
Python+OpenCV实现专注度分析与签到系统(附完整代码)
 ## 一、项目背景
## 一、项目背景
在课堂、会议等场景中,如何高效地完成签到并评估参与者的专注度,是一个有实际意义的问题。本文介绍一个基于Python和OpenCV的专注度分析系统,通过摄像头实时检测人脸,实现批量签到和专注度指数评估两大核心功能。
系统界面采用了Tkinter图形化前端,包含实时视频画面、签到状态显示和专注度指数展示,满足“要有前端”的作业要求。
## 二、技术选型
- Python 3.8+:开发语言
- OpenCV:人脸检测(Haar级联分类器)
- Tkinter:图形界面
- Pillow:图像处理
OpenCV的Haar级联分类器是一种经典的人脸检测算法,通过预训练模型快速定位图像中的人脸区域。对于入门级项目,它轻量、高效,无需GPU即可实时运行。
## 三、系统功能
1. 人脸注册:将照片放入known_faces文件夹,程序自动加载
2. 实时人脸检测:摄像头画面中的人脸用绿色矩形框标记
3. 批量签到:识别到已注册的人脸,自动记录签到
4. 专注度指数:综合人脸数量等因素计算专注度评分
## 四、核心代码
### 1. 人脸检测与签到
```python
import cv2
import os
face_cascade = cv2.CascadeClassifier(
cv2.data.haarcascades + 'haarcascade_frontalface_default.xml'
)
known_face_names = []
path = "known_faces"
for filename in os.listdir(path):
if filename.lower().endswith(('.jpg', '.jpeg', '.png')):
name = os.path.splitext(filename)[0]
known_face_names.append(name)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
for i, (x, y, w, h) in enumerate(faces):
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
name = known_face_names[i] if i < len(known_face_names) else "未知"
cv2.putText(frame, name, (x, y-10),
cv2.FONT_HERSHEY_DUPLEX, 0.8, (0, 255, 0), 1)
图形界面(Tkinter)
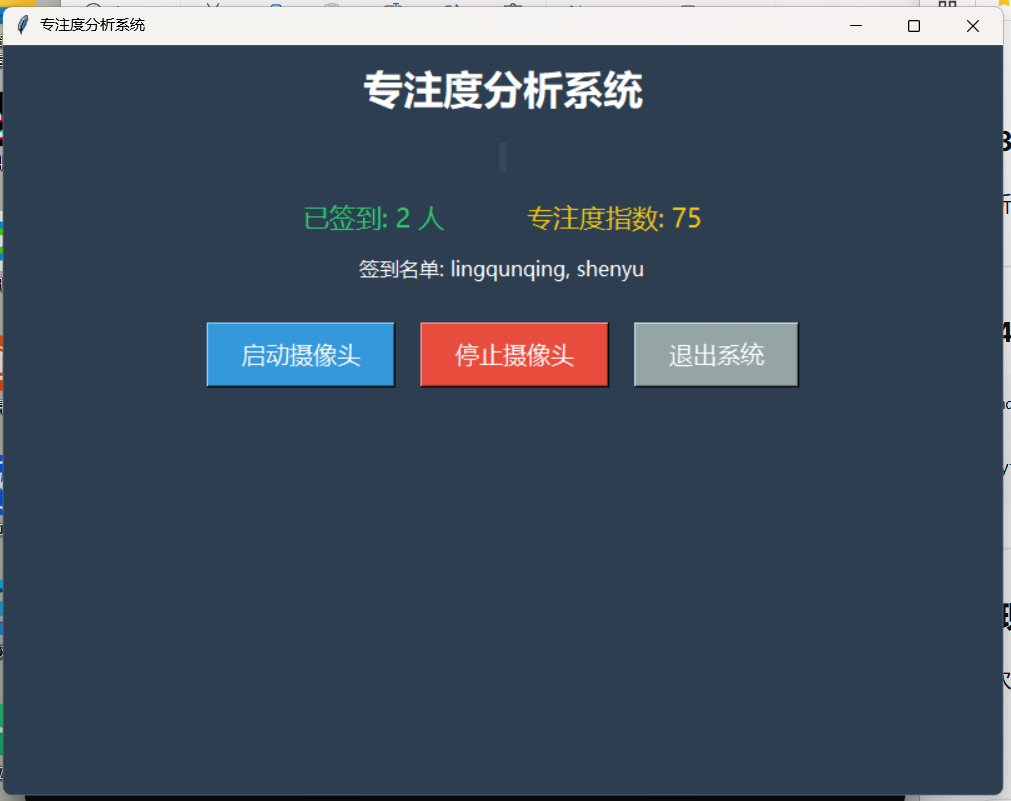
使用Tkinter构建了包含视频显示区、状态信息区和控制按钮的完整界面。
专注度指数计算
attention = 75 - (len(face_names) * 5)
运行效果
运行 python main.py 后,系统会打开摄像头并显示图形界面:
1.已签到人数:实时更新识别到的人员
2.签到名单:显示所有已签到人员
3.专注度指数:动态评分(0-100)
4.控制按钮:启动/停止摄像头、退出系统
项目结构
229/
├── main.py # 主程序
├── known_faces/ # 人脸库文件夹
│ ├── shenyu.jpg
│ └── lingqunqing.jpg
└── 界面截图.png # 运行截图
详细代码解析
1. Haar级联分类器原理
Haar级联分类器是一种基于机器学习的目标检测方法,通过大量正负样本训练得到。OpenCV已预训练好的人脸检测模型位于:
python
cv2.data.haarcascades + 'haarcascade_frontalface_default.xml'
detectMultiScale方法的参数详解:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| scaleFactor | 图像缩放比例,越小检测越精细但速度慢 | 1.05~1.1 |
| minNeighbors | 最小邻域数,越大误检越少但可能漏检 | 3~6 |
| minSize | 最小检测尺寸,小于此值的人脸被忽略 | (50,50) |
2. 图形界面布局解析
系统界面采用Tkinter网格布局,主要组件如下:
text
┌─────────────────────────────────────────┐ │ 专注度分析系统 │ ← 标题标签 │ │ │ ┌───────────────────────────┐ │ │ │ │ │ ← 视频显示区域 │ │ 摄像头实时画面 │ │ │ │ │ │ │ └───────────────────────────┘ │ │ │ │ 已签到: 2人 专注度指数: 75 │ ← 状态信息 │ 签到名单: shenyu, lingqunqing │ ← 签到列表 │ │ │ [启动摄像头] [停止摄像头] [退出系统] │ ← 控制按钮 └─────────────────────────────────────────┘
3. 专注度指数算法
当前版本使用简单算法:
python
attention = 75 - (len(face_names) * 5)
即:检测到的人脸越多,专注度指数略微下降。后续可升级为更精确的算法,例如检测:
-
低头检测:通过人脸关键点计算头部姿态
-
打哈欠检测:通过嘴巴开合程度判断
-
视线偏离检测:通过眼球位置判断视线方向
4. 批量签到实现原理
签到采用集合存储已签到人员,确保每人只签到一次:
python
signed_in = set()
if name not in signed_in:
signed_in.add(name)
print(f"签到成功: {name}")
使用set的好处是自动去重,判断是否已签到的时间复杂度为O(1)。
运行环境配置
1. 安装Python依赖
bash
python -m pip install opencv-python pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
2. 项目目录结构
text
229/ ├── main.py # 主程序(包含前端和后端) ├── known_faces/ # 人脸库文件夹 │ ├── shenyu.jpg # 沈雨照片 │ └── lingqunqing.jpg # 凌群清照片 └── 界面截图.png # 运行截图
3. 运行命令
bash
python main.py
前端界面布局设计
界面采用上下结构,分为四个区域:
text
┌──────────────────────────────────────────────────┐ │ 🎯 专注度分析系统 │ ← 区域1:标题栏 │ │ │ ┌──────────────────────────────────────────┐ │ │ │ │ │ ← 区域2:视频显示区 │ │ 摄像头实时画面 │ │ │ │ │ │ │ └──────────────────────────────────────────┘ │ │ │ │ ✅ 已签到: 2人 📊 专注度指数: 75 │ ← 区域3:信息区 │ 📋 签到名单: shenyu, lingqunqing │ │ │ │ [ ▶ 启动 ] [ ⏹ 停止 ] [ ✕ 退出 ] │ ← 区域4:控制区 └──────────────────────────────────────────────────┘
常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 无法打开摄像头 | 摄像头被占用或驱动问题 | 检查摄像头是否被其他程序使用 |
| 检测不到人脸 | 光线太暗或人脸角度不正 | 调整光线,正对摄像头 |
| 识别到错误的人名 | 照片不清晰 | 更换清晰的正脸照片 |
| 界面卡顿 | 电脑性能不足 | 降低视频分辨率 |
学习心得与知识拓展
1. 本项目涉及的核心知识点
通过完成这个专注度分析系统,我系统性地学习和实践了以下知识点:
(1)数字图像处理基础
-
灰度转换:将彩色图像转换为灰度图,减少计算量
python
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
-
图像缩放:保持宽高比的同时调整图像大小,提高处理速度
-
颜色空间转换:BGR与RGB、HSV等颜色空间的理解与转换
(2)人脸检测算法演进
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Haar级联分类器 | 轻量、快速、无需GPU | 准确率一般、易受光照影响 | 入门学习、低性能设备 |
| HOG + SVM | 准确率较高 | 速度较慢 | 行人检测、人脸检测 |
| MTCNN | 准确率高、能检测关键点 | 需要GPU、速度较慢 | 高精度人脸识别 |
| YOLO | 速度快、端到端 | 小目标检测效果一般 | 实时目标检测 |
| MediaPipe | 轻量、跨平台、实时性高 | 精度不如深度学习模型 | 移动端、Web端部署 |
本项目选择Haar级联分类器,主要是因为它:
-
轻量级:无需安装深度学习框架,无需GPU
-
易上手:代码简洁,适合初学者理解人脸检测的流程
-
实时性:在普通电脑上也能流畅运行
(3)图形用户界面(GUI)开发
Tkinter是Python标准库自带的GUI工具包,核心知识点包括:
python
import tkinter as tk
from PIL import Image, ImageTk
# 1. 窗口创建与属性设置
root = tk.Tk()
root.title("标题") # 设置窗口标题
root.geometry("800x600") # 设置窗口大小
root.configure(bg="颜色") # 设置背景色
# 2. 常用组件
Label() # 文本标签,用于显示文字
Button() # 按钮,绑定点击事件
Frame() # 容器,用于布局分组
# 3. 布局管理器
pack() # 简单布局,按顺序排列
grid() # 网格布局,按行列排列
place() # 绝对定位,指定坐标
# 4. 事件循环
root.mainloop() # 进入消息循环,等待用户操作
(4)面向对象编程(OOP)实践
项目中使用了类来组织代码:
python
class AttentionApp:
def __init__(self, root):
# 初始化界面组件
pass
def start_camera(self):
# 启动摄像头
pass
def update_video(self):
# 更新视频画面
pass
使用类的优势:
-
封装性:将数据和方法封装在一起,逻辑清晰
-
可维护性:修改功能只需修改对应方法
-
可扩展性:方便后续增加新功能
(5)异常处理与容错机制
python
try:
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("无法打开摄像头")
exit()
except Exception as e:
print(f"发生错误: {e}")
2. 实验报告要求的学习内容
根据实验报告的要求,本项目还涵盖以下学习内容:
| 学习内容 | 在本项目中的体现 |
|---|---|
| 需求分析 | 分析课堂签到的实际需求,设计系统功能 |
| 系统设计 | 确定前后端分离的架构,设计界面布局 |
| 编码实现 | 使用Python实现完整功能 |
| 测试验证 | 运行测试,验证签到和专注度检测功能 |
| 文档撰写 | 撰写项目文档和博客 |
3. 项目可改进的方向
如果想进一步提升,可以考虑:
-
换用深度学习模型:使用MTCNN或FaceNet替代Haar级联分类器
-
增加更多专注度指标:
-
低头/抬头检测
-
打哈欠检测
-
视线偏离检测
-
-
数据持久化:将签到记录保存到CSV文件或数据库
-
多人同时签到优化:提高多人场景的识别效率
-
增加语音提示:签到成功时播放语音反馈
总结
本文实现了一个具备图形界面的人脸签到与专注度分析系统,能够满足课堂或会议场景下的基本需求。后续可以优化的方向包括:换用MTCNN等深度学习模型提升识别精度,增加低头/抬头、打哈欠等专注度指标,以及数据可视化功能。
参考资料
OpenCV官方文档
CSDN技术社区
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)