
c++基础补强--Day06
异常处理
一、先搞懂核心基本概念
1. 什么是异常
程序运行时发生的非预期错误:除零、数组越界、空指针、文件打开失败、内存分配失败等。 如果不处理异常,程序会直接崩溃退出;异常机制就是专门用来优雅处理运行错误、保证程序不会直接宕机的一套语法。
区分两个容易混淆的点:
编译错误:写代码语法错,编译器直接不让运行,不属于异常;
异常:代码语法没问题,运行起来才出问题,靠
try/catch/throw处理。2. C++ 异常三巨头关键字
表格
关键字
作用
throw主动抛出一个错误(制造异常)
try包裹可能出错的代码,监控异常
catch捕获
throw抛出的异常,写错误处理逻辑3. 标准异常层次
std::exceptionC++ 标准库所有内置异常都继承自顶层父类
std::exception,头文件:<exception>继承链简化:plaintext
std::exception // 顶层基类 ├─ std::logic_error 逻辑错误(写代码逻辑问题,运行前可规避) │ ├─ invalid_argument 参数非法 │ ├─ out_of_range 下标越界 └─ std::runtime_error 运行时动态错误(运行才会触发) ├─ overflow_error 数值溢出 └─ bad_alloc new分配内存失败所有标准异常都重写了核心虚函数:
cpp
运行
virtual const char* what() const noexcept;调用
what()可以拿到异常的文字描述。
二、异常抛出与捕获(基础实操)
1. throw 抛出异常语法
可以抛出任意类型:int、string、自定义类、标准异常对象,推荐抛标准 / 自定义异常对象。
cpp
运行
throw 错误值/异常对象;2. try-catch 基础结构模板
cpp
运行
try { // 所有可能报错的代码放这里 if (出错条件) { throw 异常; // 抛出异常,立刻跳出try块 } // 后续代码:如果上面throw,这部分不会执行 } catch (捕获类型 e) { // 捕获到对应类型异常后的处理逻辑 } // 可以写多个catch,捕获不同异常 catch (...) { // 万能捕获:捕获所有任意类型异常,兜底用 }示例 1:最简单的除零异常
cpp
运行
#include <iostream> using namespace std; double div(double a, double b) { if (b == 0) { // 抛出int类型异常 throw 999; } return a / b; } int main() { try { double res = div(10, 0); cout << "结果:" << res << endl; } // 捕获throw抛出的int异常 catch (int err_code) { cout << "捕获异常,错误码:" << err_code << " 除数不能为0" << endl; } cout << "程序继续运行,没有崩溃" << endl; return 0; }输出:
plaintext
捕获异常,错误码:999 除数不能为0 程序继续运行,没有崩溃3. 异常跨函数传播(重点知识点)
throw抛出异常后,会逐层向上寻找匹配的 try-catch:
如果当前函数没有 catch,直接退出当前函数;
回到调用这个函数的上层函数继续找;
一直到 main 函数,如果全程没有匹配 catch,程序直接终止。
跨函数传播示例
cpp
运行
#include <iostream> using namespace std; void func3() { throw "除数非法"; // 抛出字符串异常 } void func2() { func3(); // 异常传到func2,func2无catch } void func1() { func2(); // 异常继续向上传播 } int main() { try { func1(); } catch (const char* err_msg) { cout << "捕获跨多层函数的异常:" << err_msg << endl; } return 0; }4. 多 catch 区分不同异常 + 万能捕获
cpp
运行
#include <iostream> #include <exception> using namespace std; void test(int num) { if (num == 0) throw -1; if (num == 1) throw "参数不能为1"; if (num == 2) throw runtime_error("运行时数值错误"); } int main() { for (int i = 0; i <= 3; i++) { try { test(i); cout << i << "无异常\n"; } catch (int code) { cout << "捕获int异常:" << code << "\n"; } catch (const char* msg) { cout << "捕获字符串异常:" << msg << "\n"; } catch (const exception& e) { // 所有继承std::exception的标准异常都能匹配 cout << "标准异常:" << e.what() << "\n"; } // catch (...) 放最后,兜底所有未知异常 catch (...) { cout << "捕获未知类型异常\n"; } } return 0; }
三、自定义异常类(核心学习点)
规则
自定义异常推荐公有继承
std::exception;必须重写虚函数
what(),返回异常描述;构造函数接收错误信息,供
what()返回。完整示例:自定义除数异常
cpp
运行
#include <iostream> #include <exception> #include <string> using namespace std; // 自定义异常类,继承标准异常基类 class DivZeroException : public exception { private: string err_info; // 存储异常描述 public: // 构造函数接收错误信息 explicit DivZeroException(const string& info) : err_info(info) {} // 重写what(),const noexcept固定格式 const char* what() const noexcept override { return err_info.c_str(); } }; double divide(double a, double b) { if (b == 0) { // 抛出自定义异常对象 throw DivZeroException("错误:除数不允许等于0"); } return a / b; } int main() { try { divide(5, 0); } // 捕获自定义异常 catch (const DivZeroException& e) { cout << "捕获自定义异常:" << e.what() << endl; } // 父类引用可以捕获所有子异常(多态) catch (const exception& e) { cout << "通用异常处理:" << e.what() << endl; } return 0; }输出:
plaintext
捕获自定义异常:错误:除数不允许等于0扩展:多层自定义异常(模拟标准库分层)
可以继承
logic_error/runtime_error细分异常类型:cpp
运行
#include <iostream> #include <stdexcept> #include <string> using namespace std; // 运行时类自定义异常 class FileOpenFail : public runtime_error { public: explicit FileOpenFail(const string& path) : runtime_error("文件打开失败:" + path) {} }; void openFile(const string& path) { bool fail = true; if (fail) throw FileOpenFail("test.txt"); } int main() { try { openFile("test.txt"); } catch (const FileOpenFail& e) { cout << e.what() << endl; } return 0; }
一、基础核心概念
什么是异常 程序运行时产生的非预期错误;编译报错不属于异常。不处理异常程序会直接崩溃。 C++ 异常三件套:
throw、try、catch。
try:包裹可能出错的代码,监控异常
throw:主动抛出异常对象 / 值,中断当前流程
catch:捕获对应类型异常,编写错误处理逻辑标准异常顶层父类:std::exception 头文件:
<stdexcept>/<exception>继承分层:
std::exception(总基类)
std::logic_error:代码逻辑错误(下标越界、参数非法)
std::runtime_error:运行时动态错误(除数为 0、文件打开失败) 所有标准异常都自带虚函数:virtual const char* what() const noexcept;调用.what()获取异常文字描述。perror 和异常完全无关
perror 是 C 语言错误处理工具,依赖全局变量
errno,仅打印错误信息;属于返回值判断式错误处理,没有自动跳转、异常传播机制;
和
throw/catch是两套独立错误体系,不能互相替代。二、异常抛出 & 捕获 细节坑点
1. throw 语法规则
不能直接
throw std::runtime_error;runtime_error 是类,必须实例化对象并传入错误字符串:cpp
运行
throw std::runtime_error("除数不能为0");异常会跨函数向上传播 当前函数无匹配 catch,则退出函数,逐层向调用方传递;全程无 catch 程序终止。
需求 “函数抛出异常” 的关键: 函数内部不要自行 catch,捕获会就地消化异常,上层接收不到; 若需要内部打印日志再向外抛出,使用无参
throw;重新抛出。cpp
运行
catch(const std::exception& e) { std::cerr << e.what(); throw; // 重新抛出给上层 }2. try-catch 多分支匹配规则
子类 catch 必须写在父类 catch 前面 例:先
std::runtime_error,再std::exception反例(错误):父类放前面,所有子类异常都会被提前截走,后序 catch 永远不执行cpp
运行
// 错误顺序 catch(const std::exception& e){} catch(const std::runtime_error& e){}两个 catch 分层的意义
catch(std::runtime_error&):精准捕获运行时错误,做专属处理;
catch(std::exception&):兜底捕获所有其他标准异常(越界、非法参数、内存失败等)。万能捕获
catch(...)放在所有 catch 最后,捕获任意类型异常,无法获取异常信息。捕获推荐写法:
const 引用 const std::exception& e使用引用避免异常对象拷贝,const 保证不修改异常信息。三、自定义异常类 全套细节
1. 自定义异常规范
公有继承
std::exception/std::runtime_error/std::logic_error;必须重写虚函数
what();构造函数接收错误描述字符串,存储为成员
std::string。2. what () 函数修饰符完整解析
cpp
运行
const char* what() const noexcept override
末尾 const 函数不会修改类内成员;父类 what 带 const,子类必须匹配签名;const 异常对象只能调用 const 成员。
noexcept 承诺该函数内部不会抛出任何异常;父类 what 标记 noexcept,子类不能省略,否则编译报错。
override 显式声明这是重写父类虚函数;编译器强制校验函数签名,少写 const/noexcept 会直接报错,避免多态失效隐藏 bug。
返回值
const char*返回只读字符串指针,禁止外部修改内部异常描述。标准自定义异常模板
cpp
运行
#include <exception> #include <string> class DivZeroException : public std::runtime_error { private: std::string err_msg; public: explicit DivZeroException(const std::string& msg) : std::runtime_error(msg), err_msg(msg) {} const char* what() const noexcept override { return err_msg.c_str(); } };四、配套浮点 float /double 补充(除法代码用到)
存储大小与精度
float:4 字节 32 位,有效十进制 6~7 位,字面量加后缀
3.14f;double:8 字节 64 位,有效十进制 15~16 位,浮点字面量默认 double。
运算坑点
int / int是整数除法,会截断小数,需强转浮点:static_cast<float>(a)/b;二进制浮点无法精准存储 0.1、0.2 等小数,禁止用 == 判断相等;
适用场景 double:日常计算、高精度迭代运算(默认首选); float:大规模数组、图形 / AI 张量,节省内存。
auto/decltype
auto + decltype 完整学习笔记(贴合你的学习大纲)
一、auto 自动类型推导
1. 核心概念
auto:编译器根据等号右侧初始化表达式,在编译期自动推导变量类型。 规则:auto 变量必须立刻初始化,不初始化无法推导,编译报错。基础示例
cpp
运行
auto a = 10; // int auto b = 3.14; // double auto c = 3.14f; // float auto str = "hello"; // const char* auto s = std::string("test"); // std::string2. auto 与 const、&、*、&& 组合(重点考点)
auto 只会推导底层类型,修饰符需要手动写在 auto 左侧。
1)const
cpp
运行
int x = 10; const auto v1 = x; // const int auto const v2 = x; // 等价 const int v1 = 20; // 报错,只读2)左值引用 &
cpp
运行
int num = 100; auto& ref = num; // int& 普通左值引用 ref = 200; const auto& cref = num; // const int& 常引用 cref = 300; // 报错注意:
auto&不能绑定右值:auto& r = 10;编译失败。3)指针 *
cpp
运行
int val = 5; auto p = &val; // int* const auto* cp = &val; // const int* 指针指向常量 auto* const pc = &val;// int* const 指针本身不可修改4)万能引用 auto&&(区分左 / 右值)
cpp
运行
int a = 1; auto&& r1 = a; // a是左值 → int& auto&& r2 = 10; // 10是右值 → int&&3. auto 常用场景
场景 1:超长复杂类型(简化代码)
不用写冗长迭代器:
cpp
运行
#include <vector> #include <iostream> int main() { std::vector<int> vec{1,2,3}; // 原生写法:std::vector<int>::iterator it = vec.begin(); auto it = vec.begin(); std::cout << *it; return 0; }场景 2:范围 for 循环遍历容器
cpp
运行
std::vector<std::string> arr{"a","b"}; // 值拷贝 for (auto x : arr); // 引用,避免拷贝,可修改元素 for (auto& x : arr); // 常引用,只读最高效 for (const auto& x : arr);场景 3:Lambda 表达式接收 / 存储
lambda 没有显式类型,只能用 auto 保存:
cpp
运行
auto func = [](int x){ return x * 2; }; std::cout << func(5);场景 4:复杂模板返回值、STL 复杂类型
std::map<std::string, std::vector<int>>这种超长类型用 auto 极简。4. auto 的限制(必背易错点)
- auto 不能用于函数形参
cpp
运行
// 非法,C++14前不支持,普通函数不能auto参数 void test(auto x){}
- auto 不能声明类成员变量(未初始化)
cpp
运行
struct A { auto x = 10; // C++17才允许,老标准报错 };
- 函数返回值不能单纯 auto(C++11 限制)
cpp
运行
// C++11 报错,C++14支持普通auto返回 auto add(int a, int b) { return a + b; }
- auto 不能用于数组、函数签名等场景
- 一行多变量推导:推导类型必须一致
cpp
运行
auto m = 10, n = 3.14; // 报错,int 和 double 类型冲突二、decltype 类型查询
1. 核心概念
decltype(表达式):不执行表达式,仅提取表达式的类型,包含 const、引用、左 / 右值属性。 与 auto 区别:
- auto:定义变量,靠初始化推导;
- decltype:单独拿类型,不需要定义变量,保留完整修饰符。
基础示例
cpp
运行
int x = 10; decltype(x) a = 20; // a 类型 int decltype(x + 0.5) b = 3; // x+double → double2. decltype 区分左值 / 右值(核心难点)
规则:
- 表达式是单纯变量名(标识符)→ 取变量原生类型;
- 表达式是带括号 (变量)、可修改左值表达式 → 推导为左值引用
T&;- 纯右值表达式 → 推导为
T/T&&。cpp
运行
int num = 5; decltype(num) v1 = num; // int decltype((num))v2 = num; // (num)是左值表达式 → int& v2 = 100; // 修改原num3. decltype 典型使用场景
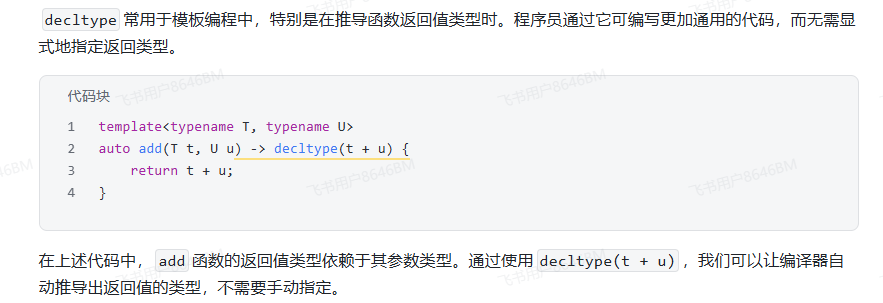
场景 1:C++11 模板函数后置返回类型(经典用法)
C++11 函数返回值无法直接 auto,用
decltype+ 后置返回:cpp
运行
template<typename T1, typename T2> auto add(T1 a, T2 b) -> decltype(a + b) { return a + b; } // auto 占位,-> decltype(表达式) 指定真实返回类型场景 2:获取复杂对象成员、函数返回类型
cpp
运行
std::vector<int> vec{1,2}; using Iter = decltype(vec.begin()); // Iter = vector<int>::iterator Iter it = vec.begin();场景 3:复用变量完整类型(保留 const&)
cpp
运行
const double pi = 3.14; decltype(pi) val = 6.28; // const double4. decltype 注意事项
- 表达式不会执行,无副作用:
cpp
运行
int a = 1; decltype(a++) t = a; // a++不会运行,a仍等于1
- 引用折叠问题
decltype识别出引用后,结合模板会发生引用折叠:
- T& & → T&
- T& && → T&
- T&& & → T&
- T&& && → T&&
decltype(auto)(融合 auto + decltype) 普通 auto 会丢弃引用、const;decltype(auto)完整保留表达式所有修饰符:cpp
运行
int x = 10; auto v1 = (x); // int(普通auto去掉引用) decltype(auto) v2 = (x);// int& 完整保留左值引用三、auto VS decltype 对比总结
表格
关键字 作用 是否需要初始化 是否保留引用 /const 适用场景 auto 定义变量,靠初始化推导类型 必须初始化 仅基础类型,丢弃引用 迭代器、循环、lambda、简化长类型 decltype 查询任意表达式完整类型 不需要变量初始化 完整保留 const、&、左值属性 模板返回值、提取复杂类型、精准保留修饰符 四、高频综合例题
例 1 auto 引用推导
cpp
运行
int m = 99; auto a = m; // int,拷贝 auto& b = m; // int&,别名 const auto& c = m;// const int& auto&& d = m; // int&(万能引用匹配左值) auto&& e = 10; // int&&(万能引用匹配右值)例 2 decltype 括号陷阱
cpp
运行
int x = 1; decltype(x) a = x; // int decltype((x))b = x; // int& b = 100; // x 最终变成100例 3 模板后置返回类型
cpp
运行
#include <iostream> template <typename A, typename B> auto mul(A a, B b) -> decltype(a * b) { return a * b; } int main() { std::cout << mul(2, 3.5); // 返回double return 0; }
参数初始化列表
列表初始化 {} 完整笔记(完全匹配你的学习大纲)
一、基础概念
1. 什么是列表初始化
C++11 新增,统一使用大括号
{}做初始化,统一所有类型(普通变量、数组、结构体、类、容器)的初始化语法,也叫统一初始化。 三种传统初始化对比:cpp
运行
// 1. 赋值初始化(等号) int a = 10; // 2. 圆括号构造初始化 int b(10); // 3. 列表初始化(C++11 推荐) int c{10}; int d = {10}; // ={} 等价 {}2. 列表初始化核心特性
- 禁止窄化转换(最重要区别) 窄化:高精度→低精度、浮点转整数、大范围整数转小范围整数,
{}直接编译报错;=/()只会警告,自动截断数值,隐藏 bug。- 统一语法,内置类型、自定义类、容器通用
- 会优先匹配
initializer_list构造函数(重载优先级更高)3. 列表初始化 vs 赋值初始化核心差异
差异 1:窄化检查
cpp
运行
// 赋值/圆括号:允许窄化,仅警告 int x = 3.14; int y(3.14); // 列表初始化:窄化直接编译报错 int z{3.14}; // 错误:double→int 窄化转换禁止差异 2:构造函数重载匹配规则
()/=:普通构造函数正常匹配;{}:优先匹配接收 std::initializer_list<T> 的构造函数,哪怕其他构造函数参数更匹配。示例:
cpp
运行
#include <iostream> #include <vector> using namespace std; vector<int> v1(10, 1); // (size, val):10个1 vector<int> v2{10, 1}; // initializer_list:两个元素 10,1同一个 vector,
()和{}结果完全不同,根源就是列表初始化优先 initializer_list。差异 3:空初始化
cpp
运行
int a{}; // 列表空初始化,内置类型默认0 int b; // 局部变量不初始化,随机垃圾值二、列表初始化全部使用场景
场景 1:普通内置变量、数组初始化
cpp
运行
// 单值 int num{66}; double pi{3.1415}; // 数组 int arr1[]{1,2,3,4}; int arr2[5]{1,2}; // 剩余元素自动补0 // 空初始化清零 int zero{}; // zero = 0 double d{}; // d = 0.0场景 2:自定义类、结构体初始化
1)聚合类(无自定义构造函数)直接初始化
cpp
运行
struct Point { int x; int y; }; Point p{10, 20}; // 直接初始化成员 x=10,y=202)有构造函数的类,列表初始化调用构造
cpp
运行
class Person { public: string name; int age; Person(string n, int a) : name(n), age(a) {} }; Person p{"张三", 18}; // 列表初始化传参3)成员初始化列表(构造函数冒号后)
这是类初始化成员的标准写法,也是列表初始化:
cpp
运行
class Person { public: string name; int age; // 冒号后 {} 初始化成员 Person() : name{"未知"}, age{0} {} Person(string n, int a) : name{n}, age{a} {} };场景 3:标准容器初始化(最常用)
容器全部支持
{}批量插入元素,底层靠initializer_list:cpp
运行
vector<int> vec{1,2,3,4,5}; map<int, string> mp{{1,"A"}, {2,"B"}}; pair<int, double> pr{10, 3.14};场景 4:函数传参(列表初始化隐式转换)
调用函数时可以直接传入
{},编译器自动构造临时对象:cpp
运行
void print(Point p) { cout << p.x << "," << p.y; } int main() { print({5, 8}); // 直接用列表初始化传参 return 0; }重载影响:如果函数有
initializer_list重载,会优先选中。场景 5:return 返回值使用列表初始化
C++11 允许 return 后直接写
{}构造返回对象,无需写类型名:cpp
运行
Point createPoint() { // 等价 return Point(1,2); return {1, 2}; }搭配 auto 推导返回类型时非常方便:
cpp
运行
auto getPair() { return {99, "test"}; // 返回 pair<int, string> }三、列表初始化限制与窄化(重点考点)
1. 什么是窄化转换(禁止行为)
满足任意一条,
{}初始化直接编译报错:
- 浮点类型 → 整数(double/float → int/char)
int a{2.5};报错- 大范围整数 → 小范围整数,值超出目标范围
char c{1000};报错(char 一般 - 128~127)- 无符号 ↔ 有符号跨类型且值溢出
unsigned u{-1};报错2. 如何避免窄化报错
- 保证大括号内数值类型、范围完全匹配变量;
- 需要强制转换时,手动显式转换后再放入
{}:cpp
运行
// 想把3.14存int,先强转 int x{static_cast<int>(3.14)};3. 其他注意事项
{}不允许隐式窄化,但允许完全无损转换double a{10};int→double 无损,合法- 区分
()和{}容器陷阱(vector 经典坑)cpp
运行
vector<int> v1(5, 2); // 5个元素,全是2 vector<int> v2{5, 2}; // 两个元素:5、2- 空大括号
T{}会执行值初始化,内置类型清零; 局部变量不写初始化则是随机脏数据。- 类同时拥有普通构造和 initializer_list 构造时,
{}永远优先选 initializer_list。四、易混对比总结
=/():宽松初始化,允许窄化,容器行为特殊;{}列表初始化:安全严格,禁止窄化,统一语法,优先 initializer_list;- 窄化:高精度 / 大范围向低精度 / 小范围转换,
{}直接拦截;- 使用全覆盖:变量、数组、结构体、类、容器、函数传参、return 返回。
列表初始化
{}全部坑点 + 细节总结(结合你刚才 Box 代码的疑问)一、重载匹配大坑(你代码遇到的核心问题)
- 只要类存在
std::initializer_list<T>构造函数:
类名{参数1,参数2...}会优先匹配 initializer_list 构造,无视参数数量匹配的普通多参构造。- 例:你有
Box(int,int)和Box(initializer_list<int>),Box{1,2}永远不走双参构造。- 区分两种调用写法:
Box(1,2)圆括号:正常匹配普通构造,不会碰 initializer_list;Box{1,2}大括号:优先 initializer_list。- 双层大括号
Box{{1,2,3}}: 外层{}表示列表初始化对象,内层{1,2,3}整体作为唯一参数传给 initializer_list,和Box{1,2,3}效果完全一样。- 取舍规则: 若你想让
{a,b}调用双参构造,不能同时定义 initializer_list 构造,二者语法冲突无解。二、窄化转换({} 独有的严格限制)
{}初始化禁止窄化转换,直接编译报错;=/()仅警告、静默截断,藏隐患。
- 非法窄化:浮点→整数、大数存入 char、负数赋值 unsigned
cpp
运行
int x{3.14}; // 报错,double窄化为int char c{200}; // 报错,超出char范围- 无损转换允许:int→double、short→int 没问题。
- 想强行窄化必须手动显式转换再放入大括号:
cpp
运行
int x{static_cast<int>(3.14)}; // 合法三、vector 经典歧义坑(日常高频踩)
cpp
运行
vector<int> v1(5, 10); // ():5个元素,全部为10 vector<int> v2{5, 10}; // {}:两个元素 5、10
- 意图创建 N 个相同元素:只能用圆括号;
- 意图批量填入一组数值:用大括号。
四、空初始化细节
T{}
- 局部变量
int a;随机垃圾值;int a{};值初始化为 0;- 内置类型、指针、容器空大括号都会默认清零 / 空构造;
- 自定义类
Box{};调用无参构造。五、三种初始化语法区分细节
- 赋值
int a = 10;宽松、允许窄化,简单内置变量可用,但不推荐统一规范。- 圆括号
int a(10);不会触发 initializer_list 优先匹配,适合容器指定容量、调用普通多参构造。- 列表
int a{10};C++11 推荐统一写法,严格防窄化,但是会优先匹配 initializer_list 构造。六、initializer_list 配套细节
- 头文件必须引入
<initializer_list>,否则无法使用;- 列表内所有元素必须能隐式转为同一个类型 T,不能混杂 int、字符串等不兼容类型;
- 只读容器,不支持增删,只能通过
begin()/end()/ 范围 for 遍历;- 不要返回局部 initializer_list,它仅引用临时数组,会产生悬空引用;
- 函数参数可直接接收
initializer_list<T>,调用时直接传{1,2,3}无需包装对象。七、return 返回值列表初始化
C++11 支持直接返回大括号,省略类型名:
cpp
运行
Box func() { return {1,2}; }注意:若类有 initializer_list 构造,这里依旧会优先匹配它。
八、聚合类简易初始化
无自定义构造的结构体 / 数组可直接批量赋值:
cpp
运行
struct Point{int x,y;}; Point p{10,20}; int arr[]{1,2,3};一旦自定义构造函数,就不再是聚合类,遵循构造函数匹配规则。
强制类型转换
一、基础概念
1. 什么是强制类型转换
强行修改表达式原有类型,分为两类:
- C 老式强转:
(目标类型)数据,写法简单、无安全检查、风险高,工程开发不推荐;- C++ 新式 4 种强转:
xxx_cast<Type>(expr),功能拆分、意图清晰、编译器检查更强,企业规范优先使用。2. C 强转 vs C++ 四种强转对比
C 风格:
double a = 3.14; int b = (int)a;缺点:一个括号包揽所有转换(数值、指针、const、底层重解释),阅读时看不出转换目的,容易隐藏 bug。 C++ 把转换按用途拆分成 4 个,各司其职,编译器会做对应校验。二、四种 C++ 标准转换(核心重点)
1. static_cast 静态转换(最常用,编译期检查)
适用场景:
- 基础算术类型互相转换(int ↔ double、float ↔ long 等);
- 存在继承关系的父子类指针 / 引用向上 / 向下安全转换(无运行时检查,程序员保证安全);
- 拥有单参数构造 / 类型转换运算符的类对象隐式转换显式化;
- void* 和其他指针互相转换。
禁止:去掉 const 属性、不相关类型指针互转。 示例 1:数值转换
cpp
运行
double pi = 3.99; int num = static_cast<int>(pi); // 3,浮点转整数示例 2:继承类向上 / 向下转换
cpp
运行
class Base {}; class Son : public Base {}; Base* b = new Son; Son* s = static_cast<Son*>(b); // 向上转安全,向下转编译器不校验,需自己保证真实类型示例 3:void * 互转
cpp
运行
int x = 10; void* p = &x; int* px = static_cast<int*>(p);2. dynamic_cast 动态转换(运行时安全检查,只用于多态)
核心前提:基类必须包含虚函数(存在虚表,才叫多态类型),否则编译报错。 作用:安全向下转型(基类指针 / 引用 → 派生类),运行时校验对象真实类型。 失败规则(必背):
- 转换指针失败:返回
nullptr;- 转换引用失败:抛出
std::bad_cast异常。cpp
运行
#include <iostream> #include <stdexcept> class Base { public: virtual void func() {} // 必须有虚函数,启用多态 }; class Son : public Base {}; class Other : public Base {}; int main() { Base* p = new Son; // 成功,真实类型是Son Son* s = dynamic_cast<Son*>(p); if (s) std::cout << "转换成功\n"; // 失败,真实对象不是Other Other* o = dynamic_cast<Other*>(p); if (!o) std::cout << "转换失败,返回空指针\n"; // 引用版本失败抛异常 Base& ref = *p; try { Other& ro = dynamic_cast<Other&>(ref); } catch (std::bad_cast& e) { std::cerr << "引用转换失败:" << e.what() << "\n"; } delete p; return 0; }适用场景:不确定基类指针真实子类型,需要安全向下转换。
3. const_cast 唯一能增减 const /volatile 限定符的转换
唯一功能:只修改顶层 const、volatile,不能改底层类型。 不能做数值、父子类指针转换。
场景 1:去除 const(谨慎使用,修改原 const 变量是未定义行为)
cpp
运行
const int a = 10; int* p = const_cast<int*>(&a); // *p = 20; // 未定义行为,a本身是const常量场景 2:给普通变量添加 const
cpp
运行
int x = 99; const int* cp = const_cast<const int*>(&x);典型用途:函数参数是常引用,但内部需要调用仅接收非 const 的旧接口。
4. reinterpret_cast 底层重解释转换(风险最高,极少用)
纯粹二进制层面重新解释内存,无任何安全检查,不做类型兼容校验。 允许:
- 任意指针 ↔ 整数(如指针转 uint64_t 存地址);
- 不相关类型指针互相转换(int* ↔ double*、自定义类指针互转); 禁止:修改 const、算术类型隐式转换。
示例 1:指针转整数存地址
cpp
运行
int val = 10; uint64_t addr = reinterpret_cast<uint64_t>(&val);示例 2:不同类型指针强行重解释(极易越界崩溃)
cpp
运行
double d = 3.14; int* pp = reinterpret_cast<int*>(&d); // *pp 读取二进制浮点数据当成int,数值完全错乱使用规范:仅底层系统编程、驱动、序列化地址场景使用,业务代码杜绝。
三、四种转换速查表
表格
转换运算符 核心用途 检查时机 风险 static_cast 数值转换、有继承关系指针、void * 互转 编译期 中等,向下转无运行校验 dynamic_cast 多态基类安全向下转型 运行时 低,失败有明确返回 / 异常 const_cast 添加 / 去除 const、volatile 编译期 高,修改原生 constUB reinterpret_cast 二进制重解释,无关指针 / 地址与整数互转 无检查 极高,极易崩溃乱码
一、总前置知识点
- C 老式强转
(Type)val:等价混合 static+const+reinterpret,可读性差,项目禁止- C++ 四类强转各司其职,编译器会做对应检查,意图清晰
二、static_cast 静态转换(你做 static_cast 父子类题目踩坑)
适用场景
- 基础数值互转 int/double/float
- 父子类指针向上 / 向下转换
- void* 和普通指针互转
踩坑点
- 向上转型(子指针→父指针)完全安全,隐式可转 Derived* → Base* 无任何风险,不会切片
- 向下转型(父指针→子指针)极度危险,无运行时校验
- 编译器只检查二者有继承关系,不判断指针真实指向对象
- 若 Base * 实际指向纯 Base 对象,强转后访问子类独有成员:内存越界、未定义行为、崩溃
- 代码示例坑:
cpp
运行
Base obj; Base* p = &obj; Derived* d = static_cast<Derived*>(p); // 语法通过,运行必炸- 无法去掉 const 属性,不能修改 const 限定
- 数值转换存在窄化丢失精度,编译器不拦截(区别于 {} 列表初始化)
cpp
运行
int a = static_cast<int>(3.99); // 直接截断为3,无报错提醒- 只能转换有合法关联的类型,不相关指针不能转(int* → char* 不行,要用 reinterpret_cast)
三、dynamic_cast 动态转换(父子类向下安全转换)
前置硬性要求(踩坑高频)
父类必须存在虚函数(虚析构 / 虚成员),类才有虚表,否则编译报错
规则
- 仅用于多态父子类指针 / 引用向下转换
- 指针转换失败:返回 nullptr,可以 if 判断规避崩溃
- 引用转换失败:抛出
std::bad_cast异常,必须 try-catch 捕获踩坑点
- 无虚函数直接编译报错,很多人忘记给基类写 virtual 析构
- 只能向下转,不能用于普通数值、无关指针转换
- 运行时扫描虚表判断真实类型,有轻微性能损耗
四、const_cast 唯一修改 const/volatile 限定符
唯一功能:只增减顶层 const、volatile,不能改变底层类型
踩坑点
- 只能改指针 / 引用的 const,不能直接作用于普通值
- 去除 const 后,若原对象本身是 const 常量,写入修改属于未定义行为
cpp
运行
const int x = 10; int* p = const_cast<int*>(&x); *p = 99; // UB,标准未定义,程序行为不可预测- 无法完成父子类、数值、跨类型指针转换,只能配合其他 cast 使用
五、reinterpret_cast 底层二进制重解释(你 int 数组转 char * 代码踩坑重点)
作用
纯粹重新解读内存二进制比特,无任何类型转换逻辑、无安全检查
适用场景
- 指针 ↔ 整数(保存内存地址)
- 无关类型指针互相转换 int* ↔ char*
你代码踩坑汇总
- 数值≠字符 int 内存值 1,和 ASCII 字符 '1'(49) 完全两码事;按 char 打印只会输出不可见控制字符,看不到数字 int 占 4 字节,char 占 1 字节,转换后会把一个 int 拆成 4 个单字节
- 没有任何自动数值转换,只改解析规则
- 极度容易越界访问内存,程序直接崩溃
- 风险:不同类型内存布局不同,读写极易篡改内存、乱码、段错误
- 只能用于底层硬件 / 地址序列化,业务代码禁止使用
六、动态数组 new [] 搭配转换的配套踩坑(你代码里出现)
new int[N]数组释放必须配套delete[] p只写delete p;:只释放第一个元素,内存泄漏 + 内存损坏,强转后指针直接失效- char * 接收 int 数组指针后,遍历长度不能只遍历原数组元素个数,int4 字节,需要遍历总字节数
sizeof(int)*数组长度七、向上转型 / 向下转型 概念易错点
- 向上:子类 → 父类,安全,static_cast 随便转,不会切片
- 向下:父类 → 子类,不安全
- static_cast:编译放行,无运行检测,风险高
- dynamic_cast:运行校验,安全优先
- 实体对象赋值会切片:Base b = DerivedObj; 子类成员直接丢失,永远不能向下还原 只有指针 / 引用才能完整保留子类内存,支持向下转换
八、四类转换快速区分背诵表
表格
转换 核心用途 检查时机 最大坑 static_cast 数值、合法父子、void* 编译期 向下转型不校验真实对象 dynamic_cast 多态安全向下转 运行时 无虚函数直接编译报错 const_cast 增删 const/volatile 编译期 修改原生 const 变量 UB reinterpret_cast 二进制暴力重解释 无检查 内存乱解析、越界崩溃 九、通用强制转换通用注意事项
- 强制转换破坏类型安全,能不用就不用,优先重载、多态、转换构造替代
- 任何跨类型指针转换都存在内存读取风险
- 向下转换不确定真实类型时,一律用 dynamic_cast,拒绝裸 static_cast 向下转
- reinterpret_cast 仅底层开发使用,日常业务杜绝
new / delete
一、基础概念:区分单对象 & 数组动态内存
1. new + delete:单个对象
new在 ** 堆(heap)** 开辟一块内存,创建单个对象,自动调用构造函数;delete释放这块内存,自动调用析构函数。cpp
运行
// 1. 内置类型单个变量 int* p = new int; // 分配int内存,无初始化,值随机 int* p2 = new int{10};// 分配并初始化为10 // 2. 自定义类单个对象 class Person { public: Person() { std::cout << "构造\n"; } ~Person() { std::cout << "析构\n"; } }; Person* per = new Person; // 调用无参构造 delete per; // 调用析构,释放内存 per = nullptr;执行顺序:
new→ 堆分配内存 → 调用构造函数delete→ 调用析构函数 → 归还堆内存2. new [] + delete []:对象数组
一次性分配连续多块同类型内存,生成数组;
new[]会依次调用数组内所有元素的无参构造;delete[]逆序调用所有元素析构,再整体释放数组内存。cpp
运行
// 内置数组 int* arr = new int[3]{1,2,3}; // 3个int堆数组 // 自定义类数组:创建3个Person,逐个调用无参构造 Person* arr_per = new Person[3]; delete[] arr_per; // 3次析构,释放整片数组 arr_per = nullptr;关键时机总结(必背)
new T:分配内存 → 调用1 次构造函数new T[N]:分配连续 N 块内存 → 循环 N 次调用无参构造delete ptr:调用1 次析构函数 → 释放单块内存delete[] arr:逆序循环 N 次析构 → 释放整片数组内存二、内存分配与释放规范、踩坑点
1. 正确配对规则(重中之重)
必须严格配对,混用直接未定义行为(崩溃、内存损坏、内存泄漏)
new T↔delete ptrnew T[N]↔delete[] arr错误示例(你之前代码踩过):
cpp
运行
int* arr = new int[3]; delete arr; // 错误!new[] 必须配 delete[] // 后果:只析构/释放第一个元素,剩下内存泄漏,堆结构破坏2. 内存泄漏场景
- new 之后忘记 delete /delete [],堆内存程序结束前无法回收;
- 指针覆盖丢失堆地址:
cpp
运行
int* p = new int{10}; p = nullptr; // 丢失堆地址,再也无法释放,永久泄漏
- 分支提前 return,跳过释放代码;
- 异常抛出提前退出,没走到 delete。
3. 野指针规避
释放内存后指针依然存旧地址,变成野指针,再次访问崩溃; 规范:释放后置空
ptr = nullptr。cpp
运行
delete[] arr; arr = nullptr;4. new [] 初始化细节
new int[N]{}:全部元素值初始化为 0;new int[N]{1,2}:前两个赋值,剩余自动 0;- 自定义类数组:仅支持无参构造,无法直接传参构造;想要带参只能循环单个 new。
三、异常安全:std::bad_alloc
1. new 抛异常规则
堆内存耗尽、操作系统分配失败时,
new默认抛出std::bad_alloc异常,不会返回空指针。 头文件:<new>cpp
运行
#include <iostream> #include <new> // std::bad_alloc int main() { try { // 疯狂分配内存,模拟内存不足 while (true) { int* p = new int[100000]; } } catch (const std::bad_alloc& e) { std::cerr << "内存分配失败:" << e.what() << std::endl; } return 0; }2. 不抛异常的 new(定位 new,了解即可)
如果希望分配失败返回
nullptr而不抛异常,使用new(std::nothrow):cpp
运行
int* p = new(std::nothrow) int[9999999999]; if (p == nullptr) { std::cout << "内存不足,分配失败\n"; }3. 异常安全核心问题
如果 new 数组中途抛出异常,已经构造完成的对象会自动调用析构释放,不会内存泄漏:
cpp
运行
// 假设创建5个对象,第3个构造时报异常 Person* arr = new Person[5]; // 1、2号对象自动调用析构释放,不会残留4. 业务代码异常安全写法
使用
try-catch捕获分配失败; 复杂场景优先用std::vector:vector 自动管理内存,出作用域自动释放,无需手动 new/delete,天然规避泄漏、配对错误、异常安全问题。
1. 四种组合配对铁律(最核心大坑)
new T→ 单个对象,释放用delete p;new T[N]→ 对象数组,释放用delete[] p;严禁混用,混用直接 未定义行为 UB 错误示范:cpp
运行
int* arr = new int[3]; delete arr; // 错误,new[] 必须配 delete[]危害:只析构第一个元素、堆内存结构损坏、内存泄漏、程序随机崩溃。
2. 构造、析构调用时机
new T(xxx)先分配堆内存 → 调用1 次对应参数构造函数new T[N]分配连续 N 块内存 → 循环调用 N 次无参默认构造delete p调用1 次析构函数 → 释放单块堆内存delete[] p逆序循环 N 次析构所有数组元素 → 释放整片数组内存3. new [] 硬性限制:必须有无参构造
使用
new Point[3]时,类必须提供无参构造,否则编译报错。 原因:数组批量初始化只会调用默认构造,无法自动传参。 两种解决方案:
- 给类写无参构造
Point() : x(0),y(0){}- 不用 new [],改用指针数组循环单个 new Point (1,2)
二、初始化写法细节与坑
1. 单个对象 new
cpp
运行
Point* p1 = new Point(1,2); // 圆括号,稳定匹配双参构造,兼容所有C++标准 Point* p2 = new Point{1,2}; // 列表初始化{},优先匹配initializer_list构造坑:类没有 initializer_list 构造时,部分编译器不会回退匹配普通多参构造,出现构造不执行,优先用
()。2. new [] 数组初始化规则
- 全部默认构造:
Point* arr = new Point[3];3 次无参构造- 部分自定义,剩下默认构造:
Point* arr = new Point[3]{Point(1,2)};第一个自定义,后两个默认构造- 全部自定义元素:
Point* arr = new Point[3]{Point(1,2), Point(2,3), Point(3,4)};坑:不能写{(1,2)},(1,2)是逗号表达式,只会保留最后一个数字,类型不匹配编译报错。3. 内置类型默认值
cpp
运行
int* p = new int; // 无初始化,随机脏值 int* p = new int{}; // 值初始化,0 int* arr = new int[5]{}; // 数组全部初始化为0 int* arr = new int[5]{1,2}; // 前两位赋值,剩余自动0三、内存泄漏场景(高频坑)
- new 后忘记 delete /delete [],堆内存不会自动回收
- 指针被覆盖丢失堆地址:
cpp
运行
int* p = new int{10}; p = nullptr; // 堆内存彻底丢失,永久泄漏- 函数提前 return、抛出异常,跳过释放代码
- 分支判断遗漏 delete 分支
四、野指针相关坑
释放内存后,指针变量仍保存旧堆地址,变成野指针,再次访问崩溃:
cpp
运行
int* p = new int; delete p; std::cout << *p; // 野指针访问,UB崩溃规范写法:释放后置空
cpp
运行
delete p; p = nullptr;五、语法书写细节
- delete 不需要括号包裹指针,可读性更好
cpp
运行
delete(p); // 语法合法但不推荐 delete p; // 标准写法- 数组释放固定
delete[] p,不能写成delete[](p)六、内存分配异常 std::bad_alloc
- 默认 new 分配失败(内存耗尽)会抛出
std::bad_alloc,不会返回空指针,需要头文件<new>+ try-catch 捕获cpp
运行
try { int* p = new int[999999999]; } catch(const std::bad_alloc& e) { std::cerr << "内存分配失败:" << e.what() << std::endl; }
- 不抛异常版本:
new(std::nothrow),分配失败返回nullptr,适合不使用异常的项目cpp
运行
int* p = new(std::nothrow) int[99999]; if(p == nullptr) { std::cout << "内存不足"; }
- 异常安全保障:new [] 创建数组中途构造抛异常,已构造完成的对象会自动析构,不会内存泄漏。
七、多维动态数组坑
二维数组不能一步 new,需要先分配指针数组,再逐行分配;释放必须逆序先释放每行,再释放外层数组。
cpp
运行
int row = 2, col = 3; int** mat = new int*[row]; for(int i=0;i<row;i++) mat[i] = new int[col]{}; // 释放 for(int i=0;i<row;i++) delete[] mat[i]; delete[] mat; mat = nullptr;八、对比栈对象 区分易错点
- 栈对象
Point obj{1,2};
- 内存自动分配释放,离开作用域自动析构
- 无指针,用
.访问成员- 赋值给父类实体对象会发生对象切片,丢失子类成员
- new 堆对象
Point* p = new Point(1,2);
- 堆内存,必须手动 delete
- 指针存储地址,用
->访问成员- 父类指针指向子类不会切片,支持多态、downcast
九、工程开发避坑最佳实践
- 尽量少手动写 new/delete/new []/delete [],优先
std::vectorvector 自动管理内存,出作用域自动释放,不存在配对错误、内存泄漏、野指针问题- 必须手动动态内存时,遵循 RAII 思想,用类封装自动释放
- new 数组优先值初始化
new T[N]{},避免随机脏数据- 释放后统一置空指针,杜绝野指针访问
- 不确定内存是否充足时,使用 try-catch 捕获 bad_alloc 异常
拷贝 / 移动 / 赋值 构造
一、拷贝构造函数(Copy Constructor)
1. 基础概念
作用:新建对象时,用一个同类型已有对象初始化新对象。 触发场景:
Point p2 = p1;Point p2(p1);/Point p2{p1};- 函数传参(值传递)
void func(Point p)- 函数返回局部对象(值返回)
固定语法(必须是const 左值引用)
cpp
运行
class Point { public: // 拷贝构造函数 Point(const Point& other); };不能写
Point(Point other)(无限递归),必须引用。2. 编译器默认拷贝构造(浅拷贝)
如果你不写拷贝构造,编译器自动生成一个默认拷贝构造: 逐成员复制(值拷贝):
- 普通内置类型:直接复制值
- 指针:只复制指针地址,不复制指针指向的堆内存 → 浅拷贝
浅拷贝致命问题(堆资源类必踩坑)
cpp
运行
class Array { private: int* data; int len; public: Array(int n) { len = n; data = new int[n]; } ~Array() { delete[] data; } }; int main() { Array a(5); Array b = a; // 默认浅拷贝,a.data 和 b.data 指向同一块堆内存 // 函数结束,先析构b:delete[] data;再析构a:重复释放同一块内存 → 崩溃、未定义行为 return 0; }3. 深拷贝(解决浅拷贝重复释放)
手动开辟独立堆内存,复制数据,两个对象拥有各自资源:
cpp
运行
Array(const Array& other) { len = other.len; // 新开内存,不共用 data = new int[len]; for(int i=0; i<len; i++) data[i] = other.data[i]; }4. 核心区分
- 浅拷贝:只复制地址,资源共享 → 双重析构崩溃
- 深拷贝:复制完整资源,各自独立,安全
二、赋值运算符重载 operator=(拷贝赋值)
1. 作用
对象已经存在,用另一个对象覆盖它:
b = a;拷贝构造是「新建对象」,赋值重载是「已有对象覆盖」。2. 默认赋值运算符
编译器默认生成浅拷贝赋值,和默认拷贝构造问题一致:指针共享堆内存。
3. 手写深拷贝赋值,必须处理三大问题
- 自赋值:
a = a;,直接释放资源会清空自身数据再拷贝,出错;- 释放当前对象旧堆内存,防止泄漏;
- 分配新内存,拷贝对方数据。
标准安全写法
cpp
运行
Array& operator=(const Array& other) { // 1. 防止自赋值 if(this == &other) return *this; // 2. 释放自己旧资源 delete[] data; // 3. 分配新内存,深拷贝 len = other.len; data = new int[len]; for(int i=0; i<len; i++) data[i] = other.data[i]; return *this; // 返回自身引用,支持连续赋值 a=b=c }4. 自赋值危害
不判断
this == &other:a = a→ 先 delete [] data,自身数据全部清空,再拷贝空数据,对象损坏。
三、移动构造函数(Move Constructor)C++11
1. 背景:拷贝的性能缺陷
临时对象(右值)拷贝会重复开辟堆内存,开销大;临时对象马上销毁,没必要完整拷贝。 移动语义:窃取临时对象的堆资源,不复制内存,只转移指针,零拷贝高性能。
2. 右值引用
T&&移动构造参数必须是非 const 右值引用:
Array(Array&& other)仅接收临时对象、std::move转换后的对象。3. 实现逻辑
- 直接接管对方的指针、长度;
- 将原对象指针置空,原对象析构时不会释放已转移资源;
- 无内存分配,性能极高。
cpp
运行
Array(Array&& other) { // 窃取资源 data = other.data; len = other.len; // 原对象置空,析构不会重复释放 other.data = nullptr; other.len = 0; }4. 触发场景
cpp
运行
Array func() { return Array(10); // 返回临时对象,触发移动构造 } Array a = func(); Array b = std::move(a); // std::move把左值强制转为右值,触发移动std::move
作用:单纯强制转换为右值引用,本身不移动、不复制,仅改变类型,让移动构造 / 移动赋值被选中。
std::forward(完美转发)
模板中保留值类别(左 / 右值),按需决定拷贝还是移动,模板进阶使用。
四、移动赋值运算符 operator=(T&&)
作用
已有对象,接收临时对象资源,转移所有权。 同样要处理自移动赋值。
cpp
运行
Array& operator=(Array&& other) { // 自移动判断 if(this == &other) return *this; // 释放自身旧资源 delete[] data; // 接管对方资源 data = other.data; len = other.len; // 原对象置空 other.data = nullptr; other.len = 0; return *this; }移动语义核心价值
堆资源类(数组、字符串、容器)避免昂贵深拷贝,只转移指针,大幅提升性能。
五、四者对比速记
表格
函数 触发时机 参数类型 资源行为 拷贝构造 新建对象,用旧对象初始化 const T& 左值引用 深拷贝,两份独立资源 拷贝赋值 operator= 已有对象 a=b覆盖const T& 左值引用 释放旧资源 + 深拷贝 移动构造 新建对象,接收临时对象 T&& 右值引用 窃取资源,原对象置空 移动赋值 operator= 已有对象接收临时对象 T&& 右值引用 释放自身资源 + 窃取对方
六、全套高频坑点整理
1. 拷贝构造坑
- 参数不能传值
Point(Point p)→ 无限递归栈溢出;必须const Point&- 有堆指针不手写深拷贝,默认浅拷贝导致双重析构崩溃
- 忘记 const,无法接收 const 对象、临时对象
2. 拷贝赋值坑
- 不判断自赋值
if(this == &other),自赋值清空自身数据- 不释放自身旧堆内存 → 内存泄漏
- 返回值不写
T&,无法连续赋值a=b=c3. 移动相关坑
- 移动构造 / 移动赋值参数不能加 const,加 const 无法修改对方指针置空
- 转移资源后不把原对象指针置空 → 双重释放崩溃
- 误以为 std::move 会移动资源:move 只是类型转换,真正移动靠移动构造 / 移动赋值
- 左值不加 std::move 不会触发移动,只会走拷贝
4. 默认函数生成规则
- 自己写拷贝构造 → 编译器不生成移动构造 / 移动赋值
- 自己写移动构造 → 编译器不生成默认拷贝构造
- 拥有动态堆内存的类,必须手动实现拷贝 / 移动 / 赋值 / 析构(RAII 规范)
5. 浅拷贝 / 深拷贝 / 移动三层区别
- 浅拷贝:共享资源,危险,仅内置无指针类可用
- 深拷贝:两份独立资源,安全,开销大
- 移动:资源转移,不复制,高性能,原对象作废
一、四大核心函数总览
类持有裸指针
int*堆资源时,必须手动实现 4 个函数,否则默认浅拷贝崩溃:
- 拷贝构造
T(const T&)- 拷贝赋值
T& operator=(const T&)- 移动构造
T(T&&)- 移动赋值
T& operator=(T&&)配套:析构函数释放堆内存二、拷贝构造函数 Copy Constructor
1. 基础规则
触发场景:新建对象,用已有同类型对象初始化
T a(b);/T a = b;/ 函数值传参、值返回 标准签名:MyClass(const MyClass& other)
- 参数必须const 左值引用
2. 你踩过的坑
- ❌ 错误写法
MyClass(MyClass other)参数值传递,构造时需要拷贝实参,无限递归栈溢出;必须用引用&。- ❌ 默认编译器拷贝构造 = 浅拷贝灾难 只复制指针地址,两个对象共享同一块堆内存;析构时
delete[]重复释放,程序崩溃。- ❌ 深拷贝逻辑写错:
data_[i] = i;只填下标数字,没有复制源对象other.data_的数据,根本不叫拷贝。 ✅ 正确:data_[i] = other.data_[i];- ❌ 无参构造不初始化裸指针
data_MyClass my;后data_是随机野指针,拷贝构造读取随机len_,new超大内存直接崩溃。 ✅ 无参构造初始化:MyClass() : data_(nullptr), len_(0){}- ❌ 浅拷贝写法
data_ = other.data_;仅复制指针地址,资源共享,双重析构崩溃;深拷贝必须new全新内存。3. 浅拷贝 vs 深拷贝
- 浅拷贝:复制指针地址,共用堆内存,裸指针类禁用;
- 深拷贝:新开独立堆数组,逐元素复制数据,两个对象资源完全隔离,安全。
4. 替代方案(不用手写深拷贝)
成员不用裸指针
int* data_,改用std::vector<int> data_,vector 自带深拷贝,编译器默认生成的拷贝构造完全安全。三、拷贝赋值运算符 operator=
1. 基础规则
触发场景:对象已存在,覆盖赋值
a = b;标准签名:MyClass& operator=(const MyClass& other)返回*this引用,支持链式赋值a=b=c2. 三大必须处理逻辑(你踩坑点)
- ❌ 不做自赋值判断
if(this == &other)自赋值a=a会先delete[]清空自身数据,再拷贝空内容,对象彻底损坏。- ❌ 忘记释放自身旧堆内存 旧
data_内存丢失,永久内存泄漏;必须先delete[] data_。- ❌ 返回值写
void,无法链式赋值;必须返回T&。- ❌ 参数漏写
const无法接收 const 对象、临时对象,语法不规范。标准安全流程
- 判断自赋值,相等直接 return;
- 释放自己旧堆资源;
- 分配新内存,深拷贝对方数据;
return *this。四、移动构造函数 Move Constructor(C++11)
1. 基础概念
作用:窃取临时右值对象的堆资源,不拷贝内存,高性能,临时对象即将销毁,无需保留资源。 标准签名:
MyClass(MyClass&& other)
- 参数是非 const 右值引用
T&&2. 你踩过的高频大坑
- ❌ 参数加
const:MyClass(const MyClass&& other)const 修饰后other内部成员只读,无法执行other.data_ = nullptr;,报「表达式必须是可修改左值」编译错误。 ✅ 移动相关函数绝对不能加 const,需要修改源对象置空指针。- ❌ 转移资源后
delete other.data_;this->data_ = other.data_后两者指向同一块堆;直接 delete 会销毁内存,当前对象变成野指针,析构崩溃。 ✅ 移动语义只抢资源,不销毁对方内存;只需要把other指针置空。- ❌ 忘记置空源对象
other.data_ = nullptr;源对象析构时会delete[]已转移的堆内存,双重释放崩溃。 原理:delete[] nullptr是 C++ 合法空操作,不会报错。- 误区:
std::move不会移动资源std::move只是强制把左值转为右值引用,仅改变类型;真正移动逻辑靠移动构造 / 移动赋值。3. 移动构造逻辑(新建空对象,无旧资源,不需要 delete)
- 接管对方指针、长度:
data_ = other.data_; len_ = other.len_;- 源对象指针置空、长度清零:
other.data_ = nullptr; other.len_ = 0;五、移动赋值运算符 operator=(T&&)
1. 基础规则
触发:已有对象接收临时对象资源
a = std::move(b);签名:MyClass& operator=(MyClass&& other)2. 和移动构造的核心区别(你容易混淆)
移动构造:新建对象,自身无旧堆内存,不需要
delete[]; 移动赋值:对象已经存在,持有旧堆资源,必须先释放,否则内存泄漏。3. 踩坑点
- ❌ 不判断自移动赋值
this == &other,a = std::move(a)直接清空自身资源;- ❌ 忘记
delete[] data_释放自身旧内存,内存泄漏;- ❌ 转移资源后不置空源对象,双重释放崩溃;
- ❌ 返回 void,不支持链式赋值。
标准流程
- 自赋值判断;
- delete 释放自身旧堆;
- 接管对方资源;
- 源对象指针置空;
return *this。六、移动语义 vs 深拷贝 核心区别
- 深拷贝:开辟两份独立堆内存,数据完整复制,开销大,新旧对象都可用;
- 移动:仅转移指针地址,不开辟新内存,性能极高;源对象置空后失效,不能再使用其堆资源。
七、指针调用成员函数补充(你提问过)
- 实体对象:
obj.函数();点号.- 对象指针:
p->函数();箭头->等价写法(*p).函数();,括号不能省略。八、new/delete 配套坑(和拷贝联动)
new T配delete p;new T[N]配delete[] p,混用 UB 崩溃;- 裸指针必须在构造初始化、析构释放,否则泄漏 / 野指针;
- vector 内部自动管理内存,不需要手动 new/delete,规避 90% 拷贝内存 bug。
九、高频报错速查清单(你遇到过的全部)
other.data_ = nullptr;报错不可修改左值 → 移动函数参数带了const,删掉 const;- 运行析构崩溃、双重释放 → 浅拷贝共享资源 / 移动未置空源对象;
- 拷贝构造无限递归 → 参数传值
T(T o),改为const T&;- std::move 未定义 → 缺少头文件
#include <utility>;- 自赋值后对象数据错乱 → 赋值运算符缺少
if(this == &other)判断;- 内存泄漏 → 赋值前没有
delete[]释放自身旧堆内存;- 无参对象拷贝直接崩溃 → 裸指针未初始化为
nullptr,随机野指针。
std::move 移动语义
1. std::move 的本质
- 头文件:
<utility>- 只做一件事:强制把任意变量转换成「右值引用 T&&」 它不拷贝、不转移内存、不修改对象,单纯是类型转换工具; 真正的资源窃取(移动逻辑)是类内部的移动构造 / 移动赋值完成的。
- 语法:
std::move(变量)左值 → 转成右值,编译器优先匹配移动重载,不再走深拷贝。2. 移动语义设计目的
普通深拷贝会完整开辟一份堆内存、复制全部数据,大型数组 / 容器对象开销极高; 移动语义直接转移堆资源所有权,只拷贝指针地址,无内存分配,零开销,大幅提升性能。
3. 移动完成后原对象的状态标准
C++ 标准规定:被移动后的源对象是有效但未定义(valid but unspecified)
- 允许操作:析构(
delete[] nullptr安全无崩溃)、赋值覆盖;- 禁止操作:读取原有资源、访问内部数据(资源已经被抢走,指针置空);
- 我们代码里统一把源对象
data_ = nullptr; len=0,保证它只会空析构,杜绝双重释放。示例
cpp
运行
MyClass a(100); MyClass b = std::move(a); // a 的堆内存全部转移给b // 此时 a 处于“可析构,但不能读数据”的状态 // std::cout << a.getPtr() 只会输出0,不能使用数组内容
二、移动构造 / 移动赋值 完整规范实现
1. 移动构造函数
标准签名
cpp
运行
// 不能加const!需要修改源对象指针置空 MyClass(MyClass&& other)执行逻辑(新建对象,自身无旧资源,无需 delete)
- 直接接管对方的堆指针、长度;
- 将源对象
other的指针置空、长度清零;- 源对象析构时只会释放空指针,不会重复释放内存。
完整模板
cpp
运行
MyClass(MyClass&& other) { // 窃取资源 data_ = other.data_; len_ = other.len_; // 源对象置空,保证移动后安全析构 other.data_ = nullptr; other.len_ = 0; }你之前踩坑
❌
MyClass(const MyClass&& other):const 修饰后无法修改 other 内部成员,other.data_ = nullptr编译报错。2. 移动赋值运算符
标准签名
cpp
运行
MyClass& operator=(MyClass&& other)和移动构造核心区别
移动构造是全新空对象,没有旧堆资源; 移动赋值是已有对象,自身持有旧堆内存,必须先释放,否则内存泄漏。
标准四步流程
- 自移动赋值判断
if(this == &other),防止a = std::move(a)清空自身资源;delete[] data_释放自己旧堆内存;- 接管对方资源;
- 源对象指针置空;
return *this支持链式赋值。完整模板
cpp
运行
MyClass& operator=(MyClass&& other) { // 1. 防护自移动赋值 if (this == &other) return *this; // 2. 释放自身旧资源 delete[] data_; // 3. 转移资源 data_ = other.data_; len_ = other.len_; // 4. 源对象置空 other.data_ = nullptr; other.len_ = 0; return *this; }你之前踩坑
❌ 转移资源后写
delete other.data_:同一块内存被销毁,当前对象变成野指针,析构崩溃。3. 何时禁用拷贝 / 移动函数
场景 1:资源不可拷贝(文件句柄、套接字、unique_ptr)
资源全局唯一,不能复制,需要禁用拷贝:
cpp
运行
// 删除拷贝构造、拷贝赋值,禁止深拷贝 MyClass(const MyClass&) = delete; MyClass& operator=(const MyClass&) = delete; // 保留移动,支持资源转移 MyClass(MyClass&&); MyClass& operator=(MyClass&&);场景 2:资源不可移动(静态全局硬件资源、共享锁)
资源不能转移所有权,直接删除移动函数:
cpp
运行
MyClass(MyClass&&) = delete; MyClass& operator=(MyClass&&) = delete;场景 3:完全禁止复制、移动(单例类)
全部删除:
cpp
运行
MyClass(const MyClass&) = delete; MyClass& operator=(const MyClass&) = delete; MyClass(MyClass&&) = delete; MyClass& operator=(MyClass&&) = delete;
三、std::move 正确使用场景 & 误区
1. 自动触发移动(不需要手动写 std::move)
函数返回局部临时对象(右值),编译器自动匹配移动构造,无需手动转换:
cpp
运行
MyClass createTemp() { return MyClass(10); // 局部对象是右值,自动移动 } // 自动触发移动构造 MyClass obj = createTemp();2. 必须手动使用 std::move 的场景
变量是左值,但你明确不需要原对象,希望转移资源:
cpp
运行
MyClass a(100); MyClass b = std::move(a); // a是左值,手动转右值触发移动构造 MyClass c; c = std::move(b); // 移动赋值3. 函数传参优化,减少拷贝
向函数传递大型对象时用
std::move转移资源:cpp
运行
void func(MyClass&& param) {} MyClass bigObj(1000); func(std::move(bigObj)); // 移动传入,无拷贝4. 高频误区(重点记)
误区 1:std::move 会移动对象
错。move 只是类型转换,没有任何内存操作; 如果类没有实现移动构造,
std::move(obj)依旧会走拷贝构造。误区 2:移动后的对象可以正常读写数据
错。标准规定移动后对象仅保证可析构,内部资源已被夺走,读取数据行为不可预测,业务代码不要再使用原对象。
误区 3:对 const 对象使用 std::move 有意义
错。
const MyClass&&无法匹配移动构造(移动函数不能带 const),只会走拷贝,完全失去移动性能优势。误区 4:频繁 move 小对象提升性能
错。小型内置类(只有几个 int)拷贝开销极低,不需要移动语义;移动语义专为堆资源 / 大型容器设计。
误区 5:返回全局 / 静态变量用 std::move
错。全局变量生命周期不会销毁,转移资源会导致原对象悬空析构,程序崩溃;只有局部临时对象适合自动移动。
四、移动语义全套对比笔记
表格
项目 深拷贝 移动语义 内存操作 开辟全新堆内存,完整复制数据 仅转移指针地址,不分配内存 性能 开销大,大数据卡顿 零拷贝,性能极高 源对象状态 完整保留,两个对象独立可用 源对象有效但失效,仅能析构 触发条件 左值对象赋值 / 初始化 右值 /std::move 转换后的左值 核心函数 T(const T&)/operator=(const T&)T(T&&)/operator=(T&&)
一、核心基础概念
- std::move 本质
- 头文件:
<utility>- 只做类型强制转换:把左值转为右值引用
T&&;不拷贝、不转移资源、不修改对象内存。- 真正的资源转移逻辑,写在移动构造 / 移动赋值函数内部。
- 移动语义目的 针对持有堆资源(裸指针、
string、vector)的大型对象,避免昂贵深拷贝;只转移资源所有权,零内存分配,提升性能。- 移动后源对象标准状态 C++ 标准定义:有效但未指定(valid but unspecified)
- 允许操作:安全析构、重新赋值覆盖
- 禁止操作:读取原资源数据(资源已被夺走,结果不可预测)
- 我们手写裸指针类时统一置空
other.data_ = nullptr,保证析构安全。二、移动构造函数 细节 & 踩坑
标准签名
cpp
运行
// 绝对不能加 const MyClass(MyClass&& other) { // 1. 接管对方资源 data_ = other.data_; len_ = other.len_; // 2. 源对象置空,防止双重释放 other.data_ = nullptr; other.len_ = 0; }你踩过的坑
- ❌ 参数写
const MyClass&& otherconst 修饰后,other内部成员只读,无法执行other.data_ = nullptr;,编译报错「表达式必须是可修改左值」。 ✅ 移动相关函数参数一律不加 const。- ❌ 转移资源后
delete other.data_;this->data_和other.data_指向同一块堆内存,提前 delete 会销毁资源,当前对象变成野指针,析构崩溃。 ✅ 移动是「抢资源自用」,不能销毁源对象内存,只需要置空指针。- ❌ 忘记置空源对象
other.data_ = nullptr;源对象析构时会重复 delete 同一块堆内存,程序崩溃。 ✅delete[] nullptr是标准安全空操作,无任何副作用。- 概念细节:移动构造是新建空对象,自身没有旧堆资源,不需要执行
delete[] data_。三、移动赋值运算符 细节 & 踩坑
标准签名
cpp
运行
MyClass& operator=(MyClass&& other) { // 1. 自移动赋值防护 if(this == &other) return *this; // 2. 释放自身旧资源(和移动构造核心区别) delete[] data_; // 3. 接管资源 data_ = other.data_; len_ = other.len_; // 4. 源对象置空 other.data_ = nullptr; other.len_ = 0; return *this; // 返回引用支持链式赋值 a = b = std::move(c) }你踩过的坑
- ❌ 不写自移动判断
if(this == &other)执行m = std::move(m)时,会先 delete 清空自身资源,后续无数据可转移,对象彻底损坏。- ❌ 忘记
delete[] data_释放自身旧内存 当前对象原本持有的堆内存丢失,永久内存泄漏。- ❌ 返回值写
void无法支持链式连续赋值语法a = b = std::move(c)。- ❌ 混淆移动构造与移动赋值
- 移动构造:新对象,无旧内存 → 不用 delete
- 移动赋值:已有对象,持有旧内存 → 必须先 delete 旧资源
四、std::move 使用规则 & 踩坑
1. 什么时候自动触发移动(不需要手动 std::move)
函数返回局部临时对象(天然右值),编译器自动匹配移动构造:
cpp
运行
MyClass tempFunc(){ return MyClass(10); // 临时右值,自动移动 } MyClass obj = tempFunc();2. 什么时候必须手动写
std::move(左值)变量是具名左值,你确定不再使用原对象,需要转移资源:
cpp
运行
MyClass m(100); MyClass n = std::move(m); // 左值转右值,触发移动构造 MyClass k; k = std::move(n); // 触发移动赋值你踩过的误区
- ❌ 误以为
std::move会移动 / 销毁对象 move 只是单纯类型转换,没有任何内存操作;没有移动重载时,std::move 依然只会走拷贝构造。- ❌ 移动后继续读取源对象内部数据 源对象资源已转移,读取结果无意义,属于未定义行为。
- ❌ 对 const 对象使用 std::move
const MyClass a; std::move(a)得到const MyClass&&,无法匹配移动函数,只会走深拷贝,完全失去移动性能优势。- ❌ 多余对临时对象写 std::move
MyClass n = std::move(tempFunc());代码冗余,临时对象本身就是右值,不需要转换。- ❌ 忘记引入头文件
<utility>,std::move 报未定义标识符。五、裸指针 vs std::string/vector 移动写法区别(重点错题)
场景 1:成员是裸指针
int* data_(你第一套代码)必须手动接管指针、手动置空源对象,否则双重释放崩溃。
cpp
运行
data_ = other.data_; other.data_ = nullptr; // 必须手写场景 2:成员是标准容器
std::string name_(你第二套错题)容器内部自带完整移动语义,不能赋值 nullptr,不用手动置空,需要调用容器自身移动:
cpp
运行
name_ = std::move(other.name_); // 禁止:other.name_ = nullptr; string不支持空指针赋值你踩的对应错误
cpp
运行
// 错误代码(string不能赋值nullptr) StringWrapper& operator=(StringWrapper &&other){ name_ = other.name_; other.name_ = nullptr; // 编译报错! }六、构造函数配套坑(关联移动初始化)
- 无参构造 + 有参构造可以同时存在,属于合法重载;
- 裸指针类无参构造必须初始化
data_(nullptr),否则随机野指针;StringWrapper s2();经典语法陷阱:这是函数声明,不是创建对象,后续赋值报错; ✅ 创建无参对象正确写法:StringWrapper s2;/StringWrapper s2{};std::string不能用nullptr初始化,空对象写name_("")。七、何时禁用拷贝 / 移动函数
- 资源唯一不可复制(文件句柄、
unique_ptr):删除拷贝构造、拷贝赋值cpp
运行
MyClass(const MyClass&) = delete; MyClass& operator=(const MyClass&) = delete;- 资源不可转移(全局硬件锁、静态资源):删除移动构造、移动赋值
cpp
运行
MyClass(MyClass&&) = delete; MyClass& operator=(MyClass&&) = delete;- 单例类:全部删除,禁止拷贝与移动。
八、左值、右值匹配逻辑速记
- 普通具名变量(
m、s1)= 左值 不加 move → 匹配const T&拷贝重载,执行深拷贝 加std::move()→ 转为右值引用T&&,匹配移动重载- 临时对象、函数返回值 = 天然右值,自动匹配移动重载
- 赋值运算符左侧必须是左值对象(如
s2 = std::move(s1),s2 是左值完全合法)九、移动语义高频报错速查表
other.data_ = nullptr;不可修改左值 → 移动函数参数带了const,删除 const- std::move 未定义 → 缺少头文件
<utility>- string 赋值
nullptr编译报错 → 容器不用手动置空,改用std::move转移- 移动后析构双重释放崩溃 → 忘记置空源对象指针
- 自赋值后对象数据清空 → 缺少
if(this == &other)自判断- 内存泄漏(移动赋值)→ 未提前
delete[]自身旧裸指针StringWrapper s2();赋值报错 → 这是函数声明,改为StringWrapper s2;十、深拷贝 vs 移动语义对比(背诵)
表格
对比项 深拷贝 移动语义 内存操作 开辟全新堆内存,完整复制数据 仅转移指针地址,不分配内存 性能 开销大,大数据卡顿 零拷贝,性能极高 源对象状态 完整独立可用,两份资源 有效但失效,仅可析构 / 重新赋值 触发条件 左值无 std::move 右值 /std::move 转换后的左值 核心函数 T(const T&)、operator=(const T&)T(T&&)、operator=(T&&)
RAII
1. RAII 全称与定义
RAII = Resource Acquisition Is Initialization,资源获取即初始化 核心机制:
- 构造函数 = 获取资源:对象创建时(初始化阶段)主动申请资源(堆内存、文件句柄、锁、网络套接字);
- 析构函数 = 释放资源:对象生命周期结束时(出作用域、函数 return、异常退出)自动释放资源;
- 资源的生命周期完全绑定对象的生命周期,对象死,资源必释放。
2. RAII 核心作用(解决三大资源痛点)
- 杜绝内存 / 资源泄漏:不用手动写
delete/fclose,对象销毁自动释放;- 异常安全:哪怕代码中途抛异常,栈上局部对象会自动析构,资源不会丢失;
- 避免重复释放、野指针:资源管理权统一交给对象,不用人工管理裸资源。
3. 对比裸指针(无 RAII)vs RAII 类(自动管理)
裸指针(危险,不满足 RAII)
cpp
运行
void badFunc() { int* arr = new int[10]; // 手动获取资源 if(true) return; // 提前return,忘记delete → 内存泄漏 delete[] arr; // 必须手动释放,极易遗漏 }RAII 封装类(安全)
cpp
运行
void goodFunc() { MyArray arr(10); // 构造自动new获取堆资源 if(true) return; // 函数退出,局部对象自动析构,自动delete[] }二、RAII 底层核心机制:栈对象自动析构
C++ 规定:栈上局部对象,离开当前作用域(
}、return、异常 throw)一定会调用析构函数。 作用域场景:
- 函数执行完毕 return;
if/for/while代码块};- 代码抛出异常,程序栈展开(栈解旋)。
无论哪种退出方式,析构一定会执行,资源必然释放,这是 RAII 异常安全的根本。
三、标准 RAII 类完整实现(两类案例:堆内存、文件)
案例 1:管理动态堆内存(你之前写的 MyClass,标准 RAII 模板)
满足 RAII 四要素:
- 构造函数申请堆内存;
- 析构函数释放堆内存;
- 实现拷贝 / 移动语义,正确转移 / 复制资源所有权;
- 资源生命周期完全绑定对象。
cpp
运行
#include <iostream> #include <utility> class RAII_Array { private: int* data_; int len_; public: // 1. 构造函数:获取资源 new 堆内存(RAII核心第一步) explicit RAII_Array(int n) { len_ = n; data_ = new int[n]{}; std::cout << "构造:分配堆内存 " << data_ << "\n"; } // 无参构造:获取空安全资源(nullptr,无堆内存占用) RAII_Array() : data_(nullptr), len_(0) {} // 拷贝构造:深拷贝,创建独立资源(资源所有权复制) RAII_Array(const RAII_Array& other) { len_ = other.len_; data_ = new int[len_]; for(int i=0; i<len_; i++) data_[i] = other.data_[i]; } // 移动构造:转移资源所有权,不拷贝 RAII_Array(RAII_Array&& other) { data_ = other.data_; len_ = other.len_; other.data_ = nullptr; other.len_ = 0; } // 拷贝赋值、移动赋值 管理资源复用逻辑(省略,前面学过) RAII_Array& operator=(const RAII_Array& other); RAII_Array& operator=(RAII_Array&& other); // 2. 析构函数:释放资源 delete[](RAII核心第二步) ~RAII_Array() { delete[] data_; std::cout << "析构:释放堆内存 " << data_ << "\n"; } }; void test() { RAII_Array arr(5); // 构造自动分配内存 throw 1; // 主动抛异常,测试异常安全 // 不用手动delete,异常退出自动析构释放内存 } int main() { try{ test(); }catch(...){ std::cout << "捕获异常,但资源已自动释放\n"; } return 0; }案例 2:文件句柄 RAII 封装(管理操作系统资源)
cpp
运行
#include <iostream> #include <cstdio> class RAII_File { private: FILE* file_; public: // 构造:打开文件,获取文件资源 RAII_File(const char* path, const char* mode) { file_ = fopen(path, mode); if(!file_) throw "文件打开失败"; } // 析构:自动关闭文件,释放句柄资源 ~RAII_File() { if(file_) fclose(file_); std::cout << "文件资源自动关闭\n"; } // 禁止拷贝:文件句柄全局唯一,不能复制 RAII_File(const RAII_File&) = delete; RAII_File& operator=(const RAII_File&) = delete; // 允许移动:转移文件所有权 RAII_File(RAII_File&& other) { file_ = other.file_; other.file_ = nullptr; } }; int main() { RAII_File f("test.txt", "w"); // 构造打开文件 // 无论函数正常退出、抛异常,析构自动fclose,不会文件句柄泄漏 return 0; }四、RAII 配套资源所有权规则(拷贝 / 移动 / 删除函数)
资源分为两类,RAII 类要对应处理拷贝、移动:
- 可复制资源(堆数组、string) 实现深拷贝构造、拷贝赋值;同时实现移动语义优化性能。
- 不可复制资源(文件、锁、unique_ptr、套接字) 使用
=delete删除拷贝构造、拷贝赋值;仅保留移动语义,允许资源转移。- 完全不可转移资源(全局硬件资源) 拷贝、移动函数全部
=delete。五、RAII 自带优势:异常安全(重点考点)
场景:裸指针会泄漏
cpp
运行
void bad() { int* p = new int[10]; func(); // func内部抛异常 // 异常直接跳出函数,delete永远执行不到 → 内存泄漏 delete[] p; }场景:RAII 类自动释放
cpp
运行
void good() { RAII_Array arr(10); func(); // 抛异常 // 栈展开,arr析构自动delete[],资源无泄漏 }原理:栈上局部对象一定会析构,不受异常、提前 return 影响。
六、RAII 实际工程应用(标准库内置 RAII 工具)
C++ 标准库大量使用 RAII,日常开发直接用,不用自己手写封装:
std::vector/std::string:管理堆内存,自动 new/delete;std::unique_ptr/std::shared_ptr:智能指针,裸指针 RAII 封装;std::lock_guard/std::unique_lock:互斥锁 RAII,构造加锁、析构自动解锁;std::ifstream/std::ofstream:文件流,自动打开关闭文件。示例:锁 RAII,防止死锁 / 忘记解锁
cpp
运行
#include <mutex> std::mutex mtx; void safeFunc() { std::lock_guard<std::mutex> lock(mtx); // 构造自动加锁 // 代码中途return/抛异常,离开作用域lock析构自动解锁 }七、RAII 使用高频坑点(笔记必记)
坑 1:创建堆上的 RAII 对象(new RAII_Array),忘记 delete
RAII 仅对栈局部对象自动析构;如果用
new创建对象,对象本身在堆,必须手动delete,否则对象不析构、内部资源泄漏。cpp
运行
void error() { RAII_Array* p = new RAII_Array(10); return; // 忘记delete p; 对象不析构,堆内存泄漏! } // 正确:优先栈对象;堆RAII对象必须配套delete void correct() { RAII_Array arr(10); // 栈对象,自动析构 }坑 2:返回局部 RAII 对象,担心资源提前释放
不会!返回局部对象触发移动构造,资源所有权转移给外部接收对象,原局部对象置空,不会提前释放资源。
cpp
运行
RAII_Array createArr() { RAII_Array temp(10); return temp; // 移动构造转移资源,无泄漏 }坑 3:RAII 类只写析构释放,构造不做资源校验
构造获取资源失败(文件打不开、内存分配失败)要抛异常;如果构造中途失败,已经申请的资源要提前释放,避免半构造对象泄漏。
坑 4:移动后原对象提前销毁导致资源重复释放
移动构造 / 移动赋值必须将源对象资源指针置空
other.data_ = nullptr,源对象析构时delete[] nullptr安全,不会重复释放。坑 5:把资源裸指针暴露给外部,脱离 RAII 管控
不要写
int* getRawData(){ return data_; }让外部直接操作裸指针,外部手动 delete 会造成双重释放;如需访问数据,提供下标 / 只读接口。坑 6:全局 RAII 对象生命周期不可控
全局对象在 main 函数结束后才析构,资源释放延迟,不推荐管理临时资源。
左值、右值、左右值引用、std::move、std::forward
一、基础概念:左值 Lvalue / 右值 Rvalue
1. 左值 Lvalue
定义:拥有持久身份、有稳定内存地址、生命周期长的具名对象 特征:
- 有变量名,能取地址
&变量;- 可以放在赋值运算符
=的左边;- 生命周期持续到当前作用域结束。
典型左值:
cpp
运行
int a = 10; a; // 变量a是左值 int arr[5]; arr[0]; // 数组元素左值 ScopedPtr p(5); p; // 自定义对象左值2. 右值 Rvalue
定义:临时对象,无持久名字、生命周期转瞬即逝,仅存在表达式求值过程 分类:纯右值(字面量、临时对象) 特征:
- 不能取地址
&10编译报错;- 只能放在赋值
=右侧;- 表达式结束直接销毁。
典型右值:
cpp
运行
10; // 数字字面量 std::string("abc"); // 临时字符串对象 func(); // 函数返回局部临时对象 a + b; // 运算表达式结果临时值快速区分口诀
能取地址、有名字 = 左值; 临时、字面量、无名字 = 右值。
二、左值引用 & 右值引用
1. 左值引用
T&语法:
类型 &变量 = 左值;绑定规则:只能绑定左值,绝对不能直接绑定右值cpp
运行
int x = 10; int& r1 = x; // ✅ 合法,绑定左值x int& r2 = 20; // ❌ 报错,20是右值,普通左值引用绑不上 // const左值引用特殊规则:const T& 可以绑定左值+右值 const int& r3 = 20; // ✅ 允许,const万能引用用途:拷贝构造、拷贝赋值参数
const T& other。2. 右值引用
T&&(C++11 新增)语法:
类型 &&变量 = 右值;绑定规则:只能绑定天然右值 /std::move 转换后的左值 核心作用:匹配移动构造、移动赋值,实现移动语义,避免深拷贝。cpp
运行
int&& rr1 = 10; // ✅ 绑定字面量右值 int a = 20; int&& rr2 = std::move(a); // ✅ std::move把左值转成右值引用,才能绑定 int&& rr3 = a; // ❌ 报错,a是原生左值,无法直接绑定右值引用关键限制总结
T&:仅左值;const T&:左值、右值全都能绑;T&&:仅天然右值 /move 转换后的左值;const T&&:无实用价值,不能修改源对象,无法实现移动,基本不用。三、std::move 完整原理
1. 本质
std::move(obj)只做类型强制转换:把任意变量强制转为T&&右值引用,不移动、不拷贝、不销毁对象。 真正的资源转移逻辑,写在移动构造 / 移动赋值内部。2. 使用场景
- 具名左值,想要触发移动语义:
cpp
运行
ScopedPtr a(10); ScopedPtr b = std::move(a); // 左值a转为右值引用,匹配移动构造
- 天然右值无需 move,写了多余:
cpp
运行
ScopedPtr b = createTemp(); // 返回临时右值,自动匹配移动,不用move3. move 后对象状态
C++ 标准:有效但未指定 仅保证可以安全析构、重新赋值;禁止读取原有资源数据。
4. 常见误区
- 误区 1:move 会转移 / 销毁对象 → 错,只是类型转换;
- 误区 2:move 之后原对象不能用 → 仅不能读旧资源,可以析构、重新赋值;
- 误区 3:const 对象 move 有意义 →
const T&&无法匹配移动重载,只会拷贝。四、完美转发 std::forward
1. 出现背景
模板函数传参时,参数会丢失原本的「左 / 右值属性」,无论传入左值还是右值,模板参数都会被推导为普通左值,无法触发移动。
std::forward<T>(arg)作用:保留参数原始值类别,原样转发(左值仍为左值,右值仍为右值),即完美转发。2. 核心规则
模板中
T&&叫万能引用,会根据实参自动推导:
- 传入左值
int a→ T = int&,推导为int& && = int&(左值引用);- 传入右值
10→ T = int,推导为int&&(右值引用);搭配
std::forward<T>(arg)还原原本的值类别:
- 左值实参 → forward 后仍是左值;
- 右值实参 → forward 后仍是右值。
3. 最简示例
cpp
运行
#include <utility> // 万能引用模板 template<typename T> void wrapper(T&& val) { // 原样转发val,保留左/右值属性 targetFunc(std::forward<T>(val)); } void targetFunc(int& x) { std::cout << "传入左值\n"; } void targetFunc(int&& x) { std::cout << "传入右值\n"; } int main() { int a = 10; wrapper(a); // 左值,打印【传入左值】 wrapper(20); // 右值,打印【传入右值】 }如果不用 forward,无论传入左 / 右值,都会统一变成左值,永远只会调用左值版本函数,丢失移动语义。
4. std::move vs std::forward 核心区别
表格
std::move std::forward 无条件强制转为右值引用 有条件转发,保留原始左右值属性 普通代码手动转移资源使用 仅模板万能引用场景使用 不需要模板参数 必须传入模板类型参数 forward<T>消耗左值,移动后源对象失效 不改变对象状态,仅转发类型
左值 & 右值 基础细节与坑
核心细节
- 左值 (Lvalue)
- 有变量名、拥有稳定内存地址,可以
&取地址;- 能放在赋值号
=左边;生命周期持久。 示例:普通变量、数组元素、类对象。- 右值 (Rvalue)
- 临时对象 / 字面量,无持久名字,表达式结束立刻销毁;
- 不能取地址,仅能放在
=右侧;分为字面量、函数返回临时对象、运算表达式结果。- 快速区分口诀:有名字可取地址 = 左值;临时无名字 = 右值。
踩坑
- 误区:“右值没有内存地址” 底层内存真实存在,只是语法不允许程序员取地址,不是不存在。
- 误区:函数返回局部变量一定是右值 返回局部对象是天然右值;但返回全局 / 静态变量是左值,不要随便
std::move,会造成双重析构崩溃。二、左值引用
T&/ 右值引用T&&细节与坑1. 左值引用
T&规则:只能绑定左值,不能直接绑定右值
cpp
运行
int a = 10; int& r1 = a; // 合法 int& r2 = 20; // 编译报错补充特殊:
const T&万能引用,左值、右值全都能绑定(拷贝构造标准参数)。2. 右值引用
T&&(C++11)规则:仅能绑定天然右值 /
std::move转换后的左值; 核心用途:匹配移动构造、移动赋值,实现资源转移,规避深拷贝。cpp
运行
int&& rr1 = 10; int a = 20; int&& rr2 = std::move(a); // 合法 int&& rr3 = a; // 报错,原生左值无法绑定右值引用高频坑点
- ❌ 移动构造 / 移动赋值参数加
const:const T&& otherconst 修饰后成员只读,无法执行other.name_ = std::move(...)置空资源,报「不可修改左值」。 ✅ 移动函数参数必须是纯T&&,不能带 const。- ❌ 混淆
T&/T&&匹配逻辑 左值不加 move → 匹配const T&拷贝重载; 右值 /move 左值 → 匹配T&&移动重载。- ❌
const T&&无实际工程价值,几乎不用。- ❌ 非模板函数里写
T&&不是万能引用,只是单纯右值引用,无法自动推导。三、std::move 细节与坑
核心本质
仅做无条件类型转换:任意值转为
T&&右值引用;不拷贝、不转移、不销毁对象,资源转移逻辑写在移动构造 / 赋值内部。使用场景
- 具名左值不再使用,手动触发移动:
Wrapper w2 = std::move(w1);- 天然临时右值无需 move,写了冗余无意义。
规范:move 后源对象状态
C++ 标准:有效但未指定 允许操作:安全析构、重新赋值覆盖; 禁止操作:读取原有资源数据(资源已被夺走,行为未定义)。
踩坑汇总
- 误区:
std::move会移动 / 删除对象 move 只是类型转换,没有任何内存操作;类不实现移动重载时,move 后依旧走拷贝。- ❌ 对 const 对象使用
std::move得到const T&&,无法匹配移动函数,只会执行深拷贝,完全失去性能优化意义。- ❌ move 全局 / 静态对象 资源转移后原对象生命周期还在,析构时双重释放崩溃。
- ❌ 移动后继续读取源对象内部数据,结果不可预测。
- ❌ 容器类移动时直接赋值,不用
std::move如name_ = other.name_是深拷贝;必须name_ = std::move(other.name_)才会触发 string 内部移动。四、移动构造 & 移动赋值(结合 StringWrapper 题目)
细节区分
- 移动构造
T(T&& other)场景:新建对象,自身无旧资源,无需提前释放内存; 逻辑:接管对方资源,源对象置空。- 移动赋值
T& operator=(T&& other)场景:对象已存在,持有旧资源; 必做三步:自赋值判断if(this == &other)→ 释放自身旧资源 → 转移资源、源对象置空。本题 StringWrapper 专属坑
- ❌ 手动写
other.name_ = ""清空字符串 std::string 移动后会自动清空源对象,手动赋值多余;裸指针才需要手动置空。- ❌ 有参构造不加
const &Wrapper(std::string name)会产生额外字符串拷贝,标准写法const std::string&。- ❌ 单参构造不加
explicit,发生隐式转换Wrapper w = "abc";静默创建临时对象,易产生意外内存开销。- ❌ 拷贝构造 / 拷贝赋值仅写删除声明,参数漏写 const 规范。
测试移动语义两种标准方法(题目验收要求)
- 打印构造日志:区分「普通拷贝构造」「移动构造」,直观看到是否触发移动;
- 对比移动前后对象状态:源对象字符串清空,新对象完整持有数据,证明资源转移而非拷贝。
五、std::boolalpha 细节
- 作用:控制
cout布尔输出格式 默认:true=1,false=0;std::cout << std::boolalpha;开启文本输出:true /false;std::noboolalpha切回数字模式。- 用途:调试类型判断、is_rvalue_reference 等 type_traits 输出,可读性更高。
六、std::is_rvalue_reference 类型判断工具
基础细节
- 头文件
<type_traits>;C++11 起支持;- 作用:编译期判断类型本身是否为右值引用
T&&
std::is_rvalue_reference<T>::value老式写法;- C++17 简写
std::is_rvalue_reference_v<T>; 返回 bool 值,配合std::boolalpha打印。- 配套区分工具:
is_lvalue_reference_v<T>:判断左值引用T&;is_reference_v<T>:任意引用(左 / 右)均返回 true。踩坑
- ❌ 误以为可以直接判断变量是左 / 右值 它只判断类型声明,判断变量值类别需要搭配
decltype(变量)。- ❌ 普通变量
int a; decltype(a)是 int,不是引用,返回 false。const int&&也会判定为 true,属于右值引用,但无实用移动价值。七、完美转发 std::forward 细节与坑
核心作用
模板万能引用
T&&配套工具,保留参数原始左 / 右值属性原样转发,不会丢失移动语义。万能引用推导规则(模板内 T&&)
- 传入左值 → T 推导为
X&,最终类型X& && = X&(左值引用);- 传入右值 → T 推导为
X,最终类型X&&(右值引用)。std::move vs std::forward 核心区分
表格
std::move std::forward<T> 无条件强制转右值 有条件保留原始值类别 普通代码手动转移资源 仅模板万能引用场景使用 不需要模板参数 必须显式传入模板类型 消耗源对象 不修改对象,仅转发类型 踩坑
- ❌ 模板万能引用不使用
std::forward,所有参数统一变为左值,永远无法触发移动;- ❌ 普通非模板函数滥用
std::forward,无任何意义;- ❌ forward 模板参数传错类型,转发类型错乱。
template 模板
函数模板
1. 核心概念
函数模板:通用函数蓝图,代码逻辑完全相同,类型不写死;调用时编译器根据实参自动推导 / 指定类型,生成对应类型的真实函数(实例化)。 优势:一份代码兼容所有类型,不用重复写
int/double/ 自定义类重载函数。2. 基础语法
模板头
cpp
运行
template <模板参数列表> 返回值 函数名(形参列表) { 逻辑 }模板参数两种:
typename T/class T:类型参数(代表任意数据类型,二者无区别)int N:非类型参数(编译期常量,数字 / 枚举 / 指针常量)最简示例(通用求和)
cpp
运行
#include <iostream> // T是类型模板参数 template<typename T> T add(T a, T b) { return a + b; } int main() { std::cout << add(1, 2) << "\n"; // T = int std::cout << add(1.5, 2.3) << "\n"; // T = double std::cout << add(std::string("a"), std::string("b")) << "\n"; // T = string return 0; }3. 函数模板实例化(两种方式)
实例化 = 编译器根据模板生成对应具体类型的真实函数代码
(1)隐式实例化(最常用,自动推导)
调用时不传类型,编译器根据实参自动推导
T:cpp
运行
add(10,20); // 实参int → T=int,隐式生成add<int>推导规则:实参类型必须匹配,否则推导失败报错
cpp
运行
add(1, 2.5); // 报错:一个int一个double,无法推导出唯一T解决:显式指定类型,或重载多模板参数
cpp
运行
template<typename T1, typename T2> auto add(T1 a, T2 b) { return a + b; } add(1, 2.5); // T1=int, T2=double(2)显式实例化(手动指定类型,
<>传参)强制指定模板参数,不依赖推导:
cpp
运行
add<int>(1, 2); add<double>(1.1, 2.2); // 即使参数类型不匹配,会强制转换 add<double>(1, 2.5);适用场景:无法推导的场景(无实参对应模板参数、返回值单独指定类型)
4. 函数模板特化(全特化)
特化:对某一个特定类型重写专属逻辑,覆盖通用模板实现 语法:
template<> 完整指定所有模板参数cpp
运行
#include <iostream> #include <string> template<typename T> void print(T val) { std::cout << "通用版本:" << val << "\n"; } // 全特化:专门给std::string单独写逻辑 template<> void print<std::string>(std::string val) { std::cout << "字符串特化版本:[" << val << "]\n"; } int main() { print(100); // 通用模板 print(std::string("hello")); // 调用string特化版本 return 0; }输出:
plaintext
通用版本:100 字符串特化版本:[hello]5. 函数模板核心坑点
- ❌ 实参类型不一致,单模板参数无法推导,编译报错;
- ❌ 模板定义和实现分离写在
.h+.cpp,链接报错(模板代码必须全放头文件,编译器需要完整代码实例化);- ❌ 特化漏写
template<>,语法错误;- ❌
typename和class混用无问题,但统一风格更好;- 万能引用
template<typename T> void func(T&& arg)属于函数模板专属推导,普通函数无推导。
二、类模板
1. 核心概念
类模板:类的蓝图,成员的类型不固定;定义容器、智能指针、数组通用结构(
std::vector<T>就是标准库类模板)。 实例化时传入类型,编译器生成对应类型的完整类。2. 基础语法
cpp
运行
template<模板参数> class 类名 { 成员(可以使用模板参数T) };示例:通用数组容器
cpp
运行
template<typename T> class MyArray { private: T* data; int size; public: // 构造、成员函数都可以使用T explicit MyArray(int n) { size = n; data = new T[n]{}; } // 成员函数声明 T& get(int idx); ~MyArray() { delete[] data; } };3. 类模板成员函数两种写法
写法 1:函数写在类内部(简单)
直接使用
T,无需额外模板头。写法 2:函数写在类外部(必须重写模板头)
cpp
运行
template<typename T> T& MyArray<T>::get(int idx) { return data[idx]; }重点:类名必须写
MyArray<T>,不能只写MyArray。4. 类模板实例化
(1)隐式实例化
定义对象时指定
<类型>,编译器生成对应类代码:cpp
运行
MyArray<int> arr1(5); // 实例化 MyArray<int> MyArray<double> arr2(10); // 实例化 MyArray<double>(2)显式实例化(全局强制生成类)
cpp
运行
template class MyArray<std::string>;5. 类模板的静态成员
每个实例化的类型拥有独立静态成员,互不干扰:
cpp
运行
template<typename T> class Test { public: static int cnt; }; // 外部初始化静态成员 template<typename T> int Test<T>::cnt = 0; int main() { Test<int>::cnt = 10; Test<double>::cnt = 20; // Test<int> 和 Test<double> 的cnt是两块独立内存 return 0; }6. 类模板特化(完全特化 + 偏特化)
6.1 完全特化(全特化)
所有模板参数全部指定,单独重写整个类,针对单一类型定制:
cpp
运行
template<typename T> class Data { public: void show() { std::cout << "通用类型\n"; } }; // 全特化:T=std::string template<> class Data<std::string> { public: void show() { std::cout << "字符串专属特化\n"; } };6.2 偏特化(部分特化)
仅固定一部分模板参数,保留另一部分可变;最常用:指针偏特化
cpp
运行
// 主模板 template<typename T> class Container { }; // 偏特化:所有指针类型 T* template<typename T> class Container<T*> { // 针对指针单独实现逻辑 }; // 使用 Container<int> c1; // 主模板 Container<int*> c2; // 匹配指针偏特化版本7. 类模板高频坑点
- ❌ 外部成员函数忘记加
template<typename T>、类名漏写<T>;- ❌ 模板拆分头文件与实现文件,链接失败;
- ❌ 静态成员误以为全局共享:不同
T实例静态变量完全隔离;- ❌ 偏特化语法写错,
Container<T*>顺序颠倒;- ❌ 类模板构造不加
explicit,发生隐式转换。
三、函数模板 vs 类模板 对比速记
表格
特性 函数模板 类模板 实例化触发 调用函数,实参推导 定义对象,手动 <T>指定类型推导 支持隐式推导 无隐式推导,必须显式写 <T>特化 仅支持全特化,无偏特化 支持全特化 + 偏特化 静态成员 无静态成员概念 每个类型实例独立静态成员 典型使用 通用算法(swap、add、print) 容器、封装资源(vector、unique_ptr) 四、配套拓展:万能引用(函数模板专属)
cpp
运行
template<typename T> void wrapper(T&& arg) // T&& 万能引用 { // 完美转发保留左右值属性 target(std::forward<T>(arg)); }只有函数模板的
T&&是万能引用;普通函数T&&仅为右值引用,无推导功能。
可变参数
可变参数模板(参数包 ...)完整笔记
一、核心概念
1. 什么是可变参数模板
普通模板参数数量固定,可变参数模板通过
...定义模板参数包,可以接收任意个数、任意类型的参数。
- 模板参数包:
typename... Args- 函数形参包:
Args... args适用场景:打印多参数、通用转发函数、容器构造、日志格式化等。2. 两个关键名词
- 参数包(pack):
Args...一堆类型 /args...一堆值的集合- 展开参数包(unpack):把一包参数逐个拆解、递归处理
- 终止递归条件:特化 / 重载空参数版本,防止无限递归
二、基础语法规则
1. 模板参数包声明
cpp
运行
// Args 是模板参数包,代表任意多个类型 template<typename... Args> void func(Args... args) // args 是函数形参包,对应一堆实参 { }调用示例:
cpp
运行
func(); func(1); func(1, 3.14, "abc", std::string("test"));2. 包展开
args...
...放在包名后代表一次性展开所有参数,只能在特定场景使用:
- 函数传参
- 初始化列表
- 基类构造、成员初始化列表
- sizeof...(包):统计参数包内参数个数
sizeof... 获取参数数量
cpp
运行
template<typename... Args> void count(Args... args) { // sizeof... 编译期计算参数包长度 std::cout << "参数个数:" << sizeof...(args) << "\n"; } count(1,2,3); // 输出3三、两种经典参数包展开方式(必考)
方式 1:递归模板展开(最传统、考试重点)
思路:
- 主模板:取出第一个参数,处理,再递归传入剩下的包
- 终止重载:空参数版本,递归出口
示例:通用打印函数
cpp
运行
#include <iostream> #include <string> // 递归终止:无参数,出口 void print() { std::cout << "\n"; } // 可变参数递归模板 template<typename T, typename... Args> void print(T first, Args... rest) { // 处理当前第一个参数 std::cout << first << " "; // 递归展开剩余参数包 rest... print(rest...); } int main() { print(); print(10); print(1, 3.14, "hello", std::string("world")); return 0; }执行流程
print(1,3.14,"hello"):
- first=1,rest=(3.14,"hello") → print(3.14,"hello")
- first=3.14,rest=("hello") → print("hello")
- first="hello",rest = 空 → print () 触发终止重载,结束递归
坑点:必须提供空参终止函数
如果没有无参
print(),递归到空包时无匹配函数,编译报错。方式 2:初始化列表折叠展开(C++11 简化写法,不用递归)
利用
{}初始化列表一次性展开参数包,无需递归终止函数。cpp
运行
template<typename... Args> void print2(Args... args) { // 逗号表达式依次执行每个参数打印 int arr[] = { (std::cout << args << " ", 0)... }; std::cout << "\n"; } int main() { print2(1, 2.2, "test"); }
(expr,0)...逗号表达式保证只执行打印,数组仅用来承载展开逻辑。四、类模板可变参数包(构造函数转发场景)
配合完美转发
std::forward,实现万能构造(类似 emplace_back)cpp
运行
#include <utility> #include <string> template<typename T> class Wrapper { private: T obj; public: // 可变参数构造,任意参数转发给T的构造函数 template<typename... Args> Wrapper(Args&&... args) : obj(std::forward<Args>(args)...) { } void show() const { std::cout << obj << "\n"; } }; int main() { Wrapper<std::string> w1("hello"); Wrapper<int> w2(100); return 0; }关键点:
std::forward<Args>(args)...转发时同步展开参数包。五、可变参数模板特化(递归终止的另一种写法)
除了重载空函数,也可以用空参数包特化做递归出口:
cpp
运行
// 主模板:非空参数包 template<typename... Args> void test(Args... args) { std::cout << "通用可变版本\n"; } // 空包全特化,递归终止 template<> void test<>() { std::cout << "空参数终止\n"; }六、万能引用 + 可变参数包(完美转发标准组合)
cpp
运行
template<typename... Args> void forwardFunc(Args&&... args) { target(std::forward<Args>(args)...); }
Args&&每个参数都是万能引用,保留原始左 / 右值属性std::forward<Args>(args)...同步展开所有参数,完整转发
一、本次代码出现的 4 个核心错误(逐条细节)
坑 1:同时重载
T&普通左值引用模板 和T&&万能引用模板,左值传入产生重载二义性原错误代码:
cpp
运行
template<typename T> void process(T &l); template<typename T> void process(T &&r);
- 推导规则:传入左值
int a
T&版本:T=int,形参int&T&&万能引用:T=int&,折叠后int& && = int&两个模板完全匹配,编译器不知道选谁,直接编译报错。- 正确规范: 只保留单一万能引用模板
T&&,内部用if constexpr + type_traits判断左 / 右值,不要分两套模板重载。- 配套头文件:
<type_traits>,提供is_lvalue_reference_v。坑 2:单参数函数一次性传入展开后的多参数包,参数数量不匹配,语法报错
原错误逻辑:
cpp
运行
template<typename ... Args> void wrapper(Args... args){ process(std::forward<Args>(args)...); }
- 问题本质:
process仅接收1 个形参;std::forward<Args>(args)...会把所有参数全部展开,一次性丢进 process。 调用wrapper(1,a,10)等价于process(1,a,10),参数个数不匹配编译失败。- 原理:参数包展开
...会把一包参数平铺成多个独立实参。- 解决方案:递归拆解参数包,一次只传一个参数给 process。
坑 3:可变参数包不会自动逐个遍历,必须手动递归 / 折叠展开
- 核心细节:参数包只是一组类型 / 值的集合,没有自动循环逻辑;
- 两种标准遍历方式:
- 递归模板(考试常用):取出第一个参数处理,剩余包递归传递;提供空参终止重载;
- C++17 折叠表达式:
(process(std::forward<Args>(args)), ...),无需递归。- 原代码误区:误以为 forward 展开会自动逐个调用 process,实际是一次性全传入。
坑 4:缺失必要头文件(隐性报错)
使用
std::is_lvalue_reference_v、万能转发、类型判断需要:
<utility>:std::forward、std::move<type_traits>:is_lvalue_reference_v、is_rvalue_reference_v 漏写会提示标识符未定义。二、万能引用
T&&关键细节(配套本题)
- 只有函数模板内的
T&&才是万能引用,普通函数T&&仅为右值引用,无推导能力;- 万能引用推导规则:
- 传入左值
int a→ T 推导为int&,最终类型int& && = int&(左值引用)- 传入右值
10→ T 推导为int,最终类型int&&(右值引用)std::forward<T>(val)作用:还原参数原始左 / 右值属性,完美转发; 转发可变参数必须写std::forward<Args>(args)...,末尾不能省略...。三、可变参数模板递归展开标准规范(背诵)
- 拆分逻辑:
T&& first, Args&&... args分离第一个参数与剩余参数包;- 处理当前第一个参数:
process(std::forward<T>(first));- 递归转发剩余包:
wrapper(std::forward<Args>(args)...);- 必须提供空参数终止重载:
void wrapper(){},否则递归无出口编译报错;- 转发每一层参数都要搭配
std::forward,否则丢失右值属性,无法触发移动语义。四、std::forward 参数包展开语法细节
- 声明包:
template<typename... Args>- 形参万能引用包:
Args&&... args- 转发并展开:
std::forward<Args>(args)...
- 少写
...:仅转发类型不展开,编译报错;- 不使用 forward:全部强制转为左值,丢失移动语义。
五、高频易混误区速记
- ❌ 分开重载
T&/T&&模板 → 左值二义性; ✅ 统一只用万能引用T&&,内部判断值类别;- ❌ 单参函数接收展开后的多参数包 → 参数数量不匹配; ✅ 递归逐个取出参数再处理;
- ❌ 可变参数不使用万能引用
Args&&...,直接Args...→ 右值会发生拷贝; ✅ 可变参数转发统一Args&&...+ forward;- ❌ 递归调用时漏写
args...,只传 args → 无法展开参数包;- ❌ 忘记空参数终止函数,递归无限嵌套编译失败。
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)