
Python 数据分析实战:2001-2024 全国婚姻登记数据全流程探索(Pandas+Matplotlib+Pyecharts)
一、文章前言
1. 项目背景
婚姻登记数据是反映社会人口结构、婚恋观念、城镇化发展的核心民生指标。本文基于全国 31 省份 2001-2024 结婚、离婚登记(万对)二维宽表数据,完整落地数据清洗→宽表转长表→时间趋势分析→空间地理可视化→动态时序排行榜全链路数据分析,综合使用pandas数据预处理、matplotlib静态绘图、pyecharts交互式地图 / 玫瑰图 / 时间轮播图。
2. 技术栈
- 数据处理:
pandas、numpy - 静态可视化:
matplotlib - 交互式可视化:
pyecharts(地图、玫瑰图、Timeline 动态排行) - 环境:Python3.8+ Jupyter Notebook
3. 数据集说明
两份 CSV 文件:
结婚登记(万对).csv:31 行省份,25 列年份(2001-2024)宽表离婚登记(万对).csv:同结构离婚数据 字段:地区 + 2001 年~2024 年登记数值(单位:万对)
4. 整体分析流程
- 阶段一:数据导入、数据质量体检(缺失、重复、分布)
- 阶段二:宽表转长表数据重塑、结婚 / 离婚数据合并
- 阶段三:时间序列趋势分析(全国大盘、单省对比、离结比)
- 阶段四:空间地域差异分析(热力地图、玫瑰图 TOP 省份)
- 阶段五:Timeline 动态时序排行榜可视化
- 阶段六:分析总结与社会解读
二、阶段一:数据初探与质量体检
2.1 导入依赖库、全局配置
python
运行
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置负号显示
plt.rcParams['axes.unicode_minus'] = False
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
2.2 读取两份婚姻数据(处理中文编码 gbk)
python
运行
#结婚登记数据
merrige_df=pd.read_csv('结婚登记(万对).csv',encoding='gbk')
#离婚登记数据
divorce_df=pd.read_csv('离婚登记(万对).csv',encoding='gbk')
#查看前5行
merrige_df.head()
输出预览表格:
表格
| 地 区 | 2024 年 | 2023 年 | 2022 年 | 2021 年 | 2020 年 | 2019 年 | ... | |
|---|---|---|---|---|---|---|---|---|
| 0 | 北 京 市 | 11.45 | 13.73 | 9.13 | 10.34 | 11.38 | 12.90 | ... |
| 1 | 天 津 市 | 6.04 | 8.38 | 6.89 | 8.04 | 8.98 | 9.64 | ... |
| 2 | 河 北 省 | 27.94 | 37.11 | 30.21 | 33.71 | 37.49 | 42.13 | ... |
2.3 数据基础信息探查
python
运行
# 查看数据行列、字段类型、缺失值
merrige_df.info()
divorce_df.info()
# 数值字段描述性统计(均值、最值、标准差、分位数)
divorce_df.describe()
统计结果解读:
- 共 31 个省份样本,25 个年份数值列;
- 所有年份无缺失值,最小值均大于 0,无异常负数;
- 标准差较大,说明各省登记数量地域差距明显。
2.4 原始宽表简单折线预览
python
运行
# 结婚数据原始宽表绘图
plt.figure(figsize=(20,6))
merrige_df.plot(kind='line',title="每年结婚登记地区分布")
plt.xticks(merrige_df.index,merrige_df['地区'],rotation=45)
plt.show()
# 离婚数据原始宽表绘图
plt.figure(figsize=(20,6))
divorce_df.plot(kind='line',title="每年离婚登记地区分布")
plt.xticks(divorce_df.index,divorce_df['地区'],rotation=45)
plt.show()
结果:
痛点:原始宽表年份作为列,无法直接按年份分组聚合、做时间序列分析,必须进行宽表转长表重构。
三、阶段二:数据重塑与结构优化(核心预处理)
3.1 melt 函数:宽表转为标准长表
长表固定三列:地区、年份、登记数,方便分组统计。
python
运行
# 结婚宽表转长表
merrige_df=merrige_df.melt(
id_vars=['地区'], # 保留维度列
var_name='年份', # 原年份列统一转为“年份”字段
value_name='结婚登记数' # 数值列命名
).sort_values(by='年份').reset_index(drop=True) # 按年份升序、重置索引
# 离婚宽表转长表
divorce_df=divorce_df.melt(
id_vars=['地区'],
var_name='年份',
value_name='离婚登记数'
).sort_values(by='年份').reset_index(drop=True)
divorce_df.head()
转换后长表输出:
表格
| 地区 | 年份 | 离婚登记数 | |
|---|---|---|---|
| 0 | 新疆维吾尔自治区 | 2001 年 | 5.51 |
| 1 | 北京市 | 2001 年 | 2.77 |
| 2 | 天津市 | 2001 年 | 1.31 |
3.2 合并结婚、离婚数据,生成综合分析表
python
运行
# 同顺序拼接离婚数据
merrige_df['离婚登记数'] = divorce_df['离婚登记数']
df = merrige_df.copy()
df.head()
合并后完整数据表结构:地区、年份、结婚登记数、离婚登记数,支撑后续所有指标计算。
四、阶段三:时间维度趋势与拐点分析
4.1 全国历年结婚 & 离婚总量双折线
python
运行
# 按年份聚合全国总登记量
year_count=df.groupby('年份')[['结婚登记数','离婚登记数']].sum().reset_index()
# 绘制双折线趋势图
plt.figure(figsize=(16,6))
plt.plot(year_count['年份'],year_count['结婚登记数'],marker='o',label='结婚登记')
plt.plot(year_count['年份'],year_count['离婚登记数'],marker='*',label='离婚登记')
plt.title("2001-2024全国每年结婚和离婚登记总量(万对)")
plt.legend()
plt.xticks(rotation=45)
plt.show()
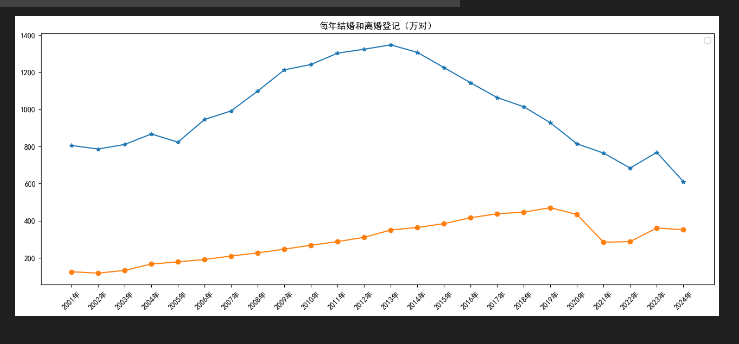
趋势核心结论
- 结婚总量 2013 年达到峰值后持续逐年下滑;
- 离婚总量长期稳步上涨,2020 年后小幅回落;
- 2013 年为婚恋趋势关键拐点。
4.2 单省趋势对比(以广西壮族自治区为例)
python
运行
# 筛选广西数据,按年份聚合
gx_count=df[df['地区']=='广西壮族自治区'].groupby('年份')[['结婚登记数','离婚登记数']].sum().reset_index()
plt.figure(figsize=(16,6))
plt.plot(gx_count['年份'],gx_count['结婚登记数'],marker='*',label='广西结婚')
plt.plot(gx_count['年份'],gx_count['离婚登记数'],marker='o',label='广西离婚')
plt.xticks(rotation=45)
plt.title("广西每年结婚和离婚登记(万对)")
plt.legend()
plt.show()
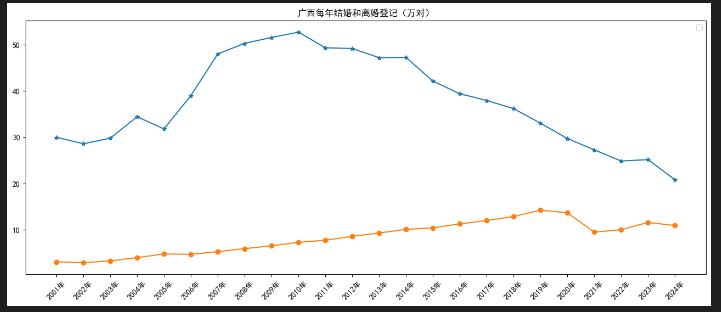
可对比全国大盘,分析地方婚恋趋势是否存在滞后 / 超前特征。
4.3 全国历年离结比趋势(离婚 / 结婚)
python
运行
# 分组计算每年离结比
year_marry_sum = df.groupby('年份')['结婚登记数'].sum()
year_div_sum = df.groupby('年份')['离婚登记数'].sum()
ratio = year_div_sum / year_marry_sum
# 绘制离结比折线
plt.figure(figsize=(12,5))
ratio.plot(kind='line',marker='*',title="全国历年离结比(离婚/结婚)")
plt.grid()
plt.show()
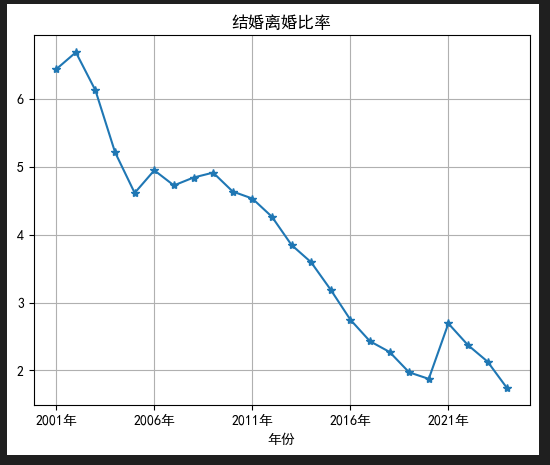
解读:离结比持续走高,反映婚姻稳定性逐年下降,结合城镇化、高等教育普及、女性独立等社会背景可深度分析。
4.4 各省份整体离结比横向对比柱状图
python
运行
# 各省累计离婚/累计结婚
prov_marry_sum = df.groupby('地区')['结婚登记数'].sum()
prov_div_sum = df.groupby('地区')['离婚登记数'].sum()
prov_ratio = prov_div_sum / prov_marry_sum
plt.figure(figsize=(16,6))
prov_ratio.plot(kind='bar',title="各省份整体离结比")
plt.xticks(rotation=45)
plt.grid(axis='y')
plt.show()
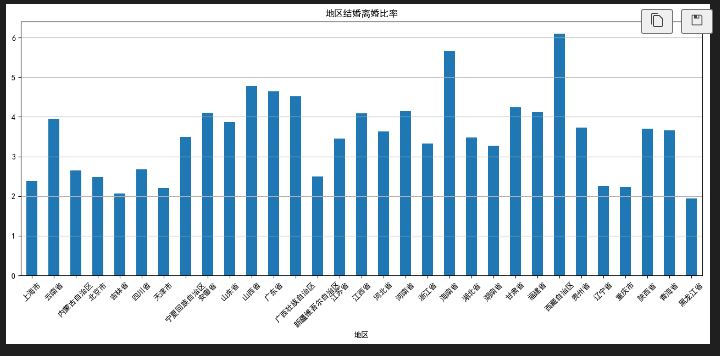
现象:东北三省、直辖市离结比显著高于中西部省份。
五、阶段四:空间维度地域差异分析(Pyecharts 可视化)
5.1 全国结婚登记总量热力地图
python
运行
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份+数值数据封装
provice_marrige=df.groupby('地区')['结婚登记数'].sum()
map_data=[list(z) for z in zip(provice_marrige.index, provice_marrige)]
m=(
Map()
.add('累计结婚登记万对',map_data)
.set_global_opts(
title_opts=opts.TitleOpts(title="全国各地区累计结婚登记数热力图"),
visualmap_opts=opts.VisualMapOpts(is_show=True,max_=1800,min_=10)
)
)
m.render('1.各地区结婚登记热力图.html')
结果:

地图特征:东部人口大省(河南、山东、广东)结婚总量最高,西部低人口省份数值偏低,符合胡焕庸线人口分布规律。
5.2 全国离婚登记总量热力地图
python
运行
from pyecharts.charts import Map
from pyecharts import options as opts
provice_divorce=df.groupby('地区')['离婚登记数'].sum()
map_div_data=[list(z) for z in zip(provice_divorce.index.astype(str), provice_divorce)]
m=(
Map()
.add('累计离婚登记万对',map_div_data)
.set_global_opts(
title_opts=opts.TitleOpts(title="全国各地区累计离婚登记数热力图"),
visualmap_opts=opts.VisualMapOpts(is_show=True,max_=700,min_=0)
)
)
m.render('2.各地区离婚登记热力图.html')
结果:
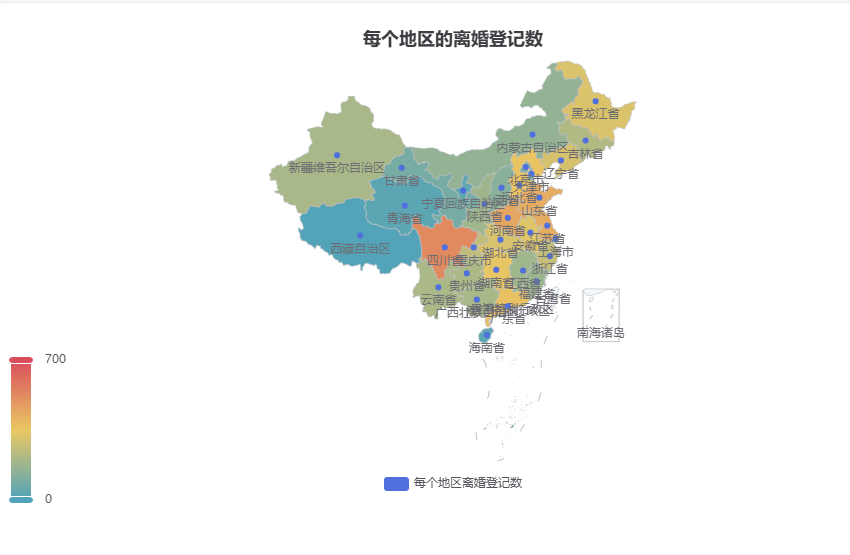
5.3 结婚总量 TOP10 省份南丁格尔玫瑰图
python
运行
from pyecharts.charts import Pie
from pyecharts import options as opts
# 降序取全部省份
provice_marrige=df.groupby('地区')['结婚登记数'].sum().sort_values(ascending=False)
pie_data=[list(z) for z in zip(provice_marrige.index.astype(str),provice_marrige)]
pie=(
Pie()
.add('结婚登记总量',pie_data,rosetype='radius',radius=['25%','60%'])
.set_global_opts(title_opts=opts.TitleOpts(title="结婚登记总量前十省份玫瑰图"))
)
pie.render("3.结婚前十省份玫瑰图.html")
结果:
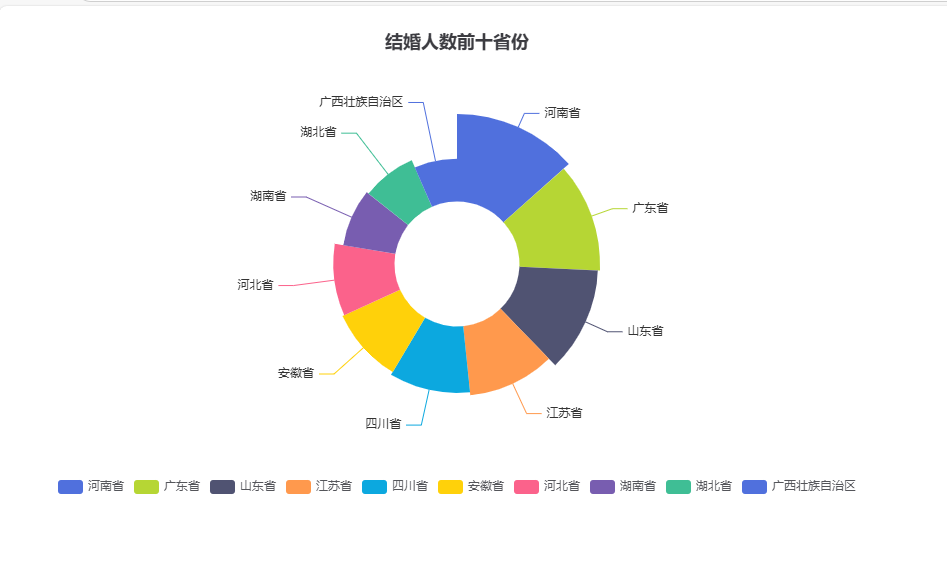
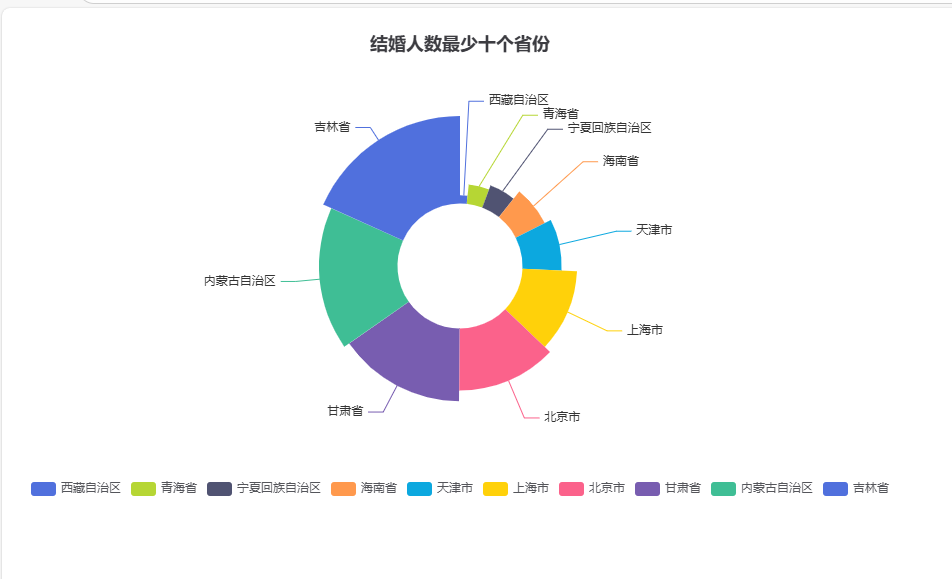
5.4 结婚总量最少 10 省份玫瑰图
python
运行
provice_marrige=df.groupby('地区')['结婚登记数'].sum().sort_values(ascending=True)
pie_data=[list(z) for z in zip(provice_marrige.index.astype(str),provice_marrige)]
pie=(
Pie()
.add('结婚登记总量最少省份',pie_data,rosetype='radius',radius=['25%','60%'])
.set_global_opts(title_opts=opts.TitleOpts(title="结婚登记最少省份玫瑰图"))
)
pie.render("4.结婚最少省份玫瑰图.html")
结果:
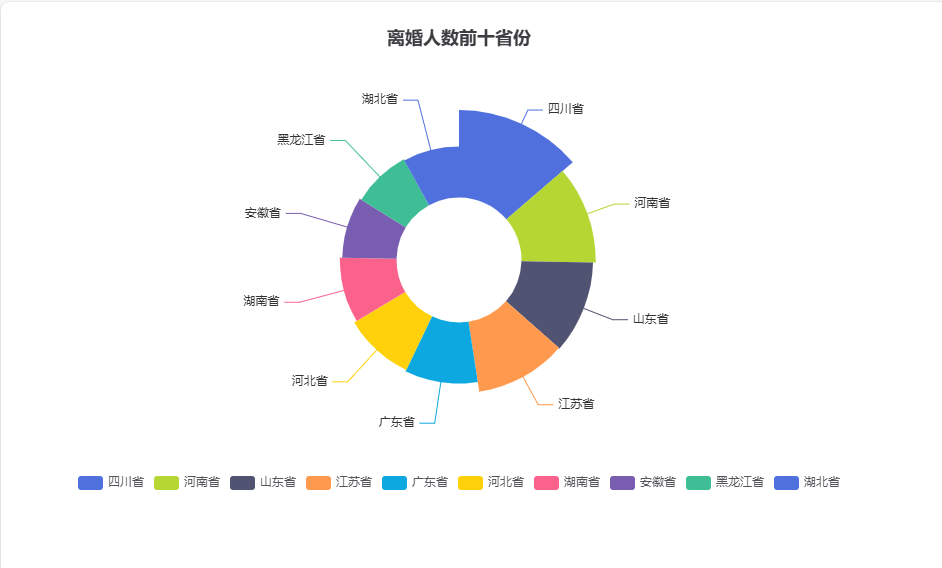
5.5 离婚总量 TOP10 省份玫瑰图
python
运行
provice_divorce=df.groupby('地区')['离婚登记数'].sum().sort_values(ascending=False)
pie_data=[list(z) for z in zip(provice_divorce.index.astype(str),provice_divorce)]
pie=(
Pie()
.add('离婚登记总量前十省份',pie_data,rosetype='radius',radius=['25%','60%'])
.set_global_opts(title_opts=opts.TitleOpts(title="离婚登记总量前十省份玫瑰图"))
)
pie.render("5.离婚前十省份玫瑰图.html")
结果:
六、阶段五:动态可视化 ——Timeline 时间轴动态排行
实现 2001-2024 每年各省结婚数量 TOP20 动态轮播柱状图,支持自动播放:
python
运行
from pyecharts.charts import Bar, Timeline
from pyecharts import options as opts
from pyecharts.globals import ThemeType, CurrentConfig
from pyecharts.commons.utils import JsCode
# 修复国内CDN空白问题
CurrentConfig.ONLINE_HOST = "https://cdn.jsdelivr.net/npm/echarts@5.4.3/dist/"
year_list=df["年份"].unique().tolist()
# 初始化时间轴容器
timeline_final = Timeline(init_opts=opts.InitOpts(width="1600px",height="850px"))
# 自定义配色
color_js = JsCode("""
function(params){
let c = ['#ff4757','#ffa502','#fffa65','#2ed573','#1e90ff','#3742fa','#a55eea'];
return c[params.dataIndex % c.length];
}
""")
# 循环每一年生成柱状图
for year in year_list:
# 筛选当年数据,降序取前20
data_year = df[df["年份"]==year].sort_values("结婚登记数",ascending=False).head(20)
data_year = data_year.sort_values(by="结婚登记数",ascending=True)
province = data_year["地区"].tolist()
count = data_year["结婚登记数"].tolist()
bar = (
Bar()
.add_xaxis(province)
.add_yaxis(
"结婚登记数",
count,
itemstyle_opts=opts.ItemStyleOpts(color=color_js,opacity=0.85,border_radius=6),
label_opts=opts.LabelOpts(is_show=True,position="right",color="#fff")
)
.reversal_axis() # 倒置坐标轴,第一名置顶
.set_global_opts(
title_opts=opts.TitleOpts(title=f"{year}年中国结婚登记数TOP20排行"),
xaxis_opts=opts.AxisOpts(name="登记数"),
yaxis_opts=opts.AxisOpts(name="省份"),
tooltip_opts=opts.TooltipOpts(trigger="axis")
)
)
timeline_final.add(bar,str(year))
# 配置时间轴自动播放
timeline_final.add_schema(
is_auto_play=True,
is_loop_play=True,
play_interval=600,
width="95%"
)
# 渲染网页
timeline_final.render("结婚登记数动态排行.html")
timeline_final.render_notebook()
结果:
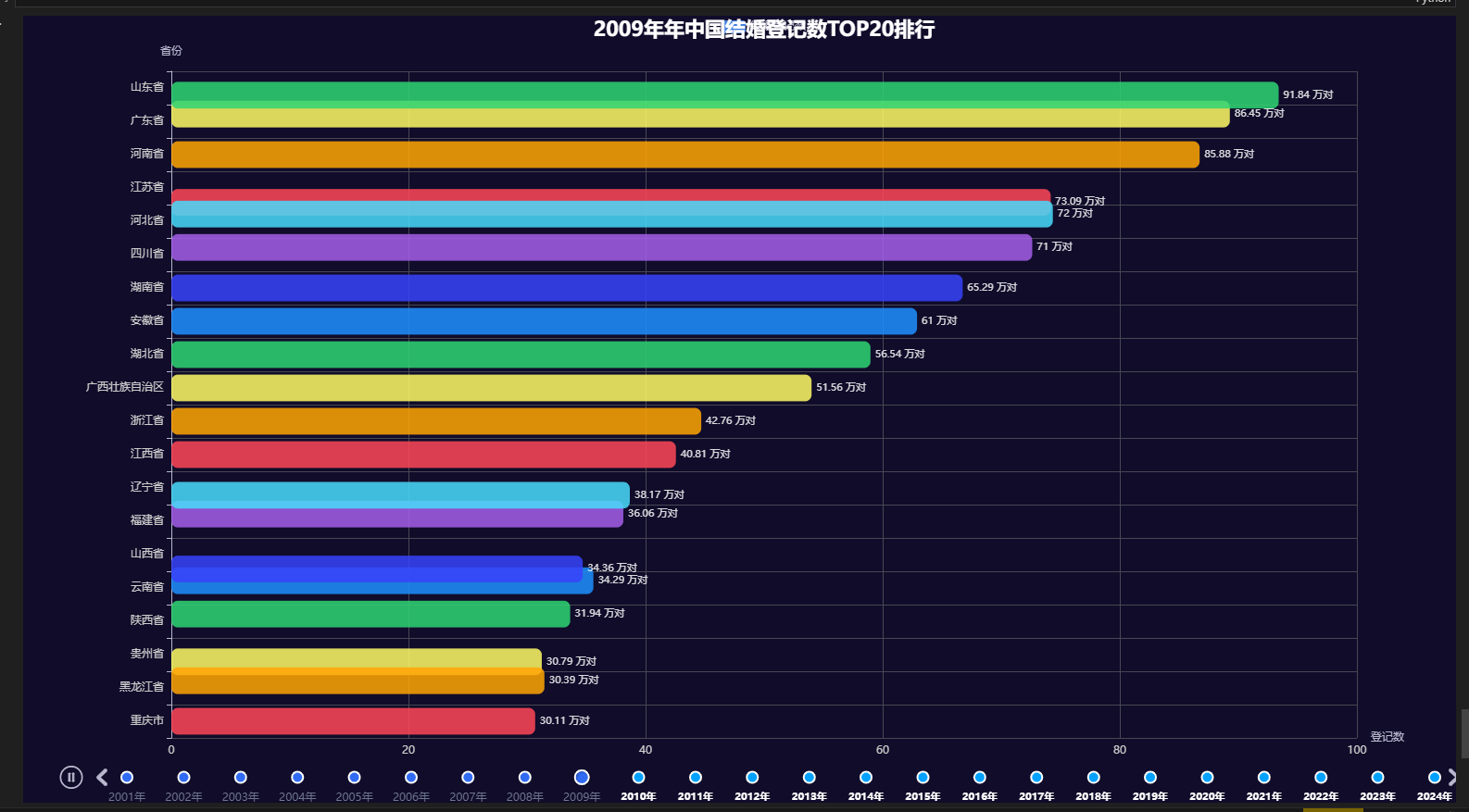
效果图说明:自动轮播 2001-2024 各年份省份结婚排名,直观观察人口大省长期稳居前列、中西部省份逐年小幅波动。
七、核心分析结论
7.1 时间趋势结论
- 全国结婚登记量 2013 年触顶后连续十几年下滑,晚婚、不婚观念普及;
- 离婚登记量长期上行,离结比持续走高,婚姻稳定性下降;
- 2020 年后两类数据同步小幅回落,受疫情、婚恋冷静期政策双重影响。
7.2 空间地域结论
- 总量维度:河南、山东、广东、四川等人口大省结婚、离婚总量遥遥领先;
- 离结比维度:东北三省、一线城市离婚相对比例更高,中西部偏低;
- 人口分布:婚姻登记总量符合胡焕庸线,东部沿海显著高于西部内陆。
7.3 社会学解读
- 城镇化:城市人口流动大、生活成本高,婚姻维系难度上升;
- 女性经济独立:女性收入提升,降低对婚姻经济依附;
- 人口结构:适婚人口逐年减少,叠加晚婚,直接压低结婚总量;
- 观念变化:当代年轻人更注重婚姻质量,不合适更倾向选择离婚。
八、项目局限与拓展方向
局限
- 数据仅包含登记对数,无分年龄段、城乡、教育程度细分字段;
- 缺少人口基数,无法计算千人结婚率,仅能分析绝对总量;
- 无跨省流动、初婚 / 再婚细分数据。
拓展方向
- 新增千人结婚率、千人离婚率指标,消除人口基数干扰;
- 引入 GDP、人均收入做相关性回归分析;
- 新增离婚原因、婚龄细分数据做多维度交叉分析;
- 构建机器学习模型预测未来 3-5 年婚姻登记趋势。
九、完整源码获取
文中所有代码均可直接复制运行,CSV 数据集为公开民政统计数据,替换文件路径即可复现全部图表。 依赖安装命令:
bash
运行
pip install pandas numpy matplotlib pyecharts -i https://pypi.tuna.tsinghua.edu.cn/simple更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)