
NLP基础 Llama(RMSNorm,SiLU,RoPE,GQA)
Llama-1
Meta推出的开源模型,在架构层引入了一些创新
- 前置归一化(Pre-Norm):将归一化步骤放在每个子层输入位置,提高训练稳定性。这类似GPT对decoder做的优化
- RMSNorm 替代 LayerNorm:减少归一化的计算开销。
- 使用 SiLU 激活函数:提升模型表达能力。
- 采用旋转位置编码(RoPE):更好处理相对位置信息。
RMSNorm
公式如下,可以发现和LayerNorm比,就是去掉了两个偏置项,一个是均值,一个是可训练参数β\betaβ,因为归一化主要是缩放到同一个数量级,所以有缩放项效果就很好了,去掉偏置项可以降低计算复杂度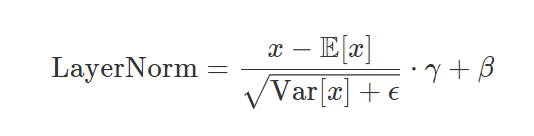
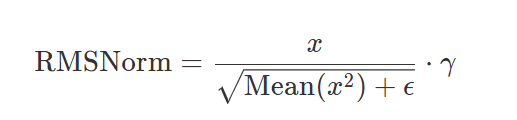
variance = x.pow(2).mean(-1, keepdim=True)均方差,保持维度是为了防止mean接口压成一个元素rms = torch.rsqrt(variance + self.eps)rsqrt是开方并取倒数,比手动计算这两步要快,相当于提供了一个优化过的融合算子self.weight = nn.Parameter(torch.ones(normalized_shape))缩放因子是唯一的可学习参数,需要声明
class RMSNorm(nn.Module):
def __init__(self, normalized_shape: int, eps: float = 1e-6):
"""
RMSNorm 的 PyTorch 实现
:param normalized_shape: 需要做归一化的维度大小(通常是模型的 hidden_dim)
:param eps: 防止除以 0 的极小值
"""
super().__init__()
self.eps = eps
# 只有可学习的缩放参数 gamma(weight),没有平移参数 beta (bias)
self.weight = nn.Parameter(torch.ones(normalized_shape))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 1. 计算输入 x 的类型,保证混合精度训练(如 fp16/bf16)时计算平方的稳定性
input_dtype = x.dtype
x = x.to(torch.float32)
# 2. 算均方根:RMS = sqrt( mean(x^2, dim=-1, keepdim=True) + eps )
# 通常在大模型中,归一化是在最后一个维度(hidden_dim)进行
variance = x.pow(2).mean(-1, keepdim=True)
rms = torch.rsqrt(variance + self.eps)
# 3. 归一化并恢复到原始数据类型,最后乘上可学习参数 weight
return (x * rms).to(input_dtype) * self.weight
SiLU
函数定义如下,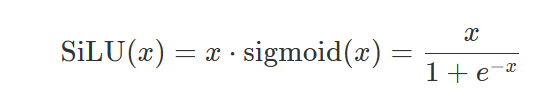
函数图像如下,远离0时接近于ReLU,也就是负数接近于0,正数接近于y=x,接近0时,函数是连续的,不像ReLU一样在0是一个间断点,更有利于训练时导数计算。
代价是计算略复杂,但还可以接受,因为激活函数本来也不是LLM前向传播中的大头。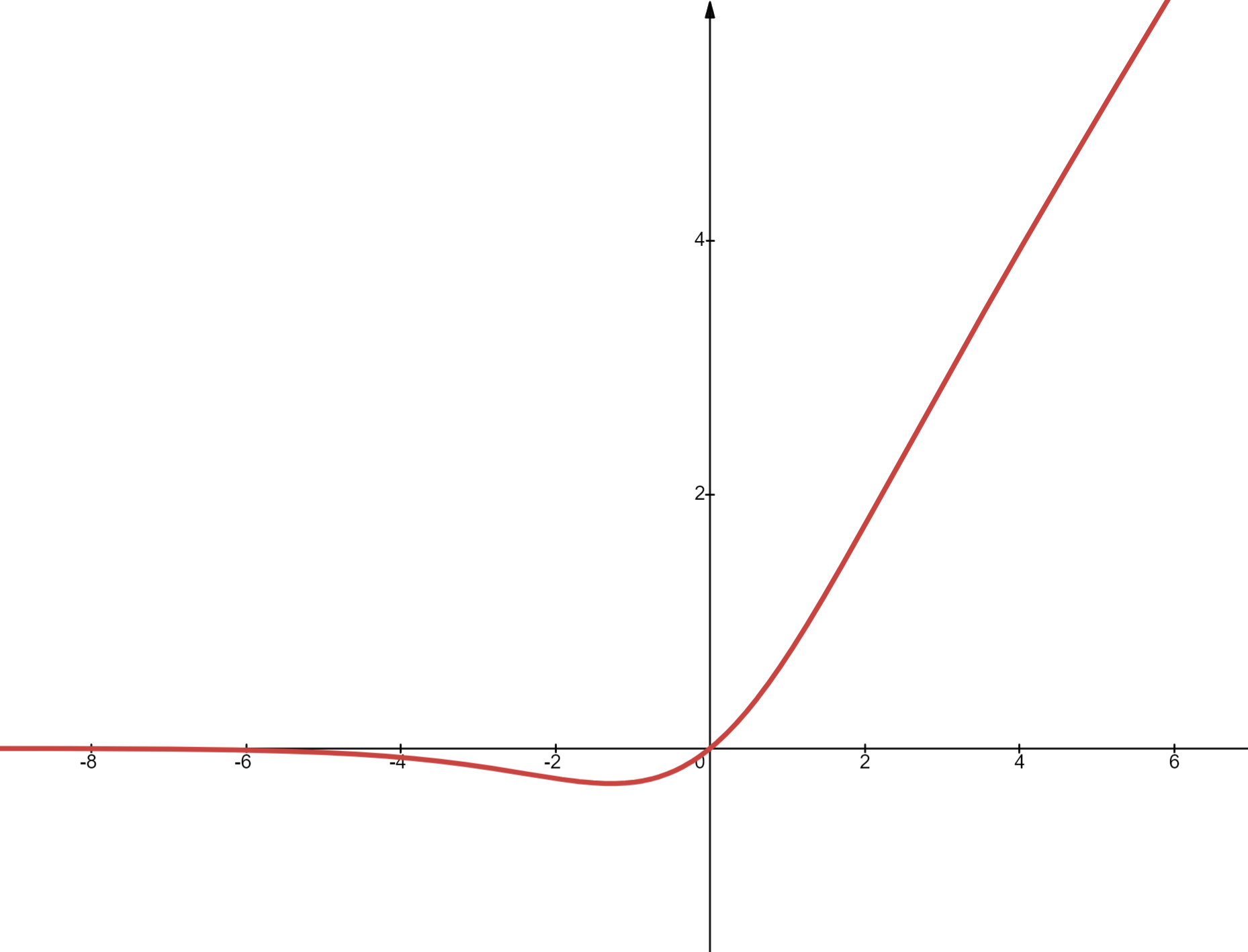
可以直接调用torch内置接口silu_layer = nn.SiLU(),也可以实现如下
class CustomSiLU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 公式:x * sigmoid(x)
return x * torch.sigmoid(x)
RoPE
数学基础
对于一个向量x=[x,y]T\mathbf{x} = [x, y]^Tx=[x,y]T,可以写成 x=rcosϕx = r \cos\phix=rcosϕy=rsinϕy = r \sin\phiy=rsinϕ
如果我们把它旋转一个角度θ\thetaθ,角度变成ϕ+θ\phi+\thetaϕ+θ,可以和差化积展开
x′=rcos(ϕ+θ)=rcosϕcosθ−rsinϕsinθx' = r \cos(\phi + \theta) = r\cos\phi\cos\theta - r\sin\phi\sin\thetax′=rcos(ϕ+θ)=rcosϕcosθ−rsinϕsinθy′=rsin(ϕ+θ)=rsinϕcosθ+rcosϕsinθy' = r\sin(\phi + \theta) = r\sin\phi\cos\theta + r\cos\phi\sin\thetay′=rsin(ϕ+θ)=rsinϕcosθ+rcosϕsinθ
把前面的 x=rcosϕx = r \cos\phix=rcosϕ 和 y=rsinϕy = r \sin\phiy=rsinϕ 代入进去,可以消掉 rrr 和 ϕ\phiϕ:
x′=xcosθ−ysinθx' = x\cos\theta - y\sin\thetax′=xcosθ−ysinθy′=ycosθ+xsinθy' = y\cos\theta + x\sin\thetay′=ycosθ+xsinθ
这个表达式可以写成矩阵乘上原始向量
(x′y′)=(cosθ−sinθsinθcosθ)(xy)\begin{pmatrix} x' \\ y' \end{pmatrix} = \begin{pmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{pmatrix} \begin{pmatrix} x \\ y\end{pmatrix}(x′y′)=(cosθsinθ−sinθcosθ)(xy)
于是中间这个矩阵 Rθ=(cosθ−sinθsinθcosθ)R_\theta = \begin{pmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{pmatrix}Rθ=(cosθsinθ−sinθcosθ),就是二维空间旋转操作的矩阵
应用到位置编码
之前做过的三角函数编码,就是利用了三角函数的周期性,这里旋转操作也有周期性,也可以用来编码,只要通过控制不同位置的token的三角函数模长,就能区分不同位置。
对于第 mmm 个位置的二维向量 q\mathbf{q}q,乘以旋转矩阵 RΘ,m2R_{\Theta, m}^2RΘ,m2:
qm=RΘ,m2q=(cosmθ−sinmθsinmθcosmθ)(q0q1)\mathbf{q}_m = R_{\Theta, m}^2 \mathbf{q} = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} q_0 \\ q_1 \end{pmatrix}qm=RΘ,m2q=(cosmθsinmθ−sinmθcosmθ)(q0q1)
这里m就是token的位置,也是模长。并且这里我们以二维向量为例
推广到高维
词嵌入实际不会是2维的,可能有几千维,比如d=4096。
此时的旋转如果严格按照二维的情况推广,是在一个4096维的高维空间旋转,旋转矩阵是一个(4096,4096)的稠密矩阵,计算太复杂。
一个简单的做法是,把维度两两绑定,每一组看成一个二维向量,在二维空间上旋转,这样我们只用维护d/2个(2,2)的旋转矩阵乘法,计算量大大减少
这也被称为分块(Block-diagonal)旋转。写成巨型矩阵的形式,它是一个分块对角矩阵:RΘ,md=(cosmθ1−sinmθ100⋯00sinmθ1cosmθ100⋯0000cosmθ2−sinmθ2⋯0000sinmθ2cosmθ2⋯00⋮⋮⋮⋮⋱⋮⋮0000⋯cosmθd/2−sinmθd/20000⋯sinmθd/2cosmθd/2)R_{\Theta, m}^d = \begin{pmatrix} \cos m\theta_1 & -\sin m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ \sin m\theta_1 & \cos m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos m\theta_2 & -\sin m\theta_2 & \cdots & 0 & 0 \\ 0 & 0 & \sin m\theta_2 & \cos m\theta_2 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2} & -\sin m\theta_{d/2} \\ 0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2} & \cos m\theta_{d/2} \end{pmatrix}RΘ,md= cosmθ1sinmθ100⋮00−sinmθ1cosmθ100⋮0000cosmθ2sinmθ2⋮0000−sinmθ2cosmθ2⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cosmθd/2sinmθd/20000⋮−sinmθd/2cosmθd/2
实现
再具体实现上,不会去真的计算这个巨型稀疏矩阵的矩阵乘法,里面大部分元素都是0,做矩阵乘法浪费算力了
但也不会手动遍历然后计算,那样并行度不高。
在代码中,通常会把 词向量 复制一份,然后把相邻的奇偶维度(或者前半部分和后半部分)交错取反并两两对调(在很多源码中这个函数叫 rotate_half)。
假设向量 q=[q0,q1,q2,q3]\mathbf{q} = [q_0, q_1, q_2, q_3]q=[q0,q1,q2,q3],我们预先计算好对应的 cos\coscos 和 sin\sinsin 向量(形状和 q\mathbf{q}q 完全一样):cos_vec=[cosθ1,cosθ1,cosθ2,cosθ2]\cos\_vec = [\cos\theta_1, \cos\theta_1, \cos\theta_2, \cos\theta_2]cos_vec=[cosθ1,cosθ1,cosθ2,cosθ2]sin_vec=[sinθ1,sinθ1,sinθ2,sinθ2]\sin\_vec = [\sin\theta_1, \sin\theta_1, \sin\theta_2, \sin\theta_2]sin_vec=[sinθ1,sinθ1,sinθ2,sinθ2]
我们再构造一个交错对调取反的向量 q~\tilde{\mathbf{q}}q~:q~=[−q1,q0,−q3,q2]\tilde{\mathbf{q}} = [-q_1, q_0, -q_3, q_2]q~=[−q1,q0,−q3,q2]
那么整个旋转矩阵乘法,在硬件底层就被完美简化为了两次逐元素相乘和一次相加:qrotated=q⊙cos_vec+q~⊙sin_vec\mathbf{q}_{\text{rotated}} = \mathbf{q} \odot \cos\_vec + \tilde{\mathbf{q}} \odot \sin\_vecqrotated=q⊙cos_vec+q~⊙sin_vec
逐元素相乘相加都是高度优化的算子,可以直接调用。
在具体实现 rotate_half 时,业界有两种主流的内存切分方式,它们在数学上完全等价,只是切分维度的习惯不同:
-
方式 A:相邻奇偶维度交错(如 GPT-NeoX, DeepSeek)把相邻的第 2i2i2i 和 2i+12i+12i+1 维当成一个二维平面:q~=[−q1,q0,−q3,q2,…,−qd,qd−1]\tilde{\mathbf{q}} = [-q_1, q_0, -q_3, q_2, \dots, -q_d, q_{d-1}]q~=[−q1,q0,−q3,q2,…,−qd,qd−1]特点: 逻辑上最直观,符合分块对角矩阵的排布。但在 GPU 内存连续性上,频繁做临近元素的 stride 交换需要精心优化。
-
方式 B:前后半段拆分(如 Meta LLaMA 官方实现)把长度为 ddd 的向量从中间一刀切开,前半段(前 d/2d/2d/2 维)作为所有二维平面的 xxx 坐标,后半段(后 d/2d/2d/2 维)作为 yyy 坐标:q~=[−qd/2,…,−qd, q0,…,qd/2−1]\tilde{\mathbf{q}} = [-q_{d/2}, \dots, -q_d, \; q_0, \dots, q_{d/2-1}]q~=[−qd/2,…,−qd,q0,…,qd/2−1]特点: 对 GPU 极其友好。在 PyTorch 中,你只需要写 torch.cat((-q[…, d//2:], q[…, :d//2]), dim=-1)。由于切分边界非常干净,在底层可以实现非常漂亮的合并内存访问(Coalesced Memory Access)。
-
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float() / self.dim))一个token向量内,不同元素的相位不同 -
t = torch.arange(seq_len, device=self.inv_freq.device, dtype=self.inv_freq.dtype)不同位置的模长不同 -
freqs = torch.outer(t, self.inv_freq)模长和相位向量做外积,得到一个max_seqlen行,每行dim/2的角度矩阵 -
freqs = torch.outer(t, self.inv_freq)后面拼接,变成(seqlen,dim) -
self.register_buffer("cos_cached", emb.cos(), persistent=False)对sin cos矩阵缓存,初始算出来最大的max_seqlen对应的矩阵,后面每次都会调用这个矩阵的一个切片。这里用bufffer保存是因为.to(‘cuda’)时只会把parameter对象和register_buffer对象拷贝到GPU上加速计算,普通成员会被留在CPU。而声明成parameter的问题是会在导出时被保存到硬盘,但这个sin,cos不属于可训练参数,不需要保存。 -
cos = self.cos_cached[:seq_len, :].to(dtype=q.dtype).unsqueeze(0).unsqueeze(1)前向传播时,对预计算的sin cos切片取钱seqlen行 -
q_embed = (q * cos) + (rotate_half(q) * sin最后直接张量逐元素乘法,加法
def rotate_half(x: torch.Tensor) -> torch.Tensor:
"""
将向量的最后一维从中间一刀切开:[前一半, 后一半]
返回: [-后一半, 前一半]
用于配合 cos 和 sin 实现复数旋转的代数展开
"""
half_dim = x.shape[-1] // 2
x1 = x[..., :half_dim]
x2 = x[..., half_dim:]
return torch.cat((-x2, x1), dim=-1)
class RotaryPositionEmbedding(nn.Module):
def __init__(self, dim: int, max_position_embeddings: int = 4096, base: int = 10000):
"""
RoPE 位置编码模块
:param dim: 每个 Attention Head 的维度 (head_dim),必须是偶数
:param max_position_embeddings: 支持的最大序列长度 (Context Window)
:param base: 预设的底数位置频率(默认 10000)
"""
super().__init__()
self.dim = dim
self.max_position_embeddings = max_position_embeddings
self.base = base
# 1. 计算位置编码的频率序列 theta_i = base ^ (-2i / d)
# shape: [dim // 2]
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float() / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
# 2. 预先计算最大长度内的 cos 和 sin 矩阵并缓存
self._set_cos_sin_cache(max_position_embeddings)
def _set_cos_sin_cache(self, seq_len: int):
# 创建绝对位置索引 t = [0, 1, 2, ..., seq_len-1]
t = torch.arange(seq_len, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
# 外积计算所有位置在各个频段的角度 m * theta
# shape: [seq_len, dim // 2]
freqs = torch.outer(t, self.inv_freq)
# 将其复制拼接成完整的 head_dim 长度
# shape: [seq_len, dim]
emb = torch.cat((freqs, freqs), dim=-1)
# 缓存 cos 和 sin 结果
self.register_buffer("cos_cached", emb.cos(), persistent=False)
self.register_buffer("sin_cached", emb.sin(), persistent=False)
def forward(self, q: torch.Tensor, k: torch.Tensor, seq_len: int) -> Tuple[torch.Tensor, torch.Tensor]:
"""
前向传播:对 q 和 k 实施原地旋转
q, k 期望的 shape: [batch_size, num_heads, seq_len, head_dim]
"""
# 如果动态输入的 seq_len 超过了缓存长度,动态扩展缓存(外推/内插的切入点)
if seq_len > self.cos_cached.shape[0]:
self._set_cos_sin_cache(seq_len)
# 截取当前序列长度所需的 cos 和 sin
# shape: [seq_len, head_dim] -> 广播至 [1, 1, seq_len, head_dim]
cos = self.cos_cached[:seq_len, :].to(dtype=q.dtype).unsqueeze(0).unsqueeze(1)
sin = self.sin_cached[:seq_len, :].to(dtype=q.dtype).unsqueeze(0).unsqueeze(1)
# 核心代数公式:q * cos + rotate_half(q) * sin
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
有效性
旋转位置编码的优势是,计算qkTqk^TqkT时,结果不仅包含q,k真实元素值,还能包含qk两个向量在token中的位置差信息。
比如对于第m行的q,第n个的k
qm=qRmq_m = qR_mqm=qRmkn=kRnk_n = kR_nkn=kRn
两向量相乘(点积),写成矩阵乘法形式:
’qmknT=(qRm)(kRn)Tq_m k_n^T = (qR_m) (kR_n)^TqmknT=(qRm)(kRn)T
利用矩阵转置公式 (AB)T=BTAT(AB)^T = B^T A^T(AB)T=BTAT,把左边的括号拆开:
qmknT=qRmRnTkTq_m k_n^T = qR_m R_n^Tk^TqmknT=qRmRnTkT
旋转矩阵 RnR_nRn 是正交矩阵,它有一个绝妙的性质:转置等于逆矩阵,即逆时针旋转 nnn 度的转置,等价于顺时针旋转 nnn 度:
把这个性质代入原式:qmknT=qRmR−n⏟连续旋转kTq_m k_n^T = q \underbrace{R_{m} R_{-n}}_{\text{连续旋转}} k^TqmknT=q连续旋转 RmR−nkT
先逆时针转 mmm 度,再顺时针转 nnn 度,结果等于直接逆时针转 m−nm - nm−n 度:
qmknT=qRm−nkTq_m k_n^T = qR_{m-n}k^TqmknT=qRm−nkT
于是在最终结果中,绝对位置无关了,只和相对位置m-n有关,并且和初始值q,k有关,这实现了位置编码的初衷:编码中附带相对位置信息
设计思想
看完架构创新了来看看设计思想,Llama的论文标题是Open and Efficient Foundation Language Models,(《开放高效的基础语言模型》),有两个关键词,Open和Efficient
- 开放(Open),为了填补开源模型的空缺。事实证明这个策略是成功的,很长一段时间Llama是唯一能抗衡GPT的开源模型,初代Llama-1就能达到GPT-3的水平,给meta在LLM时代得到了一波大曝光
- 高效(Efficient)指的是他们利用scaling law的方式是增加训练数据,而不是增大模型参数,从1-3都有参数量不超过10B的版本,增加的是训练数据量。这有点反直觉,因为一般的小参数量模型初期学习快,后期学习慢,想让小模型达到大模型同样的能力,需要更大的训练数据量,这对训练来说是不划算的,如下图
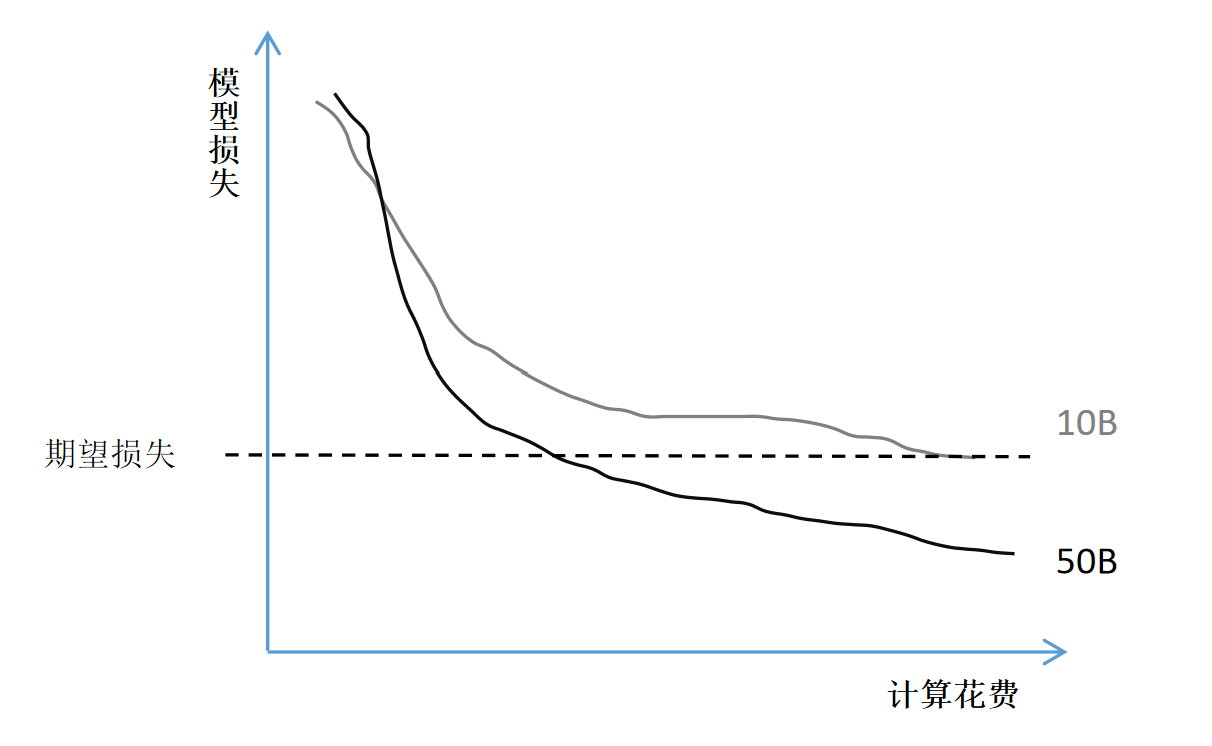
但是meta的考虑是,训练只用做一次,推理则可能被用户做无数次,而Llama是一个开源模型,要注重用户体验,所以选择缩小参数量,初代只有7B和65B两个版本,降低推理开销,让更多普通用户能跑起来Llama,增强模型能力只通过增大训练数据量来实现。事实证明这是对的,一方面用户体验很好,让Llama大受欢迎,另一方面,限制参数量增加训练数据,也能让模型性能持续提升,例如,尽管原有经验建议 10B 参数模型使用 2000 亿 token,Meta 实验发现,即便 7B 模型使用 1 万亿 token,性能依然在持续提升。
Llama-2
概述
模型参数,基本没有增加,只有7B,13B,70B三个版本和前代差不多,但是训练数据增加了,从1T增加到2T,这正是Llama-1训练策略的延续
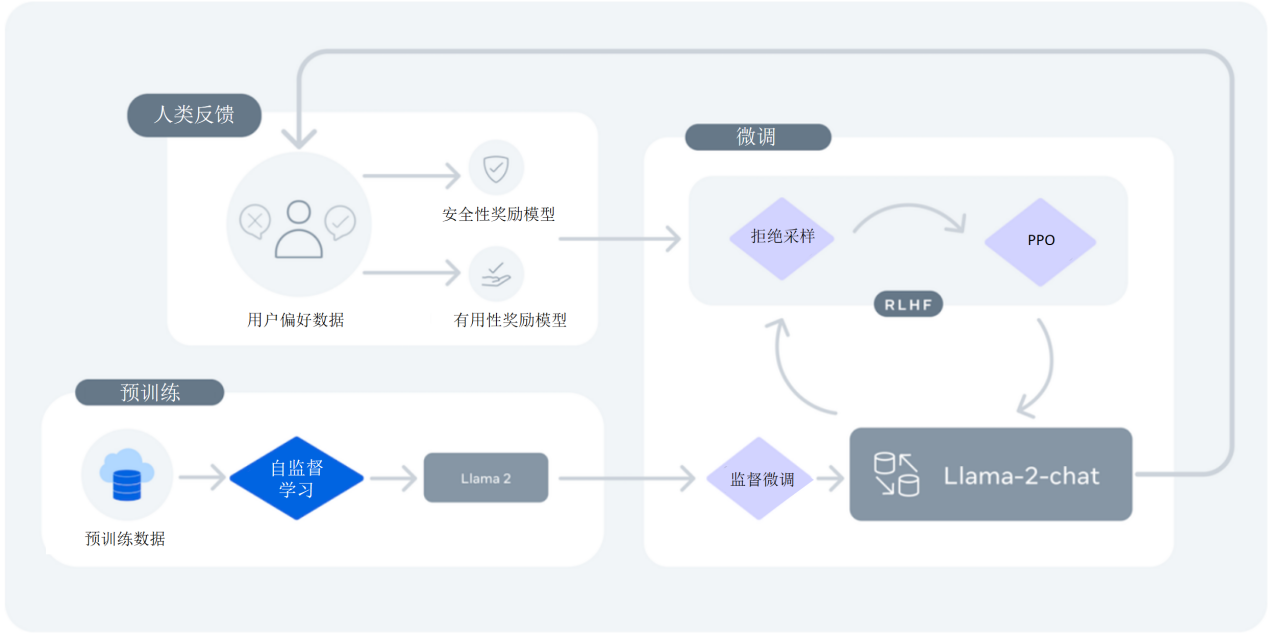
对齐
为了对标chatgpt的指令遵循,对话能力,Llama也开始了后训练,也就是SFT,RM,RL三阶段。整体模型训练思路如下:
- 监督微调(Supervised Fine-tuning, SFT),喂2T数据过程,无监督自回归训练。模型学到了海量的知识,但不会和人对话,不听人讲话,基本自言自语
- 监督微调(Supervised Fine-tuning, SFT),用少量的对话数据做微调,对话的回答被视为数据标注,也就是这个环节是有监督,有标准答案的,让模型初步学一下如何对话
- 奖励模型训练(Reward Modeling,让人类对回答排序,然后用排序数据作为标注,训练一个奖励模型,类似于RL(强化学习)里actor-critic的critic,负责在RL阶段给模型的输出打分
- 强化学习(Reinforcement Learning),基于上一阶段训练的奖励模型,做强化学习训练,继续学如何遵循指令,与人对话
GQA(分组查询注意力)
架构创新主要是分组查询注意力,如图,最开始的MHA把QKV矩阵竖着(在dim维度)切成多份,分别计算注意力然后最后拼接,这样的KV cache开销太大
于是一个优化时MQA多查询注意力,Q仍然分多头,KV只保留一个头,然后这一个KV头处理所有不同Q头的询问,最后注意力结果仍然拼接起来,这样是省显存了,但是效果太差了
GQA不是Llama而是谷歌提出的,但是Llama是第一个用GQA大规模训练的模型,思想是最MHA和MQA做个折中,让几个Q头为一组,组内共享一个KV头,这样减少了显存,也保持了一定的模型能力
在实现上,降低Wk,WvW_k,W_vWk,Wv矩阵的输出维度,生成的头数就减少了。也就线性层的输出特征维度降低,比如Q线性层输出维度128,分8个头每个16,KV头只有4个,每个大小也要是16,那么就让KV的线性层输出直接是64,这样再分4个头,每个头维度和Q头一样都是16
最后每组内通过广播机制,让一个KV头和多个Q头计算,相当于每个Q头仍然和MHA一样都能对应一个KV头,只是一组内对应的KV头参数完全一样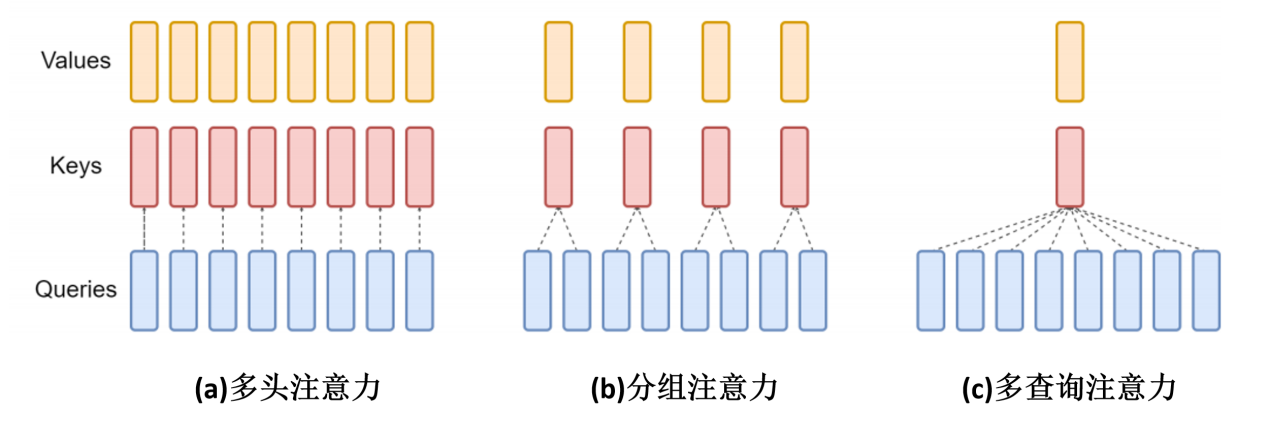
效果
实验表明在2T的数据量下,模型仍然欠拟合,小模型大训练的思路是对的,于是Llama3继续增大数据量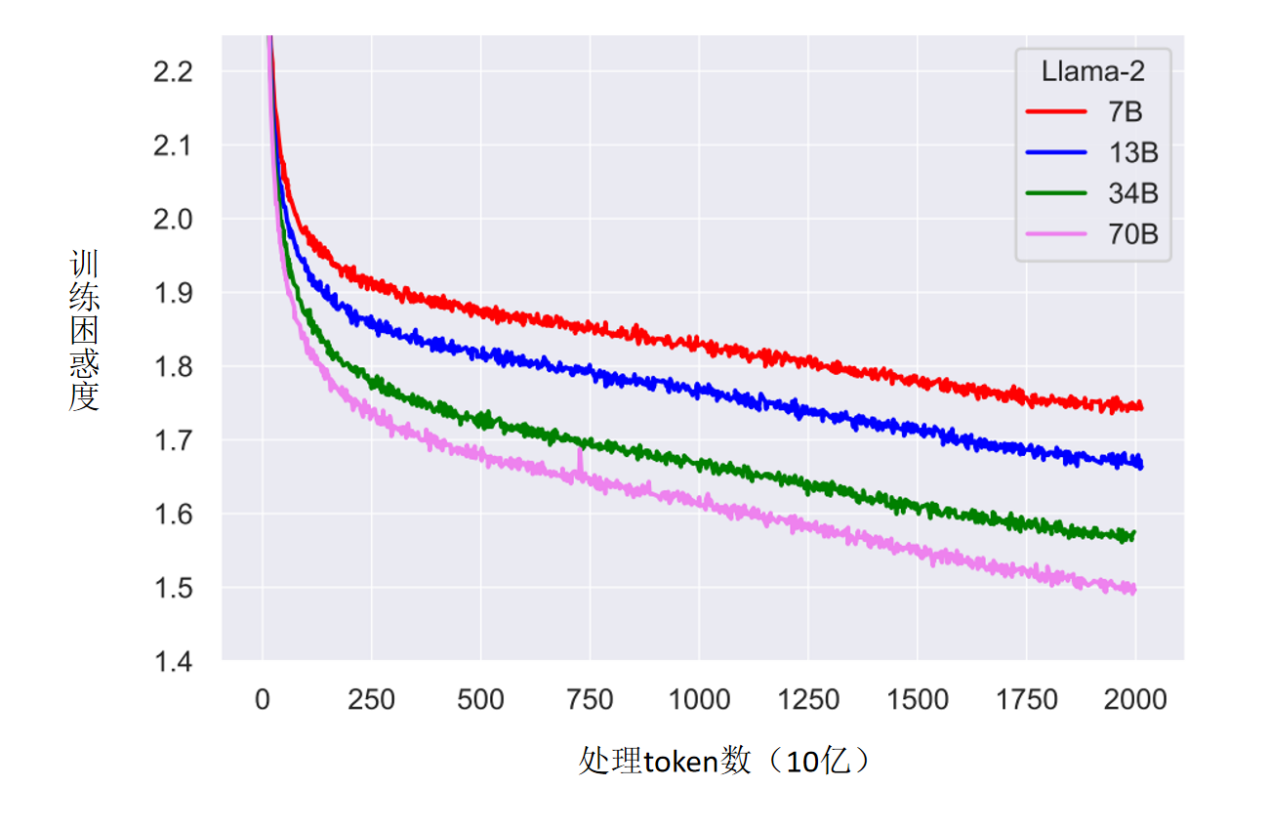
Llama-3
概述
数据量有更大的版本了,但仍然保持了小版本,分别有8B,70B,400B版本,对标GPT-4,相比Llama-2性能有了大的飞跃。这得益于训练数据从2T提升到了15T。
微调
微调阶段使用的是
- 监督微调(SFT)
- 拒绝采样(Rejection Sampling)
- 直接偏好优化(DPO)
这里DPO是为了降低PPO保存actor critic的显存占用,优化架构直接计算reward,D就是direct的意思
RS是为了适配DPO引入的类似原有的RM(奖励模型)的结构
多模态
Llama3.2增加了多模态能力,支持视觉输入,训练方式是在训练好的文本模型基础上,增加图像编码器,训练时冻结文本模型参数,只训练图像编码器。
Llama-4
概述
参数量相比前代终于增加了,有108B,400B,2T版本,但这一代引入了MoE架构,MoE的特点是实际激活比总参数量要少很多,为了让值激活一部分也能起到较好的效果,总参数量会增加。这几个版本的激活参数量只有17B,17B,260B,还是不多。重点是训练数据量,估计有40T,相比之前又大幅提升
原生多模态
和3的微调视觉能力不同,4在最开始的架构上就有视觉输入,视觉和文本一起训练
Agent能力
4训练时claude code等工具已经诞生,所以模型训练时就考虑了agent能力,包括工具调用,任务规划
思考能力
同样是训练过程中,Deepsek-R1还有GPT o3的爆火,让Llama也引入了慢思考,思维链能力
走向落寞
Llama-3在24年3月推出,本来接下来应该按部就班训个GPT-4这样的文本模型,但是到25年4月推出Llama4这一年内,出现了GPT-4o的多模态,claude code的Agent能力,GPT-o3,Deepseek-R1的思维链慢思考模型,导致Llama-4频繁补课,训练进度一拖再拖,最后匆忙发布,打榜分数虽然很好看,但是被爆根本没训好,打榜分数有造假嫌疑。
叠加上原本就很大的开源成本压力,meta从商业,技术角度考虑,转向了闭源,Llama-4成为了meta开源的最后辉煌。转入闭源后meta昏招频出,解雇lecun,关闭原有的研究性质试验室,成立商业化LLM部门,交给一个初出茅庐的数据标注公司CEO Alex Wang掌管,此后在下坡路上油门猛踩,如今过去一年了,到了2026年6月还没有拿出一个合格的下一代模型。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)