
基于Python+PyQt5+YOLOv8的摩托车头盔佩戴检测系统设计与实现(附核心代码)
前言
每年毕设季,很多计算机、人工智能相关专业的同学都会在选题和落地阶段踩坑:想做计算机视觉方向却找不到完整可运行的项目,网上零散的开源代码要么环境依赖混乱跑不通,要么只有算法模型没有可视化界面,达不到毕设答辩的要求。本文分享一个完整可落地的摩托车头盔佩戴检测系统,基于YOLOv8实现目标检测,搭配PyQt5开发桌面交互界面,支持图片、视频、摄像头实时检测与结果保存,非常适合用作本科毕业设计或课程设计项目。
一、项目概述与技术栈
本系统是一款面向交通监管场景的桌面端智能检测工具,依托深度学习目标检测技术,可自动识别图像与视频中的摩托车、骑手头盔佩戴状态,输出检测框、类别、置信度与位置坐标,辅助完成非机动车头盔佩戴合规性检测。
核心功能
-
单张图片头盔佩戴检测与结果可视化
-
本地视频逐帧检测与实时预览
-
摄像头实时流检测,适配实时监控场景
-
批量图片自动检测与结果批量保存
-
检测目标信息详情展示与数据导出
完整技术栈
|
技术分类 |
技术选型 |
版本说明 |
|---|---|---|
|
开发语言 |
Python |
3.9 |
|
目标检测框架 |
Ultralytics YOLOv8 |
8.0.199 |
|
深度学习框架 |
PyTorch |
2.2.1 |
|
GUI界面框架 |
PyQt5 |
5.15.2 |
|
图像处理库 |
OpenCV |
4.8.1.78 |
|
数据标注工具 |
LabelImg |
1.8.6 |
|
数值计算库 |
NumPy |
1.26.1 |
项目优势
-
检测精度高:头盔佩戴类mAP@0.5可达84.3%,小目标检测效果优于YOLOv5
-
交互友好:PyQt5开发的桌面界面,操作直观,支持结果表格化展示
-
功能完整:覆盖图片/视频/摄像头/批量检测全场景,支持结果保存
-
二次开发便捷:代码结构清晰,可快速替换数据集适配其他目标检测场景
二、系统整体架构与核心流程
系统采用分层架构设计,自下而上分为数据层、模型推理层、交互应用层三层,各模块职责清晰、低耦合,便于后续功能扩展与维护。
-
数据层:负责数据集构建、标注格式转换、数据增强与数据集划分,为模型训练提供高质量数据支撑;同时负责输入图像、视频的读取与预处理。
-
模型推理层:系统核心层,基于YOLOv8算法构建检测模型,融合CBAM注意力机制优化小目标检测效果,完成特征提取、目标分类与边界框回归,输出检测结果。
-
交互应用层:基于PyQt5实现桌面可视化界面,负责接收用户操作指令、调用检测模型、渲染检测结果、展示目标详情与数据表格,同时提供结果保存功能。
核心检测执行流程
用户触发检测指令后,系统按以下流水线执行:
-
读取输入源(图片/视频帧/摄像头画面)并进行尺寸归一化预处理
-
调用训练好的YOLOv8模型执行前向推理,输出原始预测结果
-
执行非极大值抑制(NMS)去除冗余检测框,过滤低置信度结果
-
解析检测目标的类别、置信度、坐标信息
-
在原图上绘制检测框与类别标签,同时将详情写入界面表格
-
支持用户选择查看单个目标详情与保存检测结果
三、核心功能实现(附核心代码)
3.1 YOLOv8检测模块核心实现
检测模块基于Ultralytics库封装,支持单图、视频帧、批量图片等多种输入格式,统一输出标准化的检测结果供界面层调用。
from ultralytics import YOLO
import cv2
import time
import numpy as np
class HelmetDetector:
def __init__(self, model_path):
# 加载预训练好的头盔检测模型
self.model = YOLO(model_path, task='detect')
# 模型预热,降低首次推理延迟
self.model(np.zeros((640, 640, 3)))
def detect_image(self, img_path):
"""
单张图片检测
:param img_path: 图片路径
:return: 检测结果对象、带检测框的图像、耗时
"""
start_time = time.time()
# 执行模型推理
results = self.model(img_path)[0]
cost_time = time.time() - start_time
# 绘制检测结果图
result_img = results.plot()
return results, result_img, cost_time
def parse_results(self, results):
"""
解析检测结果,提取坐标、类别、置信度
:param results: 模型推理结果
:return: 坐标列表、类别列表、置信度列表
"""
# 提取边界框坐标,转换为整数
xyxy_list = [list(map(int, box)) for box in results.boxes.xyxy.tolist()]
# 提取类别索引
cls_list = [int(cls) for cls in results.boxes.cls.tolist()]
# 提取置信度,格式化为百分比
conf_list = ['%.2f %%' % (conf * 100) for conf in results.boxes.conf.tolist()]
return xyxy_list, cls_list, conf_list3.2 PyQt5主界面核心逻辑
主界面采用信号与槽机制绑定用户操作,使用定时器实现视频与摄像头流的逐帧刷新,通过自定义线程处理视频保存等耗时任务,避免界面卡顿。
from PyQt5.QtWidgets import QMainWindow, QFileDialog
from PyQt5.QtCore import QTimer, Qt
import cv2
from detector import HelmetDetector
from ui_main import Ui_MainWindow
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
# 加载UI布局
self.ui = Ui_MainWindow()
self.ui.setupUi(self)
# 初始化检测模型
self.detector = HelmetDetector("./weights/best.pt")
# 显示区域尺寸
self.show_width = 770
self.show_height = 480
# 视频/摄像头定时器
self.frame_timer = QTimer()
self.frame_timer.timeout.connect(self.update_frame)
# 绑定按钮事件
self.bind_signals()
def bind_signals(self):
"""绑定所有控件信号与槽函数"""
self.ui.btn_image.clicked.connect(self.open_image_detect)
self.ui.btn_video.clicked.connect(self.open_video_detect)
self.ui.btn_camera.clicked.connect(self.toggle_camera)
self.ui.btn_save.clicked.connect(self.save_result)
def open_image_detect(self):
"""单张图片检测槽函数"""
file_path, _ = QFileDialog.getOpenFileName(self, "选择图片", "./", "Images (*.jpg *.png)")
if not file_path:
return
# 执行检测
results, result_img, cost_time = self.detector.detect_image(file_path)
xyxy_list, cls_list, conf_list = self.detector.parse_results(results)
# 缩放图片适配显示区域
resized_img = self.resize_image(result_img)
# 转换为Qt可显示格式并渲染
self.ui.label_show.setPixmap(cvimg_to_qpixmap(resized_img))
# 更新检测信息
self.ui.label_time.setText(f"{cost_time:.3f} s")
self.ui.label_count.setText(str(len(cls_list)))
# 更新结果表格
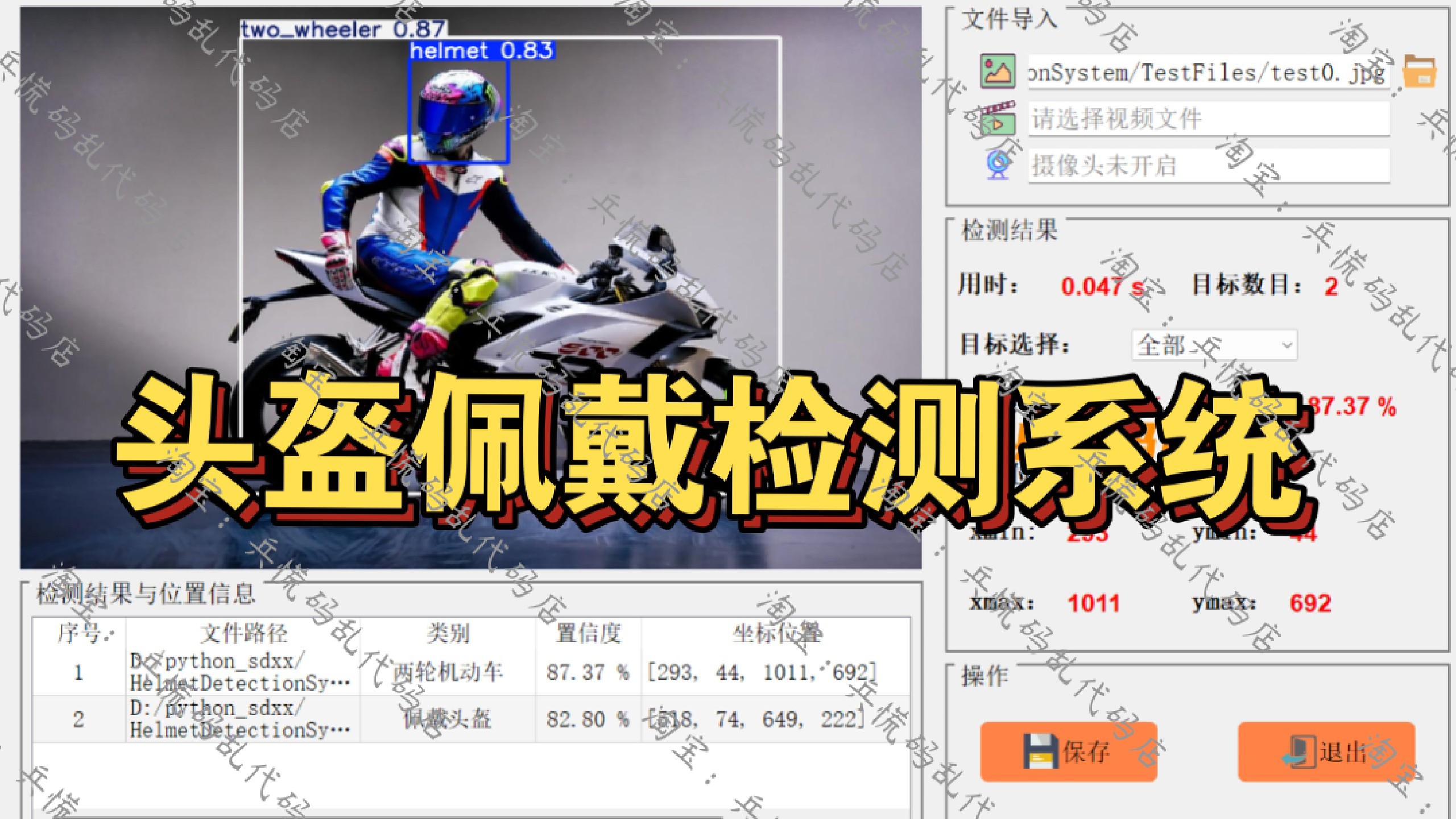
self.update_table(xyxy_list, cls_list, conf_list, file_path)四、系统界面与功能展示
系统主界面采用左右布局,左侧为检测结果预览区,右侧为操作控制与信息展示区,整体风格简洁直观,符合桌面软件使用习惯。
核心功能操作
-
图片检测:点击图片检测按钮选择本地图片,自动执行检测并在左侧显示带框结果,右侧展示检测耗时、目标总数,下拉框可切换查看单个目标的详细坐标与置信度,底部表格同步所有检测目标数据。
-
视频检测:选择本地视频文件后,系统逐帧读取并实时检测,画面流畅无卡顿,支持随时查看当前帧的检测详情。
-
摄像头实时检测:一键调用本地摄像头,实现实时头盔佩戴检测,适配现场监控、临时抽检等场景。
-
批量检测与保存:支持选择图片文件夹批量检测,自动保存所有检测结果图片到本地,无需手动逐张操作。
对应的系统全功能操作演示、部署步骤实拍视频,我也同步更新在了 B 站账号 兵慌码乱,想看动态运行效果、跟着视频一步步部署的同学,可以自行搜索查看。
五、本地部署与运行步骤
环境要求
-
操作系统:Windows 10/11(推荐)、Linux、macOS
-
Python版本:3.8 ~ 3.10
-
可选:NVIDIA显卡 + CUDA环境,可大幅提升训练与推理速度
分步部署流程
-
创建并激活虚拟环境
conda create -n helmet_det python=3.9
conda activate helmet_det-
安装项目依赖
pip install torch==2.2.1 torchvision==0.17.1
pip install ultralytics==8.0.199
pip install PyQt5==5.15.2 opencv-python==4.8.1.78
pip install numpy pandas matplotlib-
准备模型权重 将训练好的best.pt权重文件放入weights目录,或直接使用官方YOLOv8权重自行训练。
-
启动系统
python main.py启动后即可打开桌面界面,选择图片/视频/摄像头进行检测。
六、项目总结与扩展方向
项目总结
本系统完整实现了从数据集构建、模型训练到桌面可视化界面开发的全流程,基于YOLOv8算法优化了小目标检测效果,头盔佩戴检测mAP@0.5达到84.3%,相比YOLOv5有显著提升;PyQt5界面功能完整、操作直观,覆盖了绝大多数检测使用场景,整体完成度高,非常适合作为计算机视觉方向的毕设或课程设计项目。
扩展方向
-
算法优化:引入视觉Transformer模块进一步提升小目标与模糊目标检测精度,轻量化模型适配边缘设备部署
-
功能扩展:增加车牌识别模块,关联未佩戴头盔的车辆信息;加入违规记录数据库,实现数据统计与溯源
-
部署升级:打包为可执行文件,适配无Python环境的电脑使用;开发Web端版本,支持多端访问
-
场景拓展:适配更多非机动车类型,扩展为完整的非机动车交通违规检测系统
文末总结
完整的全量源码、配套资料已整理完毕,开箱即用,适合直接用作毕设或课程设计;对应的项目实操演示视频,可在 B 站搜索 兵慌码乱 查看。需要完整版本的同学,可以留意我的主页简介信息。
更多推荐
 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)