
36.图RAG-使用Python代码实现图RAG
·
内容参考于:图灵AI大模型全栈
实现一个图RAG
输入文档,文档切分,切分后使用大模型提取知识图谱,生成后保存图数据到Neo4j数据库
输入问题给大模型,大模型生成CQL语法,然后去查询Neo4j的数据,然后输出答案
langchain_neo4j要0.9.0版本
Python -m pip install langchain-neo4j==0.9.0
如下图大模型通过分析文档,转成的知识图谱,通过提示词实现
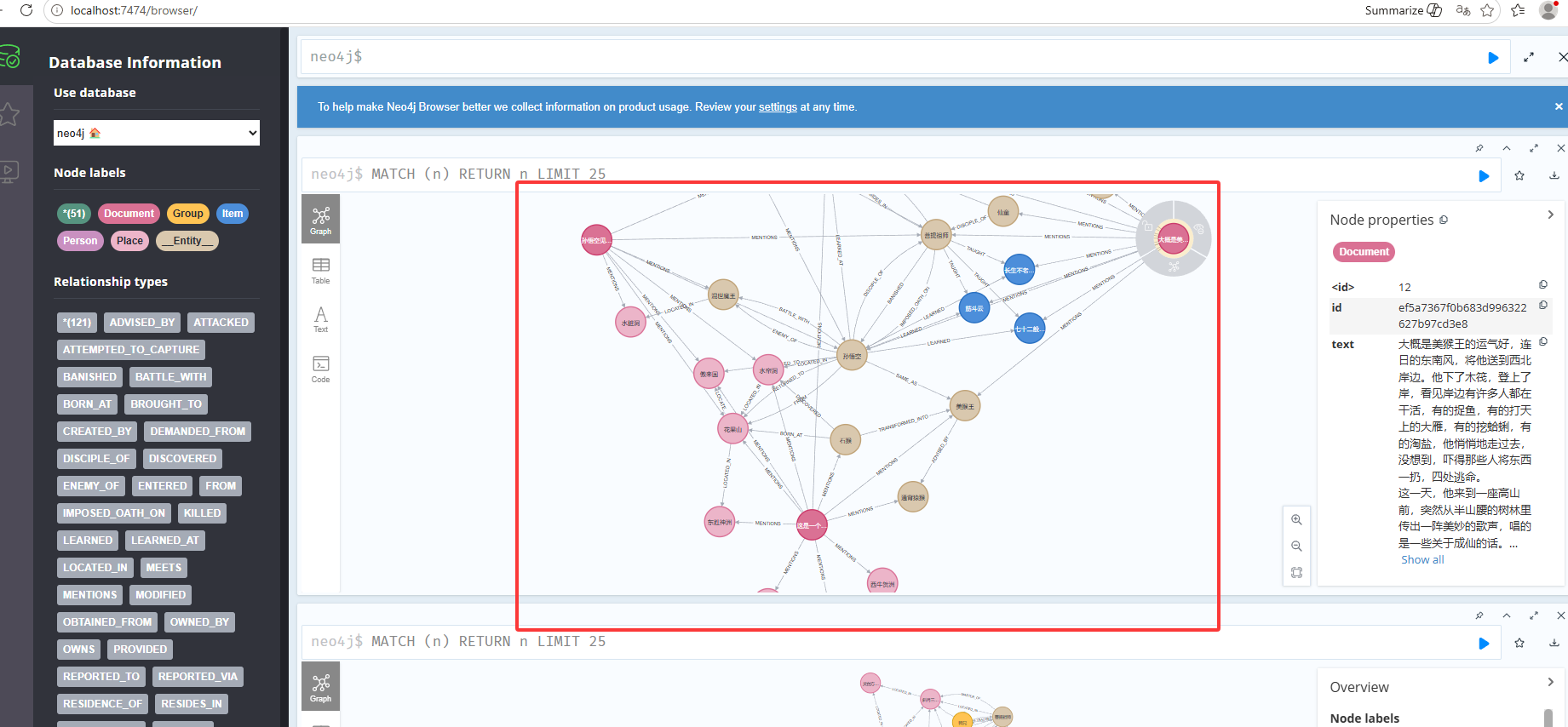
代码,下方用到的 西游记.txt 里的内容就是西游记小说的第一章和第二章
使用提示词,让大模型分析文章,下方的代码是分析西游记小说,从小说中提取关系,并返回成一个json格式,然后通过json个组装成GraphDocument格式(Neo4j通过它插入数据)
下方代码调用逻辑
1. 初始化(脚本启动自动执行)
加载环境配置 → 初始化大模型 → 连接 Neo4j 数据库 → 写好提取规则 → 组装好图谱提取链
2. 构建知识图谱(调用
ingest_data触发)读入本地文本文件 → 把长文切成小块 → 逐块调用大模型提取节点和关系(通过提示词实现) → 批量写入 Neo4j 数据库
3. 问答查询(调用
rag_chain.invoke触发)接收用户问题 → 自动转成数据库查询语句 → 去 Neo4j 查结果 → 大模型根据查到的图谱数据生成回答 → 返回最终答案
# 导入操作系统交互模块,用来读取环境变量、操作文件路径等 import os # 导入类型提示工具 List,用来标注「列表」类型的参数/返回值,让代码更易读,编辑器能做语法提示 from typing import List # 导入 OpenAI 协议的大模型封装类,用来调用兼容 OpenAI 接口的大模型(这里用来调用通义千问) from langchain_openai import ChatOpenAI # 从 langchain_neo4j 导入两个核心工具: # - Neo4jGraph:Neo4j 图数据库的连接与操作封装 # - GraphCypherQAChain:图数据库问答链,自动把自然语言问题转成 Cypher 查询语句再查库回答 from langchain_neo4j import Neo4jGraph, GraphCypherQAChain # 导入 LangChain 标准文档对象,每个 Document 包含文本内容和元数据 from langchain_core.documents import Document # 导入聊天提示词模板类,用来构建结构化的提示词,支持系统提示+用户提示的格式 from langchain_core.prompts import ChatPromptTemplate # 导入 JSON 输出解析器,自动把大模型返回的文本转成 Python 字典/列表,方便程序处理 from langchain_core.output_parsers import JsonOutputParser # 导入递归字符文本切分器,用来把长文本按规则切成小块,方便大模型分批处理 from langchain_text_splitters import RecursiveCharacterTextSplitter # 导入 dotenv 库的 load_dotenv 函数,用来加载 .env 文件里的环境变量(比如 API Key、接口地址) # 好处:敏感信息不写死在代码里,更安全,换环境也方便 from dotenv import load_dotenv # 从 langchain 社区工具里导入知识图谱文档相关的三个类: # - GraphDocument:图文档对象,对应一个文本块提取出的完整图谱片段(包含节点+关系+来源文档) # - Node as LangChainNode:节点类,代表知识图谱里的实体(比如人物、地点、法宝),起别名是避免和其他类重名 # - Relationship as LangChainRelationship:关系类,代表两个节点之间的关联(比如师徒、拥有、位于) from langchain_community.graphs.graph_document import ( GraphDocument, Node as LangChainNode, Relationship as LangChainRelationship, ) # 执行加载 .env 文件:把 .env 文件里的键值对读取到系统环境变量中 # 后面 os.getenv() 就能拿到这些配置了 load_dotenv() # 常量:Neo4j 数据库的连接地址 # bolt 是 Neo4j 专用的二进制通信协议,效率更高;localhost 表示本地服务;7687 是 Bolt 协议默认端口 NEO4J_URI = "bolt://localhost:7687" # 常量:Neo4j 登录用户名,默认初始用户名为 neo4j NEO4J_USERNAME = "neo4j" # 常量:Neo4j 登录密码,使用前需要替换成你自己本地数据库设置的密码 NEO4J_PASSWORD = "11111111" # 替换为你的密码 # 初始化大语言模型实例 llm,后面所有调用大模型的地方都用这个对象 llm = ChatOpenAI( # 注释掉的备选模型:如果有 qwen3.7-plus 权限,可以取消这行注释、注释下面一行来切换模型 # model="qwen3.7-plus", # 指定使用的模型名称,这里是通义千问的 plus 版本 model="qwen-plus", # 从环境变量中读取 API 密钥,对应 .env 文件里的 DASHSCOPE_API_KEY api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量中读取接口基础地址,因为通义千问兼容 OpenAI 协议,需要指定代理地址 base_url=os.getenv("DASHSCOPE_BASE_URL"), # 温度参数:控制大模型输出的随机性 # 调低到 0.15 的原因:知识提取需要准确、稳定,不能让大模型自由发挥、编造内容 # 温度越低,输出越确定、越保守;温度越高,创造性越强、越容易瞎编 temperature=0.15, # 调低温度从而让大模型根据文档生成内容,不让它乱编乱造 ) # 创建 Neo4j 图数据库连接实例 graph # 后续所有对图数据库的增删改查都通过这个对象来操作 graph = Neo4jGraph( url=NEO4J_URI, # 数据库连接地址 username=NEO4J_USERNAME, # 登录用户名 password=NEO4J_PASSWORD # 登录密码 ) # ========== 知识图谱提取提示词模板(核心规则载体) ========== # 整体定位:整个图谱提取环节的「规则说明书」,直接决定输出质量、格式合法性和入库可用性 # 核心目标:把大模型从「自由聊天的通用模型」约束成「标准化提取工具」 # 让大模型输入一段自然文本,稳定输出可直接解析、可直接入库的纯JSON数据 # 设计逻辑:按「定角色 → 给标准 → 立规则 → 强约束 → 给示例 → 重强调」的顺序层层约束 # 链路配合:本提示词 → llm大模型 → json_parser解析器 → extract_one_document组装 → Neo4j入库 # 提示词的约束强度,直接决定了整条自动化链路能不能稳定跑通 extraction_prompt = ChatPromptTemplate.from_messages([ # ==================== system 系统消息(全局固定规则) ==================== # 作用:给大模型设定永久生效的指令、标准、格式要求,所有请求都遵循同一套规则 # 内部分为7个核心模块,每个模块的设计逻辑如下: # 模块1:角色与任务定位 # 作用:划定领域范围(古典小说+西游记)和核心任务(提取实体+关系),避免输出跑偏 # 背后逻辑:大模型是通用模型,不限制领域会用通用百科标准提取,明确领域后会自动适配原著场景 # 比如能识别洞府、法宝、妖怪等原著特有实体,提取精准度更高 # 模块2:实体类型建议列表 # 作用:统一节点的 type 字段命名规范,全部采用英文标准类型 # 背后逻辑:如果不做限定,大模型对同一类实体会随机输出「人物/角色/Person」等多种命名 # 而Neo4j是按节点类型查询的,类型不统一会导致查不全,图谱直接废掉 # 英文类型完全兼容Neo4j和LangChain原生规范,避免中文编码、空格问题 # 加「不强制只用这些」是保留灵活性,遇到特殊实体可自行补充,不会漏掉信息 # 模块3:关系类型建议列表 # 作用:统一关系的命名和方向,避免同一种关系出现十几种不同表述 # 背后逻辑:自然语言里同一种关系有无数种说法(拜师/师徒/是徒弟),不统一会导致关系碎片化 # 最终图谱里同一种关系有多个type,节点之间连不起来,没法做关联查询 # 英文大写+下划线是Neo4j标准命名风格,后续写Cypher查询语句更方便 # 明确关系方向(比如徒弟→师父),避免正反颠倒导致逻辑混乱 # 模块4:五条核心提取规则(质量控制的核心) # 规则1「不脑补」:严格限定信息只能来自当前文本,防止大模型把自身知道的西游记常识加进去 # 保证图谱里的每一条数据都能追溯到原文片段,避免虚假信息 # 规则2「统一实体名」:解决实体对齐问题,同一个实体只用最通用的名称当id # 避免孙悟空/美猴王/齐天大圣变成三个独立节点,导致关系断裂 # 规则3「跨块一致」:适配文本分块提取的场景,保证不同chunk里的同一个实体命名统一 # 因为文本是切成小块独立提取的,大模型跨块没有记忆,必须反复强调一致性 # 命名统一后,Neo4j入库会自动合并同id节点,形成完整关联图谱 # 规则4「纯JSON」:强制输出纯JSON,不能有任何解释、markdown、客套话 # 因为后面接了JsonOutputParser自动解析,多一个字都会解析失败,整条链路中断 # 规则5「空内容返回空数组」:处理边界场景(比如纯环境描写、没有实体的chunk) # 避免大模型返回自然语言描述,导致解析报错 # 模块5:id字段强制要求 # 作用:强制符合LangChain Node对象和Neo4j节点的结构规范 # 背后逻辑:id是节点的唯一标识,漏了id程序会直接报错;别称放properties里是两全设计 # 既保留了实体的别名信息,又不破坏id的唯一性,查询时可以精确匹配也可以模糊匹配 # 模块6:输出格式示例 # 作用:给大模型提供具象的模仿模板,大幅提升格式准确率 # 背后逻辑:大模型对示例的遵循度远高于纯文字规则,只靠文字说格式很容易出错 # 给一个完整、字段齐全的示例,大模型会严格照着模板套,格式错误率会大幅下降 # 语法说明:双大括号{{}}是Python字符串模板的转义写法 # 因为单大括号{}是模板变量占位符,要输出真正的大括号字符就必须写两个转义 # 实际传给大模型的是正常的单大括号JSON格式 # 模块7:末尾重点重申 # 作用:把最核心的格式、命名要求再重复一遍,避免长提示词导致注意力稀释 # 背后逻辑:提示词越长,中间的内容越容易被大模型忽略,末尾重复核心要求能显著提升遵循度 ("system", """你是一个擅长从中文古典小说中提取知识图谱的专家。 请严格从以下文本中提取主要**实体**和**关系**,重点关注《西游记》相关内容。 实体类型建议(但不强制只用这些): Person(人、神、妖、仙)、Place(地点、山、洞府、天庭)、Item(法宝、兵器、宝贝)、Event(事件)、Group(组织、派系) 关系类型建议(常用): MASTER_OF, DISCIPLE_OF(师徒)、LOCATED_IN(位于)、OWNS(拥有)、USED_BY(使用)、ENEMY_OF(敌人)、BATTLE_WITH(战斗)、FROM(来自)、CREATED_BY(制造)、TRANSFORMED_INTO(变成)等 规则: 1. 只提取文本中明确出现或强烈暗示的信息,不要脑补。 2. 实体名称尽量使用原文最常见的叫法(例如:孙悟空 而非 美猴王,除非上下文只用了美猴王)。 3. 同一个实体在不同chunk中应尽量保持名称一致。 4. 输出**必须**是合法的 JSON,不要包含任何解释、注释、markdown。 5. 如果某段文本实在没有可提取内容,返回空数组。 重要:每个节点 **必须** 有 "id" 字段,且 "id" 是实体的主要名称(例如 "孙悟空"、"菩提祖师"、"斜月三星洞")。 如果有别名或中文名,可放在 properties 里的 "别称" 或 "中文名",但 "id" 必须是最常用的叫法。 输出格式(**严格**遵守,不要多一个字): {{ "nodes": [ {{"id": "孙悟空", "type": "Person"}}, {{"id": "菩提祖师", "type": "Person"}}, {{"id": "斜月三星洞", "type": "Place"}} ], "relationships": [ {{"source": "孙悟空", "target": "菩提祖师", "type": "DISCIPLE_OF"}}, {{"source": "孙悟空", "target": "斜月三星洞", "type": "LEARNED_AT"}} ] }} - "id" 是必须的,且全局唯一(同一个实体不同 chunk 用相同 id) - type 尽量用:Person, Place, Item, Group - 关系 type 用英文大写 + 下划线,如 DISCIPLE_OF, LOCATED_IN, OWNS, BATTLE_WITH 只返回纯 JSON。 """), # ==================== human 用户消息(动态输入槽) ==================== # 作用:每次调用时,把当前待处理的文本块填入 {text} 占位符,传给大模型 # 为什么分 system/human 两部分:这是大模型对话的标准格式 # system 是固定指令,human 是每次变化的输入内容 # 分开写比混在一个字符串里,大模型的指令遵循度更高,效果更好 ("human", "文本:\n{text}\n请提取。") ]) # 创建 JSON 输出解析器实例 # 和前面的提示词强绑定配合:提示词保证输出纯JSON,解析器负责把字符串转成Python可用的字典/列表 # 额外作用:自动校验JSON格式合法性,格式错误会直接报错,避免后续程序拿到脏数据崩溃 json_parser = JsonOutputParser() # 用管道符 | 串联成完整的图谱提取链(LCEL 语法,数据从左到右流动) # 完整执行流程: # 1. 把传入的 text 填入提示词模板,生成完整的对话消息 # 2. 调用大模型,按提示词规则提取实体和关系,输出JSON字符串 # 3. 解析器把JSON字符串转成Python字典,供后续代码处理 # 整条链的稳定性,完全依赖前面提示词的约束强度 extract_chain = extraction_prompt | llm | json_parser def extract_one_document(doc: Document) -> GraphDocument: """ 功能:处理单个文本块(Document),调用大模型提取出知识图谱,返回 GraphDocument 对象 入参说明: doc : Document 单个文本块文档对象,包含 page_content(文本内容)和 metadata(元数据) 返回值:GraphDocument 对象,包含提取到的节点列表、关系列表,以及原始来源文档 预期数据类型:GraphDocument 设计配合:严格依赖前面提示词输出的标准JSON格式,按固定字段解析节点和关系 """ # 调用提取链,传入当前文档的文本内容,得到大模型返回的解析后字典 raw = extract_chain.invoke({"text": doc.page_content}) # 校验返回结果是不是字典格式,不是的话说明提取失败,返回空的图谱文档 # 防止大模型返回了奇怪的格式,导致后面代码报错 if not isinstance(raw, dict): print("LLM 输出不是 dict,跳过该 chunk") return GraphDocument(nodes=[], relationships=[], source=doc) nodes = [] # 用来存储构建好的节点对象列表 node_map = {} # 字典:id → Node 对象,作用是去重,防止同一个实体被重复创建成多个节点 # 设计配合:对应提示词里「id全局唯一」的规则,依靠id来去重,保证同一个实体只有一个节点 # 遍历大模型返回的所有节点数据 for n in raw.get("nodes", []): # 取出节点的 id,也就是实体名称 nid = n.get("id") # 没有 id 的节点是无效的,直接跳过(对应提示词里「id必须有」的规则) if not nid: continue # 如果这个 id 已经存在于映射表里,说明重复了,跳过不重复创建 if nid in node_map: continue # 取出节点类型,取不到就默认是 Entity(实体) node_type = n.get("type", "Entity") # 取出节点的附加属性,取不到就默认空字典 props = n.get("properties", {}) # 创建 LangChainNode 节点对象,结构和提示词要求的格式一一对应 node = LangChainNode(id=nid, type=node_type, properties=props) # 存入映射表和结果列表 node_map[nid] = node nodes.append(node) relationships = [] # 用来存储构建好的关系对象列表 # 遍历大模型返回的所有关系数据 for r in raw.get("relationships", []): # 取出关系的起点实体 id、终点实体 id、关系类型 src_id = r.get("source") tgt_id = r.get("target") rel_type = r.get("type") # 三个字段缺一不可,缺了就跳过这条关系(对应提示词里的格式要求) if not (src_id and tgt_id and rel_type): continue # 如果起点或终点不在节点映射表里,说明节点不存在,这条关系是孤立无效的,跳过 if src_id not in node_map or tgt_id not in node_map: continue # 防止孤立关系 # 取出关系的附加属性 props = r.get("properties", {}) # 创建 LangChainRelationship 关系对象,必须传入真实的节点对象,而不是字符串 id rel = LangChainRelationship( source=node_map[src_id], # 起点节点对象 target=node_map[tgt_id], # 终点节点对象 type=rel_type, # 关系类型 properties=props # 关系属性 ) relationships.append(rel) # 组装成 GraphDocument 返回,同时带上原始来源文档,方便追溯 return GraphDocument( nodes=nodes, relationships=relationships, source=doc ) def ingest_data(file_path: str): """ 功能:完整的数据入库流程:读取本地文本文件 → 切分成小块 → 逐块提取知识图谱 → 批量写入 Neo4j 入参说明: file_path : str 本地文本文件的路径,比如 "西游记.txt" 返回值:无(直接把数据写入数据库) """ # 以只读模式打开文件,指定 utf-8 编码防止中文乱码,读完自动关闭文件 with open(file_path, "r", encoding="utf-8") as f: text = f.read() # 创建递归字符文本切分器,把长文本切成小块 # 为什么要切分:大模型能处理的 token 数有限,太长的文本一次处理不完,也容易提取不全 text_splitter = RecursiveCharacterTextSplitter( chunk_size=1200, # 每个文本块的最大字符数,1200 字左右适合提取知识图谱 chunk_overlap=200, # 相邻块之间重叠 200 字符,防止关键信息刚好在切割点被截断 # 分隔符优先级:从左到右依次尝试,优先按大的语义单元切分 # 先按双换行(段落)切,再按单换行(行)切,再按句号、逗号、空格切,最后硬切 separators=["\n\n", "\n", "。", ",", " ", ""] ) # 执行切分,得到字符串列表 chunks = text_splitter.split_text(text) # 把每个字符串转成 LangChain 的 Document 对象,方便后续统一处理 documents = [Document(page_content=c) for c in chunks] print(f"共切分为 {len(documents)} 个 chunk,开始提取图结构...") # 定义列表,存储所有提取成功的图文档 graph_documents: List[GraphDocument] = [] # 遍历每个文本块,逐个提取图谱 # enumerate 的第二个参数 1 表示序号从 1 开始计数 for i, doc in enumerate(documents, 1): # 每处理 10 个,或者处理到最后一个时,打印进度,让用户知道处理到哪了 if i % 10 == 0 or i == len(documents): print(f" 处理中... {i}/{len(documents)}") # 调用提取函数,得到图文档 gd = extract_one_document(doc) # 只有提取到了节点或者关系,才加入结果列表,空的就丢弃 if gd.nodes or gd.relationships: graph_documents.append(gd) print(f"提取到 {len(graph_documents)} 个有效 GraphDocument") # 如果有有效数据,就批量写入 Neo4j 数据库 if graph_documents: print("正在写入 Neo4j ...") # 调用 add_graph_documents 批量插入图谱数据 graph.add_graph_documents( graph_documents, # 要插入的图文档列表 baseEntityLabel=True, # 给所有节点都加上一个通用的 Entity 标签,方便全局查询 include_source=False # 不存储原始文本块(小说原文)节点,节省空间;如果需要追溯来源可以设为 True,上方的图中Document就是通过这里写True实现的 ) print("数据插入完成。") else: print("没有提取到任何节点/关系,跳过写入。") def get_graph_rag_chain(): """ 功能:构建并返回图数据库问答链(Graph RAG) 工作原理:用户提问 → 大模型把自然语言转成 Cypher 查询语句 → 去 Neo4j 查数据 → 把查询结果和问题一起交给大模型 → 生成自然语言回答 入参:无 返回值:GraphCypherQAChain 链对象,调用 invoke 即可提问 预期数据类型:GraphCypherQAChain """ # 刷新图数据库的 schema(结构信息),让大模型知道数据库里有哪些节点类型、关系类型 # 这样大模型才能生成正确的 Cypher 语句,这一步是图问答的前提 graph.refresh_schema() # 从大模型创建图问答链 chain = GraphCypherQAChain.from_llm( llm=llm, # 用来生成 Cypher 和最终回答的大模型 graph=graph, # 连接好的 Neo4j 图数据库 verbose=True, # 开启详细日志,会打印出生成的 Cypher 语句、查询结果,方便调试 allow_dangerous_requests=True, # 允许执行生成的 Cypher 语句 # 注意:生产环境要谨慎,因为可能有注入风险;本地测试可以开启 top_k=30, # 查询结果最多返回 30 条,防止结果太多撑爆大模型上下文 ) return chain # 主程序入口:只有直接运行这个文件时才会执行下面的代码,被导入时不执行 if __name__ == "__main__": # ========== 第一步:构建知识图谱(只需执行一次,重复执行会重复插入数据) ========== # 读取西游记.txt,提取图谱并写入 Neo4j ingest_data("西游记.txt") # ========== 第二步:创建问答链,开始提问 ========== rag_chain = get_graph_rag_chain() # 定义要测试的问题列表 questions = [ "孙悟空的师父是谁?他在哪里学艺?", "花果山在哪里", "为什么孙悟空被压在五行山下?", ] # 遍历每个问题,依次提问并打印结果 for q in questions: print(f"\n问题:{q}") # 调用问答链,传入查询问题 response = rag_chain.invoke({"query": q}) # 从返回结果中取出最终回答并打印 print(f"回答:{response['result']}")

更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)