);
if (ArmCrc32.Arm64.IsSupported) return ComputeArm64(crc, data);
return ComputeSoftware(crc, data);
}
private static uint ComputeSse42X64(uint crc, ReadOnlySpan<byte> data)
{
ulong crc64 = crc;
ref byte ptr = ref MemoryMarshal.GetReference(data);
int offset = 0;
int aligned = data.Length & ~7;
while (offset < aligned)
{
// 编译为单条 x86 crc32 指令
crc64 = Sse42.X64.Crc32(crc64, Unsafe.ReadUnaligned<ulong>(ref Unsafe.Add(ref ptr, offset)));
offset += 8;
}
uint crc32 = (uint)crc64;
while (offset < data.Length)
{
crc32 = Sse42.Crc32(crc32, Unsafe.Add(ref ptr, offset));
offset++;
}
return crc32;
}
Sse42.X64.Crc32() 会编译成单条 x86 crc32 指令。运行时检测 CPU 能力,JIT 消除无用分支,最后执行的是 C 程序员会写出的同类机器代码,同时还保留了不支持 SSE4.2 时的自动回退。
结果:每 8 KB 页面约 1.3 微秒。
SIMD 数据块访问器
Typhon 的页缓存热路径使用一个 16 槽缓存,通过三层路径查找数据。
// === 超快路径:MRU(最近最常使用)检查 ===
var mru = _mruSlot;
if (_pageIndices[mru] == pageIndex)
{
var headerOffset = pageIndex == 0 ? _rootHeaderOffset : _otherHeaderOffset;
return (byte*)_baseAddresses[mru] + headerOffset + offset * _stride;
}
// === 快路径:通过 SIMD 搜索所有 16 个缓存插槽 ===
fixed (int* indices = _pageIndices)
{
var target = Vector256.Create(pageIndex);
var v0 = Vector256.Load(indices);
var mask0 = Vector256.Equals(v0, target).ExtractMostSignificantBits();
if (mask0 != 0)
{
var slot = BitOperations.TrailingZeroCount(mask0);
return GetFromSlot(slot, pageIndex, offset, dirty);
}
var v1 = Vector256.Load(indices + 8);
var mask1 = Vector256.Equals(v1, target).ExtractMostSignificantBits();
if (mask1 != 0)
{
var slot = 8 + BitOperations.TrailingZeroCount(mask1);
return GetFromSlot(slot, pageIndex, offset, dirty);
}
}
_pageIndices 是一个 fixed int[16],共 64 字节,刚好一个缓存行,并且以适合 SIMD 的方式排列。一次 Vector256.Equals 可以比较 8 个页索引。MRU 快路径覆盖“重复访问同一页”这个常见场景,对分支预测友好,成本接近于零。
零拷贝实体读取
EntityRef 是一个只存在于栈上的 ref struct,大小为 96 字节,其中包含一个内联固定数组,用来缓存组件位置。
public unsafe ref struct EntityRef
{
internal readonly EntityId _id;
// ... 其他元数据
private fixed int _locations[16]; // 内联组件数据块 ID
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public ref readonly T Read<T>(Comp<T> comp) where T : unmanaged
{
byte slot = _archetype.GetSlot(comp._componentTypeId);
int chunkId = _locations[slot];
var table = _engineState.SlotToComponentTable[slot];
return ref _tx.ReadEcsComponentData<T>(table, chunkId);
}
}
这个 Read<T> 调用经历了:方法调用 → 插槽查找 → 数据块 ID → 页面缓存 → 指针算术 → 指向固定内存页面的 ref readonly T。零拷贝,零分配,零 GC 介入。由于泛型约束是 where T : unmanaged,JIT 知道确切布局,最终会编译成指针运算。
JIT 特化的哈希函数
Typhon 的哈希函数也利用了 JIT。由于受约束泛型下的 sizeof(TKey) 是编译期常量,不需要的分支会被消除。
[MethodImpl(MethodImplOptions.AggressiveInlining)]
internal static uint ComputeHash<TKey>(TKey key) where TKey : unmanaged
{
if (sizeof(TKey) == 4) return FastHash32(Unsafe.As<TKey, uint>(ref key));
if (sizeof(TKey) == 8) return XxHash32_8Bytes(Unsafe.As<TKey, long>(ref key));
return XxHash32_Bytes((byte*)Unsafe.AsPointer(ref key), sizeof(TKey));
}
例如调用 ComputeHash<int>(42) 时,JIT 只会生成 4 字节路径,其余分支会被完全移除。这是真正的单态化(Monomorphization),而非运行时分发(Runtime Dispatch)。
生产力论据
一个数据库引擎不仅仅只有热路径。在核心引擎周围包裹着庞大的基础设施:配置管理、结构化日志、遥测、依赖注入、测试、基准测试。
在 C 或 Rust 中,你需要自己构建其中的大部分,或者缝合质量参差不齐的库。
到了 .NET 里,这些能力已经是生产级且免费的:ILogger 和 OpenTelemetry 用于可观测性,BenchmarkDotNet 用于严谨的微基准测试,NUnit 用于测试,IConfiguration 用于配置。它们文档充分、互相兼容,并由 Microsoft 或经受过检验的开源社区维护。
对一个独立开发者来说,这是实际的竞争优势。我可以把时间花在并发原语和页缓存淘汰上,而不是重新发明日志框架。
核心在于内存布局,而非语言
这是我多年实时 3D 引擎开发经验教给我的洞察:数据库引擎的瓶颈在于内存访问模式,而非指令吞吐量。
在 Ryzen 7950X 上,一次 DRAM 缓存未命中大约需要 61 到 73 纳秒。这相当于 CPU 空等约 250 个周期。一次命中 L1 的 CAS 操作约 1.4 纳秒,两者比例约为 50:1。
如果你的数据结构导致缓存未命中,无论你的语言有多少“零成本抽象”都救不了你。反之,如果你的数据布局对缓存友好——连续、对齐、访问模式可预测——那么语言几乎无关紧要。带有 unsafe 的 C# 在热点路径上生成的机器码与 C 语言相同。JIT 就是这么强大。
真正重要的是:
- 缓存行感知: Typhon 的 B+ 树节点是 128 字节——两个缓存行。Zen4 上的步进预取器会自动覆盖第二行。仅此一项就比 64 字节节点减少了 53% 的插入延迟和 30% 的查找延迟。
- 数据导向设计(DoD): 采用 SOA(结构数组)而非 AOS(数组结构)。SIMD 友好的布局。仅使用可直接复制(Blittable)的类型。
- 最小化间接引用: 每次指针追踪都是一次潜在的缓存未命中。SIMD 数据块访问器的 MRU 命中完全避免了追踪。
因此,写什么语言远不如设计什么样的内存布局重要。
数据表现
所有测量均在 Ryzen 9 7950X、.NET 10.0、BenchmarkDotNet、Release 配置下进行。
| 操作 | 延迟 | 吞吐 |
|---|---|---|
| CRUD lifecycle MVCC(spawn、read、update、destroy、commit) | 1.2 微秒 | 830K ops/sec |
| 90 读 / 10 更新负载(每个事务 100 次操作,MVCC) | 22 微秒 | 约 4.5M entity-ops/sec |
| B+Tree 查找(命中) | 267 纳秒 |
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)