
java垃圾回收之G1
深入理解 G1 垃圾回收器:从原理到实践
本文面向中级 Java 开发者,全面剖析 G1(Garbage-First)垃圾回收器的核心原理、内存模型、回收过程、调优参数与实战经验。文末附 G1 vs CMS vs ZGC 选型对比。
目录
- 第 1 章:什么是 G1 垃圾回收器
- 第 2 章:G1 的核心思想 —— Region 内存模型
- 第 3 章:G1 的核心数据结构
- 第 4 章:G1 的完整回收过程
- 第 5 章:G1 的 Young GC 与 Mixed GC
- 第 6 章:G1 调优参数详解
- 第 7 章:G1 vs CMS vs ZGC 对比
- 第 8 章:G1 的优缺点总结
第 1 章:什么是 G1 垃圾回收器
1.1 GC 的历史背景与挑战
在 Java 应用的早期阶段(Java 6 之前),主流的垃圾回收器是 Parallel GC 和 CMS(Concurrent Mark Sweep)。它们各自有明显缺陷:
- Parallel GC:吞吐量优先,但会触发 Stop-The-World(STW) 的 Full GC,停顿时间随堆增大而显著增加。
- CMS:以低延迟为目标,回收阶段与应用线程并发执行,但容易产生 内存碎片,且在 JDK 9 已被废弃。
随着大内存(>8GB)堆的普及以及云原生场景对 可预测停顿时间 的强烈需求,JVM 迫切需要一种:
- 停顿时间可预测(软实时)
- 内存整理(无碎片)
- 大堆友好的新型 GC
这就是 G1 诞生的背景。
1.2 G1 的诞生与名称由来
G1(Garbage-First)由 Sun Microsystems 在 JDK 6 中首次以实验性方式引入,目标是取代 CMS。它的设计哲学有两个关键点:
- 化整为零:将整个堆划分成大量大小相等的 Region,每个 Region 独立管理(独立分配、回收)。
- 优先回收垃圾最多的 Region(即"Garbage-First"):G1 会跟踪每个 Region 中的垃圾量,优先回收垃圾占比最高的 Region,从而以最小代价回收最多空间。
G1 的核心思想可以类比为"打扫卫生":与其把整个房子彻底打扫一遍(Full GC),不如先打扫最脏的房间(垃圾最多的 Region),逐步推进。
1.3 G1 在 JDK 版本中的演进时间线
| JDK 版本 | 里程碑事件 |
|---|---|
| JDK 6u14 | G1 首次以实验性方式发布(-XX:+UseG1GC) |
| JDK 7u4 | G1 正式商用(推荐在堆 >4GB 时使用) |
| JDK 8 | G1 性能显著提升(字符串去重、并发类卸载) |
| JDK 9 | G1 成为 32/64 位 server 模式默认 GC,取代 Parallel GC |
| JDK 10 | 并发标记线程并行化,提高标记效率 |
| JDK 11 | 并发卸载、NUMA 感知、巨页支持 |
| JDK 12 | 增量回收 Abortable Mixed GC(提升停顿预测性) |
| JDK 14 | 支持 JFR 事件(jdk.G1Phase 等) |
| JDK 15 | ZGC / Shenandoah 成熟,但 G1 仍是默认 |
1.4 G1 的设计目标
G1 的核心设计目标可以归纳为四点:
- 可预测的停顿时间:通过
-XX:MaxGCPauseMillis(默认 200ms)参数设定目标停顿时间,G1 会尽量满足。 - 高吞吐:在满足停顿目标的前提下,最大化应用吞吐量。
- 避免 Full GC:通过增量回收(Incremental Collection)减少 Full GC 触发。
- 大堆支持:相比 CMS,G1 在 32GB+ 堆上仍能保持良好性能。
第 2 章:G1 的核心思想 —— Region 内存模型
2.1 化整为零的堆划分
G1 抛弃了传统 GC 连续内存分区(年轻代、老年代物理连续)的设计,将整个 Java 堆划分为 约 2048 个大小相等的 Region(个数可上下调整),每个 Region 大小在 1MB ~ 32MB 之间(2 的 N 次幂)。
Region 大小计算公式:
Region 大小 = 堆大小 / 2048(向上取整到 2 的幂)
例如:
- 4GB 堆 → Region 大小 = 2MB(4096 / 2048 = 2)
- 8GB 堆 → Region 大小 = 4MB
- 16GB 堆 → Region 大小 = 8MB
- 32GB 堆 → Region 大小 = 16MB
可通过 -XX:G1HeapRegionSize 手动指定。
2.2 Region 的类型
每个 Region 在运行时会被标记为以下 5 种类型之一:
| 类型 | 颜色标记 | 作用 |
|---|---|---|
| Eden | 🟢 浅绿 | 存放新创建的对象 |
| Survivor | 🟡 浅黄 | 存放 Young GC 存活的对象 |
| Old | 🔵 浅蓝 | 存放长期存活的对象 |
| Humongous | 🔴 浅红 | 存放大对象(专门区域) |
| Free | ⚪ 浅灰 | 未分配区域 |
关键特点:Region 的角色(Eden/Survivor/Old)不是固定的,可以根据回收需要动态调整。
下图展示了 8GB 堆(2048 个 4MB Region)的内存布局: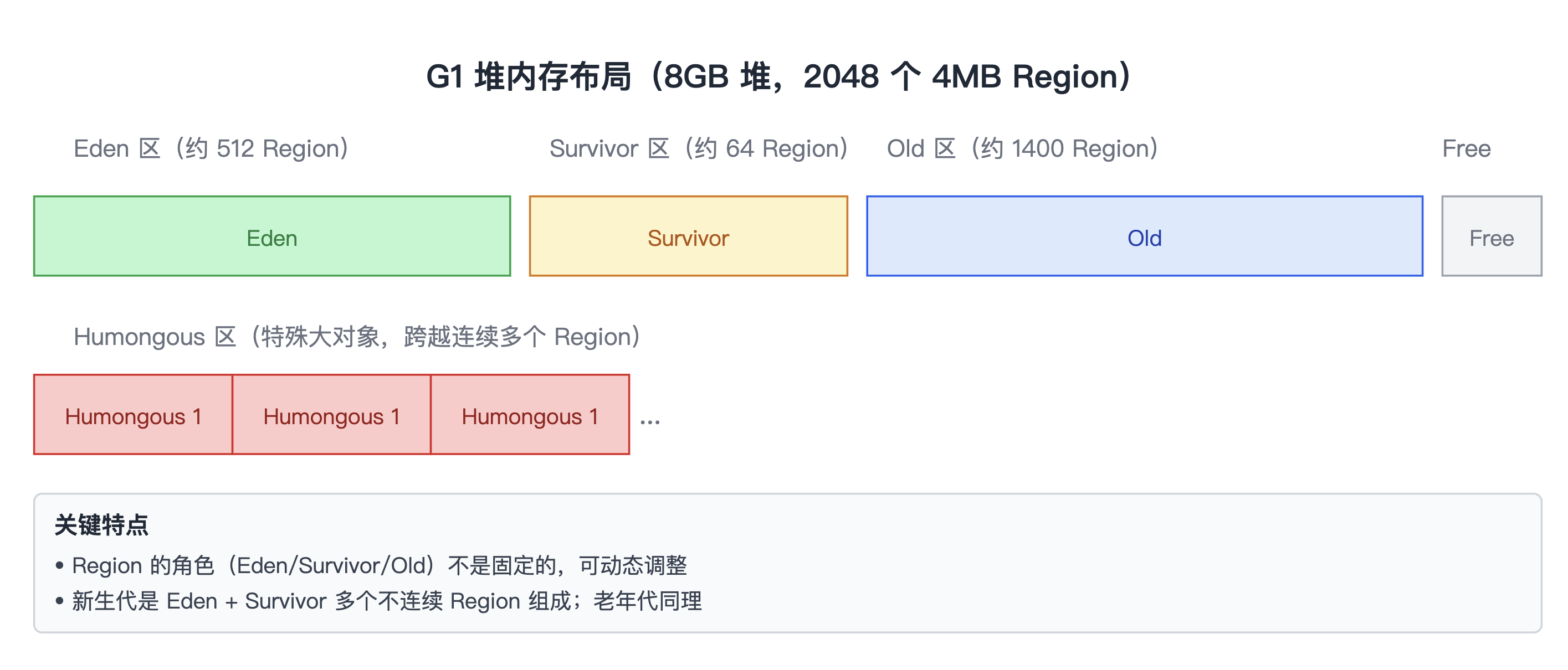
G1 堆内存布局(8GB 堆,2048 个 4MB Region)
2.3 Humongous 大对象分配机制
大对象(Humongous Object) 指大小超过 Region 容量 50% 的对象(例如 4MB Region 中 >2MB 的对象)。
G1 对大对象的处理有别于普通对象:
- 特殊分配区域:大对象会被分配到连续的多个 Humongous Region 中。
- 直接进入老年代:Humongous 对象在分配时就直接进入"老年代"区域,不会经历 Young GC。
- 回收时机特殊:只有在并发标记 + Mixed GC 阶段或 Full GC 时才可能被回收。
- 容易导致问题:频繁的大对象分配会快速填满老年代,触发并发标记失败 → 退化为 Full GC。
2.4 内存布局总结
通过 Region 模型,G1 实现了:
- 空间连续性 → 逻辑连续:物理内存是 Region 化的,但逻辑上仍可视为分代。
- 可压缩空间:回收时直接拷贝存活对象到新 Region,原 Region 整体释放,无碎片。
- 可预测停顿:根据 Region 回收成本估算,可以选出一组 Region 在指定时间内回收。
第 3 章:G1 的核心数据结构
G1 高效运行依赖三个核心数据结构:RSet、CSet 和 SATB。
3.1 RSet(Remembered Set 记忆集)
RSet 是 G1 最重要的数据结构之一,用于记录"其他 Region 中的对象对本 Region 对象的引用"。
为什么需要 RSet?
在传统 GC 中,回收一个分区(如年轻代)时,需要扫描整个老年代来找到对年轻代的引用(这就是 GC Roots 扫描),效率极低。G1 通过 RSet 把这种全堆扫描优化为 Region 级别精确扫描。
RSet 的结构:每个 Region 都有自己的 RSet,本质上是一个 Hash 表:
- Key:引用本 Region 对象的 Card 索引(Card 是更小的内存单位,约 512 字节)
- Value:引用方的 Region 列表
下图展示了 RSet 的引用关系: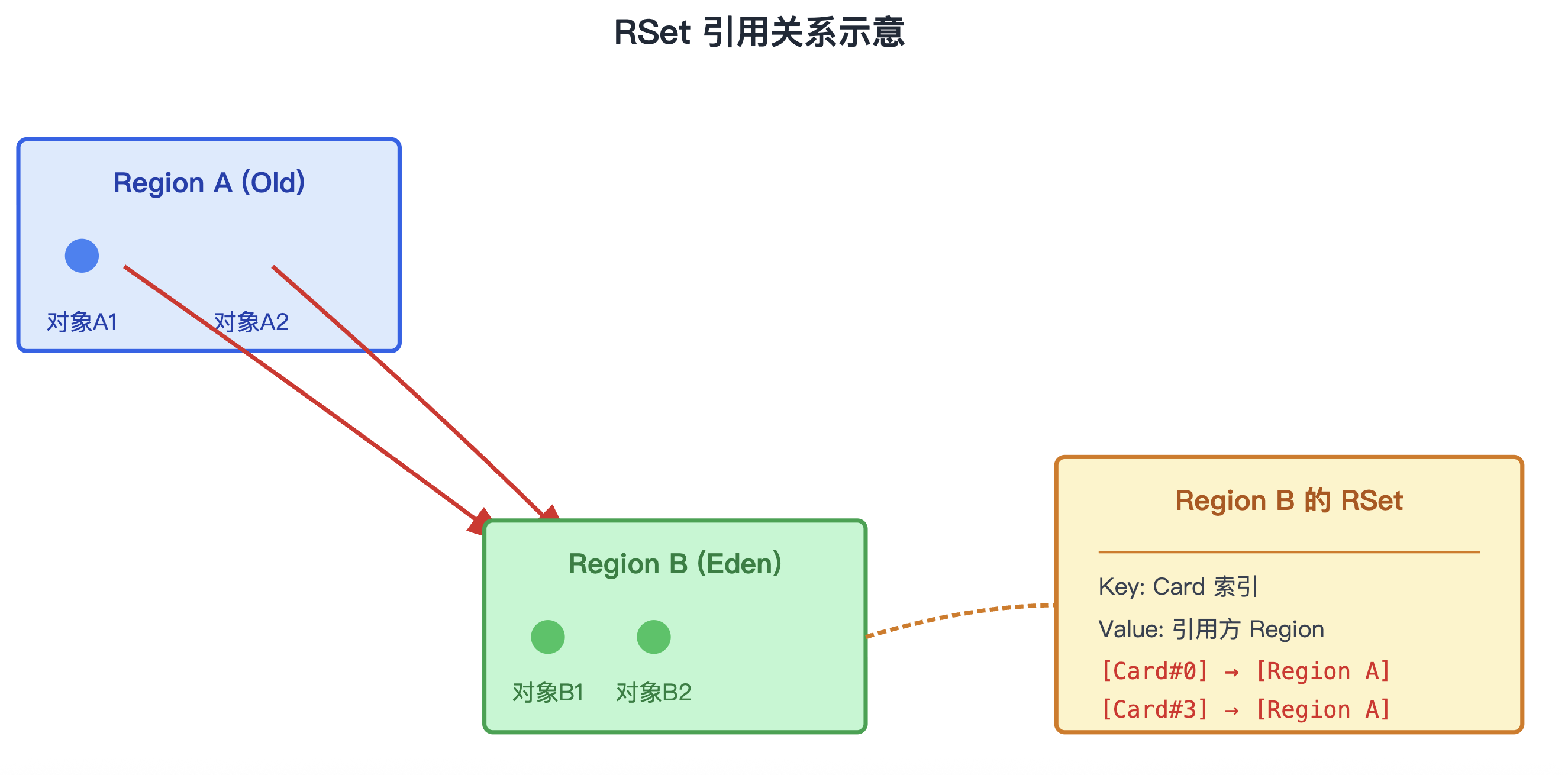
RSet 引用关系示意
RSet 的维护成本:
- 每次引用关系变化(写引用),都需要更新 RSet → 写屏障(Post-Write Barrier) 的开销。
- RSet 本身占用堆内存(默认每个 Region 的 RSet 占空间 0~3% 堆大小)。
3.1.1 Card 与 Card Table(卡与卡表)
RSet 的底层实现依赖两个重要概念:Card(卡) 和 Card Table(卡表)。
Card(卡):JVM 把整个堆内存按 512 字节 大小切分成大量"卡",每张卡可以包含 1~多个对象。
Card Table(卡表):一个与堆对应的字节数组(byte[]),堆中每 512 字节对应卡表中的 1 个字节。卡表中每个字节有 3 种状态:
| 状态 | 含义 |
|---|---|
clean (0) |
该卡内对象引用未发生变化 |
dirty (1) |
该卡内有对象的引用发生变化 |
scanned |
该卡已经被 GC 线程扫描处理过 |
Card Table 的核心作用:快速定位"哪些堆区域可能存在跨 Region 引用"。当 GC 回收 Region X 时,不需要扫描整个堆,只需要扫描其他 Region 中指向 X 的脏卡。
Region / Card / Card Table 三者的关系:
| 概念 | 大小 | 内存位置 | 作用 |
|---|---|---|---|
| Region(区域) | 1MB~32MB(默认 2 的 N 次幂) | Java 堆内 | 堆的逻辑划分单位,独立分配/回收 |
| Card(卡) | 512 字节(固定) | Region 内 | Region 内更小的内存单位,标记脏卡的最小粒度 |
| Card Table(卡表) | 堆大小/512B(字节数组) | 堆外(Native Memory) | 记录每张 Card 是否为脏,与堆 1:1 字节映射 |
包含关系:
Java 堆(GB 级别)
└─ 多个 Region(每个 1~32MB)
└─ 多个 Card(每个 512B)
└─ 对象(多个变长对象)
Card Table(堆外数组)
└─ 字节 = 堆大小/512B
└─ 每字节对应一个 Card
内存位置关系:
- Region 和 Card 都在 Java 堆中(受 GC 管理,对应用线程可见)。
- Card Table 是一个独立的字节数组,位于 Native Memory(堆外的 C Heap 中,对应用线程不可见)。
- 当堆中某张 Card 变脏时,Post-Write Barrier 会同步把 Card Table 中对应字节设为 1(dirty)。
下图展示了 RSet / Region / Card / Card Table 四者在内存中的位置关系: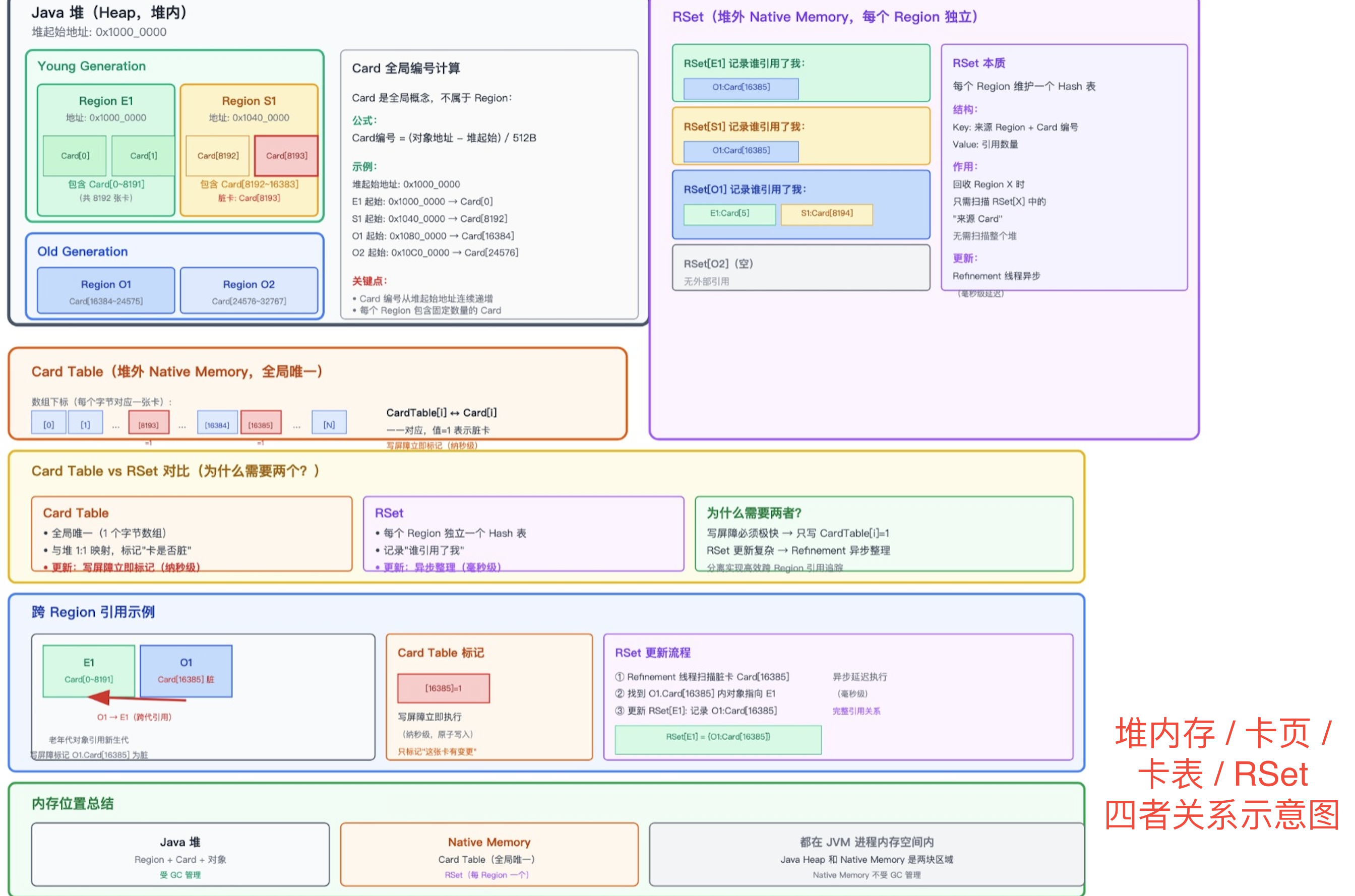
3.1.2 写后屏障(Post-Write Barrier)
当应用线程修改对象引用时,JVM 通过写后屏障把对应 Card 标记为 dirty:
// 简化的 Post-Write Barrier 伪代码
void postWriteBarrier(void* field, oop new_value) {
*field = new_value; // ① 实际写入新引用
// ② 计算 field 所在 Card 的索引(地址右移 9 位 = 除以 512)
size_t card_index = ((uintptr_t)field >> 9) & 0x1FF;
byte* card_byte = &card_table[card_index];
// ③ 把对应 Card 标记为脏
*card_byte = DIRTY;
}
写后屏障的特点:
- 写引用前不做处理,写引用后立即标记,所以叫"写后屏障"。
- 几乎所有引用修改都会触发屏障,是 G1 性能开销的主要来源(吞吐量损失 5%~10%)。
- 与之对应的还有"写前屏障"(Pre-Write Barrier),用于 SATB 算法。
3.1.3 从 Card 到 RSet 的完整路径
Card 标记为 dirty 后,到 RSet 更新完成,还要经过一个"提炼(Refinement)"过程:
┌──────────────────────┐
│ ① 应用线程修改引用 │ ← 触发 Post-Write Barrier
└──────────┬───────────┘
↓
┌──────────────────────┐
│ ② 标记 Card 为 dirty│ ← Card Table 更新
└──────────┬───────────┘
↓
┌──────────────────────┐
│ ③ Refinement 线程 │ ← 后台 GC 线程并发处理
│ 扫描脏卡 │
└──────────┬───────────┘
↓
┌──────────────────────┐
│ ④ 找到引用方 Region │
│ 和被引用方 Region│
└──────────┬───────────┘
↓
┌──────────────────────┐
│ ⑤ 更新被引用 Region │
│ 的 RSet │ ← 记录 (引用方 Region, Card索引)
└──────────────────────┘
提炼过程的两个阶段:
| 阶段 | 执行者 | 说明 |
|---|---|---|
| Concurrent Refinement | 后台 GC 线程 | 应用线程触发脏卡后,后台线程并发提炼 |
| GC Refinement | GC 线程 | 回收 Region 时,仍有未提炼的脏卡,由 GC 线程同步处理 |
为什么要 Refinement(提炼)?
如果应用线程同步完成 RSet 更新,会严重拖慢应用。因此用"异步提炼"机制:应用线程只快速标记脏卡,复杂的引用分析交给后台线程异步完成。
3.2 CSet(Collection Set 回收集合)
CSet 是本次 GC 计划回收的 Region 集合。
CSet 在每次 GC(Young GC 或 Mixed GC)开始时确定,包含两类 Region:
- 必定回收:所有 Eden Region + 部分 Survivor Region(Young GC),或并发标记阶段选出的收益最高的 Old Region(Mixed GC)。
- 可选回收:根据停顿时间预算动态决定。
CSet 的选择策略(Mixed GC 时):
- 跟踪每个 Old Region 的回收收益 = (可回收空间大小 - 回收成本)。
- 按收益从高到低排序。
- 在
MaxGCPauseMillis预算内尽可能多选。
3.3 SATB(Snapshot-At-The-Beginning)
SATB 是一种并发标记算法,由 G1 的前身(C4:Combining Concurrent Copying Collector)发展而来。
核心思想:在并发标记开始时(Initial Mark 完成那一刻),对堆的对象图做一份"逻辑快照"。并发标记过程中即使应用线程修改了引用(如 A 原来引用 B,后来改为引用 C),G1 也认为 A 仍然引用 B(按快照来标记)。
为什么需要 SATB?
如果没有 SATB,并发标记过程中应用线程修改引用会导致漏标(一个本应存活的对象被错误标记为垃圾)。SATB 通过 写前屏障(Pre-Write Barrier) 解决漏标问题:
// 简化的 SATB 写前屏障伪代码
void preWriteBarrier(oop* field, oop new_value) {
oop old_value = *field; // 记录原值
if (old_value != null && SATB_mark_active) {
// 把原值加入 SATB 标记队列,保证它一定会被扫描
satb_mark_queue.enqueue(old_value);
}
*field = new_value;
}
3.3.1 三色标记与漏标问题
SATB 解决的是并发标记中的"漏标"问题。要理解漏标,首先要理解三色标记算法。
三色标记定义:
| 颜色 | 含义 | 状态 |
|---|---|---|
| 白色 | 未被标记 | 可能被回收 |
| 灰色 | 已被标记,但其引用的对象还未扫描 | 待扫描 |
| 黑色 | 已被标记,且其引用的对象都已扫描完毕 | 存活 |
漏标发生的经典场景(同时满足两个条件):
初始状态:
灰色对象 A → 白色对象 B(A 引用 B,B 还没被扫描)
黑色对象 C(C 已经扫描完毕)
用户线程操作:
① 黑色 C 新增引用 → 白色 B(B 变成存活)
② 灰色 A 断开引用 → 白色 B(A 扫描时看不到 B 了)
结果:
B 没有被任何灰色对象引用 → GC 认为是白色 → 回收
实际情况:C 引用了 B → B 应该存活 → 漏标!
G1 vs CMS 解决漏标的方式对比:
| GC | 解决方案 | 写屏障类型 | 原理 |
|---|---|---|---|
| CMS | 增量更新 | 写后屏障 | 新增引用时,把目标重新标记为灰色,重新扫描 |
| G1 | SATB | 写前屏障 | 断开引用时,记录旧对象到 SATB Buffer,后续扫描 |
SATB 的优势:吞吐量更高(写前屏障只记录到队列,不重新标记),适合 G1 的 Region 回收模式。
3.4 TAMS(Top-At-Mark-Start)指针
TAMS 是 Region 内部的一个指针,标记"并发标记开始时的分配位置"。
- TAMS 之前的对象:属于快照的一部分,必须标记。
- TAMS 之后的对象:并发标记期间新分配的对象,隐式存活(G1 认为它们是活的对象,无需标记)。
TAMS 配合 SATB 完整地实现了"并发标记的对象图快照"。
TAMS解决的是并发标记期间先创建的对象不会被漏标;
SATB写前屏障解决的是已有对象(并发标记开始时已存在的对象)在被更换引用关系时不会被漏标
3.5 G1 的垃圾回收算法
G1 实际上是多种算法的组合,而不是单一算法:
| 阶段 | 使用的算法 | 说明 |
|---|---|---|
| 标记阶段 | 三色标记 + SATB | 并发标记存活对象,快照语义防止漏标 |
| Evacuation(转移) | 复制算法 | 把存活对象复制到新 Region,原 Region 整块回收 |
| 整体策略 | 分代收集 + Region 化 | Young GC + Mixed GC,可预测停顿 |
为什么 G1 使用复制算法而不是标记-清除或标记-压缩?
| 算法 | 问题 | G1 的替代方案 |
|---|---|---|
| 标记-清除 | 产生内存碎片 | 复制到新 Region,天然无碎片 |
| 标记-压缩 | 全堆压缩效率低 | Region 间天然"分离",复制即压缩 |
| 复制算法 | 需要 2 块空间 | G1 动态选择空闲 Region 作为目标 |
G1 能预测停顿时间的原因:
G1 跟踪每个 Region 的"回收价值":
回收价值 = 垃圾量 / 预估回收时间
每次回收时,G1 选择价值最高的 Region 组成 CSet(Collection Set),并控制 CSet 大小,使预估回收时间 ≤ -XX:MaxGCPauseMillis。
总结:
- 标记:SATB 三色标记(并发、快照语义)
- 回收:复制算法(Evacuation 阶段)
- 策略:分代 + Region 化 + 可预测停顿
第 4 章:G1 的完整回收过程
G1 的回收过程是 Young GC + 并发标记周期 + Mixed GC 的组合。一个完整的 G1 周期包含以下阶段:
4.1 阶段 1:初始标记(Initial Mark)— STW
- 触发时机:Young GC 触发时,作为 Young GC 的一部分。
- 操作:
- 标记所有 GC Roots 直接可达的对象。
- 设置 TAMS 指针,开始 SATB 标记。
- 停顿时间:很短(通常几毫秒~几十毫秒),因为是借用 Young GC 的 STW 阶段。
- 并发标记的起点。
4.2 阶段 2:并发标记(Concurrent Mark)
- 触发时机:Initial Mark 完成后立即开始。
- 操作:
- 应用线程继续运行,GC 线程并发遍历对象图,标记所有存活对象。
- 记录每个 Region 中的存活对象数(用于计算回收收益)。
- 处理 SATB 队列,处理漏标问题。
- 停顿时间:不暂停应用线程。
- 耗时:通常较长(几百毫秒~几秒),但与应用线程并发。
4.3 阶段 3:最终标记(Remark)— STW
- 触发时机:并发标记完成后。
- 操作:
- 处理所有剩余的 SATB 队列。
- 处理引用变化(Reference 引用,弱引用、软引用等)。
- 完成对象图的最终标记。
- 停顿时间:通常几十毫秒。
4.4 阶段 4:筛选回收(Mixed Evacuation / Cleanup & Copy)
- 触发时机:Remark 完成后,可以做一次或多次 Mixed GC。
- 操作:
- 根据回收收益排序 Old Region。
- 在
MaxGCPauseMillis预算内选择 CSet。 - STW:将 CSet 中存活对象拷贝到新 Region,回收旧 Region。
- 释放 Humongous Region。
- 停顿时间:受
MaxGCPauseMillis控制。 - 可能执行多次:直到满足目标(如
G1MixedGCLiveThresholdPercent设定老年代占用率)。
4.5 完整回收流程图

G1 完整回收流程
第 5 章:G1 的 Young GC 与 Mixed GC
5.1 Young GC 触发时机
- Eden 区被填满时,触发 Young GC。
- 整个 Young GC 完全 STW,回收所有 Eden + 部分 Survivor Region。
5.2 Mixed GC 触发条件
- 当老年代占用率达到 IHOP(Initiating Heap Occupancy Percent) 阈值(默认 45%),触发并发标记周期。
- 并发标记完成后,根据结果触发 Mixed GC。
- Mixed GC 会同时回收 Eden + Survivor + 部分 Old Region。
- 多次 Mixed GC 持续执行,直到 Old Region 占用率降低到
G1MixedGCLiveThresholdPercent(默认 85%)以下。
5.3 GC 日志分析(真实样例)
下面是 JDK 11 启用 G1 的典型 GC 日志:
# 启动参数(JDK 9+)
java -Xms4g -Xmx4g \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=200 \
-Xlog:gc*:file=gc.log:time,uptime,level,tags:filecount=10,filesize=100M \
-jar app.jar
一段 GC 日志示例:
[2024-01-15T10:23:45.123+0800][12.345s][info][gc] Using G1
[2024-01-15T10:23:50.456+0800][17.678s][info][gc] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 24M->8M(4096M) 12.345ms
[2024-01-15T10:23:55.789+0800][23.011s][info][gc] GC(1) Pause Young (Concurrent Start) (G1 Evacuation Pause) 64M->32M(4096M) 15.678ms
[2024-01-15T10:23:55.790+0800][23.012s][info][gc] GC(2) Concurrent Mark Cycle
[2024-01-15T10:23:56.123+0800][23.345s][info][gc] GC(2) Pause Remark 80M->78M(4096M) 8.901ms
[2024-01-15T10:23:57.234+0800][24.456s][info][gc] GC(2) Pause Cleanup 78M->76M(4096M) 1.234ms
[2024-01-15T10:23:57.345+0800][24.567s][info][gc] GC(2) Concurrent Mark Cycle 1.555s
[2024-01-15T10:23:58.456+0800][25.678s][info][gc] GC(3) Pause Young (Mixed) (G1 Evacuation Pause) 120M->80M(4096M) 18.901ms
日志解读:
| 日志片段 | 含义 |
|---|---|
Pause Young (Normal) (G1 Evacuation Pause) 24M->8M(4096M) 12.345ms |
一次普通 Young GC,STW 12.345ms,堆从 24M 降到 8M(总堆 4096M) |
Pause Young (Concurrent Start) |
Young GC 启动并发标记周期 |
Concurrent Mark Cycle |
并发标记周期开始 |
Pause Remark 80M->78M(4096M) 8.901ms |
最终标记,STW 8.901ms |
Pause Cleanup |
清理阶段,决定是否进行 Mixed GC |
Pause Young (Mixed) (G1 Evacuation Pause) |
Mixed GC,回收年轻代 + 部分老年代 |
关键指标:
- Pause 时间:每次 STW 的耗时(关注 < MaxGCPauseMillis)。
- 堆占用变化:
24M->8M表示 GC 前后堆占用。 - 并发周期耗时:
Concurrent Mark Cycle 1.555s整体耗时。
第 6 章:G1 调优参数详解
6.1 核心调优参数
| 参数 | 默认值 | 说明 |
|---|---|---|
-XX:MaxGCPauseMillis |
200 | 目标最大 GC 停顿时间(毫秒) |
-XX:InitiatingHeapOccupancyPercent (IHOP) |
45 | 触发并发标记的堆占用率阈值 |
-XX:G1HeapRegionSize |
自动计算 | Region 大小(1MB~32MB,2 的 N 次幂) |
-XX:ParallelGCThreads |
CPU 核数 | STW 阶段的并行 GC 线程数 |
-XX:ConcGCThreads |
ParallelGCThreads/4 | 并发标记阶段的线程数 |
-XX:G1MixedGCLiveThresholdPercent |
85 | Mixed GC 时,存活对象占比低于此值的 Region 才被回收 |
-XX:G1MixedGCCountTarget |
8 | Mixed GC 的目标次数 |
-XX:G1ReservePercent |
10 | 保留堆的百分比,避免晋升失败 |
-XX:MaxTenuringThreshold |
15 | 对象晋升老年代的年龄阈值 |
6.2 调优实战建议
场景 1:Full GC 频繁
原因通常是大对象分配过快,或 IHOP 设置不合理。
# 1. 调高 IHOP,给并发标记更多时间
-XX:InitiatingHeapOccupancyPercent=35
# 2. 增大 Region 大小,减少大对象分配失败
-XX:G1HeapRegionSize=16m
# 3. 保留更多空间避免晋升失败
-XX:G1ReservePercent=15
场景 2:Mixed GC 停顿时间过长
# 1. 减小单次停顿目标
-XX:MaxGCPauseMillis=100
# 2. 增加 Mixed GC 次数(每次回收更少 Region)
-XX:G1MixedGCCountTarget=16
# 3. 提高 Mixed GC 选择门槛(只回收收益更高的 Region)
-XX:G1MixedGCLiveThresholdPercent=75
场景 3:应用启动慢
# 1. 预热阶段可以关闭 G1,使用 Parallel
# 2. 启动后通过 jcmd 切换到 G1
jcmd <pid> GC.setGC(-Xms4g -Xmx4g -XX:+UseG1GC)
6.3 GC 日志参数详解
# JDK 9+ 推荐格式
-Xlog:gc,gc+heap=trace,gc+age=trace,safepoint:file=gc.log:time,uptime,level,tags:filecount=10,filesize=100M
# 各部分含义:
# gc - 基础 GC 日志
# gc+heap=trace - 堆使用详细日志
# gc+age=trace - 对象年龄分布
# safepoint - 安全点日志
# file=gc.log - 输出到文件
# time - 时间戳
# uptime - JVM 启动时间
# level - 日志级别
# tags - 日志标签
# filecount=10 - 保留 10 个文件
# filesize=100M - 每个文件最大 100M
第 7 章:G1 vs CMS vs ZGC 对比
7.1 三大 GC 核心特性对比
| 特性 | G1 | CMS | ZGC |
|---|---|---|---|
| 设计目标 | 平衡吞吐与延迟 | 低延迟 | 超低延迟 |
| 停顿时间 | 10ms~200ms(可预测) | 10ms~100ms(不保证) | < 1ms |
| 内存整理 | ✅ 复制整理 | ❌ 会碎片化 | ✅ 染色指针 + 读屏障 |
| 大堆支持 | < 64GB 推荐 | < 32GB 推荐 | 8MB~16TB |
| 吞吐量 | 95%+ | 90%+ | 95%+ |
| JDK 状态 | 默认 GC | JDK 9 废弃 | JDK 11+ 实验,JDK 15+ 生产 |
| 适用场景 | 通用服务 | 中小堆服务 | 大堆低延迟服务 |
7.2 各 GC 的适用场景
G1 适用场景:
- 堆大小 4GB ~ 64GB
- 需要可预测的停顿时间(如 200ms 内)
- 通用服务端应用(推荐默认)
CMS 适用场景(已废弃,不推荐新项目使用):
- 堆大小 < 8GB
- 老年代占比稳定
- 能容忍 Full GC 的旧系统
ZGC 适用场景:
- 堆大小 > 64GB
- 严格要求停顿 < 10ms(如金融交易、实时系统)
- 内存密集型服务
7.3 选型决策树
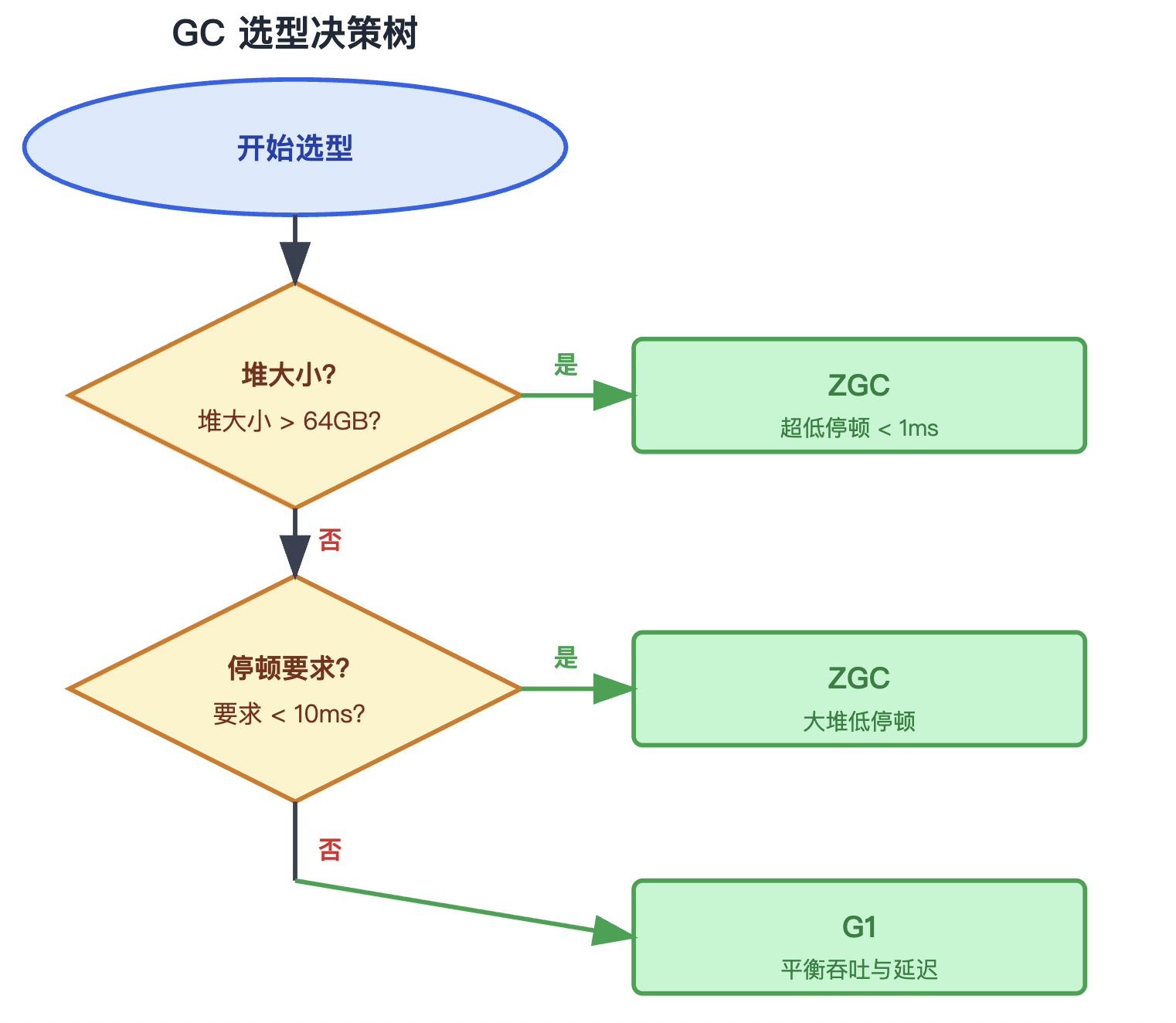
GC 选型决策树
第 8 章:G1 的优缺点总结
8.1 G1 的优点
- 可预测的停顿时间:通过
MaxGCPauseMillis控制目标停顿,适合延迟敏感型应用。 - 大堆友好:相比 CMS,64GB 堆仍能保持良好性能。
- 无内存碎片:使用复制整理算法,回收后无碎片。
- 并行与并发:充分利用多核 CPU,应用线程大部分时间不暂停。
- 增量回收:Mixed GC 渐进式清理老年代,避免长时间 STW。
- 作为 JDK 9+ 默认 GC:成熟稳定,社区支持完善。
8.2 G1 的缺点与局限
- 写屏障开销:RSet 维护和 SATB 写前屏障带来约 5%~10% 的吞吐量损失。
- 占用额外内存:RSet 占用约 0~3% 堆空间。
- Full GC 仍存在:在极端情况下(堆占满、晋升失败)会触发单线程 Full GC,停顿可能达数秒。
- 大对象处理欠佳:Humongous 分配和回收效率较低,频繁大对象会触发问题。
- 调优复杂:参数众多,新手调优门槛较高。
8.3 未来展望
- ZGC:JDK 15+ 生产可用,停顿 < 1ms,支持 TB 级堆,是未来趋势。
- Shenandoah:Red Hat 开发的低延迟 GC,与 ZGC 类似。
- G1 自身演进:JDK 仍在持续优化 G1(如 JDK 21 的 G1 弹性堆、NUMA 改进等)。
建议:新项目优先考虑 G1(默认 GC),对延迟有极端要求的场景可使用 ZGC。
附录:常用诊断命令
# 1. 查看当前 JVM 的 GC 配置
jcmd <pid> VM.flags | grep -E "UseGC|G1"
# 2. 触发 Full GC(仅用于诊断,不推荐生产环境)
jcmd <pid> GC.run
# 3. 查看堆使用情况
jcmd <pid> GC.heap_info
# 4. 查看 GC 统计
jstat -gc <pid> 1000 10
# 5. 导出堆 dump
jmap -dump:format=b,file=heap.hprof <pid>
# 6. 使用 JFR 记录 GC 事件
jcmd <pid> JFR.start name=gc duration=60s filename=gc.jfr
参考资料
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)